
Chapter 22
Java and XML
WHAT YOU WILL LEARN IN THIS CHAPTER:
- What a well-formed XML document is
- What constitutes a valid XML document
- What the components in an XML document are and how they are used
- What a DTD is and how it is defined
- What namespaces are and why you use them
- What the SAX and DOM APIs are and how they differ
- How you read documents using SAX
The Java Development Kit (JDK) includes capabilities for processing Extensible Markup Language (XML) documents. The classes that support XML processing are collectively referred to as JAXP, the Java API for XML Processing. In this chapter and the next, you explore not only how you can read XML documents, but also how you can create and modify them. This chapter provides a brief outline of XML and some related topics, plus a practical introduction to reading XML documents from within your Java programs using one of the two mechanisms you have available for this. In the next chapter I discuss how you can modify XML documents and how you create new XML documents programmatically. Inevitably, I can only skim the surface in a lot of areas because XML itself is a huge topic. However, you should find enough in this chapter and the next to give you a good feel for what XML is about and how you can handle XML documents in Java.
XML, or the Extensible Markup Language, is a system- and hardware-independent language for defining data and its structure within an XML document. An XML document is a Unicode text file that contains data together with markup that defines the structure of the data. Because an XML document is a text file, you can create XML using any plain text editor, although an editor designed for creating and editing XML obviously makes things easier. The precise definition of XML is in the hands of the World Wide Web Consortium (W3C), and if you want to consult the current XML specifications, you can find them at www.w3.org/XML.
The term markup derives from a time when the paper draft of a document to be printed was marked up by hand to indicate to the typesetter how the printed form of the document should look. Indeed, the ancestry of XML can be traced back to a system that was originally developed by IBM in the 1960s to automate and standardize markup for system reference manuals for IBM hardware and software products. XML markup looks similar to HTML in that it consists of tags and attributes added to the text in a file. However, the superficial appearance is where the similarity between XML and HTML ends. XML and HTML are profoundly different in purpose and capability.
The Purpose of XML
Although an XML document can be created, read, and understood by a person, XML is primarily for communicating data from one computer to another. XML documents are therefore more typically generated and processed by computer programs. An XML document defines the structure of the data it contains so a program that receives it can properly interpret it. Thus XML is a tool for transferring information and its structure between computer programs. HTML, on the other hand, is solely for describing how data should look when it is displayed or printed. The structuring information that appears in an HTML document relates to the presentation of the data as a visible image. The purpose of HTML is data presentation.
HTML provides you with a set of tags that is essentially fixed and geared to the presentation of data. XML is a language in which you can define new sets of tags and attributes to suit different kinds of data — indeed, to suit any kind of data including your particular data. Because XML is extensible, it is often described as a meta-language — a language for defining new languages, in other words. The first step in using XML to exchange data is to define the language that you intend to use for that purpose in XML.
Of course, if I invent a set of XML markup to describe data of a particular kind, you need to know the rules for creating XML documents of this type if you want to create, receive, or modify them. As you later see, the definition of the markup that has been used within an XML document can be included as part of the document. It also can be provided as a separate entity, in a file identified by a URI, for example, that can be referenced within any document of that type. The use of XML has already been standardized for very diverse types of data. XML languages exist for describing the structures of chemical compounds and musical scores, as well as plain old text such as in this book.
Processing XML in Java
The JAXP provides you with the means for reading, creating, and modifying XML documents from within your Java programs. To understand and use this application program interface (API) you need to be reasonably familiar with two basic topics:
- What an XML document is for and what it consists of
- What a DTD is and how it relates to an XML document
You also need to be aware of what an XML namespace is, if only because JAXP has methods relating to handling these. You can find more information on JAXP at http://jaxp.java.net.
In case you are new to XML, I introduce the basic characteristics of XML and DTDs before explaining how you apply some of the classes and methods provided by JAXP to process XML documents. I also briefly explore what XML namespaces are for. If you are already comfortable with these topics you can skip most of this chapter and pick up where I start talking about SAX. Let’s start by looking into the general organization of an XML document.
An XML document basically consists of two parts, a prolog and a document body:
- The prolog: Provides information necessary for the interpretation of the contents of the document body. It contains two optional components, and because you can omit both, the prolog itself is optional. The two components of the prolog, in the sequence in which they must appear, are as follows:
- An XML declaration that defines the version of XML that applies to the document and may also specify the particular Unicode character encoding used in the document and whether the document is standalone or not. Either the character encoding or the standalone specification can be omitted from the XML declaration, but if they do appear, they must be in the given sequence.
- A document type declaration specifying an external Document Type Definition (DTD) that identifies markup declarations for the elements used in the body of the document, or explicit markup declarations, or both.
- The document body: Contains the data. It comprises one or more elements where each element is defined by a begin tag and an end tag. The elements in the document body define the structure of the data. There is always a single root element that contains all the other elements. All of the data within the document is contained within the elements in the document body.
Processing instructions (PI) for the document may also appear at the end of the prolog and at the end of the document body. Processing instructions are instructions intended for an application that processes the document in some way. You can include comments that provide explanations or other information for human readers of the XML document as part of the prolog and as part of the document body.
Well-Formed XML Documents
When an XML document is said to be well-formed, it just means that it conforms to the rules for writing XML as defined by the XML specification. Essentially, an XML document is well-formed if its prolog and body are consistent with the rules for creating these. In a well-formed document there must be only one root element, and all elements must be properly nested. I summarize more specifically what is required to make a document well-formed a little later in this chapter, after you have looked into the rules for writing XML.
An XML processor is a software module that is used by an application to read an XML document and gain access to the data and its structure. An XML processor also determines whether an XML document is well-formed or not. Processing instructions are passed through to an application without any checking or analysis by the XML processor. The XML specification describes how an XML processor should behave when reading XML documents, including what information should be made available to an application for various types of document content.
Here’s an example of a well-formed XML document:
<proverb>Too many cooks spoil the broth.</proverb>
The document just consists of a root element that defines a proverb. There is no prolog, and formally, you don’t have to supply one, but it would be much better if the document did include at least the XML version that is applicable, like this:
<?xml version="1.0"?> <proverb>Too many cooks spoil the broth.</proverb>
The first line is the prolog, and it consists of just an XML declaration, which specifies that the document is consistent with XML version 1.0. The XML declaration must start with <?xml with no spaces within this five character sequence. You could also include an encoding declaration following the version specification in the prolog that specifies the Unicode encoding used in the document. For example:
<?xml version="1.0" encoding="UTF-8"?> <proverb>Too many cooks spoil the broth.</proverb>
The first line states that as well as being XML version 1.0, the document uses the "UTF-8" Unicode encoding. If you omit the encoding specification, "UTF-8" or "UTF-16" is assumed, and because “UTF-8" includes ASCII as a subset, you don’t need to specify an encoding if all you are using is ASCII text. The version and the character encoding specifications must appear in the order shown. If you reverse them you have broken the rules, so the document is no longer well-formed.
If you want to specify that the document is not dependent on any external definitions of markup, you can add a standalone specification to the prolog like this:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <proverb>Too many cooks spoil the broth.</proverb>
Specifying the value for standalone as "yes" indicates to an XML processor that the document is self-contained; there is no external definition of the markup, such as a DTD. A value of "no" indicates that the document is dependent on an external definition of the markup used, possibly in an external DTD.
Valid XML Documents
A valid XML document is a well-formed document that has an associated DTD (you learn more about creating DTDs later in this chapter). In a valid document the DTD must be consistent with the rules for creating a DTD and the document body must be consistent with the DTD. A DTD essentially defines a markup language for a given type of document and is identified in the DOCTYPE declaration in the document prolog. It specifies how all the elements that may be used in the document can be structured, and the elements in the body of the document must be consistent with it.
The previous example is well-formed, but not valid, because it does not have an associated DTD that defines the <proverb> element. Note that there is nothing wrong with an XML document that is not valid. It may not be ideal, but it is a perfectly legal XML document. Valid in this context is a technical term that means only that a document has a DTD.
An XML processor may be validating or non-validating. A validating XML processor checks that an XML document has a DTD and that its contents are correctly specified. It also verifies that the document is consistent with the rules expressed in the DTD and reports any errors that it finds. A non-validating XML processor does not check that the document is consistent with the DTD. As you later see, you can usually choose whether the XML processor that you use to read a document is validating or non-validating simply by switching the validating feature on or off.
Here’s a variation on the example from the previous section with a document type declaration added:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <!DOCTYPE proverb SYSTEM "proverb.dtd"> <proverb>Too many cooks spoil the broth.</proverb>
A document type declaration always starts with <!DOCTYPE so it is easily recognized. The name that appears in the DOCTYPE declaration, in this case proverb, must always match that of the root element for the document. I have specified the value for standalone as "no", but it would still be correct if I left it out because the default value for standalone is “no" if there are external markup declarations in the document. The DOCTYPE declaration indicates that the markup used in this document can be found in the DTD at the URI proverb.dtd. You read a lot more about the DOCTYPE declaration later in this chapter.
Having an external DTD for documents of a given type does not eliminate all the problems that may arise when exchanging data. Obviously, confusion may arise when several people independently create DTDs for the same type of document. My DTD for documents containing sketches created by Sketcher is unlikely to be the same as yours. Other people with sketching applications may be inventing their versions of a DTD for representing a sketch, so the potential for conflicting definitions for markup is considerable. To obviate the difficulties that this sort of thing would cause, standard markup languages are being developed in XML that can be used universally for documents of common types. For example, the Mathematical Markup Language (MathML) is a language defined in XML for mathematical documents, and the Synchronized Multimedia Integration Language (SMIL) is a language for creating documents that contain multimedia presentations. There is also the Scalable Vector Graphics (SVG) language for representing 2D graphics, such as design drawings or even sketches created by Sketcher.
Let’s understand a bit more about what XML markup consists of.
Elements in an XML Document
XML markup divides the contents of a document into elements by enclosing segments of the data between tags. As I said, there is always one root element that contains all the other elements in a document. In the earlier example, the following is an element:
<proverb> Too many cooks spoil the broth.</proverb>
In this case, this is the only element and is therefore the root element. A start tag, <proverb>, indicates the beginning of an element, and an end tag, </proverb>, marks its end. The name of the element, proverb in this case, always appears in both the start and end tags. The text between the start and end tags for an element is referred to as element content and in general may consist of just data, which is referred to as character data; other elements, which is described as markup; or a combination of character data and markup; or it may be empty. An element that contains no data and no markup is referred to as an empty element.
When an element contains plain text, the content is described as parsed character data (PCDATA). This means that the XML processor parses it — it analyzes it, in other words — to see if it can be broken down further. PCDATA allows for a mixture of ordinary data and other elements, referred to as mixed content, so a parser looks for the characters that delimit the start and end of markup tags. Consequently, ordinary text must not contain characters that might cause it to be recognized as a tag. You can’t include < or & characters explicitly as part of the text within an element, for example. It could be a little inconvenient to completely prohibit such characters within ordinary text, so you can include them when you need to by using predefined entities. XML recognizes the predefined entities in Table 22-1 that represent characters that are otherwise recognized as part of markup:
TABLE 22-1: XML Predefined Entities
| CHARACTER | PREDEFINED ENTITY |
| & | & |
| ' | ' |
| " | " |
| < | < |
| > | > |
Here’s an element that makes use of a predefined entity:
<text> This is parsed character data within a <text> element.</text>
The content of this element is the following string:
This is parsed character data within a <text> element.
Here’s an example of an XML document containing several elements:
<?xml version="1.0"?> <address> <buildingnumber>29</buildingnumber> <street>South LaSalle Street</street> <city>Chicago</city> <state>Illinois</state> <zip>60603</zip> </address>
This document evidently defines an address. Each tag pair identifies and categorizes the information between the tags. The data between <address> and </address> is an address, which is a composite of five further elements that each contain character data that forms part of the address. You can easily identify what each of the components of the address is from the tags that enclose each subunit of the data.
Rules for Tags
The tags that delimit an element have a precise form. Each element start tag must begin with < and end with >, and each element end tag must start with </ and end with >. The tag name — also known as the element type name — identifies the element and differentiates it from other elements. Note that the element name must immediately follow the opening < in the case of a start tag and the </ in the case of an end tag. If you insert a space here it is incorrect and is flagged as an error by an XML processor.
Because the <address> element contains all of the other elements that appear in the document, this is the root element. When one element encloses another, it must always do so completely if the document is to be well-formed. Unlike HTML, where a somewhat cavalier use of the language is usually tolerated, XML elements must never overlap. For example, you can’t have
<address><zip>60603</address></zip>
An element that is enclosed by another element is referred to as the child of the enclosing element, and the enclosing element is referred to as the parent of the child element. In the earlier example of a document that defined an address, the <address> element is the parent of the other four because it directly encloses each of them, and the enclosed elements are child elements of the <address> element. In a well-formed document, each start tag must always be matched by a corresponding end tag, and vice versa. If this isn’t the case, the document is not well-formed.
Don’t forget that there must be only one root element that encloses all the other elements in a document. This implies that you cannot have an element of the same type as the root element as a child of any element in the document.
Empty Elements
You already know that an element can contain nothing at all, so just a start tag immediately followed by an end tag is an empty element. For example:
<commercial></commercial>
You have an alternative way to represent empty elements. Instead of writing a start and an end tag with nothing between them, you can write an empty element as a single tag with a forward slash immediately following the tag name:
<commercial/>
This is equivalent to a start tag followed by an end tag. There must be no spaces between the opening < and the element name, or between the / and the > marking the end of the tag.
You may be thinking at this point that an empty element is of rather limited use, whichever way you write it. Although by definition an empty element has no content, it can and often does contain additional information that is provided within attributes that appear within the tag. You see how you add attributes to an element a little later in this chapter. An empty element can be used as a marker or flag to indicate something about the data within its parent. For example, you might use an empty element as part of the content for an <address> element to indicate that the address corresponds to a commercial property. Absence of the <commercial/> element indicates a private residence.
Document Comments
When you create an XML document using an editor, it is often useful to add explanatory text to the document. You can include comments in an XML document like this:
<!-- Prepared on 14th January 2011 -->
Comments can go just about anywhere in the prolog or the document body, but not inside a start tag or an end tag, or within an empty element tag. You can spread a comment over several lines if you wish, like this:
<!-- Eeyore, who is a friend of mine, has lost his tail. -->
For compatibility with SGML, from which XML is derived, the text within a comment should not contain a sequence of two or more hyphens, and it must not end with a hyphen. A comment that ends with ---> is not well-formed and is rejected by an XML processor. Although an XML processor of necessity scans comments to distinguish them from markup and document data, they are not part of the character data within a document. XML processors need not make comments available to an application, although some may do so.
Element Names
If you’re going to be creating elements then you’re going to have to give them names, and XML is very generous in the names you’re allowed to use. For example, there aren’t any reserved words to avoid in XML, as there are in most programming languages, so you do have a lot of flexibility in this regard. However, there are certain rules that you must follow. The names you choose for elements must begin with either a letter or an underscore and can include digits, periods, and hyphens. Here are some examples of valid element names:
net_price Gross-Weight _sample clause_3.2 pastParticiple
In theory you can use colons within a name but because colons have a special purpose in the context of names, you should not do so. XML documents use the Unicode character set, so any of the national language alphabets defined within that set may be used for names. HTML users need to remember that tag names in XML are case-sensitive, so <Address> is not the same as <address>.
Note also that names starting with uppercase or lowercase x followed by m followed by l are reserved, so you must not define names that begin xml or XmL or any of the other six possible sequences.
Defining General Entities
There is a frequent requirement to repeat a given block of parsed character data in the body of a document. An obvious example is some kind of copyright notice that you may want to insert in various places. You can define a named block of parsed text like this:
<!ENTITY copyright "© 2011 Ivor Horton">
This is an example of declaration of a general entity. You can put declarations of general entities within a DOCTYPE declaration in the document prolog or within an external DTD. I describe how a little later in this chapter. The block of text that appears between the double quotes is identified by the name copyright. You could equally well use single quotes as delimiters for the string. Wherever you want to insert this text in the document, you just need to insert the name delimited by an ampersand at the beginning and a semicolon at the end, thus:
©right;
This is called an entity reference. This is exactly the same notation as the predefined entities representing markup characters that you saw earlier. It causes the equivalent text to be inserted at this point when the document is parsed. A general entity is parsed text, so you need to take care that the document is still well-formed and valid after the substitution has been made.
An entity declaration can include entity references. For example, I could declare the copyright entity like this:
<!ENTITY copyright "© 2011 Ivor Horton &documentDate;">
The text contains a reference to a documentDate entity. Entity references may appear in a document only after their corresponding entity declarations, so the declaration for the documentDate entity must precede the declaration for the copyright entity:
<!ENTITY documentDate "24th January 2011"> <!ENTITY copyright "© 2011 Ivor Horton &documentDate;">
Entity declarations can contain nested entity references to any depth, so the declaration for the documentDate entity could contain other entity references. Substitutions for entity references are made recursively by the XML processor until all references have been resolved. An entity declaration must not directly or indirectly contain a reference to itself though.
You can also use general entities that are defined externally. You use the SYSTEM keyword followed by the URL for where the text is stored in place of the text in the ENTITY declaration. For example:
<!ENTITY usefulstuff SYSTEM "http://www.some-server.com/inserts/stuff.txt">
The reference &usefulstuff; represents the contents of the file stuff.txt.
