
CHAPTER 4
Network Building Blocks
In this chapter, you will learn about
• Basic networking components, including switches and routers
• Two main network operating systems—Windows and UNIX
• Servers in general and various types of servers in particular
• External storage systems, including RAID systems
So far we have outlined the basics of how data travels across a network, including giving a description of the logical model for defining that process—the OSI model—in Chapter 2. It’s important to understand the OSI model because, as you learn more about network devices and protocols, you’ll hear the layers referenced again and again.
In coming chapters, we drill down further into the layers of the OSI model, but first things first. Before you can understand fully how data moves through the OSI model, you need a basic grasp of the devices that move data. You need a quick overview of common networking hardware and software, including a review of the differences between the two major network operating systems—Windows and UNIX.
Networking Components
Throughout this book, you’ll encounter references to common networking devices, such as switches, routers, and gateways. By now you may be familiar with all of these, but in the interest of thoroughness, let’s review them quickly. You can get an idea of where these three sit on a network in Figure 4-1.
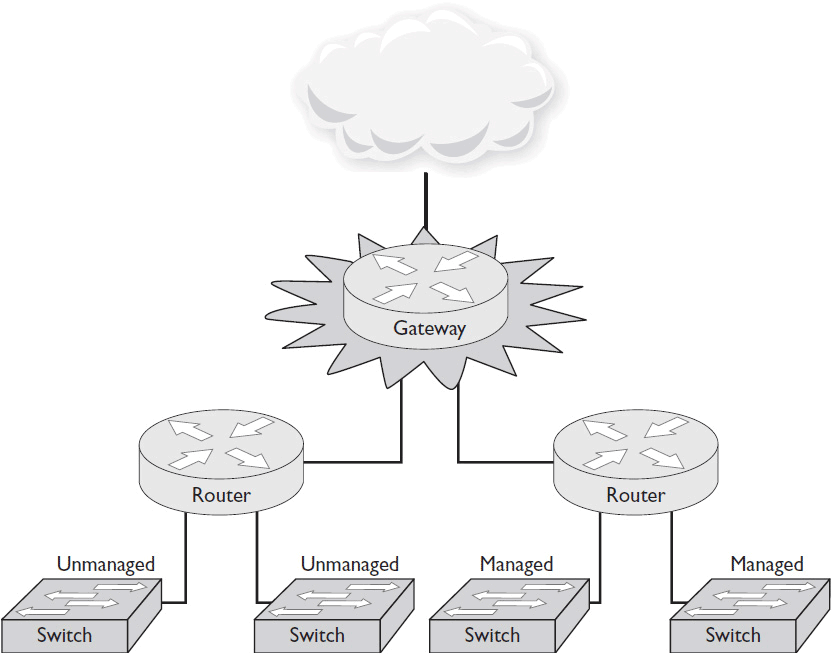
Figure 4-1 Basic networking components and where they sit in a network hierarchy.
• Switch (unmanaged) A network switch provides a physical connection between multiple devices. As you connect each device, the switch collects and stores its MAC address. This allows devices connected to the same switch to communicate directly via Ethernet, using only MAC addresses to locate each other. Switches operate at the Data Link Layer of the OSI model. Unmanaged switches have no configuration options. You just plug in a device and it connects.
• Switch (managed) Managed switches offer the same basic functionality as unmanaged switches—connection and communication between networked devices. But managed switches allow a network technician to adjust port speeds, set up virtual local area networks (VLANs), configure QoS, monitor traffic, and more. Managed switches are more common than unmanaged switches in modern enterprise environments.
• Router A router forwards data between devices that are not directly connected. Routers operate at the Network Layer of the OSI model. They mark the border between the LAN and the WAN. Once data traffic leaves the LAN (i.e., it travels beyond the switch), routers direct it until it reaches its final destination. When data arrives at a router, the router examines the packet’s logical address—its IP address—to determine its destination or next stop.
• Gateway A gateway connects a private network to outside networks. All data that travels to the Internet must pass through a gateway. Routers below the gateway forward packets to the gateway if they determine those packets are destined for any device that can’t be found on the private network. When traffic arrives from outside the private network, the gateway forwards it to the appropriate router below. Gateways can also translate data from one protocol to another. For example, when data leaves a private network to travel across the Internet, a gateway may translate it from a baseband to a broadband protocol.
 NOTE As you’ve heard it used for years, broadband refers to the wide-bandwidth characteristics of a transmission medium (cable, fiber, DSL, etc.) that can transport multiple signals and traffic types simultaneously. Baseband describes a communication system that uses a single channel.
NOTE As you’ve heard it used for years, broadband refers to the wide-bandwidth characteristics of a transmission medium (cable, fiber, DSL, etc.) that can transport multiple signals and traffic types simultaneously. Baseband describes a communication system that uses a single channel.
Switches versus Hubs
In today’s networks, switches are the primary devices used to connect devices on the same LAN. The primary data link protocol in modern IT networks is Ethernet, which is a baseband connection. It uses the entire frequency range of the cable to send data.
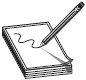
With a switch, each device has its own dedicated connection to the LAN. That connection goes from the node to a port on a switch. The switch keeps the MAC addresses of the devices connected to each of its ports in a lookup table. When it receives an Ethernet frame addressed to one of those MAC addresses, it forwards it out to the appropriate port. If it receives a frame addressed to an unfamiliar MAC address, it forwards it out to all ports except the one it arrived on. If that device is connected to another switch on the same LAN, the first switch receives an acknowledgment that the packet arrived, and it updates its lookup table accordingly. The next time it gets a frame addressed to that MAC address, it will forward it out to only the appropriate port.
This process allows switched Ethernet LANs to operate in full-duplex mode. The only devices that ever use a given network connection are the one sending node and the one receiving node (e.g., a switch and a computer, or a switch and a router). The two nodes can send messages to each other simultaneously because they don’t have to wait for any other devices that might be using the same connection.
Today most enterprise networks are fully switched. Figure 4-2 shows how switches communicate. However, if you’re working with an older network that incorporates legacy devices, you may encounter a different mechanism for connecting devices on the LAN: a hub.
