
Chapter 8
Understanding Streams
WHAT YOU WILL LEARN IN THIS CHAPTER
- What a stream is and what the main classes that Java provides to support stream operations are
- What stream readers and writers are and what they are used for
- How to read data from the keyboard
- How to format data that you write to the command line
This is the first of five chapters devoted to input and output. This chapter introduces streams, and deals with keyboard input and output to the command line. In subsequent chapters you learn how to work with files.
STREAMS AND INPUT/OUTPUT OPERATIONS
Streams are fundamental to input and output in your programs in the most instances. The package that supports stream input/output primarily is java.io but other packages such as java.nio.file define stream classes, too. The java.io defines a large number of classes and interfaces, many of which have a significant number of methods. It is quite impractical to go into them all in detail in this book so my strategy in this and in the following chapters discussing file I/O is to take a practical approach. I provide an overall grounding in the concepts and equip you with enough detailed knowledge of the classes involved to enable you to do a number of specific, useful, and practical things in your programs. These are:
- To be able to read data from the keyboard
- To be able to write formatted output to a stream, such as System.out
- To be able to read and write files containing strings and basic types of data
- To be able to read and write files containing objects
To achieve this, I first give you an overview of the important stream classes in this chapter and how they interrelate. I’ll go into the detail selectively, just exploring the classes and methods that you need to accomplish the specific things I noted.
Two areas where you must use the facilities provided by the stream classes are reading from the keyboard and writing to the command line or the console window of an IDE. I cover both of these in this chapter along with some general aspects of the stream classes and the relationships between them. You learn about how you use streams to read and write binary and character data files in Chapters 10 and 11. You look into how you read from and write objects to a file in Chapter 12.
A stream is an abstract representation of an input or output device that is a source of, or destination for, data. The stream concept enables you to transfer data to and from diverse physical devices such as disk files, communications links, or just your keyboard, in essentially the same way.
In general you can write data to a stream or read data from a stream. You can visualize a stream as a sequence of bytes that flows into or out of your program. Figure 8-1 illustrates how physical devices map to streams.

Input and Output Streams
A stream to which you can write data is called an output stream. The output stream can go to any device to which a sequence of bytes can be transferred, such as a file on a hard disk, or a network connection. An output stream can also go to your display screen, but only at the expense of limiting it to a fraction of its true capability. Stream output to your display is output to the command line. When you write to your display screen using a stream, it can display characters only, not graphical output. Graphical output requires more specialized support that I discuss from Chapter 17 onward.
NOTE Note that although a printer can be considered notionally as a stream, printing in Java does not work this way. A printer in Java is treated as a graphical device, so sending output to the printer is very similar to displaying graphical output on your display screen. You learn how printing works in Java in Chapter 21.
You read data from an input stream. In principle, this can be any source of serial data, but is typically a disk file, the keyboard, or a connection to a remote computer.
Under normal circumstances, file input and output for the machine on which your program is executing is available only to Java applications. It’s not available to Java applets except to a strictly limited extent. If this were not so, a malicious Java applet embedded in a web page could trash your hard disk. An IOException is normally thrown by any attempted operation on disk files on the local machine in a Java applet. The directory containing the class file for the applet and its subdirectories are freely accessible to the applet. Also, the security features in Java can be used to control what an applet (and an application running under a Security Manager) can access so that an applet can access only files or other resources for which it has explicit permission.
The main reason for using a stream as the basis for input and output operations is to make your program code for these operations independent of the device involved. This has two advantages. First, you don’t have to worry about the detailed mechanics of each device, which are taken care of behind the scenes. Second, your program works for a variety of input/output devices without any changes to the code.
Stream input and output methods generally permit very small amounts of data, such as a single character or byte, to be written or read in a single operation. Transferring data to or from a stream like this may be extremely inefficient, so a stream is often equipped with a buffer in memory, in which case it is called a buffered stream. A buffer is simply a block of memory that is used to batch up the data that is transferred to or from an external device. Reading or writing a stream in reasonably large chunks reduces the number of input/output operations necessary and thus makes the process more efficient.
When you write to a buffered output stream, the data is sent to the buffer and not to the external device. The amount of data in the buffer is tracked automatically, and the data is usually sent to the device when the buffer is full. However, you will sometimes want the data in the buffer to be sent to the device before the buffer is full, and methods are provided to do this. This operation is usually termed flushing the buffer.
Buffered input streams work in a similar way. Any read operation on a buffered input stream reads data from the buffer. A read operation for the device that is the source of data for the stream is read only when the buffer is empty and the program has requested data. When this occurs, a complete buffer-full of data is read into the buffer automatically from the device, or less if insufficient data is available.
Binary and Character Streams
The java.io package supports two types of streams — binary streams, which contain binary data, and character streams, which contain character data. Binary streams are sometimes referred to as byte streams. These two kinds of streams behave in different ways when you read and write data.
When you write data to a binary stream, the data is written to the stream as a series of bytes, exactly as it appears in memory. No transformation of the data takes place. Binary numerical values are just written as a series of bytes, 4 bytes for each value of type int, 8 bytes for each value of type long, 8 bytes for each value of type double, and so on. As you saw in Chapter 2, Java stores its characters internally as Unicode characters, which are 16-bit characters, so each Unicode character is written to a binary stream as 2 bytes, the high byte being written first. Supplementary Unicode characters that are surrogates consist of two successive 16-bit characters, in which case the two sets of 2 bytes are written in sequence to the binary stream with the high byte written first in each case.
Character streams are used for storing and retrieving text. You may also use character streams to read text files not written by a Java program. All binary numeric data has to be converted to a textual representation before being written to a character stream. This involves generating a character representation of the original binary data value. Reading numeric data from a stream that contains text involves much more work than reading binary data. When you read a value of type int from a binary stream, you know that it consists of 4 bytes. When you read an integer from a character stream, you have to determine how many characters from the stream make up the value. For each numerical value you read from a character stream, you have to be able to recognize where the value begins and ends and then convert the token — the sequence of characters that represents the value — to its binary form. Figure 8-2 illustrates this.
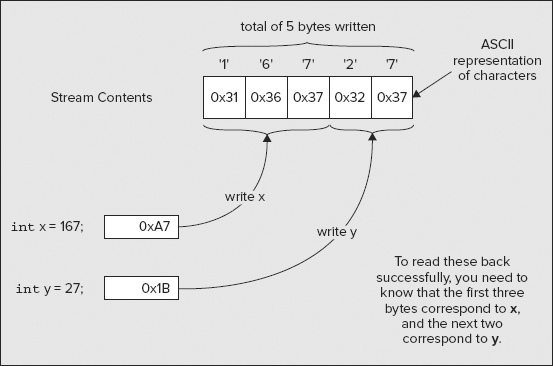
When you write strings to a stream as character data, by default the Unicode characters are automatically converted to the local representation of the characters in the host machine, and these are then written to the stream. When you read a string, the default mechanism converts the data from the stream back to Unicode characters from the local machine representation. With character streams, your program reads and writes Unicode characters, but the stream contains characters in the equivalent character encoding used by the local computer.
