
Chapter 8 Random Matrix Theory
‡ L’École Supérieure D’Electricité (SUPELEC), France
Random matrix theory deals with the study of matrix-valued random variables. It is conventionally considered that random matrix theory dates back to the work of Wishart in 1928 [1] on the properties of matrices of the type XX† with X ∈ ℂN×n a random matrix with independent Gaussian entries with zero mean and equal variance. Wishart and his followers were primarily interested in the joint distribution of the entries of such matrices and then on their eigenvalues distribution. It then dawned to mathematicians that, as the matrix dimensions N and n grow large with ratio converging to a positive value, its eigenvalue distribution converges weakly and almost surely to some deterministic distribution, which is somewhat similar to a law of large numbers for random matrices. This triggered a growing interest in particular among the signal processing community, as it is usually difficult to deal efficiently with large dimensional data because of the so-called curse of dimensionality. Other fields of research have been interested in large dimensional random matrices, among which the field of wireless communications, as the eigenvalue distribution of some random matrices is often a sufficient statistics for the performance evaluation of multidimensional wireless communication systems.
In the following, we introduce the main notions, results and details of classical as well as recent techniques to deal with large random matrices.
In this chapter, an event will be the element ω of some set Ω. Based on Ω, we will consider the probability space (Ω, F
μχ(A)≜Pr({ω,χ(ω)∈ A})
the probability distribution of X
When μX
∫f(x)Pχ(x)dx ≜ ∫f(x)μχ(dx).
To differentiate between multidimensional random variables and scalar random variables, we may denote pX
F(x)≜pχ(( − ∞,x])
denotes the CDF of X
We further denote, for X
Pχ|Y(x,y)≜Pχ,Y(x,y)PY(y)
the conditional probability density of X
8.2 Spectral Distribution of Random Matrices
We start this section with a formal definition of a random matrix and the introduction of necessary notations.
Definition 8.2.1. An N × n matrix X is said to be a random matrix if it is a matrix-valued random variable on some probability space (Ω, F
We shall in particular often consider the marginal probability distribution function of the eigenvalues of random Hermitian matrices X. Unless otherwise stated, the distribution function (d.f.) of the real eigenvalues of X will be denoted FX.
We now discuss the properties of the so-called Wishart matrices and some known results on unitarily invariant random matrices. These properties are useful to the characterization, e.g., of Neyman-Pearson tests for signal sensing procedures [2] , [3].
We start with the definition of a Wishart matrix.
Definition 8.2.2. The N × N random matrix XX† is a (real or complex) central Wishart matrix with n degrees of freedom and covariance matrix R if the columns of the N × n matrix X are zero mean independent (real or complex) Gaussian vectors with covariance matrix R. This is denoted
XX†~WN(n,R).
Defining the Gram matrix associated to any matrix X as being the matrix XX†, XX† ~ W
One interest of Wishart matrices in signal processing applications lies in the following remark.
Remark 8.2.1. Let x1,…, xn ∈ ℂN be n independent samples of the random process x1 ≃ C
n∑i = 1xix†i=XX†.
For this reason, the random matrix Rn = 1nXX†
Wishart provides us with the joint probability density function of the entries of Wishart matrices, as follows:
Theorem 8.2.1 ([1]). The PDF of the complex Wishart matrix XX‡ ≃ W
PXX†(B) = πN(N − 1)/2det (Rn)∏Ni = 1(n − i)!e − tr(R − 1B)det (Bn − N). |
(8.1) |
Note in particular that for N =1, this is a conventional chi-square distribution with n degrees of freedom.
For null Wishart matrices, notice that PXX† (B) = PXX† (UBU‡), for any unitary N × N matrix U.1 Otherwise stated, the eigenvectors of the random variable XX† are uniformly distributed over the space U
The joint PDF of the eigenvalues of zero Wishart matrices were studied simultaneously in 1939 by different authors [4, 5, 6, 7]. The two main results are summarized in the following,
Theorem 8.2.2. Let the entries of X ∈ ℂN×n, n > N, be independent and identically distributed (i.i.d.) Gaussian with zero mean and unit variance. The joint PDF P(λi)
P(λi)(λ1,…λN) = e − ∑Ni = 1λiN∏i = 1λn − Ni(n − i)!(N − i)Δ(Λ)2,
where, for a Hermitian non-negative N × N matrix Λ,2 Δ(Λ) denotes the Vandermonde determinant of its eigenvalues λ1,…, λN,
Δ(Λ)≜∏1≤i<j≤N(λj − λi).
The marginal PDF pλ (≜ Pλ) of the unordered eigenvalues is
pλ(λ) = 1MN − 1∑k = 0k!(k + n − N)![Ln − Nk(λ)]2λn − Ne − λ,
where Lkn(λ)
Lkn(λ) = eλk!λndkdλk(e − λλn + k).
The generalized case of (non-zero) central Wishart matrices is more involved since it requires advanced tools of multivariate analysis, such as the fundamental Harish-Chandra integral [8]. We will mention the result of Harish-Chandra, which is at the core of the results in signal sensing presented later in Section 8.5.1.
Theorem 8.2.3. For nonsingular N × N positive definite Hermitian matrices A and B of respective eigenvalues a1,…, aN and b1,…, bN, such that for all i ≠ j, ai ≠ aj and bi ≠ bj, we have
∫U∈U(N)eκ tr(AUBU†)dU = (N − 1∏i = 1i!)κ12N(N − 1)det ({e − bjai}1≤i,j≤N)Δ(A)Δ(B)
where, for any bivariate function f, {f (i,j)}1≤ij≤N denotes the N × N matrix of (i,j) entry f (i,j), and U
This result enables the calculation of the marginal joint-eigenvalue distribution of (non-zero) central Wishart matrices [9], given as follows:
Theorem 8.2.4. Let the columns of X ∈ ℂN×n be independent and identically distributed (i.i.d.) zero mean Gaussian with positive definite covariance R. The joint PDF P(λi)
P(λi)(λ1,…,λN)det ({e − r − 1jλi}1≤i,j≤N)Δ(R − 1)Δ(Λ)N∏j = 1λn − Njrnj(n − j)!
where r1 ≥ … ≥ rN denote the ordered eigenvalues of R and Λ = diag (λ1 ≥ … ≥ λN).
This is obtained from the joint distribution of Wishart matrices XX† which, up to a variables change, leads to the joint distribution of the couples (U, L) of unitary matrices and diagonal eigenvalue matrices such that XX† = ULU†. In performing this variable change, the Jacobian Δ(L)2 arises. Integrating over U to obtain the marginal distribution of L, we recognize the Harish-Chandra equality which finally leads to the result.
These are the tools we need for the study of Wishart matrices. As it appears, the above properties hold due to the rotational invariance of Gaussian matrices. For more involved random matrix models, e.g., when the entries of the random matrices under study are no longer Gaussian, the study of the eigenvalue distribution is much more involved, if not unfeasible.
However, it turns out that, as the matrix dimensions grow large, nice properties arise that can be studied much more efficiently than when the matrix sizes are kept fixed. A short introduction to these large matrix considerations is described hereafter.
8.2.2 Limiting Spectral Distribution
Consider an N × N (non-necessarily random) Hermitian matrix XN. Define its empirical spectral distribution (e.s.d.) FXN
FXN(x) = 1NN∑j = 11λj≤x(x),
where λ1 ≥ … ≥ λN are the eigenvalues of XN.3
The relevant aspect of large N × N Hermitian matrices XN is that their (random) e.s.d. FXn often converges, with N ϕ ∞, towards a nonrandom distribution F. This function F, if it exists, will be called the limit spectral distribution (l.s.d.) of XN. Weak convergence [11] of FXN
FXN⇒F.
