
Chapter 2. Anatomy of a Redis web application
- Login cookies
- Shopping cart cookies
- Caching generated web pages
- Caching database rows
- Analyzing web page visits
In the first chapter, I introduced you to what Redis is about and what it’s capable of. In this chapter, I’ll continue on that path, starting to dig into several examples that come up in the context of some types of web applications. Though I’ve simplified the problems quite a bit compared to what happens in the real world, each of these pieces can actually be used with little modification directly in your applications. This chapter is primarily meant as a practical guide to what you can do with Redis, and chapter 3 is more of a command reference.
To start out, let’s look at what we mean by a web application from the high level. Generally, we mean a server or service that responds over the HTTP protocol to requests made by web browsers. Here are the typical steps that a web server goes through to respond to a request:
1. The server parses the request.
2. The request is forwarded to a predefined handler.
3. The handler may make requests to fetch data from a database.
4. With the retrieved data, the handler then renders a template as a response.
5. The handler returns the rendered response, which gets passed back to the client.
This list is a high-level overview of what happens in a typical web server. Web requests in this type of situation are considered to be stateless in that the web servers themselves don’t hold information about past requests, in an attempt to allow for easy replacement of failed servers. Books have been written about how to optimize every step in that process, and this book does similarly. How this book differs is that it explains how to replace some queries against a typical relational database with faster queries against Redis, and how to use Redis with access patterns that would’ve been too costly using a relational database.
Through this chapter, we’ll look at and solve problems that come up in the context of Fake Web Retailer, a fairly large (fake) web store that gets about 100 million hits per day from roughly 5 million unique users who buy more than 100,000 items per day. These numbers are big, but if we can solve big problems easily, then small and medium problems should be even easier. And though these solutions target a large web retailer, all but one of them can be handled by a Redis server with no more than a few gigabytes of memory, and are intended to improve performance of a system responding to requests in real time.
Each of the solutions presented (or some variant of them) has been used to solve real problems in production environments. More specifically, by reducing traditional database load by offloading some processing and storage to Redis, web pages were loaded faster with fewer resources.
Our first problem is to use Redis to help with managing user login sessions.
2.1. Login and cookie caching
Whenever we sign in to services on the internet, such as bank accounts or web mail, these services remember who we are using cookies. Cookies are small pieces of data that websites ask our web browsers to store and resend on every request to that service. For login cookies, there are two common methods of storing login information in cookies: a signed cookie or a token cookie.
Signed cookies typically store the user’s name, maybe their user ID, when they last logged in, and whatever else the service may find useful. Along with this user-specific information, the cookie also includes a signature that allows the server to verify that the information that the browser sent hasn’t been altered (like replacing the login name of one user with another).
Token cookies use a series of random bytes as the data in the cookie. On the server, the token is used as a key to look up the user who owns that token by querying a database of some kind. Over time, old tokens can be deleted to make room for new tokens. Some pros and cons for both signed cookies and token cookies for referencing information are shown in table 2.1.
Table 2.1. Pros and cons of signed cookies and token cookies
|
Cookie type |
Pros |
Cons |
|---|---|---|
| Signed cookie | Everything needed to verify the cookie is in the cookie Additional information can be included and signed easily |
Correctly handling signatures is hard It’s easy to forget to sign and/or verify data, allowing security vulnerabilities |
| Token cookie | Adding information is easy Very small cookie, so mobile and slow clients can send requests faster |
More information to store on the server If using a relational database, cookie loading/storing can be expensive |
For the sake of not needing to implement signed cookies, Fake Web Retailer chose to use a token cookie to reference an entry in a relational database table, which stores user login information. By storing this information in the database, Fake Web Retailer can also store information like how long the user has been browsing, or how many items they’ve looked at, and later analyze that information to try to learn how to better market to its users.
As is expected, people will generally look through many different items before choosing one (or a few) to buy, and recording information about all of the different items seen, when the user last visited a page, and so forth, can result in substantial database writes. In the long term, that data is useful, but even with database tuning, most relational databases are limited to inserting, updating, or deleting roughly 200–2,000 individual rows every second per database server. Though bulk inserts/updates/deletes can be performed faster, a customer will only be updating a small handful of rows for each web page view, so higher-speed bulk insertion doesn’t help here.
At present, due to the relatively large load through the day (averaging roughly 1,200 writes per second, close to 6,000 writes per second at peak), Fake Web Retailer has had to set up 10 relational database servers to deal with the load during peak hours. It’s our job to take the relational databases out of the picture for login cookies and replace them with Redis.
