

Pre-Incident Preparation
Your chances of performing a successful investigation are low unless your organization commits resources to prepare for such an event. This chapter on pre-incident preparation is designed to help create an infrastructure that allows an organization to methodically investigate and remediate. This chapter will help ensure your team is properly prepared to investigate, collect, analyze, and report information that will allow you to address the common questions posed during an incident:
• What exactly happened? What is the damage and how did the attackers get in?
• Is the incident ongoing?
• What information was stolen or accessed?
• What resources were affected by the incident?
• What are the notification and disclosure responsibilities?
• What steps should be performed to remediate the situation?
• What actions can be taken to secure the enterprise from similar incidents?
The investigation itself is challenging. Extracting the necessary data from your information systems and managing communications will be equally challenging unless you prepare. This chapter will help you make preparations that significantly contribute to a successful investigation. We cover three high-level areas:
• Preparing the organization This area includes topics such as identifying risk, policies for a successful IR, working with outsourced IT, global infrastructure concerns, and user education.
• Preparing the IR team This area includes communication procedures and resources such as hardware, software, training, and documentation.
• Preparing the infrastructure This area includes asset management, instrumentation, documentation, investigative tools, segmentation, and network services.
PREPARING THE ORGANIZATION FOR INCIDENT RESPONSE
Computer security is a technical subject, and because there is a perceived ease to it, many organizations tend to focus on the technical issues: buy an appliance, install agents, and analyze “big data” in the cloud. Money is easier to come by than skilled personnel or committing to self-improvement. However, during most investigations, we are regularly faced with significant organizational challenges of a nontechnical nature. In this section we cover some of the most common challenge areas:
• Identifying risk
• Policies that promote a successful IR
• Thoughts on global infrastructure issues
• Educating users on host-based security
Identifying Risk
The initial steps of pre-incident preparation involve getting the big picture of your corporate risk. What are your critical assets? What is their exposure? What is the threat? What regulatory requirements must your organization comply with? (These generally have some associated risk.) By identifying risk, you can ensure that you spend resources preparing for the incidents most likely to affect your business. Critical assets are the areas within your organization that are critical to the continued success of the organization. The following are some examples of critical assets:
• Corporate reputation Do consumers choose your products and services in part due to their confidence in your organization’s ability to keep their data safe?
• Confidential business information Do you have critical marketing plans or a secret product formula? Where do you store patents, source code, or other intellectual property?
• Personally identifiable information Does your organization store or process PII data?
• Payment account data Does your organization store or process PCI data?
Critical assets are the ones that produce the greatest liability, or potential loss, to your organization. Liability occurs through exposures. Consider what exposures in your people, processes, or technology result in or contribute to loss. Examples of exposures include unpatched web servers, Internet-facing systems, disgruntled employees, and untrained employees.
Another contributing factor is who can actually exploit these exposures: Anyone connected to the Internet? Anyone with physical access to a corporate building? Only individuals physically within a secure area? Combine these factors to prioritize your risk. For example, the most critical assets that have exposures accessible only to trusted individuals within a controlled physical environment may present less risk than assets with exposures accessible to the Internet.
Risk identification is critical because it allows you to spend resources in the most efficient manner. Not every resource within your environment should be secured at the same level. Assets that introduce the most risk receive the most resources.
Policies That Promote a Successful IR
Every investigative step your team makes during an IR is impacted by policies that should be in place long before that first notification occurs. In most situations, information security policies are written and executed by the organization’s legal counsel in cooperation with the CISO’s office and compliance officers. Typical policies include:
• Acceptable Use Policy Governs what the expected behavior is for every user.
• Security Policy Establishes expectations for the protection of sensitive data and resources within the organization. Subsections of this policy may address physical, electronic, and data security matters.
• Remote Access Policy Establishes who can connect to the organization’s resources and what controls are placed on the connections.
• Internet Usage Policy Establishes appropriate use of general Internet resources, including expectation of privacy and notification of monitoring by or on behalf of the organization.
The policies that IR teams should be most concerned about would address expectations on the search and seizure of company-owned resources and interception of network traffic. If these two (admittedly general) issues are covered, the team should be able to perform most investigative actions. As we note elsewhere in this chapter, be aware of local privacy laws that will affect your actions. An action performed in one office may run afoul of federal laws in another.
GO GET IT ON THE WEB
ISO 27002:2005 www.iso.org
Working with Outsourced IT
In many larger organizations, and even some mid or small size, we have found there is a good chance that at least some IT functions are outsourced. If the investigation requires a task to be performed by the outsourced provider, there may be challenges in getting the work done. Usually processes are in place for requesting the work, which may require project plans, approvals, or other red tape. There may also be an additional cost, sometimes charged per system, for minor configuration changes such as host-based firewall rules. In some cases, there may be no vehicle to accomplish a requested task because it falls outside the scope of the contract. We have experienced this situation when an organization requested log files from an outsourced service for analysis.
These challenges may prevent the investigation from moving forward effectively. What every organization should do is work with their providers to ensure arrangements are in place that include service level agreements (SLAs) for responsiveness to critical requests and options to perform work that is out of scope of the contract. Without the proper agreements in place, you may find yourself helpless in an emergency.
Thoughts on Global Infrastructure Issues
In recent years, we’ve performed a number of intrusion investigations with large multinational organizations. During those investigations, we were met with new and interesting challenges that gave us some insight into how hard it is to properly investigate an incident that crosses international borders. Although we don’t have all the answers, we can make you aware of some of the challenges you may face so you have time to prepare.
Privacy and Labor Regulations
As investigators, we normally view an organization’s network as a large source of evidence just waiting for us to reach out and find it. One may not immediately consider that the network spans five countries on three continents, each with its own local privacy laws and regulations. It’s easy to get yourself into trouble if you decide to search for indicators of compromise and the method you use violates local privacy laws or federal labor regulations. If you plan to investigate an incident that involves a network spanning more than one country, you will need to do some homework before you begin. You should contact the organization’s legal counsel within each country to discuss the situation and determine what actions you can, and cannot, take.
Team Coordination
Another significant challenge with incidents that span the globe is coordination. Because both personnel and technology resources will be spread out over many time zones, staying organized will require careful planning and constant effort to ensure everyone is in sync. Because some staff may be sleeping while you are awake, getting things done may take more time. Tracking tasks and performing handoffs will be critical to ensure that acceptable progress is made. Scheduling a meeting could take days because participants are in different time zones.
Data Accessibility
During an investigation, massive amounts of data are collected for analysis. Oftentimes, it is in the form of singularly large data sets, such as hard disk images. When the core team is responsible for performing the majority of the analysis tasks, you must find a way to efficiently transfer this data to the team members with forensic analysis experience. Although you should keep in mind any customs documentation or restrictions in the source and destination countries, the greatest challenge will be the delay in getting relevant data into the right hands. If there is any question whether data needs to be transferred, begin the process immediately. Multiple days have been lost from miscommunication or indecision.
Educating Users on Host-Based Security
Users play a critical role in your overall security. The actions users take often circumvent your best-laid security plans. Therefore, user education should be a part of pre-incident preparation.
Users should know what types of actions they should and should not take on their systems, from both a computer-security and an incident-response perspective. Users should be aware of the common ways attackers target and take advantage of them to compromise the network. Users should be educated about the proper response to suspected incidents. Typically, you will want users to immediately notify a designated contact. In general, users should be instructed to take no investigative actions, because these actions can often destroy evidence and impede later response.
