
Nagios is a very powerful platform because it is easy to extend. The previous chapters talked about the check command plugins and how they can be used to check any host or service that your company might be using. Another great feature that Nagios offers is the ability for third-party software or other Nagios instances to report information on the status of services or hosts. This way Nagios does not need to schedule and run checks by itself; other applications can report information as it is available to them.
In this chapter, we will cover the following topics:
- Understanding passive checks
- Using NRDP
The previous parts of this book often mentioned Nagios performing checks on various software and machines. In such cases, Nagios decides when a check is to be performed, runs the check, and stores the result. These types of checks are called active checks.
Nagios also offers another way to let Nagios know about the status of hosts and services. It is possible to configure Nagios so that it will receive status information sent over a command pipe.
In such cases, other programs can either perform checks or report the current monitoring status by sending the current host or service status to Nagios. These types of checks are called passive checks. Nagios will still handle all notifications, event handlers, and dependencies between hosts and services.
Active checks are the most common way to perform checks of services. They have a lot of advantages and some disadvantages. One of the problems is that such checks can take only a few seconds to complete; a typical timeout for an active check to complete is 10 or 30 seconds. While this timeout is configurable (with the global option service_check_timeout set in main Nagios configuration file— nagios.cfg), the idea behind Nagios is to run checks that take a few seconds to complete and return status.
In many cases, the time taken is not enough as some checks need to be performed over a longer period of time to have satisfactory results—such as if a test takes several hours to complete. In this case, it does not make sense to raise the check timeout. Instead, a better solution is to schedule these checks outside of Nagios and only report the results back after the checks are complete.
There are also different types of checks including external applications or devices that want to report information directly to Nagios. This can be done to gather all critical errors in a single, central place.
For example, when a web application cannot connect to the database, it can let Nagios know about it immediately. It can also send reports after a database recovery, or periodically, even if connectivity to the database has consistently been available so that Nagios has an up to date status. This can be done in addition to active checks to identify critical problems earlier.
Another example is where an application already processes information such as network bandwidth utilization. In this case, adding code that reports current utilization along with the OK/WARNING/CRITICAL state to Nagios seems much easier than using active checks for the same job.
Often, there are situations where active checks obviously fit better. In other cases, passive checks are the way to go. In general, if a check can be done quickly and does not require long-running processes, it should definitely be done as an active service. If the situation involves reporting problems that will be sent independently by Nagios from other applications or machines, it is definitely a use case for a passive check. In cases where the checks require the deployment of long-running processes or monitoring information constantly, this should be done as a passive service.
Another difference is that active checks require much less effort to be set up when compared to passive checks. In the first case, Nagios takes care of the scheduling, and the command only needs to perform the actual checks and mark the results as OK/WARNING/CRITICAL based on how a check command is configured. Passive checks require all the logic related to what should be reported and when it should be checked to be put in an external application. This usually calls for some effort.
The following diagram shows how both active and passive checks are performed by Nagios. It shows what is performed by Nagios in both cases and what needs to be done by the check command or an external application for passive checks:

Nagios also offers a way of combining the benefits of both active and passive checks. Often, you have situations where other applications can report if a certain service is working properly or not. But if the monitoring application is not running or some other issue prevents it from reporting, Nagios can use active checks to keep the service status up to date.
A good example would be a server that is a part of an application, processing job queues using a database. It can report each problem when accessing the database. We want Nagios to monitor this database, and as the application is already using it, we can add a module that reports this to Nagios.
The application can also periodically let Nagios know if it succeeded in using the database without problems. However, if there are no jobs to process and the application is not using it, there will be no up to date information about the database status. In this case Nagios would simply run a check on its own.