CDATA Sections
It is possible to embed unparsed character data (CDATA) anywhere in a document where character data can occur. You do this by placing the unparsed character data in a CDATA section, which begins with <![CDATA[ and ends with ]]>. The data is described as unparsed because the XML processor does not analyze it in any way but makes it available to an application. The data within a CDATA section can be anything at all — it can even be binary data. You can use a CDATA section to include markup in a document that you don’t want to have parsed. For example
<explanation> A typical circle element is written as: <![CDATA[ <circle diameter="30"> <position x="40" y="50"/> </circle> ]]> </explanation>
The lines shown in bold are within a CDATA section, and although they look suspiciously like markup, an XML processor looking for markup does not scan them. I have used some of the reserved characters in here without escaping them, but because the data in a CDATA section is not parsed, they are not identified as markup.
Element Attributes
You can put additional information within an element in the form of one or more attributes. An attribute is identified by an attribute name, and the value is specified as a string between single or double quotes. For example:
<elementname attributename="Attribute value"> ... </elementname>
As I said earlier, empty elements frequently have attributes. Here’s an example of an empty element with three attributes:
<color red="255" green="128" blue="64"></color>
This is normally written in the shorthand form, like this:
<color red="255" green="128" blue="64" />
You can use single quotes to delimit an attribute value if you want. The names of the three attributes here are red, green, and blue, which identify the primary components of the color. The values for these between 0 and 255 represent the contribution of each primary color to the result. Attribute names are defined using the same rule as element names. The attributes for an element follow the element name in the start tag (or the only tag in the case of an empty element) and are separated from it by at least one space. If a tag has multiple attributes, they must be separated by spaces. You can also put spaces on either side of the = sign, but it is clearer without, especially where there are several attributes. HTML fans should note that a comma separator between attributes is not allowed in XML and is reported as an error.
A string that is an attribute value must not contain a delimiting character explicitly within the string, but you can put a double quote as part of the value string if you use single quotes as delimiters, and vice versa. For example, you could write the following:
<textstuff answer="it's mine" explanation='He said"It is mine"'/>
The value for the answer attribute uses double quotes as delimiters, so it can contain a single quote explicitly; thus the value is it's mine. Similarly, the value for the second attribute uses single quotes so the string can contain a double quote, so its value is He said "It is mine". Of course, someone is bound to want both a single quote and a double quote as part of the value string. Easy, just use an escape sequence within the value for the one that is a delimiter. For example, you could rewrite the previous example as
<textstuff answer='it's mine' explanation="He said"It's mine""/>
In general it’s easiest to stick to a particular choice of delimiter for strings and always escape occurrences of the delimiter within a string.
You can define a circle by a diameter and a position. You can easily define a circle in XML — in fact, there are many ways in which you could do this. Here’s one example:
<circle diameter="30"> <position x="40" y="50"/> </circle>
The diameter attribute for the <circle> tag specifies the diameter of the circle, and its position is specified by an empty <position/> tag, with the x and y coordinates of the circle’s position specified by attributes x and y. A reasonable question to ask is whether this is the best way of representing a circle. Let’s explore the options in this context a little further.
Attributes versus Elements
Obviously you could define a circle without using attributes, maybe like this:
<circle>
<diameter>30</diameter>
<position>
<x-coordinate>40</x-coordinate>
<y-coordinate>50</y-coordinate>
</position>
</circle>
This is the opposite extreme. There are no attributes here, only elements. Where the content of an element is one or more other elements — as in the case of the <circle> and <position> elements here — it is described as element content. A document design in which all the data is part of element content and no attributes are involved is described as element-normal.
Of course, it is also possible to represent the data defining a circle just using attributes within a single element:
<circle positionx="40" positiony="50" diameter="30"/>
Now you have just one element defining a circle with all the data defined by attribute values. Where all the data in a document is defined as attribute values, it is described as attribute-normal.
An element can also contain a mixture of text and markup — so-called mixed content — so you have another way in which you could define a circle in XML, like this:
<circle>
<position>
<x-coordinate>40</x-coordinate>
<y-coordinate>50</y-coordinate>
</position>
30
</circle>
Now the value for the diameter just appears as text as part of the content of the <circle> element along with the position element. The disadvantage of this arrangement is that it’s not obvious what the text is, so some information about the structure has been lost compared to the previous example.
So which is the better approach, to go for attributes or elements? Well, it can be either, or both, if you see what I mean. It depends on what the structure of the data is, how the XML is generated, and how it will be used. One overriding consideration is that an attribute is a single value. It has no inner structure, so anything that does have substructure must be expressed using elements. Where data is essentially hierarchical, representing family trees in XML, for example, you should use nested elements to reflect the structure of the data. Where the data is serial or tabular, temperature and rainfall or other weather data over time, for example, you may well use attributes within a series of elements within the root element.
If you are generating an XML document interactively using an editor, then readability is an important consideration. Poor readability encourages errors. You’ll lean toward whatever makes the editing easier — and for the most part, elements are easier to find and edit than attributes. Attribute values should be short for readability, so this limits the sort of data that you can express as an attribute. You probably would not want to see the soliloquy from Shakespeare’s Hamlet appearing as an attribute value, for example. That said, if the XML is computer-generated and is not primarily intended for human viewing, the choice is narrowed down to the most efficient way to handle the data in the computer. Attributes and their values are readily identified in a program, so documents are likely to make use of attributes wherever the structure of the data does not require otherwise. You see how this works out in practice when you get to use the Java API for processing XML.
Whitespace and Readability
The indentation shown in the examples so far has been included just to provide you with visual cues to the structure of the data. It is not required, and an XML processor ignores the whitespace between elements. When you are creating XML in an editor, you can use whitespace between elements to make it easier for a human reader to understand the document. Whitespace can consist of spaces, tabs, carriage returns, and linefeed characters. You can see that a circle expressed without whitespace, as shown below, is significantly less readable:
<circle><position><x-coordinate>40</x-coordinate><y-coordinate>50 </y-coordinate></position>30</circle>
Having said that, you don’t have complete freedom in deciding where you put whitespace within a tag. The tag name must immediately follow the opening < or </ in a tag, and there can be no space within an opening </ delimiter, or a closing /> delimiter in the case of an empty element. You must also separate an attribute from the tag name or from another attribute with at least one space. Beyond that you can put additional spaces within a tag wherever you like.
The ability to nest elements is fundamental to defining the structure of the data in a document. We can easily represent the structure of the data in our XML fragment defining an address, as shown in Figure 22-1.
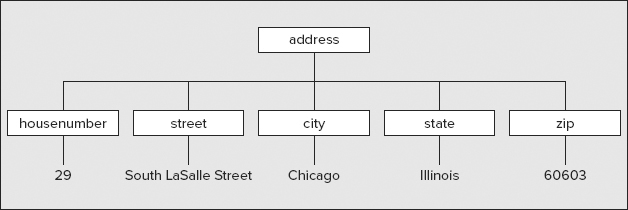
The structure follows directly from the nesting of the elements. The <address> element contains all of the others directly, so the nested elements are drawn as subsidiary or child elements of the <address> element. The items that appear within the tree structure — the elements and the data items — are referred to as nodes.
Figure 22-2 shows the structure of the first circle definition in XML that you saw in the previous section. Even though there’s an extra level of elements in this diagram, there are strong similarities to the structure shown in Figure 22-1.
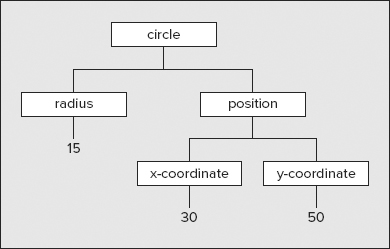
You can see that both structures have a single root element, <address> in the first example and <circle> in the second. You can also see that each element contains either other elements or some data that is a segment of the document content. In both diagrams all the document content lies at the bottom. Nodes at the extremities of a tree are referred to as leaf nodes.
In fact an XML document always has a structure similar to this. Each element in a document can contain other elements, or text, or elements and text, or it can be empty.
You have seen several small examples of XML, and in each case it was fairly obvious what the content was meant to represent, but where are the rules that ensure such data is represented consistently and correctly in different documents? Do the <diameter> and <position> elements have to be in that sequence in a <circle> element, and could you omit either of them?
Clearly there has to be a way to determine what is correct and what is incorrect for any particular element in a document. As I mentioned earlier, a DTD defines how valid elements are constructed for a particular type of document, so the XML for purchase order documents in a company could be defined by one DTD, and sales invoice documents by another. The Document Type Definition for a document is specified in a document type declaration — commonly known as a DOCTYPE declaration — that appears in the document prolog following any XML declaration. A DTD essentially defines a vocabulary for describing data of a particular kind — the set of elements that you use to identify the data, in other words. It also defines the possible relationships between these elements — how they can be nested. The contents of a document of the type identified by a particular DTD must be defined and structured according to rules that make up the DTD. Any document of a given type can be checked for validity against its DTD.
A DTD can be an integral part of a document, but it is usually, and more usefully, defined separately. Including a DTD in an XML document makes the document self-contained, but it does increase its bulk. It also means that the DTD has to appear within every document of the same type. A separate DTD that is external to a document avoids this and provides a single reference point for all documents of a particular type. An external DTD also makes maintenance of the DTD for a document type easier, as it only needs to be changed in one place for all documents that make use of it. Let’s look at how you identify the DTD for a document and then investigate some of the ways in which elements and their attributes can be defined in a DTD.
Declaring a DTD
You use a document type declaration (a DOCTYPE declaration) in the prolog of an XML document to specify the DTD for the document. An XML 1.0 document can have only one DOCTYPE declaration. You can include the markup declarations for elements used in the document explicitly within the DOCTYPE statement, in which case the declarations are referred to as the internal subset. You can also specify a URI that identifies the DTD for the document, usually in the form of a URL. In this case the set of declarations is referred to as the external subset. If you include explicit declarations as well as a URI referencing an external DTD, the document has both an internal and an external subset. Here is an example of an XML document that has an external subset:
<?xml version="1.0"?>
<!DOCTYPE address SYSTEM "http://docserver/dtds/AddressDoc.dtd">
<address>
<buildingnumber> 29 </buildingnumber>
<street> South LaSalle Street</street>
<city>Chicago</city>
<state>Illinois</state>
<zip>60603</zip>
</address>
The name following the DOCTYPE keyword must always match the root element name in the document, so the DOCTYPE declaration here indicates that the root element in the document has the name address. The declaration also indicates that the DTD in which this and the other elements in the document are declared is an external DTD located at the URI following the SYSTEM keyword. This URI, which is invariably a URL, is called the system ID for the DTD.
In principle, you can also specify an external DTD by a public ID using the keyword PUBLIC in place of SYSTEM. A public ID is just a unique public name that identifies the DTD — a Uniform Resource Name (URN), in other words. As you probably know, the idea behind URNs is to get over the problem of changes to URLs. Public IDs are intended for DTDs that are available as public standards for documents of particular types, such as SVG. However, there is a slight snag. Because there is no mechanism defined for resolving public IDs to find the corresponding URL, if you specify a public ID, you still have to supply a system ID with a URL so the XML processor can find it, so you won’t see public IDs in use much.
If the file containing the DTD is stored on the local machine, you can specify its location relative to the directory containing the XML document. For example, the following DOCTYPE declaration implies that the DTD is in the same directory as the document itself:
<!DOCTYPE address SYSTEM "AddressDoc.dtd">
The AddressDoc.dtd file includes definitions for the elements that may be included in a document containing an address. In general, a relative URL is assumed to be relative to the location of the document containing the reference.
Defining a DTD
In looking at the details of how we put a DTD together, I’ll use examples in which the DTD is an internal subset, but the declarations in an external DTD are exactly the same. Here’s an example of a document with an integral DTD:
<?xml version="1.0"?> <!DOCTYPE proverb [ <!ELEMENT proverb (#PCDATA)> ]> <proverb>A little knowledge is a dangerous thing.</proverb>
All the internal definitions for elements used within the document appear between the square brackets in the DOCTYPE declaration. In this case just one element is declared, the root element, and the element content is PCDATA — parsed character data.
You could define an external DTD in a file with the name proverbDoc.dtd in the same directory as the document. The file would contain just a single line:
<!ELEMENT proverb (#PCDATA)>
The XML document would then be the following:
<?xml version="1.0"?>
<!DOCTYPE proverb SYSTEM "proverbDoc.dtd">
<proverb>A little knowledge is a dangerous thing.</proverb>
The DTD is referenced by a relative URI that is relative to the directory containing the document.
When you want both an internal and external subset, you just put both in the DOCTYPE declaration, with the external DTD reference appearing first. Entities from both are available for use in the document, but where there is any conflict between them, the entities defined in the internal subset take precedence over those declared in the external subset.
The syntax for defining elements and their attributes is rather different from the syntax for XML markup. It also can get quite complex, so I’m not able to go into it comprehensively here. However, you do need to have a fair idea of how a DTD is put together in order to understand the operation of the Java API for XML, so let’s look at some of the ways in which you can define elements in a DTD.
Defining Elements in DTDs
The DTD defines each type of element that can appear in the document using an ELEMENT type declaration. For example, the <address> element could be defined like this:
<!ELEMENT address (buildingnumber, street, city, state, zip)>
This defines the element with the name address. The information between the parentheses specifies what can appear within an <address> element. The definition states that an <address> element contains exactly one each of the elements <buildingnumber>, <street>, <city>, <state>, and <zip>, in that sequence. This is an example of element content because only elements are allowed within an <address> element. Note the space that appears between the element name and the parentheses enclosing the content definition. This is required, and a parser flags the absence of at least one space here as an error. The ELEMENT identifier must be in capital letters and must immediately follow the opening “<!."
The preceding definition of the <address> element makes no provision for anything other than the five elements shown, and in that sequence. Thus, any whitespace that you put between these elements in a document is not part of the content and is ignored by a parser; therefore, it is known as ignorable whitespace. That said, you can still find out if there is whitespace there when the document is parsed, as you later see.
You can define the <buildingnumber> element like this:
<!ELEMENT buildingnumber (#PCDATA)>
This states that the element can contain only parsed character data, specified by #PCDATA. This is just ordinary text, and because it is parsed, it cannot contain markup. The # character preceding the word PCDATA is necessary just to ensure it cannot be confused with an element or attribute name — it has no other significance. Because element and attribute names must start with a letter or an underscore, the # prefix to PCDATA ensures that it cannot be interpreted as such.
The PCDATA specification does provide for markup — child elements — to be mixed in with ordinary text. In this case you must specify the names of the elements that can occur mixed in with the text. If you want to allow a <suite> element specifying a suite number to appear alongside the text within a <buildingnumber> element, you could express it like this:
<!ELEMENT buildingnumber (#PCDATA|suite)*>
This indicates that the content for a <buildingnumber> element is parsed character data, and the text can be combined with <suite> elements. The | operator here has the same meaning as the | operator you read about in the context of regular expressions in Chapter 15. It means one or other of the two operands, but not both. The * following the parentheses is required here and has the same meaning as the * operator that you also read about in the context of regular expressions. It means that the operand to the left can appear zero or more times.
If you want to allow several element types to be optionally mixed in with the text, you separate them by |. Note that it is not possible to control the sequence in which mixed content appears.
The other elements used to define an address are similar, so you could define the whole document with its DTD like this:
<?xml version="1.0"?> <!DOCTYPE address [ <!ELEMENT address (buildingnumber, street, city, state, zip)> <!ELEMENT buildingnumber (#PCDATA)> <!ELEMENT street (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT state (#PCDATA)> <!ELEMENT zip (#PCDATA)> ]> <address> <buildingnumber> 29 </buildingnumber> <street> South LaSalle Street</street> <city>Chicago</city> <state>Illinois</state> <zip>60603</zip> </address>
Note that you have no way with DTDs to constrain the parsed character data in an element definition. It would be nice to be able to specify that the building number had to be numeric, for example, but the DTD grammar and syntax provide no way to do this. This is a serious limitation of DTDs and one of the driving forces behind the development of XML Schemas, which is an XML-based description language that supports data types and offers an alternative to DTDs. I introduce XML Schemas a little later in this chapter.
If you were to create the DTD for an address document as a separate file, the file contents would just consist of the element definitions:
<!ELEMENT address (buildingnumber, street, city, state, zip)> <!ELEMENT buildingnumber (#PCDATA)> <!ELEMENT street (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT state (#PCDATA)> <!ELEMENT zip (#PCDATA)>
The DOCTYPE declaration identifies the DTD for a particular document, so it is not part of the DTD. If the preceding DTD were stored in the AddressDoc.dtd file in the same directory as the document, the DOCTYPE declaration in the document would be the following:
<?xml version="1.0"?>
<!DOCTYPE address SYSTEM "AddressDoc.dtd">
<address>
<buildingnumber> 29 </buildingnumber>
<street> South LaSalle Street</street>
<city>Chicago</city>
<state>Illinois</state>
<zip>60603</zip>
</address>
Of course, the DTD file would also include definitions for element attributes, if there were any. These will be useful later, so save the DTD (as AddressDoc.dtd) and the preceding XML file (as Address.xml, perhaps) in your Beg Java Stuff directory that is in your user.home directory.