In most cases though, the weak convergence of FXN
The Marc̆enko-Pastur Law
In signal processing, one is often interested in sample covariance matrices or even more general matrices such as independent and identically distributed (i.i.d.) matrices with left and right correlation, or i.i.d. matrices with a variance profile [12]. One of the best known results with a large range of applications in signal processing is the convergence of the empirical spectral distribution (e.s.d.) of the Gram matrix of a random matrix with i.i.d. entries of zero mean and normalized variance (not necessarily a Wishart matrix). This result is due to Marc̆enko and Pastur [13], so that the limiting e.s.d. of the Gram matrix is called the Marc̆enko-Pastur law. The result unfolds as follows.
Theorem 8.2.5. Consider a matrix X ∈ ℂN×n with i.i.d. entries (1√nχ(N)ij)
fc(x) = (1 − c − 1) + δ(x) + 12πcx√(x − a) + (b − x) + , |
(8.2) |
where a = (1 − √c)2,b = (1 + √c)2
The d.f. Fc is named the Marc̆enko-Pastur law with limiting ratio c. This is depicted in Figure 8.1 for different values of the limiting ratio c. Notice in particular that, when c tends to be small and approaches zero, the Marc̆enko-Pastur law reduces to a single mass in 1, as the law of large numbers in classical probability theory requires.
Several approaches can be used to derive the Marc̆enko-Pastur law. However, the original technique proposed by Marc̆enko and Pastur is based on a fundamental tool, the Stieltjes transform, which will be constantly used in this chapter. In the following we present the Stieltjes transform, along with a few important lemmas, before we introduce several applications based on the Stieltjes transform method.

Figure 8.1: Marc̆enko-Pastur law for different limit ratios c = lim N/n.
The Stieltjes Transform and Associated Lemmas
Definition 8.2.3. Let F be a real-valued bounded measurable function over ℝ. Then the Stieltjes transform mF(z),4 for z ∈ Supp (F)c, the complex space complementary to the support of F,5 is defined as
(8.3) |
For all F that admit a Stieltjes transform, the inverse transformation exists and is given by [10, Theorem B.8]:
Theorem 8.2.6. If x is a continuity points of F, then
F(x) = 1πlimy→0 + ∫x − ∞J[mF(x + iy)] dx. |
(8.4) |
In practice here, F will be a distribution function. Therefore, there exists an intimate link between distribution functions and their Stieltjes transforms. More precisely, if F1 and F2 are two distribution functions (therefore right-continuous by definition [16, see §14]) that have the same Stieltjes transform, then F1 and F2 coincide everywhere and the converse is true. As a consequence, mF uniquely determines F and vice versa. It will turn out that, while working on the distribution functions of the empirical eigenvalues of large random matrices is often a tedious task, the approach via Stieltjes transforms greatly simplifies the study. The initial intuition behind the Stieltjes transform approach for random matrices lies in the following remark: for an Hermitian matrix X ∈ ℂN×N,
mFX(z) = ∫1λ − zdFX(λ) = 1Ntr(Λ − zIN) − 1 = 1Ntr(X − zIN) − 1,
in which we denoted Λ the diagonal matrix of eigenvalues of X. Working with the Stieltjes transform of FX therefore boils down to working with the matrix (X − zIN)−1, and more specifically with the sum of its diagonal entries. From matrix inversion lemmas and several fundamental matrix identities, it is then rather simple to derive limits of traces 1Ntr(X − zIN) − 1
An identity of particular interest is the relation between the Stieltjes transform of XX† and X†X, for X ∈ ℂN×n. Note that both matrices are Hermitian, and actually non-negative definite, so that the Stieltjes transform of both is well defined.
Lemma 8.2.1. For z ∈ ℂ ℝ+, we have
nNmFxx†(z) = mFxx†(z) + N − nN1z.
On the wireless communication side, it turns out that the Stieltjes transform is directly connected to the expression of the mutual information, through the so-called Shannon transform, initially coined by Tulino and Verdú [17, see §2.3.3].
Definition 8.2.4. Let F be a probability distribution defined on ℝ+. The Shannon-transform V
(8.5) |
The Shannon-transform of F is related to its Stieltjes transform mF through the expression
VF(x) = ∫∞1x(1t − mF( − t))dt. |
(8.6) |
This last relation is fundamental to derive a link between the limit spectral distribution (l.s.d.) of a random matrix and the mutual information of a multidimensional channel, whose model is based on this random matrix.
We complete this section by the introduction of fundamental lemmas, required to derive the l.s.d. of random matrix models with independent entries, among which the Marčenko-Pastur law, and that will be necessary to the derivation of deterministic equivalents. These are recalled briefly below.
The first lemma is called the trace lemma, introduced in [15] (and extended in [18] under the form of a central limit theorem), which we formulate in the following theorem.
Theorem 8.2.7. Let A1, A2,AN ∈ ℂN×N, be a series of matrices with uniformly bounded spectral norm. Let x1, x2,… be random vectors of i.i.d. entries such that xN ∈ ℂN has zero mean, variance 1/N and finite eighth order moment, independent of AN. Then
(8.7) |
as N → ∞.
Several alternative versions of this result exist in the literature, which can be adapted to different application needs, see e.g., [12, 14].
The second important ingredient is the rank-1 perturbation lemma, given below [14, Lemma 2.6]:
Theorem 8.2.8. (i) Let z ∈ ℂℝ, A ∈ ℂN×N , B ∈ ℂN×N with B Hermitian, and v ∈ ℂN. Then
|1Ntr (A((B − zIN) − 1 − (B+vv† − zIN) − 1))|≤‖A‖N|J(z)|,
with ∥A∥ the spectral norm of A.
(ii) Moreover, if B is non-negative definite, for z ∈ ℝ−,
|1Ntr (A((B − zIN) − 1 − (B+vv† − zIN) − 1))|≤‖A‖N|(z)|.
Generalizations of the above result can be found e.g., in [12].
Based on the above ingredients and classical results from probability theory, it is possible to prove the almost sure weak convergence of the e.s.d. of XX†, where X ∈ ℂN×n has i.i.d. entries of zero mean and variance 1/n, the Marc̆enko-Pastur law, as well as the convergence of the e.s.d. of more involved random matrix models based on matrices with independent entries. In particular, we will be interested in Section 8.5.2 in limiting results on the e.s.d. of sample covariance matrices.
Limiting Spectrum of Sample Covariance Matrices
The limiting spectral distribution of the sample covariance matrix unfolds from the following result, originally provided by Bai and Silverstein in [14], and further extended in e.g., [10],
Theorem 8.2.9. Consider the matrix BN = AN + X†NTNXN∈Cn × n
mFB(z) = mFA(z − c∫t1 + tmFB(z)dFT(t)). |
(8.8) |
The solution of the implicit equation (8.8) in the dummy variable mFB (z) is unique on the set {z ∈ ℂ+, mFB (z) ∈ ℂ+}. Moreover, if the XN has identically distributed entries, then the result holds without requiring that a moment of order 2 + ε exists.
In the following, using the tools from the previous sections, we give a sketch of the proof of Theorem 8.2.9.
Proof. The fundamental idea to infer the final formula of Theorem 8.2.9 is to first guess the form it should take. For this, write
mFBN(z)≜1ntr(AN + X†NTNXN − zIN) − 1.
and take DN ∈ ℂN×N to be some deterministic matrix such that
mFBN(z) − mN(z)a.s.→0
with
mN(z)≜1ntr(AN + DN − zIN) − 1
as N, n → ∞ with N/n → c. We then have, from the identity A−1 − B−11 = A−1(B − A)B−1,
mFBN(z) − mN(z) = 1ntr((BN − zIN) − 1(DN − X†NTNXN)(AN + DN − zIN) − 1).