A specific issue you should address is the danger inherent in server software installed by users. Users might install their own web or FTP servers without authorization, thereby jeopardizing the overall security of your organization. Later in this chapter, we mention removing administrative privileges, which is a configuration change that helps to mitigate this risk. However, users can sometimes find ways around security measures and should be made aware of the danger associated with installing unauthorized software.
PREPARING THE IR TEAM
As we introduced in the previous chapter, the core IR team is composed of several disciplines: IT, investigators, forensic examiners, and even external consultants. Each is likely to come to the team with different skills and expectations. You will want to ensure that your team is composed of hard workers who show attention to detail, remain in control, do not rush the important things, and document what they are doing. The groundwork for team development will be built in this section. We will discuss defining the mission, communication, deliverables, and the resources necessary to outfit the team properly.
Defining the Mission
Defining the mission of your IR team will help keep the team focused and set expectations with the rest of your organization. All elements of the team’s mission must be fully endorsed and supported by top management; otherwise, the IR team will not be able to make an impact within the organization. The team’s mission may include all or some of the following:
• Respond to all security incidents or suspected incidents using an organized, formal investigative process.
• Conduct a complete impartial investigation.
• Quickly confirm or dispel whether an intrusion or security incident actually occurred.
• Assess the damage and scope of an incident.
• Control and contain the incident.
• Collect and document all evidence related to an incident.
• Select additional support when needed.
• Provide a liaison to proper law enforcement and legal authorities.
• Maintain appropriate confidentiality of the incident to protect the organization from unnecessary exposure.
• Provide expert testimony.
• Provide management with recommendations that are fully supported by facts.
Communication Procedures
During an incident, you will have several teams working concurrently: your core investigative team, ancillary teams, legal teams, and system administrators who not only respond to the core team’s tasks, but who often perform pertinent actions on their own. Good communication is paramount, and defining how that works before an incident begins is essential. This section discusses tactical and ad-hoc communications.
Discuss with your organization’s counsel the topic of communications and documentation. They may prefer that you include their office on certain communications to ensure that the information is not discoverable. That decision depends heavily on the nature of the IR work you are performing and whether any work the organization does is subject to compliance controls. In this section we will assume you have sought proper guidance on this issue and are labeling communications appropriately. |
Internal Communications
In a large number of recent investigations, the attackers made a beeline to the e-mail servers. On a number of servers, we discovered evidence that the attackers retrieved the e-mail boxes of C-level employees and senior IT administrators. Shortly thereafter, the attackers returned and searched the entire mail server for strings related to the investigation. Sadly, the threat of the attackers watching you watching them is not theoretical. Keep the following Communications Security (ComSec) issues in mind when preparing for an IR:
• Encrypt e-mail. Before an incident occurs, procure S/MIME certificates for members of the core and ancillary IR teams. Check with your organization’s IT department, as they may issue certificates to employees at no direct cost to you. Alternatives such as PGP may be used; however, integration with common mail clients is traditionally poor.
• Properly label all documents and communications. Phrases such as “Privileged & Confidential,” “Attorney Work Product,” and “Prepared at Direction of Counsel” may be prudent, or even required. You should seek legal counsel to establish what labels, if any, are appropriate.
• Monitor conference call participation. Ensure that your conference call system allows you to monitor who has called in or who is watching a screencast. Keep an eye on the participant list and disconnect unverified parties.
• Use case numbers or project names to refer to an investigation. Using project names helps to keep details out of hallway conversations, meeting invitations, and invoices for external parties. This is less applicable to possible interception by the attackers as it is to minimizing the number of personnel who have details on the IR. Outwardly, treat it as you would any other project. The fewer people who know about a possible lapse in security, the better.
Keep in mind the type of information that is sent to your e-mail server from automated processes. If your incident management system, IDS, or simply the voicemail system for your desk phone sends you potentially sensitive information, consider limiting the contents of those messages to a simple notification. Although it is a bit inconvenient, it may prevent the compromise of investigative data. |
GO GET IT ON THE WEB
Sources for free S/MIME certificates
Sources for commercial S/MIME certificates
Communicating with External Parties
If an organization is lucky, the impact of an intrusion will not require notification or consultation with external entities. With the growing amount of governance and legislation, not to mention incident disclosure language in contracts, it is highly likely that your organization will need to determine how it communicates with third parties. Planning for potential disclosure is a process that should involve legal counsel, compliance officers, as well as C-level personnel.
We cannot provide much guidance on this topic, except to manage it well. Use approved channels, such as your public relations (PR) or legal office. Once disclosure occurs, you may lose control of the investigation. Other entities may use contracts to demand actions or investigative steps that are meant to protect their interests over the interests of your organization. A few questions to consider when determining the content and timing of any notification are
• When does an incident meet a reporting threshold? Immediately at detection? Perhaps after the incident has been confirmed?
• How is a notification passed to the third party? What contract language is in place to protect confidentiality?
• If the incident warrants a public disclosure, who is responsible for the contents and timing of the communication? How is the disclosure to occur?
• What penalties or fines are levied against your organization post-disclosure? Consider whether the timing of the notification impacts this factor
• What investigative constraints are expected after the disclosure? Is a third party required to participate in the investigation?
• How does disclosure affect remediation?
Deliverables
Because we work for a consulting firm, deliverables are an important part of what we provide our customers. We believe it’s important for any team to view what they do in terms of service delivery and define the standard items they will produce. The most important deliverables for an IR team are investigative reports. The reports may range from simple one-page status updates to detailed forensic examination reports that are 30 pages long each. Your IR team should explicitly define its primary deliverables, including the appropriate target completion time frames or recurrence intervals. In addition, you should create templates and instructions for each deliverable to ensure consistency. A sample list of deliverables for an IR team follows:

As with any team, your IR team will need resources to be successful. In addition to the standard organizational elements, such as providing training and creating documentation, an IR team has unique hardware and software requirements. Even if you have already established resources for your team, you may find it useful to read through this section to get our perspective on each area.
Training the IR Team
The importance of good training cannot be overemphasized. Numerous classes provide hands-on incident response training. These courses are usually well worth their cost. Programs offered at select universities typically provide the best education. The universities currently offering the best programs are:
• Carnegie Mellon Software Engineering Institute (www.sei.cmu.edu)
• Purdue University College of Technology (tech.purdue.edu)
• Johns Hopkins University Information Security Institute (isi.jhu.edu)
The SysAdmin, Audit, Networking, and Security (SANS) Institute is currently the leader in the commercial IR and computer forensic training market. They have a large number of quality courses.
GO GET IT ON THE WEB
The SANS Institute www.sans.org
Hardware to Outfit the IR Team
Modern hardware solutions make it much easier for an IR team to perform forensic and IR tasks using a commodity computer system. Higher-end systems from major computer vendors in conjunction with some specialized forensic hardware will likely meet the needs of your IR team. At the company we work for, there are two high-level locations where we perform investigative work: out in the field and back at our office. We’ll cover the solutions that have worked for us in each of these settings.
Data Protection During an incident, you will be handling and analyzing sensitive data. Whether in the field, at your office, or in transport, you must take the appropriate steps to ensure that data is not accessible to unauthorized parties. The most effective way to do this is use a solution that encrypts the data. There are two high-level categories where sensitive data might rest:
• Permanent, internal media This includes hard drives or media that are a permanent part of a computer system. The most common solution is to use a software-based full disk encryption (FDE) product such as Truecrypt or McAfee Endpoint Encryption. Another option, although usually somewhat expensive, is to use hardware-based FDE, sometimes called a Self-Encrypting Drive (SED).