To get started, we’ll use a HASH to store our mapping from login cookie tokens to the user that’s logged in. To check the login, we need to fetch the user based on the token and return it, if it’s available. The following listing shows how we check login cookies.
Listing 2.1. The check_token() function
![]()
Checking the token isn’t very exciting, because all of the interesting stuff happens when we’re updating the token itself. For the visit, we’ll update the login HASH for the user and record the current timestamp for the token in the ZSET of recent users. If the user was viewing an item, we also add the item to the user’s recently viewed ZSET and trim that ZSET if it grows past 25 items. The function that does all of this can be seen next.
Listing 2.2. The update_token() function

And you know what? That’s it. We’ve now recorded when a user with the given session last viewed an item and what item that user most recently looked at. On a server made in the last few years, you can record this information for at least 20,000 item views every second, which is more than three times what we needed to perform against the database. This can be made even faster, which we’ll talk about later. But even for this version, we’ve improved performance by 10–100 times over a typical relational database in this context.
Over time, memory use will grow, and we’ll want to clean out old data. As a way of limiting our data, we’ll only keep the most recent 10 million sessions.[1] For our cleanup, we’ll fetch the size of the ZSET in a loop. If the ZSET is too large, we’ll fetch the oldest items up to 100 at a time (because we’re using timestamps, this is just the first 100 items in the ZSET), remove them from the recent ZSET, delete the login tokens from the login HASH, and delete the relevant viewed ZSETs. If the ZSET isn’t too large, we’ll sleep for one second and try again later. The code for cleaning out old sessions is shown next.
1 Remember that these sorts of limits are meant as examples that you could use in a large-scale production situation. Feel free to reduce these to a much smaller number in your testing and development to see that they work.
Listing 2.3. The clean_sessions() function

How could something so simple scale to handle five million users daily? Let’s check the numbers. If we expect five million unique users per day, then in two days (if we always get new users every day), we’ll run out of space and will need to start deleting tokens. In one day there are 24 × 3600 = 86,400 seconds, so there are 5 million / 86,400 < 58 new sessions every second on average. If we ran our cleanup function every second (as our code implements), we’d clean up just under 60 tokens every second. But this code can actually clean up more than 10,000 tokens per second across a network, and over 60,000 tokens per second locally, which is 150–1,000 times faster than we need.
Where to run cleanup functions
This and other examples in this book will sometimes include cleanup functions like listing 2.3. Depending on the cleanup function, it may be written to be run as a daemon process (like listing 2.3), to be run periodically via a cron job, or even to be run during every execution (section 6.3 actually includes the cleanup operation as part of an “acquire” operation). As a general rule, if the function includes a while not QUIT: line, it’s supposed to be run as a daemon, though it could probably be modified to be run periodically, depending on its purpose.
Python syntax for passing and receiving a variable number of arguments
Inside listing 2.3, you’ll notice that we called three functions with a syntax similar to conn.delete(*vtokens). Basically, we’re passing a sequence of arguments to the underlying function without previously unpacking the arguments. For further details on the semantics of how this works, you can visit the Python language tutorial website by visiting this short url: http://mng.bz/8I7W.
Expiring data in Redis
As you learn more about Redis, you’ll likely discover that some of the solutions we present aren’t the only ways to solve the problem. In this case, we could omit the recent ZSET, store login tokens as plain key-value pairs, and use Redis EXPIRE to set a future date or time to clean out both sessions and our recently viewed ZSETs. But using EXPIRE prevents us from explicitly limiting our session information to 10 million users, and prevents us from performing abandoned shopping cart analysis during session expiration, if necessary in the future.
Those familiar with threaded or concurrent programming may have seen that the preceding cleanup function has a race condition where it’s technically possible for a user to manage to visit the site in the same fraction of a second when we were deleting their information. We’re not going to worry about that here because it’s unlikely, and because it won’t cause a significant change in the data we’re recording (aside from requiring that the user log in again). We’ll talk about guarding against race conditions and about how we can even speed up the deletion operation in chapters 3 and 4.
We’ve reduced how much we’ll be writing to the database by millions of rows every day. This is great, but it’s just the first step toward using Redis in our web application. In the next section, we’ll use Redis for handling another kind of cookie.
2.2. Shopping carts in Redis
One of the first uses of cookies on the web was pioneered by Netscape way back in the mid ’90s, and ultimately resulted in the login session cookies we just talked about. Originally, cookies were intended to offer a way for a web retailer to keep a sort of shopping cart for the user, in order to track what items they wanted to buy. Prior to cookies, there were a few different solutions for keeping track of shopping carts, but none were particularly easy to use.