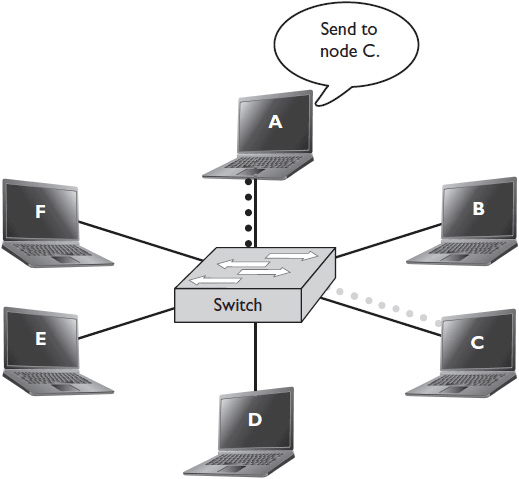
Figure 4-2 Switches send data directly to the intended node.
A hub performs the same role as a switch in that it connects multiple devices to a LAN, but it’s not as smart as a switch. Hubs don’t read the MAC addresses of frames as they arrive. When a frame arrives at a hub, the hub simply broadcasts it out on all ports, including the port on which it received the frame. It is then up to the connected devices to read the frame’s destination MAC address, decide if it was meant for them, and either keep the frame or discard it. As a result, even though the physical topology of a hub network looks like a star, the logical topology is really a bus, because data sent by one node arrives at every connected node. Figure 4-3 shows how a hub communicates.
Figure 4-3 Hubs send data to all nodes, including the one that sent the data.
Hubs are only capable of half-duplex communication. They can send or receive data but not at the same time. That means that if you have several devices connected to a hub, only one of them can send data at a time. All the devices have to share the network’s bandwidth. Before a device sends any data, it will check to see if any other devices are using the network. If the network is clear, it sends. If not, it waits its turn. If two devices send data at the same time—or nearly the same time—the data can collide, causing all communication to be lost.
Any network segment where data can collide like this is called a “collision domain.” With a hub, all of its connections form one big collision domain. With a switch, each connection is its own tiny collision domain, like a private highway.
Hubs were popular at one time because they’re simple and cheap. However, they result in much slower networks than switches, with greatly reduced management capabilities. A LAN that relies on hubs operates at half the speed (or less) of a switched LAN. It’s no wonder, then, that most enterprise networks have abandoned hubs in favor of switches. They want full-duplex communication to meet their growing network needs.
Blended Machines
It’s important to note that switches, routers, and gateways—as well as other common networking devices, such as firewalls—do not have to be separate physical devices. On your home network, you probably don’t have a separate gateway, router, and switch. In fact, you may have only one router, which acts as both your gateway to the Internet and a switch directing Layer 2 traffic among the devices on your home network. Much like an audio DSP combines the separate functions of a mixer, equalizer, compressor/limiter, and so on, networking devices often combine several functions in a single box.
For example, a switch may include some of the functions of a router. Normally, switches are thought to operate at Layer 2 of the OSI model since their main function is to forward Ethernet traffic among physically connected devices. But some switches can do a lot more. So-called Layer 3 switches also perform hardware-based routing, allowing them to route between VLANs. A Layer 3 switch is basically a fast version of a router. It’s able to route between VLANs more quickly than a router because it routes data using circuitry instead of software.
NIC Card and MAC Addresses
Every device that connects to the network must have a network interface card (NIC) and associated MAC address. Some devices may have more than one NIC, particularly if they need to connect to multiple networks (e.g., both a secure classified network and an unsecure public network). Each NIC has its own associated MAC address. Let’s take a second to review both elements.
A hardware interface is required to connect a device to a network. This interface is the NIC. At one time, most devices had a separate card or adapter, as shown here. While separate cards are still common, their components increasingly are being integrated into the main circuitry of the devices they connect.

A MAC address is the actual hardware address, or number, of the NIC. Each device has a unique MAC address to identify its connection on the network. It is part of the IEEE 802.3 standard. A MAC address is a 48-bit number that consists of six groups of two hexadecimal numbers, separated by a hyphen or colon, such as 01-23-45-67-89-ab, or 01:23:45:67:89:ab.
These numbers come from a table assigned to manufacturers of Ethernet-capable devices. The first part of the number indicates the manufacturer, and the second part of the number is a serial number for the product or circuit component. Due to the nature of the MAC address, there can be only one device on any given network with that number.
The MAC address is one of the lowest levels of communication on the network. It is one of the first pieces of the network communication structure. Because each address is unique, switches and routers can store them in order to quickly send data traffic throughout the network to each MAC-specific device.
Network Operating Systems
As you work with networked systems, you’ll inevitably encounter references to the network’s operating system (OS). But what is a network operating system (NOS, or network OS), and how does it differ from the OS on your PC or tablet?
The term can be hard to pin down. Some purists consider only operating systems that have been optimized for the purpose of networking to be true network OSs. Examples of such OSs include Cisco IOS, Juniper OS, and NETGEAR OS. Still, most people consider more general-purpose OSs to be part of the NOS family. Microsoft Windows Server OSs, UNIX, and Linux are all generally considered network operating systems, even though they do a lot more than manage network communications.
Despite the challenge in applying hard-and-fast definitions, an NOS does have several characteristics that distinguish it from other types of operating systems, including
• Support for distributed applications in a client-server architecture
• Support for sharing peripherals, as in the case of print services
• The ability to manage authentication and authorization (i.e., user logins)
• Support for multiple remote users, also known as terminal sessions
• The ability to forward remote sessions (i.e., provide port routing and/or access to the Internet)
• The ability to assign security policies to individual user accounts
• The ability to provide network-based services such as web service, email, and file sharing
• Support for multiple processors
In the past only a few specially designed operating systems offered these features. Now they’re available on almost every computer and platform on the market. Virtually any OS can function as a network OS if it’s being used to support these features. That said, there are two categories of network OSs that enjoy the most widespread use—Windows and UNIX.
Windows Servers
The Windows NT server was Microsoft’s first serious effort at a network OS. Windows NT took a hierarchical approach to managing users and resources, referred to as “domains.” The Windows NT family of network OSs was eventually replaced by the Windows 2000 server, originally called Windows NT 5.0. Windows 2000 replaced domains with a new resource administration tool called Active Directory. The Windows 2000 series has been updated several times and continues today. The most recent iteration of the Windows server is Windows 2012, also known as Windows NT 6.2. Ever since Windows 2000, Active Directory has been the administrative system for Windows networks.