• External media Often portable, this includes thumb drives, USB drives, and regular hard drives that are in external enclosures. There are a variety of solutions for this category, both software and hardware. A common software solution is Truecrypt. Hardware solutions include in-line USB and SATA.
GO GET IT ON THE WEB
Be sure to properly assess your risk when deciding if you will encrypt storage media. Laptops used in insecure environments or shipping portable media are examples of high risk. Desktop systems in a secure, restricted access lab environment are low risk. Also, keep in mind that even though you may not copy sensitive data on your computer, sensitive data may still find its way on your hard drive. For example, if you access data on a network share or external USB drive, the operating system or an application may create temporary files on your local hard drive. If you find yourself looking for reasons not to use encryption, you probably need it. Remember that most CPUs now have special encryption instructions that provide a performance boost, so adding encryption is no longer a performance concern. |
Forensics in the Field Many incidents require us to perform forensic work on our customer’s site. The main platform we use in that situation is a well-equipped laptop from a major vendor. We select a laptop that interfaces properly with the specialized forensic hardware that we discuss in the upcoming shared equipment section. There are a few additional considerations we keep in mind when building the system:
• Memory Normally specified to be at or near the maximum capacity supported by the platform.
• CPU Normally within the top tier for the platform.
• I/O buses Includes eSATA, Firewire 800, USB 3.0, and other high-speed interfaces for external hard drives.
• Screen size and resolution Physically large and a high resolution. It is difficult to get work done on a 14-inch display.
• Portability Weight and dimensions are important when one is on the road.
• Warranty service If the equipment fails, the vendor should be able to send a replacement or technician immediately.
• Internal storage Large and fast are the adjectives to keep in mind. Additionally, if you are able to find a self-encrypting drive that is supported by your BIOS, it is worth the extra cost.
Forensics at the Office During some incidents, we perform the forensics work at our office. Our customers or other employees of our company may ship hard drives, disk images, or other relevant data to our offices for analysis. On both coasts, we have dedicated labs where systems with write blockers are ready to create working copies of evidence. The original material is then stored in a controlled area in accordance with written evidence-handling policies. Our analysts use virtual environments to perform the analysis on the working copies. We maintain standard examination environment templates preconfigured with common forensic tools, and we spawn a new, clean virtual machine per examiner, per case. Once the analysis is complete, the virtual machine is destroyed. This operating model allows each analysis to begin from a known state, and helps to prevent clutter and resource contention.
Shared Forensics Equipment In both operating locations noted previously, an IR team or group of analysts use a set of shared resources in addition to their assigned workstations. First, we need specialized forensic-related hardware. Several complete write-blocking kits should be available to the teams. Versions are available that allow for examination and duplication of many interfaces, including PATA, SATA, SCSI, and SAS. The approach we take is to keep a pool of this hardware at the office and make the items available for checkout as needed. In Chapter 8, we will discuss these categories of specialized forensic hardware in more detail:
• Stand-alone disk duplication and imaging systems
• Write blockers for all media interface types you expect to encounter
• Mobile device acquisition systems
• Assorted cables and adaptors
In addition to the specialized forensic hardware, we keep a healthy bench stock of the following items:
• Large external hard drives for evidence storage and for managing working copies of data
• Digital cameras for documenting evidence
• Blank CDs and DVDs
• Network switches and cabling
• Power strips and cables
• I/O bus cables—Firewire, eSATA, USB
• Computer maintenance tools such as screwdrivers, Torx bits, spudgers, and other specialized case-opening tools.
Network Monitoring Platforms We use two primary platforms for network monitoring. For ad-hoc monitoring, we have used laptop systems whose specifications closely mirror those used for on-site forensic work. The main advantages are that the platform is portable and has a built-in UPS. For most installations, however, we use 1U rack-mount systems with a high-end CPU, a respectable amount of memory (12–16GB at the time of publication), and storage whose speed and capacity are sufficient to hold incoming data for a reasonable period of time at 80 percent line rate of the connection we are monitoring. These monitoring platforms are typically outfitted with multiport network interface cards, allowing one to be reserved for a management interface and the remaining ports for monitoring. In some investigations, we also include interfaces for monitoring fiber and multigigabit copper links.
Monitoring network links with high utilization can be a challenge for most monitoring platforms, unless custom drivers and storage schemes are developed. For most environments, however, an organization can manage with a minimum install of FreeBSD or Linux. In the past, one would wrestle with kernel patches and system tuning, IDS system configuration, console installation (plus the multitude of libraries to experience a manageable analysis experience), and signature management. A few projects, three of which we’ve linked to below, have made deployment of a reliable monitoring platform easier. Network monitoring will be discussed in greater detail in Chapter 9.
GO GET IT ON THE WEB
Security Onion securityonion.blogspot.com
Network Security Toolkit networksecuritytoolkit.org
Easy-IDS skynet-solutions.net
Software for the IR Team
In this section, we cover the general categories and functions of basic software your IR team will need to be able to perform its job. Additional details on the use of specific tools are covered in the data analysis Chapters 11 through 16.
What Software Do We Use? Most organizations we work with ask us what kind of IR and forensic software we use and why. They are usually interested in if we use any free or open source tools, as well as if we use any commercial tools. The answer is that we use a combination of both free and commercial software, some open source and some closed source. Instead of endorsing specific tools, we’d rather explain our reasoning behind how we choose what tools to use.
When considering exactly what solutions we use, it usually comes down to time—all things being equal, we choose the tool gets the job done in the least amount of time. We factor in preparation, execution, and the reporting associated with findings from that tool. There are two main reasons why time is most important to us—because it allows us to find evil and solve crime faster (minimizing potential damage) and our customers pay us by the hour. Time is likely a major factor for your organization as well, but there may be other considerations, such as your budget.
We also like to have options—because sometimes a tool may not work in a given situation. So we normally have at least two or more tools that can perform the same (or a very similar) function. We maintain a list of the currently accepted tools a consultant may use. Before we place a tool on the list, however, we perform some testing. Even though other organizations may have already tested the tool, it is a good idea for you to test it in your environment.
You may hear some people say that a tool must be “forensically sound,” and that its status in that regard affects the admissibility of any findings from that tool in a court of law. However, there is no strict definition of “forensically sound,” and normally a judge decides admissibility of evidence in court. We encourage your IR team to consider the factors outlined in the legal cases outlined here.
In 1923, a federal court decided on a set of standards known as the Frye test. More recently, in 1993, the U.S. Supreme Court published an opinion that rewrote the standards necessary for the admissibility of scientific evidence in federal cases. (Note that the states have the freedom to adopt the standards from Frye, Dow, or their own case law.) This case, Daubert v. Merrell Dow Pharmaceuticals, 509 U.S. 579 (1993), shifted the focus from a test for general acceptance to a test for “reliability and relevance.” The judges’ findings on the admission of expert testimony resulted in the creation of a series of illustrative factors that are kept in mind during an inquiry of reliability. The four factors applied to determine the reliability of scientific techniques are as follows:
• Has the scientific theory or technique been empirically tested?
• Has the scientific theory or technique been subjected to peer review and publication?
• Is there a known or potential error rate? Do standards that control the technique’s operation exist?
• Is there a general acceptance of the methodology or technique in the relevant scientific community?
During another case, Kumho Tire Co et al. v. Carmichael et al. (1993), the court found that the tests set forth in the Daubert standard were insufficient for testing cases where the methodology was not formed on a scientific framework. These methods were no less valid; however, the law was not provisioned to account for this type of analysis. The court came up with additional tests to address these deficiencies:
• Has the technique been created for a purpose other than litigation?