Taking DN = aNIN, and writing
X†NTNXN = N∑k = 1tNkxkx†k
with xk the kth column of X†N
MFBN(z) − mN(z) = aNntr((BN − zIN) − 1(AN + DN − zIN) − 1) − 1nN∑k = 1tNkx†k(AN + DN − zIN) − 1(BN − zIN) − 1xk.
Using the matrix inversion identity
(A + vv† − zIN) − 1v = 11 + v†(A − zIN) − 1v(A − zIN) − 1v,
each term in the sum of the right-hand side can further be expressed as
tNkx†k(AN + DN − zIN) − 1(BN − zIN) − 1xk = tNkx†k(AN + DN − zIN) − 1(B(k) − zIN) − 1xk1 + tNkx†k(B(k) − zIN) − 1xk
where B(k) = BN − tNkxkx†k and where now xk and (AN + DN − ZIN)−1(B(k) − ZIN)−1 are independent. But then, using the trace lemma, Theorem 8.2.7, we have that
x†k(AN + DN − zIN) − 1(B(k) − zIN) − 1xk − 1ntr((AN + DN − zIN) − 1(B(k) − zIN) − 1)a.s.→0.
Replacing the quadratic form by the trace in the Stieltjes transform difference, we then have for all large N,
MFBN(z) − mN(z)≃ aNntr((BN − zIN) − 1(AN + DN − zIN) − 1) − 1nN∑k = 1tNk1ntr((AN + DN − zIN) − 1(B(k) − zIN) − 1)1 + tNk1ntr((BN − zIN) − 1).
But then, from the rank−1 perturbation lemma, Theorem 8.2.8, this is further approximated, for all large N by
MFBN(z) − mN(z)≃ aNntr((BN − zIN) − 1(AN + DN − zIN) − 1) − 1nN∑k = 1tNk1ntr((AN + DN − zIN) − 1(B(k) − zIN) − 1)1 + tNk1ntr((BN − zIN) − 1).
where we recognize in the right-hand side the Stieltjes transform mFBN(z) = 1ntr((BN − zIN) − 1). Taking
aN = 1nN∑k = 1tNk11 + tNkmFBN(z)≃c∫t1 + tmFBN(z)dFT(t),
it is clear that the difference mFBN (Z) − mN (Z) becomes increasingly small for large N and therefore mFBN (Z) is asymptotically close to
1ntr((AN + c)∫tdFT(t)tmFBN(z)IN − zIN) − 1
which is exactly
mFAN(z − c∫tdFT(t)1 + tmFBN(z)).
Hence the result.
□
The sample covariance matrix model corresponds to the particular case where AN = 0. In that case, (8.8) becomes
(8.9) |
where we denoted F̲ ≜ FB in this special case. This special notation will often be used to differentiate the l.s.d. F of the matrix T12NXNX†NT12N from the l.s.d. F̲ of the reversed Gram matrix X†NTNXN. Remark indeed from Lemma 8.2.1 that the Stieltjes transform mF̲ of the l.s.d. F̲ of X†NTNXN is linked to the Stieltjes transform mF of the l.s.d. F of T12NXNX†NT12N through
(8.10) |
and then we also have access to a characterization of F, which is exactly the asymptotic eigenvalue distribution of the sample covariance matrix model, when the denormalized columns √nx1,…√nxn of √nXN form a sequence of independent vectors with zero mean and covariance matrix nE{x1x†1} = TN. An illustrative simulation example is given in Figure 8.2 where TN is constituted of three distinct eigenvalues.
Secondly, in addition to the uniqueness of the pair (z,mF̲(z)) in the set {z ∈ ℂ+, mF̲ (z) ∈ ℂ+} solution of (8.9), an inverse formula for the Stieltjes transform can be written in closed-form, i.e., we can define a function zF̲(m) on {m̲ ∈ ℂ+, zF̲(m) ∈ ℂ+}, such that
(8.11) |
This will turn out to be extremely useful to characterize the spectrum of F. More on this topic is discussed in Section 8.3.
In this section, we summarize some important results regarding (i) the characterization of the support of the eigenvalues of a sample covariance matrix and (ii) the position of the individual eigenvalues of a sample covariance matrix. The point (i) is obviously a must-have from a pure mathematical viewpoint, but is also fundamental to the study of estimators based on large dimensional random matrices. We will provide in Section 8.4 and in Section 8.5.2 estimators of functionals of the eigenvalues of a population covariance matrix based on the observation of a sample covariance matrix. We will in particular investigate large dimensional sample covariance matrix models with population covariance matrix composed of a few eigenvalues with large multiplicities. The validity of these estimators relies importantly on the fact that the support of the l.s.d. of the sample covariance matrix is formed of disjoint so-called clusters; each cluster is associated to one of the few eigenvalues of the population covariance matrix. Characterizing the limiting support is therefore paramount to the study of the estimator performance. The point (ii) is even more important for the estimators described above, as knowing the position of the individual eigenvalues allows one to derive such estimators. This second point is also fundamental to the derivation of hypothesis tests based on large dimensional matrix analysis, that will be introduced in Section 8.5.1. What we will show in particular is that, under mild assumptions on the random matrix model, all eigenvalues are asymptotically contained within the limiting support. Also, when the limiting support is divided into disjoint clusters, the number of sample eigenvalues in each cluster corresponds exactly to the multiplicity of the population eigenvalue attached to this cluster. For signal sensing, this is fundamental as the observation of a sample eigenvalue outside the expected limiting support of the pure noise hypothesis (called hypothesis H0) suggests that a signal is present in the observed data.

Figure 8.2: Histogram of the eigenvalues of BN=T12NXNX†NT12N, n = 3000, with TN diagonal composed of three evenly weighted masses in (a) 1, 3, and 7, (b) 1, 3, and 4.
We start with the point (ii).
8.3.1 Exact Eigenvalue Separation
The results of interest here are due to Bai and Silverstein and are summarized in the following theorems.
Theorem 8.3.1 ([15]). Let XN = (1√nχNij)∈CN × n have i.i.d. entries, such that XNij has zero mean, variance 1 and finite fourth order moment. Let TN ∈ ℂN×N be nonrandom, whose e.s.d. FTN converge weakly to H. From Theorem 8.2.9, the e.s.d. of BN=T12NXNX†NT12N∈CN × N converges weakly and almost surely towards some distribution function F, as N, n go to infinity with ratio cN = N/n → c, 0 < c < ∞. Similarly, the e.s.d. of B_N=X†NTNXN∈Cn × n converges towards F̲ given by
F_(x) = cF(x) + (1 − c)1[0,∞)(x).
Denote F̲N the distribution of Stieltjes transform mF_N(z), solution, for z ∈ ℂ+, of the following equation in m
m = − (z − Nn∫τ1 + τmdFTN(τ)) − 1,
and define FN the d.f. such that
F_N(x) = NnFN(x) + (1 − Nn)1[0,∞)(x).
Let N0 ∈ ℕ, and choose an interval [a, b], a > 0, outside the union of the supports of F and FN for all N ≥ N0. For ω ∈ Ω, the random space generating the series X1, X2,…, denote LN(ω) the set of eigenvalues of BN(ω). Then,
P(ω,ℒN(ω)∩ [a,b]≠ 0, i.o.) = 0.
This means concretely that, given a segment [a, b] outside the union of the supports of F and FN0,FN0 + 1,…, for all series B1(ω), B2(ω), …, with ω in some set of probability one, there exists M(ω) such that, for all N ≥ M(ω), there will be no eigenvalue of BN (ω) in [a, b].
As an immediate corollary of Theorem 8.2.5 and Theorem 8.3.1, we have the following results on the extreme eigenvalues of BN, with TN = IN.
