
State flapping is a situation where a host or service changes states very rapidly, constantly switching between working correctly and not working. This can happen due to various reasons; a service might crash after a short period of operating correctly or due to some maintenance work being done by system administrators.
Nagios can detect that a host or service state is flapping if it is configured to do so. It does so by analyzing previous results in terms of how many state changes have taken place within a specific period of time. Nagios keeps a history of the 21 most recent checks and analyzes changes within that history.
The following is a screenshot illustrating the 21 most recent check results, which means that Nagios can detect up to 20 state changes in the recent history of an object. It also shows how Nagios detects state transitions:
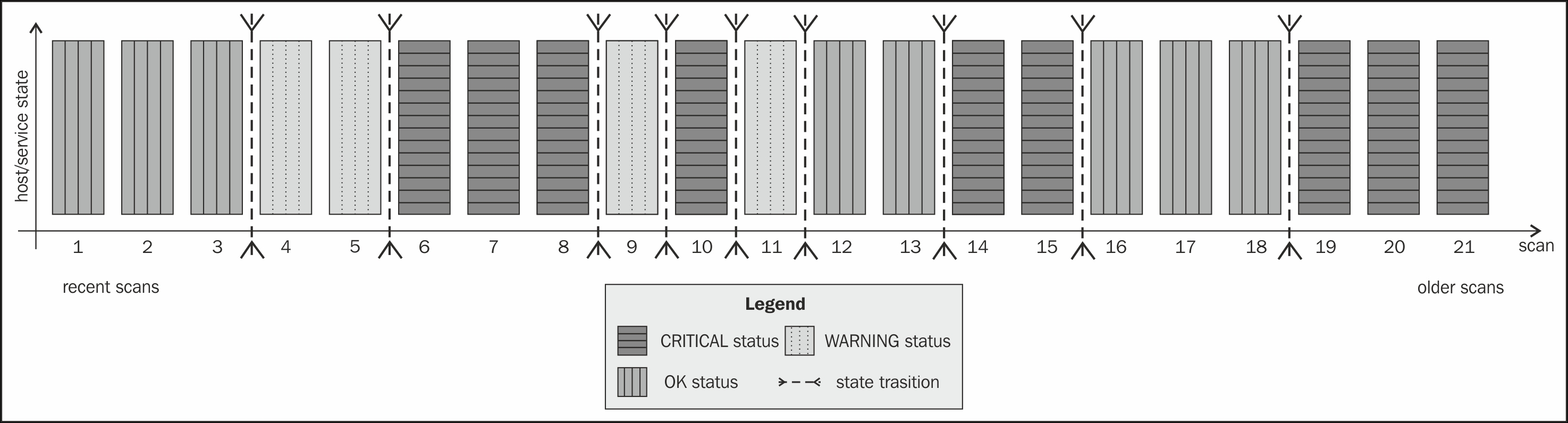
Nagios then finds all of the changes between different states and uses them to determine if a host or service state is flapping. It checks to see if a state is the same as the result from the previous check, and if it has changed, a state transition is counted at this place. In the preceding example, we have nine transitions.
Nagios calculates a flapping threshold based on this information. The value reflects how many of the state changes have occurred recently. If there are no changes in the last 21 state checks, the value would be 0 percent. If all checks have different states, the flapping threshold would be 100 percent.
In our case, if Nagios would only take the number of transitions into account, the flapping threshold would be 45 percent. The weighted algorithm used in Nagios would calculate the flapping threshold as more than 45 percent because there have been many changes in the more recent checks.
Nagios takes threshold values into consideration when estimating whether a host or service has started or stopped flapping. The configuration for each object allows the definition of high and low flapping thresholds.
If an object state was not flapping previously, and the current flapping threshold is equal to or greater than the high flap threshold, Nagios assumes that the object has just started flapping. If an object was flapping previously and the current threshold is lower than the low flap threshold, Nagios assumes the object has just stopped flapping.
The following chart shows how the flapping threshold for an object has changed over time and when Nagios flapping detection assumes it has been flapping. In this case, the high flap threshold is set to 40 percent and the low flap threshold is set to 25 percent. The vertical lines indicate when Nagios assumed the flapping to have started and stopped, and the gray area shows where the service was assumed to be flapping:
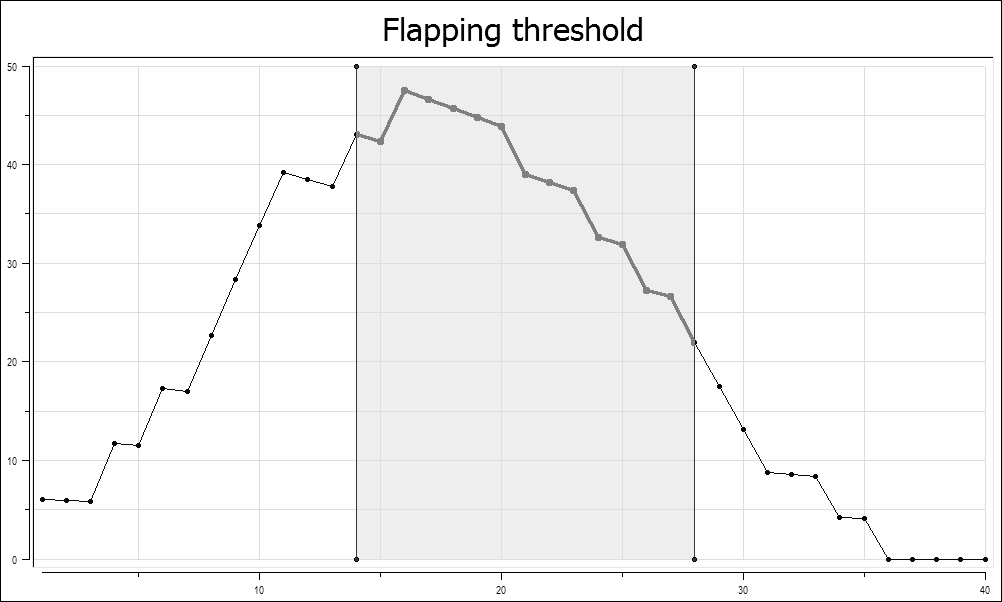
It is worth noting that the low flap threshold should be lower than the high flap threshold. This prevents the situation where, after one state transition, flapping would be detected, and the next check would tell Nagios that the object has stopped flapping. If both the attributes are set to the same value, an object might be identified as having started and stopped flapping often. This can happen when the flapping threshold changes from below threshold to above threshold or vice versa. This might cause Nagios to send out a large number of notifications and cause its performance to degrade.