• Does the expert sufficiently explain important empirical data?
• Is the technique based on qualitatively sufficient data?
• Is there a measure of consistency to the technique’s process or methods?
• Is there a measure of consistency to the technique’s process or methods as applied to the current case?
• Is the technique represented in a body of literature?
• Does the expert possess adequate credentials in the field?
• How did the technique used differ from other similar approaches?
Types of Software Used by IR Teams The software that we use during investigations generally falls into eight categories. Your IR team should inventory what it has for each area, and research if it needs any additional tools based on some of the criteria we discuss here:
• Boot disks This category consists of “live” media (CD or USB) you can boot to and perform useful IR or forensic tasks. For example, the Backtrack, CAINE, and Helix projects all provide bootable environments that are useful for IR or forensic tasks.
GO GET IT ON THE WEB
BackTrack www.backtrack-linux.org
CAINE www.caine-live.net
Helix www.e-fense.com
• Operating systems The IR team should be familiar with each OS that is used within their organization. We recommend obtaining installation media for each OS and create virtual machines that have snapshots you can revert to. This is quite helpful for learning purposes, but you may need to perform tests or other experiments to develop or confirm accurate procedures.
• Disk imaging tools Maintain a list of imaging tools authorized by your team. To understand what should and should not make this list, review the NIST Computer Forensic Tool Testing site at www.cftt.nist.gov. Disk imaging will be discussed in detail in Chapter 8. Ensure that IT personnel and others on the front line are familiar with your tools and procedures.
• Memory capture and analysis Similar to disk imaging, you should have a number of reliable and tested memory-capture tools available. Keep in mind the different operating systems within your environment, and test solutions for each. Memory analysis will be discussed in detail in Chapters 12 through 14.
• Live response capture and analysis You should create and test live a response toolkit for each OS that is used within your organization. The process of performing a live response and the tools we prefer will be discussed in detail in Chapter 7.
• Indicator creation and search utilities Throughout the process of an investigation, you will need tools to help you create and search for indicators of compromise (IOCs). Chapters 2 and 5 cover this topic.
• Forensic examination suites Forensic examination suites provide a comprehensive set of features in a single package. Typically focused on the analysis of disk images, these suites provide the ability to interpret data formats and allow the investigator to perform searches for relevant information. We do not cover the use of any specific examination suite in this book. Rather, we discuss the fundamentals and the methods you need to effectively perform an examination.
• Log analysis tools During most investigations, the team is faced with examining vast amounts of log files. A common log format is a delimited plain text file. In those cases, we perform analysis with any tool that can operate on plain text. However, sometimes the format is proprietary and we need a tool to read or convert the data. Often, the volume of log data is tremendous—we’ve been involved in a number of cases with multiterabyte archives. If you expect to encounter the same in your organization, it is wise to identify log tools that can deal with that kind of “big data.”
Documentation
In this section, the term documentation refers to policy, procedure, knowledge management, or workflow within the IR team. The areas that we cover in this section are the two most important we believe all IR teams should address. There are many other valuable topics, but your IR team will have to evaluate what makes the most sense to document.
Evidence Handling Evidence is the source of findings for any investigation, and must be handled appropriately. Attention to detail and strict compliance are mandatory with respect to evidence handling. If the integrity of the evidence is called into question, the findings of an investigation may no longer provide value to your organization. To prevent that from happening, we recommend that you implement appropriate evidence-handling policy and procedures. Typically, they will include guidance on evidence collection, documentation, storage, and shipment.
At a minimum, you need to create procedures to enforce integrity, and provide for authentication and verification. Integrity is accomplished through what we call positive control. Positive control means the evidence must always be under direct supervision by authorized personnel, or secured in a controlled environment or container, such as a safe. When shipping evidence, it must be sent via a traceable carrier and packaged so it’s tamper-evident and protected against the elements. Authentication is accomplished through documentation, including an evidence tag and chain of custody. We’ve provided a sample evidence tag in Appendix B. Validation is accomplished through a cryptographic checksum, such as MD5, that is computed at the time of collection and can be validated at any time. Validation proves the evidence has not changed from the time of collection. You can read more about rules of evidence and U.S. Department of Justice evidence collection guidelines at the following websites:
GO GET IT ON THE WEB
Internal Knowledge Repository As your IR team performs investigations and interacts with other departments in your organization, they will accumulate knowledge that should to be documented in a central location. Some information may only be related to a single incident, and can be stored in the ticketing or case management system that the IR team uses. Other information may be related to the organization as a whole, and should be documented in a knowledge repository that the IR team maintains. The knowledge repository should be logically organized and searchable so that the team can effectively locate relevant information.
PREPARING THE INFRASTRUCTURE FOR INCIDENT RESPONSE
Over the years, we have responded to hundreds of incidents, from computer intrusions to fraud investigations. Although the elements of proof for the investigations differ, the source of actionable leads and relevant data remain fairly consistent, as well as the methods used to extract and analyze that data. Regardless of the investigation, the IR team should have the ability to acquire data and search for relevant material across the enterprise as easily as it does on a single machine. It is not surprising then that, good information security practices and change management procedures promote rapid response and ease the remediation process.
Throughout our careers, we’ve noticed a number of areas that organizations frequently have challenges with. They broadly fall into two categories: computing devices (such as servers, desktops, and laptops) and networking. We will take a look at computing devices first, and then we’ll cover network configuration. Within each of these two categories, we will cover the top four areas that we have seen many organizations struggle with. Here is an outline of these areas:
• Computing device configuration
• Asset management
• Performing a survey
• Instrumentation
• Additional steps to improve security
• Network configuration
• Network segmentation and access control
• Documentation
• Instrumentation
• Network services
Computing Device Configuration
Computing devices, such as servers, desktops, and laptops, in your enterprise harbor the majority of evidence relevant to an investigation, and the manner in which these systems are configured can drastically affect the outcome. Without the proper evidence, basic questions about what happened cannot be answered. Therefore, your organization should configure all systems in a manner that facilitates an effective investigation. A common approach that many organizations take is to focus their attention on systems that they perceive as important. However, that approach assumes an attacker will perform actions that can be detected on the critical system. In our experience, it is common for an attacker to use unrelated systems as their base of operations, creating hundreds of artifacts on numerous noncritical systems. An attacker is also likely to use valid credentials to access critical systems in ways that are consistent with normal activity. If those artifacts are not captured and preserved, many questions about the incident will remain unanswered. To help ensure you cover all aspects of system configuration that are applicable in your organization, consider the following two steps:
1. Understand what you have. It’s rather difficult to protect systems you don’t know exist. Your organization should consider implementing a comprehensive asset management system. In addition, performing a survey on what is actually in production, both from a system and an application perspective, can reveal details about the environment that requires additional planning.
2. Improve and augment. After you determine what systems and technology you have to work with, you should ensure they are configured in a way that helps an investigation. Log settings, antivirus and HIPS configuration, investigative tool deployment, and many other enhancements will need to be done. Keep in mind organizational policy and legal issues, because privacy or other laws may affect what you can or cannot do.
