
Chapter 7 Probability, Random Variables, and Stochastic Processes
‡ Southern Methodist University, Dallas, USA
7.1 Introduction to Probability
Probability theory essentially provides a framework and tools to quantify and predict the chance of occurrence of an event in the presence of uncertainties. Probability theory also provides a logical way to make decisions in situations where the outcomes are uncertain. Probability theory has widespread applications in a plethora of different fields such as financial modeling, weather prediction, and engineering. The literature on probability theory is rich and extensive. A partial list of excellent references includes [1, 5]. The goal of this chapter is to focus on the basic results and illustrate the theory with several numerical examples. The proofs of the major results are not provided and relegated to the references.
While there are many different philosophical approaches to define and derive probability theory, Kolmogorov’s axiomatic approach is the most widely used. This axiomatic approach begins by defining a small number of precise axioms or postulates and then deriving the rest of the theory from these postulates.
Before formally defining Kolmogorov’s axioms, we first specify the basic framework to understand and study probability theory. Probability is essentially defined in the context of a repeatable random experiment. An experiment consists of a procedure for conducting the experiment and a set of outcomes/observations of the experiment. A model is assigned to the experiment which affects the occurrence of the various outcomes. A sample space, S, is a collection of finest grain, mutually exclusive and collectively exhaustive set of all possible outcomes. Each element ω of the sample space S represents a particular outcome of the experiment. An event E is a collection of outcomes.
Example 7.1.1. A fair coin is tossed three times. The sample space S = {HHH, HHT, HTH, HTT, THH, THT, TTH, TTT}. Event E1 = {HTT, THT, TTH} is the set of all outcomes with exactly 1 Head in the three coin flips.
□
Example 7.1.2. The angle that the needle makes in a wheel of fortune game is observed. The sample space S = {θ : 0 ≤ 9 < 2π}.
□
Events Ej and Ek are said to be mutually exclusive or disjoint events if there are no outcomes that are common to both events, i.e., Ej ∩ Ek = ϕ.
A collection of events defined over a sample space S is called a sigma field if:
• includes both the impossible event ϕ and the certain event S.
• For every set A ⊂ , it implies that Ac ⊂ .
• is closed under countable set operations of union and intersection, i.e., A ∩ B ∩ and A ∪ B ⊂ , ∀A, B ⊂ .
Given a sigma Field , a probability measure Pr (·) is a mapping from every event A ⊂ to a real number Pr (A) called the probability of event A satisfying the following three axioms:
1. Pr (A) ≥ 0.
2. Pr (S) = 1.
3. For a countable collection of mutually exclusive events A1,A2,…, Pr (A1 ∪ A2 ∪ A3 ∪ …) = Pr (A1) + Pr (A2) + Pr (A3) + …
A probability space consists of the triplet (S, , P).
Example 7.1.3. A fair coin is flipped 1 time. In this case, S = {H,T}. The sigma field consists of the sets, {H}, {T}, {ϕ}, {S}. The probability measure maps these sets to the probabilities as follows: Pr (H) = Pr (T) = 0.5, Pr (ϕ) = 0, and Pr (S) = 1.
□
The following simple and intuitive properties of the probability of an event can be readily derived from these axioms:
• The probability of the null set equals 0, i.e., Pr (ϕ) = 0.
• The probability of any event A is no greater than 1, i.e., Pr (A) ≤ 1.
• The sum of the probability of an event and the probability of its complement equals 1, i.e., Pr (Ac) = 1 − Pr (A).
• If A ⊂ B then Pr (A) ≤ Pr (B).
• The probability of the union of events A and B can be expressed in terms of the probability of events A, B and their intersection A ∩ B, i.e.,
(7.1) |
To prove (7.1), we can express A ∪ B in terms of three mutually exclusive sets A1 = A ∩ B, A2 = A − B and A3 = B − A. Hence, Pr (A ∪ B) = Pr (A1) + Pr (A2) + Pr(A3). Then by applying Axiom 3, we obtain Pr (A) = Pr(A1) + Pr(A2) and Pr(B) = Pr (A1) + Pr(A3). Property (7.1) readily follows. The other properties stated above can be similarly proved.
The conditional probability Pr (A∣B) for events A and B is defined as
(7.2) |
if Pr (B) > 0. This conditional probability represents the probability of occurrence of event A given the knowledge that event B has already occurred.
If events A1, A2,… An form a set of mutually exclusive events (Ai ∩ Aj = ϕ ∀i, j) that partition the sample space (A1 ∪ A2 ∪ … An = S) then
(7.3) |
Conditional probabilities are useful to infer the probability of events that may not be directly measurable.