One further possibility you need to consider is that in many situations it is desirable to allow some child elements to be omitted. For example, <buildingnumber> may not be included in some cases. The <zip> element, while highly desirable, might also be left out in practice. We can indicate that an element is optional by using the cardinality operator, ?. This operator expresses the same idea as the equivalent regular expression operator, and it indicates that a child element may or may not appear. The DTD would then look like this:
<!DOCTYPE address
[
<!ELEMENT address (buildingnumber?, street, city, state, zip?)>
<!ELEMENT buildingnumber (#PCDATA)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
<!ELEMENT zip (#PCDATA)>
]>
The ? operator following an element indicates that the element may be omitted or may appear just once. This is just one of three cardinality operators that you use to specify how many times a particular child element can appear as part of the content for the parent. The cardinality of an element is simply the number of possible occurrences for the element. The other two cardinality operators are *, which you have already seen, and +. In each case the operator follows the operand to which it applies. You now have four operators that you can use in element declarations in a DTD, and they are each similar in action to their equivalent in the regular expression context (see Table 22-2):
TABLE 22-2: Operators for Element Declarations in a DTD
| OPERATOR | DESCRIPTION |
| + | This operator indicates that there can be one or more occurrences of its operand. In other words, there must be at least one occurrence, but there may be more. |
| * | This operator indicates that there can be zero or more occurrences of its operand. In other words, there can be none or any number of occurrences of the operand to which it applies. |
| ? | This indicates that its operand may appear once or not at all. |
| | | This operator indicates that there can be an occurrence of either its left operand or its right operand, but not both. |
You might want to allow a building number or a building name in an address, in which case the DTD could be written as follows:
<!ELEMENT address ((buildingnumber | buildingname), street, city, state, zip?)>
<!ELEMENT buildingnumber (#PCDATA)>
<!ELEMENT buildingname (#PCDATA)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
<!ELEMENT zip (#PCDATA)>
The DTD now states that either <buildingnumber> or <buildingname> must appear as the first element in <address>. But you might want to allow neither, in which case you would write the third line as the following:
<!ELEMENT address ((buildingnumber | buildingname)?, street, city, state, zip?)>
The ? operator applies to the parenthesized expression (buildingnumber | buildingname), so it now states that either <buildingnumber> or <buildingname> may or may not appear, so you allow one, or the other, or none.
Of course, you can use the | operator repeatedly to express a choice between any number of elements, or indeed, subexpressions between parentheses. For example, given that you have defined elements Linux, Solaris, and Windows, you might define the element operatingsystem as
<!ELEMENT operatingsystem (Linux | Solaris | Windows)>
If you want to allow an arbitrary operating system to be identified as a further alternative, you could write
<!ELEMENT operatingsystem (AnyOS | Linux | Solaris | Windows)> <!ELEMENT AnyOS (#PCDATA)>
You can combine the operators you’ve seen to produce definitions for content of almost unlimited complexity. For example:
<!ELEMENT breakfast ((tea|coffee), orangejuice?, ((egg+, (bacon|sausage)) | cereal) , toast)>
This states that <breakfast> content is either a <tea> or <coffee> element, followed by an optional <orangejuice> element, followed by either one or more <egg> elements and a <bacon> or <sausage> element, or a <cereal> element, with a mandatory <toast> element bringing up the rear. However, while you can produce mind-boggling productions for defining elements, it is wise to keep things as simple as possible.
After all this complexity, you mustn’t forget that an element may also be empty, in which case it can be defined like this:
<!ELEMENT position EMPTY>
This states that the <position> element has no content. Elements can also have attributes, so let’s take a quick look at how they can be defined in a DTD.
Defining Element Attributes
You use an ATTLIST declaration in a DTD to define the attributes for a particular element. As you know, attributes are name-value pairs associated with a particular element, and values are typically, but not exclusively, text. Where the value for an attribute is text, it is enclosed between quotation marks, so it is always unparsed character data. Attribute values that consist of text are therefore specified just as CDATA. No preceding # character is necessary in this context because there is no possibility of confusion.
You could declare the elements for a document containing circles as follows:
<?xml version="1.0"?> <!DOCTYPE circle [ <!ELEMENT circle (position)> <!ATTLIST circle diameter CDATA #REQUIRED > <!ELEMENT position EMPTY> <!ATTLIST position x CDATA #REQUIRED y CDATA #REQUIRED > ]> <circle diameter="30"> <position x="30" y="50"/> </circle>
Three items define each attribute — the attribute name, the type of value (CDATA), and whether or not the attribute is mandatory. This third item may also define a default value for the attribute, in which case this value is assumed if the attribute is omitted. The #REQUIRED specification against an attribute name indicates that it must appear in the corresponding element. You specify the attribute as #IMPLIED if it need not be included. In this case the XML processor does not supply a default value for the attribute. An application is expected to have a default value of its own for the attribute value that is implied by the attribute’s omission.
Save this XML in your Beg Java Stuff directory with a suitable name such as "circle with DTD.xml;" it comes in handy in the next chapter.
You specify a default value for an attribute between double quotes. For example:
<!ATTLIST circle
diameter CDATA "2"
>
This indicates that the value of diameter is 2 if the attribute is not specified for a <circle> element.
You can also insist that a value for an attribute must be one of a fixed set. For example, suppose you had a color attribute for your circle that could be only red, blue, or green. You could define it like this:
<!ATTLIST circle
color (red|blue|green) #IMPLIED
>
The value for the color attribute in a <circle> element must be one of the options between the parentheses. In this case the attribute can be omitted because it is specified as #IMPLIED, and an application processing it supplies a default value. To make the inclusion of the attribute mandatory, you define it as
<!ATTLIST circle
color (red|blue|green) #REQUIRED
>
An important aspect of defining possible attribute values by an enumeration like this is that an XML editor can help the author of a document by prompting with the list of possible attribute values from the DTD when the element is being created.
An attribute that you declare as #FIXED must always have the default value. For example:
<!ATTLIST circle
color (red|blue|green) #REQUIRED
line_thickness medium #FIXED
>
Here the XML processor supplies an application only with the value medium for the thickness attribute. If you were to specify this attribute for the <circle> element in the body of the document you could use only the default value; otherwise, it is an error.
Defining Parameter Entities
You often need to repeat a block of information at different places in a DTD. A parameter entity identifies a block of parsed text by a name that you can use to insert the text at various places within a DTD. Note that parameter entities are for use only within a DTD. You cannot use parameter entity references in the body of a document. You declare general entities in the DTD when you want to repeat text within the document body.
The form for a parameter entity is very similar to what you saw for general entities, except that a % character appears between ENTITY and the entity name, separated from both by a space. For example, it is quite likely that you would want to repeat the x and y attributes that you defined in the <position> element in the previous section in other elements. You could define a parameter entity for these attributes and then use that wherever these attributes appear in an element declaration. Here’s the parameter entity declaration:
<!ENTITY % coordinates "x CDATA #REQUIRED y CDATA #REQUIRED">
Now you can use the entity name to insert the x and y attribute definitions in an attribute declaration:
<!ATTLIST position %coordinates; >
A parameter entity declaration must precede its use in a DTD.
The substitution string in a parameter entity declaration is parsed and can include parameter and general entity references. As with general entities, you can also define a parameter entity by a reference to a URI containing the substitution string.
Other Types of Attribute Values
There are a further eight possibilities for specifying the type of the attribute value. I’m not going into detail on these, but a brief description of each is in Table 22-3 so you can recognize them:
TABLE 22-3: Other Types of Attribute Values
| VALUE | DESCRIPTION |
| ENTITY | An entity defined in the DTD. An entity here is a name identifying an unparsed entity defined elsewhere in the DTD by an ENTITY tag. The entity may or may not contain text. An entity could represent something very simple, such as <, which refers to a single character, or it could represent something more substantial, such as an image. |
| ENTITIES | A list of entities defined in the DTD, separated by spaces. |
| ID | An ID is a unique name identifying an element in a document. This is to enable internal references to a particular element from elsewhere in the document. |
| IDREF | A reference to an element elsewhere in a document via its ID. |
| IDREFS | A list of references to IDs, separated by spaces. |
| NMTOKEN | A name conforming to the XML definition of a name. This just says that the value of the attribute is consistent with the XML rules for a name. |
| NMTOKENS | A list of name tokens, separated by spaces. |
| NOTATION | A name identifying a notation — which is typically a format specification for an entity such as a JPEG or PostScript file. The notation is identified elsewhere in the DTD using a NOTATION tag that may also identify an application capable of processing an entity in the given format. |
A DTD for Sketcher
With what you know of XML and DTDs, you can have a stab at putting together a DTD for storing Sketcher files as XML. As I said before, an XML language has already been defined for representing and communicating two-dimensional graphics. This is called Scalable Vector Graphics, and you can find it at www.w3.org/TR/SVG/. Although this would be the choice for transferring 2D graphics as XML documents in a real-world context, the objective here is to exercise your knowledge of XML and DTDs, so you’ll reinvent your own version of this wheel, even though it has fewer spokes and may wobble a bit.
First, let’s consider what the general approach is going to be. The objective is to define a DTD that enables you to exercise the Java API for XML with Sketcher, so you define the language to make it an easy fit to Sketcher rather than worrying about the niceties of the best way to represent each geometric element. Because Sketcher was a vehicle for trying out various capabilities of the Java class libraries, it evolved in a somewhat Topsy-like fashion, with the result that the classes defining geometric entities are not necessarily ideal. However, you just map these directly in XML to avoid the mathematical hocus pocus that would be necessary if you adopted a more formal representation of geometry in XML.
You want to be able to reconstruct the elements in an existing sketch from the XML, so this does not necessarily require the same data as you used to create the elements in the first place. Essentially, you want to reconstruct the fields in an Element object. For the geometric elements, this means reconstructing the object that represents a particular element, plus its position, rotation angle, bounding rectangle, and color.
The XML Element for a Sketch
A sketch is a very simple document. It’s basically a sequence of lines, circles, rectangles, curves, and text. You can therefore define the root element <sketch> in the DTD as the following:
<!ELEMENT sketch (line|circle|rectangle|curve|text)*>
This says that a sketch consists of zero or more of any of the elements between the parentheses. You now need to define each of these elements.
The XML Element for a Line Element in a Sketch
A line is easy. It is defined by its location, which is its start point and a Line2D.Double object. It also has an orientation — its rotation angle — and a color. You could define a <line> element like this:
<!ELEMENT line (color, position, bounds, endpoint)>
<!ATTLIST line
angle CDATA #REQUIRED
>
A line is fully defined by two points, its position, and its end point, which is relative to the origin. A line has a bounds rectangle, as all the elements do, so you define another type of element, <bounds>, for this rectangle.
You could define color by a color attribute to the <line> element with a set of alternative values, but to allow the flexibility for lines of any color, it would be better to define a <color> element with three attributes for RGB values. In this case you can define the <color> element as
<!ELEMENT color EMPTY>
<!ATTLIST color
R CDATA #REQUIRED
G CDATA #REQUIRED
B CDATA #REQUIRED
>
You can now define the <position> and <endpoint> elements. These are both points defined by an (x, y) coordinate pair, so you would sensibly define them consistently. Empty elements with attributes are the most economical way here, and you can use a parameter entity for the attributes:
<!ENTITY % coordinates "x CDATA #REQUIRED y CDATA #REQUIRED"> <!ELEMENT position EMPTY> <!ATTLIST position %coordinates;> <!ELEMENT endpoint EMPTY> <!ATTLIST endpoint %coordinates;>
You can define a <bounds> element with the coordinates of its top-left corner and the width and height as attributes:
<!ENTITY % dimensions "width CDATA #REQUIRED height CDATA #REQUIRED">
<!ELEMENT bounds EMPTY>
<!ATTLIST bounds
%coordinates;
%dimensions;>
You could conceivably omit the top-left corner coordinates because they are the same as the position for the sketch element. However, including them enables you to reconstruct the bounding rectangle object with no dependency on the position field having been reconstructed previously.
The XML Element for a Rectangle Element in a Sketch
You can define a rectangle very similarly to a line because it is defined by its position, which corresponds to the top-left corner, plus a rectangle at the origin with a width and height. The width and height attributes are specified by a parameter entity because you are able to use this in the XML element for a rectangle. A rectangle also has a color in which it is to be drawn, a rotation angle, and a bounding rectangle. Here’s how this looks in the DTD:
<!ELEMENT rectangle (color, position, bounds)>
<!ATTLIST rectangle
angle CDATA #REQUIRED
%dimensions;
>
As with a line, the rotation angle is specified by an attribute, as are the width and height of the Rectangle2D.Double object.
The XML Element for a Circle Element in a Sketch
The <circle> element is no more difficult. It has a position and the Ellipse2D.Double object has a width and a height, but these are the same, being the diameter of the circle. Like other elements, it has a color, a rotation angle (remember, we rotate circles about the top-left corner of the enclosing rectangle in Sketcher), and a bounding rectangle. You can define it like this:
<!ELEMENT circle (color, position, bounds)>
<!ATTLIST circle
angle CDATA #REQUIRED
diameter CDATA #REQUIRED
>
The XML Element for a Curve Element in a Sketch
The <curve> element is a little more complicated because it’s defined by an arbitrary number of points, but it’s still quite easy:
<!ELEMENT curve (color, position, bounds, point+)> <!ATTLIST curve angle CDATA #REQUIRED> <!ELEMENT point EMPTY> <!ATTLIST point %coordinates;>
The start point of the curve is defined by the <position> element, and the GeneralPath object that defines a curve includes at least one <point> element in addition to the origin, which is specified by the + operator. The <point> element just has attributes for the coordinate pair.
The XML Element for a Text Element in a Sketch
You need to allow for the font name and its style and point size, a rotation angle for the text, and a color — plus the text itself, of course, and its position. A Text element also has a bounding rectangle that is required to construct it. You have some options as to how you define this element. You could use mixed element content in a <text> element, combining the text string with <font> and <position> elements, for example.
The disadvantage of this is that you cannot limit the number of occurrences of the child elements and how they are intermixed with the text. You can make the definition more precisely controlled by enclosing the text in its own element. Then you can define the <text> element as having element content — like this:
<!ELEMENT text (color, position, bounds, font, string)>
<!ATTLIST text
angle CDATA #REQUIRED
maxascent CDATA #REQUIRED
>
<!ELEMENT font EMPTY>
<!ATTLIST font
fontname CDATA #REQUIRED
fontstyle (plain|bold|italic) #REQUIRED
pointsize CDATA #REQUIRED
>
<!ELEMENT string (#PCDATA)>
The text element has a maxascent attribute in addition to the angle attribute to specify the value of the maximum ascent for the font. The <font> and <string> elements are new. The <font> element provides the name, style, and size of the font as attribute values, and because nothing is required beyond that, it is an empty element. You could specify the style as CDATA because its value is just an integer, but that would make the XML for a sketch rather less readable because the font style would not be obvious from the integer value. The <string> element content is just the text to be displayed. Other children of the <text> element specify the color and position of the text.
The Complete Sketcher DTD
That’s all you need. The complete DTD for Sketcher documents is the following:
<?xml version="1.0" encoding="UTF-8"?> <!ELEMENT sketch (line|circle|rectangle|curve|text)*> <!ELEMENT color EMPTY> <!ATTLIST color R CDATA #REQUIRED G CDATA #REQUIRED B CDATA #REQUIRED > <!ENTITY % coordinates "x CDATA #REQUIRED y CDATA #REQUIRED"> <!ENTITY % dimensions "width CDATA #REQUIRED height CDATA #REQUIRED"> <!ELEMENT position EMPTY> <!ATTLIST position %coordinates;> <!ELEMENT endpoint EMPTY> <!ATTLIST endpoint %coordinates;> <!ELEMENT bounds EMPTY> <!ATTLIST bounds %coordinates; %dimensions;> <!ELEMENT string (#PCDATA)> <!ELEMENT point EMPTY> <!ATTLIST point %coordinates;> <!ELEMENT font EMPTY> <!ATTLIST font fontname CDATA #REQUIRED fontstyle (plain|bold|italic|bold-italic) #REQUIRED pointsize CDATA #REQUIRED > <!ELEMENT line (color, position, bounds, endpoint)> <!ATTLIST line angle CDATA #REQUIRED > <!ELEMENT rectangle (color, position, bounds)> <!ATTLIST rectangle angle CDATA #REQUIRED %dimensions; > <!ELEMENT circle (color, position, bounds)> <!ATTLIST circle angle CDATA #REQUIRED diameter CDATA #REQUIRED > <!ELEMENT curve (color, position, bounds, point+)> <!ATTLIST curve angle CDATA #REQUIRED> <!ELEMENT text (color, position, bounds, font, string)> <!ATTLIST text angle CDATA #REQUIRED maxascent CDATA #REQUIRED >
You can use this DTD to represent any sketch in XML. Stash it away in your Beg Java Stuff directory as sketcher.dtd. You will try it out later.
RULES FOR A WELL-FORMED DOCUMENT
Now that you know a bit more about XML elements and what goes into a DTD, I can formulate what you must do to ensure your XML document is well-formed. The rules for a document to be well-formed are quite simple:
1. If the XML declaration appears in the prolog, it must include the XML version. Other specifications in the XML document must be in the prescribed sequence — character encoding followed by standalone specification.
2. If the document type declaration appears in the prolog, the DOCTYPE name must match that of the root element, and the markup declarations in the DTD must be according to the rules for writing markup declarations.
3. The body of the document must contain at least one element, the root element, which contains all the other elements, and an instance of the root element must not appear in the content of another element. All elements must be properly nested.
4. Elements in the body of the document must be consistent with the markup declarations identified by the DOCTYPE declaration.
The rules for writing an XML document are absolutely strict. Break one rule and your document is not well-formed and is not processed. This strict application of the rules is essential because you are communicating data and its structure. If any laxity were permitted, it would open the door to uncertainty about how the data should be interpreted. HTML used to be quite different from XML in this respect. Until recently, the rules for writing HTML were only loosely applied by HTML readers such as web browsers.
For example, even though a paragraph in HTML should be defined using a start tag, <p>, and an end tag, </p>, you can usually get away with omitting the end tag, and you can use both capital and lowercase p, and indeed close a capital P paragraph with a lowercase p, and vice versa. You can often have overlapping tags in HTML and get away with that, too. Although it is not to be recommended, a loose application of the rules for HTML is not so harmful because HTML is concerned only with data presentation. The worst that can happen is that the data does not display quite as you intended.
In 2000, the W3C released the XHTML 1.0 standard that makes HTML an XML language, so more and more HTML documents are conforming to this. The enduring problem is, of course, that the Internet has accumulated a great deal of material over many years that is still very useful but that will never be well-formed XML, so browsers may never be fully XML-compliant.