You don’t have to accept the default conversion process for character streams. Java allows named mappings between Unicode characters and sets of bytes to be defined, called charsets, and you can select an available charset that is to apply when data is transferred to, or from, a particular character stream. This is important when the data is being transferred to or from another computer where the data representation is different from your PC. Without the correct mapping, your PC will not interpret data from the destination machine correctly, and vice versa. I don’t go into charsets in detail, but you can find more information on defining and using charsets in the JDK documentation for the Charset class.
THE CLASSES FOR INPUT AND OUTPUT
There are quite a number of stream classes but, as you will see later, they form a reasonably logical structure. After you see how they are related, you shouldn’t have much trouble using them. I work through the class hierarchy from the top down, so you can see how the classes hang together and how you can combine them in different ways to suit different situations.
The package java.io contains two classes that provide the foundation for Java’s support for stream I/O, shown in Table 8-1.
TABLE 8-1: Package java.io Classes
| CLASS | DESCRIPTION |
| InputStream | The base class for byte stream input operations |
| OutputStream | The base class for byte stream output operations |
InputStream and OutputStream are both abstract classes. As you are well aware by now, you cannot create instances of an abstract class — these classes serve only as a base from which to derive classes with more concrete input or output capabilities. However, both of the classes declare methods that define a basic set of operations for the streams they represent, so the fundamental characteristics of how a stream is accessed are set by these classes. Generally, the InputStream and OutputStream subclasses represent byte streams and provide the means of reading and writing binary data as a series of bytes.
Both classes implement the Closeable interface. This interface declares just one method, close(), which closes the stream and releases any resources that the stream object is holding. The Closeable interface extends the AutoCloseable interface that also declares the close() method so classes that implement Closeable also implement AutoCloseable. Classes that implement the AutoCloseable interface can have their close() method called automatically when the class object is created within a special try block. I discuss this in Chapter 9.
Basic Input Stream Operations
As you saw in the previous section, the InputStream class is abstract, so you cannot create objects of this class type. Nonetheless, input stream objects are often accessible via a reference of this type, so the methods identified in this class are what you get. The InputStream class includes three methods for reading data from a stream, shown in Table 8-2.
TABLE 8-2: InputStream Class Methods
| METHOD | DESCRIPTION |
| read() | This method is abstract, so it has to be defined in a subclass. The method returns the next byte available from the stream as type int. If the end of the stream is reached, the method returns the value -1. An exception of type IOException is thrown if an I/O error occurs. |
| read(byte[] array) | This method reads bytes from the stream into successive elements of array. The maximum of array.length bytes is read. The method does not return until the input data is read or the end of the stream is detected. The method returns the number of bytes read or -1 if no bytes were read because the end of the stream was reached. If an I/O error occurs, an exception of type IOException is thrown. If the argument to the method is null then a NullPointerException is thrown. An input/output method that does not return until the operation is completed is referred to as a blocking method, and you say that the methods blocks until the operation is complete. |
| read(byte[] array, int offset, int length) | This works in essentially the same way as the previous method, except that up to length bytes are read into array starting with the element array[offset]. The method returns the number of bytes read or -1 if no bytes were read because the end of the stream was reached. |
These methods read data from the stream simply as bytes. No conversion is applied. If any conversion is required — for a stream containing bytes in the local character encoding, for example — you must provide a way to handle this. You see how this might be done in a moment.
You can skip over bytes in an InputStream by calling its skip() method. You specify the number of bytes to be skipped as an argument of type long, and the actual number of bytes skipped is returned, also a value of type long. This method can throw an IOException if an error occurs.
You can close an InputStream by calling its close() method. After you have closed an input stream, subsequent attempts to access or read from the stream cause an IOException to be thrown because the close() operation has released the resources held by the stream object, including the source of the data, such as a file. I discuss closing a stream in more detail in Chapter 9.
Buffered Input Streams
The BufferedInputStream class defines an input stream that is buffered in memory and thus makes read operations on the stream more efficient. The BufferedInputStream is derived from the FilterInputStream class, which has InputStream as a base.
You create a BufferedInputStream object from another input stream, and the constructor accepts a reference of type InputStream as an argument. The BufferedInputStream class overrides the methods inherited from InputStream so that operations are via a buffer; it implements the abstract read() method. Here’s an example of how you create a buffered input stream:
BufferedInputStream keyboard = new BufferedInputStream(System.in);
The argument System.in is an InputStream object that is a static member of the System class and encapsulates input from the keyboard. You look into how you can read input from the keyboard a little later in this chapter.
The effect of wrapping a stream in a BufferedInputStream object is to buffer the underlying stream in memory so that data can be read from the stream in large chunks — up to the size of the buffer that is provided. The data is then made available to the read() methods directly from the buffer in memory and the buffer is replenished automatically. A real read operation from the underlying stream is executed only when the buffer is empty.
With a suitable choice of buffer size, the number of input operations from the underlying stream that are needed is substantially reduced, and the process is a whole lot more efficient. This is because for many input streams, each read operation carries quite a bit of overhead, beyond the time required to actually transfer the data. The buffer size that you get by default when you call the BufferedInputStream constructor as in the previous code fragment is 8192 bytes. This is adequate for most situations where modest amounts of data are involved. The BufferedInputStream class also defines a constructor that accepts a second argument of type int that enables you to specify the size in bytes of the buffer to be used.
Basic Output Stream Operations
The OutputStream class contains three write() methods for writing binary data to the stream. As can be expected, these mirror the read() methods of the InputStream class. This class is also abstract, so only subclasses can be instantiated. The principal direct subclasses of OutputStream are shown in Figure 8-3.

You investigate the methods belonging to the ObjectOutputStream class in Chapter 12, when you learn how to write objects to a file.
NOTE Note that this is not the complete set of output stream classes. The FilterOutputStream class has a further eight subclasses, including the BufferedOutputStream class, which does for output streams what the BufferedInputStream class does for input streams. There is also the PrintStream class, which you look at a little later in this chapter, because output to the command line is via a stream object of this type.