Corollary 8.3.2. Let BN ∈ ℂN×N be defined as BN = XNX†N, with XN ∈ ℂN ×n with i.i.d. entries of zero mean, variance 1/n and finite fourth order moment. Then, denoting λNmin and λNmax the smallest and largest eigenvalues of BN, respectively, we have
λNmin a.s.→(1 − √c)2λNmax a.s.→(1 + √c)2
as N, n → ∞ with N/n → c.
This result further extends to the case when BN = XNTNX†N, with TN diagonal with ones on the diagonal but for a few entries different from one. This model, often referred to as spiked model lets some eigenvalues escape the limiting support of BN (which is still the support of the Marc̆enko-Pastur law). Note that this is not inconsistent with Theorem 8.3.1 since here, for all finite N0, the distribution functions FN0,FN0 + 1,… may all have a non-zero mass outside the support of the Marc̆enko-Pastur law. The segments [a, b] where no eigenvalues are found asymptotically must be away from these potential masses. The theorem, due to Baik, is given precisely as follows
Theorem 8.3.3 ([19]). Let ˉBN = ˉT12NXNX†NˉT12N, where XN ∈ ℂN×n has i.i.d. entries of zero mean and variance 1/n, and ̄TN ∈ ℝN ×N is diagonal given by
ˉTN = diag (α1,…,α1︸k1…,αM,…,αM︸kM,1,…,1︸N − ∑Mi = 1ki)
with α1 > … > αM > 0 for some positive integer M. We denote here c = limNN/n.Call M0 = #{j|αj>1 + √c}. For c < 1, take also M1 to be such that M − M1 = #{j|αj<1 − √c}. Denote additionally λ1 ≥ … ≥ λN the eigenvalues of BN, ordered as λ1 ≥ … ≥ λN. We then have
• for 1 ≤ j ≤ M0, 1 ≤ i ≤ kj,
λk1 + … + kj − 1 + ia.s.→αj + cαjαj − 1,
• for the other eigenvalues, we must discriminate upon c,
– if c < 1,
* for M1 + 1 ≤ j ≤ M, 1 ≤ i ≤ kj,
λN − kj − … − kM + ia.s.→αj + cαjαj − 1,
* for the indexes of eigenvalues of TN inside [1 − √c,1 + √c],
λk1 + … + kM0 + 1a.s.→(1 + √c)2,λN − kM1 + 1 − … − kMa.s.→(1 − √c)2,
– if c > 1,
λna.s.→(1 − √c)2,λn + 1 = … = λN = 0,
– if c = 1,
λmin(n,N)a.s.→0.
The important part of this result is that all αj such that αj>1 + √c produces an eigenvalue of BN outside the support of the Marc̆enko-Pastur, found asymptotically at the position aj + cαjαj − 1.
Now Theorem 8.3.1 and Theorem 8.3.3 ensure that, for a given N0, no eigenvalue of BN is found outside the support of FN0,FN0 + 1,… for all large N, but do not say where the eigenvalues of BN are approximately positioned. The answer to this question is provided by Bai and Silverstein in [20] in which the exact separation properties of the l.s.d. of such matrices BN is discussed.
Theorem 8.3.4 ([20]). Assume BN is as in Theorem 8.3.1 with TN non-negative definite and FTN converging weakly to the distribution function H, and cN = N/n converging to c. Consider also 0 < a < b < ∞ such that [a, b] lies outside the support of F, the l.s.d. of BN. Denote additionally λk and τk the kth eigenvalues of BN and TN in decreasing order, respectively. Then we have
1. If c(1 − H(0)) > 1, then the smallest eigenvalue x0 of the support of F is positive and λN → x0 almost surely, as N → ∞.
2. If c(1 − H(0)) ≤ 1, or c(1 − H(0)) > 1 but [a,b] is not contained in [0, x0], then
Pr(ω, λiN > b, λiN + 1 < a) = 1,
for all N large, where iN is the unique integer such that
τiN > − 1/mF(b),τiN + 1 < − 1/mF(a).
Theorem 8.3.4 states in particular that, when the limiting spectrum can be divided in disjoint clusters, then the index of the sample eigenvalue “for which a jump from one cluster (right to b) to a subsequent cluster (left to a) arises” corresponds exactly to the index of the population eigenvalue where a jump arises in the population eigenvalue spectrum (from −1/mF(b) to −1/mF(a)). Therefore, the sample eigenvalues distribute as one would expect between the consecutive clusters. This result will be used in Section 8.4 and Section 8.5.2 to find which sample eigenvalues are present in which cluster. This is necessary because we will perform complex integration on contours surrounding specific clusters and that residue calculus will demand that we know exactly what eigenvalues are found inside these contours.
Nonetheless, this still does not exactly answer the question of the exact characterization of the limiting support, which we treat in the following.
Remember from the inverse Stieltjes transform formula (8.4) that it is possible to determine the support of the l.s.d. F of a random matrix once we know its limiting Stieltjes transform mF(z) for all z ∈ ℂ+. Thanks to Theorem 8.2.9, we know in particular that we can determine the support of the l.s.d. of a sample covariance matrix. Nonetheless, (8.4) features a limit for the imaginary part y of the argument z = x + iy of mF (z) going to zero, which has not been characterized to this point (even its existence everywhere is not ensured). Choi and Silverstein proved in [21] that this limit does exist for the case of sample covariance matrices and goes even further in characterizing exactly what this limit is. This uses the important Stieltjes transform composition inverse formula (8.11) and is summarized as follows.
Theorem 8.3.5 ([21]). Denote ScX the complementary of SX, the support of some d.f. X. Let B_N = X†NTNXN∈Cn × n have l.s.d. F̲, where XN ∈ ℂN ×n has i.i.d. entries of zero mean and variance 1/n, TN has l.s.d. H and N/n → c. Let B = {m_|m_≠0, − 1/m_∈ScH} and XF̲ be the function defined on B by
(8.12) |
For x0 ∈ ℝ*, we can then determine the limit of mF̲ (z) as z → x0, z ∈ ℂ+, along the following rules,
(R.I) |
If x0∈ScF_, then the equation x0 = xF_(m_) in the dummy variable m̲ has a unique real solution m0 ∈ B such that x′F̲(m0) > 0; this m0 is the limit of x′F̲(z) when z → x0, z ∈ ℂ+. Conversely, for m0 ∈ B such that x′F_(m0)>0. |
(R.II) |
If x0 ∈ SF̲ then the equation x0 = xF̲(m̲) in the dummy variable m̲ has a unique complex solution mo ∈ B with a positive imaginary part; this m0 is the limit of mF̲(z) when z → x0, z ∈ ℂ+. |
From Theorem 8.3.5.(R.I), it is possible to determine the exact support of F. It indeed suffices to draw xF̲ (m̲) for −1 /m̲ ∈ ℝ SH. Whenever xF̲ is increasing on an interval I, xF̲ (I) is outside SF̲. The support SF̲ of F̲, and therefore of F (modulo the mass in 0), is then defined exactly by
SF_ = ℝ∪a,b,∈,ℝ a<b{zF_((a,b))|∀m_ ∈ (a,b),x′F_(m_)>0}.
This is depicted in Figure 8.3 in the case when H is composed of three evenly weighted masses t1,t2,t3 in {1, 3, 5} or {1, 3, 10} and c = 1/10. Notice that, in the case where t3 = 10, F is divided into three clusters while when t3 = 5, F is divided into only two clusters, which is due to the fact that xF̲ is nonincreasing in the interval (−1/3, −1/5).
From Figure 8.3 and Theorem 8.3.5, we now observe that x′F̲(m̲) has exactly 2KF roots with KF the number of clusters in F. Denote these roots m_−1<m_ + 1≤m_ − 2<m_ + 2<…≤m_ − KF<m_ + KF. Each pair (m_ − j,m_ + j) is such that xF_([m_ − j,m_ + j]) is the jth cluster in F. We therefore have a way to determine the support of the asymptotic spectrum through the function x′F̲. This is presented in the following result.