The Windows NOS family offers all standard features of a network OS, plus a few extras specific to Windows products, including
• Windows server domain—a shared, centralized directory and user database
• Active Directory, for enterprise-wide policy administration
• A domain controller, for servers responsible for access control (i.e., authentication and authorization)
• Group policy, for centralized management of users and resource settings
• Internet Information Services (IIS), for supporting web services
One of the main reasons for Windows’ popularity is its ease of use. Unlike UNIX, which we discuss next, or other early NOS models, Windows relies heavily on graphical user interface (GUI) tools. In other early network OSs, administrators had to learn text commands for practically everything they wanted to accomplish. The GUI tools in Windows replaced many former command-line interface (CLI) commands with detailed menus. Most of the GUI tools are found in the control panel. Table 4-1 lists a few of the basic Windows GUI tools.

Table 4-1 Basic Windows GUI Tools
NOTE Windows also employs a wide array of command-line tools, executable through the command-line interface (CLI). Command-line tools are found in system32 and system subdirectories of every Windows operating system. The full path to these tools depends on how the system is administratively installed.
For Windows NT, Microsoft defined an administrative model with four domain options: single domain, single master, multiple master, and complete trust. Each domain level required additional resources, administrative oversight, and complexity. This model was replaced by Active Directory in Windows 2000, but you might encounter domain levels in some older networks.
In a single domain model, all the enterprise network tasks are handled by a single server. It is the simplest implementation and is useful for small to medium-sized networks. The single server functions as both the account domain server and the resource domain server. In this model, all management is centralized. Single domain can support up to 40,000 accounts.
In the single master model, only one server is responsible for administration of accounts. Other servers are responsible for the rest of the networked resources. Because there’s still only one server managing user accounts, there is still a maximum of 40,000 accounts in a single master system.
The multiple master domain model uses two or more master domains to administer accounts. Additional servers are responsible for delivering networked resources. The multiple master domain model is scalable. It’s capable of managing an unlimited number of user and group accounts. On the downside, the multiple master model is more difficult to set up and administer.
The complete trust model establishes a bidirectional trust relationship between every master domain server and is useful when master domains must be joined to simplify administration of user accounts. For example, when two companies merge, it may be more cost-effective to combine existing domains than to build a new domain.
From Windows 2000 onward, the domain model was no longer used to administer accounts. To accommodate existing networks, Microsoft implemented a mixed domain model with Windows NT. This model supports the integration of Windows 2000 servers and Active Directory into existing legacy domains, allowing organizations to make a smooth transition to Active Directory.
Active Directory
The original Microsoft domain models were abstract models representing physical configurations and trust relationships. Active Directory, introduced in Microsoft Windows 2000, is more than an abstract model. It provides both a database and services. The database contains information about all the networked resources. The services provide administrative tools, policy administration, and access control management. Together, the two sides of Active Directory store network device information and implement services that allow network users to access and use devices.
The logical structure of Active Directory is very flexible. Its framework consists of forests, trees, domains, and organizational units. Each of these units contains the smaller units: forests contain trees, which contain domains, which contain organizational units.
Windows NOS User Accounts
Network OS security policies focus on access control, determining who is allowed on a network and what they are allowed to do after they log on. Security policies are set up by system administrators. Windows servers offer predefined templates to set security policies for an entire enterprise or just a group of users.
User accounts are a way of managing network access control. Policies should be set for user account password strength, length, and duration. Microsoft NOS products implement a form of user accounts called discretionary access control (DAC).
Every Windows user account is assigned a unique security identifier (SID). Windows server products offer two types of user accounts—local and domain. Both account types provide authentication and authorization. The difference lies in how much someone can access. Local user accounts are restricted to the device holding the account information. If those users want to access network services, such as shared file drives, they may need to sign in using a different account type.
Domain accounts are part of the Active Directory management model. Using a domain account, a user gains access not just to a single device but to whatever domain resources they are authorized to use. This is what’s known as a single-sign-on (SSO) solution.
User accounts can be further divided by scope. The three standard scope categories are administrator, user, and guest. Each user is assigned the smallest scope within which they can accomplish their duties. So if you don’t need an administrator account to do your job, you won’t be given an administrator account.
Windows allows security policies to be set at a group level. The Group Policy Manager, located under Administrative Tools in the control panel, is used to set basic and advanced security policies. Windows network administrators can simplify user account administration using group accounts. Group accounts allow administrators to group together users with similar work responsibilities and provide the same access permissions to everyone in the group. Users can be added or removed as their roles and responsibilities within the organization change.
NOTE Resource sharing is a fundamental reason to connect to a network. Any resource—printer, fax machine, copier, or storage device—that is networked or attached to a networked computer can be shared. With Windows servers, sharing is a simple administrative task for most devices. The Microsoft “group policy management console” provides access to most sharable resources on a system. Right-clicking the resource will normally offer sharing as an option.
UNIX
UNIX is a very efficient, open-source, platform-independent operating system. Most UNIX-based OSs can be downloaded from the Internet for free, and developers are free to add to UNIX and create their own OSs. UNIX forms the basis for many other OSs. Linux, a popular server operating system, is considered “UNIX-like,” while Apple’s Mac OS X operating system is UNIX based.
On a UNIX-based network, multiple users can run applications on the same server without worrying about interference. That’s because UNIX has a highly efficient virtual memory model, allowing applications to execute with a modest impact on physical resources.
Unlike Windows NOSs, UNIX does not rely on a GUI. A UNIX-based system doesn’t even have to have a GUI. In fact, in highly secure UNIX networks, administrators may specifically avoid using a GUI. It takes a lot of code to create a GUI, and more code means more potential areas for malicious intruders to exploit. Instead, in UNIX, all tasks can be accomplished through its powerful CLI.
Because of its dependence on the CLI, the UNIX learning curve can be steep. UNIX has more than 400 standard commands and utilities. The design of these commands prizes efficiency above all. As a result, many commands are very short, and their meanings are far from intuitive. All UNIX commands are case-sensitive. They can be strung together to create complex commands that execute multiple actions at once. This allows for greater efficiency, but in practice it can be intimidating to the UNIX newcomer.
