
![]()
Views represent virtual pseudo tables defined by underlying queries, and they add another layer of abstraction to the system. Views hide implementation details and can present queries with complex joins and aggregation as a single table. Moreover, views can be used to restrict access to the data and provide just a subset of the rows and columns to the users.
There are two different kinds of views available in SQL Server: regular and indexed (materialized). Perhaps this is not the standard terminology; that is, regular views are just called views, although I will clearly differentiate them in the chapter.
Regular views are just the metadata. When you reference a view in your queries, SQL Server replaces it with the query from the view definition and optimizes and executes the statement, as the view is not present. They are working similarly to#define macro in the C programming language, where preprocessor replaces the macro with its definition during compilation.
There are two main benefits provided by the views. First, they simplify security administration in the system. You can use views as another security layer and grant users permissions on the views rather than on the actual tables. Moreover, views can provide users only with a subset of the data filtering out of some rows and columns from the original tables.
Consider the example where you have a table that contains information about a company’s employees, which has both private and public attributes. The code that creates this table is shown in Listing 9-1.
Listing 9-1. Views and Security: Table creation
create table dbo.Employee
(
EmployeeId int not null,
Name nvarchar(100) not null,
Position nvarchar(100) not null,
Email nvarchar(256) not null,
DateOfBirth date not null,
SSN varchar(10) not null,
Salary money not null,
PublishProfile bit not null, -- specifies if employee info needs to be listed in the intranet
constraint PK_Employee
primary key clustered(EmployeeID)
)
Let’s assume that you have a system that displays the company directory on their intranet. You can define the view that selects public information from the table, filtering out the employees who do not want their profiles to be published, and then, grant users select permission on the view rather than on the table. You can see the code in Listing 9-2.
Listing 9-2. Views and Security: View creation
create view dbo.vPublicEmployeeProfile(EmployeeId, Name, Position, Email)
as
select EmployeeId, Name, Position, Email
from dbo.Employee
where PublishProfile = 1
go
grant select on object::dbo.vPublicEmployeeProfile to [IntranetUsers]
While you can accomplish this task without the view with column-level permissions and additional filter in the queries, the view approach is simpler to develop and maintain.
Another benefit of views is abstracting the database schema from the client applications. You can alter the database schema, keeping it transparent to the applications by altering the views and changing the underlying queries. It is then transparent to the client applications as long as the views interface remain the same.
In addition, you can hide complex implementation details and table joins and use views as a simple interface to client applications. That approach is a bit dangerous, however. It could lead to unnecessary performance overhead if we are not careful.
Let’s look at a few examples. Let’s assume that you have Order Entry system with two tables: Orders and Clients. The code to create these tables is shown in Listing 9-3.
Listing 9-3. Views and Joins: Tables creation
create table dbo.Clients
(
ClientId int not null,
ClientName varchar(32),
constraint PK_Clients
primary key clustered(ClientId)
);
create table dbo.Orders
(
OrderId int not null identity(1,1),
Clientid int not null,
OrderDate datetime not null,
OrderNumber varchar(32) not null,
Amount smallmoney not null,
constraint PK_Orders
primary key clustered(OrderId)
);
Let’s create a view that returns orders information, including client names, as shown in Listing 9-4.
Listing 9-4. Views and Joins: vOrders view creation
create view dbo.vOrders(OrderId, Clientid, OrderDate, OrderNumber, Amount, ClientName)
as
select o.OrderId, o.ClientId, o.OrderDate, o.OrderNumber, o.Amount, c.ClientName
from
dbo.Orders o join dbo.Clients c on
o.Clientid = c.ClientId;
This implementation is very convenient for developers. By referencing the view, they have complete information about the orders without worrying about the underlying join. When a client application wants to select a specific order, it could issue the select, as shown in Listing 9-5, and get the execution plan, as shown in Figure 9-1.
Listing 9-5. Views and Joins: Selecting all columns from vOrders view
select OrderId, Clientid, ClientName, OrderDate, OrderNumber, Amount
from dbo.vOrders
where OrderId = @OrderId
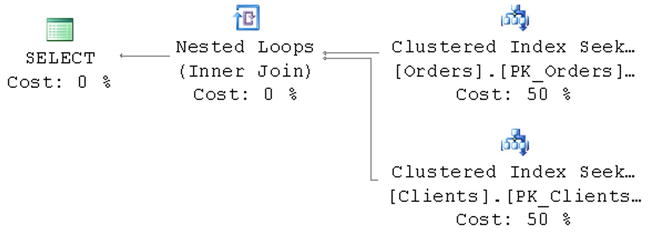
Figure 9-1. Execution plan when selecting all columns from the view
This is exactly what you are expecting. SQL Server replaces the view with an underlying query that selects data from the Orders table, joining it with the data from the Clients table. Although, if you run the query that returns columns only from the Orders table, as shown in Listing 9-6, you would have slightly unexpected results and the corresponding execution plan, as shown in Figure 9-2.
