
Event handlers are commands that are triggered whenever the state of a host or service changes. They offer functionality similar to notifications. The main difference is that the event handlers are called for each type of change and even for each soft state change. This provides the ability to react to a problem before Nagios notifies it as a hard state and sends out notifications about it. Another difference is what the event handlers should do. Instead of notifying users that there is a problem, event handlers are meant to carry out actions automatically.
For example, if a service defined with max_check_attempts is set to 4, the retry_interval is set to 1, and check_interval is set to 5, then the following example illustrates when event handlers would be triggered, and with what values, for $SERVICESTATE$, $SERVICESTATETYPE$, and $SERVICEATTEMP$ macro definitions:
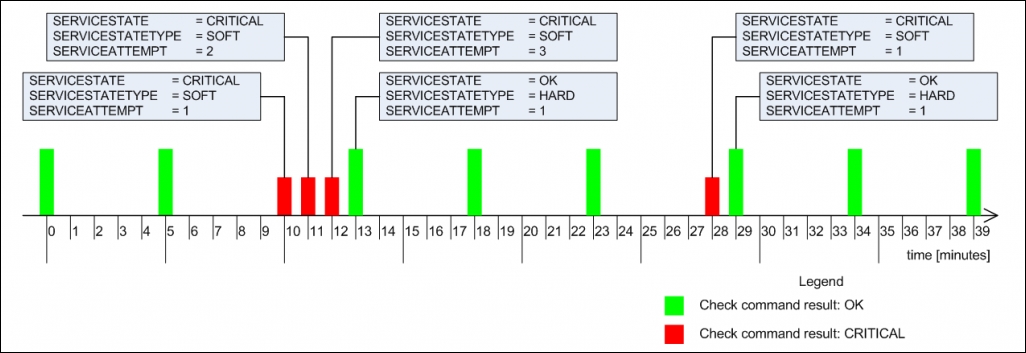
Event handlers are triggered for each state change—for example, in minutes, 10, 23, 28, and 29. When writing an event handler, it is necessary to check whether an event handler should perform an action at that particular time or not. See the preceding example for more details.
Event handlers are also triggered for each soft check attempt. It is also triggered when the host status becomes hard (when max_check_attempts attempts of checks have been made and service has not recovered). In this example, these occur at minutes 11, 12, and 13. It's important to know that the events will not be run if no state changes have occurred, and the object is in a hard state—for example, no events are triggered in minutes 5, 18, 34, and 39.
A typical example might be that your web server process tends to crash once a month. Because this is rare enough, it is very difficult to debug and resolve it. Therefore, the best way to proceed is to restart the server automatically until a solution to the problem is found.
If your configuration has max_check_attempts set to 4, as in the example above, then a good place to try to restart the web server is after the third soft failure check-in the previous example, this would be minute 12.
Assuming that the restart has been successful, the diagram shown above would look like this:

Please note that no hard critical state has occurred since the event handler resolved the problem. If a restart cannot resolve the issue, Nagios will only try it once, as the attempt is done only in the third soft check.
Event handlers are defined as commands, similar to check commands. The main difference is that the event handlers only use macro definitions to pass information to the actual event handling script. This implies that the $ARGn$ macro definitions cannot be used and arguments cannot be passed in the host or service definition by using the ! separator.
In the previous example, we would define the following command:
define command
{
command_name restart-apache2
command_line $USER1$/events/restart_apache2
$SERVICESTATE$ $SERVICESTATETYPE$ $SERVICEATTEMPT$
}
The command would need to be added to the service. For both hosts and services, this requires adding an event_handler directive that specifies the command to be run for each event that is fired. In addition, it is good to set event_handler_enabled to 1 to make sure that event handlers are enabled for this object.
The following is an example of a service definition:
define service
{
host_name localhost
service_description Webserver
use apache
event_handler restart-apache2
event_handler_enabled 1
}
Finally, a short version of the script is as follows:
#!/bin/sh
# use variables for arguments
SERVICESTATE=$1
SERVICESTATETYPE=$2
SERVICEATTEMPT=$3
# we don't want to restart if current status is OK
if [ "$SERVICESTATE" != "OK" ] ; then
# proceed only if we're in soft transition state
if [ "$SERVICESTATETYPE" == "SOFT" ] ; then
# proceed only if this is 3rd attempt, restart
if [ "$SERVICESTATEATTEMPT" == "3" ] ; then
# restarts Apache as system administrator
sudo service apache2 restart
fi
fi
fi
exit 0
As we're using sudo here, obviously the script needs an entry in the sudoers file to allow the user nagios to run the command without a password prompt. An example entry for the sudoers file would be as follows:
nagios ALL=NOPASSWD: /usr/sbin/service
This will tell sudo that the command /usr/sbin/service can be run by the user nagios and that asking for passwords before running the command will not be done.
