
Chapter 18. Testing JPA-based applications
Unfortunately we need to deal with the object relational (O/R) impedance mismatch, and to do so you need to understand two things: the process of mapping objects to relational databases and how to implement those mappings.
Scott W. Amber, Mapping Objects to Relational Databases: O/R Mapping In Detail
This chapter covers
- Multilayered application testing
- Using DbUnit to test JPA applications
- JPA mapping tests
- Testing JPA-based DAOs
- Verifying JPA-generated schema
Most Java applications need to store data in persistent storage, and typically this storage is a relational database. There are many approaches to persisting the data, from executing low-level SQL statements directly to more sophisticated modules that delegate the task to third-party tools.
Although discussing the different approaches is almost a religious matter, we assume it’s a good practice to abstract data persistence to specialized classes, such as DAOs. The DAOs themselves can be implemented in many different ways:
- Writing brute-force SQL statements (such as the UserDaoJdbcImpl example in chapter 17)
- Using third-party tools (like Apache iBATIS or Spring JDBC templates) that facilitate JDBC programming
- Delegating the whole database access to tools that map objects to SQL (and vice-versa)
Over the last few years, the third approach has become widely adopted, through the use of ORM (object-relational mapping) tools such as Hibernate and Oracle TopLink. ORM became so popular that JCP (Java Community Process, the organization responsible for defining Java standards) created a specification[1] to address it, the JPA (Java Persistence API). JPA, as the name states, is just an API; in order to use it, you need an implementation. Fortunately, most existing tools adhere to the standard, so if you already use an ORM tool (such as Hibernate), you could use it in JPA mode, that is, using the Java Persistence APIs instead of proprietary ones.
1 Some people may argue that two standards already existed before JPA: EJB entities and JDO. Well, EJB entities were too complicated, and JDO never took off.
This chapter consists of two parts. First, we show how to test layers that use DAOs in a multilayered application. Then we explain how to test the JPA-based DAO (data access object) implementation, using DbUnit.[2]
2 And in this aspect, this chapter is an extension of chapter 17; if you aren’t familiar with DbUnit, we recommend you read that chapter first.
And although this chapter focuses on JPA and Hibernate, the ideas presented here apply to other ORM tools as well.
18.1. Testing multilayered applications
By multilayered (or multitiered) application we mean an application whose structure has been divided in layers, with each layer responsible for one aspect of the application. A typical example is a three-tiered web application comprising of presentation, business, and persistence layers.
Ideally, all of these layers should be tested, both in isolation (through unit tests) and together (through integration tests). In this section, we show how to unit test the business layer without depending on its lower tier, the persistence layer. But first, let’s look at the sample application.
18.1.1. The sample application
The examples in this chapter test the business and persistence layers (presentation layer testing was covered in chapter 11) of an enterprise application. The persistence layer comprises a User object and an UserDao interface, similar to those defined in chapter 17, but with a few differences: a new method (removeUser())on UserDao, the User object now has a one-to-many relationship with a Telephone object, and both of these classes are marked with JPA annotations, as shown in listing 18.1.
Listing 18.1. User and Telephone class definitions
@Entity
@Table(name="users")
public class User {
@Id @GeneratedValue(strategy=GenerationType.AUTO)
private long id;
private String username;
@Column(name="first_name")
private String firstName;
@Column(name="last_name")
private String lastName;
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="user_id")
@ForeignKey(name="fk_telephones_users")
private List<Telephone> telephones = new ArrayList<Telephone>();
// getters and setters omitted
}
@Entity
@Table(name="phones")
public class Telephone {
public static enum Type {
HOME, OFFICE, MOBILE;
}
@Id @GeneratedValue(strategy=GenerationType.AUTO)
private long id;
private String number;
private Type type;
// getters and setters omitted
}
This chapter’s sample application also has a business layer interface (UserFacade, defined in listing 18.2), which in turn deals with DTOs (data transfer objects), not the persistent objects directly. Therefore, we need a UserDto class (also defined in listing 18.2).
Listing 18.2. Business layer interface (UserFacade) and transfer object (UserDto)
public interface UserFacade {
UserDto getUserById(long id);
}
public class UserDto {
private long id;
private String username;
private String firstName;
private String lastName;
// getters and setters omitted
}
Finally, because the persistence layer will be developed using JPA, a new implementation (UserDaoJpaImpl) is necessary, and its initial version is shown in listing 18.3.[3]
3 The astute reader might be wondering why we listed UserDaoJpaImpl in this chapter but omitted UserDaoJdbcImpl in chapter 17. The reason is that the JPA implementation is much simpler, just a few lines of nonplumbing code.
Listing 18.3. Initial implementation of UserDao using JPA
public class UserDaoJpaImpl implements UserDao {
private EntityManager entityManager; // getters and setters omitted
public void addUser(User user) {
entityManager.persist(user);
}
public User getUserById(long id) {
return entityManager.find(User.class, id);
}
public void deleteUser(long id) {
String jql = "delete User where id = ?";
Query query = entityManager.createQuery(jql);
query.setParameter(1, id);
query.executeUpdate();
}
}
The sample application is available in two flavors, Maven and Ant. To run the tests on Maven, type 'mvn clean test'. Similarly, to use Ant instead, type 'ant clean test'. The application is also available as two Eclipse projects, one with the required libraries (under the lib directory) and another with the project itself.
18.1.2. Multiple layers, multiple testing strategies
Because each application layer has different characteristics and dependencies, the layers require different testing strategies. If your application has been designed to use interfaces and implementations, it’s possible to test each layer in isolation, using mocks or stubs to implement other layers’ interfaces.