Listing 9-6. Views and Joins: Selecting columns from the Orders table using vOrders view
select OrderId, OrderNumber, Amount
from dbo.vOrders
where OrderId = @OrderId
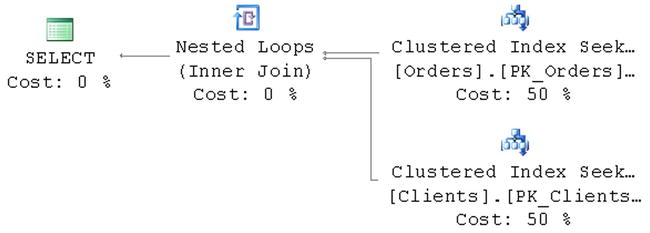
Figure 9-2. Execution plan when selecting columns that belong to the Orders table only
As you see, SQL Server still does the join even if you do not need ClientName data there. It makes sense: You are using inner join in the view, and SQL Server needs to exclude the rows from the Orders table that do not have corresponding rows in the Clients table.
How can you solve this problem and eliminate the unnecessary join? The first option is to use an outer join rather than the inner one, as shown in Listing 9-7.
Listing 9-7. Views and Joins: vOrders2 view creation
create view dbo.vOrders2(OrderId, Clientid, OrderDate, OrderNumber, Amount, ClientName)
as
select o.OrderId, o.ClientId, o.OrderDate, o.OrderNumber, o.Amount, c.ClientName
from
dbo.Orders o left outer join dbo.Clients c on
o.Clientid = c.ClientId;
Now if you run select statement, as shown in Listing 9-8, you would have the execution plan without join, as shown in Figure 9-3.
Listing 9-8. Views and Joins: Selecting columns from the Orders table using vOrders2 view
select OrderId, OrderNumber, Amount
from dbo.vOrders2
where OrderId = @OrderId

Figure 9-3. Execution plan with left outer join
While it does the trick, outer joins restrict the choices of the query optimizer when generating execution plans. Another thing to keep in mind is that you changed the behavior of the view. If you can have orders that do not belong to clients in the system, then the new implementation would not exclude them from the result set. This can introduce side effects and break other code that references the view and relies on the old behavior of the inner join. You must analyze the data and subject area before implementing join elimination using the outer joins.
A better option is adding a foreign key constraint to the Orders table, as shown in Listing 9-9.
Listing 9-9. Views and Joins: Adding foreign key constraint
alter table dbo.Orders
with check
add constraint FK_Orders_Clients
foreign key(ClientId)
references dbo.Clients(ClientId)
A trusted foreign key constraint would guarantee that every order has a corresponding client row. As a result, SQL Server can eliminate the join from the plan, as shown in Listing 9-10 and in Figure 9-4.
Listing 9-10. Views and Joins: Selecting columns from the Orders table using vOrders view
select OrderId, OrderNumber, Amount
from dbo.vOrders
where OrderId = @OrderId

Figure 9-4. Execution plan with inner join when foreign key constraint is present
Unfortunately, there is no guarantee that SQL Server will eliminate all unnecessary joins, especially in very complex cases with many tables involved. Moreover, SQL Server does not eliminate joins if the foreign key constraints include more than one column.
Now let’s review an example where a system collects location information for devices that belong to multiple companies. The code that creates the tables is shown in Listing 9-11.
Listing 9-11. Join elimination and multi-column foreign key constraints: Table creation
create table dbo.Devices
(
CompanyId int not null,
DeviceId int not null,
DeviceName nvarchar(64) not null,
);
create unique clustered index IDX_Devices_CompanyId_DeviceId
on dbo.Devices(CompanyId, DeviceId);
create table dbo.Positions
(
CompanyId int not null,
OnTime datetime2(0) not null,
RecId bigint not null,
DeviceId int not null,
Latitude decimal(9,6) not null,
Longitute decimal(9,6) not null,
constraint FK_Positions_Devices
foreign key(CompanyId, DeviceId)
references dbo.Devices(CompanyId, DeviceId)
);
create unique clustered index IDX_Positions_CompanyId_OnTime_RecId
on dbo.Positions(CompanyId, OnTime, RecId);
create nonclustered index IDX_Positions_CompanyId_DeviceId_OnTime
on dbo.Positions(CompanyId, DeviceId, OnTime);
Let’s create the view that joins these tables, as shown in Listing 9-12.