We do not cover host hardening and other security posturing topics in detail. Many other resources, such as the Defense Information Systems Agency (DISA) Security Technical Implementation Guides (STIGs) found at iase.disa.mil/stigs, provide in-depth information on those subjects. Our focus is on the areas that have the greatest impact on an investigation. |
Asset Management
When computer security professionals think of important ways to prepare their environment for an incident, asset management is usually not one of them. But imagine this scenario: you discover that an attacker has targeted a department within your organization. The department researches technologies that are critical to a new service that your organization delivers. A natural reaction might be to examine the systems that are part of that department to make sure they are not compromised. Or perhaps you’d like to implement some additional security protocols for that department. Effectively accomplishing either of those goals requires that you know precisely what systems belong to that department and where they are located.
In the context of an investigation, there are several important asset management considerations. Although it is more convenient to have all of this information in a single place, we find that most organizations have different categories of information about a system in different places. The key is to understand how to access the information when you need it. You should evaluate your organization’s ability to provide the following information about a system:
• Date provisioned Imagine a situation where you find evidence of suspicious activity that occurred two months ago on a specific system. You look up the host name in your asset management system and find that it is a server that was replaced last week. Based on that information, you know that the current system will not contain evidence associated with activity two months ago. In this case, the best chance of obtaining evidence is to track down the old server, which the asset management system can also help with.
• Ownership Many organizations outsource services. If a system is not actually owned by your organization, that may affect how you respond. The inventory should clearly indicate who owns the hardware.
• Business unit Knowing what business unit within your organization a system belongs to can help the investigators build context and make better investigative decisions. For example, the fact that a compromised system is a database server may or may not be important. If you also know that the database server is part of a business unit that handles data subject to federal regulations, that fact will change how you react.
• Physical location If you need to obtain a hard drive image, or take some other action that requires physical access to the system, you will need to know where it’s located. We’re not suggesting that the location information is live, such as in the case of laptops, just that the primary location of the system is documented.
• Contact information Coordinating access requests, gaining physical access, and notifying affected stakeholders requires a list of contacts associated with the system. Ideally, there is a primary and a secondary contact listed. For servers, it’s helpful to include the system administrator, the application administrator, and a business point of contact. For end-user systems, include the primary user and their supervisor.
• Role or services It is important for an investigator to know what role a system performs. We suggest you be as detailed as makes sense—simply listing “server” is not very descriptive. What kind of server? Based on the role, you will make different decisions on what to do, who to contact, and how much urgency to place on the matter. For example, it’s more straightforward to perform a forensic image of a hard drive in a laptop than of a 16TB SAN drive attached to a production database server. Knowing that sooner rather than later will help you respond appropriately.
• Network configuration The network configuration tracked should include the host name, IP configuration, and MAC address for each interface. If the IP address is determined via DHCP, normally the IP itself would not be listed. However, if the IP address is statically assigned, having that in the asset management system is useful.
An organization’s standard system build, software inventories, and other documentation will rarely provide the entire picture of the IT infrastructure. During the course of an investigation, we find that it is common to come across software, hardware, or operating systems that the organization did not previously know about. Because we don’t like surprises in the middle of an investigation, we encourage organizations to seek them out ahead of time. We recommend performing a hands-on survey (automated or otherwise) to gather and verify the following information. Be sure to include manufacturer, product, and version information for each item in use in your organization.
• Operating systems (Windows, Mac OS X, Linux, HP-UX)
• Hardware (laptops, desktops, servers, mobile devices)
• Networking technologies (switches, wireless access points, firewalls, IDS, proxies)
• Network diagram
• Security software (AV, HIPS, whitelisting)
• IT management software (patch, configuration, and asset management, performance monitoring)
• Endpoint applications (word processing, graphics, engineering, Internet browsers)
• Business applications (time keeping, document management, payment processing)
Passwords
Mass credential change (for example, password reset) is often a particularly difficult task for many organizations. As part of an investigation, you may discover that the attacker was able to determine the password for one or more accounts. The remediation step for that finding is to change the affected credentials. However, we frequently find that an attacker obtains hundreds, if not thousands, of passwords in the form of password hash dumps from Windows domain controllers. Often, the password hashes obtained include service accounts—which are commonly hard-coded into various back-office systems and applications. There may also be application-specific passwords, such as for a specialized finance system. And finally, some organizations use the same local administrator account on all systems. This adds up to one huge nightmare for the IT department, unless they develop a plan to roll out changes for all users and services. This process is often scheduled with the help of the IT help desk staff, who will bear the load of perhaps thousands of confused users. The importance of the success of this remediation step cannot be overstated. One missed system or administrative credential and all effort put into this process may be lost.
With the availability of rainbow tables, any Windows Lanman hash for a password shorter than 15 characters or NTLM hash for a password shorter than nine characters should be considered compromised. We frequently work with organizations that believe it’s not possible for an attacker to determine their Windows passwords quickly enough to matter—until we dump the password hashes and display the plain-text passwords within five minutes (for NTLM it takes a few hours). Check it out for yourself using the tools linked next. |
GO GET IT ON THE WEB
Password hash dumping tool, fgdump www.foofus.net/~fizzgig/fgdump
Free rainbow tables www.freerainbowtables.com
Rainbow table cracking tool, rcracki_mt sourceforge.net/projects/rcracki
Instrumentation
When considering how to improve system configuration to facilitate an investigation, think about the two initial phases: developing and following leads. What can be logged, captured, or otherwise recorded that might help determine what happened on an affected system? Think about the instrumentation mechanisms you already have in place—software metering, performance monitoring, and AV or host-based firewalls—and how you could improve their configuration. Then take a look into new areas, such as investigative tools. How can you reach out to a system and ask it questions: Does this file exist? Is a certain registry key present?
Event, Error, and Access Logs In nearly every investigation we perform, log files are an invaluable resource. You can help an investigation succeed by ensuring relevant events are logged and that they are retained for an appropriate amount of time. A centralized logging system is also a major contributor to an effective investigation. However, centralized logging also presents an organization with a number of challenges. How do you collect the log data, and where is it stored? How long do you retain the data? Are all systems in the same time zone so events are easily correlated? In this section we will cover a few logging solutions and system configuration options that will help you preserve information that is useful to an investigation.
Your organization may already have a centralized logging solution. If that is the case, great! If your organization does not have a centralized logging solution, you should consider what it would take to put one in place. The options range from free or open source solutions such as Splunk, ELSA, Snare from InterSect Alliance, and NTSyslog, to high-end commercial Security Information and Event Management (SIEM) solutions such as ArcSight and RSA’s enVision. Your organization will have to decide what makes the most sense.
The next area you will have to make a decision about is retention. In general, we recommend that most organizations retain log data for at least a year. In some environments, the volume of events is so high that it is difficult to retain those events for much more than a couple of weeks. In those cases, you should examine the log data to determine what subset of information can be preserved for a longer period. Most breaches are not discovered for weeks, and sometimes even months or years. Also, keep in mind that logging may be regulated by your industry. For example, the PCI Data Security Standards (DSS) v2.0 requires a retention period of one year for all assets that fall within a PCI data processing environment. In other cases, your legal counsel will want to limit logging to a very short amount of time. Ensure that their preference is weighed against potential risk to future investigations.
Finally, you will have to make decisions about what to log. There are two main sources of logging you should think about: operating systems and applications. During most investigations we perform, we find that the organization has poorly configured operating system logging and often has completely overlooked application logging. First, let’s cover operating systems.
Two common operating systems in most environments are Microsoft Windows and a Unix or Unix-like operating system such as Linux. Many default installations of Windows do not enable sufficient auditing to be useful in an investigation. We recommend configuring the following minimum settings in your organization’s baseline system images:
• Increase auditing to include log-on and log-off events, as well as user and group management events.