The first thing that needs to be done in order to use passive checks for your Nagios setup is to make sure that you have the following options in your main Nagios configuration file—such as /etc/nagios/nagios.cfg if Nagios was set up according to instructions from Chapter 2, Installing Nagios 4:
accept_passive_service_checks=1 accept_passive_host_checks=1
It is also good to enable the logging of incoming passive checks; this makes determining the problem of not processing a passive check much easier. The following directive enables it:
log_passive_checks=1
Setting up hosts or services for passive checking requires an object to have the passive_checks_enabled option set to 1 for Nagios to accept passive check results over the command pipe. If only passive checks will be sent to Nagios, it is also advised that you disable active checks by setting the active_checks_enabled option to 0. The following is an example of the required configuration for a host that accepts passive checks and has active checks disabled:
define host
{
use generic-host
host_name linuxbox01
address 10.0.2.1
active_checks_enabled 0
passive_checks_enabled 1
}
Configuring services is exactly the same as with hosts. For example, to set up a very similar service, all we need to do is to use the same parameters as those for the hosts:
define service
{
use ping-template
host_name linuxbox01
service_description PING
active_checks_enabled 0
passive_checks_enabled 1
}
In this case, Nagios will never perform any active checks on its own and will only rely on the results that are passed to it.
We can also configure Nagios so that if no new information has been provided within a certain period of time, it will perform active checks to get the current status of the host or service. If up to date information has been provided by a passive check during this period, then no active checks will be performed.
To do this, we need to enable active checks by setting the active_checks_enabled option to 1 without specifying the normal_check_interval directive. For Nagios to perform active checks when there is no up to date result from passive checks, you need to set the check_freshness directive to 1 and set freshness_threshold to the duration after which a check should be performed. The time specified in the freshness_threshold option is specified in seconds.
The first parameter tells Nagios that it should check whether the results from the checks are up to date. The next parameter specifies the number of seconds after which Nagios should consider the results to be out of date. Attributes can be used for both hosts and services.
A sample definition for a host that runs an active check if there has been no result provided within the last two hours is as follows:
define host
{
use generic-host
host_name linuxbox02
address 10.0.2.2
check_command check-host-alive
check_freshness 1
freshness_threshold 7200
active_checks_enabled 1
passive_checks_enabled 1
}
The following is a diagram showing when Nagios will invoke active checks:
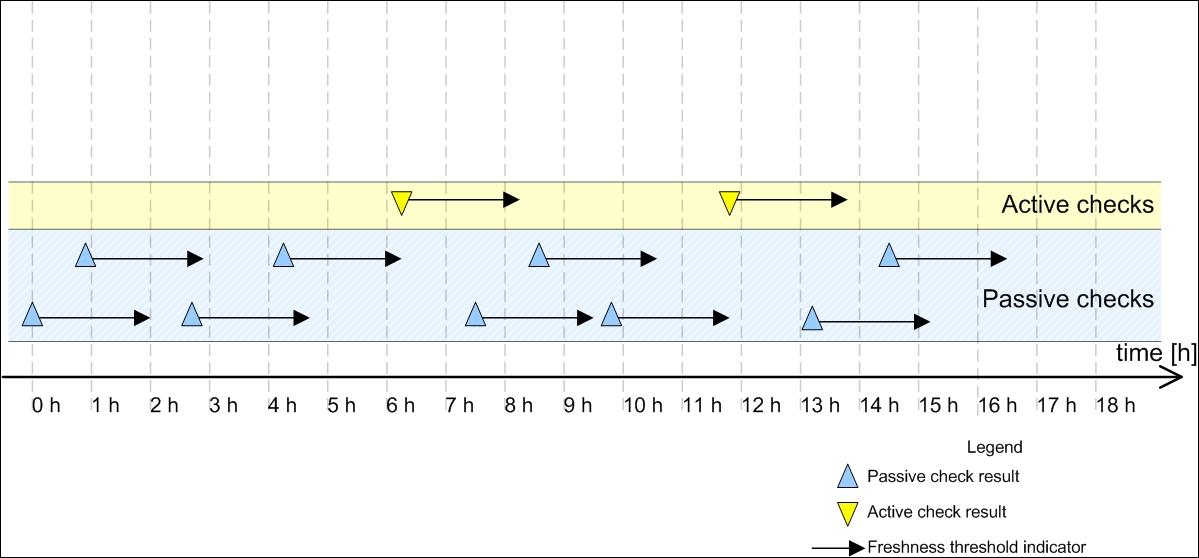
Each time there is at least one passive check result that is still valid (a result that was received within the past two hours), Nagios will not perform any active checks.