Some UNIX-based OSs, such as Apple OS X, do offer rich GUI environments. Still, there are always certain tasks in a UNIX system that can only be accomplished from the CLI. The UNIX CLI is known as a “shell.” There are many different types of shells, each with its own unique language and syntax for performing commands.
NOTE If you’re accustomed to graphical interfaces, UNIX commands can take a lot of getting used to. Fortunately, you can download a UNIX-based operating system and practice for free. The site www.unixdownload.net has a list of free UNIX-based operating systems available for download. Open a shell and play!
UNIX File Systems
Every object in UNIX is represented as a file. That includes devices, users, executable commands, pipes and redirects, and normal data files. One of these files is the kernel file—the file that actually houses the UNIX OS.
All the files in a UNIX system are arranged in a hierarchy. The top level of this hierarchy is the root, represented by the symbol “/”. This is similar to the “c:” drive in Windows. However, whereas a Windows system may have many top-level drives (c:, d:, e:, etc.), every UNIX system has only one top-level root. Any new drives that are added to a UNIX system exist below the root in the file system.
Each hardware component of a device—hard drives, sound card, NIC, and so on—is represented by a device file in UNIX. UNIX device files aid communication between hardware and software. They look like regular files, but the kernel relies on them to redirect input and output requests. The regular files in a UNIX system—text files, media files, data files, executables, and so on—are organized into directories. Files with a commonality or established relationship appear in the same directory.
UNIX Security
In UNIX, access control and security are enforced through strict authentication and authorization procedures. As in Windows, UNIX access control is based on the discretionary access control (DAC) model.
Network authentication takes many forms in UNIX. The least secure access control mode in UNIX is “simple authentication.” Simple authentication is a form of anonymous login. It uses “anonymous” as the login name and a pseudopassword—normally an email address. Simple authentication is often used for anonymous File Transfer Protocol (FTP) servers. It presents a risk because anyone can gain access to the system.
Plain text authentication is another form of access control used in UNIX. Plain text is used in FTP and Telnet sessions. Telnet is a tool used to access network resources from a remote device. It allows you to log in to another device from a computer and check settings, make adjustments, or change configurations. A user account and password are required. However, the login information and password are sent in plain text and could become compromised in transit.
UNIX provides secure network authentication on an application-by-application basis. Secure Shell (SSH) is an example of application-based network authentication. The user needs an account (login and password). Unlike Telnet, SSH transactions are encrypted to provide confidentiality.
There are even more secure network authentication methods available in UNIX. Pluggable authentication module (PAM) is an example of security-enhanced authentication using Kerberos. UNIX also supports other network security services, such as Open Lightweight Directory Access Protocol (OpenLDAP), and non-Kerberos network authentication methods, such as Simple Authentication and Security Layer (SASL).
NOTE Kerberos is a network authentication protocol used in the United States to encrypt data exchanges. This software is subject to US export control.
Servers
Regardless of the network operating system used to administer it, just about every network of significant size uses servers to share resources among connected nodes. A server isn’t necessarily a piece of hardware. Rather, it’s a role that a piece of hardware can play. Almost any hardware platform can be used as a server. The functionality of the OS and the service support software are what makes a computer a server. If a piece of computer hardware does nothing but provide services, that computer is considered a server. However, the term “server” can also refer to a program that runs on a computer alongside other programs.
Recall the concept of a client-server network architecture (Chapter 1). A server provides services to dependent nodes. It handles resource-intensive or remotely hosted tasks that those nodes can’t perform themselves. Servers are typically named after the service they provide. For example, a AAA server provides authentication, authorization, and accounting services for remote access clients. A mail server hosts email services.
An organization’s servers can reside on a single computer or on several computers grouped together. The approach depends on the organization’s size and the types of services it uses. Some services require little computational power or storage capacity. As a result, they can exist alongside other programs on the same computer. Your laptop computer might also act as a web server, for example, or several servers might reside side by side on a single dedicated computer. Typically, you’ll only see all of an organization’s servers running on one computer in very small networks because such single-server solutions can quickly become overburdened.
Some services require a dedicated hardware platform, either because they need the CPU power and storage capacity or because they are so mission-critical that they warrant a separately maintained device. A network might even have redundant backup servers for crucial functions. Multiple-server solutions are more reliable and tend to perform better, but they are also more expensive and difficult to maintain.
Server Components
The hardware component of a server is a computer. The difference between a typical server and a desktop or laptop usually comes down to power, memory, and capacity. Servers typically have more of each. Servers don’t usually require human interface peripherals, such as a keyboard, mouse, or monitor. Still, you may occasionally connect such peripherals to a server to make configuration changes or perform other tasks.
Servers are often set up differently than PCs. For example, a server often has built-in backup components, such as hard drives, in case the primary component fails. Often, servers are set up to enable hot swapping, which is the ability to replace a device without shutting down the system. Servers are also usually set up for scalability, which means you can improve the performance or capacity of a service by adding more servers. Still, servers share all the basic system resources of any computer. First and foremost is the central processing unit (CPU).
CPU
A CPU is a microchip. The CPU manages all the computer’s activities. It is connected to all other system resources through buses. CPUs are classified according to clock speed and the number of cores they have. Clock speed is the speed at which the CPU can execute commands, measured in hertz. Cores are essentially mini-CPUs that reside together on the same chip. For example, a dual-core chip can execute two sets of commands at once. A server may have one CPU or several, and each CPU may have one core or ten. Generally speaking, the faster the clock speed and the more cores, the more expensive the CPU.
Memory
Memory is where a computer stores data and programs when they are in use. Computer memory can be divided into several different categories. Typically, when computing professionals refer to memory, they’re actually referring to random access memory (RAM). Computers use RAM to store data they’re using for their current processes. A CPU has fast access to data stored in RAM and can use it to execute commands quickly.
RAM is a form of volatile memory,. which requires constant power. When a computer’s power is turned off, everything that’s stored in RAM is lost. Nonvolatile memory (NVM) doesn’t require constant power. Hard disks, flash drives, DVDs, and SD cards are all forms of nonvolatile memory. Nonvolatile memory is used for long-term storage. CPUs can access data on NVM components, but the process is much slower. This is why computers need both RAM and storage (NVM). RAM enables CPUs to execute commands efficiently, and NVM helps the computer remember data after it’s been powered off.