Even though they are very simple, XML namespaces can be very confusing. The confusion arises because it is so easy to make assumptions about what they imply when you first meet them. Let’s look briefly at why you have XML namespaces in the first place, and then see what an XML namespace actually is.
You saw earlier that an XML document can have only one DOCTYPE declaration. This can identify an external DTD by a URI or include explicit markup declarations, or it may do both. What happens if you want to combine two or more XML documents that each has its own DTD into a single document? The short answer is that you can’t — not easily anyway. Because the DTD for each document has been defined without regard for the other, element name collisions are a real possibility. It may be impossible to differentiate between different elements that share a common name, and in this case major revisions of the documents’ contents, as well as a new DTD, are necessary to deal with this. It won’t be easy.
XML namespaces are intended to help deal with this problem. They enable names used in markup to be qualified, so that you can make duplicate names that are used in different markup unique by putting them in separate namespaces. An XML namespace is just a collection of element and attribute names that is identified by a URI. Each name in an XML namespace is qualified by the URI that identifies the namespace. Thus, different XML namespaces may contain common names without causing confusion because each name is notionally qualified by the unique URI for the namespace that contains it.
I say “notionally qualified" because you don’t usually qualify element and attribute names using the URI directly, although you could. Normally, in the interests of not making the markup overly verbose, you use another name called a namespace prefix whose value is the URI for the namespace. For example, I could have a namespace that is identified by the URI www.wrox.com/Toys and a namespace prefix, toys, that contains a declaration for the name rubber_duck. I could have a second namespace with the URI www.wrox.com/BathAccessories and the namespace prefix bathAccessories that also defines the name rubber_duck. The rubber_duck name from the first namespace is referred to as toys:rubber_duck and that from the second namespace is bathAccessories:rubber_duck, so there is no possibility of confusing them. The colon is used in the qualified name to separate the namespace prefix from the local name, which is why I said earlier in the chapter that you should avoid the use of colons in ordinary XML names.
Let’s come back to the confusing aspects of namespaces for a moment. There is a temptation to imagine that the URI that identifies an XML namespace also identifies a document somewhere that specifies the names in the namespace. This is not required by the namespace specification. The URI is just a unique identifier for the namespace and a unique qualifier for a set of names. It does not necessarily have any other purpose, or even have to refer to a real document; it only needs to be unique. The definition of how names within a given namespace relate to one another and the rules for markup that uses them is an entirely separate question. This may be provided by a DTD or some other mechanism, such as an XML Schema.
Namespace Declarations
A namespace is associated with a particular element in a document, which of course can be, but does not have to be, the root element. A typical namespace declaration in an XML document looks like this:
<sketcher:sketch xmlns:sketcher="http://www.wrox.com/dtds/sketches">
A namespace declaration uses a special reserved attribute name, xmlns, within an element, and in this instance the namespace applies to the <sketch> element. The name sketcher that is separated from xmlns by a colon is the namespace prefix, and it has the value www.wrox.com/dtds/sketches. You can use the namespace prefix to qualify names within the namespace, and because this maps to the URI, the URI is effectively the qualifier for the name. The URL that I’ve given here is hypothetical — it doesn’t actually exist, but it could. The sole purpose of the URI identifying the namespace is to ensure that names within the namespace are unique, so it doesn’t matter whether it exists or not. You can add as many namespace declarations within an element as you want, and each namespace declared in an element is available within that element and its content.
With the namespace declared with the sketcher prefix, you can use the <circle> element that is defined in the sketcher namespace like this:
<sketcher:sketch xmlns:sketcher="http://www.wrox.com/dtds/sketches"> <sketcher:circle angle="0" diameter="30"> <sketcher:color R="150" G="250" B="100"/> <sketcher:position x="30" y="50"/> <sketcher:bounds x="30" y="50" width="32" height="32"> </sketcher:bounds> </sketcher:circle> </sketcher:sketch>
Each reference to the element name is qualified by the namespace prefix sketcher. A reference in the same document to a <circle> element that is defined within another namespace can be qualified by the prefix specified in the declaration for that namespace. By qualifying each element name by its namespace prefix, you avoid any possibility of ambiguity.
A namespace has scope — a region of an XML document over which the namespace declaration is visible. The scope of a namespace is the content of the element within which it is declared, plus all direct or indirect child elements. The preceding namespace declaration applies to the <sketch> element and all the elements within it. If you declare a namespace in the root element for a document, its scope is the entire document.
You can declare a namespace without specifying a prefix. This namespace then becomes the default namespace in effect for this element, and its content and unqualified element names are assumed to belong to this namespace. Here’s an example:
<sketch xmlns="http://www.wrox.com/dtds/sketches">
There is no namespace prefix specified, so the colon following xmlns is omitted. This namespace becomes the default, so you can use element and attribute names from this namespace without qualification and they are all implicitly within the default namespace. For example:
<sketch xmlns="http://www.wrox.com/dtds/sketches"> <circle angle="0" diameter="30"> <color R="150" G="250" B="100"/> <position x="30" y="50"/> <bounds x="30" y="50" width="32" height="32"> </bounds> </circle> </sketch>
This markup is a lot less cluttered than the earlier version that used qualified names, which makes it much easier to read. It is therefore advantageous to declare the namespace that you use most extensively in a document as the default.
You can declare several namespaces within a single element. Here’s an example of a default namespace in use with another namespace:
<sketch xmlns="http://www.wrox.com/dtds/sketches"
xmlns:print="http://www.wrox.com/dtds/printed">
<circle angle="0" diameter="30">
<color R="150" G="250" B="100"/>
<position x="30" y="50"/>
<bounds x="30" y="50"
width="32" height="32">
</bounds>
</circle>
<print:circle print:lineweight="3" print:linestyle="dashed"/>
</sketch>
Here the namespace with the prefix print contains names for elements relating to hardcopy presentation of sketch elements. The <circle> element in the print namespace is qualified by the namespace prefix so it is distinguished from the element with the same name in the default namespace.
XML Namespaces and DTDs
For a document to be valid, you must have a DTD, and the document must be consistent with it. The way in which a DTD is defined has no specific provision for namespaces. The DTD for a document that uses namespaces must therefore define the elements and attributes using qualified names, and must also make provision for the xmlns attribute, with or without its prefix, in the markup declaration for any element in which it can appear. Because the markup declarations in a DTD have no specific provision for accommodating namespaces, a DTD is a less than ideal vehicle for defining the rules for markup when namespaces are used. The XML Schema specification provides a much better solution, and overcomes a number of other problems associated with DTDs.
Because of the limitations of DTDs that I mentioned earlier, the W3C has developed the XML Schema language for defining the content and structure of sets of XML documents, and this language is now a W3C standard. You use the XML Schema Definition language to create descriptions of particular kinds of XML documents in a similar manner to the way you use DTDs, and such descriptions are referred to as XML Schemas and fulfill the same role as DTDs. The XML Schema language is itself defined in XML and is therefore implicitly extensible to support new capabilities when necessary. Because the XML Schema language enables you to specify the type and format of data within an XML document, it provides a way for you to define and create XML documents that are inherently more precise, and therefore safer than documents described by a DTD.
It’s easy to get confused when you are working with XML Schemas. One primary source of confusion is the various levels of language definition you are involved with. At the top level, you have XML — everything you are working with in this context is defined in XML. At the next level you have the XML Schema Definition language — defined in XML, of course — and you use this language to define an XML Schema, which is a specification for a set of XML documents. At the lowest level you define an XML document — such as a document describing a Sketcher sketch — and this document is defined according to the rules you have defined in your XML Schema for Sketcher documents. Figure 22-3 shows the relationships between these various XML documents.
The XML Schema language is sometimes referred to as XSD, from XML Schema Definition language. The XML Schema namespace is usually associated with the prefix name xsd, and files containing a definition for a class of XML documents often have the extension .xsd. You also often see the prefix xs used for the XML Schema namespace, but in fact you can use anything you like. A detailed discussion of the XML Schema language is a substantial topic that really requires a whole book to do it justice. I’m just giving you enough of a flavor of how you define XML document schemas so that you’re able to see how it differs from a DTD.
Defining a Schema
The elements in a schema that defines the structure and content of a class of XML documents are organized in a similar way to the elements in a DTD. A schema has a single root element that is unique, and all other elements must be contained within the root element and must be properly nested. Every schema consists of a schema root element with a number of nested subelements. Let’s look at a simple example.
Here’s a possible schema for XML documents that contain an address:
<?xml version="1.0" ?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:annotation>
<xsd:documentation>
This schema defines documents that contain an address.
</xsd:documentation>
</xsd:annotation>
<!--This declares document content. -->
<xsd:element name="address" type="AddressType"/>
<!--This defines an element type that is used in the declaration of content. -->
<xsd:complexType name="AddressType">
<xsd:sequence>
<xsd:element name="buildingnumber" type="xsd:positiveInteger"/>
<xsd:element name="street" type="xsd:string"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string"/>
<xsd:element name="zip" type="xsd:decimal"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>
You might like to contrast this schema with the DTD you saw earlier that defined XML documents with similar content. This schema defines documents that consist of an <address/> root element that contains a sequence of child elements with the names buildingnumber, street, city, state, and zip.
The root element in the schema definition is the xsd:schema element, and that has an attribute with the name xmlns that identifies an XML namespace. The value you specify for the xmlns attribute is a URI that is the namespace name for the content document, and because the current document is a schema, the namespace is the one corresponding to elements in the XML Schema Definition language. The xsd that follows the colon is the prefix that is used to identify element names from the “http://www.w3.org/2001/XMLSchema” namespace, so xsd is shorthand for the full namespace name. Thus schema, complexType, sequence, and element are all names of elements in a namespace defined for the XML Schema Definition language. The root element for every XML Schema is a schema element. Don’t lose sight of what a schema is; it’s a definition of the form of XML documents of a particular type, so it declares the elements that can be used in such a document and how they may be structured. A document that conforms to a particular schema does not have to identify the schema, but it can. I come back to how you reference a schema when you are defining an XML document a little later in this chapter.
The example uses an <annotation/> element to include some simple documentation in the schema definition. The text that is the documentation appears within a child <documentation/> element. You can also use an <appInfo/> child element within an <annotation/> element to reference information located at a given URI. Of course, you can also use XML comments, <!--comment-->, within a schema, as the example shows.
In an XML Schema, a declaration specifies an element that is content for a document, whereas a definition defines an element type. The xsd:element element is a declaration that the content of a document consists of an <address/> element. Contrast this with the xsd:complexType element, which is a definition of the AddressType type for an element and does not declare document content. The xsd:element element in the schema declares that the address element is document content and happens to be of type AddressType, which is the type defined by the xsd:complexType element.
Now let’s take a look at some of the elements that you use to define a document schema in a little more detail.
Defining Schema Elements
As I said, the xsd:complexType element in the sample schema defines a type of element, not an element in the document. A complex element is simply an element that contains other elements, or that has attributes, or both. Any elements that are complex elements need an xsd:complexType definition in the schema to define a type for the element. You place the definitions for child elements for a complex element between the complexType start and end tags. You also place the definitions for any attributes for a complex element between the complexType start and end tags. You can define a simple type using an xsd:simpleType definition in the schema. You would use a simple type definition to constrain attribute values or element content in some way. You see examples of this a little later in this chapter.
In the example you specify that any element of type AddressType contains a sequence of simple elements — a buildingnumber element, a street element, a city element, a state element, and a zip element. A simple element is an element that does not have child elements or attributes; it can contain only data, which can be of a variety of standard types or of a type that you define. The definition of each simple element that appears within an element of type AddressType uses an xsd:element element in which the name attribute specifies the name of the element being defined and the type attribute defines the type of data that can appear within the element.
You can also control the number of occurrences of an element by specifying values for two further attributes within the xsd:element tag, as shown in Table 22-4:
TABLE 22-4: Attributes Specifying the Number of Element Occurrences
| ATTRIBUTE | DESCRIPTION |
| minOccurs | The value defines the minimum number of occurrences of the element and must be a positive integer (which can be 0). If this attribute is not defined, then the minimum number of occurrences of the element is 1. |
| maxOccurs | The value defines the maximum number of occurrences of the element and can be a positive integer or the value unbounded. If this attribute is not defined, then the maximum number of occurrences of the element is 1. |
Thus, if both of these attributes are omitted, as is the case with the child element definitions in the sample schema for elements of type AddressType, the minimum and maximum numbers of occurrences are both one, so the element must appear exactly once. If you specify minOccurs as 0, then the element is optional. Note that you must not specify a value for minOccurs that is greater than maxOccurs, and the value for maxOccurs must not be less than minOccurs. You should keep in mind that both attributes have default values of 1 when you specify a value for just one attribute.
Specifying Data Types
In the example, each of the definitions for the five simple elements within an address element has a type specified for the data that it contains, and you specify the data type by a value for the type attribute. The data in a buildingnumber element is specified to be of type positiveInteger, and the others are all of type string. These two types are relatively self-explanatory, corresponding to positive integers greater than or equal to 0, and strings of characters. The XML Schema Definition language enables you to specify many different values for the type attribute in an element definition. Here are a few other examples:
| DATA TYPE | EXAMPLES OF DATA |
| integer | 25, -998, 12345, 0, -1 |
| negativeInteger | -1, -2, -3, -12345, and so on |
| nonNegativeInteger | 0, 1, 2, 3, and so on |
| hexBinary | 0DE7, ADD7 |
| long | 25, 123456789, -9999999 |
| float | 2.71828, 5E5, 500.0, 0, -3E2, -300.0, NaN, INF, -INF |
| double | 3.14159265, 1E30, -2.5, NaN, -INF, INF |
| boolean | true, false, 1, 0 |
| date | 2010-12-31 |
| language | en-US, en, de |
The float and double types correspond to values within the ranges for 32-bit and 64-bit floating-point values, respectively. The date type is of the form yyyy-mm-dd so there can be no confusion. There are many more standard types within the XML Schema Definition language, and because this is extensible, you can also define data types of your own.
You can also define a default value for a simple element by using the default attribute within the definition of the element. For example, within an XML representation of a sketch you undoubtedly need to have an element defining a color. You might define this as a simple element like this:
<xsd:element name="color" type="xsd:string" default="blue"/>
This defines a color element containing data that is a string and a default value for the string of "blue." In a similar way, you can define the content for a simple element to be a fixed value by specifying the content as the value for the fixed attribute within the xsd:element tag.
Defining Attributes for Complex Elements
You use the xsd:attribute tag to define an attribute for a complex element. Let’s take an example to see how you do this. Suppose you decided that you would define a circle in an XML document for a sketch using a <circle/> element, where the coordinates of the center, the diameter, and the color are specified by attributes. Within the document schema, you might define the type for an element representing a circle like this:
<xsd:complexType name="CircleType"> <xsd:attribute name="x" type="xsd:integer"/> <xsd:attribute name="y" type="xsd:integer"/> <xsd:attribute name="diameter" type="xsd:nonNegativeInteger"/> <xsd:attribute name="color" type="xsd:string"/> </xsd:complexType>
The elements that define the attributes for the <circle/> element type appear within the complexType element, just like child element definitions. You specify the attribute name and the data type for the value in exactly the same way as for an element. The type specification is not mandatory. If you leave it out, it just means that anything goes as a value for the attribute.
You can also specify in the definition for an attribute whether it is optional or not by specifying a value for the use attribute within the xsd:attribute element. The value can be either "optional" or "required." For a circle element, none of the attributes are optional, so you might modify the complex type definition to the following:
<xsd:complexType name="CircleType"> <xsd:attribute name="x" type="xsd:integer" use="required"/> <xsd:attribute name="y" type="xsd:integer" use="required"/> <xsd:attribute name="diameter" type="xsd:double" use="required"/> <xsd:attribute name="color" type="xsd:string" use="required"/> </xsd:complexType>
Restrictions on Values
You can place restrictions on values for element content and element attributes. Such restrictions are referred to as facets. Quite often you want to restrict the values that can be assigned to attributes. For example, the diameter of a circle certainly cannot be zero or negative, and a color may be restricted to standard colors. You could do this by adding a simple type definition that defines the restrictions for these values. For example:
<xsd:complexType name="circle"> <xsd:attribute name="x" type="xsd:integer" use="required"/> <xsd:attribute name="y" type="xsd:integer" use="required"/> <xsd:attribute name="diameter" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:double"> <xsd:minExclusive value="1.0"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="color" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:string"> <xsd:enumeration value="red"/> <xsd:enumeration value="blue"/> <xsd:enumeration value="green"/> <xsd:enumeration value="yellow"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> </xsd:complexType>
The diameter and color attributes have facets that specify the values that are acceptable. The simpleType element that appears within the xsd:attribute elements specifies the constraints on the values for each attribute. You can also use the simpleType element with an xsd:element element definition to constrain the content for an element in a similar way. The xsd:restriction element defines the constraints, and you have a considerable range of options for specifying them, many more than I can possibly explain here. The base attribute in the xsd:restriction element defines the type for the value that is being restricted, and this attribute specification is required.
I’ve used an xsd:minExclusive specification to define an exclusive lower limit for values of the diameter attribute, and this specifies that the value must be greater than "1.0." Alternatively, you might prefer to use xsd:minInclusive with a value of "2.0" to set a sensible minimum value for the diameter. You also have the option of specifying an upper limit on numerical values by specifying either maxInclusive or maxExclusive values. For the color attribute definition, I’ve introduced a restriction that the value must be one of a fixed set of values. Each value that is allowed is specified in an xsd:enumeration element, and there can be any number of these. Obviously, this doesn’t just apply to strings; you can restrict the values for numeric types to be one of an enumerated set of values. For the color attribute the value must be one of the four string values specified.