• When feasible, increase auditing to include process creation and termination.
• Increase local storage for each event log to a minimum of 100MB (ideally 500MB).
• Forward all events to a centralized logging system.
GO GET IT ON THE WEB
Snare for Windows www.intersectalliance.com/projects/BackLogNT
Unix-based systems tend to log more details relevant to an investigation, but sometimes suffer from a limited retention period. We recommend checking the following settings under Unix:
• When feasible, enable process accounting
• Increase local storage
• Forward all events to a centralized logging system
In terms of applications, some of the most common logs useful to an investigation are web server, proxy, and firewall logs. But many others are important, such as database, e-mail, DNS (queries and responses), DHCP lease assignments (so you can track down a system based on IP address only), firewall, antivirus, IPS/IDS, and custom application logs. You should examine each business process or service within your organization and understand where logging is retained and if you can centralize the storage. In some cases, you may find that logging is not turned on. For example, we find that DNS query logging is commonly overlooked.
Antivirus and Host Intrusion Prevention Systems There are many antivirus (AV) and host intrusion prevention system (HIPS) solutions on the market. Because they change over time, it doesn’t make much sense for us to talk about specific solutions here. What is more important from the perspective of incident response is how they are configured and what information they can provide that will benefit the investigation. Let’s walk through a couple scenarios to illustrate what we mean.
Nearly every organization has an AV or HIPS solution deployed. We have found everything from free products to expensive solutions from multiple vendors. We won’t get into the effectiveness of such solutions in actually preventing an infection, but what is important is the control you have over what happens when something is detected. For example, if the solution does not log events to a central server, you have no way to review detections across the entire organization. Also, the solution in your organization may be set to delete malware upon detection. Although that may seem like a good practice, it is also destroying evidence. Performing a quarantine to a central location gives you the opportunity to analyze the malware, generate indicators of compromise, and perhaps determine IP addresses it was configured to communicate with.
Another concern is sending malware to the AV vendor. Some solutions can be configured to automatically transmit suspicious binaries to the vendor for analysis. Once that happens, you potentially lose some control of the situation. Targeted malware may contain information that is unique to your environment—such as proxy settings or even credentials. The malware may also contain information that reveals the nature of the attack. And finally, the vendor may release a signature update that cleans malware before you are ready—that may sound odd, but we will cover that topic more in Chapter 15. Be wary of submitting malware to analysis sites. When you submit malware, most of the sites have agreements with major AV vendors and immediately receive the samples that you provide.
The bottom line is, the AV or HIPS solutions in place should be configured to help your investigation, not hinder it. They should provide central storage and query capabilities for events, captured files, or other related content. And they should be configurable so that you can control the actions taken when something is detected.
Investigative Tools The ability to reach out to systems within your environment and ask them questions related to leads you are following is critical to an investigation. When you find something unique in an investigation, such as malware, attacker tools, or anything else, your next question should be, “What other systems in my environment have this artifact?” An accurate answer to that question will help you properly scope the incident.
Ideally, your organization includes investigative tools as part of the standard build for every system: servers, laptops, and desktops. There are a number of solutions on the market, including AccessData Enterprise, Guidance Software EnCase Enterprise, and Mandiant Intelligent Response. You could also create a homegrown solution using a number of standard system administration and programming tools such as shell scripts and Windows Management Instrumentation (WMI). Your organization will need to research the market and determine what the most appropriate tool is for your situation.
This section lists a number of steps you can take that will improve the overall security posture of individual systems. Chances are, these steps will also have a positive effect on investigations as well. But because they are not directly related to preparing for an incident, we don’t cover them in detail:
• Establish a patching solution for both operating systems and applications.
• Consider the use of two-factor authentication, and enforce good password complexity.
• Remove local administrative access from users.
• Ensure systems have firewall and AV solutions deployed and configured appropriately.
• Decommission end-of-life systems.
• Establish a configuration management system.
• Consider application whitelisting.
• Conform with DISA STIGs: iase.disa.mil/stigs.
• Follow NSA IA mitigation guidance: www.nsa.gov/ia/mitigation_guidance/index.shtml.
Network Configuration
Now that we’ve covered the first area, computing devices, let’s take a look at the second area—network configuration. There are numerous guides and publications on the process of designing a secure networking environment. We will not address all of the topics in this relatively short section; however, some common practices can greatly enhance an IR team’s ability to perform investigations. To recap, the four topics that we will discuss in this section are
• Network segmentation and controls
• Documentation
• Instrumentation
• Network services
To help illustrate the methods described in this section, we will reference the following simplified network diagram of a fictitious organization. This diagram incorporates designs that may be difficult to implement in an existing network. Nonetheless, a number of our clients have relied-upon designs such as these for security and incident response.
Very few organizations believe they have the luxury of “starting over” and redesigning their networks. Even when small companies start off with a well-designed plan, growth, mergers, and acquisitions add complexity and require careful planning. Most organizations we have worked with have found that in the aftermath of an incident, anything is possible and management is willing to support sweeping changes to an infrastructure. As a bit of a silver lining to a computer intrusion, most end up in a better situation than before the incident occurred. Those that do not are typically reinfected within weeks.
In Figure 3-1, we have an example of a good, segmented network. Our simple fictitious company has four internal suborganizations; Finance, Engineering, Sales, and IT Support. Each has access to its own set of resources (servers) and to corporate-wide resources in the “internal services” zone. The lack of an apparent connection between the suborganizations and the firewalls may appear a bit odd. We’ll discuss that in the next section.
GO GET IT ON THE WEB
NIST Computer Security Resource Center csrc.nist.gov
ISO 27001 Security iso27001security.com
Network Segmentation and Access Control
A common information security best practice is the segmentation of a network based on the information processed by the segment or the role of the systems or users therein. Controlling the traffic between network segments allows an organization to monitor and protect significant resources and communications. During an investigation, these controls can greatly assist in identification and containment of compromised systems.
In the network diagram shown in Figure 3-1, we have segmented the suborganizations into their own zones and used filtering to permit only traffic that is necessary for business operations. For example, systems in the Finance zone have a set of servers that run an ERP accounting application. The information processed by this collection of servers requires a high degree of confidentiality because its loss can affect the financial health of the company as well as expose clients and suppliers. Tight controls would dictate that both local (in-zone) traffic and remote (other suborganizations) be minimized to essential traffic only, and all access would be properly authenticated (in the previous section we noted the importance of two-factor authentication for privileged accounts or user-level access to sensitive data). Likewise, Engineering has its own server resources that must be isolated from the other suborganizations, particularly Sales.
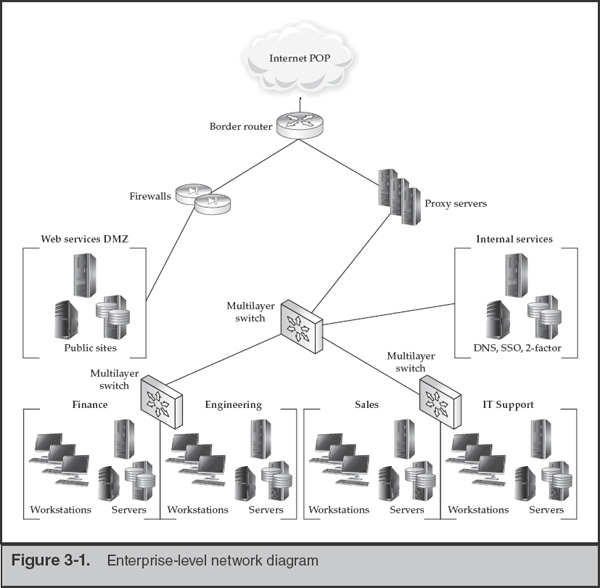
Many essential access controls are difficult to represent on network diagrams. At this level, three controls aren’t represented but are considered essential:
• Traffic filtering at the suborganization level Ingress filtering and its oft-ignored counterpart, egress filtering, is absolutely essential to impede an intruder’s access across the enterprise. Consider what resources are actually required, lock the border down, and utilize change control and periodic reviews to ensure consistency over time.