Example 7.1.4. A card is selected at random from a standard deck of cards. Let event A1 represent the event of picking a diamond and let event B represent the event of picking a card with the number 7. Then the probability of the various events are Pr(A1) = 1/4 and Pr(B) = 1/13. Further, . Also, .
Let events A2, A3 and A4 represent the event of picking, respectively, a heart, spade and clubs. Clearly, events Ai, i = 1, 2, 3, and 4 are mutually exclusive and partition the sample space. Now, we evaluate Pr (A1∣B) using Bayes results (7.3) as
(7.4) |
which is the same value as calculated directly.
□
Example 7.1.5. Consider the transmission of a equiprobable binary bit sequence over a binary symmetric channel (BSC) with crossover probability α, i.e., a bit gets flipped by the channel with probability α. For simplicity, we consider the transmission of a single bit and let event A0 denote the event that a bit 0 was sent and event A1 denote the event that a bit 1 was sent. Similarly, let B0 and B1 denote, respectively, the event that bit 0 and bit 1 are received. In this case, the conditional probability that a bit 0 was sent given that a bit 0 was received can be calculated as
(7.5) |
□
Events A and B are independent events if
(7.6) |
Equivalently, the events are independent if Pr(A∣B) = Pr (A) and Pr (B∣A) = Pr(B). Intuitively, if events A and B are independent then the occurrence or nonoccurrence of event A does not provide any additional information about the occurrence or nonoccurrence of event B.
Multiple events E1, E2,… En are jointly independent if for every countable collection of events, the probability of their intersection equals the product of their individual probabilities. It should be noted that pairwise independence of events does not imply joint independence as the following example clearly illustrates.
Example 7.1.6. A fair coin is flipped n − 1 times, where n is odd and event Ei, i = 1, 2,…, n − 1 represents the event of receiving a Head in the ith flip. Let event En represent the event that there are even number of Heads in the n − 1 flips. Clearly, we can evaluate the probability of the various events as Pr (E)i = 1/2, ∀i = 1, 2,…, n. It is also clear that Pr (Ei ∩ Ej) = 1/4, ∀i ≠ j, which implies that the events are pairwise independent. It can also be verified that any k-tuple of these events are independent for k < n. However, events E1, E2,… En are not n independent, since .
A random variable, (ω), is a mapping that assigns a real number for each value ω in the set of outcomes of the random experiment. The mapping needs to be such that all outcomes that are mapped to the values +∞ and −∞ should have probability 0. Further, for all values x, the set { ≤ x} corresponds to an event. Random variables are typically used to quantify and study the statistical properties associated with a random experiment.
A complex random variable is defined as = + i where and are real valued random variables. For simplicity, most of the material in this chapter will focus on real valued random variables.
The cumulative distribution function (CDF) or probability distribution function, F, of random variable is defined as
(7.7) |
The following properties of the CDF immediately follow:
• The CDF is a number between 0 and 1, i.e., 0 ≤ (x) ≤ 1.
• The CDF of a random variable evaluated at infinity and negative infinity equals, 1 and 0, respectively, i.e., (∞) = 1 and (−∞) = 0.
• The CDF (x) is a nondecreasing function of x.
• The probability that the random variable takes values between x1 and x2 is given by the difference in the CDF at those values, i.e., Pr , if x1 < x2.
• The CDF is right continuous, i.e., limϵ→0 (x + ϵ) = (x), when ϵ > 0.
A random variable is completely defined by its CDF in the sense that any property of the random variable can be calculated from the CDF. A random variable is typically categorized as being a discrete random variable, continuous random variable, or mixed random variable.
7.2.1 Discrete Random Variables
Random variable is said to be a discrete random variable if the CDF is constant except at a countable set of points. For a discrete random variable, the probability mass function (PMF), (x), is equal to the probability that random variable takes on value x. Thus (x) = (x) − (x−). Clearly, since the PMF represents a probability value, (x) ≥ 0 and . Similar to the CDF, the PMF also completely determines the properties of a discrete random variable.
Example 7.2.1. Let random variable be defined as the number of Heads that appear in 3 flips of a biased coin with probability of Head in each flip equal to 0.3. Figure 7.1 shows a plot of the PMF and corresponding CDF for random variable .
□
Certain random variables appear in many different contexts and consequently they have been assigned special names. Moreover, their properties have been thoroughly studied and documented. We now highlight a few of the common discrete random variables, their distributions, and a typical scenario where they are applicable.