In our example, the business layer façade (listing 18.4) will be tested using EasyMock as the implementation of the DAO interfaces, as shown in listing 18.5.
Listing 18.4. Façade implementation (UserFacadeImpl)
[...]
public class UserFacadeImpl implements UserFacade {
private static final String TELEPHONE_STRING_FORMAT = "%s (%s)";
private UserDao userDao; // getters and setters omitted
public UserDto getUserById(long id) {
User user = userDao.getUserById(id);
UserDto dto = new UserDto();
dto.setFirstName(user.getFirstName());
dto.setLastName(user.getLastName());
dto.setUsername(user.getUsername());
List<String> telephoneDtos = dto.getTelephones();
for ( Telephone telephone : user.getTelephones() ) {
String telephoneDto =
String.format(TELEPHONE_STRING_FORMAT,
telephone.getNumber(), telephone.getType());
telephoneDtos.add(telephoneDto);
}
return dto;
}
}
Listing 18.5. Unit test for UserFacadeImpl
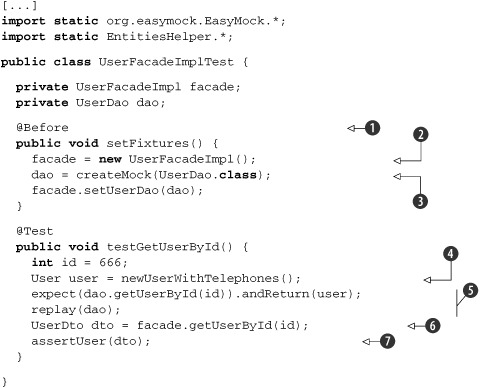
Before the test is run, we prepare the fixtures ![]() that will be used in the test methods, the object being tested
that will be used in the test methods, the object being tested ![]() , and a mock
, and a mock ![]() . Even if you have only one test method (as is the case in this example), eventually more will be added, so it’s worth having such a setup method from the beginning.
. Even if you have only one test method (as is the case in this example), eventually more will be added, so it’s worth having such a setup method from the beginning.
Then, on the test case we create a User object ![]() and set the mock expectation
and set the mock expectation ![]() to return it when requested (see more about mock expectations in chapter 6). Notice that newUser() belongs to EntitiesHelper, which provides methods to create new entities (like User) and assert the properties of existing ones (EntitiesHelper was introduced in chapter 17, and new methods are added in this chapter; the full code isn’t listed here but is available for download).
to return it when requested (see more about mock expectations in chapter 6). Notice that newUser() belongs to EntitiesHelper, which provides methods to create new entities (like User) and assert the properties of existing ones (EntitiesHelper was introduced in chapter 17, and new methods are added in this chapter; the full code isn’t listed here but is available for download).
Finally, on ![]() the method being tested is called, and the result is checked on
the method being tested is called, and the result is checked on ![]() (which is another method defined in EntitiesHelper).
(which is another method defined in EntitiesHelper).
This test case seems pretty much complete, and it almost is, except that it exercises only the best-case scenario. But what if the DAO didn’t find the request user? To be complete, the test cases must also exercise negative scenarios. Let’s try to add a new test case that simulates the DAO method returning null:[4]
4 How do we know the DAO returns null in this case? And who defined what the Facade should return? What happens in these exceptional cases should be documented in the DAO and Facade methods’ Javadoc, and the test cases should follow that contract. In our example, we don’t document that on purpose, to show how serious that lack of documentation can be. Anyway, we’re returning null in both cases, but another approach could be throwing an ObjectNotFoundException.
@Test
public void testGetUserByIdUnknownId() {
int id = 666;
expect(dao.getUserById(id)).andReturn(null);
replay(dao);
UserDto dto = facade.getUserById(id);
assertNull(dto);
}
Running this test, we get the dreaded NPE (NullPointerException):
java.lang.NullPointerException
at com.manning.junitbook.ch18.business.UserFacadeImpl.getUserById(UserFacade Impl.java:49)
at com.manning.junitbook.ch18.business.UserFacadeImplTest.testGetUserById
This makes sense, because the Facade method isn’t checking to see if the object return by the DAO is null. It could be fixed by adding the following lines after the user is retrieved from the DAO:
if ( user == null ) {
return null;
}
Once this test case is added and the method fixed, our Facade is complete and fully tested, without needing a DAO implementation.
Such separation of functionalities in interfaces and implementations greatly facilitates the development of multilayered applications, because each layer can be developed in parallel, by different teams. Using this approach, the whole business layer could be developed and unit tested without depending on the persistence layer, which would free the business developers from database worries. It’s still necessary to test everything together though, but that could be achieved through integration tests. A good compromise is to write many small (and fast) unit tests that extensively exercise individual components and then a few (and slower) integration tests that cover the most important scenarios.
Similarly, we could test the persistence layer using mocks for the JPA interfaces. But this approach isn’t recommended, because mocks only emulate API calls, and that wouldn’t be enough, for a few reasons. First, the API is part of JPA-based development; it’s still necessary to annotate classes and provide configuration files. Second, even if the JPA part is correctly configured, there are still third parties involved: the JPA vendor (like Hibernate), the vendor’s driver (such as HibernateDialect implementations) for the database being used, not to the mention the database itself. Many things could go wrong (like vendor or drivers bugs, the use of table names that are illegal for a given database, transaction issues, and the like) at runtime that wouldn’t be detected by using mocks for testing.