Stream Readers and Writers
Stream readers and writers are objects that can read and write byte streams as character streams. So a character stream is essentially a byte stream fronted by a reader or a writer. The base classes for stream readers and writers are shown in Table 8-3.
TABLE 8-3: Base Class for Stream Readers and Writers
| CLASS | DESCRIPTION |
| Reader | The base class for reading a character stream |
| Writer | The base class for writing a character stream |
Reader and Writer are both abstract classes. Both classes implement the AutoCloseable interface, which declares the close() method. The Reader class also implements the Readable interface, which declares the read() method for reading characters into a CharBuffer object that is passed as the argument to the method. The Reader class defines two further read() methods. One of these requires no arguments and reads and returns a single character from the stream and returns it as type int. The other expects an array of type char[] as the argument and reads characters into the array that is passed to the method. The method returns the number of characters that were read or −1 if the end of the stream is reached. The reader has an abstract read() method as a member, which is declared like this:
public abstract int read(char[] buf, int offset, int length) throws IOException;
This method is the reason the Reader class is abstract and has to be implemented in any concrete subclass. The method reads length characters into the buf array starting at position buf[offset]. The method also returns the number of characters that were read or 21 if the end of the stream was reached.
Another read() method reads characters into a buffer:
public int read(CharBuffer buffer) throws IOException;
This reads characters into the CharBuffer buffer specified by the argument. No manipulation of the buffer is performed. The method returns the number of characters transferred to buffer or 21 if the source of characters is exhausted.
All four read() methods can throw an exception of type IOException, and the read() method declared in Readable can also throw an exception of NullPointerException if the argument is null.
The Writer class implements the Appendable interface. This declares three versions of the append() method; one takes an argument of type char and appends the character that is passed to it to whatever stream the Writer encapsulates, another accepts an argument of type CharSequence and appends that to the underlying stream, and the third appends a subsequence of a character sequence to the stream. Recall from Chapter 6 that a CharSequence reference can refer to an object of type String, an object of type StringBuilder, an object of type StringBuffer, or an object of type CharBuffer, so the append() method handles any of these. The Writer class has five write() methods (shown in Table 8-4), all of which have a void return type and throw an IOException if an I/O error occurs.
TABLE 8-4: Writer Class write () Methods
| METHOD | DESCRIPTION |
| write(int ch) | Writes the character corresponding to the low-order 2 bytes of the integer argument, ch. |
| write(char[] buf) | Writes the array of characters buf. |
| write(char[] buf, int offset, int length) |
This is an abstract method that writes length characters from buf starting at buf[offset]. |
| write(String str) | Writes the string str. |
| write(String str, int offset, int length) |
Writes length characters from str starting with the character at index position offset in the string. |
The Reader and Writer classes and their subclasses are not really streams themselves, but provide the methods you can use for reading and writing an underlying stream as a character stream. Thus, you typically create a Reader or Writer object using an underlying InputStream or OutputStream object that encapsulates the connection to the external device that is the ultimate source or destination of the data.
Using Readers
The Reader class has the direct subclasses shown in Figure 8-4.

You can read an input stream as a character stream using an InputStreamReader object that you could create like this:
InputStreamReader keyboard = new InputStreamReader(System.in);
The parameter to the InputStreamReader constructor is of type InputStream, so you can pass an object of any class derived from InputStream to it. The preceding example creates an InputStreamReader object, keyboard, from the object System.in, the keyboard input stream.
The InputStreamReader class defines the abstract read() method that it inherits from Reader and redefines the read() method without parameters. These methods read bytes from the underlying stream and return them as Unicode characters using the default conversion from the local character encoding. In addition to the preceding example, there are also three further constructors for InputStreamReader objects (shown in Table 8-5).
TABLE 8-5: InputStreamReader Object Constructors
| METHOD | DESCRIPTION |
| InputStreamReader( InputStream in, Charset s) |
Constructs an object with in as the underlying stream. The object uses s to convert bytes to Unicode characters. |
| InputStreamReader( InputStream in, CharsetDecoder dec) |
Constructs an object that uses the charset decoder dec to transform bytes that are read from the stream in to a sequence of Unicode characters. |
| InputStreamReader( InputStream in, String charsetName) |
Constructs an object that uses the charset identified in the name charsetName to convert bytes that are read from the stream in to a sequence of Unicode characters. |
A java.nio.charset.Charset object defines a mapping between Unicode characters and bytes. A Charset can be identified by a name that is a string that conforms to the IANA conventions for Charset registration. A java.nio.charset.CharsetDecoder object converts a sequence of bytes in a given charset to bytes. Consult the class documentation in the JDK for the Charset and CharsetDecoder classes for more information.
Of course, the operations with a reader are much more efficient if you buffer it with a BufferedReader object like this:
BufferedReader keyboard = new BufferedReader(new InputStreamReader(System.in));
Here, you wrap an InputStreamReader object around System.in and then buffer it using a BufferedReader object. This makes the input operations much more efficient. Your read operations are from the buffer belonging to the BufferedReader object, and this object takes care of filling the buffer from System.in when necessary via the underlying InputStreamReader object.
A CharArrayReader object is created from an array and enables you to read data from the array as though it were from a character input stream. A StringReader object class does essentially the same thing, but obtains the data from a String object.
Using Writers
The main subclasses of the Writer class are as shown in Figure 8-5.
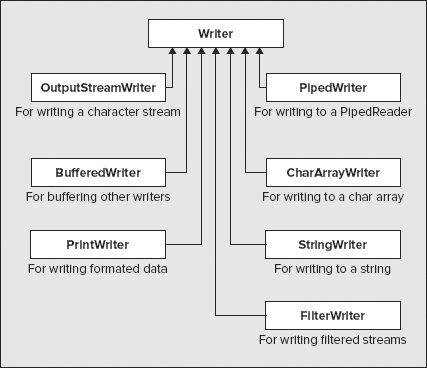

Let’s discuss just a few details of the most commonly used of these classes.
The OutputStreamWriter class writes characters to an underlying binary stream. It also has a subclass, FileWriter, that writes characters to a stream encapsulating a file. Both of these are largely superseded by the new I/O facilities.
Note that the PrintWriter class has no particular relevance to printing, in spite of its name. The PrintWriter class defines methods for formatting binary data as characters and writing it to a character stream. It defines overloaded print() and println() methods that accept an argument of each of the primitive types, of type char[], of type String, and of type Object. The data that is written is a character representation of the argument. Numerical values and objects are converted to a string representation using the static valueOf() method in the String class. Overloaded versions of this method exist for all the primitive types plus type Object. In the case of an argument that is an Object reference, the valueOf() method just calls the toString() method for the object to produce the string to be written to the stream. The print() methods just write the string representation of the argument, whereas the println() method appends to the output. You can create a PrintWriter object from a stream or from another Writer object.