Listing 9-12. Join elimination and multi-column foreign key constraints: View creation
create view dbo.vPositions(CompanyId, OnTime, RecId, DeviceId, DeviceName, Latitude, Longitude)
as
select p.CompanyId, p.OnTime, p.RecId, p.DeviceId, d.DeviceName, p.Latitude, p.Longitude
from dbo.Positions p join dbo.Devices d on
p.CompanyId = d.CompanyId and p.DeviceId = d.DeviceId;
Now let’s run the select shown in Listing 9-13. This select returns the columns from the Positions table only, and it produces the execution plan shown in Figure 9-5.
Listing 9-13. Join elimination and multi-column foreign key constraints: Select from vPositions view
select OnTime, DeviceId, Latitude, Longitude
from dbo.vPositions
where CompanyId = @CompanyId and OnTime between @StartTime and @StopTime
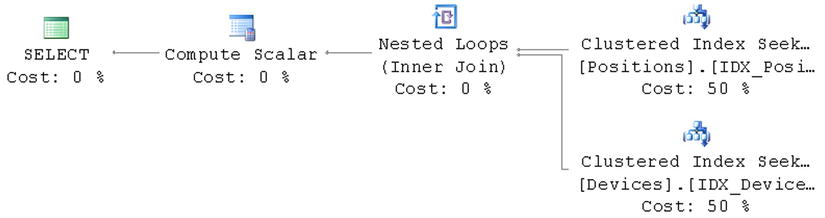
Figure 9-5. Execution plan with multi-column foreign key constraints
Even with a foreign key constraint in place, you still have the join. SQL Server does not perform join elimination when a foreign key constraint has more than one column. Unfortunately, there is very little you can do in such a situation to perform join elimination. You can use the approach with the outer joins, although it is worth considering querying the tables directly rather than using views in such a scenario.
Finally, SQL Server does not perform join elimination, even with single column foreign key constraints, when tables are created in tempdb. You need to keep this in mind if you use tempdb as the staging area for the ETL processes when you load the data from external sources and do some processing and data transformation before inserting it into user database.
![]() Tip Using tempdb as the staging area can improve the performance of the processing due to more efficient transaction logging there, although it introduces development challenges because SQL Server recreates tempdb on restart. We will talk more about tempdb in Chapter 12, “Temporary Tables” and discuss tempdb transaction logging in Chapter 29, “Transaction Log Internals.”
Tip Using tempdb as the staging area can improve the performance of the processing due to more efficient transaction logging there, although it introduces development challenges because SQL Server recreates tempdb on restart. We will talk more about tempdb in Chapter 12, “Temporary Tables” and discuss tempdb transaction logging in Chapter 29, “Transaction Log Internals.”
As opposed to regular views, which are just metadata, indexed views materialize the data from the view queries storing it in the database similarly to the tables. Then every time the base tables are updated, SQL Server synchronously refreshes the data in the indexed views, thus keeping them up to date.
In order to define an indexed view, you need to create a regular view using schemabinging option. This option binds the view and underlying tables, and it prevents any alteration of the tables that affects the view.
Next, you need to create a unique clustered index on the view. At this point, SQL Server materializes the view data in the database. You can also create non-clustered indexes if needed after the clustered index has been created. When indexes are defined as unique, SQL Server enforces the rule and fails the modifications of the base tables in case of a uniqueness violation.
One of the common use-cases for indexed views prior to SQL Server 2008 was for supporting uniqueness on a subset of values. We discussed one such example, uniqueness of the optional SSN column, in Chapter 4, “Special Features,” solving the problem by creating a filtered index on the SSN column.
Listing 9-14 shows how you can use indexed view to achieve the same results.
Listing 9-14. Enforcing uniqueness of not-null values in nullable column with indexed view
create table dbo.Clients
(
ClientId int not null,
Name nvarchar(128) not null,
SSN varchar(10) null
)
go
create view dbo.vClientsUniqueSSN(SSN)
with schemabinding
as
select SSN from dbo.Clients where SSN is not null
go
create unique clustered index IDX_vClientsUniqueSSN_SSN on dbo.vClientsUniqueSSN(SSN)
At that point, you would not be able to insert a non-unique SSN value into the table because it violates the uniqueness of the clustered index of the view.