In a JPA-based application, it’s paramount to start and commit transactions, and the methods that use an EntityManager have two options: either they handle the transactions themselves, or they rely on the upper layers for this dirty job. Typically, the latter option is more appropriate, because it gives the caller the option to invoke more than one DAO method in the same transaction. Looking at our examples, UserDaoJpaImpl follows this approach, because it doesn’t deal with transaction management. But if you look at its caller, UserFacadeImpl, it doesn’t handle transactions either! So, in our application example, who is responsible for transaction management?
The answer is the container. In our examples, we’re showing pieces of an application. But in a real project, these pieces would be assembled by a container, like a Java EE application server or Spring, and this container would be responsible for wrapping the Facade methods inside a JPA transaction and propagating it to the DAO object. In our DAO test cases, we play the role of the container and explicitly manage the transactions.
For the persistence layer, it’s important to test real access to the database, as we demonstrate in the next section.
18.2. Aspects of JPA testing
When you use JPA (or any other ORM software) in your application, you’re delegating the task of persisting objects to and from the database to an external tool. But in the end, the results are the same as if you wrote the persistence code yourself. So, in its essence, JPA testing isn’t much different than testing regular database access code, and hence most of the techniques explained in chapter 17 apply here. A few differences and caveats are worth mentioning though, and we cover them in the next subsections. But first, let’s consider some aspects of JPA testing.
What Should Be Tested?
JPA programming could be divided in two parts: entities mapping and API calls. Initially, you need to define how your objects will be mapped to the database tables, typically through the use of Java annotations. Then you use an EntityManager object to send these objects to or from the database: you can create objects, delete them, fetch them using JPA queries, and so on.
Consequently, it’s a good practice to test these two aspects separately. For each persistent object, you write a few test cases that verify that they’re correctly mapped (there are many caveats on JPA mapping, particularly when dealing with collections). Then you write separate unit tests for the persistence code itself (such as DAO objects). We present practical examples for both tests in the next subsections.
The Embedded Database Advantage
As we mentioned in section 17.1.3, unit tests must be fast to run, and database access is typically slow. A way to improve the access time is to use an in-memory embedded database, but the drawback is that this database might not be totally compatible with the database the application uses.
But when you use JPA, database compatibility isn’t an issue—quite the opposite. The JPA vendor is responsible for SQL code generation,[5] and vendors typically support all but the rarest databases. It’s perfectly fine to use a fast embedded database (like HSQLDB or its successor, H2) for unit tests. Better yet, the project should be set in such a way that the embedded database is used by default, but databases could be easily switched. That would take advantage of the best of both worlds: developers would use the fast mode, whereas official builds (like nightly and release builds) would switch to the production database (guaranteeing the application works in the real scenario).
5 This is the ideal scenario; some applications might still need to manually issue a few SQL commands because of JPA bugs or performance requirements. These cases are rare, though, and they could be handled separately in the test cases.
Commitment Level
JPA operations should happen inside a transaction, which typically also translates to a vendor-specific session. A lot of JPA features and performance depends on the transaction/session lifecycle management: objects are cached, new SQL commands are issued on demand to fetch lazy relationships, update commands are flushed to the database, and so on.
On the other hand, committing a transaction is not only an expensive operation, but it also makes the database changes permanent. Because of that, there’s a tendency for test cases to roll back the transaction on teardown, and many frameworks (such as Spring TestContext) follow this approach.
So what is the better approach, to commit or not? Again, there’s no secret ingredient, and each approach has its advantages. We, in particular, prefer the commit option, because of the following aspects:
- If you’re using an embedded database, speed isn’t an issue. You could even recreate the whole database before each test case.
- As we mention in section 18.8.5, test cases can do cleanup on teardown when necessary. And again, when using an embedded database, the cleanup is a cheap operation.
- If you roll back the transaction, the JPA vendor might not send the real SQL to the database (for instance, Hibernate issues the SQL only at commit or if session.flush() is explicitly called). There might be cases where your test case passes, but when the code is executed in real life, if fails.
- In some situations, you want to explicitly test how the persistent objects will behave once outside a JPA transaction/session.
For these reasons, the test cases in this chapter manually handle the transaction’s lifecycle.
Now, without further ado, let’s start testing it.
18.3. Preparing the infrastructure
Okay, we lied: before our first test, we need some more ado! More specifically, we need to define the infrastructure classes that our real test case classes will extend (remember section 17.3’s best practice: define a superclass for your database tests). Figure 18.1 shows the class diagram for such infrastructure.
Figure 18.1. Class diagram of the testing infrastructure
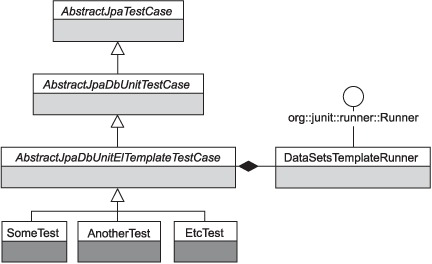
The infrastructure class hierarchy depicted in figure 18.1 is quite similar to the one used in chapter 17. The only difference is the root class, AbstractJpaTestCase, which is shown in listing 18.6.