An important point note when using a PrintWriter object is that its methods do not throw I/O exceptions. To determine whether any I/O errors have occurred, you have to call the checkError() method for the PrintWriter object. This method returns true if an error occurred and false otherwise.
The StringWriter and CharArrayWriter classes are for writing character data to a StringBuffer object, or an array of type char[]. You typically use these to perform data conversions so that the results are available to you from the underlying array or string. For example, you could combine the capabilities of a PrintWriter with a StringWriter to obtain a String object containing binary data converted to characters:
StringWriter strWriter = new StringWriter(); PrintWriter writer = new PrintWriter(strWriter);
Now you can use the methods for the writer object to write to the StringBuffer object underlying the StringWriter object:
double value = 2.71828; writer.println(value);
You can get the result back as a StringBuffer object from the original StringWriter object:
StringBuffer str = strWriter.getBuffer();
Of course, the formatting done by a PrintWriter object does not help make the output line up in neat columns. If you want that to happen, you have to do it yourself. You see how you might do this for command-line output a little later in this chapter.
Let’s now turn to keyboard input and command-line output.
Your operating system typically defines three standard streams that are accessible through members of the System class in Java:
- A standard input stream that usually corresponds to the keyboard by default. This is encapsulated by the in member of the System class and is of type InputStream.
- A standard output stream that corresponds to output on the command line or in the console window of an IDE. This is encapsulated by the out member of the System class and is of type PrintStream.
- A standard error output stream for error messages that usually maps to the command-line output by default. This is encapsulated by the err member of the System class and is also of type PrintStream.
You can reassign any of these to another stream within a Java application. The System class provides the static methods setIn(), setOut(), and setErr() for this purpose. The setIn() method requires an argument of type InputStream that specifies the new source of standard input. The other two methods expect an argument of type PrintStream.
Because the standard input stream is of type InputStream, you are not exactly overwhelmed by the capabilities for reading data from the keyboard in Java. Basically, you can read a byte or an array of bytes using a read() method as standard, and that’s it. If you want more than that, reading integers, or decimal values, or strings as keyboard input, you’re on your own. Let’s see what you can do to remedy that.
Getting Data from the Keyboard
To get sensible input from the keyboard, you have to be able to scan the stream of characters and recognize what they are. When you read a numerical value from the stream, you have to look for the digits and possibly the sign and decimal point, figure out where the number starts and ends in the stream, and finally convert it to the appropriate value. To write the code to do this from scratch would take quite a lot of work. Fortunately, you can get a lot of help from the class libraries. One possibility is to use the java.util.Scanner class, but I defer discussion of that until Chapter 15 because you need to understand another topic before you can use Scanner objects effectively. The StreamTokenizer class in the java.io package is another possibility, so let’s look further into that.
The term token refers to a data item such as a number or a string that, in general, consists of several consecutive characters of a particular kind from the stream. For example, a number is usually a sequence of characters that consists of digits, maybe a decimal point, and sometimes a sign in front. The class has the name StreamTokenizer because it can read characters from a stream and parse it into a series of tokens that it recognizes.
You create a StreamTokenizer object from a stream reader object that reads data from the underlying input stream. To read the standard input stream System.in you can use an InputStreamReader object that converts the raw bytes that are read from the stream from the local character encoding to Unicode characters before the StreamTokenizer object sees them. In the interest of efficiency it would be a good idea to buffer the data from the InputStreamReader through a BufferedReader object that buffers the data in memory. With this in mind, you could create a StreamTokenizer object like this:
StreamTokenizer tokenizer = new StreamTokenizer(
new BufferedReader(
new InputStreamReader(System.in)));
The argument to the StreamTokenizer object is the original standard input stream System.in inside an InputStreamReader object that converts the bytes to Unicode inside a BufferedReader object that supplies the stream of Unicode characters via a buffer in memory.
Before you can make use of the StreamTokenizer object for keyboard input, you need to understand a bit more about how it works.
Tokenizing a Stream
The StreamTokenizer class defines objects that can read an input stream and parse it into tokens. The input stream is read and treated as a series of separate bytes, and each byte is regarded as a Unicode character in the range 'u�000' to 'u�0FF'. A StreamTokenizer object in its default state can recognize the following kinds of tokens (shown in Table 8-6):
TABLE 8-6: StreamTokenizer Object Tokens
| TOKEN | DESCRIPTION |
| Numbers | A sequence consisting of the digits 0 to 9, plus possibly a decimal point, and a + or − sign. |
| Strings | Any sequence of characters between a pair of single quotes or a pair of double quotes. |
| Words | Any sequence of letters or digits 0 to 9 beginning with a letter. A letter is defined as any of A to Z and a to z or u00A0 to u00FF. A word follows a whitespace character and is terminated by another whitespace character, or any character other than a letter or a digit. |
| Comments | Any sequence of characters beginning with a forward slash, /, and ending with the end-of-line character. Comments are ignored and not returned by the tokenizer. |
| Whitespace | All byte values from ’u0000’ to ’u0020’, which includes space, backspace, horizontal tab, vertical tab, line feed, form feed, and carriage return. Whitespace acts as a delimiter between tokens and is ignored (except within a quoted string). |
To retrieve a token from the stream, you call the nextToken() method for the StreamTokenizer object:
int tokenType = 0;
try {
while((tokenType = tokenizer.nextToken()) != tokenizer.TT_EOF) {
// Do something with the token...
}
} catch (IOException e) {
e.printStackTrace(System.err);
System.exit(1);
}
The nextToken() method can throw an exception of type IOException, so we put the call in a try block. The value returned depends on the token recognized, indicating its type, and from this value you can determine where to find the token itself. In the preceding fragment, you store the value returned in tokenType and compare its value with the constant TT_EOF. This constant is a static field of type int in the StreamTokenizer class that is returned by the nextToken() method when the end of the stream has been read. Thus the while loop continues until the end of the stream is reached. The token that was read from the stream is itself stored in one of two instance variables of the StreamTokenizer object. If the data item is a number, it is stored in a public data member nval, which is of type double. If the data item is a quoted string or a word, a reference to a String object that encapsulates the data item is stored in the public data member sval, which is of type String, of course. The analysis that segments the stream into tokens is fairly simple, and the way in which an arbitrary stream is broken into tokens is illustrated in Figure 8-6.