The use of shopping cart cookies is common, as is the storage of the entire cart itself in the cookie. One huge advantage to storing shopping carts in cookies is that you don’t need to write to a database to keep them. But one of the disadvantages is that you also need to keep reparsing and validating the cookie to ensure that it has the proper format and contains items that can actually be purchased. Yet another disadvantage is that cookies are passed with every request, which can slow down request sending and processing for large cookies.
Because we’ve had such good luck with session cookies and recently viewed items, we’ll push our shopping cart information into Redis. Since we’re already keeping user session cookies in Redis (along with recently viewed items), we can use the same cookie ID for referencing the shopping cart.
The shopping cart that we’ll use is simple: it’s a HASH that maps an item ID to the quantity of that item that the customer would like to purchase. We’ll have the web application handle validation for item count, so we only need to update counts in the cart as they change. If the user wants more than 0 items, we add the item(s) to the HASH (replacing an earlier count if it existed). If not, we remove the entry from the hash. Our add_to_cart() function can be seen in this listing.
Listing 2.4. The add_to_cart() function

While we’re at it, we’ll update our session cleanup function to include deleting old shopping carts as clean_full_sessions() in the next listing.
Listing 2.5. The clean_full_sessions() function
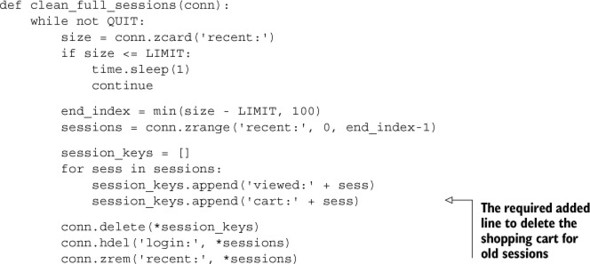
We now have both sessions and the shopping cart stored in Redis, which helps to reduce request size, as well as allows the performing of statistical calculations on visitors to our site based on what items they looked at, what items ended up in their shopping carts, and what items they finally purchased. All of this lets us build (if we want to) features similar to many other large web retailers: “People who looked at this item ended up buying this item X% of the time,” and “People who bought this item also bought these other items.” This can help people to find other related items, which is ultimately good for business.
With both session and shopping cart cookies in Redis, we now have two major pieces for performing useful data analysis. Continuing on, let’s look at how we can further reduce our database and web front-end load with caching.
2.3. Web page caching
When producing web pages dynamically, it’s common to use a templating language to simplify page generation. Gone are the days when each page would be written by hand. Modern web pages are generated from page templates with headers, footers, side menus, toolbars, content areas, and maybe even generated JavaScript.
Despite being capable of dynamically generating content, the majority of pages that are served on Fake Web Retailer’s website don’t change much on a regular basis. Sure, some new items are added to the catalog, old items are removed, sometimes there are specials, and sometimes there are even “hot items” pages. But really, only a handful of account settings, past orders, shopping cart/checkout, and similar pages have content that needs to be generated on every page load.
By looking at their view numbers, Fake Web Retailer has determined that 95% of the web pages that they serve change at most once per day, and don’t actually require content to be dynamically generated. It’s our job to stop generating 95% of pages for every load. By reducing the amount of time we spend generating static content, we can reduce the number of servers necessary to handle the same load, and we can serve our site faster. (Research has shown that reducing the time users spend waiting for pages to load increases their desire to use a site and improves how they rate the site.)
All of the standard Python application frameworks offer the ability to add layers that can pre- or post-process requests as they’re handled. These layers are typically called middleware or plugins. Let’s create one of these layers that calls out to our Redis caching function. If a web request can’t be cached, we’ll generate the page and return the content. If a request can be cached, we’ll try to fetch and return the page from the cache; otherwise we’ll generate the page, cache the result in Redis for up to 5 minutes, and return the content. Our simple caching method can be seen in the next listing.
Listing 2.6. The cache_request() function
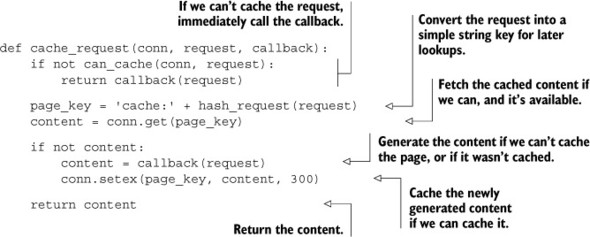
For that 95% of content that could be cached and is loaded often, this bit of code removes the need to dynamically generate viewed pages for 5 minutes. Depending on the complexity of content, this one change could reduce the latency for a data-heavy page from maybe 20–50ms, down to one round trip to Redis (under 1ms for a local connection, under 5ms for computers close to each other in the same data center). For pages that used to hit the database for data, this can further reduce page load time and database load.