Listing 18.6. Root class of testing infrastructure, AbstractJpaTestCase

| The first step is to create an EntityManagerFactory, and as this is an expensive operation, it’s done only once, using the @Before annotation. Notice that this initialization doesn’t contain any information about the JPA provider (Hibernate) or database (HSQLDB) used in the test case. That information is defined in the persistence.xml and hibernate.properties files (shown in listings 18.7 and 18.8, respectively). | |
| Although when you use JPA you don’t need to deal with low-level JDBC interfaces directly, DbUnit needs a database connection. You could define the JDBC settings for this connection in a properties file, but that would be redundant; it’s better to extract the JDBC connection from JPA’s entity manager. Also notice that such reuse is the reason why this chapter’s AbstractJpaDbUnitTestCase (which isn’t shown here either, but is the same as chapter’s 17 AbstractDbUnitTestCase) extends AbstractJpaTestCase, and not vice versa. If @BeforeClass methods didn’t have to be static, such reversal of fortune wouldn’t be necessary: AbstractJpaDbUnitTestCase could define a protected getConnection() method, which in turn would be overridden by AbstractJpaTestCase. | |
| Don’t forget to close at @After what you opened at @Before! | |
| The EntityManager, which is the object effectively used by the test cases, is created before each test method and closed thereafter. This is the way JPA is supposed to be used, and this object creation is cheap. | |
| Unfortunately, there’s no standard way to extract the JDBC Connection from the JPA EntityManagerFactory, so it’s necessary to use proprietary APIs from the chosen JPA vendors. | |
| Because our test cases will manually manage transactions, it’s convenient to create helper methods for this task. | |
| Similarly, some test cases will test how objects behave outside the JPA context, so we define an overloaded commitTransaction(), which also clears the context. |
The JPA configuration is quite simple: persistence.xml (listing 18.7) only defines a persistence-unit name, and the vendor-specific configuration is defined in hibernate.properties (listing 18.8). Such a split is a good practice, because if the test cases must change any configuration (as you’ll see later on), we could create a new hibernate.properties file in the test directories, without interfering with the artifacts used by the production code. Notice also that we set the property hibernate.hbm2ddl.auto to update, so the test cases don’t need to create the database tables (Hibernate will automatically create or update the database schema as needed).
Listing 18.7. JPA configuration (persistence.xml)
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=
"http://java.sun.com/xml/ns/persistence persistence_1_0.xsd"
version="1.0">
<persistence-unit name="chapter-18">
<!-- properties are loaded from a separate file, and classes are
scanned through annotations -->
</persistence-unit>
</persistence>
Listing 18.8. Hibernate-specific configuration (hibernate.properties)
hibernate.hbm2ddl.auto=update
hibernate.show_sql=false
hibernate.dialect=org.hibernate.dialect.HSQLDialect
hibernate.connection.driver_class=org.hsqldb.jdbcDriver
hibernate.connection.url=jdbc:hsqldb:mem:my-project-test;shutdown=true
As a final note, some frameworks—such as Spring and Unitils (which we cover in the next chapter)—already provide a similar setup. So even though this infrastructure is based on real projects (it was not created for the book samples), provides flexibility (and can be adapted to your project needs), and is simple enough (just a few classes), you might prefer—or it might be more suitable for your project—to use such frameworks instead.
Now that the infrastructure is set, let’s move on to our tests, starting with the JPA entity mapping tests.
18.4. Testing JPA entities mapping
The first step in JPA development is mapping your objects to tables. Although JPA does a good job of providing default values for most mappings, it’s still necessary to tune it up, typically through the use of Java annotations. And as you annotate the persistent classes, you want to be sure they’re correctly mapped, so you write test cases that exercise the mapping alone (without worrying about how your final code is going to call the JPA API).
You might be wondering whether these tests are necessary. What could be wrong?
Unfortunately, despite the fact that JPA is a powerful and helpful tool, many things could be wrong in the mappings, and the sooner you figure it out, the better, for instance:
- Some table or column name (like user, role, or group) might be a reserved word in the chosen database.
- If you don’t set the relationship annotations (like @OneToMany) correctly, JPA will create many weird mappings, sometimes even unnecessary tables.
- When dependent objects must be persisted automatically, it’s important to verify that the proper cascade options have been set.
Not to mention the mother of all reasons why you write unit tests: you need to somehow verify that JPA is persisting/restoring your objects! Without the entity mapping tests, you’d have to either rely on your IDE or manually test it using the main() method of some hacky class.
In order to avoid these issues, it’s a good practice to write a couple (at least two: one for loading, another for saving) of unit tests for each primary persistent entity in the system. You don’t need to write tests for all of them, though. Some entities are too simple or can be indirectly tested (like the Telephone entity in our examples).
Also, because the load and save tests are orthogonal, they should use the same dataset whenever possible, to facilitate maintenance; listing 18.9 shows the dataset used in the user entity mapping tests (listing 18.10).
Listing 18.9. Dataset file for User and Telephone tests, user-with-telephone.xml
<?xml version="1.0"?>
<dataset>
<users id="${id}" username="ElDuderino"
first_name="Jeffrey" last_name="Lebowsky" />
<phones id="${phoneId}" user_id="${id}" type="0" number="481 516-2342"/>
<phones id="${phoneId+1}" user_id="${id}" type="2"
number="108 555-6666"/>
</dataset>
Notice that the IDs are dynamically defined using EL expressions, so the test cases succeed regardless of the order in which they’re executed.
Listing 18.10. Entity mapping unit tests for User and Telephone classes

Although these tests run fine and pass, the way the IDs (id and phoneId) are handled is far from elegant and presents many flaws. For instance, if a test case fails, the IDs aren’t updated, and then other tests running after it will fail as well. Sure, a try/ finally block would fix this particular issue, but that would make the test even uglier and more verbose. Another problem is that testSaveUserWithTelephone() doesn’t update the IDs (because its dataset assertion would fail), so a third test case would probably fail.
What should we do to solve these ID issues? Well, don’t throw the book away (yet)—a solution for this problem follows.