As I’ve said, the int value that is returned by the nextToken() method indicates what kind of data item was read. It can be any of the constant static variables shown in Table 8-7 defined in the StreamTokenizer class:
TABLE 8-7: Constant Static Variables
| TOKEN VALUE | DESCRIPTION |
| TT_NUMBER | The token is a number that has been stored in the public field nval of type double in the tokenizer object. |
| TT_WORD | The token is a word that has been stored in the public field sval of type String in the tokenizer object. |
| TT_EOF | The end of the stream has been reached. |
| TT_EOL | An end-of-line character has been read. This is set only if the eolIsSignificant() method has been called with the argument, true. Otherwise, end-of-line characters are treated as whitespace and ignored. |
If a quoted string is read from the stream, the value that is returned by nextToken() is the quote character used for the string as type int — either a single quote or a double quote. In this case, you retrieve the reference to the string that was read from the sval member of the tokenizer object. The value indicating what kind of token was read last is also available from a public data member ttype, of the StreamTokenizer object, which is of type int.
Customizing a Stream Tokenizer
You can modify default tokenizing mode by calling one or other of the methods found in Table 8-8.
TABLE 8-8: Methods that Modify Tokenizing Modes
| METHOD | DESCRIPTION |
| resetSyntax() | Resets the state of the tokenizer object so no characters have any special significance. This has the effect that all characters are regarded as ordinary and are read from the stream as single characters so no tokens are identified. The value of each character is stored in the ttype field. |
| ordinaryChar( int ch) |
Sets the character ch as an ordinary character. An ordinary character is a character that has no special significance. It is read as a single character whose value is stored in the ttype field. Calling this method does not alter the state of characters other than the argument value. |
| ordinaryChars( int low, int hi) |
Causes all characters from low to hi inclusive to be treated as ordinary characters. Calling this method does not alter the state of characters other than those specified by the argument values. |
| whitespaceChars( int low, int hi) |
Causes all characters from low to hi inclusive to be treated as whitespace characters. Unless they appear in a string, whitespace characters are treated as delimiters between tokens. Calling this method does not alter the state of characters other than those specified by the argument values. |
| wordChars( int low, int hi) |
Specifies that the characters from low to hi inclusive are word characters. A word is at least one of these characters. Calling this method does not alter the state of characters other than those specified by the argument values. |
| commentChar( int ch) |
Specifies that ch is a character that indicates the start of a comment. All characters to the end of the line following the character ch are ignored. Calling this method does not alter the state of characters other than the argument value. |
| quoteChar( int ch) |
Specifies that matching pairs of the character ch enclose a string. Calling this method does not alter the state of characters other than the argument value. |
| slashStarComments( boolean flag) |
If the argument is false, this switches off recognizing comments between /* and */. A true argument switches it on again. |
| slashSlashComments( boolean flag) |
If the argument is false, this switches off recognizing comments starting with a double slash. A true argument switches it on again. |
| lowerCaseMode( boolean flag) |
An argument of true causes strings to be converted to lowercase before being stored in sval. An argument of false switches off lowercase mode. |
| pushback() | Calling this method causes the next call of the nextToken() method to return the ttype value that was set by the previous nextToken() call and to leave sval and nval unchanged. |
If you want to alter a tokenizer, it is usually better to reset it by calling the resetSyntax() method and then calling the other methods to set up the tokenizer the way that you want. If you adopt this approach, any special significance attached to particular characters is apparent from your code. The resetSyntax() method makes all characters, including whitespace and ordinary characters, so that no character has any special significance. In some situations you may need to set a tokenizer up dynamically to suit retrieving each specific kind of data that you want to extract from the stream. When you want to read the next character as a character, even if it would otherwise be part of a token, you just need to call resetSyntax() before calling nextToken(). The character is returned by nextToken() and stored in the ttype field. To read tokens subsequently, you have to set the tokenizer up appropriately.
Let’s see how you can use this class to read data items from the keyboard.
TRY IT OUT: Creating a Formatted Input Class
One way of reading formatted input is to define your own class that uses a StreamTokenizer object to read from standard input. You can define a class, FormattedInput, that defines methods to return various types of data items entered via the keyboard:
import java.io.StreamTokenizer;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public class FormattedInput {
// Method to read an int value...
// Method to read a double value...
// Plus methods to read various other data types...
// Helper method to read the next token
private int readToken() {
try {
ttype = tokenizer.nextToken();
return ttype;
} catch (IOException e) { // Error reading in nextToken()
e.printStackTrace();
System.exit(1); // End the program
}
return 0;
}
// Object to tokenize input from the standard input stream
private StreamTokenizer tokenizer = new StreamTokenizer(
new BufferedReader(
new InputStreamReader(System.in)));
private int ttype; // Stores the token type code
}
Directory "TestFormattedInput"
The default constructor is quite satisfactory for this class, because the instance variable tokenizer is already initialized. The readToken() method is there for use in the methods that read values of various types. It makes the ttype value returned by nextToken() available directly, and saves having to repeat the try and catch blocks in all the other methods.
All you need to add are the methods to read the data values that you want. Here is one way to read a value of type int:
// Method to read an int value
public int readInt() {
for (int i = 0; i < 5; ++i) {
if (readToken() == StreamTokenizer.TT_NUMBER) {
return (int) tokenizer.nval; // Value is numeric, so return as int
} else {
System.out.println("Incorrect input: " + tokenizer.sval
+ " Re-enter an integer");
continue; // Retry the read operation
}
}
System.out.println("Five failures reading an int value"
+ " - program terminated");
System.exit(1); // End the program
return 0;
}
Directory "TestFormattedInput"
This method gives the user five chances to enter a valid input value before terminating the program. Terminating the program is likely to be inconvenient to say the least in many circumstances. If you instead make the method throw an exception in the case of failure here, and let the calling method decide what to do, this would be a much better way of signaling that the right kind of data could not be found.
You can define your own exception class for this. Let’s define it as the type InvalidUserInputException:
public class InvalidUserInputException extends Exception {
public InvalidUserInputException() {}
public InvalidUserInputException(String message) {
super(message);
}
private static final long serialVersionUID = 90001L;
}
Directory "TestFormattedInput"
You haven’t had to add much to the base class capability. You just need the ability to pass your own message to the class. The significant things you have added are your own exception type name and a member serialVersionUID, which is a version identifier for a serializable class type. This is there because the base class is serializable and your class inherits this capability. Serialization is the process of writing an object to a file; you learn more about this in Chapter 12.
Now you can change the code for the readInt() method so it works like this:
public int readInt() throws InvalidUserInputException {
if (readToken() != StreamTokenizer.TT_NUMBER) {
throw new InvalidUserInputException("readInt() failed."
