
Chapter 10 Fundamentals of Estimation Theory
‡ University of Hong Kong
Parameter estimation is prevalent in communications and signal processing applications, e.g., in channel estimation, synchronization, parametric spectral estimation, direction-of-arrival estimation, etc. Estimation theory is extensively used in modern research in various fields related to signal processing. This chapter presents an overview of basic parameter estimation techniques and discusses the relationships among them. Applications in problems involving recent research are provided as examples.
In an estimation problem, we have some observations which depend on the parameters we want to estimate. For example, the observations can be written as
(10.1) |
where x stands for the observations, θ is the parameter we want to estimate, f is a known function, and w denotes the random noise corrupting the observations. All the above quantities can be in vector form. In this chapter, it is assumed that the dimension of x is N × 1 while that of θ is p × 1 with N > p. In general, x can depend on θ in a linear or nonlinear way. It is even possible that some of the elements of θ are related to x in a linear way, while others are related to x in a nonlinear way. The task of parameter estimation is to construct a function (called estimator) such that ˆθ: = g(x)
MSE(ˆθi) = E{(ˆθi − θi)2},
where expectation is taken with respect to the random noise w. If we rewrite the above expression as
it can be seen that the mean-square error (MSE) can be decomposed into two terms. The first term, variance, measures the variation of the estimate ˆθi
Example 10.1.1. [1] Consider a very simple example with observations
x[n] = A + ω[n] n = 0,1…,N − 1
where x[n] represent the observations, A is the parameter we want to estimate, and w[n] denote the independent and identically distributed (i.i.d.) observation noise with variance σ2. A reasonable estimator for A is the sample mean estimator:
ˆA = 1NN − 1∑n = 0x[n].
If we compute the mean of the estimate, we have
E{ˆA} = 1NN − 1∑n = 0E{x[n]} = 1NN − 1∑n = 0A = A.
Therefore, the sample mean estimator is unbiased. Now, consider another estimator
⌣A = aNN − 1∑n = 0x[n],
where a is an adjustable constant such that the MSE is minimized. It can be easily shown that E {Ǎ} = aA. Furthermore, the variance of Ǎ can be computed as
ver(Ă) = a2E{[1NN − 1∑n = 0x[n] − A]2} = a2E{1N2N − 1∑n = 0N − 1∑m = 0(A + ω[n])(A + ω[m]) − 2ANN − 1∑n = 0(A + ω[n] + A2)} = a2[A2 + 1Nσ2 − 2A2 + A2] = a2σ2N.
Putting the mean and variance expressions into the bias-variance decomposition of MSE expression (10.2), the MSE can be shown to be
MSE(Ă) = a2σ2N + (a − 1)2A2.
Differentiating the MSE with respect to a and setting the result to zero yields
aopt = A2A2 + σ2/N.
It is obvious that the optimal a depends on the unknown parameter A, and therefore, the optimal estimator might not be realizable.
10.2 Bound on Minimum Variance – Cramér-Rao Lower Bound
Before we discuss a general method of finding MVUE, we first introduce the Cramér-Rao lower bound (CRLB) in this section. CRLB is a lower bound on the variance of any unbiased estimator. This bound is important, as it provides a benchmark performance for any unbiased estimator. If we have an unbiased estimator that can reach the CRLB, then we know that it is the MVUE, and there is no other unbiased estimator that can perform better (at most another estimator would have equal performance). Even though a given unbiased estimator cannot touch the CRLB, we still have an idea of how far away the performance of this estimator is from the theoretical limit.
The CRLB is derived from the likelihood function, which is the probability density function (PDF) of the observations viewed as a function of the unknown parameter.
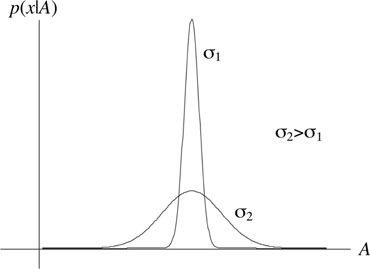
Figure 10.1: Sharpness of likelihood function and estimation accuracy.
In (10.1), if the noise w is Gaussian with covariance matrix C, then the likelihood function is
p(x|θ) = 1(2π)N/2det1/2[C]exp[ − 12(x − f(θ))TC − 1(x − f(θ))]. |
(10.3) |
In likelihood function, x is considered to be fixed, and for different θ, it represents the relative probability that θ being the true parameter (thus the probability that θ generates the given observation x). With this interpretation, one popular method for estimation is the maximum likelihood (ML) estimation approach, which searches for θ that maximizes p(x|θ). We will discuss ML estimation in more detail later in this chapter.
The “sharpness” of the likelihood function contains information about the ultimate accuracy any estimator can achieve. For example, Figure 10.1 shows two likelihood functions for the simple model x = A + w with w being Gaussian with two different variances. It can be seen that the likelihood function with smaller noise variance has a much sharper peak, and the values of A with significant likelihood lie within a small range. Thus, the variance of estimate in this scenario will be smaller. Mathematically, the “sharpness” is quantified by the second order derivative of the likelihood function. This is exactly the idea behind CRLB.