18.4.1. Integrating test cases with JPA ID generators
In JPA, every persistent entity needs an ID, which is the equivalent of a primary key. When a new entity is persisted, the JPA engine must set its ID, and how its value is determined depends on the mapping. For instance, our User class has the following mapping:
@Id @GeneratedValue(strategy=GenerationType.AUTO)
private long id;
The @Id annotation indicates this attribute represents the entity’s primary key, and @GeneratedValue defines how its value is obtained when the entity is persisted. AUTO in this case means we left the decision to the JPA vendor, which will pick the best strategies depending on what the target database supports. Other values are IDENTITY (for databases that support autogenerated primary keys), SEQUENCE (uses database sequences, where supported), and TABLES (uses one or more tables only for the purpose of generating primary keys). A fifth option would be omitting @GeneratedValue, which means the user (and not the JPA engine) is responsible for setting the IDs. In most cases, AUTO is the best choice; it’s the default option for the @GeneratedValue annotation.
Back to our test cases, the dataset files contain references to the ID columns (both as primary key in the users table and foreign key on telephones), and because we’re using the same dataset for both load and save, the ID values must be defined dynamically at the time the test is run. If we used distinct datasets, the IDs wouldn’t matter on the load test (because JPA wouldn’t be persisting entities, only loading them), and for the save tests, we could ignore them. The problem with this option is that it makes it harder to write and maintain the test cases. It would require two datasets and also changes in the DataSetsTemplateRunner.assertDataSet() method in order to ignore the ID columns. Because our goal is always to facilitate long-term maintenance, we opted for using the same dataset, and hence we need a solution for the ID synchronization problem.
Listing 18.10 tried to solve the problem the simplest way, by letting the test case update the IDs, but that approach had many issues. A better approach is to integrate the dataset ID’s maintenance with the JPA’s entity ID’s generation, and there are two ways to achieve such integration: taking control of ID generation or being notified of the generated IDs.
Generating IDs for persistent objects isn’t a simple task, because there are many complex aspects to be taken into account, such as concurrent ID generation in different transactions. Besides, when you use this approach, your test cases won’t be reflecting the real application scenario (and hence they could hide potential problems). For these reasons, we choose the second approach: being notified of the generated IDs.
Using pure JPA, it’s possible to define a listener for entity lifecycle events (like object creation, update, and deletion). But this approach doesn’t work well in our case, because these events don’t provide a clear way to obtain the ID of the saved objects. A better solution is to use vendor-specific extensions.
Hibernate provides its own API for lifecycle events, with listeners for many pre and post events. In particular, it provides a PostInsertEventListener interface with an onPostInsert(PostInsertEvent event) method, and the event itself contains a reference to both the entity inserted and the generated ID.
The PostInsertEventListener API solves part of our problem: our test cases now can be notified of the IDs generated for each object. Good, but now what? Well, the answer relies on our good, old friend EL (Expression Language, introduced in chapter 17, section 17.7.3). So far, we’ve been using simple variable resolution (like ${id}) on our datasets. But EL also supports function resolution, so we could have a function that returns an ID for a given class and then use a PostInsertEventListener to set the values returned by the function. Let’s start with the new dataset, shown in listing 18.11.
Listing 18.11. New version of user-with-telephone.xml dataset, using EL functions
<dataset>
<users id="${db:id('User')}" username="ElDuderino"
first_name="Jeffrey" last_name="Lebowsky" />
<phones id="${db:id('Telephone')}" user_id="${db:id('User')}" type="0"
number="481 516-2342"/>
</dataset>
Instead of using hardcoded IDs for each class (like ${id} and ${phoneId}), this new version uses a generic ${db:id('ClassName')} function, which is much more flexible. The db:id() function then returns the respective ID for a given class, which is either the value defined by the Hibernate listener or 1 by default (which means no entity has been generated by JPA for that class. In this case the value doesn’t matter, but using 1 makes it easier to debug in case of errors). To add support for this function, first we need to change ELContextImpl to support function mapping, as shown in listing 18.12.
Listing 18.12. Changes to ELContextImpl to support the id function
[...]
public final class ELContextImpl extends ELContext {
[...]
private FunctionMapper functionMapper = new ELFunctionMapperImpl();
[...]
@Override
public FunctionMapper getFunctionMapper() {
return functionMapper;
}
[...]
}
The ID function itself is defined at ELFunctionMapperImpl, shown in listing 18.13.
Listing 18.13. Custom EL functions (ELFunctionMapperImpl)

The next step is the Hibernate integration. But first we need a listener, as defined in listing 18.14.
Listing 18.14. Custom Hibernate event listener (ELPostInsertEventListener)

In order to simplify the datasets, only the simple name ![]() of the class is used, not the whole fully qualified name (otherwise, the datasets would need something like ${db:id('com.manning.jia.chapter18.model.User')}). If your project has more than one class with the same name (but in different packages), then you’ll need some workaround
here, but keeping the simple class name should be enough most of the time (and having multiple classes with the same name
isn’t a good practice anyway).
of the class is used, not the whole fully qualified name (otherwise, the datasets would need something like ${db:id('com.manning.jia.chapter18.model.User')}). If your project has more than one class with the same name (but in different packages), then you’ll need some workaround
here, but keeping the simple class name should be enough most of the time (and having multiple classes with the same name
isn’t a good practice anyway).
Next, we change hibernate.properties to add the custom listener, by including the following property:
hibernate.ejb.event.post-insert=
Notice that when you set the listeners for a lifecycle event in the properties, you’re defining all listeners, not just adding new ones. Therefore, it’s recommended to keep the default Hibernate listeners. But Hibernate doesn’t clearly document what these listeners are, so you need to figure that out by yourself, and one way of doing that is by changing the setEntityManager(), as shown in listing 18.15.