• A Bernoulli random variable takes values 0 and 1 with probabilities α and 1 − α, respectively. A Bernoulli random variable is commonly used to model scenarios in which there are only two possible outcomes such as in a coin toss or in a pass or fail testing.
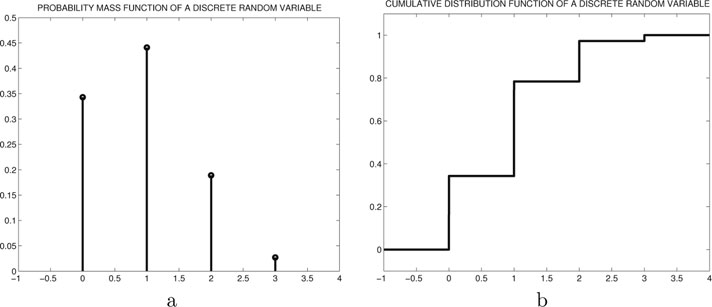
Figure 7.1: Illustration of the PMF and CDF of a simple discrete random variable in Example 7.2.1.
• A binomial random variable takes values in the set {0,1, 2,…, N} and could represent the number of Heads in N independent flips of a coin. If the probability of receiving a Head in each flip of the coin equals p, then the PMF of the binomial random variable is given by
(7.8) |
Example 7.2.2. In error control coding, a rate 1/n repetitive code [6] consists of transmitting n identical copies of each bit. Let these bits be transmitted over a binary symmetric channel (BSC) with crossover probability p. In this case, random variable that represents the number of bits that are received correctly has the binomial distribution given in (7.8).
□
• A geometric random variable has a PMF of the form
(7.9) |
Example 7.2.3. Consider a packet communication network in which a packet is retransmitted by the transmitter until a successful acknowledgment is received. In this case, if the probability of successful packet transmission in each attempt equals p and each transmission attempt is independent of the others, then random variable which represents the number of attempts until successful packet reception has a geometric distribution given in (7.9).
• A discrete uniform random variable has PMF of the form
(7.10) |
where without loss of generality b ≥ a.
• A Pascal random variable has PMF
(7.11) |
Consider a sequence of independent Bernoulli trials in which the probability of success in each trial equals p. The experiment is repeated until exactly L successes. The random variable that represents the number of trials has a Pascal distribution.
• A Poisson random variable has PMF of the form
(7.12) |
The Poisson random variable is obtained as the limit of the binomial random variable in the limit that n → ∞ and p → 0 but the product np is a constant. The Poisson random variable represents the number of occurrences of an event in a given time period. For instance, the number of radioactive particles emitted in a given period of time by a radioactive source is modeled as a Poisson random variable. Similarly, in queueing theory a common model for packet arrivals is a Poisson process, in which the number of packet arrivals per unit time is given by (7.12).
□
7.2.2 Continuous Random Variables
Random variable is said to be a continuous random variable if the CDF of is continuous. The probability density function (PDF) (x) of random variable is defined as
(7.13) |
Note that unlike the PMF, the PDF may take values greater than 1. The PDF is only proportional to the probability of an event. The interpretation of the PDF is that the probability of taking values between x and x + δx approximately equals (x)δx, for small positive values of δx. Similar to the CDF, the PDF is also a complete description of the random variable. The PDF of satisfies the following properties:
• Since the CDF is a nondecreasing function, the PDF is non-negative, i.e., (x) ≥ 0.
• The integral of the PDF over a certain interval represents the probability of the random variable taking values in that interval, i.e., .
• Extending the above property, the integral of the PDF over the entire range -TO equals 1, i.e., .
Example 7.2.4. Suppose a random point on the number line uniformly between the values 0 and 3. Let random variable represent the coordinate of that point. Then the PDF of is given by , 0 < x < 3. The corresponding CDF is given by
(7.14) |
A plot of this PDF and CDF are given in Figure 7.2.
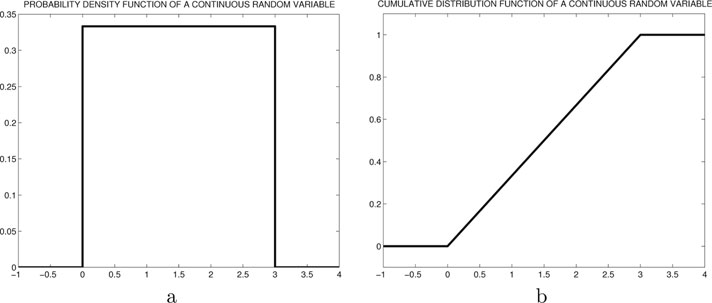
Figure 7.2: Illustration of the PMF and CDF of a simple discrete random variable in Example 7.2.4.