Theorem 10.2.1. (Cramér-Rao Lower Bound) [1] Assume the likelihood function p(x|θ) satisfies the regularity condition
E{[∂lnp(x|θ)∂θ]} = 0
where the expectation is taken with respect to p(x|θ). Then, the covariance matrix of any unbiased estimator ˆθ satisfies
(10.4) |
where A ≥ B means A − B is positive semidefinite. Matrix I(θ) is the Fisher information matrix with the (i,j)th element given by
(10.5) |
where the expectation is taken with respect to p(x|θ), and θi stands for the ith element of θ.
Equation (10.4) is an inequality on the covariance matrix, which includes as a corollary the lower bound on the variance of individual element-wise estimates: var (θi) = [Cˆθ]ii≥[I − 1(θ)]ii. Also notice that the discussion here is about the potential accuracy, and is irrelevant to the specific estimation method being used. Of course, although the potential ultimate accuracy might be high, using a bad estimator might yield poor performance.
Example 10.2.1. [3] In clock synchronization in a wireless sensor node, the observations can be modeled as
(10.6) |
(10.7) |
where {x1[n],x2[n]}N − 1n = 0 are the observations, {t1[n],t2[n]}N − 1n = 0 are known quantities and can be considered as the training data, β1, β0 and d are the unknowns to be estimated, and w[n] and z[n] are i.i.d. observation noise sequences with zero mean and variance σ2.
Since the random delays w[n] and z[n] follow i.i.d. Gaussian distributions, the PDF of the observations conditioned on β1, β0 and d can be expressed from (10.6)–(10.7) as ln p({x1[n],x2[n]}N − 1n = 0|β1,β0,d)
lnp({x1[n],x2[n]}N − 1n = 0|β1,β0,d) = lnN1πσ2 − 12σ2 × N − 1∑n = 0[(x1[n]β1 − t1[n]β0β1 − d)2 + (x2[n] − t2[n]β1 + β0β1 − d)2]. |
(10.8) |
To derive the CRLB, we first check the regularity condition. Taking β0 as an example, it can be shown that
∂lnp∂β0 = − 1σ2N − 1∑n = 0[ − 1β1(x1[n] − β0β1 − t1[n] − d) + 1β1(x2[n] − d − t2[n] − β0β1)]. |
(10.9) |
Putting (10.6) and (10.7) into (10.9), it yields:
(10.10) |
Since w[n] and z[n] have zero means, it is easy to see that the expectation of (10.10) is zero (notice that taking the expectation with respect to x1[n], x2[n] is equivalent to taking expectation with respect to w[n], z[n]) and the PDF in (10.8) satisfies the regularity condition for β0. The regularity conditions for β1 and d can be checked in a similar way.
From (10.5), the Fisher information matrix is given by
I(β1,β0,d) = [ − E{∂2lnp∂β21} − E{∂2lnp∂β1∂β0} − E{∂2lnp∂β1∂d} − E{∂2lnp∂β20} − E{∂2lnp∂β0∂β1} − E{∂2lnp∂β0∂d} − E{∂2lnp∂d2} − E{∂2lnp∂d∂β1} − E{∂2lnp∂d∂β0}],
and each element in the matrix can be obtained separately. For example for − E{∂lnp∂β1∂β0}, based on (10.9), we obtain
∂2lnp∂β1∂β0 = − 1σ2N − 1∑n = 0[2(x1[n] − 2β0)β31 − t1[n] + x2[n]β21]. |
(10.11) |
Putting (10.6) and (10.7) into (10.11), we have
∂2lnp∂β1∂β0 = − 1σ2N − 1∑n = 0(t1[n] + d + 2w[n] − z[n]β21 + t2[n] − β0β31) |
(10.12) |
Taking expectation of (10.12) with respect to random delays w[n] and z[n] gives
− E{∂2lnp∂β1∂β0} = 1σ2β31N − 1∑n = 0[β1(t1[n] + d) + (t2[n] − β0)],
where we have used the fact that w[n] and z[n] have zero means. Similarly, the other elements of I(β1,β0,d) can be obtained and the Fisher information matrix can be expressed as
(10.13) |
where
A: = β − 41∑N − 1n = 0[β21(t1[n] + d)2 + β21σ2 + (t2[n] − β0)2],
ℬ: = β − 31∑N − 1n = 0[β1(t1[n] + d) + (t2[n] − β0)], and
C: = β − 21∑N − 1n = 0[β1(t1[n] + d) − (t2[n] − β0)]. By inverting the matrix (10.13), it can be shown that the CRLB for each parameter (i.e., the diagonal elements of I−1(β1,β0, d)) is given, respectively, by:
CRLB(β1) = 1Nσ22NA − β21ℬ2 − C2,CRLB(β0) = σ2β21(2NA − C2)2N(2NA − β21ℬ2 − C2),CRLB(d) = σ2(2NA − β21ℬ2)2N(2NA − β21ℬ2 − C2).
As can be seen from this example, CRLB in general depends on the true parameters.