Theorem 8.3.6 ([22, 23]). Let BN ∈ ℂN×N be defined as in Theorem 8.3.1. Then the support SF of the l.s.d. F of BN is defined as
SF=KF∪i=1[x−j,x+j],
where x − 1,x + 1,…,x − KF,x + KF are defined as
x−j=−1m_−j+K∑r=1crtr1+trm_−j,x+j=−1m_−j+K∑r=1crtr1+trm_+j,
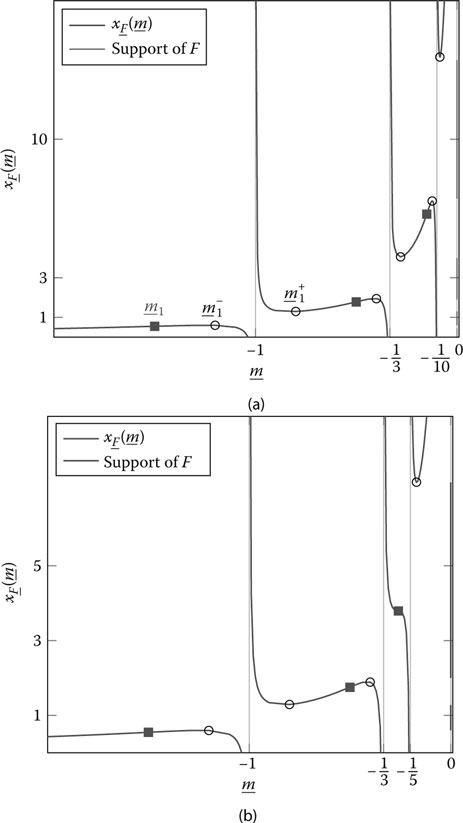
Figure 8.3: xF̲(m̲) for TN diagonal composed of three evenly weighted masses in 1, 3, and 10 (a) and 1, 3, and 5 (b), c = 1/10 in both cases. Local extrema are marked in circles, inflexion points are marked in squares. The support of F can be read on the right vertical axes.
with m_ − 1<m_ + 1≤m_ − 2<m_ + 2<…≤m_ − KF<m_ + KF the 2KF (possibly counted with multiplicity) real roots of the equation in m̲,
K∑r = 1crt2rm_2(1 + trm_2)2 = 1.
Notice further from Figure 8.3 that, while x′F̲(m̲) might not have roots on some intervals (−1/tk−1, −1/tk), it always has a unique inflexion point there. This is proved in [23] by observing that x″F̲(m̲) = 0 is equivalent to
K∑r = 1crt3rm_3(1 + trm_)3 − 1 = 0,
the left-hand side of which has always a positive derivative and shows asymptotes in the neighborhood of tr; hence the existence of a unique inflexion point on every interval (−1/tk−1, − 1/tk), for 1 ≤ k ≤ K, with convention t0 = 0+. When xF̲ increases on an interval (−1/tk−1, − 1/tk), it must have its inflexion point in a point of positive derivative (from the concavity change induced by the asymptotes). Therefore, to verify that cluster kF is disjoint from clusters (k − 1)F and (k + 1)F (when they exist), it suffices to verify that the (k − 1)th and kth roots m̲k−1 and m̲k of x″F̲(m̲) are such that x′F̲(m̲k_1) > 0 and x′F̲(m̲k) > 0. This is exactly what the following result states for the case of a sample covariance matrix whose population covariance matrix has few eigenvalues, each with a large multiplicity.
Theorem 8.3.7 ([23, 24]). Let BN be defined as in Theorem 8.3.1, with TN = diag (τ1,…, τN) ∈ ℝN×N, diagonal containing K distinct eigenvalues 0 < t1 < … < tK, for some fixed K. Denote Nk the multiplicity of the kth largest eigenvalue, counted with multiplicity (assuming ordering of the τi, we may then have τ1 = … = τN1 = t1,…,τN − NK + 1 = …τN = tK). Assume also that for all 1 ≤ r ≥ K, Nr/n → cr > 0, and N/n → c, with 0 < c < ∞. Then the cluster kF associated to the eigenvalue tk in the l.s.d. F of BN is distinct from the clusters (k − 1)F and (k + 1)F (when they exist), associated to tk−1 and tk+1 in F, respectively, if and only if
K∑r = 1crt3rm_2k(1 + trm_2k)2<1,K∑r = 1crt3rm_2k + 1(1 + trm_2k + 1)2<1, |
(8.13) |
where m̲1, …, m̲K are such that m̲K+1 = 0 and m̲1 < m̲2 < … < m̲K are the K solutions of the equation in m̲,
K∑r = 1crt3rm_3(1 + trm_)3 = 1.
For k = 1, this condition ensures 1F = 2F − 1; for k = K, this ensures KF = (K − 1)F +1; and for 1 < k < K, this ensures (k − 1)F+1 = kF = (k + 1)F− 1.
This result is again fundamental in the sense that the separability of subsequent clusters in the support of the l.s.d. of BN will play a fundamental role in the validity of statistical inference methods. In the subsequent section, we introduce the key ideas that allow statistical inference for sample covariance matrices.
Statistical inference allows for the estimation of deterministic parameters present in a stochastic model based on observations of random realizations of the model. In the context of sample covariance matrices, statistical inference methods consist in providing estimates of functionals of the eigenvalue distribution of the population covariance matrix TN ∈ ℂN×N based on the observation YN = T12NXN with XN ∈ ℂN×n a random matrix of independent and identically distributed entries. Different methods exist that allow for statistical inference that mostly rely on the study of the l.s.d. of the sample covariance matrix BN = 1nYNY†N. One of these methods relates to free probability theory [25], and more specifically to free deconvolution approaches, see e.g., [26], [27]. The idea behind free deconvolution is based on the fact that the moments of the l.s.d. of some random matrix models can be written as a polynomial function of the moments of the l.s.d. of another (random) matrix in the model, under some proper conditions. Typically, the moments of the l.s.d. of TN can be written as a polynomial of the moments of the (almost sure) l.s.d. of BN, if XN has Gaussian entries and the e.s.d. of TN has uniformly bounded support. Therefore, to put it simply, one can obtain all moments of TN based on a sufficiently large observation of BN; this allows one to recover the l.s.d. of TN (since Carleman condition is satisfied) and therefore any functional of the l.s.d. However natural, this method has some major drawbacks. From a practical point of view, a reliable estimation of moments of high order requires extremely large dimensional matrix observations. This is due to the fact that the estimate of the moment of order k of the l.s.d. is based on polynomial expressions of the estimates of moments of lower orders. A small error in the estimate in a low order moment therefore propagates as a large error for higher moments; it is therefore compelling to obtain accurate first order estimates, hence large dimensional observations.
We will not further investigate the moment-based approach above, which we discuss in more detail with a proper introduction to free probability theory in [28]. Instead, we introduce the methods based on the Stieltjes transform and those rely strongly on the results described in the previous section. We will introduce this method for the sample covariance matrix model discussed so far, because it will be instrumental to understanding the power estimator introduced in Section 8.5.2. Similar results have been provided for other models of interest to telecommunications, as for instance the so-called information-plus-noise model, studied in [29].
The central idea is based on a trivial application of the Cauchy complex integration formula [30]. Consider f some complex holomorphic function on U ⊂ ℂ, H a distribution function and denote G the functional
G(f) = ∫f(z)dH(z).