+ "Input data not numeric");
}
return (int) tokenizer.nval;
}
Directory "TestFormattedInput"
If you need a method to read an integer value and return it as one of the other integer types, byte, short, or long, you could implement it in the same way, but just cast the value in nval to the appropriate type. You might want to add checks that the original value was an integer, and maybe that it was not out of range for the shorter integer types. For example, to do this for type int, you could code it as the following:
public int readInt() throws InvalidUserInputException {
if (readToken() != StreamTokenizer.TT_NUMBER) {
throw new InvalidUserInputException("readInt() failed."
+ "Input data not numeric");
}
if (tokenizer.nval > (double) Integer.MAX_VALUE
|| tokenizer.nval < (double) Integer.MIN_VALUE) {
throw new InvalidUserInputException("readInt() failed."
+ "Input outside range of type int");
}
if (tokenizer.nval != (double) (int) tokenizer.nval) {
throw new InvalidUserInputException("readInt() failed."
+ "Input not an integer");
}
return (int) tokenizer.nval;
}
Directory "TestFormattedInput"
The Integer class makes the maximum and minimum values of type int available in the public members MAX_VALUE and MIN_VALUE. Other classes corresponding to the basic numeric types provide similar fields. To determine whether the value in nval is really a whole number, you cast it to an integer and then cast it back to double and see whether it is the same value.
The code to implement readDouble() is very simple. You don’t need the cast for the value in nval because it is type double anyway:
public double readDouble() throws InvalidUserInputException {
if (readToken() != StreamTokenizer.TT_NUMBER) {
throw new InvalidUserInputException("readDouble() failed."
+ "Input data not numeric");
}
return tokenizer.nval;
}
Directory "TestFormattedInput"
A readFloat() method would just need to cast nval to type float.
Reading a string is slightly more involved. You could allow input strings to be quoted or unquoted as long as they were alphanumeric and did not contain whitespace characters. Here’s how the method might be coded to allow that:
public String readString() throws InvalidUserInputException {
if (readToken() == StreamTokenizer.TT_WORD || ttype == '"'
|| ttype == '"') {
return tokenizer.sval;
} else {
throw new InvalidUserInputException("readString() failed."
+ "Input data is not a string");
}
}
Directory "TestFormattedInput"
If either a word or a string is recognized, the token is stored as type String in the sval field of the StreamTokenizer object.
Let’s see if it works.
TRY IT OUT: Formatted Keyboard Input
You can try out the FormattedInput class in a simple program that iterates round a loop a few times to give you the opportunity to try out correct and incorrect input:
public class TestFormattedInput {
public static void main(String[] args) {
FormattedInput kb = new FormattedInput();
for (int i = 0; i < 5; ++i) {
try {
System.out.print("Enter an integer:");
System.out.println("Integer read:" + kb.readInt());
System.out.print("Enter a double value:");
System.out.println("Double value read:" + kb.readDouble());
System.out.print("Enter a string:");
System.out.println("String read:" + kb.readString());
} catch (InvalidUserInputException e) {
System.out.println("InvalidUserInputException thrown.
"
+ e.getMessage());
}
}
}
}
Directory "TestFormattedInput"
It is best to run this example from the command line. Some Java development environments are not terrific when it comes to keyboard input. If you try a few wrong values, you should see your exception being thrown.
How It Works
This just repeats requests for input of each of the three types of value you have provided methods for, over five iterations. Of course, after an exception of type InvalidUserInputException is thrown, the loop goes straight to the start of the next iteration — if there is one.
This code isn’t foolproof. Bits of an incorrect entry can be left in the stream to confuse subsequent input and you can’t enter floating-point values with exponents. However, it does work after a fashion and it’s best not to look a gift horse in the mouth.
Writing to the Command Line
Up to now, you have made extensive use of the println() method from the PrintStream class in your examples to output formatted information to the screen. The out object in the expression System.out.println() is of type PrintStream. This class outputs data of any of the basic types as a string. For example, an int value of 12345 becomes the string "12345" as generated by the valueOf() method from the String class. However, you also have the PrintWriter class that I discussed earlier in the chapter to do the same thing because this class has all the methods that PrintStream provides.
The principle difference between the two classes is that with the PrintWriter class you can control whether or not the stream buffer is flushed when the println() method is called, whereas with the PrintStream class you cannot. The PrintWriter class flushes the stream buffer only when one of the println() methods is called, if automatic flushing is enabled. A PrintStream object flushes the stream buffer whenever a newline character is written to the stream, regardless of whether it was written by a print() or a println() method.
Both the PrintWriter and PrintStream classes format basic data as characters. In addition to the print() and println() methods that do this, they also define the printf() method mentioned in Chapter 6. This method gives you a great deal more control over the format of the output and also accepts an arbitrary number of arguments to be formatted and displayed.
The printf() Method
The printf() method that is defined in the PrintStream and PrintWriter classes produces formatted output for an arbitrary sequence of values of various types, where the formatting is specified by the first argument to the method. System.out happens to be of type PrintStream, so you can use printf() to produce formatted output to the command line. The PrintStream and PrintWriter classes define two versions of the printf() method, shown in Table 8-9.
TABLE 8-9: printf() Method Versions
| VERSION | DESCRIPTION |
| printf(String format, Object ... args) |
Outputs the values of the elements in args according to format specifications in format. An exception of type NullPointerException is thrown if format is null. |
| printf(Locale loc, String format, Object ... args) |
This version works as the preceding version does except that the output is tailored to the locale specified by the first argument. I explain how you define objects of the java.util.Locale class type a little later in this chapter. |
The format parameter is a string that should contain at least one format specification for each of the argument values that follow the format argument. The format specification for an argument value just defines how the data is to be presented and is of the following general form:
%[argument_index$][flags][width][.precision]conversion
The square brackets around components of the format specification indicate that they are optional, so the minimum format specification if you omit all of the optional parts is %conversion.
The options that you have for the various components of the format specification for a value are shown in Table 8-10.