10.2.2 Finding MVUE Attaining the CRLB
With the lower bound on minimum variance, one may wonder if we can construct an unbiased estimator that can reach the CRLB. The answer is yes. Such an estimator is called efficient and might be obtained during the evaluation of the CRLB.
Theorem 10.2.2. [1] [2] An estimator ˆθ = g(x) is the MVUE if and only if
(10.14) |
for some matrix I(θ). Furthermore, the covariance matrix of the MVUE is I(θ)−1, which is also the CRLB.
Example 10.2.2. [1] Let us consider a linear model
x = Hθ + s + w
where x is the observation vector, H represents a known matrix, θ denotes the parameter vector to be estimated, s is a known vector, and w stands for a noise vector with PDF N(0, C). Subtracting s on both sides, and applying the whitening matrix D with DTD = C−1, we have
D(x − s) = DHθ + Dwx′=H′θ+w′.
It can be easily shown that w′ is Gaussian with zero mean and the covariance matrix is an identity matrix. Taking the first order derivative of logarithm of the likelihood function in the form of (10.3), it follows that:
∂lnp(x′|θ)∂θ = − 12∂∂θ[x′Tx′ − 2x′TH′θ + θTH′THθ].
Since
∂x′TH′θ∂θ = H′Tx′,∂θTH′θ∂θ = 2H′TH′θ,
we have
∂lnp(x′|θ)∂θ = H′Tx′ − H′TH′θ = H′TH′[(H′TH′) − 1H′Tx′ − θ], |
(10.15) |
where in the last step, it is assumed that H′TH′ is invertible. Comparing the above equation with (10.14), it is obvious that we obtain
(10.16) |
(10.17) |
the MVUE and its corresponding covariance, respectively. Notice that this result does not require the computation of second order derivative in order to obtain the CRLB.
10.3 MVUE Using Rao-Blackwell-Lehmann-Scheffe Theorem
In the previous section, we introduced a method for finding MVUE that can reach the CRLB. However, even if there is no estimator that can reach the CRLB, there may still exist a MVUE (the MVUE in such case is not an efficient estimator). In this section, we introduce another technique that can determine the MVUE from the likelihood function, and this technique requires the concept of sufficient statistics.
In a general estimation problem, we have access to a bunch of observations or data x[0], x[1], …, x[N − 1]. These observations contain information about the parameter we want to estimate. In general, making use of all available data would achieve the best estimation performance (how to use them is another problem). One would wonder: Is there any way to compress the data while the useful information for parameter estimation is not lost? If so, we can compress the original data set into sufficient statistics and use them for parameter estimation instead. Of course, the original data set is a sufficient statistic itself. Furthermore, for given original observations, there are many sufficient statistics. The one with the minimum number of elements is called the minimal sufficient statistic.
Formally, the concept of sufficient statistic is defined as follows. Let x be a vector of observations, and θ be the parameter of interest, with the likelihood function given by p(x|θ). A statistic T(x) is sufficient for θ if p(x|T(x), θ) is independent of θ. Intuitively, if T(x) is observed, and if p(x|T(x), θ) still depends on θ, there must be some information contain in x but not in T(x), and therefore T(x) cannot be a sufficient statistic.
Example 10.3.1. [2] Consider a sequence of independent Bernoulli trial x[0], x[1], …, x[N − 1] ∊ {0,1}. The probability for x[n] = 1 is θ. Then the likelihood function for estimation of θ is
(10.18) |
where k:∑N − 1n = 0x[n]. Now consider
p(x|k,θ) = p(x,k|θ)p(k|θ).
Since κ completely depends on x, p(x, κ|θ) is zero except when κ equals the number of ones in x. When it does, p(x, κ|θ) = p(x|θ). On the other hand, p(κ|θ) is the distribution of number of ones in N independent Bernoulli trials, and it is given by
p(k|θ) = (Nk)θk(1 − θ)N − k.
Therefore,
p(x|k,θ) = θk(1 − θ)N − k(Nk)θk(1 − θ)N − k = 1(Nk).
It is obvious that p(x|κ, θ) is independent of θ, and k = ∑N − 1n = 0x[n] is a sufficient statistic. That is, for estimation of θ, we only need to store the number of ones in the observations rather than the original sequence of ones and zeros.
Finding sufficient statistic using the basic definition involves guessing the sufficient statistic and verifying the conditional PDF being independent of the parameter of interest. Both steps can be challenging. Fortunately, we have the following theorem to help us in practice.
Theorem 10.3.1. (Neyman-Fisher Factorization) [1] [2] Let x be a vector of observations with the likelihood function p(x|θ). The statistic T(x) is sufficient if and only if the likelihood function can be factorized as follows
p(x|θ) = g(T(x),θ)h(x)
where g is a function depending on x only through T(x) and h is a function depending on x only.
Now, let us revisit the previous example of Bernoulli trials. The likelihood function in (10.18) can be expressed as
p(x|θ) = θk(1 − θ)N − k︸g(T(x) = k,θ).1︸h(x).
The first term g depends on x through κ only, while h is independent of θ. Therefore, from the Neyman-Fisher factorization Theorem, κ is a sufficient statistic. Obviously, identifying the sufficient statistic using this theorem is much simpler. Below is another example.