From the Cauchy integration formula, we have, for a negatively oriented closed path γ enclosing the support of H and with winding number one,
G(f) = 12πi∫∮γf(ω)z − ωdωdH(z) = 12πi∮γ∫f(ω)z − ωdH(z)dω = 12πi∮γf(ω)mH(ω)dω, |
(8.14) |
the integral inversion being valid since f (ω)/(z − ω) is bounded for ω ∈ γ. Note that the sign inversion due to the negative contour orientation is compensated by the sign reversal of (ω − z) in the denominator.
If dH is a sum of finite or countable masses and one is interested in evaluating f (λk), with λk the value of the kth mass with weight lk, then on a negatively oriented contour λk enclosing λk and excluding λj, j ≠ k,
(8.15) |
This last expression is particularly convenient when one has access to H only through an expression of its Stieltjes transform.
Now, in terms of random matrices, for the sample covariance matrix BN = T12NXNX†NT12N, we already noticed that the l.s.d. F of BN (or equivalently the l.s.d. F̲ of B_N = X†NTNXN) can be rewritten under the form (8.9), which can further be rewritten
(8.16) |
where H is the l.s.d. of TN. Note that it is allowed to evaluate mH in −1/mF̲(z) for z ∈ ℂ+ since −1/mF̲(z) ∈ ℂ+.
As a consequence, if one only has access to FBN (from the observation BN), then the only link from the observation to H is obtained by (i) the fact that FB_N⇒F_ almost surely and (ii) the fact that F̲ and H are related through (8.16). Evaluating a functional f of the eigenvalue λk of TN is then made possible by (8.15) . The relations (8.15) and (8.16) are the essential ingredients behind the derivation of a consistent estimator for f (λk).
We now concentrate specifically on the sample covariance matrix B_N = T12NXNX†NTN defined as in Theorem 8.3.1 with TN composed of K distinct eigenvalues t1,…, tK of multiplicities N1,…, NK, respectively. We further denote ck ≜ limn Nk/n and will discuss the question of estimating tk itself. What follows summarizes the original ideas of Mestre in [22] and [24]. We have from (8.15) that, for any continuous f and for any negatively oriented contour Ck that encloses tk and tk only, f (tk) can be written under the form
NkNf(tk) = 12πi∮Ckf(ω)mH(ω)dω = 12πi∮Ck1NK∑r = 1Nrf(ω)tr − ωdω
with H the limit FTN⇒H. This provides a link between f (tk) for all continuous f and the Stieltjes transform mH(z).
Letting f (x) = x and taking the limit N → ∞, Nk/N → ck/c, with c ≜ c1 + … + cK the limit of N/n, we have
(8.17) |
We now want to express mH as a function of mF, the Stieltjes transform of the l.s.d. F of BN. For this, we have the two relations (8.10), i.e.,
mF_(z) = cmF(z) + (c − 1)1z
and (8.16) with FT = H, i.e.,
cmF_(z)mH( − 1mF_(z)) = − zmF_(z) + (c − 1).
Together, those two equations give the simpler expression
mH( − 1mF_(z)) = − zmF_(z)mF(z).
Applying the variable change ω = −1/mF̲(z) in (8.17), we obtain
ckctk = 12πi∮CF_,kzmF_(z)m′F_(z)c + 1 − ccmF_(z)′m2F_(z)dz = 1c12πi∮CF_,kzm′F_(z)mF_(z)dz, |
(8.18) |
where CF̲,k is the preimage of CF̲ by −1/mF̲. The second equality (8.18) comes from the fact that the second term in the previous relation is the derivative of (c − 1) / (cmF̲(z)), which therefore integrates to 0 on a closed path, from classical real or complex integration rules [30]. Obviously, since z ∈ ℂ+ is equivalent to − 1/mF̲(z) ∈ ℂ+ (the same being true if ℂ+ is replaced by ℂ−), CF̲ ,k is clearly continuous and of non-zero imaginary part whenever I(z) = 0. Now, one must be careful about the exact choice of CF̲ ,k.
We make the important assumption that the index k satisfies the separability conditions of Theorem 8.3.7. That is, the cluster kF associated to k in F is distinct from (k − 1)F and (k + 1)F (whenever they exist). Let us then pick x(l)F and x(r)F two real values such that
x+(k−1)F < x(l)F < x−kF < x+kF< x(r)F < x−(k+1)F
with {x − 1,x + 1,…,x − KF,x + KF} the support boundary of F, as defined in Theorem 8.3.6. Now remember Theorem 8.3.5 and Figure 8.3; for x(l)F as defined previously, mF̲ (z) has a limit m(l) ∈ ℝ as z→x(l)F,z∈ℂ + , and a limit m(r) ∈ ℝ as z→x(r)F,z∈ℂ + , those two limits verifying
(8.19) |
with x(l) = − 1/m(l) and x(r) = − 1/m(r).
This is the most important outcome of the integration process. Let us define CF̲,k to be any continuous contour surrounding cluster kF such that CF̲,k crosses the real axis in only two points, namely x(l)F and x(r)F. Since −1/mF̲(ℂ+) ⊂ ℂ+ and −1/mF̲(ℂ+) ⊂ ℂ+, Ck does not cross the real axis whenever I(z) ≠ 0 and is obviously continuously differentiable there; now Ck crosses the real axis in x(l) and x(r), and is in fact continuous there. Because of (8.19), we then have that Ck is (at least) continuous and piecewise continuously differentiable and encloses only tk. This is what is required to ensure the validity of (8.18).
The difficult part of the proof is completed. The rest will unfold more naturally. We start by considering the following expression,
ˆtk≜12πinNk∮CF_,kzm′FB_N(z)mFB_N(z)dz = 12πinNk∮CF_,kz1n∑ni = 11(λi − z)21n∑ni = 11λi − zdz, |
(8.20) |
where we remind that B_NΔ__X†NTNXN and where, if n ≥ N, we defined λN+1 = … =λn = 0.
The value t̂k can be viewed as the empirical counterpart of tk. Now, we know from Theorem 8.2.9 that mFBN(z)a.s.→mF(z) and mFB_N(z)→mF_(z). It is not difficult to verify, from the fact that mF̲ is holomorphic, that the same convergence holds for the successive derivatives.
At this point, we need the two fundamental results that are Theorem 8.3.1 and Theorem 8.3.4. We know that, for all matrices BN in a set of probability one, all the eigenvalues of BN are contained in the support of F for all large N, and that the eigenvalues of BN contained in cluster kF are exactly {λi, i ∈ Nk} for these large N, with Nk{∑k − 1j = 1Nj + 1,…,∑kj = 1Nj}. Take such a BN. For all large N,mBN(z) is uniformly bounded over N and z ∈ CF̲,k, since CF̲,k is away from the support of F. The integrand on the right-hand side of (8.20) is then uniformly bounded for all large N and for all z ∈ CF̲,k. By the dominated convergence theorem, Theorem 16.4 in [16], we then have that ˆtk − tka.s.→0.
It then remains to evaluate t̂k explicitly. This is performed by residue calculus [30], i.e., by determining the poles in the expanded expression of t̂k (when developing mFBN(z) in its full expression). Those poles are found to be λ1,…, λN (indeed, the integrand of (8.20) behaves like O(1/(λi − z)) for z ≃ λi) and μ1,…, μN, the N real roots of the equation in μ,mFBN(μ) = 0 (indeed, the denominator of the integrand cancels for z = μi while the numerator is non-zero). Since CF̲,k encloses only those values λi such that i ∈ Vk, the other poles are discarded. Noticing now that mFBN(μ) = ±∞ as μ → Ai, we deduce that μ1 < μ1 < μ2 < … < μN < λN, and therefore we have that μi,j ∈ Nk are all in CF̲,k but maybe for μj, j = min Nk. It can in fact be shown that μj is also in CF̲,k. To notice this last remaining fact, observe simply that
12πi∮Ck1ωdω = 0.
since 0 is not contained in the contour Ck. Applying the variable change ω = −1/mF̲ (z) as previously, this gives
(8.21) |
From the same reasoning as above, with the dominated convergence theorem argument, we have that for sufficiently large N and almost surely,
(8.22) |
At this point, we need to proceed to residue calculus in order to compute the integral on the left-hand side of (8.22). We will in fact prove that the value of this integral is an integer, hence necessarily equal to zero from the inequality (8.22) . Notice indeed that the poles of (8.21) are the λi and the μi that lie inside the integration contour CF̲,k, all of order one with residues equal to −1 and 1, respectively. Therefore, (8.21) equals the number of such λi minus the number of such μi (remember that the integration contour is negatively oriented, so we need to reverse the signs). We, however, already know that this difference, for large N, equals either 0 or 1, since only the position of the leftmost μi is unknown yet. But since the integral is asymptotically less than 1/2, this implies that it is identically zero, and therefore the leftmost μi (indexed by min Nk) also lies inside the integration contour.