Cache memory is a form of volatile memory that’s often located on the CPU, making it very fast (faster than RAM). Cache memory can store frequently accessed data so the CPU doesn’t have to keep fetching it from RAM. A CPU may have several levels of cache memory. Typically, on a multicore processor, each core has its own level-one cache. Cores may then share a level-two cache, level-three cache, and so on.
Direct Memory Access
You don’t always want every single command or request to pass through the computer’s CPU—sometimes a CPU can’t keep up. Direct memory access (DMA) allows some hardware subsystems direct access to the memory, bypassing the CPU. This leaves the CPU free for more important operations.
Several hardware subsystems use DMA, such as graphics cards, hard drive controllers, network cards, and sound cards. The input/output requirements for these subsystems are intense. If the CPU has to process each request individually, it may cause latency. DMA can also manage memory-to-memory operation, moving or copying a large amount of data without disturbing the CPU.
Input/Output Ports
Computers are based on a fundamental principle—for every input, there is an output. Input/output (I/O) ports are found on both the CPU and the external peripheral ports connected to the motherboard. I/O ports are used to transfer small chunks of information into and out of the processor and/or into and out of the computer.
Examples of peripheral ports include serial (DB-9), USB, parallel, Ethernet (RJ-45), and others. The I/O ports that support these peripherals have a small, built-in memory buffer to hold input from peripheral devices, such as keyboards, mice, and more. The CPU has a set of I/O ports too. The number of CPU I/O ports is a factor in determining the CPU’s clock speed.
When data arrives at an I/O buffer, it triggers what is known as an interrupt request (IRQ) to the CPU. Access to the CPU is controlled by a set of chips called programmable interrupt controllers (PICs). Each peripheral has an interrupt port on the PIC. The PIC forwards these requests to the CPU.
Web Servers and Services
A web server is a server that delivers content such as web pages over the Internet. Web servers are often thought of as a piece of hardware, but that’s not always the case. Web servers are also software and can run independent of traditional server hardware. For example, if a modern network switch is managed through a web interface, the switch has a web server application built into its firmware.
There are literally hundreds of choices when it comes to web servers. Among the most popular are Apache and Microsoft Internet Information Services.
The Apache web server, from the Apache Software Foundation, is one of the most widely used web servers. Apache is an open-source, free application that has been ported to many platforms. Apache supports a wide variety of services, in addition to traditional web content delivery. Because it is open source, administrators and programmers can modify Apache to meet their business needs. The current distribution of Apache is Apache2. Apache2 integrates support for the PHP Hypertext Preprocessor (PHP) scripting language and the MySQL database during standard installation. Apache provides basic authentication services and supports advanced authentication services through digital certificates.
Microsoft Internet Information Services (IIS), formerly called Internet Information Server, is Microsoft’s high-end web server. Like Apache, IIS offers integration of additional services, such as email, file sharing, and streaming media. IIS supports basic security and/or advanced security through different security services, such as digest access authentication or integrated Windows authentication.
Web servers use Hypertext Transfer Protocol (HTTP) to share content. HTTP is an Application Layer protocol used for website communication. HTTP is encapsulated in Transmission Control Protocol (TCP) for reliable two-way communication. Further encapsulation in Internet Protocol (IP) allows HTTP to pass through the Internet. The primary language of HTTP is Hypertext Markup Language (HTML). The illustration shows a live HTTP capture. Notice the structure of the HTTP packet. It includes information about the operating system that initiated the request, the web browser version making the request, the desired language (HTML), and the destination—in this instance, Google.
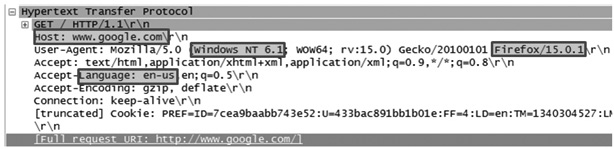
HTML is the primary language used for crafting web pages. HTML uses tags (e.g., <HTML>) and text strings. Each tag identifies how the following text string will be processed by the receiving web browser. The basic syntax for a tag is <WORD>, where WORD represents one of several options. Tags are normally formed in pairs—a start tag, <WORD>, and an end tag, </WORD>. The following illustration shows a captured packet that contains HTML.

Here’s an explanation of the HTML in the illustration:
• <HTML> defines the start of the message. All HTML files begin this way.
• The <HEAD> tag is similar to a header in a word processing document. It normally contains the <TITLE> tag and other document encoding information.
• </HEAD> denotes the end of the header.
• The <BODY> section contains the bulk of the HTML page.
• </BODY> denotes the end of the body.
• </HTML> defines the end of the message. All HTML files end this way.
Extensible Markup Language (XML) is another web page markup language. XML is designed to be human- and machine-readable. The primary goal of XML is to simplify and standardize communication across the Internet. Since XML’s conception, more than 200 variants have been developed and are now in use. Like HTML, XML is transparent to the end user. XML uses a tag-based syntax with both start and end tags. However, unlike HTML, XML does not have a predefined set of tags.
Here is an example of web page data written in both XML and HTML as well as how the data would appear in a web browser:
XML
<CATALOG> <PLANT> <COMMON>Bloodroot</COMMON>
<BOTANICAL>Sanguinaria Canadensis</BOTANTICAL> <ZONE>4</ZONE>
<LIGHT>Mostly Shady</LIGHT> <PRICE>$2.44</PRICE> </PLANT> </CATALOG>
HTML
<HTML><HEAD>Bloodroot</HEAD><TITLE>Sanguinaria Canadensis</TITLE>
<BODY>Zone 4<BR>Mostly Shady<BR>Price: $2.44</BODY></HTML>
How it Appears
Bloodroot Sanguinaria Canadensis
Zone 4
Mostly shady
Price: $2.44
File Servers
A file server is typically a dedicated server used to store and share data files. Dedicated file servers have a distinct advantage over peer-to-peer file sharing because they are more secure and the data they store is available to more users at once.
A file server simplifies sharing and backup of corporate or individual data files. Within a company’s private network, users typically access file servers as if they were drives installed on their computers. The network administrator determines who can access which file servers through access control policies. In order to access a file server over the Internet, however, you will probably find yourself using a File Transfer Protocol (FTP) server.