However, two hours after the last passive or active check result is received, Nagios will perform an active check to keep the results up to date.
Nagios allows applications and event handlers to send out passive check results for host objects. In order to use them, the host needs to be configured to accept passive check results. In order to be able to submit passive check results, we need to configure Nagios to allow the sending of passive check results and set the host objects to accept them.
Submitting passive host check results to Nagios requires sending a command to the Nagios external command pipe. This way, other applications on your Nagios server can report the status of the hosts.
All commands sent to the Nagios command pipe are sent as a single line of text and use a specific format:
[<time>] <command_id>;<command_arguments>
The time should be put in square brackets and has to be a Unix timestamp (which is number of seconds since January 1st 1970). The command and all of its arguments are separated using a semicolon.
The format is described in more detail in the external command documentation available at: http://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/extcommands.html.
The command to submit passive checks is PROCESS_HOST_CHECK_RESULT (visit http://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/passivechecks.html for more details on the command). This command accepts the hostname and status code. The host status code should be 0 for an UP state, 1 for DOWN, and 2 for an UNREACHABLE state.
The syntax is:
[<time>] PROCESS_HOST_CHECK_RESULT;<host>;<status>;<plugin_output>
The following is a sample script that will accept the hostname, status code, and output from a check and will submit these to Nagios:
#!/bin/sh
NOW=`date +%s`
HOST=$1
STATUS=$2
OUTPUT=$3
echo "[$NOW] PROCESS_HOST_CHECK_RESULT;$HOST;$STATUS;$OUTPUT"
>/var/nagios/rw/nagios.cmd
exit 0
As an example of the use of this script, the command sent to Nagios for host01, status code 2 (UNREACHABLE), and output router 192.168.1.2 down would be as follows:
[1206096000] PROCESS_HOST_CHECK_RESULT;host01;2;router 192.168.1.2 down
While submitting results, it is worth noting that Nagios might take some time to process them, depending on the intervals between checks of the external command pipe in Nagios. Unlike active checks, Nagios will not take network topology into consideration by default. This is very important in situations where a host behind a router is reported to be down because the router is actually down.
By default, Nagios handles results from active and passive checks differently. When Nagios plans and receives results from active checks, it takes the actual network topology into consideration and return as an UNREACHABLE state.
When a passive result check comes in to Nagios, Nagios expects that the result already has a network topology included. When a host is reported to be DOWN as a passive check result, Nagios does not perform a translation from DOWN to UNREACHABLE. Even if its parent host is currently DOWN, the child host state is also stored as DOWN.
How Nagios handles passive check results can be defined in the main Nagios configuration file. In order to make Nagios treat passive host check results in the same way as active check results, we need to enable the following option:
translate_passive_host_checks=1
By default, Nagios treats host results from passive checks as hard results. This is because, very often, passive checks are used to report host and service statuses from other Nagios instances. In such cases, only reports regarding hard state changes are propagated across Nagios servers. If you want Nagios to treat all passive check results for hosts as if they were soft results, you need to enable the following option in the main Nagios configuration file:
passive_host_checks_are_soft=1
Passive service checks are very similar to passive host checks. In both cases, the idea is that Nagios receives information about host statuses over the external command pipe. As with passive checks of hosts, all that is needed is to enable the global Nagios option to accept passive check results and to also enable this option for each service that should allow the passing of passive check results.