• Web, chat, and file transfer proxies Traffic to external resources should pass through proxies that are capable of monitoring and filtering. This serves as an important line of defense for traffic permitted by policy. As a bonus, most proxies double as caching servers, potentially lowering the bandwidth requirements of a site over time. If the proxy is able to log and preserve communications, your compliance and legal folks will reap benefits from this control as well.
• Two-factor authentication for connections crossing significant borders Most organizations know that all VPN traffic originating from the Internet should be controlled with two-factor credentials. Unfortunately, few apply these restrictions to internal resources. Servers, administrative workstations, and “jump boxes” should also require two-factor authentication. We’ll discuss the concept of jump boxes in the next section.
Be wary of overly permissive rule sets for Microsoft RPC (remote procedure call) protocols. Many organizations will create an alias on their internal firewalls that includes standard Windows ports. In order to “just make things work,” ports 135, 137, 138, 139, 445, and a handful of others are permitted and applied as a general rule, pushing security to the endpoints. Recall that once you allow access for simple file sharing, you get remote administration (psexec) over those same RPC ports as an unintended bonus. Thanks to poor RPC design, granting access to file share is not limited to a simple mount point, and attackers can spread through an otherwise segmented network unimpeded. |
In the diagram shown in Figure 3-2, we have expanded on the Finance suborganization, showing a simple ERP (enterprise resources planning) configuration within a protected enclave inside of the Finance zone. The enclave (Finance Servers) is configured to allow the minimum traffic necessary for the services provided. Similarly, the traffic exiting the enclave and the Finance group is controlled, although some detail has been omitted for clarity (for example, authentication traffic from the enclave to a corporate two-factor server). Note that the vertical line extending down as an extension of the multilayer switch is representative of a clear division between the two networks. This can be accomplished using VLANs and filtering in a single chassis or through multiple switches.
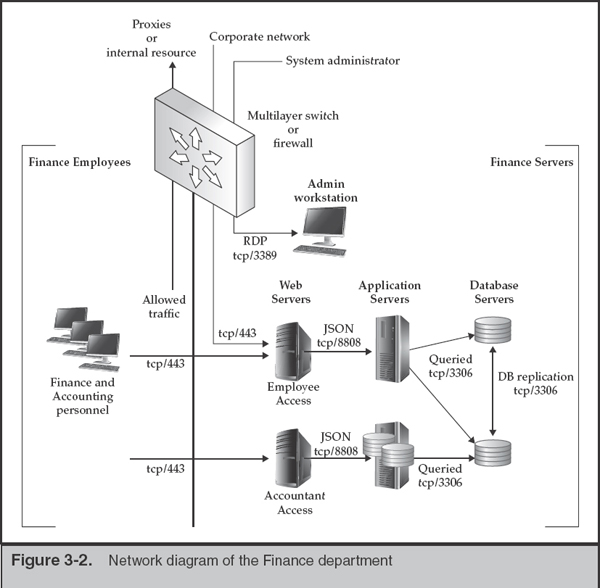
Figure 3-2 shows three network-based controls that help limit exposure and promote data collection in the event of a compromise: network segregation, limited access to administrative functions, and centralized opportunities for monitoring.
Access Control As discussed with the higher-level diagram, traffic between the zones is carefully controlled. Personnel working in the Finance group have limited access to external networks. The “allowed traffic” may include authentication traffic to LDAP or Active Directory servers, IMAPS or similar traffic to corporate mail servers, and web traffic to the corporate proxies and other internal sites. They also have limited access to the servers within their department. In this example, all of their business needs can be served via HTTPS access to the ERP accounting system, and the filtering allows only that. Inbound traffic (not shown) would be limited to access from system management servers, run by IT.
Inside the Finance server zone, traffic is similarly restricted. Egress rules resemble those of the Finance user zone, with explicit destinations defined. Note, however, that web traffic outbound is never allowed from servers, unless specific applications require it. Ingress rules allow general employee access to web servers that are used to enter time and accounting information. Access by system administrators is restricted in a different manner, however. In this example, an administrative workstation (requiring two-factor authentication) is the only connection that may be made into the environment for system management purposes. If a system administrator needs to perform maintenance on a database server, they must first log in to an interactive desktop session on the admin workstation (or “jump-box”) and connect to the Finance database server from there. This greatly simplifies filter creation and auditing because a minimum number of systems and ports are allowed as the source and destination of inbound connections. Although we never place significant trust in the endpoints, host-based firewalls are also employed as part of a “defense-in-depth” approach.
Finally, the IR team may readily monitor all traffic that is controlled by the single filtering entity assigned to the Finance group. Most of the time, sensors are first placed on the edge of the corporate network, gathering traffic for analysis and alerting the team when known signatures are matched. When the team is comfortable enough with the monitoring solution, expanding the scope to include inter-departmental traffic can reveal lateral movement across your enterprise.
When designing or analyzing network segmentation and filtering, always consider the implications of a system or credential compromise. Unfortunately, when humans are involved, you can assume that some control will fail. A great exercise to undertake when planning is to perform fault tree analysis for several significant, undesired events. Minimize the number of OR conditions at the top levels and focus prevention efforts on the remaining hazards. This type of analysis also applies to the next section on instrumentation because the hazards are often able to be monitored. |
Limiting Workstation Communication Another control not represented in the figures is endpoint traffic filtering. Regardless of what your operating system vendor may prefer, do not place all trust in the security of the endpoints. Host-based firewalls are trivial to modify once malware elevates to system-level privileges. Furthermore, the RPC elements of Microsoft’s networking model prevents limiting service-level access with edge and switching devices. If your infrastructure supports it, disallow traffic between ports on your managed switches unless the port is connected to a shared resource or another switch. The ease by which one can set up this type of filtering depends entirely on the technology in place within the organization.
Eye Witness Report
During the remediation phase of an IR, one of our clients was able to limit all workstation traffic to specific servers and gateways. Users’ workstations were not permitted to communicate directly to other users’ workstations. Over the course of several months, a few users were successfully phished. Although the individuals’ systems were independently compromised and credentials stolen, the infection did not spread. Between the actions taken to isolate workstations and protect domain credentials, the incidents were prevented from becoming an enterprise-wide problem.
Several of our clients have implemented an interesting way to control and monitor how traffic exits their networks. This is reflected in our top-level network diagram. With the exception of proxy servers, firewalls, and border routers, no switching device is configured with a default route entry. All workstations and servers that require access to external resources are directed toward proxy servers that enforce authentication. Traffic to external IP addresses can be sent to a routing blackhole or to a system for analysis. Some organizations use this as an effective early warning system to identify simple malware.
Note that although a fair amount of malware is now “proxy aware” and may authenticate properly, forcing traffic through proxy servers can give the organization significant insight into the traffic exiting the network. Logs from proxy servers can be used by the IR team to determine whether requests matching specific criteria are occurring as well as the volume of traffic generated by those requests. By monitoring permitted and unexpected connection attempts, you are collecting direct and indirect evidence of an incident.