File Transfer Protocol
FTP is an insecure protocol used to move files via TCP/IP. FTP was built to support a client-server architecture. Usually, users are required to log in to the FTP server before they are able to download or upload files. An FTP server can be configured to support only receiving or only delivering files. It can also be configured to give users access to files anonymously. An anonymous file transfer server uses simple guest authentication and allows users to share files without a dedicated user account. A file transfer server configured to accept anonymous users reduces security but increases availability.
Secure File Transfer Protocols (SFTP and FTPS)
As mentioned, FTP is insecure; user passwords and login credentials are sent as plain text—unencrypted—during the authentication process. To address this issue, new protocols have been created. Secure Shell File Transfer Protocol (SFTP) and File Transfer Protocol over Secure Socket Layer (FTPS) are two ways of securing file transfers over the Internet. SFTP uses Secure Shell (SSH) authentication to improve security; FTPS uses Secure Socket Layer (SSL) certificates to improve security. Both protocols provide confidentiality with encryption.
You will learn more about encryption protocols, including SSH and SSL, in Chapter 16.
Data Servers
Data servers are commonly referred to as database servers. They are used for storing large amounts of corporate data that is accessible, typically, through Structured Query Language (SQL).
The most common database is the relational database. A relational database is composed of a set of interrelated tables with columns and rows. Depending on the needs of the organization, there are several commercial database solutions on the market, plus a few open-source options. Creating a data server is less challenging than configuring and administrating the underlying database.
The database management system (DMBS) manages the database. Every database requires a DBMS. The DBMS allows the database administrator to create the database, add tables to store the data, and implement integrity rules for the database. Now we take a look at some database options.
Oracle
Oracle is a DBMS. It used to be a classic relational database management system (RDBMS), but it has evolved into what is considered an object relational database management system (ORDBMS). This is a hybrid approach that incorporates features of object-oriented design into a relational structure.
In a typical relational database, each cell contains a piece of data. For instance, in an address database, a cell might contain the last name of the person. However, in the object-oriented world, the cell would contain and understand the entire address of the individual—name, address, city, state, and zip code. It would know the different objects that create a standard address object and recognize if one of those objects is invalid or missing. Oracle’s implementation allows storage of entire files within a cell.
Microsoft Structured Query Language
Microsoft SQL Server is an RDBMS. SQL Server has a rich set of management tools used to design, analyze, and optimize a database. It’s capable of managing multiple databases with multiple users. High-end versions of SQL Server are capable of supporting millions of users in a distributed architecture.
MySQL
MySQL is a popular open-source RDBMS, especially for supporting web applications. It does not have a native GUI, but several third-party developers have contributed GUIs for MySQL. Although MySQL is open-source software, there are commercial versions that offer added functionality. Many big-name websites, including Facebook, Twitter, and YouTube, use MySQL.
NoSQL
NoSQL is a nontraditional, nonrelational, cloud-based database. It does not rely on SQL and promises a “zero-admin” solution to database administration. NoSQL (often referred to as “Not only SQL”) is mostly open-source software. Nonrelational or “cloud” databases are gaining support in the database community, especially for so-called big data and real-time applications. Instead of using tables like a relational database, NoSQL uses what are called “collections.” These offer little functionality beyond record storage. “Zero-admin” isn’t always a good thing, however. It can also mean “zero technical support” and “zero user experience.”
Email Servers
Simple Mail Transfer Protocol (SMTP) servers are often referred to as email servers. Email servers are networked computers that receive and forward email messages across a network. While there are some dedicated email appliances, email servers are usually a common server with SMTP services installed as an application.
On the Internet side of the equation, email servers forward and receive messages from other email servers. On the enterprise side of the equation, email clients send and receive email from the email server. As such, an email server acts as a gateway between its clients and the Internet. The following are the Application Layer protocols used by email servers to transmit messages, along with their associated ports. You will learn more about ports and protocols in Chapter 9.
NOTE In a TCP/IP network, a port is a 16-bit number included in the TCP or UDP Transport Layer header. The port number typically indicates the Application Layer protocol that generated a data packet. A port may also be called by its associated service. For example, port 80 may be called HTTP, or port 23 may be called Telnet. You will learn more in coming chapters.
Simple Mail Transfer Protocol
Simple Mail Transfer Protocol (SMTP) is an Application Layer protocol used to transmit email messages across a network. SMTP uses Transmission Control Protocol (TCP) for transport and Internet Protocol (IP) for routing the email message to email servers. An SMTP server listens for traffic on TCP port 25, and it uses port 25 for receiving and sending data between email servers. An email client might use SMTP port 25 for sending messages to the email server but typically uses other protocols, such as Post Office Protocol (POP) or Internet Message Access Protocol (IMAP), to receive messages from the email server.
Post Office Protocol
Post Office Protocol (POP) is one of two primary Application Layer protocols used to retrieve email messages from an email server. POP uses TCP port 110 to download messages from an email server. Because POP downloads every available message, once downloaded, a user can read messages at their leisure. With POP a user can choose to leave a copy of the message on the server. POP is currently at version 3 and normally displayed as POP3. Post Office Protocol Secure (POPS) can be configured to use Secure Socket Layer (SSL) to encapsulate email messages. POPS uses TCP port 995.
Internet Message Access Protocol
Internet Message Access Protocol (IMAP) is the other Application Layer protocol used to retrieve email messages from an email server. IMAP uses TCP port 143 to receive the message header. Receiving only the message header is faster than downloading the entire message. Users can then determine which messages they want to read or discard. When a user wants to read a message, the entire message must be downloaded. IMAP is currently at version 4 and is normally written as IMAP4. Internet Message Access Protocol Secure (IMAPS) can be configured to use SSL to encapsulate email messages. IMAPS uses TCP port 993.
Hypertext Transfer Protocol Email
HTTP is not a dedicated email protocol. However, HTTP is used to access web-based email applications. Google Mail, Yahoo Mail, and other services use a web-based interface for delivering and managing client email.
Multipurpose Internet Mail Extensions
Multipurpose Internet Mail Extensions (MIME) is an extended email support format. MIME allows non-text-based formats, such as sound, images, videos, or program executables, to be included in an email message. MIME is extensible, which means that as new forms of content are developed, MIME can be adapted to accommodate the transport via email.