Defining Groups of Attributes
Sometimes several different elements have the same set of attributes. To avoid having to repeat the definitions for the elements in such a set for each element that requires them, you can define an attribute group. Here’s an example of a definition for an attribute group:
<xsd:attributeGroup name="coords">
<xsd:attribute name="x" type="xsd:integer" use="required"/>
<xsd:attribute name="y" type="xsd:integer" use="required"/>
</xsd:attributeGroup>
This defines a group of two attributes with names x and y that specify x and y coordinates for a point. The name of this attribute group is coords. In general, an attribute group can contain other attribute groups. You could use the coords attribute group within a complex type definition like this:
<xsd:complexType name="PointType">
<xsd:attributeGroup ref="coords"/>
</xsd:complexType>
This defines the element type PointType as having the attributes that are defined in the coords attribute group. The ref attribute in the xsd:attributeGroup element specifies that this is a reference to a named attribute group. You can now use the PointType element type to define elements. For example:
<xsd:element name="position" type="PointType"/>
This declares a <point/> element to be of type PointType, and thus have the required attributes x and y.
Specifying a Group of Element Choices
The xsd:choice element in the Schema Definition language enables you to specify that one out of a given set of elements included in the choice definition must be present. This is useful in specifying a schema for Sketcher documents because the content is essentially variable — it can be any sequence of any of the basic types of elements. Suppose that you have already defined types for the geometric and text elements that can occur in a sketch. You could use an xsd:choice element in the definition of a complex type for a <sketch/> element:
<xsd:complexType name="SketchType">
<xsd:choice minOccurs="0" maxOccurs="unbounded">
<xsd:element name="line" type="LineType"/>
<xsd:element name="rectangle" type="RectangleType"/>
<xsd:element name="circle" type="CircleType"/>
<xsd:element name="curve" type="CurveType"/>
<xsd:element name="text" type="TextType"/>
</xsd:choice>
</xsd:complexType>
This defines that an element of type SketchType contains zero or more elements that are each one of the five types identified in the xsd:choice element. Thus, each element can be any of the types LineType, RectangleType, CircleType, CurveType, or TextType, which are types for the primitive elements in a sketch that are defined elsewhere in the schema. Given this definition for SketchType, you can declare the content for a sketch to be the following:
<xsd:element name="sketch" type="SketchType"/>
This declares the contents of an XML document for a sketch to be a <sketch/> element that has zero or more elements of any of the types that appeared in the preceding xsd:choice element. This is exactly what is required to accommodate any sketch, so this single declaration defines the entire contents of all possible sketches. All you need is to fill in a few details for the element types. I think you know enough about XML Schema to put together a schema for Sketcher documents.
As I noted when I discussed a DTD for Sketcher, an XML document that defines a sketch can have a very simple structure. Essentially, it can consist of a <sketch/> element that contains a sequence of zero or more elements that define lines, rectangles, circles, curves, or text. These child elements may be in any sequence, and there can be any number of them. To accommodate the fact that any given child element must be one of five types of elements, you could use some of the XML fragments from earlier sections to make an initial stab at an outline of a Sketcher schema like this:
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<!--The entire document content -->
<xsd:element name="sketch" type="SketchType"/>
<!--Type for a sketch root element -->
<xsd:complexType name="SketchType">
<xsd:choice minOccurs="0" maxOccurs="unbounded">
<xsd:element name="line" type="LineType"/>
<xsd:element name="rectangle" type="RectangleType"/>
<xsd:element name="circle" type="CircleType"/>
<xsd:element name="curve" type="CurveType"/>
<xsd:element name="text" type="TextType"/>
</xsd:choice>
</xsd:complexType>
<!--Other definitions that are needed... -->
</xsd:schema>
This document references the XML Schema language namespace, so it’s evidently a definition of a schema. The documents that this schema defines have no namespace specified, so elements on documents conforming to this schema do not need to be qualified. The entire content of a Sketcher document is declared to be an element with the name sketch that is of type SketchType. The <sketch/> element is the root element, and because it can have child elements, it must be defined as a complex type. The child elements within a <sketch/> element are the elements specified by the xsd:choice element, which represents a selection of one of the five complex elements that can occur in a sketch. The minOccurs and maxOccurs attribute values for the xsd:choice element determines that there may be any number of such elements, including zero. Thus, this definition accommodates XML documents describing any Sketcher sketch. All you now need to do is fill in the definitions for the possible varieties of child elements.
Defining Line Elements
Let’s define the same XML elements in the schema for Sketcher as the DTD for Sketcher defines. On that basis, a line element has four child elements specifying the color, position, and end point for a line, plus an attribute that specifies the rotation angle. You could define the type for a <line/> element in the schema like this:
<!--Type for a sketch line element -->
<xsd:complexType name="LineType">
<xsd:sequence>
<xsd:element name="color" type="ColorType"/>
<xsd:element name="position" type="PointType"/>
<xsd:element name="bounds" type="BoundsType"/>
<xsd:element name="endpoint" type="PointType"/>
</xsd:sequence>
<xsd:attribute name="angle" type="xsd:double" use="required"/>
</xsd:complexType>
This defines the type for a <line/> element in a sketch. An element of type LineType contains four child elements, <color/>, <position/>, <bounds/>, and <endpoint/>. These are enclosed within a <sequence/> schema definition element, so they must all be present and must appear in a sketch document in the sequence in which they are specified here. The element type definition also specifies an attribute with the name angle that must be included in any element of type LineType.
Of course, you now must define the types that you have used in the definition of the complex type, LineType: the ColorType, PointType, and BoundsType element types.
Defining a Type for Color Elements
As I discussed in the context of the DTD for Sketcher, the data for a <color/> element is supplied by three attributes that specify the RGB values for the color. You can therefore define the element type like this:
<!--Type for a sketch element color -->
<xsd:complexType name="ColorType">
<xsd:attribute name="R" type="xsd:nonNegativeInteger" use="required"/>
<xsd:attribute name="G" type="xsd:nonNegativeInteger" use="required"/>
<xsd:attribute name="B" type="xsd:nonNegativeInteger" use="required"/>
</xsd:complexType>
This is a relatively simple complex type definition. There are just the three attributes — R, G, and B — that all have integer values that can be 0 or greater, and are all mandatory.
You could improve this. As well as being non-negative integers, the color component values must be between 0 and 255. You could express this by adding facets for the color attributes, as follows:
<!--Type for a sketch element color -->
<xsd:complexType name="ColorType">
<xsd:attribute name="R" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:nonNegativeInteger">
<xsd:maxInclusive value="255"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="G" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:nonNegativeInteger">
<xsd:maxInclusive value="255"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="B" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:nonNegativeInteger">
<xsd:maxInclusive value="255"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:complexType>
Now, only values from 0 to 255 are acceptable for the color components.
Defining a Type for Point Elements
You saw a definition for the PointType element type earlier:
<!--Type for elements representing points -->
<xsd:complexType name="PointType">
<xsd:attributeGroup ref="coords"/>
</xsd:complexType>
This references the attribute group with the name coords, so this must be defined elsewhere in the schema. You’ve also seen this attribute group definition before:
<!--Attribute group for an x,y integer coordinate pair -->
<xsd:attributeGroup name="coords">
<xsd:attribute name="x" type="xsd:integer" use="required"/>
<xsd:attribute name="y" type="xsd:integer" use="required"/>
</xsd:attributeGroup>
You are able to use this attribute group in the definitions for other element types in the schema. The definition of this attribute group must appear at the top level in the schema, within the root element; otherwise, it is not possible to refer to it from within an element declaration.
Defining a Type for Bounds Elements
The BoundsType corresponds to the bounding rectangle for an element. You need to specify the coordinates of the top-left corner and its width and height:
<!--Type for a bounding rectangle for a sketch element -->
<xsd:complexType name="BoundsType">
<xsd:attributeGroup ref="coords"/>
<xsd:attribute name="width" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:nonNegativeInteger">
<xsd:minExclusive value="2"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="height" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:nonNegativeInteger">
<xsd:minExclusive value="2"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:complexType>
The width and height are identified and are both restricted to be non-negative integers with a minimum value of 2.
Defining a Rectangle Element Type
The definition of the type for a <rectangle/> element is somewhat similar to the LineType definition:
<!--Type for a sketch rectangle element -->
<xsd:complexType name="RectangleType">
<xsd:sequence>
<xsd:element name="color" type="ColorType"/>
<xsd:element name="position" type="PointType"/>
<xsd:element name="bounds" type="BoundsType"/>
</xsd:sequence>
<xsd:attribute name="width" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:double">
<xsd:minInclusive value="2.0"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="height" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:double">
<xsd:minInclusive value="2.0"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:complexType>
This references the schema element types ColorType, PointType, and BoundsType, and all of these have already been defined. The definition for the width and height attributes are slightly different from the <bounds/> element because they are floating-point values. This is because they relate to a Rectangle2D.Double object whereas a bounding rectangle is a java.awt.Rectangle object with integer width and height values.
Defining a Circle Element Type
There’s nothing new in the definition of CircleType:
<!--Type for a sketch circle element -->
<xsd:complexType name="CircleType">
<xsd:sequence>
<xsd:element name="color" type="ColorType"/>
<xsd:element name="position" type="PointType"/>
<xsd:element name="bounds" type="BoundsType"/>
</xsd:sequence>
<xsd:attribute name="diameter" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:double">
<xsd:minExclusive value="2.0"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="angle" type="xsd:double" use="required"/>
</xsd:complexType>
The child elements appear within a sequence element, so their sequence is fixed. You have the diameter and angle for a circle specified by attributes that both have values of type double, and are both mandatory. The diameter is restricted to non-negative values with a minimum of 2.0.
Defining a Curve Element Type
A type for the curve element introduces something new because the number of child elements is variable. A curve is defined by the origin plus one or more points, so the type definition must allow for an unlimited number of child elements defining points. Here’s how you can accommodate that:
<!--Type for a sketch curve element -->
<xsd:complexType name="CurveType">
<xsd:sequence>
<xsd:element name="color" type="ColorType"/>
<xsd:element name="position" type="PointType"/>
<xsd:element name="bounds" type="BoundsType"/>
<xsd:element name="point" type="PathPointType" minOccurs="1"
maxOccurs="unbounded"/>
</xsd:sequence>
<xsd:attribute name="angle" type="xsd:double" use="required"/>
</xsd:complexType>
The flexibility in the number of point elements is specified through the minOccurs and maxOccurs attribute values. The value of 1 for minOccurs ensures that there is always at least one, and the unbounded value for maxOccurs allows an unlimited number of point elements to be present. These elements are going to be points with floating-point coordinates because that’s what you get from the GeneralPath object that defines a curve. You can define this element type like this:
<!--Type for elements representing points in a general path -->
<xsd:complexType name="PathPointType">
<xsd:attribute name="x" type="xsd:double" use="required"/>
<xsd:attribute name="y" type="xsd:double" use="required"/>
</xsd:complexType>
This is a straightforward complex element with attributes for the coordinate values, which are specified as type double.
Defining a Text Element Type
The type for <text/> elements is the odd one out, but it’s not difficult. It involves four child elements for the color, the position, the font, and the text itself, plus an attribute to specify the angle. The type definition is as follows:
<!--Type for a sketch text element -->
<xsd:complexType name="TextType">
<xsd:sequence>
<xsd:element name="color" type="ColorType"/>
<xsd:element name="position" type="PointType"/>
<xsd:element name="bounds" type="BoundsType"/>
<xsd:element name="font" type="FontType"/>
<xsd:element name="string" type="xsd:string"/>
</xsd:sequence>
<xsd:attribute name="angle" type="xsd:double" use="required"/>
<xsd:attribute name="maxascent" type="xsd:integer" use="required"/>
</xsd:complexType>
The text string itself is a simple <string/> element, but the font is a complex element that requires a type definition:
<!--Type for a font used by a sketch text element -->
<xsd:complexType name="FontType">
<xsd:attribute name="fontname" type="xsd:string" use="required"/>
<xsd:attribute name="fontstyle" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:enumeration value="plain"/>
<xsd:enumeration value="bold"/>
<xsd:enumeration value="italic"/>
<xsd:enumeration value="bold-italic"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:complexType>
The style attribute for the <font/> element can be only one of four fixed values. You impose this constraint by defining an enumeration of the four possible string values within a simpleType definition for the attribute value. The xsd:simpleType definition is implicitly associated with the style attribute value because the type definition is a child of the xsd:attribute element.
The Complete Sketcher Schema
If you assemble all the fragments into a single file, you have the following definition for the Sketcher schema that defines XML documents containing a sketch:
<?xml version="1.0" encoding="UTF-8"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <xsd:element name="sketch" type="SketchType"/> <!--Type for a sketch root element --> <xsd:complexType name="SketchType"> <xsd:choice minOccurs="0" maxOccurs="unbounded"> <xsd:element name="line" type="LineType"/> <xsd:element name="rectangle" type="RectangleType"/> <xsd:element name="circle" type="CircleType"/> <xsd:element name="curve" type="CurveType"/> <xsd:element name="text" type="TextType"/> </xsd:choice> </xsd:complexType> <!--Type for a color element --> <xsd:complexType name="ColorType"> <xsd:attribute name="R" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:nonNegativeInteger"> <xsd:maxInclusive value="255"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="G" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:nonNegativeInteger"> <xsd:maxInclusive value="255"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="B" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:nonNegativeInteger"> <xsd:maxInclusive value="255"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> </xsd:complexType> <!--Type for a bounding rectangle for a sketch element --> <xsd:complexType name="BoundsType"> <xsd:attributeGroup ref="coords"/> <xsd:attribute name="width" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:nonNegativeInteger"> <xsd:minExclusive value="2"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="height" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:nonNegativeInteger"> <xsd:minExclusive value="2"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> </xsd:complexType> <!--Type for a sketch line element --> <xsd:complexType name="LineType"> <xsd:sequence> <xsd:element name="color"/> <xsd:element name="position"/> <xsd:element name="bounds"/> <xsd:element name="endpoint"/> </xsd:sequence> <xsd:attribute name="angle" type="xsd:double" use="required"/> </xsd:complexType> <!--Type for a sketch rectangle element --> <xsd:complexType name="RectangleType"> <xsd:sequence> <xsd:element name="color" type="ColorType"/> <xsd:element name="position" type="PointType"/> <xsd:element name="bounds" type="BoundsType"/> </xsd:sequence> <xsd:attribute name="width" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:double"> <xsd:minInclusive value="2.0"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="height" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:double"> <xsd:minInclusive value="2.0"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="angle" type="xsd:double" use="required"/> </xsd:complexType> <!--Type for a sketch circle element --> <xsd:complexType name="CircleType"> <xsd:sequence> <xsd:element name="color" type="ColorType"/> <xsd:element name="position" type="PointType"/> <xsd:element name="bounds" type="BoundsType"/> </xsd:sequence> <xsd:attribute name="diameter" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:double"> <xsd:minExclusive value="2.0"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="angle" type="xsd:double" use="required"/> </xsd:complexType> <!--Type for a sketch curve element --> <xsd:complexType name="CurveType"> <xsd:sequence> <xsd:element name="color" type="ColorType"/> <xsd:element name="position" type="PointType"/> <xsd:element name="bounds" type="BoundsType"/> <xsd:element name="point" type="PathPointType" minOccurs="1" maxOccurs="unbounded"/> </xsd:sequence> <xsd:attribute name="angle" type="xsd:double" use="required"/> </xsd:complexType> <!--Type for a sketch text element --> <xsd:complexType name="TextType"> <xsd:sequence> <xsd:element name="color" type="ColorType"/> <xsd:element name="position" type="PointType"/> <xsd:element name="bounds" type="BoundsType"/> <xsd:element name="font" type="FontType"/> <xsd:element name="string" type="xsd:string"/> </xsd:sequence> <xsd:attribute name="angle" type="xsd:double" use="required"/> <xsd:attribute name="maxascent" type="xsd:integer" use="required"/> </xsd:complexType> <!--Type for a font element --> <xsd:complexType name="FontType"> <xsd:attribute name="fontname" type="xsd:string" use="required"/> <xsd:attribute name="fontstyle" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:string"> <xsd:enumeration value="plain"/> <xsd:enumeration value="bold"/> <xsd:enumeration value="italic"/> <xsd:enumeration value="bold-italic"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> </xsd:complexType> <!--Type for elements representing points --> <xsd:complexType name="PointType"> <xsd:attributeGroup ref="coords"/> </xsd:complexType> <!--Type for elements representing points in a general path --> <xsd:complexType name="PathPointType"> <xsd:attribute name="x" type="xsd:double" use="required"/> <xsd:attribute name="y" type="xsd:double" use="required"/> </xsd:complexType> <!--Type for a color element --> <xsd:complexType name="ColorType"> <xsd:attribute name="R" type="xsd:nonNegativeInteger" use="required"/> <xsd:attribute name="G" type="xsd:nonNegativeInteger" use="required"/> <xsd:attribute name="B" type="xsd:nonNegativeInteger" use="required"/> </xsd:complexType> <!--Attribute group for an x,y integer coordinate pair --> <xsd:attributeGroup name="coords"> <xsd:attribute name="x" type="xsd:integer" use="required"/> <xsd:attribute name="y" type="xsd:integer" use="required"/> </xsd:attributeGroup> </xsd:schema>
This is somewhat longer than the DTD for Sketcher, but it does provide several advantages. All the data in the document now has types specified so the document is more precisely defined. This schema is XML, so the documents and the schema are defined in fundamentally the same way and are equally communicable. There is no problem combining one schema with another because namespaces are supported, and every schema can be easily extended. You can save this as a file Sketcher.xsd.