According to our script, the restart is only done after the third check fails. Assuming that the restart went correctly, the next Nagios check will notify that Apache is running again. As this is considered a soft state, Nagios has not yet sent out any notifications about the problem.
If the service would not restart correctly, the next check will cause Nagios to set this failure as a hard state. At this point, notifications will be sent out to the object owners.
You can also try performing a restart in the second check. If that did not help, then during the third attempt, the script can forcefully terminate all Apache2 processes using the killall or pkill command. After this has been done, it can try to start the service again. For example:
# proceed only if this is 3rd attempt, restart
if [ "$SERVICESTATEATTEMPT" == "2" ] ; then
# restart Apache as system administrator
sudo service apache2 restart
fi
# proceed only if this is 3rd attempt, restart
if [ "$SERVICESTATEATTEMPT" == "3" ] ; then
# try to terminate apache2 process as system administrator
sudo pkill apache2
# starts Apache as system administrator
sudo service apache2 start
fi
Similar to the previous example, it requires adding an entry in the sudoers file. In addition to the previous line it also requires adding the pkill command, the whole path to the command is /usr/bin/pkill:
nagios ALL=NOPASSWD: /usr/bin/pkill nagios ALL=NOPASSWD: /usr/sbin/service
Another common scenario is to restart one service if another one has just recovered—for example, you might want to restart e-mail servers that use a database for authentication if the database has just recovered from a failure state. The reason for doing this is that some applications may not handle disconnected database handles correctly—this can lead to the service working correctly from the Nagios perspective, but not allowing some of the users in due to internal problems.
If you have set this up for hosts or services, it is recommended that you keep flapping enabled for these services. It often happens that due to incorrectly planned scripts and the relations between them, some services might end up being stopped and started again.
In such cases, Nagios will detect these problems and stop running event handlers for these services, which will cause fewer malfunctions to occur. It is also recommended that you keep notifications set up so that people also get information on when flapping starts and stops.
Nagios also offers the ability to change various parameters related to notifications. These parameters are modified via an external command pipe, similar to a few of the commands shown in the previous section.
A good example would be when Nagios contact persons have their workstations connected to the local network only when they are actually at work (which is usually the case if they are using notebooks), and turn their computers off when they leave work. In such a case, a ping check for a person's computer could trigger an event handler to toggle that person's attributes.
Let's assume that our user jdoe has two actual contacts—jdoe-e-mail and jdoe-jabber, each for different types of notifications. We can set up a host corresponding to the jdoe workstation. We will also set it up to be monitored every five minutes and create an event handler. The handler will change the jdoe-jabber's host and service notification time period to none on a hard host down state. On a host up state change, the time period for jdoe-jabber will be set to 24x7. This way, the user will only get Jabber notifications if they are at work.
Nagios offers commands to change the time periods during which a user wants to receive notifications. The commands for this purpose are: CHANGE_CONTACT_HOST_NOTIFICATION_TIMEPERIOD and CHANGE_CONTACT_SVC_NOTIFICATION_TIMEPERIOD. Both commands take the contact and the time period name as their arguments.
An event handler script that modifies the user's contact time period based on state is as follows:
#!/bin/sh
NOW=`date +%s`
CONTACT=$1-jabber
if [ "$2,$3" = "DOWN,HARD" ] ; then
TP=none
else
TP=24x7
fi
echo "[$NOW] CHANGE_CONTACT_HOST_NOTIFICATION_TIMEPERIOD; $CONTACT;$TP"
>/var/nagios/rw/nagios.cmd
echo "[$NOW] CHANGE_CONTACT_SVC_NOTIFICATION_TIMEPERIOD; $CONTACT;$TP"
>/var/nagios/rw/nagios.cmd
exit 0
The command should pass $CONTACTNAME$, $SERVICESTATE$, and $SERVICESTATETYPE$ as parameters to the script.
In case you need a notification about a problem sent again, you should use the SEND_CUSTOM_HOST_NOTIFICATION or SEND_CUSTOM_SVC_NOTIFICATION command. These commands take host or host and service names, additional options, author name, and comments that should be put in the notification.
The additional options allow specifying if the notification should also include all escalation levels (a value of 1), if Nagios should skip time periods for specific users (a value of 2), as well as if Nagios should increment notifications counters (a value of 4). Options are stored bitwise, so a value of 7 (1+2+4) would enable all of these options. The notification would be sent to all people including escalations; it will be forced, and the escalation counters will be increased. Option value 3 means it should be broadcast to all escalations as well, and the time periods should be skipped.
To send a custom notification about the main router to all users including escalations, you should send the following command to Nagios:
[1206096000] SEND_CUSTOM_HOST_NOTIFICATION;router1;3;jdoe;RESPOND ASAP