Network Time Protocol Server
A Network Time Protocol (NTP) server is used to synchronize time across a network. Some operating systems will not function properly in an unsynchronized network.
NTP servers are grouped in a hierarchical structure known as the clock strata. Clock strata are separated into stratum 0 through stratum 16. Stratum 0 clocks are the most accurate clocks on the planet—typically atomic, global positioning satellite (GPS), or radio clocks. Stratum 1 clocks are the computers attached to stratum 0 devices. They provide time service to stratum 2 clocks. Stratum 2 clocks are computers that provide time synchronization for stratum 3 servers. Stratums 4 through 15 are typically recipients of the NTP server services. Stratum 16 computers are considered unsynchronized systems.
External Storage Systems
One of the most commonly used network services is data storage. An external storage system is really any storage that is not part of a node itself (a PC, laptop, media player, etc.). External storage both adds storage capacity and, with the help of a network, allows nodes to share storage space and access shared files.
The redundant array of independent disks (RAID) system is one of the most commonly employed storage solutions in today’s enterprise networks. A RAID connects several hard drives together to improve data retrieval performance. There are two basic types of RAIDs: hardware based and software based. When troubleshooting RAIDs, it is very important to verify the type before beginning repairs.
RAIDs are classified by level. The Storage Networking Industry Association originally standardized five RAID levels—RAID 1 through RAID 5. Each level has a different balance of capacity, performance, and fault tolerance. Many new variations have emerged; one of the most common configurations used today, RAID 0, was not part of the initial specification.
Some RAIDs are fault tolerant, while others are not. A fault-tolerant system ensures data remains intact even if a drive fails. A fault-tolerant RAID solution includes additional inactive hard drives used for data parity across the RAID. If a hard drive fails, the parity drive is capable of rebuilding the RAID after a new hard drive is installed. The failed drive can be removed and replaced without interrupting the system. Some RAIDs use a standby spare hard drive, which automatically joins and rebuilds the RAID operations if an existing hard drive fails. This is known as a “hot spare.” Table 4-2 compares the most common RAIDs in use today.
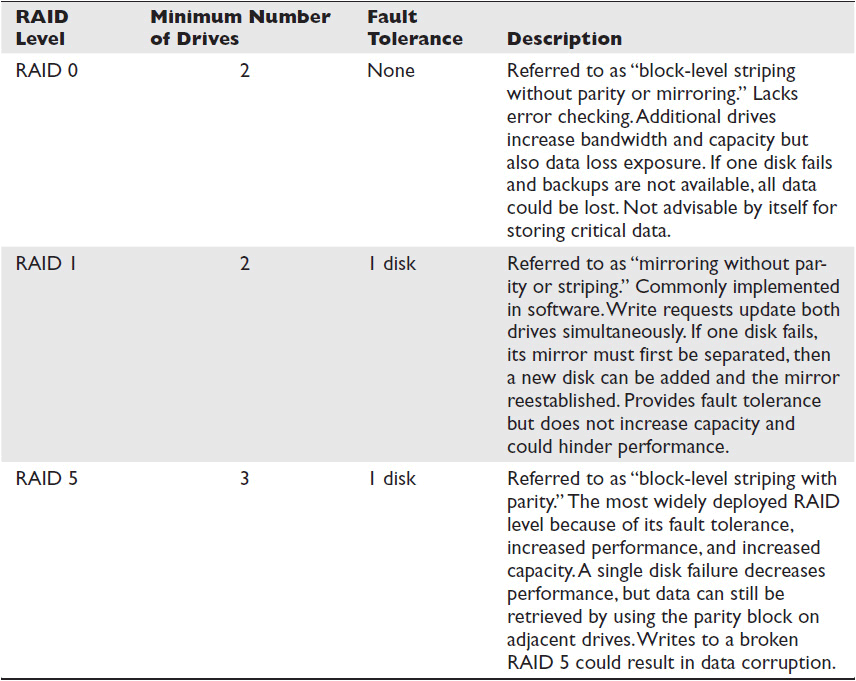
Table 4-2 Common RAID Configurations
NOTE Hard drives aren’t the only technology used for redundant arrays. For example, a RAIT uses tape drives to build an array. The latest entry is RAIS—redundant array of independent solid-state disks. These are external storage systems like a RAID, but with different storage media.
Network-Attached Storage
Network-attached storage (NAS) is normally a dedicated computer file server with a RAID and a networking interface. It has been optimized for management and delivery over a network. A NAS is “thinner” than a typical file server. Its pared-down OS simplifies administration and increases security. NAS systems are typically accessible either from within an organization’s private network, or via a virtual private network (VPN).
NAS servers typically lack I/O ports for monitors and keyboards. Usually, users and administrators access them from a remote terminal over the network instead. NAS servers can be clustered together to increase storage capacity, and can transfer data to their client nodes over Ethernet or TCP/IP. They can also be deployed on other types of networks, but for our purposes, they are principally Ethernet- and TCP/IP-based.
While a NAS system is a storage device attached to a network, a storage area network (SAN) is a dedicated high-speed network of storage devices. SANs can be a single RAID attached via a fiber channel directly to a computer, or a group of storage devices connected to each other by fiber channels whereby the fiber channels form a network.
The downside of a SAN is the way it manages data. SANs operate only at block level, not file level. File abstraction (i.e., file name/location mapping) can be achieved by overlaying file-level access directly on the SAN, but this could affect system performance. Instead, SANs are normally attached to a file server that manages all file-level access.
NOTE These days you hear a lot about “cloud storage,” which is basically data storage that you rent from a service provider and access via the Internet. One of the benefits of cloud storage is that you only pay for the storage you need. If you need extra storage space, the cloud system can be set up to expand without any intervention—you just pay extra for the extra capacity. You need robust network connections to make any cloud-based solution work well, but at least with cloud storage you shouldn’t end up buying physical disk drives that you may not need.
Virtual Machines
Operating system platforms and servers are typically associated with hardware. However, thanks to virtualization and virtual machines, this doesn’t have to be the case. A virtual machine (VM) is software that pretends to be hardware. It acts like the sort of robust program that is traditionally associated with a dedicated device; but instead of requiring a physical device of its own, a VM runs on a computer alongside other programs.