A Document That Uses a Schema
A document that has been defined in accordance with a particular schema is called an instance document for that schema. An instance document has to identify the schema to which it conforms, and this is done using attribute values within the root element of the document. Here’s an XML document for a sketch that identifies the location of the schema:
<sketch xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="file:/D:/Beg%20Java%20Stuff/Sketcher.xsd"> <!-- Elements defined for the sketch... --> </sketch>
The value for the xmlns attribute identifies the namespace name http://www.w3.org/2001/XMLSchema-instance and specifies xsi as the prefix used to represent this namespace name. In an instance document, the value for the noNamespaceSchemaLocation attribute in the xsi namespace is a hint about the location where the schema for the document can be found. Here the noNamespaceSchemaLocation value is a URI for a file on the local machine, and the spaces are escaped because this is required within a URI. The value you specify for the xsi:noNamespaceSchemaLocation attribute is always regarded as a hint, so in principle an application or parser processing this document is not obliged to take account of this. In practice, though, this usually is taken into account when the document is processed, unless there is good reason to ignore it.
You define a value for the noNamespaceSchemaLocation attribute because a sketch document has no namespace; if it had a namespace, you would define a value for the schemaLocation attribute that includes two URIs separated by whitespace within the value specification — the URI for the namespace and a URI that is a hint for the location of the namespace. Obviously, because one or more spaces separate the two URIs, the URIs cannot contain unescaped spaces.
PROGRAMMING WITH XML DOCUMENTS
Right at the beginning of this chapter I introduced the notion of an XML processor as a module that is used by an application to read XML documents. An XML processor parses a document and makes the elements, together with their attributes and content, available to the application, so it is also referred to as an XML parser. In case you haven’t met the term before, a parser is just a program module that breaks down text in a given language into its component parts. A natural language processor would have a parser that identifies the grammatical segments in each sentence. A compiler has a parser that identifies variables, constants, operators, and so on in a program statement. An application accesses the content of a document through an API provided by an XML parser and the parser does the job of figuring out what the document consists of.
Java supports two complementary APIs for processing an XML document that I’m introducing at a fairly basic level:
- SAX, which is the Simple API for XML parsing
- DOM, which is the Document Object Model for XML
The support in JDK 7 is for DOM level 3 and for SAX version 2.0.2. JDK 7 also supports XSLT 1.0, where XSL is the Extensible Stylesheet Language and T is Transformations — a language for transforming one XML document into another, or into some other textual representation such as HTML. However, I’m concentrating on the basic application of DOM and SAX in this chapter and the next, with a brief excursion into using XSLT in a very simple way in the context of DOM in Chapter 23.
Before I get into detail on these APIs, let’s look at the broad differences between SAX and DOM, and get an idea of the circumstances in which you might choose to use one rather than the other.
NOTE Java also supports a streaming API for XML processing capability that is called StAX. This provides more control of the parsing process than you get with SAX and DOM and requires a lot less memory than DOM. StAX is particularly useful when you are processing XML with limited memory available.
SAX Processing
SAX uses an event-based process for reading an XML document that is implemented through a callback mechanism. This is very similar to the way in which you handle GUI events in Java. As the parser reads a document, each parsing event, such as recognizing the start or end of an element, results in a call to a particular method associated with that event. Such a method is often referred to as a handler. It is up to you to implement these methods to respond appropriately to the event. Each of your methods then has the opportunity to react to the event, which results in it being called in any way that you want. In Figure 22-4 you can see the events that would arise from the XML shown.

Each type of event results in a different method in your program being called. There are, for example, different events for registering the beginning and end of a document. You can also see that the start and end of each element results in two further kinds of events, and another type of event occurs for each segment of document data. Thus, this particular document involves five different methods in your program being called — some of them more than once, of course, so there is one method for each type of event.
Because of the way SAX works, your application inevitably receives the document a piece at a time, with no representation of the whole document. This means that if you need to have the whole document available to your program with its elements and content properly structured, you have to assemble it yourself from the information supplied piecemeal to your callback methods.
Of course, it also means that you don’t have to keep the entire document in memory if you don’t need it, so if you are just looking for particular information from a document — all <phonenumber> elements, for example — you can just save those as you receive them through the callback mechanism, and you can discard the rest. As a consequence, SAX is a particularly fast and memory-efficient way of selectively processing the contents of an XML document.
First of all, SAX itself is not an XML document parser; it is a public domain definition of an interface to an XML parser, where the parser is an external program. The public domain part of the SAX API is in three packages that are shipped as part of the JDK:
- org.xml.sax: This defines the Java interfaces specifying the SAX API and the InputSource class that encapsulates a source of an XML document to be parsed.
- org.xml.sax.helpers: This defines a number of helper classes for interfacing to a SAX parser.
- org.xml.sax.ext: This defines interfaces representing optional extensions to SAX2 to obtain information about a DTD, or to obtain information about comments and CDATA sections in a document.
In addition to these, the javax.xml.parsers package provides factory classes that you use to gain access to a parser.
In Java terms there are several interfaces involved. The XMLReader interface specifies the methods that the SAX parser calls as it recognizes elements, attributes, and other components of an XML document. You must provide a class that implements these methods and responds to the method calls in the way that you want.
DOM Processing
DOM works quite differently from SAX. When an XML document is parsed, the whole XML tree is assembled in memory and returned to your application encapsulated in an object of type org.w3c.dom.Document, as Figure 22-5 illustrates.
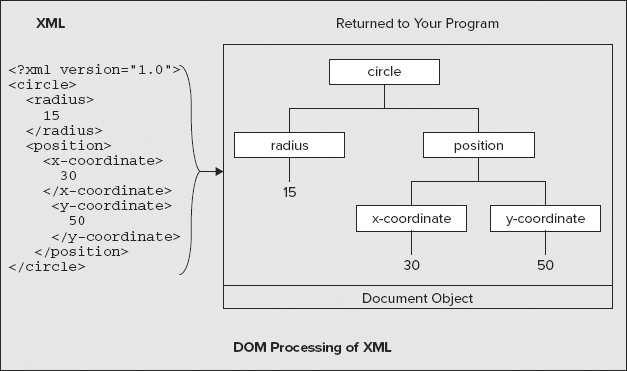
After you have the Document object available, you can call the Document object’s methods to navigate through the elements in the document tree starting with the root element. With DOM, the entire document is available for you to process as often and in as many ways as you want. This is a major advantage over SAX processing. The downside to this is the amount of memory occupied by the document — there is no choice, you get it all, no matter how big it is. With some documents the amount of memory required may be prohibitively large.
DOM has one other unique advantage over SAX. It enables you to modify existing documents and create new ones. If you want to create an XML document programmatically and then transfer it to an external destination, such as a file or another computer, DOM is a better API for this than SAX because SAX has no direct provision for creating or modifying XML documents. I’ll discuss how you can use a DOM parser in the next chapter.
NOTE StAX also has the capability for creating XML documents.
The javax.xml.parsers package defines four classes supporting the processing of XML documents:
- SAXParserFactory: Enables you to create a configurable factory object that you can use to create a SAXParser object.
- SAXParser: Defines an object that wraps a SAX-based parser.
- DocumentBuilderFactory: Enables you to create a configurable factory object that you can use to create a DocumentBuilder object encapsulating a DOM-based parser.
- DocumentBuilder: Defines an object that wraps a DOM-based parser.
All four classes are abstract. This is because JAXP is designed to allow different parsers and their factory classes to be plugged in. Both DOM and SAX parsers are developed independently of the Java JDK, so it is important to be able to integrate new parsers as they come along. The Xerces parser that is currently distributed with the JDK is controlled and developed by the Apache Project, and it provides a very comprehensive range of capabilities. However, you may want to take advantage of the features provided by other parsers from other organizations, and JAXP allows for that.
These abstract classes act as wrappers for the specific factory and parser objects that you need to use for a particular parser and insulate your code from a particular parser implementation. An instance of a factory object that can create an instance of a parser is created at runtime, so your program can use a different parser without changing or even recompiling your code. Now that you have a rough idea of the general principles, let’s get down to specifics and practicalities, starting with SAX.
To process an XML document with SAX, you first have to establish contact with the parser that you want to use. The first step toward this is to create a SAXParserFactory object like this:
SAXParserFactory spf = SAXParserFactory.newInstance();
The SAXParserFactory class is defined in the javax.xml.parsers package along with the SAXParser class that encapsulates a parser. The SAXParserFactory class is abstract, but the static newInstance() method returns a reference to an object of a class type that is a concrete implementation of SAXParserFactory. This is the factory object for creating an object encapsulating a SAX parser.
Before you create a parser object, you can condition the capabilities of the parser object that the SAXParserFactory object creates. For example, the SAXParserFactory object has methods for determining whether the parser that it attempts to create is namespace-aware or validates the XML as it is parsed. The isNamespaceAware() method returns true if the parser it creates is namespace-aware and returns false otherwise. The isValidating() method returns true if the parser it creates validates the XML during parsing and returns false otherwise.
You can set the factory object to produce namespace-aware parsers by calling its setNamespaceAware() method with an argument value of true. An argument value of false sets the factory object to produce parsers that are not namespace-aware. A parser that is namespace-aware can recognize the structure of names in a namespace — with a colon separating the namespace prefix from the name. A namespace-aware parser can report the URI and local name separately for each element and attribute. A parser that is not namespace-aware reports only an element or attribute name as a single name, even when it contains a colon. In other words, a parser that is not namespace-aware treats a colon as just another character that is part of a name.
Similarly, calling the setValidating() method with an argument value of true causes the factory object to produce parsers that can validate the XML. A validating parser can verify that the document body has a DTD or a schema, and that the document content is consistent with the DTD or schema identified within the document.
You can now use the SAXParserFactory object to create a SAXParser object as follows:
SAXParser parser = null;
try {
parser = spf.newSAXParser();
}catch(SAXException | ParserConfigurationException e){
e.printStackTrace();
System.exit(1);
}
The SAXParser object that you create here encapsulates the parser supplied with the JDK. The newSAXParser() method for the factory object can throw the two exceptions you are catching here. A ParserConfigurationException is thrown if a parser cannot be created consistent with the configuration determined by the SAXParserFactory object, and a SAXException is thrown if any other error occurs. For example, if you call the setValidating() option and the parser does not have the capability for validating documents, SAXException will be thrown. This should not arise with the parser supplied with the JDK, though, because it supports both of these features.
The ParserConfigurationException class is defined in the javax.xml.parsers package and the SAXException class is in the org.xml.sax package. Now let’s see what the default parser is by putting together the code fragments you have looked at so far.
TRY IT OUT: Accessing a SAX Parser
Here’s the code to create a SAXParser object and output some details about it to the command line:
import javax.xml.parsers.*;
import org.xml.sax.SAXException;
public class TrySAX {
public static void main(String args[]) {
// Create factory object
SAXParserFactory spf = SAXParserFactory.newInstance();
System.out.println(
"Parser will " + (spf.isNamespaceAware() ? "" : "not ") + "be namespace aware");
System.out.println(
"Parser will " + (spf.isValidating() ? "" : "not ") + "validate XML");
SAXParser parser = null; // Stores parser reference
try {
parser = spf.newSAXParser(); // Create parser object
}catch(SAXException | ParserConfigurationException e){
e.printStackTrace();
System.exit(1);
}
System.out.println("Parser object is: " + parser);
}
}
TrySAX.java
When I ran this I got the following output:
Parser will not be namespace aware Parser will not validate XML Parser object is: com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl@4c71d2
How It Works
The output shows that the default configuration for the SAX parser produced by the SAXParserFactory object spf is neither namespace-aware nor validating. The parser supplied with the JDK is the Xerces parser from the XML Apache Project. This parser implements the W3C standard for XML, the de facto SAX2 standard, and the W3C DOM standard. It also provides support for the W3C standard for XML Schema. You can find detailed information on the advantages of this particular parser on the http://xml.apache.org website.
The code to create the parser works as I have already discussed. After you have an instance of the factory method, you use that to create an object encapsulating the parser. Although the reference is returned as type SAXParser, the object is of type SAXParserImpl, which is a concrete implementation of the abstract SAXParser class for a particular parser.
The Xerces parser is capable of validating XML and can be namespace-aware. All you need to do is specify which of these options you require by calling the appropriate method for the factory object. You can set the parser configuration for the factory object spf so that you get a validating and namespace-aware parser by adding two lines to the program:
// Create factory object
SAXParserFactory spf = SAXParserFactory.newInstance();
spf.setNamespaceAware(true);
spf.setValidating(true);
If you compile and run the code again, you should get output something like the following:
Parser will be namespace aware
Parser will validate XML
Parser object is: com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl@18e18a3
You arrive at a SAXParser instance without tripping any exceptions, and you clearly now have a namespace-aware and validating parser. By default the Xerces parser validates an XML document with a DTD. To get it to validate a document with an XML Schema, you need to set another option for the parser, as I discuss in the next section.
Parser Features and Properties
Specific parsers, such as the Xerces parser that you get with the JDK, define their own features and properties that control and report on the processing of XML documents. A feature is an option in processing XML that is either on or off, so a feature is set as a boolean value, either true or false. A property is a parameter that you set to a particular object value, usually of type String. There are standard SAX2 features and properties that may be common to several parsers, and non-standard features and properties that are parser-specific. Note that although a feature or property may be standard for SAX2, this does not mean that a SAX2 parser necessarily supports it.
Querying and Setting Parser Features
Namespace awareness and validating capability are both features of a parser, and you already know how you tell the parser factory object that you want a parser with these features turned on. In general, each parser feature is identified by a name that is a fully qualified URI, and the standard features for SAX2 parsing have names within the namespace http://xml.org/sax/features/. For example, the feature specifying namespace awareness has the name http://xml.org/sax/features/namespaces. Here are a few of the standard features that are defined for SAX2 parsers:
- namespaces: When true, the parser replaces prefixes to element and attribute names with the corresponding namespace URIs. If you set this feature to true, the document must have a schema that supports the use of namespaces. All SAX parsers must support this feature.
- namespace-prefixes: When true, the parser reports the original prefixed names and attributes used for namespace declarations. The default value is false. All SAX parsers must support this feature.
- validation: When true, the parser validates the document and reports any errors. The default value is false.
- external-general-entities: When true, the parser includes general entities.
- string-interning: When true, all element and attribute names, namespace URIs, and local names use Java string interning so each of these corresponds to a unique object. This feature is always true for the Xerces parser.
- external-parameter-entities: When true, the parser includes external parameter entities and the external DTD subset.
- lexical-handler/parameter-entities: When true, the beginning and end of parameter entities will be reported.
You can find a more comprehensive list in the description for the org.xml.sax package that is in the JDK documentation. There are other non-standard features for the Xerces parser. Consult the documentation for the parser on the Apache website for more details. Apart from the namespaces and namespaces-prefixes features that all SAX2 parsers are required to implement, there is no set collection of features for a SAX2 parser, so a parser may implement any number of arbitrary features that may or may not be in the list of standard features.
You have two ways to query and set features for a parser. You can call the getFeature() and setFeature() methods for the SAXParserFactory object to do this before you create the SAXParser object. The parser that is created then has the features switched on. Alternatively, you can create a SAXParser object using the factory object and then obtain an org.sax.XMLReader object reference from it by calling the getXMLReader() method. You can then call the getFeature() and setFeature() methods for the XMLReader object. XMLReader is the interface that a concrete SAX2 parser implements to allow features and properties to be set and queried. The principle difference in use between calling the factory object methods and calling the XMLReader object methods is that the methods for a SAXParserFactory object can throw an exception of type javax.xml.parsers.ParserConfigurationException if a parser cannot be created with the feature specified.
After you have created an XMLParser object, you can obtain an XMLReader object reference from the parser like this:
XMLReader reader = null;
try{
reader = parser.getXMLReader();
} catch(org.xml.sax.SAXException e) {
System.err.println(e.getMessage());
}
The getFeature() method that the XMLReader interface declares for querying a feature expects an argument of type String that identifies the feature you are querying. The method returns a boolean value that indicates the state of the feature. The setFeature() method expects two arguments; the first is of type String and identifies the feature you are setting, and the second is of type boolean and specifies the state to be set. The setFeature() method can throw exceptions of type org.xml.SAXNotRecognizedException if the feature is not found, or of type org.xml.sax.SAXNotSupportedException if the feature name was recognized but cannot be set to the boolean value you specify. Both exception types have SAXException as a base, so you can use this type to catch either of them. Here’s how you might set the features for the Xerces parser so that it supports namespace prefixes:
String nsPrefixesFeature = "http://xml.org/sax/features/namespace-prefixes";
XMLReader reader = null;
try{
reader = parser.getXMLReader();
reader.setFeature(nsPrefixesFeature, true);
} catch(org.xml.sax.SAXException e) {
System.err.println(e.getMessage());
}
This sets the feature to make the parser report the original prefixed element and attribute names.
If you want to use the SAXParserFactory object to set the features before you create the parser object, you could do it like this:
String nsPrefixesFeature = "http://xml.org/sax/features/namespace-prefixes";
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parser = null;
try {
spf.setFeature(nsPrefixesFeature, true);
parser = spf.newSAXParser();
System.out.println("Parser object is: "+ parser);
}
catch(SAXException | ParserConfigurationException e) {
e.printStackTrace();
System.exit(1);
}
You must call the setFeature() method for the SAXParserFactory object in a try block because of the exceptions it may throw.
Setting Parser Properties
As I said at the outset, a property is a parser parameter with a value that is an object, usually a String object. Some properties have values that you set to influence the parser’s operation, but the values for other properties are set by the parser for you to retrieve to provide information about the parsing process.
You can set the properties for a parser by calling the setProperty() method for the SAXParser object after you have created it. The first argument to the method is the name of the property as type String, and the second argument is the value for the property. A property value can be of any class type, as the parameter type is Object, but it is usually of type String. The setProperty() method throws a SAXNotRecognizedException if the property name is not recognized or a SAXNotSupportedException if the property name is recognized but not supported. Both of these exception classes are defined in the org.xml.sax package. Alternatively, you can get and set properties using the XMLReader object reference that you used to set features. The XMLReader interface declares the getProperty() and setProperty() methods with the same signatures as those for the SAXParser object.