Example 10.3.2. [1] For the mean estimation from observations x[n] = A + w[n] for n = 0,1,…, N − 1, with w[n] being i.i.d. zero mean Gaussian distributed with variance σ2, the likelihood function is given by
(10.19) |
= 1(2πσ2)N/2exp[ − 12σ2(NA2 − 2AN − 1∑n = 0x[n])]︸g(T(x) = ∑N − 1n = 0x[n],A)exp[ − 12σ2N − 1∑n = 0x2[n]]︸h(x). |
(10.20) |
Now, g depends on x through ∑N − 1n = 0x[n] only, while h is a function of x only and is independent of A. Clearly, T(x) = ∑N − 1n = 0x[n] is a sufficient statistic for estimating A. Notice that T′(x) = 2∑N − 1n = 0x[n] is also a sufficient statistic for A. In fact, sufficient statistics are unique only to within a one-to-one transformation.
□
Another concept that is important to the determination of MVUE is the concept of complete sufficient statistic. In essence, a statistic is complete if there is only one function of the statistic that forms an unbiased estimator. Suppose T(x) is a sufficient statistic for θ. Furthermore, suppose there are two function g1 and g2 of T (x) that are unbiased estimators of θ. Equivalently, we have
(10.21) |
for all θ, and the expectation is taken with respect to the observations (or equivalently the sufficient statistics). In order to prove T(x) is a complete sufficient statistic, we must prove that if (10.21) holds, then g1(T(x)) = g2(T(x)).
Example 10.3.3. [1] In the estimation of A from observations x[n] = A + w[n] with w[n] being i.i.d. Gaussian noise with zero mean and variance σ2, we have shown in the previous example that a sufficient statistic for A is T(x) = ∑N − 1n = 0x[n]. Now suppose there are two unbiased estimators g1(T(x)) and g2(T(x)), that is
E{g1(T(x)) − g2(T(x))} = 0
for all A. Since τ ≔ T(x) ~ N(NA, Nσ2), and defining v(τ) ≔ g1(τ) − g2(τ), the above equation is equivalent to
∫∞ − ∞v(τ)1√2πNσ2exp[ − 12Nσ2(NA − τ)2]dr = 0.
It can be recognized that the above equation is the convolution of v(τ) and a Gaussian pulse. Since the Gaussian pulse is non-negative, in order to have the convolution equal to zero for all A, v(τ) must be identically zero. Therefore, g1(T(x)) = g2(T(x)), implying the unbiased estimator is unique, and the sufficient statistic T(x) = ∑N − 1n = 0x[n] is complete.
□
10.3.2 Finding MVUE from Sufficient Statistics
With the background of sufficient statistics, we now present a theorem that helps us to identify the MVUE.
Theorem 10.3.2. (Rao-Blackwell-Lehmann-Scheffe) [1] [2] Let ˆθ be an unbiased estimator of θ, and T(x) be a sufficient statistic for θ. Then ˆθ = E{ˆθ|Τ(x)} improves on ⌣θ in the following ways:
1. ˆθ is a valid unbiased estimator for θ;
2. var (ˆθ)≤var (⌣θ).
The result of this theorem is important in the sense that it provides a way to improve the variance of any unbiased estimator using sufficient statistics. However, this theorem does not immediately offer the MVUE, since it is not guaranteed that the improved estimator is of minimum variance within the class of unbiased estimators. But if we have the additional knowledge that the sufficient statistic is complete, the estimator ˆθ = E{⌣θ|T(x)} is the only unbiased estimator for θ while making use of the sufficient statistic. Therefore, it must be the MVUE. In fact, if the estimator we start with ⌣θ is also an unbiased estimator using complete sufficient statistics, it is automatically the MVUE, since there is only one unbiased estimator if the sufficient statistic is complete. There is even no need to compute the expectation E{⌣θ|T(x)}. In summary, the procedure of determining MVUE using Rao-Blackwell-Lehmann-Scheffe theorem is as follows.
1. Find a sufficient statistic for θ, T(x), using Neyman-Fisher factorization Theorem.
2. Determine if the sufficient statistic is complete.
3. If so, find a function ˆθ = g(T(x)) which is an unbiased estimator of θ. The MVUE will be ˆθ.
Example 10.3.4. [4] In the clock offset estimation in a wireless sensor node, the observation equations can be written as
Un = δ + ϕ + wn,n = 1,2,…,N,Vn = δ − ϕ + zn,n = 1,2,…N,
where δ symbolizes the fixed portions of the transmission delays, wn and zn denote the variable portions of delays and assume i.i.d. exponential distributions with means α and β, respectively, and φ stands for the clock phase offset from the reference time. We want to determine the MVUE of θ ≔ [δ, ϕ, α, β]T using the procedure introduced above.