The results are passed to Nagios in the same way as they are passed for hosts. The command to submit passive checks is PROCESS_SERVICE_CHECK_RESULT. This command accepts the hostname, service description, status code, and the textual output from a check. Service status codes are the same as those for active checks— 0 for OK, 1 for WARNING, 2 for CRITICAL, and 3 for an UNKNOWN state.
The syntax is:
[<time>] PROCESS_SERVICE_CHECK_RESULT;<host>;<svc>;<status>;<output>
The following is a sample script that will accept the hostname, status code, and output from a check and submit these to Nagios:
#!/bin/sh CLOCK=`date +%s` HOST=$1 SVC=$2 STATUS=$3 OUTPUT=$4 echo "[$CLOCK] PROCESS_SERVICE_CHECK_RESULT;$HOST;$SVC;$STATUS; $OUTPUT" >/var/nagios/rw/nagios.cmd exit 0
As a result of running the script, the command that is sent to Nagios for host01, service PING, status code 0 (OK), and output RTT=57 ms is as follows:
[1206096000] PROCESS_SERVICE_CHECK_RESULT;host01;PING;0;RTT=57 ms
A very common scenario for using passive checks is a check that takes a very long time to complete. When submitting results, it is worth noting that Nagios might take some time to process them, depending on the intervals between checks of the external command pipe in Nagios.
A major difference between hosts and services is that service checks differentiate between soft and hard states. When new information regarding a service gets passed to Nagios via the external command pipe, Nagios treats it in the same way as if it had been received by an active check. If a service is set up with a max_check_attempts directive of 5, then the same number of passive check results would be needed in order for Nagios to treat the new status as a hard state change.
The passive service checks are often used to report the results of long lasting tests that were run asynchronously. A good example of such a test is checking whether there are bad blocks on a disk. This requires trying to read the entire disk directly from the block device (such as /dev/sda1) and checking if the attempt has failed. This can't be done as an active check as reading the device takes a lot of time and larger disks might require several hours to complete. For this reason, the only way to perform such a check is to schedule it from the system, for example, by using the cron daemon (visit http://linux.die.net/man/8/cron). The script should then post results to the Nagios daemon.
The following is a script that runs the dd system command (visit http://linux.die.net/man/1/dd) to read an entire block device. Based on whether the read was successful or not, the appropriate status code along with the plugin output is sent out:
#!/bin/sh SVC=$1 DEVICE=$2 TMPFILE=`mktemp` NOW=`date +%s` PREFIX="[$NOW] PROCESS_SERVICE_CHECK_RESULT;localhost;$SVC" # try to read the device dd bs=1M if=$DEVICE of=/dev/null >$TMPFILE 2>&1 CODE=$? RESULT=`grep copied <$TMPFILE` rm $TMPFILE if [ $CODE == 0 ] ; then echo "$PREFIX;0;$RESULT" else echo "$PREFIX;2;Error while checking device $DEVICE" fi exit 0
If the check fails, then a critical status along with text stating that there was a problem checking the specific device is sent out to Nagios. If the check was successful, an output mentioning the number of bytes and the speed of transfer is sent out to Nagios. A typical output would be something like this:
254951424 bytes (255 MB) copied, 9.72677 seconds, 26.2 MB/s
The hostname is hardcoded to localhost. Using this script requires configuring a service to have active checks disabled and passive checks enabled. As the checks will be done quite rarely, it's recommended that you set max_check_attempts to 1. It is also possible to use the badblocks (please visit http://linux.die.net/man/8/badblocks for more details) command to check for bad blocks on a hard drive.
It's not always possible to set up passive checks correctly the first time. In such cases, it is a good thing to try to debug the issue one step at a time in order to find any potential problems. Sometimes, the problem could be a configuration issue, while in other cases it could be an issue such as the mistyping of the host or service name.