You can also retrieve the values for some properties during parsing to obtain additional information about the most recent parsing event. You use the parser’s getProperty() method in this case. The argument to the method is the name of the property, and the method returns a reference to the property’s value.
As with features, there is no defined set of parser properties, so you need to consult the parser documentation for information on these. There are four standard properties for a SAX parser, none of which are required to be supported by a SAX parser. Because these properties involve the more advanced features of SAX parser operation, they are beyond the scope of this book, but if you are interested, they are documented in the description for the org.xml.sax package that you can find in the JDK documentation.
Parsing Documents with SAX
To parse a document using the SAXParser object you simply call its parse() method. You have to supply two arguments: the first identifies the XML document, and the second is a reference of type org.xml.sax.helpers.DefaultHandler to a handler object that you have created to process the contents of the document. The DefaultHandler object must contain a specific set of public methods that the SAXParser object expects to be able to call for each event, where each type of event corresponds to a particular syntactic element it finds in the document.
The DefaultHandler class already contains do-nothing definitions for subsets of all the callback methods that a SAXParser object supporting SAX2.0 expects to be able to call. Thus, all you have to do is define a class that extends the DefaultHandler class and override the methods in the base class for the events that you are interested in. There is the org.xml.sax.ext.DefaultHandler2 class that extends the DefaultHandler class. This adds methods to support extensions to SAX2, but I won’t be going into these.
Let’s not gallop too far ahead, though. You need to look into the versions of the parse() method that you have available before you can get into handling parsing events. The SAXParser class defines ten overloaded versions of the parse() method, but you are interested in only five of them. The other five use a deprecated handler type HandlerBase that was applicable to SAX1, so you can ignore those and just look at the versions that relate to SAX2. All versions of the method have a return type of void, and the five varieties of the parse() method that you consider are as follows:
- parse(File file, DefaultHandler handler): Parses the document in the file specified by file using handler as the object containing the callback methods called by the parser. This throws an IOException if an I/O error occurs and an IllegalArgumentException if file is null.
- parse(String uri, DefaultHandler dh): Parses the document specified by uri using dh as the object defining the callback methods. This throws an exception of type SAXException if uri is null, and an exception of type IOException if an I/O error occurs.
- parse(InputStream in, DefaultHandler dh): Parses in as the source of the XML with dh as the event handler. This throws an IOException if an I/O error occurs and an IllegalArgumentException if input is null.
- parse(InputStream in, DefaultHandler dh, String systemID): Parses input as the previous method, but uses systemID to resolve any relative URIs.
- parse(InputSource srce, DefaultHandler dh): Parses the document specified by srce using dh as the object providing the callback methods to be called by the parser.
The InputSource class is defined in the org.xml.sax package. It defines an object that wraps a variety of sources for an XML document that you can use to pass a document reference to a parser. You can create an InputSource object from a java.io.InputStream object, a java.io.Reader object encapsulating a character stream, or a String specifying a URI — either a public name or a URL. If you specify the document source as a URL, it must be fully qualified.
Implementing a SAX Handler
As I said, the DefaultHandler class in the org.xml.sax.helpers package provides a default do-nothing implementation of each of the callback methods a SAX parser may call. These methods are declared in four interfaces that are all implemented by the DefaultHandler class:
- The ContentHandler interface declares methods that are called to identify the content of a document to an application. You should usually implement all the methods defined in this interface in your subclass of DefaultHandler.
- The EntityResolver interface declares one method, resolveEntity(), that is called by a parser to pass a public and/or system ID to your application to allow external entities in the document to be resolved.
- The DTDHandler interface declares two methods that are called to notify your application of DTD-related events.
- The ErrorHandler interface defines three methods that are called when the parser has identified an error of some kind in the document.
All four interfaces are defined in the org.xml.sax package. Of course, the parse() method for the SAXParser object expects you to supply a reference of type DefaultHandler as an argument, so you have no choice but to extend the DefaultHandler class in your handler class. This accommodates just about anything you want to do because you decide which base class methods you want to override.
The methods that you must implement to deal with parsing events that relate to document content are those declared by the ContentHandler interface, so let’s concentrate on those first:
- void startDocument(): Called when the start of a document is recognized.
- void endDocument(): Called when the end of a document is recognized.
- void startElement(String uri, String localName, String qName, Attributes attr): Called when the start of an element is recognized. Up to three names may be provided for the element:
- uri: The namespace URI for the element name. This is an empty string if there is no URI or if namespace processing is not being done.
- localName: The unqualified local name for the element. This is an empty string if namespace processing is not being done. In this case the element name is reported via the qName parameter.
- qName: The qualified name for the element. This is just the name if the parser is not namespace-aware. (A colon, if it appears, is then just an ordinary character.)
- attr: Encapsulates the attributes for the element that have explicit values.
- void endElement(String uri, String localName, String qName): Called when the end of an element is recognized. The parameters are as described for the startElement() method.
- void characters(char[] ch, int start, int length): Called for each segment of character data that is recognized. Note that a contiguous segment of text within an element can be returned as several chunks by the parser via several calls to this method. The characters that are available are from ch[start] to ch[start+length-1], and you must not try to access the array outside these limits.
- void ignorableWhitespace(char[] ch, int start, int length): Called for each segment of ignorable whitespace that is recognized within the content of an element. Note that a contiguous segment of ignorable whitespace within an element can be returned as several chunks by the parser via several calls to this method. The whitespace characters that are available are from ch[start] to ch[start+length-1], and you must not try to access the array outside these limits.
- void startPrefixMapping(String prefix, String uri): Called when the start of a prefix URI namespace mapping is identified. Most of the time you can disregard this method, as a parser automatically replaces prefixes for elements and attribute names by default.
- void endPrefixMapping(String prefix): Called when the end of a prefix URI namespace mapping is identified. Most of the time you can disregard this method for the reason noted in the preceding method.
- void processingInstruction(String target, String data): Called for each processing instruction that is recognized.
- void skippedEntity(String name): Called for each entity that the parser skips.
- void setDocumentLocator(Locator locator): Called by the parser to pass a Locator object to your code that you can use to determine the location in the document of any SAX document event. The Locator object can provide the public identifier, the system ID, the line number, and the column number in the document for any event. Just implement this method if you want to receive this information for each event.
Your implementations of these methods can throw an exception of type SAXException if an error occurs.
When the startElement() method is called, it receives a reference to an object of type org.xml.sax.Attributes as the last argument. This object encapsulates information about all the attributes for the element. The Attributes interface declares methods you can call for the object to obtain details of each attribute name, its type, and its value. These methods use either an index value to select a particular attribute or an attribute name — either a prefix qualified name or a name qualified by a namespace name. I just describe the methods relating to using an index because that’s what the code examples use. Index values start from 0. The methods that the Attributes interface declares for accessing attribute information using an index are as follows:
- int getLength(): Returns a count of the number of attributes encapsulated in the Attributes object.
- String getLocalName(int index): Returns a string containing the local name of the attribute for the index value passed as the argument.
- String getQName(int index): Returns a string containing the XML 1.0 qualified name of the attribute for the index value passed as the argument.
- String getType(int index): Returns a string containing the type of the attribute for the index value passed as the argument. The type is returned as one of the following:"CDATA", "ID", "IDREF", "IDREFS", "NMTOKEN", “NMTOKENS", "ENTITY", "ENTITIES", "NOTATION"
- String getValue(int index): Returns a string containing the value of the attribute for the index value passed as the argument.
- String getURI(int index): Returns a string containing the attribute’s namespace URI, or an empty string if no URI is available.
If the index value that you supply to any of these getXXX() methods here is out of range, then the method returns null.
Given a reference, attr, of type Attributes, you can retrieve information about all the attributes with the following code:
int attrCount = attr.getLength();
if(attrCount>0) {
System.out.println("Attributes:");
for(int i = 0 ; i < attrCount ; ++i ) {
System.out.println(" Name : " + attr.getQName(i));
System.out.println(" Type : " + attr.getType(i));
System.out.println(" Value: " + attr.getValue(i));
}
}
This is very straightforward. You look for data on attributes only if the value returned by the getLength() method is greater than zero. You then retrieve information about each attribute in the for loop.
The DefaultHandler class is just like the adapter classes you have used for defining GUI event handlers. To implement your own handler class you just extend the DefaultHandler class and define your own implementations for the methods that you are interested in. The same caveat applies here that applied with adapter classes — you must be sure that the signatures of your methods are correct. The best way to do this is to use the @Override annotation. Let’s try implementing a handler class.
TRY IT OUT: Handling Parsing Events
Let’s first define a handler class to deal with document parsing events. You just implement a few of the methods from the ContentHandler interface in this — only those that apply to a very simple document — and you don’t need to worry about errors for the moment. Here’s the code:
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.Attributes;
public class MySAXHandler extends DefaultHandler {
@Override
public void startDocument() {
System.out.println("Start document: ");
}
@Override
public void endDocument() {
System.out.println("End document");
}
@Override
public void startElement(String uri, String localName, String qname,
Attributes attr) {
System.out.println("Start element: local name: " + localName +
" qname: " + qname + " uri: " + uri);
int attrCount = attr.getLength();
if(attrCount > 0) {
System.out.println("Attributes:");
for(int i = 0 ; i < attrCount ; ++i ) {
System.out.println(" Name : " + attr.getQName(i));
System.out.println(" Type : " + attr.getType(i));
System.out.println(" Value: " + attr.getValue(i));
}
}
}
@Override
public void endElement(String uri, String localName, String qname) {
System.out.println("End element: local name: " + localName +
" qname: " + qname + " uri: " + uri);
}
@Override
public void characters(char[] ch, int start, int length) {
System.out.println("Characters: " + new String(ch, start, length));
}
@Override
public void ignorableWhitespace(char[] ch, int start, int length) {
System.out.println("Ignorable whitespace: " + length + " characters.");
}
}
Directory "TrySAXHandler 1"
Each handler method just outputs information about the event to the command line.
Now you can define a program to use a handler of this class type to parse an XML document. You can make the example read the name of the XML file to be processed from the command line. Here’s the code:
import javax.xml.parsers.*;
import org.xml.sax.SAXException;
import java.io.*;
public class TrySAXHandler {
public static void main(String args[]) {
if(args.length == 0) {
System.out.println("No file to process. Usage is:" +
"
java TrySax "filename" ");
return;
}
File xmlFile = new File(args[0]);
if(xmlFile.exists()) {
process(xmlFile);
} else {
System.out.println(xmlFile + " does not exist.");
}
}
private static void process(File file) {
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parser = null;
spf.setNamespaceAware(true);
spf.setValidating(true);
System.out.println("Parser will " +
(spf.isNamespaceAware() ? "" : "not ") + "be namespace aware");
System.out.println("Parser will " + (spf.isValidating() ? "" : "not ")
+ "validate XML");
try {
parser = spf.newSAXParser();
System.out.println("Parser object is: " + parser);
} catch(SAXException | ParserConfigurationException e) {
e.printStackTrace();
System.exit(1);
}
System.out.println("
Starting parsing of "+file+"
");
MySAXHandler handler = new MySAXHandler();
try {
parser.parse(file, handler);
} catch(IOException | SAXException e) {
e.printStackTrace();
}
}
}
Directory "TrySAXHandler 1"
I created the circle.xml file with the following content:
<?xml version="1.0"?>
<circle diameter="40" angle="0">
<color R="255" G="0" B="0"/>
<position x="10" y="15"/>
<bounds x="10" y="15"
width="42" height="42"/>
</circle>
Directory "TrySAXHandler 1"
I saved this in my Beg Java Stuff directory, but you can put it wherever you want and adjust the command-line argument accordingly.
On my computer the program produced the following output:
Parser will be namespace aware
Parser will validate XML
Parser object is: com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl@159d510
Starting parsing of D:Beg Java Stuffcircle.xml
Start document:
Start element: local name: circle qname: circle uri:
Attributes:
Name : diameter
Type : CDATA
Value: 40
Name : angle
Type : CDATA
Value: 0
Characters:
Length: 3
Start element: local name: color qname: color uri:
Attributes:
Name : R
Type : CDATA
Value: 255
Name : G
Type : CDATA
Value: 0
Name : B
Type : CDATA
Value: 0
End element: local name: color qname: color uri:
Characters:
Length: 3
Start element: local name: position qname: position uri:
Attributes:
Name : x
Type : CDATA
Value: 10
Name : y
Type : CDATA
Value: 15
End element: local name: position qname: position uri:
Characters:
Length: 3
Start element: local name: bounds qname: bounds uri:
Attributes:
Name : x
Type : CDATA
Value: 10
Name : y
Type : CDATA
Value: 15
Name : width
Type : CDATA
Value: 42
Name : height
Type : CDATA
Value: 42
End element: local name: bounds qname: bounds uri:
Characters:
Length: 1
End element: local name: circle qname: circle uri:
End document
How It Works
Much of the code in the TrySAXHandler class is the same as in the previous example. The main() method first checks for a command-line argument. If there isn’t one, you output a message and end the program. The code following the creation of the java.io.File object calls exists() for the object to make sure the file does exist.
Next you call the static process() method with a reference to the File object for the XML document as the argument. This method creates the XMLParser object in the way you’ve seen previously and then creates a handler object of type MySAXHandler for use by the parser. The parsing process is started by calling the parse() method for the parser object, parser, with the file reference as the first argument and the handler reference as the second argument. This identifies the object whose methods are called for parsing events.
You have overridden six of the do-nothing methods that are inherited from DefaultHandler in the MySAXHandler class and the output indicates which ones are called. Your method implementations just output a message along with the information that is passed as arguments. You can see from the output that there is no URI for a namespace in the document, so the value for qname is identical to localname.
The output shows that the characters() method is called with just whitespace in the ch array. You could see how much whitespace by adding another output statement for the value of length. This whitespace is ignorable whitespace that appears between the elements, but the parser is not recognizing it as such. This is because there is no DTD to define how elements are to be constructed in this document, so the parser has no way to know what can be ignored.
You can see that the output shows string values for both a local name and a qname. This is because you have the namespace awareness feature switched on. If you comment out the statement that calls setNamespaceAware() and recompile and re-execute the example, you see that only a qname is reported. Both the local name and URI outputs are empty.
You get all the information about the attributes, too, so the processing of attributes works without a DTD or a schema.
Processing a Document with a DTD
You can run the example again with the Address.xml file that you saved earlier in the Beg Java Stuff directory to see how using a DTD affects processing. This should have the following contents:
<?xml version="1.0"?> <!DOCTYPE address SYSTEM "AddressDoc.dtd"> <address> <buildingnumber> 29 </buildingnumber> <street> South Lasalle Street</street> <city>Chicago</city> <state>Illinois</state> <zip>60603</zip> </address>
Directory "TrySAXHandler 1"
The AddressDoc.dtd file in the same directory as Address.xml should contain the following:
<!ELEMENT address (buildingnumber, street, city, state, zip)> <!ELEMENT buildingnumber (#PCDATA)> <!ELEMENT street (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT state (#PCDATA)> <!ELEMENT zip (#PCDATA)>
Directory "TrySAXHandler 1"
If the path to the file contains spaces, you need to specify the path between double quotes in the command-line argument. I got the following output:
Parser will be namespace aware Parser will validate XML Parser object is: com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl@2515 Starting parsing of D:Beg Java StuffAddress.xml Start document: Start element: local name: address qname: address uri: Ignorable whitespace: 3 characters. Start element: local name: buildingnumber qname: buildingnumber uri: Characters: 29 End element: local name: buildingnumber qname: buildingnumber uri: Ignorable whitespace: 3 characters. Start element: local name: street qname: street uri: Characters: South Lasalle Street End element: local name: street qname: street uri: Ignorable whitespace: 3 characters. Start element: local name: city qname: city uri: Characters: Chicago End element: local name: city qname: city uri: Ignorable whitespace: 3 characters. Start element: local name: state qname: state uri: Characters: Illinois End element: local name: state qname: state uri: Ignorable whitespace: 3 characters. Start element: local name: zip qname: zip uri: Characters: 60603 End element: local name: zip qname: zip uri: Ignorable whitespace: 1 characters. End element: local name: address qname: address uri: End document
You can see that with a DTD, the ignorable whitespace is recognized as such, and is passed to your ignorableWhitespace() method. A validating parser must call this method to report whitespace in element content. Although the parser is validating the XML, you still can’t be sure that the document is valid based on the output you are getting. If any errors are found, the default do-nothing error-handling methods that are inherited from the DefaultHandler class are called, so there’s no indication of when errors are found. You can fix this quite easily by modifying the MySAXHandler class, but let’s first look at processing some other XML document flavors.
Processing a Document with Namespaces
You can convert the Address.xml file to use a namespace by modifying the root element like this:
<address xmlns="http://www.wrox.com/AddressNamespace">
With this change to the XML file, the URI for the default namespace is http://www.wrox.com/AddressNamespace. This doesn’t really exist, but it doesn’t need to. It’s just a unique qualifier for the names within the namespace.
You also need to use a different DTD that takes into account the use of a namespace, so you must modify the DOCTYPE declaration in the document:
<!DOCTYPE address SYSTEM "AddressNamespaceDoc.dtd">
You can now save the revised XML document with the name AddressNamespace.xml.
You must also create the new DTD. This is the same as AddressDoc.dtd with the addition of a declaration for the xmlns attribute for the <address> element:
<!ATTLIST address xmlns CDATA #IMPLIED>
If you run the previous example with this version of the XML document, you should see the URI in the output. Because the namespace is the default, there is no prefix name, so the values for the localname and qname parameters to the startElement() and endElement() methods are the same.