From this point on, we can evaluate (8.20), which is clearly determined since we know exactly which eigenvalues of BN are contained (with probability one for all large N) within the integration contour. This calls again for residue calculus, the steps of which are detailed below. Denoting
f(z) = zm′FB_N(z)mFB_N(z),
we find that λi (inside CF̲,k) is a pole of order 1 with residue
limz→λi(z − λi)f(z) = − λi,
which is straightforwardly obtained from the fact that f(z)∼1λi − z as z ~ λi. Also μi (inside CF̲,k) is a pole of order 1 with residue
limz→μi(z − μi)f(z) = − μi.
Since the integration contour is chosen to be negatively oriented, it must be kept in mind that the signs of the residues need be inverted in the final relation.
Noticing finally that μ1,…, μN are also the eigenvalues of diag (λ) − 1n√λ√λT, with λ ≜ (λ1,…, AN)T, from a lemma provided in [23, Lemma 1] and [31], we finally have the following statistical inference result for sample covariance matrices.
Theorem 8.4.1 ([24]). Let BN=T12NXNX†NT12N∈ℂN × N be defined as in Theorem 8.3.7, i.e., TN has K distinct eigenvalues t1 < … < tK with multiplicities N1, …, NK, respectively, for all r, Nr/n → cr , 0 < cr < ∞, and the separability conditions (8.13) are satisfied. Further denote λ1 < … ≤ λN the eigenvalues of BN and λ = (λ1, …, λN)T. Let k ∈ {1, …, K}, and define
(8.23) |
with Nk{∑k − 1j = 1Nj + 1,…,∑kj = 1Nj} and μ1 ≤ … ≤ are the ordered eigenvalues of the matrix diag (λ) − 1n√λ√λT.
Then, if condition (8.13) is fulfilled, we have
ˆtk − tk→0
almost surely as N,n → ∞, N/n → c, 0 < c < ∞.
Similarly, for the quadratic form, the following holds.

Figure 8.4: Estimation of t1,t2,t3 in the model BN=T12NXNX†NT12N based on the first three empirical moments of BN and Newton-Girard inversion, see [32], for N1/N = N2/N = N3/N = 1/3, N/n = 1/10, for 100,000 simulation runs; (a) N = 30, n = 90; (b) N = 90, n = 270. Comparison is made against the Stieltjes transform estimator of Theorem 8.4.1.
Theorem 8.4.2 ([24]). Let BN be defined as in Theorem 8.4.1, and denote BN = ∑Nk = 1λkbkb†k,b†kbi = δik, the spectral decomposition of BN. Similarly, denote TN = ∑Kk = 1tkUkU†k,U†kUk = Ink, with Uk∈ℂN × Nk the eigenspace associated to tk. For given vectors x, γ ∈ ℂN, denote
u(k;x,y)≜x†UkU†ky.
Then we have
ˆu(k;x,y) − u(k;x,y)a.s.→0
as N,n → ∞ with ratio cN = N/n → c, where
ˆu(k;x,y)≜N∑i = 1θk(i)x†bkb†ky
and θk (i) is defined by
θi(k) = { − ϕk(i),i ∉ Nk1 + ψk(i),i∈ Nk,
with
ϕk(i) = ∑r∈Nk(λrλi − λr − μrλi − μr),ψk(i) = ∑r∉Nk(λrλi − λr − μrλi − μr)
and Nk , μ1,…, μN defined as in Theorem 8.4.1.
The estimator proposed in Theorem 8.4.1 is extremely accurate and is in fact much more flexible and precise than free deconvolution approaches. A visual comparison is proposed in Figure 8.4 for the same scenario as in Figure 8.3, where the free deconvolution (also called moment-based) method is based on the inference techniques proposed in e.g., [26, 32]. Nonetheless, it must be stressed that the cluster separability condition, necessary to the validity of the Stieltjes transform approach, is mandatory and sometimes a rather strong assumption. Typically, the number of observations must be rather large compared to the number of sensors in order to be able to resolve close values of tk.
In this section, we apply the random matrix methods developed above to the problems of multidimensional binary hypothesis testing and parameter estimation. More details on these applications as well as a more exhaustive list of applications, notably in the field of wireless communications, are provided in [28].
8.5.1 Binary Hypothesis Testing
We first consider the problem of detecting the presence of a signal source impaired by white Gaussian noise. The question is therefore to decide whether only noise is being sensed or if some data plus noise are sensed.
Precisely, we consider a signal source or transmitter of dimension K and a sink or receiver composed of N sensors. The linear filter between the transmitter and the receiver is modelled by the matrix H ∈ ℂN×K, with (i, j)th entries hij. If at time l the transmitter emits data, those are denoted by the K-dimensional vector x(l) = (x(l)1,…,x(l)K)∈ℂK. The additive white Gaussian noise at the receiver is modelled, at time l, by the vector σw(l) = σ(ω(l)1,…ω(l)N)T∈ℂN, where σ2 denotes the variance of the noise vector entries. Without generality restriction, we consider in the following zero mean and unit variance of the entries of both w(1) and x(1), i.e., E{|w(l)i|2} = 1,E{|w(l)i|2} = 1 for all i. We then denote y(l) = (y(l)1,…,y(l)N)T the N-dimensional data received at time l. Assuming the filter is static during at least M sampling periods, we finally denote Y = [y(1),…, y(M)] ∈ ℂN×N the matrix of the concatenated received vectors.
Depending on whether the transmitter emits data, we consider the following hypotheses
• H0. Only background noise is received.
• H1. Data plus background noise are received.
Therefore, under condition H0, we have the model
Y = σW
with W = [w(1),…, w(M)] ∈ ℂN×N and under condition H1
(8.24) |
with X = [x(1),…, x(M)] ∈ ℂN×N.
Under this hypothesis, we further denote ∑ the covariance matrix of y(1),
∑ = E{y(1)(y(1))†} = HH† + σ2IN = UGU†
where G = diag (ν1 + σ2,…, νN + σ2) ∈ ℝN×N, with {ν1,…, vN} the eigenvalues of HH† and U ∈ ℂN×N a certain unitary matrix.
The receiver is entitled to decide whether data were transmitted or not. It is a common assumption to be in the scenario where σ2 is known in advance, although it is uncommon to know the transfer matrix H. This is true in particular of the wireless signal sensing scenario where H is the wireless fading channel matrix between two antenna arrays. We consider specifically the scenario where the probability distribution of H is unitarily invariant, which is in particular consistent in wireless communications with channel models that do not a priori exhibit specific directions of energy propagation. This is in particular relevant when the filter H presents rotational invariance properties. For simplicity we take H and x(l) to be i.i.d. Gaussian with zero mean and E {∣hij∣2} = 1/K, although our study could go well beyond the Gaussian case.