There are plenty of requirements and restrictions in order for a view to be indexable. To name just a few, a view cannot have subqueries, semi and outer joins, reference LOB columns, and have UNION, DISTINCT, and TOP specified. There are also the restrictions on the aggregate functions that can be used with a view. Finally, a view needs to be created with specific SET options, and it can reference only deterministic functions.
![]() Note Look at Books Online at: http://technet.microsoft.com/en-us/library/ms191432.aspx for a complete list of requirements and restrictions.
Note Look at Books Online at: http://technet.microsoft.com/en-us/library/ms191432.aspx for a complete list of requirements and restrictions.
![]() Tip You can use the function OBJECTPROPERTY with parameter IsIndexable to determine if you can create the clustered index on the view. The following select returns 1 if the view vPositions is indexable:
Tip You can use the function OBJECTPROPERTY with parameter IsIndexable to determine if you can create the clustered index on the view. The following select returns 1 if the view vPositions is indexable:
SELECT OBJECTPROPERTY (OBJECT_ID(N'dbo.vPositions','IsIndexable')
One instance where an indexed view is useful is for optimization of queries that include joins and aggregations on large tables. Let’s look at this situation, assuming that you have OrderLineItems and Products tables in the system. The code that creates these tables is shown in Listing 9-15.
Listing 9-15. Indexed views: Table creation
create table dbo.Products
(
ProductID int not null identity(1,1),
Name nvarchar(100) not null,
constraint PK_Product
primary key clustered(ProductID)
);
create table dbo.OrderLineItems
(
OrderId int not null,
OrderLineItemId int not null identity(1,1),
Quantity decimal(9,3) not null,
Price smallmoney not null,
ProductId int not null,
constraint PK_OrderLineItems
primary key clustered(OrderId,OrderLineItemId),
constraint FK_OrderLineItems_Products
foreign key(ProductId)
references dbo.Products(ProductId)
);
create index IDX_OrderLineItems_ProductId on dbo.OrderLineItems(ProductId);
Now let’s imagine a dashboard that displays information about the ten most popular products sold to date. The dashboard can use the query shown in Listing 9-16.
Listing 9-16. Indexed views: Dashboard query
select top 10 p.ProductId, p.name as ProductName, sum(o.Quantity) as TotalQuantity
from dbo.OrderLineItems o join dbo.Products p on
o.ProductId = p.ProductId
group by
p.ProductId, p.Name
order by
TotalQuantity desc
If you run dashboard query in the system, you would receive the execution plan shown in Figure 9-6.

Figure 9-6. Execution plan of the query that selects the top-10 most popular products
As you see, this plan scans and aggregates the data from the OrderLineItems table, which is expensive in terms of IO and CPU. Alternatively, you can create an indexed view that does the same aggregation and materializes the results in the database. The code to create this view is shown in Listing 9-17.
Listing 9-17. Indexed views: Indexed view creation
create view dbo.vProductSaleStats(ProductId, ProductName, TotalQuantity, Cnt)
with schemabinding
as
select p.ProductId, p.Name, sum(o.Quantity), count_big(*)
from dbo.OrderLineItems o join dbo.Products p on
o.ProductId = p.ProductId
group by
p.ProductId, p.Name
go
create unique clustered index IDX_vProductSaleStats_ProductId
on dbo.vProductSaleStats(ProductId);
create nonclustered index IDX_vClientOrderTotal_TotalQuantity
on dbo.vProductSaleStats(TotalQuantity desc)
include(ProductName);
The code in Listing 9-17 creates a unique clustered index on the ProductId column as well as a non-clustered index on the TotalQuantity column.
![]() Note An Indexed view must have count_big(*) aggregation if group by is present. This helps to improve the performance of the indexed view maintenance if data in the underlying tables is modified.
Note An Indexed view must have count_big(*) aggregation if group by is present. This helps to improve the performance of the indexed view maintenance if data in the underlying tables is modified.
Now you can select data directly from the view, as shown in Listing 9-18.
Listing 19-18. Indexed views: Selecting data from the indexed view
select top 10 ProductId, ProductName, TotalQuantity
from dbo.vProductSaleStats
order by TotalQuantity desc
The execution plan shown in Figure 9-7 is much more efficient.