Listing 18.15. Changes on setEntityManager() to show Hibernate listeners
[...]
public abstract class AbstractJpaTestCase {
[...]
@Before
public void setEntityManager() {
em = entityManagerFactory.createEntityManager();
// change if statement below to true to figure out the Hibernate
// listeners
if ( false ) {
Object delegate = em.getDelegate();
SessionImpl session = (SessionImpl) delegate;
EventListeners listeners = session.getListeners();
PostInsertEventListener[] postInsertListeners =
listeners.getPostInsertEventListeners();
for ( PostInsertEventListener listener : postInsertListeners ) {
System.out.println("Listener: " + listener.getClass().getName() );
}
}
}
}
Finally, it’s necessary to change the test case classes: first the infrastructure classes (as shown in listing 18.16) and then the test methods themselves (listing 18.17).
Listing 18.16. Changes on AbstractJpaDbUnitELTemplateTestCase

| Although not shown here, superclass AbstractJpaDbUnitTestCase also changed; it doesn’t need to keep track of the IDs anymore, so id and phoneId were removed. | |
| This method now is also simpler than before. Instead of binding the id variable to the EL context before and after invoking the test, it resets the ID’s map before each test is run. |
Listing 18.17. New version of EntitiesMappingTest using JPA ID’s integration

Because IDs aren’t tracked by a superclass anymore, it’s necessary to ask ELFunctionMapperImpl ![]() to get the ID on testLoadUserWithTelephone(). Test case testSaveUserWithTelephone()
to get the ID on testLoadUserWithTelephone(). Test case testSaveUserWithTelephone() ![]() , on the other hand, was not changed, because it doesn’t use the IDs directly (only in the dataset).
, on the other hand, was not changed, because it doesn’t use the IDs directly (only in the dataset).
18.5. Testing JPA-based DAOs
Once you’re assured the persistence entities are correctly mapped, it’s time to test the application code that effectively uses JPA, such as DAOs. The test cases for JPA-based DAOs are similar to the entity mapping tests you saw in the previous section; the main difference (besides the fact that you use DAO code instead of direct JPA calls) is that you have to cover more scenarios, paying attention to some tricky issues.
Let’s start with the simplest cases, the same cases for getUserById() and addUser() we implemented in chapter 17 (where the DAOs were implemented using pure JDBC), plus a test case for testRemoveUser(). The test cases are shown in listing 18.18, and the initial DAO implementation was shown in listing 18.4.
Listing 18.18. Initial version of UserDaoJpaImplTest
[...]
public class UserDaoJpaImplTest extends AbstractJpaDbUnitELTemplateTestCase {
UserDaoJpaImpl dao;
@Before
public void prepareDao() {
dao = new UserDaoJpaImpl();
dao.setEntityManager(em);
}
@Test
@DataSets(setUpDataSet="/user.xml")
public void testGetUserById() throws Exception {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class);
User user = dao.getUserById(id);
commitTransaction();
assertUser(user);
}
@Test
@DataSets(assertDataSet="/user.xml")
public void testAddUser() throws Exception {
beginTransaction();
User user = newUser();
dao.addUser(user);
commitTransaction();
long id = user.getId();
assertTrue(id>0);
}
@Test
@DataSets(setUpDataSet="/user.xml",assertDataSet="/empty.xml")
public void testDeleteUser() throws Exception {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class);
dao.deleteUser(id);
commitTransaction();
}
}
Compare this test case with chapter 17’s latest version (listing 17.24) of the equivalent test; they’re almost the same, the only differences being the pretest method prepareDao() (which instantiates a DAO object and sets its EntityManager), the local variable representing the user’s ID (because of the Hibernate ID generation integration we discussed in the previous section), and the transaction management calls.
But now the User object could also have a list of telephones; it’s necessary, then, to add analogous test cases to handle this scenario, as shown in listing 18.19. Note that if the User/Telephone relationship was mandatory (and not optional), the new tests would replace the old ones (instead of being added to the test class).
Listing 18.19. New test cases on UserDaoJpaImplTest to handle user with telephone
[...]
public class UserDaoJpaImplTest extends AbstractJpaDbUnitELTemplateTestCase {
[...]
@Test
@DataSets(setUpDataSet="/user-with-telephone.xml")
public void testGetUserByIdWithTelephone() throws Exception {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class);
User user = dao.getUserById(id);
commitTransaction();
assertUserWithTelephone(user);
}
@Test
@DataSets(assertDataSet="/user-with-telephone.xml")
public void testAddUserWithTelephone() throws Exception {
beginTransaction();
User user = newUserWithTelephone();
dao.addUser(user);
commitTransaction();
long id = user.getId();
assertTrue(id>0);
}
@Test
@DataSets(setUpDataSet="/user-with-telephone.xml",
assertDataSet="/empty.xml")
public void testDeleteUserWithTelephone() throws Exception {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class);
dao.deleteUser(id);
commitTransaction();
}
}
Running these tests will expose the first bug in the DAO implementation, because testDeleteUserWithTelephone() fails with a constraint violation exception. Although the user row was deleted, its telephone wasn’t. The reason? Cascade deletes are taken into account only when the EntityManager’s remove() method is called, and our DAO used a JPA query to delete the user. The fix is shown in listing 18.21.
Regardless of this delete issue, the tests presented so far cover only the easy scenarios: saving, loading, and deleting a simple user, with or without a telephone. It’s a good start but not enough; we need to test negative cases as well.