First, we need to determine a sufficient statistic. The likelihood of θ is given by
L(θ) = α − Ne − 1αN∑n = 1(Un − δ − ϕ)︸: = g1(∑Nn = 1Un,δ,ϕ,α)u[U(1) − δ − ϕ]︸: = g3(U(1),δ,ϕ).β − Ne − 1βN∑k = 1(Vk − δ + ϕ)︸: = g2(∑Nn = 1Vn,δ,ϕ,α)u[V(1) − δ + ϕ]︸: = g4(V(1),δ,ϕ).1︸: =h (Un, Vn),
where u[·] denotes the unit step function, and U(1) and V(1) are the minimum order statistics of Uκ and Vκ, respectively. In the above expression, h(Un, Vn) is independent of the unknown parameter vector θ, whereas g1, g2, g3 and g4 are functions depending on the data through T = {∑Nn = 1Un,U(1),∑Nn = 1Vn,V(1)}. Therefore, according to Neyman-Fisher factorization Theorem 10.3.1, T is a sufficient statistic for θ.
Next, we need to prove that T is complete, a step which requires the PDF of T. Unfortunately, since ∑Nn = 1Un and U(1), and similarly ∑Nn = 1Vn and V(1), are not independent, the PDF of T is difficult to be obtained. But if we consider the statistic T′ = {∑Nn = 1(Un − U(1)),U(1),∑Nn = 1(Vn − V(1)),V(1)}, it turns out that it is also a sufficient statistic because it is obtained using a one-to-one transformation from T. It can be proved that the elements of T′ are independent, and each of them obeys the three-parameter Gamma distribution:
r: = N∑n = 1(Un − U(1))∼Γ(N − 1,α,0),s: = N∑n = 1(Vn − V(1))∼Γ(N − 1,β,0),U(1)∼Γ(1,α/N,δ + ϕ),V(1)∼Γ(1,β/N,δ − ϕ).
Now, suppose there are two functions g(T′) and h(T′) that are unbiased estimators of θ. Then we have
E{g(T′) − h(T′)} = E{π(T′)} = 0 ∀ θ
where π(T′) ≔ g(T′) − h(T′). As a result,
∫∞δ − ϕ∫∞0∫∞δ + ϕ∫∞0π(r,U(1),s,V(1)).(αβ) − (N − 1){Γ(N − 1)}2(rs)N − 2e − rα − sβ × N2αβe − Nα{U(1) − δ − ϕ} − Nβ{V(1) − δ + ϕ}dr dU(1) ds dV(1) = 0
for all θ. The above relation can also be expressed as
∫∞ − ∞∫∞ − ∞∫∞ − ∞∫∞ − ∞[π(r,U(1),s,V(1))(rs)N − 2u(s)u(r)u(U(1) − δ − ϕ)u(V(1) − δ + ϕ)] × e − {rα + NU(1)α + sβ + NV(1)β}dr dU(1) ds dV(1) = 0.
The expression on the left above is the four-dimensional Laplace transform of the function within the square brackets. It follows from the uniqueness theorem for the two-sided Laplace transform that π(T′)(rs)N−2u(s)u(r)u(U(1) − δ − ϕ)u(V(1) − δ + ϕ) = 0 almost everywhere. Since r, s, u(s), u(r), u(U(1) − δ − ϕ), u(V(1) − δ + ϕ) are not identically zero, we can conclude that π(T′) = 0, resulting in g(T′) = h(T′). This proves that the statistic T′, or equivalently T, is complete for estimating θ.
Finally, we have to find an unbiased estimator for θ as a function of T. A careful inspection of the sufficient statistics reveals that
ˆθ = 12(N − 1)[N(U(1) + V(1)) − 1N(∑Nn = 1Un + ∑Nn = 1Vn)N(U(1) − V(1)) − 1N(∑Nn = 1Un − ∑Nn = 1Vn)2N(1N∑Nn = 1Un − U(1))2N(1N∑Nn = 1Vn − V(1))]
is an unbiased estimator of θ, which is also the MVUE according to the Rao-Blackwell-Lehmann-Scheffe Theorem 10.3.2.
10.4 Maximum Likelihood Estimation
In general, determining MVUE is difficult due to the fact that we do not know whether the MVUE for a particular problem exists. Even if it does exist, the procedure for determining the MVUE is overwhelmingly challenging for most problems. Therefore, in practice, MVUEs are only reported in isolated cases. In this section, we introduce the maximum likelihood (ML) estimation, a popular technique that usually results in practical estimators.
10.4.1 ML Estimation Principle
As it was introduced previously in Section 10.2 in the context of Cramér-Rao lower bound, the likelihood function can be interpreted as a PDF of the unknown parameter θ with fixed observation x. The maximum likelihood estimation approach resumes to finding the parameter vector that maximizes the likelihood function:
ˆθ = arg[max˜θp(x|˜θ)],
where ˜θ is the trial value of the unknown parameter. In fact, the ML estimate ˆθ is the parameter that is the most probable for generating the observations.
Example 10.4.1. [1] Consider the received data x[n] = A + w[n] for n = 0,1,…, N − 1, with A unknown, and w[n] is i.i.d. Gaussian distributed with zero mean and variance σ2. We want to derive the ML estimator for A. First, the likelihood function of A is given by (10.19). Taking logarithm on the likelihood function gives
lnp(x|A) = − N2ln 2π − Nlnσ − 12σ2N − 1∑n = 0(x[n] − A)2.