□
Similar to the discrete case, several commonly occurring continuous random variables have been studied including the following:
• The PDF of a uniform random variable is given by
(7.15) |
• The PDF of a Gaussian random variable (also referred to as Normal random variable) is given by
(7.16) |
The special case of a Gaussian random variable with 0 mean and unit variance is called a standard normal random variable. As will become clear in our study of the Central Limit Theorem, the distribution of any sum of independent random variables asymptotically approaches that of a Gaussian. Consequently, many noise and other realistic scenarios are modeled as Gaussian. The CDF of a Gaussian random variable is unfortunately not known in closed form. However, the CDF of a standard normal random variable has been computed numerically for various values and provided in the form of tables in several books. This CDF, denoted by Φ is defined as
(7.17) |
The CDF of any other Gaussian random variable with mean and variance can be evaluated using the CDF tables of a standard normal random variable as follows
(7.18) |
Note that several authors use other variants of Φ to numerically calculate the CDF and tail probabilities of a Gaussian random variable. For instance, the error function er f (x) is defined as
(7.19) |
This error function er f (x) and the Φ function can be expressed in terms of each other as and for positive values of x.
• An exponential random variable has a PDF given by
(7.20) |
The exponential distribution is frequently used to model the interarrival time between packets in the queueing theory (see Chapter 17). The exponential distribution has the special memoryless property as demonstrated by the following example.
Example 7.2.5. Let the lifetime of a fluorescent bulb be modeled as an exponential random variable with a mean of 10 years. Then the probability that the lifetime exceed 15 years is given by
(7.21) |
Now suppose the bulb has already been working for 6 years. In this case, the conditional probability that the lifetime exceeds 15 years is given by
(7.22) |
which is the same as the probability that the lifetime exceeds 15 − 6 = 9 years. The exponential random variable is the only continuous random variable that has this memoryless property.
□
Recall that a random variable is a mapping from the set of outcomes of an experiment to real numbers. Clearly, for a given set of experimental outcomes, there could be numerous mappings representing different random variables to different sets of real numbers. To understand the relationships between the various random variables, it is not sufficient to study their properties independent of each other; a joint study of these random variables is required.
The joint CDF (x,y) of two random variables and is given by
(7.23) |
Similar to the case of a single random variable, the joint CDF completely specifies the properties of the random variables. From the joint CDF, the marginal CDF of RVs and can be obtained as (x) = (x, ∞) and (y) = (∞,y). The joint CDF satisfies the following properties:
• 0 ≤ (x, y) ≤ 1.
• (−∞, −∞) = 0 and (∞, ∞) = 1.
• Pr (a < < b, c < ≤ d) = (a,c) + (b,d) − (a,d) − (b,c).
• (x, y) = limϵ→0,ϵ>0 (x+ϵ, y) and (x, y) = limϵ→0,ϵ>0 (x, y+ ϵ).
The joint PDF of RVs and is given by any function (x, y) such that
(7.24) |
Example 7.3.1. Consider random variables and with joint PDF given by
(7.25) |
The value of constant a =1/4 can be computed using the property that the integral of the PDF over the entire interval equals 1. In this case, the CDF can be computed as
(7.26) |
The probability of various events can be computed either from the PDF or from the CDF. For example, let event A = {0 ≤ ≤ 1/2, 1 ≤ ≤ 2}. The probability of A can be calculated using the PDF as
(7.27) |
(7.28) |
(7.29) |
The same probability can also be calculated using the joint CDF as
(7.30) |
(7.31) |
(7.32) |
The marginal PDFs of and can now be computed as
(7.33) |
(7.34) |
□
The conditional PDF (x∣y) is defined as
(7.35) |
when (y) > 0. For instance, in Exercise 7.3.1, the conditional PDF , 0<x<1 and conditional PDF , 0<y<1. Continuous random variables and are said to be independent if and only if
7.36 |
Example 7.3.2. Let the joint PDF of random variables and be given by (x, y) = xy for 0 ≤ x ≤ 1,0 ≤ y ≤ 2. Then the corresponding marginal PDFs are given by , 0 ≤ x ≤ 1 and , 0 ≤y ≤ 2. Clearly, (x,y) = (x) (y), which implies that random variables and are independent.
□
Similarly, discrete random variables and are said to be independent if and only if
(7.37) |
It is important to note that for independence of random variables (7.37) needs to be satisfied for all values of the random variables and .