Now that we’ve cut loading time for pages that don’t change often, can we keep using Redis to cut loading time for pages that do change often? Of course we can! Keep reading to find out how.
2.4. Database row caching
In this chapter so far, we’ve moved login and visitor sessions from our relational database and web browser to Redis, we’ve taken shopping carts out of the relational database and put them into Redis, and we’ve cached entire pages in Redis. This has helped us improve performance and reduce the load on our relational database, which has also lowered our costs.
Individual product pages that we’re displaying to a user typically only load one or two rows from the database: the user information for the user who’s logged in (with our generated pages, we can load that with an AJAX call to keep using our cache), and the information about the item itself. Even for pages where we may not want to cache the whole page (customer account pages, a given user’s past orders, and so on), we could instead cache the individual rows from our relational database.
As an example of where caching rows like this would be useful, let’s say that Fake Web Retailer has decided to start a new promotion to both clean out some older inventory and get people coming back to spend money. To make this happen, we’ll start performing daily deal sales for certain items until they run out. In the case of a deal, we can’t cache the full page, because then someone might see a version of the page with an incorrect count of items remaining. And though we could keep reading the item’s row from the database, that could push our database to become over-utilized, which would then increase our costs because we’d need to scale our databases up again.
To cache database rows in preparation for a heavy load, we’ll write a daemon function that will run continuously, whose purpose will be to cache specific database rows in Redis, updating them on a variable schedule. The rows themselves will be JSON-encoded dictionaries stored as a plain Redis value. We’ll map column names and row values to the dictionary keys and values. An example row can be seen in figure 2.1.
Figure 2.1. A cached database row for an item to be sold online
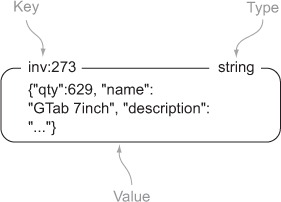
In order to know when to update the cache, we’ll use two ZSETs. Our first ZSET, the scheduleZSET, will use the row ID from the original database row as the member of the ZSET. We’ll use a timestamp for our schedule scores, which will tell us when the row should be copied to Redis next. Our second ZSET, the delayZSET, will use the same row ID for the members, but the score will be how many seconds to wait between cache updates.
Using JSON instead of other formats
Our use of JSON instead of XML, Google’s protocol buffers, Thrift, BSON, MessagePack, or other serialization formats is a subjective one. We generally use JSON because it’s human readable, somewhat concise, and it has fast encoding and decoding libraries available in every language with an existing Redis client (as far as we know). If your situation requires the use of another format, or if you’d prefer to use a different format, then feel free to do so.
Nested structures
One feature that users of other non-relational databases sometime expect is the ability to nest structures. Specifically, some new users of Redis expect that a HASH should be able to have a value that’s a ZSET or LIST. Though conceptually this is fine, there’s a question that comes up early in such a discussion that boils down to a simple example, “How do I increment a value in a HASH that’s nested five levels deep?” As a matter of keeping the syntax of commands simple, Redis doesn’t allow nested structures. If necessary, you can use key names for this (user:123 could be a HASH and user:123:posts could be a ZSET of recent posts from that user). Or you can explicitly store your nested structures using JSON or some other serialization library of your choice (Lua scripting, covered in chapter 11, supports server-side manipulation of JSON and MessagePack encoded data).
In order for rows to be cached on a regular basis by the caching function, we’ll first add the row ID to our delay ZSET with the given delay. This is because our actual caching function will require the delay, and if it’s missing, will remove the scheduled item. When the row ID is in the delay ZSET, we’ll then add the row ID to our schedule ZSET with the current timestamp. If we want to stop a row from being synced to Redis and remove it from the cache, we can set the delay to be less than or equal to 0, and our caching function will handle it. Our function to schedule or stop caching can be seen in the following listing.
Listing 2.7. The schedule_row_cache() function

Now that we have the scheduling part done, how do we cache the rows? We’ll pull the first item from the schedule ZSET with its score. If there are no items, or if the timestamp returned is in the future, we’ll wait 50 milliseconds and try again. When we have an item that should be updated now, we’ll check the row’s delay. If the delay for the next caching time is less than or equal to 0, we’ll remove the row ID from the delay and schedule ZSETs, as well as delete the cached row and try again. Finally, for any row that should be cached, we’ll update the row’s schedule, pull the row from the database, and save a JSON-encoded version of the row to Redis. Our function for doing this can be seen in this listing.