Since the value of A that maximizes p(x|A) is the same as that maximizing ln p(x|A), we can proceed to maximize the log-likelihood function ln p(x|A) instead. Differentiating ln p(x|A) with respect to A, we have
(10.22) |
Setting (10.22) to zero, the ML estimator of A is given by
ˆA = 1NN − 1∑n = 0x[n],
which can be interpreted as the sample mean estimator.
Notice that the first derivative of the log-likelihood function (10.22) of the above example can also be written as
(10.23) |
Comparing (10.23) to (10.14), it is obvious that the ML estimator of A is also the MVUE. Furthermore, in the general linear model considered in Example 10.2.2, the first derivative of the log-likelihood function is given by (10.15). By setting (10.15) to zero and solving for θ, the ML estimator of θ can be easily shown to be identical to the MVUE in (10.16). This can be viewed as a special case of following important result.
Theorem 10.4.1. (Optimality of the MLE for the Linear Model) [1] [2] For the data x described by the general linear model
x = Hθ + w
where H stands for a known N × p matrix with N > p and of full rank, θ represents a p × 1 vector of parameters to be estimated, and w denotes the Gaussian noise vector with PDF N(0, C), the ML estimate of θ is given by
(10.24) |
Furthermore, ˆθ is also the MVUE and its variance (HTC−1H)−1 attains the CRLB.
The above two examples are not pure coincidence. In fact, if an unbiased estimator attains the CRLB (i.e., an efficient estimator exists), the ML procedure will produce it. This can be easily explained by the fact that if an efficient estimator exists, (10.14) holds. On the other hand, ML estimate is obtained by setting the first derivative of the log-likelihood function, i.e., (10.14), to zero. This automatically produces ˆθ = g(x), which is also the MVUE.
10.4.2 Properties of the ML Estimator
However, being identical to the MVUE in certain situations is not the main reason for the popularity of the ML estimation, as these situations do not frequently occur. On the other hand, the following property itself is strong enough for the ML estimation to be useful in practice.
Theorem 10.4.2. (Asymptotic Property of the ML estimator) [1] [2] If the likelihood function p(x|θ) of data x satisfies certain “regularity” conditions (existence of the derivatives of the log-likelihood function, as well as the Fisher information being nonzero), then the ML estimate of θ is asymptotically distributed (for large data records) according to
ˆθ a˜ N(θ,I − 1(θ))
where I(θ) is the Fisher information matrix evaluated at the true value of the unknown parameter.
This theorem states that when the observation data length tends to infinity, the ML estimate is asymptotically unbiased and asymptotically attains the CRLB. The ML estimate is therefore asymptotically efficient.
Example 10.4.2. [1] Consider x[n] = A + w[n] for n = 0,1,…,N − 1, with A > 0 is the parameter of interest, and w[n] is i.i.d. Gaussian noise with unknown variance A. The likelihood function of A is
p(x|A) = 1(2πA)N/2exp[ − 12AN − 1∑n = 0(x[n] − A)2].
Notice that this problem is not the same as that in the last example, as A appears as both the mean of received data and the variance of the noise. Differentiating the log-likelihood function with respect to A, it follows that
∂lnp(x|A)∂A = − N2A + 1AN − 1∑n = 0(x[n] − A) + 12A2N − 1∑n = 0(x[n] − A)2. |
(10.25) |
Setting the result to zero produces
A2 + A − 1NN − 1∑n = 0x2[n] = 0,
which yields the ML estimate of A:
ˆA = − 12 + √1NN − 1∑n = 0x2[n] + 14,
and the other solution is dropped to guarantee A > 0.
Now, we will examine the asymptotic mean and variance of the above estimator. To simply the notation, we let u = 1N∑N − 1n = 0x2[n], and g(u) be the function:
ˆA = g(u) = − 12 + √u + 14.
As N → ∞, u → E {x2[n]} = A2 + A := uo. Using a first order Taylor series approximation for g(u) around uo yields
ˆA = g(u)≈g(uo) + dg(u)du|u = uo(u − uo) = A + 1/2A + 1/2[1NN − 1∑n = 0x2[n] − (A + A2)].
Therefore, E {Â} = A, so  is asymptotically unbiased. Furthermore, the asymptotic variance is computed as
var(ˆA) = (1/2A + 1/2)2var(1NN − 1∑n = 0x2[n]) = 1/4N(A + 1/2)2var(x2[n]).
Since x[n] is Gaussian distributed with mean A and variance A, it can be shown that var (x2[n]) = 4A3 + 2A2, and therefore
(10.26) |
To check whether this asymptotic variance equals the CRLB, we differentiate (10.25) with respect to A again, and obtain
∂lnp(x|A)∂A2 = N2A2 − 1A2N − 1∑n = 0(x[n] − A) − NA − 1A3N − 1∑n = 0(x[n] − A)2N − 1∑n = 0(x[n] − A).
The CRLB of A is then given by
[ − E{∂2lnp(x|A)∂A2}] − 1 = − (N2A2 − NA − NA2) − 1 = A2N(A + 1/2).