TABLE 8-10: Format Specification Options
| OPTION | DESCRIPTION |
| conversion | This is a single character specifying how the argument is to be presented. The commonly used values are the following: 'd', 'o', and 'x' apply to integer values and specify that the output representation of the value should be decimal, octal, or hexadecimal, respectively. 'f', 'g', and 'a' apply to floating-point values and specify that the output representation should be decimal notation, scientific notation (with an exponent), or hexadecimal with an exponent, respectively. 'c' specifies that the argument value is a character and should be displayed as such. 's' specifies that the argument is a string. 'b' specifies that the argument is a boolean value, so it is output as "true" or "false". 'h' specifies that the hashcode of the argument is to be output in hexadecimal form. 'n' specifies the platform line separator so "%n" has the same effect as " ". |
| argument_index | This is a decimal integer that identifies one of the arguments that follow the format string by its sequence number, where "1$" refers to the first argument, "2$" refers to the second argument, and so on. You can also use '<' in place of a sequence number followed by $ to indicate that the argument should be the same as that of the previous format specification in the format string. Thus "<" specifies that the format specification applies to the argument specified by the preceding format specification in the format string. |
| flags | This is a set of flag characters that modify the output format. The flag characters that are valid depend on the conversion that is specified. The most used ones are the following: '-' and '^' apply to anything and specify that the output should be left-justified and uppercase, respectively. '+' forces a sign to be output for numerical values. '0' forces numerical values to be zero-padded. |
| width | Specifies the field width for outputting the argument and represents the minimum number of characters to be written to the output. |
| precision | This is used to restrict the output in some way depending on the conversion. Its primary use is to specify the number of digits of precision when outputting floating-point values. |
The best way to explain how you use this is through examples. I start with the simplest and work up from there.
Formatting Numerical Data
I suggest that you set up a program source file with an empty version of main() into which you can plug a succession of code fragments to try them out. You’ll find TryFormattedOutput.java in the download with the code fragments that are bold in the text commented out in main(). You can just comment out the one you want to try but as always, it’s better to type them in yourself.
The minimal format specification is a percent sign followed by a conversion specifier for the type of value you want displayed. For example:
int a = 5, b = 15, c = 255; double x = 27.5, y = 33.75; System.out.printf("x = %f y = %g", x, y); System.out.printf(" a = %d b = %x c = %o", a, b, c);
TryFormattedOutput.java
Executing this fragment produces the following output:
x = 27.500000 y = 33.750000 a = 5 b = f c = 377
There is no specification of the argument to which each format specifier applies, so the default action is to match the format specifiers to the arguments in the sequence in which they appear. You can see from the output that you get six decimal places after the decimal point for floating-point values, and the field width is set to be sufficient to accommodate the number of characters in each output value. Although there are two output statements, all the output appears on a single line, so you can deduce that printf() works like the print() method in that it just transfers output to the command line starting at the current cursor position.
The integer values also have a default output field width that is sufficient for the number of characters in the output. Here you have output values in normal decimal form, in hexadecimal form, and in octal representation. Note that there must be at least as many arguments as there are format specifiers. If you remove c from the argument list in the last printf() call, you get an exception of type MissingFormatArgumentException thrown. If you have more arguments than there are format specifiers in the format string, on the other hand, the excess arguments are simply ignored.
By introducing the argument index into the specification in the previous code fragment, you can demonstrate how that works:
int a = 5, b = 15, c = 255; double x = 27.5, y = 33.75; System.out.printf("x = %2$f y = %1$g", x, y); System.out.printf(" a = %3$d b = %1$x c = %2$o", a, b, c);
TryFormattedOutput.java
This produces the following output:
x = 33.750000 y = 27.500000 a = 255 b = 5 c = 17
Here you have reversed the sequence of the floating-point arguments in the output by using the argument index specification to select the argument for the format specifier explicitly. The integer values are also output in a different sequence from the sequence in which the arguments appear so the names that are output do not correspond with the variables.
To try out the use of "<" as the argument index specification, you could add the following statement to the preceding fragment:
System.out.printf("%na = %3$d b = %<x c = %<o", a, b, c);
TryFormattedOutput.java
This produces the following output on a new line:
a = 255 b = ff c = 377
You could equally well use " " in place of "%n" in the format string. The second and third format specifiers use "<" as the argument index, so all three apply only to the value of the first argument. The arguments b and c are ignored.
Note that if the format conversion is not consistent with the type of the argument to which you apply it, an exception of type IllegalFormatConversion is thrown. This would occur if you attempted to output any of the variables a, b, and c, which are of type int, with a specifier such as "%f", which applies only to floating-point values.
Specifying the Width and Precision
You can specify the field width for any output value. Here’s an example of that:
int a = 5, b = 15, c = 255; double x = 27.5, y = 33.75; System.out.printf("x = %15f y = %8g", x, y); System.out.printf("a = %1$5d b = %2$5x c = %3$2o", a, b, c);
TryFormattedOutput.java
Executing this results in the following output:
x = 27.500000 y = 33.750000 a = 5 b = f c = 377
You can see from the output that you get the width that you specify only if it is sufficient to accommodate all the characters in the output value. The second floating-point value, y, occupies a field width of 9, not the 8 that is specified. When you want your output to line up in columns, you must be sure to specify a field width that is sufficient to accommodate every output value.
Where the specified width exceeds the number of characters for the value, the field is padded on the left with spaces so the value appears right-justified in the field. If you want the output left-justified in the field, you just use the '-' flag character. For example:
System.out.printf("%na = %1$-5d b = %2$-5x c = %3$-5o", a, b, c);
This statement produces output left-justified in the fields, thus:
a = 5 b = f c = 377
You can add a precision specification for floating-point output:
double x = 27.5, y = 33.75;
System.out.printf("x = %15.2f y = %14.3f", x, y);
Here the precision for the first value is two decimal places, and the precision for the second value is 3 decimal places. Therefore, you get the following output:
x = 27.50 y = 33.750
Formatting Characters and Strings
The following code fragment outputs characters and their code values:
int count = 0; for(int ch = 'a' ; ch<= 'z' ; ch++) { System.out.printf(" %1$4c%1$4x", ch); if(++count%6 == 0) { System.out.printf("%n"); } }
TryFormattedOutput.java
Executing this produces the following output:
a 61 b 62 c 63 d 64 e 65 f 66
g 67 h 68 i 69 j 6a k 6b l 6c
m 6d n 6e o 6f p 70 q 71 r 72
s 73 t 74 u 75 v 76 w 77 x 78
y 79 z 7a
First the format specification %1$4c is applied to the first and only argument following the format string. This outputs the value of ch as a character because of the 'c' conversion specification and in a field width of 4. The second specification is %1$4x, which outputs the same argument — because of the 1$ — as hexadecimal because the conversion is 'x' and in a field width of 4.
You could write the output statement in the loop as:
System.out.printf(" %1$4c%<4x", ch);
The second format specifier is %<4x, which outputs the same argument as the preceding format specifier because of the '<' following the % sign.