Example 7.3.3. Let the joint PMF of random variables and be given by
(7.38) |
The marginal PMFs of and can be computed to show that they are both uniform densities over their respective alphabets. In this case, it can be easily verified that the events = 1 and =1 are independent. However, the events = 1 and = 2 are not independent. Thus, the random variables and are not independent.
Example 7.3.4. Consider a network in which packets are routed from the source node to the destination node using a routing protocol. Let there also be a probability a of packet loss at each node due to buffer overflows or errors in the link. In order to increase the overall chances of success, the routing algorithm sends three copies of each packet over different mutually exclusive routes. The three routes have a1, a2 and a3 hops between the source and destination, respectively. Assume that the probability of success in each hop is independent of the other hops. In this case the overall probability that at least one copy of the packet is received correctly at the destination node can be calculated as .
□
7.3.1 Expected Values, Characteristic Functions
As noted before, the PDF, CDF and PMF are all complete descriptors of the random variable and can be used to evaluate any property of the random variable. However, for many complex scenarios, computing the exact distribution can be challenging. In contrast, there are several statistical values that are computationally simple, but provide only partial information about the random variable. In this section, we highlight some of the frequently utilized statistical measures.
The expected value, E { }, of random variable is defined as
(7.39) |
In general the expected value of any function g( ) of a random variable is given by
(7.40) |
The term, E { } is known as the kth moment of . The variance of is related to the second moment and is given by
(7.41) |
As another variation, the kth central moment of random variable is defined as .
The covariance between random variables and is defined as
(7.42) |
The correlation coefficient is defined as
(7.43) |
Example 7.3.5. Jointly Gaussian Vector The joint PDF of the Gaussian vector is given by
(7.44) |
where x = [x1, x2,… xn]T and μX = is the mean of the different random variables and is the covariance matrix with ith row and jth column element given by Cov . Gaussian random vectors are frequently used in several signal processing applications. For instance, when estimating a vector parameter in the presence of additive noise. The reasons for the popularity of these Gaussian vector models are: i) by central limit theorem, the noise density is well approximated as a Gaussian, ii) several closed form analytical results can be derived using the Gaussian model, and iii) the results derived using a Gaussian approximation serves as a bound for the true performance.
The marginal density of a jointly Gaussian vector are a Gaussian random variable. However, marginal densities being Gaussian does not necessarily imply that the joint density is also Gaussian.
□
The random variables and are said to be uncorrelated if = 0. If and are independent, then
(7.45) |
which implies that the random variables are also uncorrelated. However, uncorrelated random variables are not always independent as demonstrated by the following example.
Example 7.3.6. Let be uniformly distributed in the interval (0, 2π). Let = cos( ) and = sin(). Then it is clear that and E = 0. Consequently, = 0. However, it is clear that and are dependent random variables since and given the value of the value of is known except for its sign.
□
In the special case that and are jointly Gaussian, then if they are uncorrelated they are also independent. This result can be verified by plugging in crosscorrelation values of 0 in the autocorrelation matrix that determines the joint PDF of and . Matrix R becomes a diagonal matrix and consequently the joint PDF then simply becomes the product of the marginal PDFs.
The characteristic function of is defined as
(7.46) |
The characteristic function and the PDF form a unique pair; thus, the characteristic function also completely defines the random variable.
The characteristic function can be used to easily compute the moments of the random variable. Using the Taylors series expansion of ejωx, we can expand the characteristic function as
(7.47) |
(7.48) |
(7.49) |
Now to compute the kth moment , we can differentiate (7.49) k times with respect to ω and then evaluate the result at ω = 0. Thus, .
Example 7.3.7. Let be an exponential random variable with parameter λ. The characteristic function of this random variable is given by
(7.50) |
The mean of can be calculated as
(7.51) |
The second order moment can be evaluated as
(7.52) |
Consequently, the variance can be calculated as
(7.53) |
The second characteristic function is defined as the natural logarithm of the function . The cumulants λn are
□
(7.54) |
The various cumulants are related to the moments as follows:
(7.55) |
(7.56) |
(7.57) |
(7.58) |
The cumulants of order higher than 3 are not the same as the central moment. Of special interest is the fourth-order cumulant, which is also referred to as kurtosis. The kurtosis is typically used as a measure of the deviation from Gaussianity of a random variable. The kurtosis of a Gaussian random variable equals 0. Further, for a distribution with a heavy tail and a peak at zero, the kurtosis is positive and for distribution with a fast decaying tail the kurtosis is negative.
Example 7.3.8. Consider the uniform random variable with support over (0,1). The first four moments of can be calculated as
The kurtosis of can be now calculated using (7.58) as λ4 = −2/15.
□