The asymptotic variance (10.26) coincides with the CRLB. Therefore, the ML estimator for A is asymptotic efficient.
□
Example 10.4.3. [5] In orthogonal frequency division multiple access (OFDMA) uplink, multiple signals from different users arrive at the base station at the same time. However, their carrier frequency offsets (CFO) and channels are different and unknown. Before the data can be detected, we need to estimate all these parameters. In general, the received signal model in such systems can be expressed in the form of matrix equation:
(10.27) |
where x stands for the received data from one OFDM symbol, h denotes an unknown vector containing the channel coefficients of different users, Q(ω) is a matrix with known structure but parameterized nonlinearly by the unknown vector ω = [ω1 ω2 …ωK]T of frequency offsets, w represents the i.i.d. complex Gaussian noise with zero mean and variance σ2. The ML estimate of parameters {h, ω} is obtained by maximizing the likelihood function
p(x|˜h,˜ω) = 1(πσ2)N⋅exp{ − 1σ2[x − Q(˜ω)˜h]H[x − Q(˜ω)˜h]}, |
(10.28) |
where h̃ and ˜ω are trial values of h and ω, respectively. Notice that since w is complex, the PDF expression (10.28) assumes a slightly different form than that when w is real-valued in (10.3). Taking the logarithm of (10.28), and ignoring the constant irrelevant terms, the ML estimate can be equivalently found by minimizing
(10.29) |
Due to the linear dependence of parameter h in (10.27), the ML estimate for the channel vector h (when ˜ω is fixed) is given by (see (10.24))
ˆh = (QH(˜ω)Q(˜ω)) − 1QH(˜ω)x.
Plugging ĥ into (10.29), and retaining only those terms related to ˜ω, the ML estimate of ω can be expressed as
(10.30) |
Now the question resumes to how to maximize the nonlinear function J(˜ω). One straightforward way is to use a grid search, in which the feasible region of the parameter is divided into many subregions and the potential points are checked one by one. For example, if the parameter ω is one-dimensional and lies within [a, b], we can divide this range into 10,000 equally spaced intervals, and compute the cost function for 10,000 different values of ω. This approach may be acceptable in the presence of a single unknown parameter. However, when the dimension of parameter vector increases, the number of points to be searched increases exponentially. For example, if there are four users in the OFDMA system, the unknown vector ω is four dimensional. If we divide each dimension into 10,000 subintervals, the number of points to be searched is (10,000)4. This is unacceptable. Furthermore, if the parameter of interest is not bounded to a finite-length interval, this approach is also practically infeasible.
Another possible solution is to use iterative numerical search methods, such as the Newton-Raphson or steepest descent method. The idea is to approximate the optimization of a nonlinear function by a series of linearized optimizations with respect to a previously obtained solution. In the Newton-Raphson method, the second order Taylor series expansion is applied to the nonlinear function J(ω) around a previous estimate ˜ω(i):
J(ω)≈J(ˆω(i)) + (ω − ˆω(i))∂J(ω)∂ω|ω = ˆω(i) + 12(ω − ˆω(i))H[∂2J(ω)∂ω∂ωH]ω = ˆω(i)(ω − ˆω(i)) |
(10.31) |
where
∂J(ω)∂ω = [∂J∂ω1,∂J∂ω2,… .∂J∂ωK]T
is the gradient vector, and
∂2J(ω)∂ω∂ωH = (∂2J∂ω1∂ω1∂2J∂ω1∂ω2⋯∂2J∂ω1∂ωK∂2J∂ω2∂ω1∂2J∂ω2∂ω2⋯∂2J∂ω2∂ωK⋮∂2J∂ωK∂ω1∂2J∂ωK∂ω2⋯∂2J∂ωK∂ωK)
is the Hessian of J(ω). Differentiating (10.31) with respect to (ω − ˆω(i)) and setting the result to zero leads to
∂J(ω)∂ω|ω = ˆω(i) + [∂2J(ω)∂ω∂ωH]ω = ˆω(i)(ω = ˆω(i)) = 0.
Solving the above equation gives the value of ω that maximizes the second order approximated Taylor series expansion:
ˆω(i + 1) = ˆω(i) − [∂2J(ω)∂ω∂ωH] − 1ω = ˆω(i)∂J(ω)∂ω|ω = ˆω(i).
On the other hand, in the steepest descent method, the update is given by the equation:
ˆω(i + 1) = ˆω(i) − α∂J(ω)∂ω|ω = ˆω(i),
where ˆω(i) is the estimate of ω at the ith iteration, the gradient vector ∂J(ω)/∂ω points in the direction of the maximum increase of J(ω) at the point ω, and α is a parameter that determines how far away each update moves along the direction opposite to the gradient. Notice that the steepest descent method is derived to minimize a function, but minimizing a function is equivalent to maximizing the negative of the same function. Therefore, we do not explicitly describe the maximization algorithm.