Using Qualified Names
You can change the document to make explicit use of the namespace prefix like this:
<?xml version="1.0"?> <!DOCTYPE addresses:address SYSTEM "AddressNamespaceDoc.dtd"> <addresses:address xmlns:addresses=" http://www.wrox.com/AddressNamespace"> <addresses:buildingnumber> 29 </addresses:buildingnumber> <addresses:street> South Lasalle Street</addresses:street> <addresses:city>Chicago</addresses:city> <addresses:state>Illinois</addresses:state> <addresses:zip>60603</addresses:zip> </addresses:address>
Directory "TrySAXHandler 2 with extra callback methods"
I saved this as AddressNamespace1.xml. Unfortunately, you also have to update the DTD. Otherwise, if the qualified names are not declared in the DTD, they are regarded as errors. You need to change the DTD to the following:
<!ELEMENT addresses:address (addresses:buildingnumber, addresses:street, addresses:city, addresses:state, addresses:zip)> <!ATTLIST addresses:address xmlns:addresses CDATA #IMPLIED> <!ELEMENT addresses:buildingnumber (#PCDATA)> <!ELEMENT addresses:street (#PCDATA)> <!ELEMENT addresses:city (#PCDATA)> <!ELEMENT addresses:state (#PCDATA)> <!ELEMENT addresses:zip (#PCDATA)>
Directory "TrySAXHandler 2 with extra callback methods"
I saved this as AddressNamespaceDoc1.dtd. The namespace prefix is addresses, and each element name is qualified by the namespace prefix. You can usefully add implementations for two further callback methods in the MySAXHandler class:
@Override public void startPrefixMapping(String prefix, String uri) { System.out.println( "Start "" + prefix + "" namespace scope. URI: " + uri); } @Override public void endPrefixMapping(String prefix) { System.out.println("End "" + prefix + "" namespace scope."); }
Directory "TrySAXHandler 2 with extra callback methods"
The parser doesn’t call these methods by default. You have to switch the http://xml.org/sax/features/namespace-prefixes feature on to get this to happen. You can add a call to the setFeature() method for the parser factory object to do this in the process() method that you defined in the TrySAXHandler class, immediately before you create the parser object in the try block:
spf.setFeature("http://xml.org/sax/features/namespace-prefixes",true);
parser = spf.newSAXParser();
You place the statement here rather than after the call to the setValidating() method because the setFeature() method can throw an exception of type ParserConfigurationException and it needs to be in a try block. Now the parser calls the startPrefixMapping() method at the beginning of each namespace scope, and the endPrefixMapping() method at the end. If you parse this document, you see that each of the qname values is the local name qualified by the namespace prefix. You should also see that the start and end of the namespace scope are recorded in the output.
Handling Other Parsing Events
I have considered only events arising from the recognition of document content, those declared in the ContentHandler interface. In fact, the DefaultHandler class defines do-nothing methods declared in the other three interfaces that you saw earlier. For example, when a parsing error occurs, the parser calls a method to report the error. Three methods for error reporting are declared in the ErrorHandler interface and are implemented by the DefaultHandler class:
- void warning(SAXParseException spe): Called to notify conditions that are not errors or fatal errors. The exception object, spe, contains information to enable you to locate the error in the original document.
- void error(SAXParseException spe): Called when an error has been identified. An error is anything in a document that violates the XML specification but is recoverable and allows the parser to continue processing the document normally.
- void fatalError(SAXParseException spe): Called when a fatal error has been identified. A fatal error is a non-recoverable error. After a fatal error the parser does not continue normal processing of the document.
Each of these methods is declared to throw an exception of type SAXException, but you don’t have to implement them so that they do this. With the warning() and error() methods you probably want to output an error message and return to the parser so it can continue processing. Of course, if your fatalError() method is called, processing of the document does not continue anyway, so it would be appropriate to throw an exception in this case.
Obviously your implementation of any of these methods wants to make use of the information from the SAXParseException object that is passed to the method. This object has four methods that you can call to obtain additional information that help you locate the error:
- int getLineNumber(): Returns the line number of the end of the document text where the error occurred. If this is not available, –1 is returned.
- int getColumnNumber(): Returns the column number within the document that contains the end of the text where the error occurred. If this is not available, –1 is returned. The first column in a line is column 1.
- String getPublicID(): Returns the public identifier of the entity where the error occurred, or null if no public identifier is available.
- String getSystemID(): Returns the system identifier of the entity where the error occurred, or null if no system identifier is available.
A simple implementation of the warning() method could be like this:
@Override public void warning(SAXParseException spe) { System.out.println("Warning at line " + spe.getLineNumber()); System.out.println(spe.getMessage()); }
Directory "TrySAXHandler 3 with error reporting"
This outputs a message indicating the document line number where the error occurred. It also outputs the string returned by the getMessage() method inherited from the base class, SAXException. This usually indicates the nature of the error that was detected.
You could implement the error() callback method similarly, but you might want to implement fatalError() so that it throws an exception. For example:
@Override public void fatalError(SAXParseException spe) throws SAXException { System.out.println("Fatal error at line " + spe.getLineNumber()); System.out.println(spe.getMessage()); throw spe; }
Directory "TrySAXHandler 3 with error reporting"
Here you just rethrow the SAXParseException after outputting an error message indicating the line number that caused the error. The SAXParseException class is a subclass of SAXException, so you can rethrow spe as the superclass type. Don’t forget the import statements in the MySAXHandler source file for the SAXException and SAXParseException class names from the org.xml.sax package.
You could try these out with the previous example by adding them to the MySAXHandler class. You could introduce a few errors into the XML file to get these methods called. Try deleting the DOCTYPE declaration or deleting the forward slash on an element end tag, or even just deleting one character in an element name.
Parsing a Schema Instance Document
You can create a simple instance of a document that uses the Sketcher.xsd schema you developed earlier. Here’s the definition of the XML document contents:
<?xml version="1.0" encoding="UTF-8"?> <sketch xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="file:/D:/Beg%20Java%20Stuff/Sketcher.xsd"> <circle diameter="40" angle="0.0"> <color R="255" G="0" B="0"/> <position x="10" y="10"/> <bounds x="10" y="10" width="42" height="42"/> </circle> <line angle="0.0"> <color R="0" G="0" B="255"/> <position x="10" y="10"/> <bounds x="10" y="10" width="22" height="32"/> <endpoint x="30" y="40"/> </line> <rectangle width="30.0" height="20.0" angle="0.0"> <color R="255" G="0" B="0"/> <position x="30" y="40"/> <bounds x="30" y="40" width="32" height="22"/> </rectangle> </sketch>
Directory "TryParsingSchemaInstance"
This defines a sketch that consists of three elements: a circle, a line, and a rectangle. The location of the schema is specified by the value for the noNamespaceSchemaLocation attribute, which here corresponds to the Sketcher.xsd file in the Beg Java Stuff directory. You can save the document as sketch1.xml in the same directory.
An XML document may have the applicable schema identified by the value for the noNamespaceSchemaLocation attribute, or the schema may not be identified explicitly in the document. You have the means for dealing with both of these situations in Java.
A javax.xml.validation.Schema object encapsulates a schema. You create a Schema object by calling methods for a javax.xml.validation.SchemaFactory object that you generate by calling the static newInstance() method for the SchemaFactory class. It works like this:
SchemaFactory sf =
SchemaFactory.newInstance("http://www.w3.org/2001/XMLSchema");
A SchemaFactory object compiles a schema from an external source in a given Schema Definition Language into a Schema object that can subsequently be used by a parser. The argument to the static newInstance() method in the SchemaFactory class identifies the schema language that the schema factory can process. The only alternative to the argument used in the example to specify the XML Schema language is “http://relaxng.org/ns/structure/1.0,” which is another schema language for XML. At the time of writing, Schema objects encapsulating DTDs are not supported.
The javax.xml.XMLConstants class defines String constants for basic values required when you are processing XML. The class defines a constant with the name W3C_XML_NS_URI that corresponds to the URI for the Schema Definition Language, so you could use this as the argument to the newInstance() method in the SchemaFactory class, like this:
SchemaFactory sf = SchemaFactory.newInstance(W3C_XML_NS_URI);
This statement assumes you have statically imported the names from the XMLConstants class.
After you have identified the Schema Definition Language to be used, you can create a Schema object from a schema definition. Here’s an example of how you might do this:
File schemaFile = Paths.get(System.getProperty("user.home")).
resolve("Beginning Java Stuff").resolve("sketcher.xsd").toFile();
try {
Schema schema = sf.newSchema(schemaFile);
}catch(SAXException e) {
e.printStackTrace();
System.exit(1);
}
The newSchema() method for the SchemaFactory object creates and returns a Schema object from the file specified by the File object you pass as the argument. There are versions of the newSchema() method with parameters of type java.net.URL and java.xml.transform.Source. An object that implements the Source interface represents an XML source. There’s also a version of newSchema() that accepts an argument that is an array of Source object references and generates a Schema object from the input from all of the array elements.
Now that you have a Schema object, you can pass it to the SAXParserFactory object before you create your SAXParser object to process XML documents:
SAXParserFactory spf = SAXParserFactory.newInstance(); spf.setSchema(schema);
The parser you create by calling the newSAXParser() method for this SAXParserFactory object validates documents using the schema you have specified. XML documents are validated in this instance, even when the isValidating() method returns false, so it’s not essential that you configure the parser to validate documents.
In many situations the document itself identifies the schema to be used. In this case you call the newSchema() method for the SchemaFactory object with no argument specified:
try {
Schema schema = sf.newSchema();
}catch(SAXException e) {
e.printStackTrace();
System.exit(1);
}
A special Schema object is created by the newSchema() method that assumes the schema for the document is identified by hints within the document. Note that you still need to call newSchema() within a try block here because the method throws an exception of type SAXException if the operation fails for some reason. If the operation is not supported, an exception of type UnsupportedOperationException is thrown, but because this is a subclass of RuntimeException, you are not obliged to catch it.
TRY IT OUT: Parsing a Schema Instance Document
Here’s a variation on the TrySAXHandler class that parses a schema instance document:
import javax.xml.parsers.*;
import java.io.*;
import javax.xml.validation.SchemaFactory;
import org.xml.sax.SAXException;
import static javax.xml.XMLConstants.*;
public class TryParsingSchemaInstance {
public static void main(String args[]) {
if(args.length == 0) {
System.out.println("No file to process. Usage is:" +
"
java TrySax "xmlFilename" " +
"
or:
java TrySaxHandler "xmlFilename" "schemaFileName" ");
return;
}
File xmlFile = new File(args[0]);
File schemaFile = args.length > 1 ? new File(args[1]) : null;
process(xmlFile, schemaFile);
}
private static void process(File file, File schemaFile) {
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parser = null;
spf.setNamespaceAware(true);
try {
SchemaFactory sf = SchemaFactory.newInstance(W3C_XML_SCHEMA_NS_URI);
spf.setSchema(
schemaFile == null ? sf.newSchema() : sf.newSchema(schemaFile));
parser = spf.newSAXParser();
} catch(SAXException | ParserConfigurationException e) {
e.printStackTrace();
System.exit(1);
}
System.out.println("
Starting parsing of " + file + "
");
MySAXHandler handler = new MySAXHandler();
try {
parser.parse(file, handler);
} catch(IOException | SAXException e) {
e.printStackTrace();
}
}
}
Directory "TryParsingSchemaInstance"
You need to copy the MySAXHandler.java source file from the previous example to the folder you are using for this example. You have the option of supplying an additional command-line argument when you run the program. The first argument is the name of the XML file to be parsed, as in the TrySAXHandler example; the second argument is the path to the schema that is to be used to parse the file. When the second argument is present, the program processes the XML file using the specified schema. If the second argument is absent, the XML file is processed using the schema specified by hints in the document.
Processing the sketch1.xml file that I defined in the previous section resulted in the following output:
Starting parsing of D:Beg Java Stuffsketch1.xml
Start document:
Start "xsi" namespace scope. URI: http://www.w3.org/2001/XMLSchema-instance
Start element: local name: sketch qname: sketch uri:
Attributes:
Name : xsi:noNamespaceSchemaLocation
Type : CDATA
Value: file:/D:/Beg%20Java%20Stuff/Sketcher.xsd
Ignorable whitespace: 5 characters.
Start element: local name: circle qname: circle uri:
Attributes:
Name : diameter
Type : CDATA
Value: 40
Name : angle
Type : CDATA
Value: 0.0
Ignorable whitespace: 9 characters.
This is followed by a lot more output that ends:
Start element: local name: rectangle qname: rectangle uri:
Attributes:
Name : width
Type : CDATA
Value: 30.0
Name : height
Type : CDATA
Value: 20.0
Name : angle
Type : CDATA
Value: 0.0
Ignorable whitespace: 9 characters.
Start element: local name: color qname: color uri:
Attributes:
Name : R
Type : CDATA
Value: 255
Name : G
Type : CDATA
Value: 0
Name : B
Type : CDATA
Value: 0
End element: local name: color qname: color uri:
Ignorable whitespace: 9 characters.
Start element: local name: position qname: position uri:
Attributes:
Name : x
Type : CDATA
Value: 30
Name : y
Type : CDATA
Value: 40
End element: local name: position qname: position uri:
Ignorable whitespace: 9 characters.
Start element: local name: bounds qname: bounds uri:
Attributes:
Name : x
Type : CDATA
Value: 30
Name : y
Type : CDATA
Value: 40
Name : width
Type : CDATA
Value: 32
Name : height
Type : CDATA
Value: 22
End element: local name: bounds qname: bounds uri:
Ignorable whitespace: 5 characters.
End element: local name: rectangle qname: rectangle uri:
Ignorable whitespace: 1 characters.
End element: local name: sketch qname: sketch uri:
End "xsi" namespace scope.
End document
Of course, you can also try the example specifying the schema location by the second argument on the command line.
How It Works
The only significant difference from what you had in the previous example that processed a document with a DTD is the creation of the Schema object to identify the schema to be used. When you supply a second command-line argument, a File object encapsulating the schema file path is created and a reference to this is passed as the second argument to the process() method. The process() method uses the second argument that you pass to it to determine how to create the Schema object that is passed to the setSchema() method for the SAXParserFactory object:
SchemaFactory sf = SchemaFactory.newInstance(W3C_XML_SCHEMA_NS_URI);
spf.setSchema(schemaFile == null ? sf.newSchema() : sf.newSchema(schemaFile));
The argument to the newInstance() method is the constant from the XMLConstants class that defines the URI for the Schema Definition Language. There’s a static import statement for the static names in this class, so you don’t need to qualify the name of the constant. The Schema object is created either by passing the non-null File reference schemaFile to the newSchema() method or by calling the newSchema() method with no argument. In both cases the Schema object that is created is passed to the setSchema() method for the parser factory object. The parser that is subsequently created by the SAXParserFactory object uses the schema encapsulated by the Schema object to validate documents. In this way the program is able to process documents for which the schema is specified by hints in the document, as well as documents for which the schema is specified independently through the second command-line argument.
In this chapter I discussed the fundamental characteristics of XML and how Java supports the analysis and synthesis of XML documents. This is very much an introductory chapter on XML and only covers enough of the topic for you to understand the basic facilities that you have in Java for processing XML documents. In the next chapter you see how you can synthesize an XML document programmatically so you can write it to a file. You also find out how you can read an XML document and use it to reconstitute Java class objects.
EXERCISES
You can download the source code for the examples in the book and the solutions to the following exercises from www.wrox.com.
1. Write a program using SAX that counts the number of occurrences of each element type in an XML document and displays them. The document file to be processed should be identified by the first command-line argument.
2. Modify the program resulting from the previous exercise so that it accepts optional additional command-line arguments that are the names of elements. When there are two or more command-line arguments, the program should count and report only on the elements identified by the second and subsequent command-line arguments.

• WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | CONCEPT |
| XML | XML is a language for describing data that is to be communicated from one computer to another. Data is described in the form of text that contains the data, plus markup that defines the structure of the data. XML is also a meta-language because you can use XML to create new languages for defining and structuring data. |
| XML Document Structure | An XML document consists of a prolog and a document body. The document body contains the data and the prolog provides the information necessary for interpreting the document body. |
| Markup | Markup consists of XML elements that may also include attributes, where an attribute is a name-value pair. |
| Well-Formed XML | A well-formed XML document conforms to a strict set of rules for document definition, as defined by the XML language specification. |
| DTDs | The structure and meaning of a particular type of XML document can be defined within a Document Type Definition (DTD). A DTD can be defined in an external file or it can be part of a document. |
| Valid XML Documents | A valid XML document is a well-formed document that has a DTD. |
| DOCTYPE Declarations | A DTD is identified by a DOCTYPE declaration in a document. |
| XML Elements | XML markup divides the contents of a document into elements by enclosing segments of the data between tags. |
| Element Attributes | Attributes provide a way for you to embed additional data within an XML element. |
| CDATA Sections | A CDATA section in an XML document contains unparsed character data that is not analyzed by an XML processor. |
| Schemas | Using the Schema Definition language to define a schema for XML documents provides a more flexible alternative to DTDs. |
| The SAX API | The SAX API defines a simple event-driven mechanism for analyzing XML documents. |
| SAX Parsers | A SAX parser is a program that parses an XML document and identifies each element in a document by calling a particular method in your program. The methods that are called by a parser to identify elements are those defined by the SAX API. |
| SAX Parsing Events | You can create a class that has methods to handle SAX2 parsing events by extending the DefaultHandler class that defines do-nothing implementations of the methods. The DefaultHandler2 class extends DefaultHandler to provide methods for extensions to SAX2. |
| DOM Parsers | A DOM parser makes an entire XML document available encapsulated in an object of type Document. You can call methods for the Document object to extract the contents of the document. |