Listing 2.8. The cache_rows() daemon function

With the combination of a scheduling function and a continuously running caching function, we’ve added a repeating scheduled autocaching mechanism. With these two functions, inventory rows can be updated as frequently as we think is reasonable. For a daily deal with inventory counts being reduced and affecting whether someone can buy the item, it probably makes sense to update the cached row every few seconds if there are many buyers. But if the data doesn’t change often, or when back-ordered items are acceptable, it may make sense to only update the cache every minute. Both are possible with this simple method.
Now that we’re caching individual rows in Redis, could it be possible to further reduce our memory load by caching only some of our pages?
2.5. Web page analytics
As people come to the websites that we build, interact with them, maybe even purchase something from them, we can learn valuable information. For example, if we only pay attention to pages that get the most views, we can try to change the way the pages are formatted, what colors are being used, maybe even change what other links are shown on the pages. Each one of these changes can lead to a better or worse experience on a page or subsequent pages, or even affect buying behavior.
In sections 2.1 and 2.2, we talked about gathering information about items that a user has looked at or added to their cart. In section 2.3, we talked about caching generated web pages in order to reduce page load times and improve responsiveness. Unfortunately, we went overboard with our caching for Fake Web Retailer; we cached every one of the 100,000 available product pages, and now we’re running out of memory. After some work, we’ve determined that we can only reasonably hold about 10,000 pages in the cache.
If you remember from section 2.1, we kept a reference to every item that was visited. Though we can use that information directly to help us decide what pages to cache, actually calculating that could take a long time to get good numbers. Instead, let’s add one line to the update_token() function from listing 2.2, which we see next.
Listing 2.9. The updated update_token() function

With this one line added, we now have a record of all of the items that are viewed. Even more useful, that list of items is ordered by the number of times that people have seen the items, with the most-viewed item having the lowest score, and thus having an index of 0. Over time, some items will be seen many times and others rarely. Obviously we only want to cache commonly seen items, but we also want to be able to discover new items that are becoming popular, so we know when to cache them.
To keep our top list of pages fresh, we need to trim our list of viewed items, while at the same time adjusting the score to allow new items to become popular. You already know how to remove items from the ZSET from section 2.1, but rescaling is new. ZSETs have a function called ZINTERSTORE, which lets us combine one or more ZSETs and multiply every score in the input ZSETs by a given number. (Each input ZSET can be multiplied by a different number.) Every 5 minutes, let’s go ahead and delete any item that isn’t in the top 20,000 items, and rescale the view counts to be half has much as they were before. The following listing will both delete items and rescale remaining scores.
Listing 2.10. The rescale_viewed() daemon function

With the rescaling and the counting, we now have a constantly updated list of the most-frequently viewed items at Fake Web Retailer. Now all we need to do is to update our can_cache() function to take into consideration our new method of deciding whether a page can be cached, and we’re done. You can see our new can_cache() function here.
Listing 2.11. The can_cache() function

And with that final piece, we’re now able to take our actual viewing statistics and only cache those pages that are in the top 10,000 product pages. If we wanted to store even more pages with minimal effort, we could compress the pages before storing them in Redis, use a technology called edge side includes to remove parts of our pages, or we could pre-optimize our templates to get rid of unnecessary whitespace. Each of these techniques and more can reduce memory use and increase how many pages we could store in Redis, all for additional performance improvements as our site grows.
2.6. Summary
In this chapter, we’ve covered a few methods for reducing database and web server load for Fake Web Retailer. The ideas and methods used in these examples are currently in use in real web applications today.
If there’s one thing that you should take away from this chapter, it’s that as you’re building new pieces that fit within your application, you shouldn’t be afraid to revisit and update old components that you’ve already written. Sometimes you may find that your earlier solutions got you a few steps toward what you need now (as was the case with both shopping cart cookies and web analytics combined with our initial login session cookies code). As we continue through this book, we’ll keep introducing new topics, and we’ll occasionally revisit them later to improve performance or functionality, or to reuse ideas we already understand.
Now that you’ve gotten a taste for what Redis can do as part of a real application, the next chapter will go over a wider variety of commands available in Redis. After you learn more about each structure and what can be done with them, you’ll be ready to build even more useful components for other layers of your application or stack of services. So what are you waiting for? Keep reading!