Both methods share some similarities. For example, both methods require the initial estimate near the global optimal solution. Otherwise, in general, in the presence of multi-modal objective functions, only convergence to a local optimum can be guaranteed. Furthermore, both methods require the use of the derivative information. However, the Newton-Raphson method requires the additional computation of the Hessian, which may be difficult or impossible to obtain. Notice that even if the Hessian can be obtained, it may not be invertible. However, the use of the Hessian information (if available) ensures a faster convergence rate for the Newton-Raphson method relative to the steepest descent method.
Newton-Raphson and steepest descent methods may indeed reduce the computational complexity compared to the grid search. However, they are still multidimensional optimization approaches. To further reduce the computational burden brought by the multidimensional searches in the ML estimator, the alternating projection algorithm can be exploited. The alternating projection method reduces a K-dimensional maximization problem (10.30) into a series of one-dimensional maximization problems, by updating one parameter at a time, while keeping the other parameters fixed at the previous estimated values. Let ˆω(i)k be the estimate of ωκ at the ith iteration. Further, let
ˆω(i) − k = [ˆω(i + 1)1⋯ˆω(i + 1)k − 1 ˆω(i)k + 1⋯ˆω(i)k + 1]T.
Given the initial estimates {ˆω(0)k}Kk = 0, the ith (i ≥ 1) iteration of the alternating projection algorithm for maximizing (10.30) assumes the following form:
ˆω(i)k = arg max˜ωk{J(˜ωk,ˆω(i − 1) − k)},
for κ = 1,…,K. Grid search, steepest descent or Newton-Raphson method can be used in each of the one-dimensional search. Multiple iterations on i are performed until the estimates of ωκ converge to a stable solution. Similar to other iterative algorithms, in general, the alternating projection can only be guaranteed to converge to at least a local optimum. Therefore, a good initialization is important.
Figure 10.2(a) shows the MSE performance of the ML estimator of ω with alternating projection and grid search in each dimension, as a function of observation length N. There are two users (K=2), the signal–to–noise ratio (SNR) is set to 10dB, and the number of iterations for alternating projection is 3. CRLB is also shown in the figure. It can be seen that the performance of the ML estimator approaches the CRLB when N increases, confirming the ML estimator is asymptotic efficient. On the other hand, Figure 10.2(b) shows the MSE performance of the ML estimator as a function of SNR. The OFDMA system has N = 64 subcarriers and K = 4 users. It is obvious that the MSE coincides with the CRLB in medium to high SNRs. Notice that increasing the number of observations has the same effect as decreasing the noise variance in observations. Thus, the ML estimator is also asymptotically efficient at high SNRs.
The ML estimate of a parameter θ is obtained by maximizing the likelihood function p(x|θ). But suppose we are interested not in θ itself, but α = g(θ). The question is if we can obtain the ML estimate of α from the ML estimate of θ. Such a situation occurs when the ML estimate of θ is relatively easy to obtain, but the direct derivation of ML estimate of α is difficult. The following theorem answers this question and is another major factor in making the ML estimation so popular.
Theorem 10.4.3. (Invariance property of the ML estimator) [1] Suppose α = g(θ); where θ is a p × 1 vector with likelihood function p(x|θ) and g is an r-dimensional function of θ. The ML estimator of α is given by
ˆα = g(ˆθ)
where ˆθ is the ML estimate of θ.
Example 10.4.4. In this example, we consider again the clock synchronization of wireless sensor node discussed in Example 10.2.1, with observations given by (10.6) and (10.7). However, in this example, the observation noise w[n] and z[n] are modeled as i.i.d. exponential random variables with an unknown common rate parameter λ. The goal is to estimate β0, β1, λ and d based on the observations {x1[n],x2[n]}N − 1n = 0.
To derive the ML estimator, we rewrite the observation equations (10.6) and (10.7) as
(10.32) |
(10.33) |
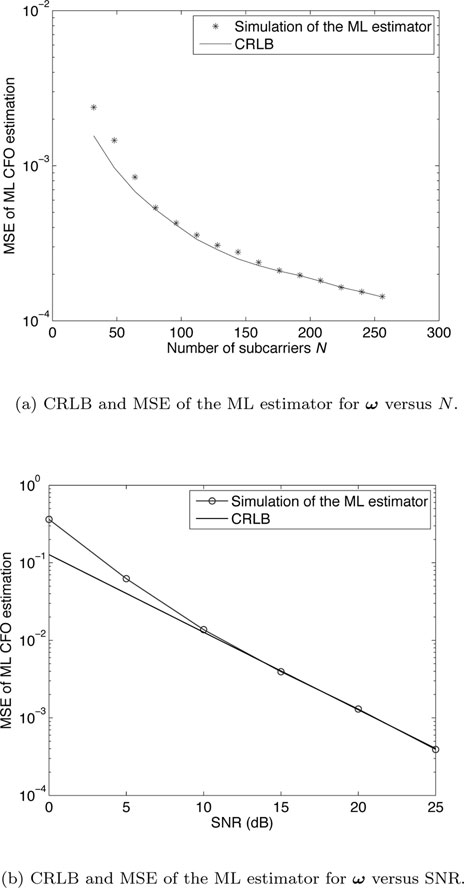
Figure 10.2: Asymptotic property of the ML estimator.