VMs allow you to run an OS inside another OS, like a nesting doll. Or, for example, you could run an entire web media server as a virtual machine on a Windows computer. This would allow you to use that computer as both a web media server and a PC. It would also save you from having to purchase a separate web server.
Similarly, you can use VMs to test programs or files on different platforms. If you have enough processing power, you can run OS X, Windows, and Linux on the same computer in their own VMs. This allows you to test, for instance, a media file to see if it plays on all three systems.
You need a fairly robust CPU to run multiple VMs. Still, a virtual machine is a lot cheaper than a physical one. You can download many OS VMs for free. In any case, remember: Neither a server nor a personal computer has to be tied to a physical device anymore.
Chapter Review
This chapter gave a broad overview of the hardware and software that make up a typical network. When you build a networked AV system, you need to be aware of these components and how they affect one another—and your AV devices. What services will the AV system need to connect to? How will it be managed by the network OS?
Now that you’ve completed this chapter, you should be able to
• Identify the components required to build and access a TCP/IP network and define their roles
• Compare and contrast Windows and UNIX-based network operating systems
• Identify the role and general characteristics of a server
• Describe the roles and functionality of commonly used web servers and services as well as other types of servers
• Identify the characteristics of networked external storage systems
Review Questions
1. A card that links a device to a network is known as a _____.
A. radio frequency card (RFC)
B. network interface card (NIC)
C. versatile interface processor (VIP)
D. data interface card (DIC)
2. A _____ address is unique to every device and identifies a network’s equipment.
A. media access control
B. transfer mode
C. digital subscriber line
D. baseband
3. Which of the following functions are performed by an unmanaged switch? Select all that apply.
A. Examines a packet’s IP address to determine its next destination
B. Allows technicians to set up VLANs and configure LAN-based QoS
C. Forwards Ethernet traffic based on its MAC address
D. Provides a physical connection between multiple devices
4. Which of the following functions are performed by a router? Select all that apply.
A. Allows technicians to set up VLANs and configure LAN-based QoS
B. Forwards data between devices that are not physically connected
C. Translates data from one Network Layer protocol to another
D. Examines a packet’s IP address to determine its next destination
5. When a frame arrives at a _____, the device broadcasts the frame out on all ports, including the one on which it arrived.
A. switch
B. gateway
C. hub
D. router
6. A network operating system is distinguished from other operating systems by its ability to _____. Select all that apply.
A. accept commands through a command-line interface
B. require a password before a user is allowed to log in
C. forward remote sessions
D. assign security policies to multiple user accounts
7. The ______ network OS relies heavily on graphical user interface (GUI) tools.
A. UNIX
B. Windows
C. CLI
D. Linux
8. A server is _____.
A. any device or software program that provides services to dependent devices
B. any software program that provides access to a network
C. any piece of hardware capable of accessing or providing network resources
D. a piece of computer hardware without any peripherals or extra components, designed to be installed in a rack
9. A server that delivers content such as web pages over the Internet is known as a(n) _____.
A. Internet server
B. data server
C. file server
D. web server
10. Which of the following best describes the main difference between HTML and XML?
A. XML uses customizable tags that are designed to be both human- and machine-readable, while HTML uses a predefined set of tags.
B. HTML is used to format content, while XML is used to segment content for delivery over the Internet.
C. HTML tags are transparent to the end user, while XML tags are exposed.
D. HTML is an Application Layer protocol, while XML is a Presentation Layer protocol.
11. Which of the following are traditional relational database management systems? Select all that apply.
A. NoSQL
B. MySQL
C. Microsoft SQL Server
D. Oracle
12. Which of the following best describes the main difference between the mail protocols POP and IMAP?
A. POP sends message contents as clear text, while all IMAP traffic is encrypted.
B. POP is an Application Layer protocol, while IMAP is a Presentation Layer protocol.
C. POP allows users to send text only, while IMAP allows users to embed non-text traffic, such as sound, images, or video.
D. POP downloads every available message so that they can be read offline, while IMAP downloads only message headers.
13. Unlike a RAID 0 system, a fault-tolerant RAID ensures that _____.
A. several hard drives are interconnected to improve data performance
B. the storage system automatically detects and compensates for user errors
C. data systems remain intact even if one of the RAID’s drives fails
D. the RAID does not have to be attached to the network node
14. Which of the following best describes the main difference between network-attached storage (NAS) and a storage area network (SAN)?
A. NAS data is transmitted over copper while SAN data is transmitted over fiber.
B. NAS allows users to send files over FDDI or ATM networks, while SAN allows users to send files over Ethernet or TCP/IP networks.
C. A NAS device is typically a dedicated computer file server with an attached RAID system, while a SAN is a dedicated high-speed network of such devices.
D. NAS uses file servers to manage file access, while SAN uses software to manage peer-to-peer file exchanges.
Answers
1. B. A card that links a device to a network is known as a network interface card (NIC).
2. A. A media access control (MAC) address is unique to every device and identifies a network’s equipment.
3. C, D. An unmanaged switch forwards Ethernet traffic based on its MAC address and provides a physical connection between multiple devices.
4. B, D. A router can forward data between devices that are not physically connected and examines a packet’s IP address to determine its next destination.
5. C. When a frame arrives at a hub, the hub broadcasts the frame out on all ports, including the one on which it arrived.
6. C, D. A network operating system is distinguished from other operating systems by its ability to forward remote sessions and assign security policies to multiple user accounts.
7. B. The Windows network OS relies heavily on graphical user interface (GUI) tools.
8. A. A server is any device or software program that provides services to dependent devices.
9. D. A server that delivers content such as web pages over the Internet is known as a web server.
10. A. XML uses customizable tags that are designed to be both human- and machine-readable, while HTML uses a predefined set of tags.
11. B, C. MySQL and Microsoft SQL Server are traditional relational database management systems.
12. D. POP downloads every available message so that they can be read offline, while IMAP downloads only message headers.
13. C. Unlike a RAID 0 system, a fault-tolerant RAID ensures that data systems remain intact even if one of the RAID’s drives fails.
14. C. A NAS device is typically a dedicated computer file server with an attached RAID system, while a SAN is a dedicated high-speed network of such devices.