Figure 9-7. Execution plan of the query that selects the top-10 most popular products utilizing an indexed view
As always, “there is no such thing as a free lunch.” Now SQL Server needs to maintain the view. Each time you insert or delete the OrderLineItem row or, perhaps, modify the quantity or product there, SQL Server needs to update the data in the indexed view in addition to the main table.
Let’s look at the execution plan of the insert operation, as shown in Figure 9-8.
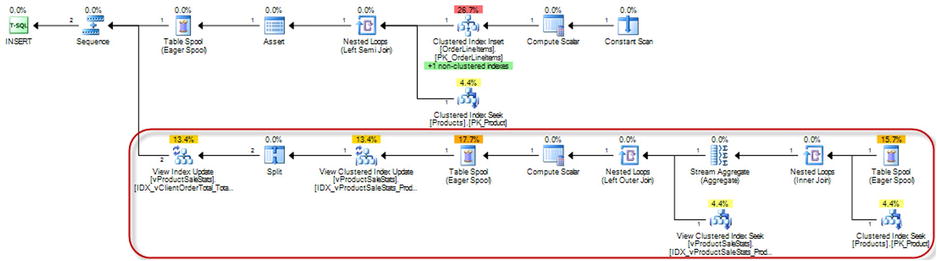
Figure 9-8. Execution plan of the query that inserts data into OrderLineItems table
The part of the plan in the highlighted area is responsible for indexed view maintenance. This portion of the plan could introduce a lot of overhead when data in the table is highly volatile, which leads us to a very important conclusion. That is, indexed views work the best when the benefits we get while selecting the data exceed the overhead of maintaining the view during data modifications. Simply said, indexed views are most beneficial when underlying data is relatively static. Think about Data Warehouse systems where a typical workload requires a lot of joins and aggregations, and the data is updating infrequently, perhaps based on some schedule, as an example.
![]() Tip Always test the performance of the batch data update when there is an indexed view referencing a table. In some cases, it would be faster to drop and recreate the view, rather than keep it during such operations.
Tip Always test the performance of the batch data update when there is an indexed view referencing a table. In some cases, it would be faster to drop and recreate the view, rather than keep it during such operations.
In an OLTP system, you need to consider carefully the pros and cons of indexed views on a case-by-case basis. It is better to avoid indexed views if the underlying data is volatile. The view we created above is an example of what should not be done in systems where data in the OrderLineItems table is constantly changing.
Another case where indexed views can be beneficial is join optimization. One system I dealt with had a hierarchical security model with five levels in the hierarchy. There were five different tables, and each of them stored information about specific permissions for every level in the hierarchy. Almost every request in the system checked permissions by joining the data from those tables. We optimized that part of the system by creating an indexed view that performed a five-table join so that every request performed just a single index seek operation against the indexed view. Even though it were OLTP system, the data in the underlying tables was relatively static, and the benefits we achieved exceeded the overhead of the indexed view maintenance.
While indexed views can be created in every edition of SQL Server, their behavior is indeed edition-specific. Non-Enterprise editions of SQL Server need to reference a view directly in the queries using WITH (NOEXPAND) hint in order to use the data from the indexed view. Without the hint, SQL Server expands the indexed view definition and replaces it with an underlying query similar to the regular views. Enterprise and Developer editions do not require such hints. SQL Server can utilize the indexed views even when you do not reference them in the query.
Now let’s return to our previous example. In Enterprise edition, when you run the original query shown in Listing 9-19, you would still get the execution plan that utilizes it, as shown in Figure 9-9:
Listing 9-19. Indexed views: Dashboard query
select top 10 p.ProductId, p.name as ProductName, sum(o.Quantity) as TotalQuantity
from dbo.OrderLineItems o join dbo.Products p on
o.ProductId = p.ProductId
group by
p.ProductId, p.Name
order by
TotalQuantity desc

Figure 9-9. Execution plan of the query that does not reference the indexed view (Enterprise or Developer editions)
In fact, the Enterprise edition of SQL Server can use indexed views for any queries, regardless of how close they are to the view definition. For example, let’s run the query that selects the list of all of the products ever sold in the system. The query is shown in Listing 9-20.
Listing 9-20. Indexed views: Query that returns the list of all of the products ever sold in the system
select p.ProductId, p.Name
from dbo.Products p
where
exists
(
select *
from dbo.OrderLineItems o
where p.ProductId = o.ProductId
)
SQL Server recognizes that it would be cheaper to scan the indexed view rather than perform the join between two tables, and it generates the plan as shown in Figure 9-10.