Oftentimes, we are asked the question, “Should we set up a honeypot to distract the attackers?” Honeypots generally serve two purposes. First, it is thought that they can consume an attacker’s time and resources by presenting systems and data that is of little importance to the organization. This is generally ineffective. If the honeypot presents data that is more easily accessible than “significant data,” the attackers will likely be distracted for an amount of time equal to that of a coffee break for your IR team. If you set up an elaborate honeypot that presents a challenge to an attacker, your time is far better spent defending your real assets. Second, honeypots are used as a research tool to learn what methods are being used by active or potential attackers. From an investigative perspective, and during an active incident, your entire network serves this purpose.
If you are not in an active investigation, your regular penetration tests yield no significant results, your patch management is up to date, your IR tabletop exercises are complete, all of your logs have been reviewed, and your IR team is bored to tears, then by all means, play with honeypots. |
Documentation
Through growth, mergers, and acquisitions, maintaining accurate and current network diagrams is a tough task to accomplish. This is a responsibility of the IT and networking folks; however, the IR team uses these documents continually during an investigation to determine risk, scope, and remediation measures.
The IR team should have a series of diagrams at their disposal that represents the environment at various levels. Typically the high-level network design, where gateways, MPLS connections, VPN tunnels, and border control devices reside, should not change often. These diagrams are usually the most useful during the initial phases of an investigation. If not already deployed, the accurate placement of network monitoring devices relies on this information. The successively detailed diagrams allow an IR team to determine where potentially compromised systems reside and the risk they pose to the enterprise. At a point, the usefulness of diagrams gives way to a knowledgeable system administrator.
Also part of a good documentation plan is the storage of various devices’ configuration. The IR team needs to have access to network configurations, such as routers, firewalls, and switches. That information can be useful if the IR team suspects tampering. With an archive of configuration files and associated change control documentation, any suspicious changes or suspected tampering can be easily validated.
The bottom line is that maintaining documentation forces the larger organization to be aware of its assets and configuration. Coupled with change control, documentation will lessen the probability that the organization will be surprised during an active investigation.
Instrumentation
In the previous section, we discussed instrumentation applied to individual or groups of systems. We ask the same questions here: what can be logged, captured, or otherwise recorded that might help determine what happened on the network? The answer varies widely for each organization, depending on the technologies deployed. Recall that we are not only considering what should be captured for typical IT security purposes, but also what can be logged on a tactical basis during an investigation. The most common sources of logging and monitoring are
• Firewalls Events should be logged to a location that promotes searching and retention. During an investigation, you may elect to use firewalls to notify you when traffic matches selected network IOCs.
• Intrusion detection systems Far better suited for examining traffic for indicators of compromise, your IR team should have access to review alerts and submit additional indicators. Outsourced IDS and traffic monitoring services work well, if they can react quickly and give you sufficient actionable information.
• Full-content capture systems Periodically you may need to capture an entire session for analysis. If your network was designed with this in mind, performing a full-content capture of suspicious traffic may be as simple as turning on a SPAN or port-mirroring function on a switch. In some situations, simply having a platform ready to deploy with a hardware network tap is sufficient.
Eye Witness Report
The number of IT and IS managers we have worked with that learn of new servers, networks, and even Internet gateways during an active investigation is staggering. We have witnessed instances where the attackers were more familiar with the routing capabilities of an enterprise than the staff. The attackers learned of active network monitoring at a U.S. gateway and inserted static routes to an unmonitored gateway in Europe to avoid detection. The organization did not know that their incomplete filtering rules allowed that route path until the static route entries were discovered on a few compromised workstations.
• Netflow emitters At common gateways and internal switches, collect netflow statistical data on a per-host or per-port basis. Analysis of the volume and frequency of data flows can lead one to compromised systems and give the team a sense for how stolen data may be moving through the environment.
• Proxy servers If all outbound traffic is forced through authenticated proxies, an IR team can use the proxy logs to examine the content of communications, detect the movement of data, identify communication with known-bad external systems, and trace the source of requests across address translation devices. You can more readily turn an FBI notification such as “a system in your network pushed your product’s source code to a known drop site at 16:07 last Sunday” into an actionable lead when you have internal addresses and authentication records to refer to.
Network Services
When designing or modifying a network to be IR friendly, you have a few services to consider. In addition to the proxy servers noted in the prior sections, configure your DNS systems and DHCP servers to permit extensive logging. In subnets where workstations receive leases for addresses, ensure that the DHCP servers retain (or transfer) assignment logs for a significant amount of time (one year at a minimum). Recall that if you are retaining other logs for a long period of time, the source IP addresses captured therein may be useless if you cannot locate which system was assigned that address during the period of suspicious activity.
Implementing a DNS Blackhole The DNS systems in your environment may be one of most useful tools you can use to track and impede an attacker’s attempts to use backdoor malware. A DNS blackhole occurs when you redirect an entire subdomain to a nonexistent or managed IP address. For example, let’s assume you believe that the domain “pwn.ie” is malicious. You have found malware configured to beacon out to that site and wish to prevent further successful resolution of that domain name. You will need to generate a zone file for the domain and have its entries point to an invalid address. Often, 127.0.0.1 is used in the primary A record. For example, a zone file for “blackhole.zone” would be created with the following contents:
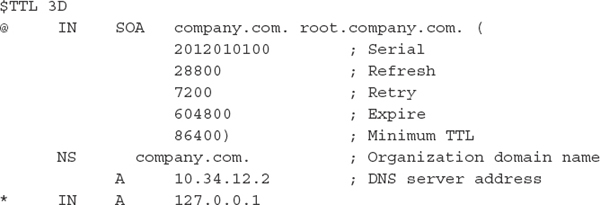
In the resolver’s configuration, all queries for the malicious domain would be assigned to that zone:
Any requests for subdomains within pwn.ie would get a reply for 127.0.0.1. A better option would be to redirect those requests to a system dedicated to capturing the malicious traffic. Set up a Unix system with a logging web server and packet capture software. The malicious software may attempt to communicate to your false drop site, alerting you to the type of information being targeted.
GO GET IT ON THE WEB
DNS blackhole on BIND and FreeBSD www.pintumbler.org/Code/dnsbl
DNS blackhole on Microsoft DNS www.sans.org/windows-security/2010/08/31/windowsdns-server-blackhole-blacklist
SO WHAT?
As old saying goes, “An ounce of prevention is worth a pound of cure.” In this chapter, we presented information that will help you prepare your organization, your IR team, and your infrastructure to better deal with an incident. With an organization that understands its assets and risks, and has a well-equipped response team and a properly designed network architecture, responding to an incident will be much less painful. However, don’t stop there—once you’ve prepared, we recommend you perform “dry runs” of your processes and procedures. Because waiting for an incident to happen to “see how things go” is not likely to end well. In the next chapter, we will look at the critical moments between event detection and taking action—and what you can do to help avoid costly missteps.
QUESTIONS
1. Explain how a simple network service such as DHCP might become critical in an investigation.
2. Discuss some of the challenges related to outsourced IT services as they pertain to conducting an investigation. How can they be dealt with?
3. Why is asset management a critical aspect of preparing for an incident?
4. What forensic tools are acceptable in court? Explain your answer.
5. Why is centralized logging important?
6. What is a DNS blackhole? When would you use one? Write a BIND zone file that will accept all queries for a malicious domain and answer with an RFC1918 address.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.