For the addUser() method, the only negative case is receiving a null reference. It’s always a good practice to check for method arguments and throw an Illegal-AccessArgumentExeption if they don’t comply. The getUserById() method has at least two negative cases: handling an ID that doesn’t exist in the database and loading from an empty database. In our sample application, a null reference should be returned in these cases (but another valid option would be to throw an exception). Negative cases for removeUser() would be the same as for getUserById(), and in our example they don’t need to be tested because nothing happens when the user doesn’t exist (if an exception should be thrown, we should exercise these scenarios). Listing 18.20 adds these new tests.
Listing 18.20. New test cases for negative scenarios
[...]
public class UserDaoJpaImplTest extends AbstractJpaDbUnitELTemplateTestCase {
[...]
@Test(expected=IllegalArgumentException.class)
public void testAddNullUser() throws Exception {
dao.addUser(null);
}
@Test
public void testGetUserByIdOnNullDatabase() throws Exception {
getUserReturnsNullTest(0);
}
@Test
@DataSets(setUpDataSet="/user.xml")
public void testGetUserByIdUnknownId() throws Exception {
getUserReturnsNullTest(666);
}
private void getUserReturnsNullTest(int deltaId) {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class)+deltaId;
User user = dao.getUserById(id);
commitTransaction(true);
assertNull(user);
}
}
Notice that the workflow for getUserById() negative cases is the same for both scenarios, so we used a private helper method (getUserReturnsNullTest()) on both.
Now we have a fully tested DAO implementation, right? Well, not really. Once you put this code into production (or hand it to the QA team for functional testing), a few bugs are bound to happen.
To start with, the first time someone calls UserFacade.getUserById() (which in turn calls the DAO method; see listing 18.4) on a user that has at least one telephone and tries to call user.getTelephones(), the following exception will occur:
org.hibernate.LazyInitializationException: failed to lazily initialize
at org.hibernate.collection.AbstractPersistentCollection.throwLazy
at org.hibernate.collection.AbstractPersistentCollection.
at org.hibernate.collection.AbstractPersistentCollection.
at org.hibernate.collection.PersistentBag.size(PersistentBag.java:225)
at com.manning.jia.chapter18.model.EntitiesHelper.
at com.manning.jia.chapter18.model.EntitiesHelper.assertUserWithTelephone
at com.manning.jia.chapter18.dao.UserDaoJpaImplTest.testGetUserByIdWith
When that happens, you, the developer, are going to curse Hibernate, JPA, ORM, and (with a higher intensity) this book’s authors: you followed our advice and created unit tests for both the Façade and DAO classes in isolation, but once one called the other in real life, a JPA exception arose! Unfortunately, situations like these are common. Just because you wrote test cases, it doesn’t mean your code is bug free. But on the bright side, because you have a test case, it’s much easier to reproduce and fix the issue. In this case, the exception is caused because the User/Telephone relationship is defined as lazy, which means the telephones were not fetched by the JPA queries and are loaded on demand when getTelephones() is called. But if that method is called outside the JPA context, an exception is thrown. So, to simulate the problem in the test case, we change testGetUserByIdWithTelephone() to clear the context after committing the transaction:
@Test
@DataSets(setUpDataSet="/user-with-telephone.xml")
public void testGetUserByIdWithTelephone() throws Exception {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class);
User user = dao.getUserById(id);
commitTransaction(true);
assertUserWithTelephone(user);
}
Running the test case after this change fails because of the same exception our poor user faced in the real application. The solution then is to fix the JPA query to eagerly fetch the telephones, as shown here:
public User getUserById(long id) {
String jql = "select user from User user left join fetch " +
"user.telephones where id = ?";
Query query = entityManager.createQuery(jql);
query.setParameter(1, id);
return (User) query.getSingleResult();
}
Such a change allows testGetUserByIdWithTelephone() to pass, but now testGetUserByIdOnNullDatabase() and testGetUserByIdUnknownId() fail:
javax.persistence.NoResultException: No entity found for query
at org.hibernate.ejb.QueryImpl.getSingleResult(QueryImpl.java:83)
at com.manning.jia.chapter18.dao.UserDaoJpaImpl.
Let’s change the method again, using getResultList() instead of getSingleResult():
public User getUserById(long id) {
String jql = "select user from User user left join fetch " +
"user.telephones where id = ?";
Query query = entityManager.createQuery(jql);
query.setParameter(1, id);
@SuppressWarnings("unchecked")
List<User> users = query.getResultList();
// sanity check
assert users.size() <= 1 : "returned " + users.size() + " users";
return users.isEmpty() ? null : (User) users.get(0);
}
Although the change itself is simple, this issue illustrates the importance of negative tests. If we didn’t have these tests, the lazy-initialization fix would have introduced a regression bug!
Once these two fixes are in place, the application will run fine for awhile, until a user has two or more telephones, which would cause the following exception:
java.lang.AssertionError: returned 2 users
at com.manning.jia.chapter18.dao.UserDaoJpaImpl.getUserById
at com.manning.jia.chapter18.dao.UserDaoJpaImplTest.
What’s happening now is that a query that was supposed to return one user is returning two—weird!
But again, because the testing infrastructure is already in place, it’s easy to reproduce the problem. All we have to do is add a new testGetUserByIdWithTelephones() method:[6]
6 We also need a new assertUserWithTelephones() method on EntitiesHelper and a new user-with-telephones.xml dataset, but because they’re very similar to the existing method and dataset, they aren’t shown here.