Figure 9-10. Execution plan of the query (Enterprise or Developer editions)
In some cases, you can use such behavior if you need to optimize the systems where you cannot refactor the code and queries. If you are working with Enterprise edition, you can create the indexed views and optimizer would start using them for some of the queries, even when those queries do not reference the views directly. Obviously, you need carefully consider the indexed view maintenance overhead that you would introduce with such an approach.
Partitioned Views
Partitioned views combine the data via a UNION ALLof the multiple tables stored on the same or different database servers. One of the common use-cases for such an implementation is data archiving; that is, when you move old (historical) data to a separate table(s) and combine all of the data, current and historic, with the partitioned view. Another case is data sharding, when you separate (shard) data between multiple servers based on some criteria. For example, a large, Web-based shopping cart system can shard the data based on geographic locations of the customers. In such cases, partitioned views can combine the data from all shards and use it for analysis and reporting purposes.
![]() Note We will discuss partitioned views in greater detail in Chapter 15, “Data Partitioning.”
Note We will discuss partitioned views in greater detail in Chapter 15, “Data Partitioning.”
Client applications can modify data in underlying tables through a view. It can reference the view in the DML statements, although there is a set of requirements to be met. To name just a few, all modifications must reference the columns from only one base table. Those columns should be physical columns and should not participate in the calculations and aggregations.
![]() Note You can see the full list of requirements in Books Online at: http://technet.microsoft.com/en-us/library/ms187956.aspx.
Note You can see the full list of requirements in Books Online at: http://technet.microsoft.com/en-us/library/ms187956.aspx.
These restrictions are the biggest downside of this approach. One of the reasons we are using views is to add another layer of abstraction that hides the implementation details. By doing updates directly against views, we are limited in how we can refactor them. If our changes violate some of the requirements to make the view updatable, the DML statements issued by the client applications would fail.
Another way to make a view updateable is by defining an INSTEAD OF trigger. While this gives us the flexibility to refactor the views in the manner we want, this approach is usually slower than directly updating the underlying tables. It also makes the system harder to support and maintain—you must remember that data in tables can be modified through views.
Finally, you can create the view with the CHECK OPTION parameter. When this option is specified, SQL Server checks if the data, inserted or updated through the view, conforms to criteria set in the view select statement. It guarantees that the rows will be visible through the view after the transaction is committed. For example, look at the table and view defined in Listing 9-21.
Listing 9-21. CHECK OPTION: Table and View creation
create table dbo.Numbers(Number int)
go
create view dbo.PositiveNumbers(Number)
as
select Number
from dbo.Numbers
where Number > 0
with check option
go
Either of the statements shown in Listing 9-22 would fail because they violate the criteria Number > 0 specified in the view select.
Listing 9-22. CHECK OPTION: Insert statements
insert into dbo.PositiveNumbers(Number) values(-1)
update dbo.PositiveNumbers set Number = -1 where Number = 1
You should consider creating the view with CHECK OPTION when it is used to prevent access to a subset of the data and client applications update the data through the view. Client applications would not be able to modify the data outside of the allowed scope.
Summary
Views are a powerful and useful tool that can help in several different situations. Regular views can provide a layer of abstraction from both the security and implementation standpoints. Indexed views can help with system optimization, and they reduce the number of joins and aggregations that need to be performed.
As with other SQL Server objects, they come at a cost. Regular views can negatively affect performance by introducing unnecessary joins. Indexed views introduce overhead during data modifications, and you need to maintain their indexes in a manner similar to those defined on regular tables. You need to keep these factors in mind when designing the views in systems.
Views are generally better suited to read data. Updating data through views is a questionable practice. Using INSERT OF triggers is usually slower than directly updating the underlying tables. Without triggers, there are restrictions that you have to follow to make views updatable. This could lead to side effects and break client applications when you change the implementation of the views.
As with the other database objects, you need to consider pros and cons of views, especially when you design the dedicated data access tier. Another option you have at your disposal is using stored procedures. Even though views are generally simpler to use in client applications, you can add another filter predicate on the client side, for example, without changing anything in the view definition, stored procedures provide more flexibility and control over implementation during the development and optimization stages.
![]() Note We will discuss implementation of the data access tier in greater detail in Chapter 16, “System Design Considerations.”
Note We will discuss implementation of the data access tier in greater detail in Chapter 16, “System Design Considerations.”