Because a % sign always indicates the start of a format specifier, you must use "%%" in the format string when you want to output a % character. For example:
int percentage = 75;
System.out.printf("
%1$d%%", percentage);
The format specifier %1$d outputs the value of percentage as a decimal value. The %% that follows in the format string displays a percent sign, so the output is:
75%
You use the %s specifier to output a string. Here’s an example that outputs the same string twice:
String str = "The quick brown fox."; System.out.printf("%nThe string is:%n%s%n%1$25s", str);
TryFormattedOutput.java
This produces the following output:
The string is:
The quick brown fox.
The quick brown fox.
The first instance of str in the output is produced by the "%s" specification that follows the first "%n", and the second instance is produced by the "%1$25s" specification. The "%1$25s" specification has a field width that is greater than the length of the string so the string appears right-justified in the output field. You could apply the '-' flag to obtain the string left-justified in the field.
You have many more options and possibilities for formatted output. Try experimenting with them yourself, and if you want details of more specifier options, read the JDK documentation for the printf() method in the PrintStream class.
The Locale Class
You can pass an object of type java.util.Locale as the first argument to the printf() method, preceding the format string and the variable number of arguments that you want displayed. The Locale object specifies a language or a country + language context that affects the way various kinds of data, such as dates or monetary amounts, is presented.
You have three constructors available for creating Locale objects that accept one, two, or three arguments of type String. The first argument specifies a language as a string of two lowercase letters representing a Language Code defined by the standard ISO-639. Examples of language codes are "fr" for French, "en" for English, and "be" for Belarusian. The second argument specifies a country as a string of two uppercase letters representing a country code defined by the ISO-3166 standard. Examples of country codes are "US" for the USA, "GB" for the United Kingdom, and "CA" for Canada. The third argument is a vendor or browser-specific code such as "WIN" for Windows or "MAC" for Macintosh.
However, rather than using a class constructor, more often than not you use one of the Locale class constant static data members that provide predefined Locale objects for common national contexts. For example, you have members JAPAN, ITALY, and GERMANY for countries and JAPANESE, ITALIAN, and GERMAN for the corresponding languages. Consult the JDK documentation for the Locale class for a complete list of these.
Formatting Data into a String
The printf() method produces the string that is output by using an object of type java.util.Formatter, and it is the Formatter object that is producing the output string from the format string and the argument values. A Formatter object is also used by a static method format() that is defined in the String class, and you can use this method to format data into a string that you can use wherever you like — for displaying data in a component in a windowed application, for example. The static format() method in the String class comes in two versions, and the parameter lists for these are the same as for the two versions of the printf() method in the PrintStream class just discussed, one with the first parameter as a Locale object followed by the format string parameter and the variable parameter list and the other without the Locale parameter. Thus, all the discussion of the format specification and the way it interacts with the arguments you supply applies equally well to the String.format() method, and the result is returned as type String.
For example, you could write the following to output floating-point values:
double x = 27.5, y = 33.75;
String outString = String.format("x = %15.2f y = %14.3f", x, y);
outString contains the data formatted according to the first argument to the format() method. You could pass outString to the print() method to output it to the command line:
System.out.print(outString);
You get the following output:
x = 27.50 y = 33.750
This is exactly the same output as you got earlier using the printf() method, but obviously outString is available for use anywhere.
You can use a java.util.Formatter object directly to format data. You first create the Formatter object like this:
StringBuffer buf = new StringBuffer();
java.util.Formatter formatter = new java.util.Formatter(buf);
The Formatter object generates the formatted string in the StringBuffer object buf — you could also use a StringBuilder object for this purpose, of course. You now use the format() method for the formatter object to format your data into buf like this:
double x = 27.5, y = 33.75;
formatter.format("x = %15.2f y = %14.3f", x, y);
If you want to write the result to the command line, the following statement does it:
System.out.print(buf);
The result of executing this sequence of statements is exactly the same as from the previous fragment.
A Formatter object can format data and transfer it to destinations other than StringBuilder and StringBuffer objects, but I defer discussion of this until I introduce file output in Chapter 10.
In this chapter, I have introduced the facilities for inputting and outputting basic types of data to a stream. You learned how to read data from the keyboard and how to format output to the command line. Of course, you can apply these mechanisms to any character stream. You work with streams again when you learn about reading and writing files.
EXERCISES
You can download the source code for the examples in the book and the solutions to the following exercises from www.wrox.com.
1. Use a StreamTokenizer object to parse a string entered from the keyboard containing a series of data items separated by commas and output each of the items on a separate line.
2. Create a class defining an object that parses each line of input from the keyboard that contains items separated by an arbitrary delimiter (for example, a colon, or a comma, or a forward slash, and so on) and return the items as an array of type String[]. For example, the input might be:
1/one/2/two
The output would be returned as an array of type String[] containing "1", "one", "2", "two".
3. Write a program to generate 20 random values of type double between 250 and +50 and use the printf() method for System.out to display them with two decimal places in the following form:
1) +35.93 2) -46.94 3) +42.27 4) +32.09 5) +29.21
6) +13.87 7) -47.87 8) +30.67 9) -25.20 10) +29.67
11) +48.62 12) +6.70 13) +28.97 14) -41.64 15) +16.67
16) +17.01 17) +9.62 18) -15.21 19) +7.46 20) +4.09
4. Use a Formatter object to format 20 random values of type double between –50 and +50 and output the entire set of 20 in a single call of System.out.print() or System.out.println().
• What You Learned in This Chapter
| TOPIC | CONCEPT |
| Streams | A stream is an abstract representation of a source of serial input or a destination for serial output. |
| Stream Classes | The classes supporting stream operations are contained in the package java.io. |
| Stream Operations | Two kinds of stream operations are supported. Binary stream operations result in streams that contain bytes, and character stream operations are for streams that contain characters in the local machine character encoding. |
| Byte Streams | No conversion occurs when characters are written to, or read from, a byte stream. Characters are converted from Unicode to the local machine representation of characters when a character stream is written. |
| Byte Stream Classes | Byte streams are represented by subclasses of the classes InputStream and OutputStream. |
| Character Stream Classes | Character stream operations are provided by subclasses of the Reader and Writer classes. |
| Formatted Output to a Stream | The printf() method that is defined in the PrintStream and PrintWriter classes formats an arbitrary number of argument values according to a format string that you supply. You can use this method for the System.out object to produce formatted output to the command line. |
| Formatting Using a String Class Method | The static format() method that is defined in the String class formats an arbitrary number of argument values according to a format string that you supply and returns the result as a String object. This method works in essentially the same way as the printf() method in the PrintStream class. |
| The Formatter Class | An object of the Formatter class that is defined in the java.util package can format data into a StringBuilder or StringBuffer object, as well as other destinations. |