@Test
@DataSets(setUpDataSet="/user-with-telephones.xml")
public void testGetUserByIdWithTelephones() throws Exception {
beginTransaction();
long id = ELFunctionMapperImpl.getId(User.class);
User user = dao.getUserById(id);
commitTransaction(true);
assertUserWithTelephones(user);
}
What about the issue itself? The solution is to use the distinct keyword in the query, as shown here:
jql = "select distinct(user) from User user left join fetch " +
"user.telephones where id = ?";
Notice that having both testGetUserByIdWithTelephone() and testGetUserByIdWithTelephones() methods is redundant and would make the test cases harder to maintain. Once we add testGetUserByIdWithTelephones(), we can safely remove testGetUserByIdWithTelephone() and its companion helpers newUserWithTelephone() and assertUserWithTelephone(), which would be replaced by newUserWithTelephones() and assertUserWithTelephones(), respectively.
Listing 18.21 shows the final version of UserDaoJpaImpl, with all issues fixed.
Listing 18.21. Final (and improved) version of UserDaoJpaImpl
[...]
public class UserDaoJpaImpl implements UserDao {
public void addUser(User user) {
if ( user == null ) {
throw new IllegalArgumentException("user cannot be null");
}
entityManager.persist(user);
}
public User getUserById(long id) {
String jql = "select distinct(user) from User user left join fetch " +
"user.telephones where id = ?";
Query query = entityManager.createQuery(jql);
query.setParameter(1, id);
@SuppressWarnings("unchecked")
List<User> users = query.getResultList();
// sanity check assertion
assert users.size() <= 1 : "returned " + users.size() + " users";
return users.isEmpty() ? null : (User) users.get(0);
}
public void deleteUser(long id) {
User user = entityManager.find(User.class, id);
entityManager.remove(user);
}
}
18.6. Testing foreign key names
When the first version of testDeleteUserWithTelephone() failed, the error message was
Integrity constraint violation FKC50C70C5B99FE3B2 table:
Because we’re just starting development, it’s easy to realize that the violated constraint is the telephones foreign key on the users table. But imagine on down the road you face a bug report with a similar problem—would you know what constraint FKC50C70C5B99FE3B2 refers to?
By default, Hibernate doesn’t generate useful names for constraints, so you get gibberish like FKC50C70C5B99FE3B2. Fortunately, you can use the @ForeignKey annotation to explicitly define the FK names, as we did in the User class (see listing 18.1). But as more entities are added to the application, it’s easy for a developer to forget to use this annotation, and such a slip could stay undetected for months, until the application is hit by a foreign key violation bug (whose violated constraint would be a mystery).
As you can imagine, there’s a solution for this problem: writing a test case that verifies that all generated foreign keys have meaningful names. The skeleton for this test is relatively simple: you ask Hibernate to generate the schema for your application as SQL statements and then check for invalid foreign key names. The tricky part is how to generate the SQL code in a string, using only the project JPA settings. We present a solution in the listing below, and although it isn’t pretty, it gets the work done.[7] Anyway, let’s look at the test case by itself first, in listing 18.22.
7 We could do further diligence and present a more elegant solution, because this is a book (and hence educational). But when you’re writing unit tests in real life, many times you have to be pragmatic and use a quick-and-dirty solution for a given problem, so we decided to take this approach here as well.
Listing 18.22. Test case for Hibernate-generated database schema (SchemaTest.java)

This test case relies on a new infrastructure method, analyzeSchema(), which is defined in AbstractJpaTestCase; listing 18.23 shows all changes required to implement it.
Listing 18.23. Changes on AbstractJpaTestCase to support analyzeSchema()

| analyzeSchema() is based on the Template Design Pattern (see section 17.7.1). It knows how to create a Java string containing the database schema but doesn’t know what to do with it, so it passes this string to a SqlHandler, which was passed as a parameter. | |
| SchemaExport is the Hibernate class (part of the Hibernate Tools project) used to export the schema. It requires a Hibernate Properties object, which unfortunately can’t be obtained from EntityManager or EntityManagerFactory, the objects our test case has references to. To overcome this limitation, we need our first hack: using an Ant task (JPAConfigurationTask), which is also part of Hibernate Tools. | |
| This is where the schema is effectively generated. The problem is, SchemaExport either exports it to the system output or to a file. Ideally, it should allow the schema to be exported to a Writer or OutputStream object, so we could pass a StringWriter as a parameter to this method. Because this isn’t the case, we have to use a second hack: replace the System.out when this method is executed and then restore it afterwards. Yes, we know this is ugly, but we warned you. | |
| A final hack: because JPAConfigurationTask’s createConfiguration() method is protected, our test case won’t have access to it, so we create a subclass and override that method, making it accessible to classes in the same package. |
18.7. Summary
Using ORM tools (such as Hibernate and JPA) greatly simplifies the development of database access code in Java applications. But regardless of how great the technology is or how much it automates the work, it’s still necessary to write test cases for code that uses it.
A common practice among Java EE applications is to use Façades and DAOs in the business and persistence layers (respectively). In this chapter, we showed how to test these layers in isolation, using mocks as DAO implementation.
We also showed how to leverage DbUnit and advanced techniques to effectively test the JPA-based persistence layer, first testing the entity mappings and then the DAOs, properly speaking. We also demonstrated how to use JPA-generated IDs in your DbUnit datasets.
And although JPA testing is an extension of database testing (which was covered in chapter 17), it has its caveats, such as lazy initialization exceptions, duplicated objects returned in queries, cascade deletes, and generation of weird constraint names. The examples in this chapter demonstrated how to deal with such issues.