One thing worth checking is whether the Web UI shows changes after you have sent the passive result check. If it doesn't, then at some point, things were not working correctly. The first thing you should start with is enabling the logging of external commands and passive checks. To do this, make sure that the following values are enabled in the main Nagios configuration file:
log_external_commands=1 log_passive_checks=1
In order for the changes to take effect, a restart of the Nagios process is needed. After this has been done, Nagios will log all commands passed via the command pipe and log all of the passive check results it receives.
A very common problem is that the application or script cannot write data to the Nagios command pipe. In order to test this, simply try to write to the Nagios external command pipe in the same manner that the application/script's user is running.
For example if the application or script is running as daemon, you can run the following as root:
root@ubuntuserver:# su -s/bin/sh daemon $ echo TEST >/var/nagios/rw/nagios.cmd
The su command will switch the user to the specified user. The next line is run as the user daemon and an attempt to write to the Nagios external command pipe is made. The -s flag for the su command forces /bin/sh as the shell to use. It is useful in cases where the user's default shell is not a proper shell, that is, it is set to /bin/false for security reasons to prevent the account from interactive shell access.
If the preceding command runs fine and no errors are reported, then your permissions are set up correctly. If an error shows up, you should add the user to the nagioscmd group as described in Chapter 2, Installing Nagios 4. The following command will add the user daemon to the nagioscmd group:
root@ubuntuserver:# adduser daemon nagioscmd
The next thing to do is to manually send a passive check result to the Nagios command pipe and check whether the Nagios log file was received and parsed correctly. To do this, run the following command as the same user that the application or script is running as:
root@ubuntuserver:# su -s/bin/sh daemon $ echo "[`date +%s`] PROCESS_HOST_CHECK_RESULT;host1;2;test" >/var/nagios/rw/nagios.cmd
The name host1 needs to be replaced with an actual hostname from your configuration. A few seconds after running this command, the Nagios log file should reflect the command that we have just sent. You should see the following lines in your log:
EXTERNAL COMMAND: PROCESS_HOST_CHECK_RESULT;host1;2;test [1220257561] PASSIVE HOST CHECK: host1;2;test
If both of these lines are in your log file, then we can conclude that Nagios has received and parsed the command correctly. If only the first line is present, then it means either that the option to receive passive host check results are disabled globally or that it is disabled for this particular object.
If this is the case, first thing you should do is to make sure that your main Nagios configuration file contains the following line:
accept_passive_host_checks=1
Next, you should check your configuration to see whether the host definition has passive checks enabled as well. If not, simply add the following directive to the object definition:
passive_checks_enabled 1
If you have misspelled the name of the host object, then the following will be logged:
Warning: Passive check result was received for host 'host01', but the host could not be found!
In this case, make sure that your hostname is correct. Similar checks can also be done for services. You can run the following command to check if a passive service check is being handled correctly by Nagios:
root@ubuntuserver:# su -s/bin/sh daemon $ echo "[`date +%s`] PROCESS_SERVICE_CHECK_RESULT;host1;APT;0;test" >/var/nagios/rw/nagios.cmd
Again, host1 should be replaced by the actual hostname, and APT needs to be an existing service for that host.
After a few seconds, the following entries in the Nagios log file (/var/nagios/nagios.log) will indicate that the result has been successfully parsed:
EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;host1;APT;0;test PASSIVE SERVICE CHECK: host1;APT;0;test
If the second line is not in the log file, there are two possible reasons for this.
One is that the global option to accept service passive checks by Nagios is disabled. You should start by making sure that your main Nagios configuration file (/etc/nagios/nagios.cfg) contains the following line:
accept_passive_service_checks=1
The other possibility is that the host does not have passive checks enabled. You should make sure that the service definition has passive checks enabled as well, and if not, add the following directive to the object definition:
define host
{
host_name host1
passive_checks_enabled 1
}
If you have misspelled the name of the host or service, then the following information will be logged in the Nagios log file:
Warning: Passive check result was received for service 'APT' on host 'host1', but the service could not be found!