For simplicity, we consider in the following K = 1, although a generalized result exists for K ≥ 1 [2]. The Neyman-Pearson criterion for the receiver to establish whether data were transmitted is based on the ratio
(8.25) |
where Prℋi|Y(Y) is the probability of the event Hi conditioned on the observation Y. For a given receive space-time matrix Y, if C(Y) > 1, then the odds are that an informative signal was transmitted, while if C(Y) < 1, it is more likely that only background noise was captured. To ensure a low probability of false alarm (or false positive), i.e., the probability to declare a pure noise sample to carry an informative signal, a certain threshold ξ is generally set such that, when C(Y) > ξ, the receiver declares data were transmitted, while when C(Y) < ξ the receiver declares that no data were sent. The question of what ratio ξ should be set to ensure a given maximally acceptable false alarm rate will not be treated here. We will however provide an explicit expression of (8.25) for the aforementioned model, and shall compare its performance to that achieved by the classical energy detector. The results provided in this section are taken from [2].
Applying Bayes’ rule, (8.25) becomes
C(Y) = Pr ℋ0⋅Pr ℋ1|Y(Y)Pr ℋ1⋅Pr ℋ0|Y(Y),
with PrHi the a priori probability for hypothesis Hi to hold. We suppose that no side information allows the receiver to consider that H1 is more or less probable than H0, and therefore set Prℋ0 = Prℋ1 = 12, so that
(8.26) |
reduces to a maximum likelihood ratio.
Likelihood under H0. In this first scenario, the noise entries w(l)i are Gaussian and independent. The probability density of Y, which can be seen as a random vector with NM entries, is then an NM multivariate uncorrelated complex Gaussian with covariance matrix σ2 INM,
(8.27) |
Denoting λ = (λ1,…, λN)T the eigenvalues of YY†, (8.27) only depends on ∑Ni = 1λi, as follows
PrY|ℋ0(Y) = 1(πσ2)NMe − 1σ2∑Ni = 1λi.
Likelihood under H1. Under the data plus noise hypothesis H1, the problem is more involved. The entries of the channel matrix H are modeled as jointly uncorrelated Gaussian, with E {∣hij∣2} = 1/K. Therefore, since here K =1, H ∈ ℂN×1 and ∑ = HH† + σ2IN has N − 1 eigenvalues g2 = ⋯ = gN equal to σ2 and another distinct eigenvalue g1 = v1 + σ2(∑Ni = 1|hi1|2) + σ2. The density of g1 − σ2 is a complex chi-square distribution of N degrees of freedom (denoted X2N), which up to a scaling factor 2 is equivalent to a real X22N distribution. Hence, the eigenvalue distribution of ∑, defined on ℝ+N = [0, ∞)N, reads
PrG(G) = 1N((g1 − σ2)N − 1 + )e − (g1 − σ2)(N − 1)!N∏i = 2(gi − σ2).
From the model H1, Y is distributed as correlated Gaussian, as follows
PrY|∑,I1(Y,∑) = 1πMNdet(G)Me − tr(YY†UG − 1U†),
where Ik denotes the prior information at the receiver “H1 and K = k.”
Since H is unknown, we need to integrate out all possible linear filters for the transmission model under H1 over the probability space of N × K matrices with Gaussian i.i.d. distribution. From the invariance of Gaussian i.i.d. random matrices by left and right products with unitary matrices, this is equivalent to integrating out all possible covariance matrices ∑ over the space of such nonnegative definite Hermitian matrices, as follows
PrY|ℋ1(Y) = ∫∑PrY|∑,ℋ1(Y,∑)Pr∑(∑)d∑.
Eventually, after complete integration calculus given in the proof below, the Neyman-Pearson decision ratio (8.25) for the single-input multiple-output channel takes an explicit expression, given by the following theorem.
Theorem 8.5.1. The Neyman-Pearson test ratio CY(Y) for the presence of data reads
CY(Y) = 1NN∑l = 1σ2(N + M − 1)eσ2 + λlσ2N∏i = 1i≠l(λl − λi)JN − M − 1(σ2,λl) |
(8.28) |
with λ1, …, λN the eigenvalues of YY† and where
Jk(x,y)≜ ∫ + ∞xtke − t − ytdt.
The proof of Theorem 8.5.1 is provided below. Among the interesting features of (8.28), note that the Neyman-Pearson test does only depend on the eigenvalues of YY†. This suggests that the eigenvectors of YY† do not provide any information regarding the presence of data. The essential reason is that, both under H0 and H1, the eigenvectors of Y are isotropically distributed on the unit N-dimensional complex sphere due to the Gaussian assumptions made here. As such, a given realization of the eigenvectors of Y does indeed not carry any relevant information to the hypothesis test. The Gaussian assumption for H brought by the maximum entropy principle is in fact essential here. Note however that (8.28) is not reduced to a function of the sum ∑i λi of the eigenvalues, as suggests the classical energy detector.
On the practical side, note that the integral Jk (x,y) does not take a closedform expression, but for x = 0, [33, see e.g., pp. 561]. This is rather inconvenient for practical purposes, since Jk (x, y) must either be evaluated every time, or be tabulated. It is also difficult to get any insight on the performance of such a detector for different values of σ2, N and K. We provide hereafter a sketch of proof of Theorem 8.5.1, in which classical multidimensional integration techniques are introduced. In particular, the tools introduced in Section 8.2 will be shown to be key ingredients of the derivation.
Proof. We start by noticing that H is Gaussian and therefore that the joint density of its entries is invariant by left and right unitary products. As a consequence, the distribution of the matrix ∑ = HH† + σ2I is unitarily invariant. This allows us to write
PrY|I1(Y) = PrY|Σ,ℋ1(Y,∑)Pr∑(∑)d∑ = ∫U(N) × (ℝ + )NPrY|Σ,ℋ1(Y,∑)PrG(G)dUdG = ∫U(N) × ℝ + PrY|Σ,ℋ1(Y,∑)Prg1(g1)dUd(g1)
with U(N) the space of N × N unitary matrices and ∑ = UGU†.
The latter can further be equated to
PrY|I1(Y) = ∫U(N) × ℝ + e − tr(YY†UG − 1U†)πNMdet(G)M((g1 − σ2)N − 1 + )e − (g1 − σ2)N!dUd(g1)
with (x)+ ≜ max(x, 0) here.
To go further, we use the Harish–Chandra identity provided in Theorem 8.2.3. Denoting Δ(Z) the Vandermonde determinant of matrix Z ∈ ℂN×N with eigenvalues z1 ≤ … ≤ zN
(8.29) |
the likelihood PrY|I1(Y) reads
PrY|I1 (Y) = (limg2,…,gN→σ2eσ2( − 1)N(N − 1)2N − 1∏j = 1j!πMNσ2M(N − 1)N!) + ∞∫σ21gM1(g1 − σ2)N − 1 e − g1det(e − λigj)Δ(YY†)Δ(G − 1)d(g1) |
(8.30) |
in which we remind that λ1,…, λN are the eigenvalues of YY†. Note the trick of replacing the known values of g2,…, gN by limits of scalars converging to these known values, which allows us to use correctly the Harish–Chandra formula. The remainder of the proof consists of deriving the explicit limits, which in particular relies on the following result [34, Lemma 6].
Theorem 8.5.2. Let f1,…,fN be a family of infinitely differentiable functions and let x1,…, xN ∈ ℝ. Denote
R(x1,…,xN)≜det({fi(xj)}i,j)∏i>j(xi − xj).
Then, for p ≤ N and for x0 ∈ ℝ,
limx1,…,xp→x0R(x1,…,xN) = det(fi(x0),f′i(x0),…,f(p − 1)i(x0),fi(xp + 1),…,fi(xN))∏p<j<i(xi − xj)N∏i = p + 1(xi − x0)pp − 1∏j = 1j!.