
The previous chapter introduced the collaborative development landscape through the perspective of GitHub. Collaboration has another facet to it which emulates our usual curiosity cycle of questions and answers. Internet has time and again seen some very popular Question and Answer (Q&A) platforms such as Yahoo Answers, Wiki Answers, and so on, which provide users with the ability to ask questions and utilize their collective might to find answers. Yet they all lacked the quality and discipline to stand the test of time. This second chapter on a similar theme introduces you to the world of StackExchange which is, in certain ways, a gold mine of information. It caters to topics from mathematics to programming languages, and even spirituality, all available at the click of a button!
A Q&A platform such as StackExchange doesn't just assist users to find answers but also acts as a perfect partner to a collaborative development platform such as GitHub. Both of these platforms are very popular amongst developers in particular and the whole of Internet in general. Through this chapter, we will cover:
- The basics of the StackExchange platform, its origins and popularity
- Understand its data access patterns through APIs, data dumps, and so on
- Work upon specific use cases to uncover interesting insights related to the platform, demographics, user base, and so on
- Challenges faced while working with data from a platform such as StackExchange
This chapter builds and complements the previous one in terms of overall theme yet readers can focus on this as a complete chapter of its own.
What started as a single website in 2008 by the name of StackOverflow for developers/programmers has now outgrown its humble beginnings to become a full-fledged Q&A platform catering to topics as varied as mathematics, biology, music, and many more.
Stated simply, StackExchange is a platform consisting of various Q&A websites under its umbrella (one for each topic) where questions, answers, and users are subject to a reward/award process. The platform gamifies the Q&A process and rewards its users with increasing privileges as their reputation scores improve based upon their activity on the network. The reputation scores in turn have been really successful in moderating the content on the network and thus providing useful high quality answers to the majority of the questions unlike other Q&A platforms.

StackExchange site portfolio
In terms of numbers, StackExchange has over 150+ sites for as many topics and growing, it handles about 1.3 billion page views per month catering to over 4 million+ registered users.
Note
More statistics related to StackExchange can be accessed at http://stackexchange.com/performance
The sites under the StackExchange umbrella contain tons of data which is available through various methods under the Creative Commons license. Amazing, isn't it?
Note
Creative Commons is an American non-profit organization which handles and releases copyright licenses free of cost to promote and protect creative work. The licenses are crafted in an easy to understand manner and allow users to reserve certain rights and waive off others for the benefit of users or other creators. You can read more on this here: https://creativecommons.org/
Let us now understand the various methods of getting this wealth of data to play with.
Most social networks/platforms provide certain predefined ways of accessing their data. Across previous chapters, we have seen and utilized Application Programming Interfaces (APIs) in general. Unlike other platforms we have covered so far, StackExchange provides a slightly different way to access its data. Since the data on the platform is under the Creative Commons license, the StackExchange team takes it seriously and has opened up most of its data for the public. The following are popular methods of getting data related to any StackExchange website:
- Data dump: StackExchange regularly releases a data dump of all of its user generated public data. This data is available in the form of separate XML files for each of the sites in the platform. Each site's archive includes data for posts, users, votes, comments, post history, links, and tags.
- Data explorer: This is a tool based on SQL. It allows users to execute arbitrary queries on the user generated public content of the platform. The queries are publicly available for reuse/modification along with the ability to write new ones. The base data is similar to what is available in the data dumps. More details at: https://data.stackexchange.com/help:

One of the popular queries on the data explorer
- APIs: StackExchange exposes data through its APIs as well. The APIs utilize OAuth for authentication and respond with JSON data. The APIs have restrictions in terms of request counts and hence should be utilized with care. Though most of the data can be extracted through APIs as well, usually these are utilized by developers of apps based on the StackExchange platform rather than for data science projects. More details at: https://api.stackexchange.com/docs
As discussed in the previous section, StackExchange provides multiple ways of getting data from the platform. Depending upon the use case, one method may be preferred over the other. We as users can be sure of the fact that the same data is available across the methods. For the use cases in this chapter, we will be utilizing the data dumps from the platform.
StackExchange's data dumps are fairly extensive in information they contain and granular enough to work with. These also free us of the query rate limitations imposed upon APIs or row count limitations set on the data explorer methods. This method may be limited from the perspective that the data is not real-time. This should not be much of a barrier given the fact that the data is not too old (usually lags by a month or so) and we can work on most behaviors with a little data lag unless we have a real-time analytics use case to work with. Before we dive into the use cases, let us get familiarized with the data dumps themselves.
Unlike APIs (we have seen plenty of those in the previous chapters) which require us to create an app to get keys/tokens and then use certain packages to request the data, data dumps are plain, simple downloads. Anybody familiar with Internet knows how to download stuff and getting StackExchange data dumps is as simple as that. No registrations or apps are required.
The data dumps are available at https://archive.org/details/stackexchange. These are available under CC-by-SA license for anyone to use with attribution. Readers may download the complete dump from the website as a direct dump or through a torrent file. Both methods are listed on the website mentioned.
The full data dump, consisting of data from all StackExchange websites is more than 40 GBs in size. Each website's data is available in the form of XML files. Users can also choose to work with a subset of this data based upon the use case and thus limit the amount of data to be downloaded. For the use cases in the upcoming section, we will be relying on a subset but readers can easily extend the same to the complete data dump as well.
The data is available in the form of eight separate XML files for each of the sites under the StackExchange umbrella. The different XML files are as follows:
Badges.xml: This file consists of data related to badges earned/associated with each user on the respective site. This data is keyed on the user's ID itself.Comments.xml: As the name suggests, this file contains comments for each of the questions or answers on the website. It contains the text, date and timestamp, and user identification fields for each comment.Posts.xml: This is the main data file for each site. This file contains data related to the questions and answers themselves. Each of the posts is keyed on an ID and its type identifies whether it is a question post or an answer post. Each row in this XML file is associated with a post and contains a multitude of attributes which we will see in the coming sections.PostHistory.xml: StackExchange websites are one of the best examples of collaborative/crowd sourcing efforts. The website is magically self-moderated. This self-moderation is seen through posts (questions and answers) being edited/revised for the sake of clarity and details. Posts are even marked duplicate or closed down altogether for a variety of reasons (such as being off topic). Such changes are tracked in this file which contains data associated with every change a post goes through, including the user's information associated with the same.PostLinks.xml: This file acts more like a look-up of sorts. It helps in maintaining links between similar/associated posts as well as duplicate ones for easy traversal/analysis.Users.xml: As the name suggests, this file contains public information associated with each user registered with the site under considerationVotes.xml: As briefly discussed in the introduction to StackExchange, gamification is the key to this platform. Posts are voted up and down based on their relevance. StackExchange even allows users to attach bounties with questions as an added incentive. This information is available through this file for analysis.Tags.xml: Each StackExchange website caters to millions of users asking and answering thousands of different things. Tags are unique markers to each such post for better reach and searching. This file contains a summary of tags associated with posts on the site under consideration. UnlikePosts.xmlwherein all tags associated with a post are listed as a list, this file contains frequencies and other information at a per tag level.
StackExchange exposes quite an extensive set of data from the platform which is neatly segregated based on sites and entity levels. To get a complete picture of the data landscape, let us visually understand how the different files are associated:

StackExchange sample site wise entity relationships (diagram only shows key fields)
The preceding visual representation not just helps us understand the relationships between different data elements available, it also helps us during our analysis of the data to think critically and try and find potential spots for deriving insights. This will be clearer when we dive into the use cases.
As is evident from the preceding diagram, posts and users are the most important and central entities to the whole landscape. This shouldn't be surprising at all since posts (Q&A) are the site's bread and butter and it is the users who drive the whole platform.
Let us have a brief look at post and user files for a better understanding.
We discussed in the previous section about Posts.xml in brief. Now let us have a look at the contents of this file to see what we have at hand and prepare a strategy to utilize the contents to uncover insights. The Posts.xml file looks like the following snapshot:

Sample Posts.xml
The file consists of multiple <row> tags, one for each post (where a post can be a question or answer). Each row element consists of various attributes. Each post is uniquely identified by its Id field. It has attributes such as:
PostTypeId: This signifies if a post is a question or an answerCreationDate: This creates a date and timestamp of the postTitle: This is the question header we get on the websiteBody: This is the post's actual text
There are many more attributes. Each row consists of about 20 such attributes. The attributes are a mix of numeric, string, and categorical data types. The following is a snapshot of the data in tabular form at:
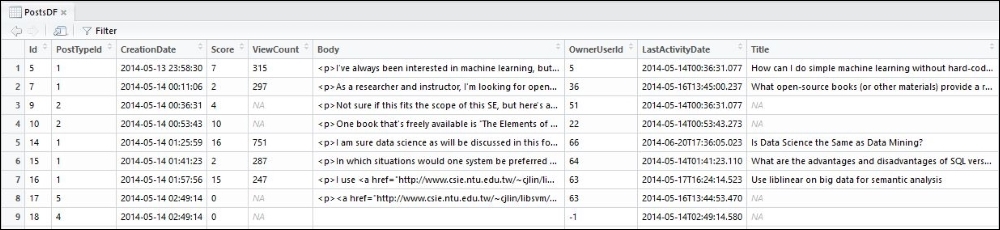
Posts data in tabular format
It is the users who drive any social network and StackExchange is no exception. The Users.xml file contains public information associated with each registered user. Users on the platform are characterized by the following attributes:
CreationDate: The date and timestamp when the user registered on the platformDisplayName: The identifiable string used by the user while interacting with the platformUpVotes/DownVotes: The count of votes this user has contributed to
There are many more attributes associated with demographic information such as age, location, and so on. We can utilize this information to get user-centric insights from the data. The following is a snapshot of this data in tabular format:

Users data in tabular format
Now that we have a basic understanding of what is available as part of the StackExchange data dumps, let us get our hands dirty and work upon a few use cases.
As discussed in the previous sections, the data is available on a per site basis and each site's data is segregated into separate XML files. For the purpose of the use cases to be discussed in the coming sections, we will be loading these XML files as required into R for analysis (mostly in the form of R DataFrames).
Note
For the remainder of this chapter, we will be referring to the data associated with https://datascience.stackexchange.com/ obtained through the official data dump from https://archive.org/details/stackexchange.
The following is a quick utility function we will be utilizing to load the XML files into R as DataFrames:
# load XML data
loadXMLToDataFrame<- function(xmlFilePath){
doc <- xmlParse(xmlFilePath)
xmlList<- xmlToList(doc)
total<-length(xmlList)
data<-data.frame()
for(i in 1: total){
data <- rbind.fill(data,as.data.frame(as.list( xmlList[[i]])))
}
return(data)
}The functions xmlParse() and xmlToList() are available through the package XML. This package contains many such utility functions. The rest of the code is pretty straightforward and returns a dataframe object from the XML input.
Tip
XML files can be huge in size. The preceding utility function performs a full load of XML data in memory. This method may not work beyond certain file sizes due to system memory limitations. For analysis of files which are bigger in size (StackOverflow's data is close to 30 GB as compared to http://datascience.stackechange.com/ which is a few MBs), a better solution would be to load data into a database and extract into R, a subset of it based on the requirements. Using data through a database is also straightforward but is beyond the scope of this chapter. Readers are encouraged to explore the same.
Now that we have the utility to get data into R, let us load the Posts.xml into R. The following snippet will return a DataFrame consisting of rows from Posts.xml:
> PostsDF <- loadXMLToDataFrame(paste0(path,"Posts.xml"))
Similarly, we can load other XML files as required. Let us now get started with our use cases.