
Chapter 1. Getting to know Redis
This chapter covers
- How Redis is like and unlike other software you’ve used
- How to use Redis
- Simple interactions with Redis using example Python code
- Solving real problems with Redis
Redis is an in-memory remote database that offers high performance, replication, and a unique data model to produce a platform for solving problems. By supporting five different types of data structures, Redis accommodates a wide variety of problems that can be naturally mapped into what Redis offers, allowing you to solve your problems without having to perform the conceptual gymnastics required by other databases. Additional features like replication, persistence, and client-side sharding allow Redis to scale from a convenient way to prototype a system, all the way up to hundreds of gigabytes of data and millions of requests per second.
My first experience with Redis was at a company that needed to search a database of client contacts. The search needed to find contacts by name, email address, location, and phone number. The system was written to use a SQL database that performed a series of queries that would take 10–15 seconds to find matches among 60,000 clients. After spending a week learning the basics of what was available in Redis, I built a search engine that could filter and sort on all of those fields and more, returning responses within 50 milliseconds. In just a few weeks of effort involving testing and making the system production-worthy, performance improved 200 times. By reading this book, you can learn about many of the tips, tricks, and well-known problems that have been solved using Redis.
This chapter will help you to understand where Redis fits within the world of databases, and how Redis is useful for solving problems in multiple contexts (communicating between different components and languages, and more). Remaining chapters will show a variety of problems and their solutions using Redis.
Now that you know a bit about how I started using Redis and what we’ll cover, let’s talk more about what Redis is, and how it’s probably something you’ve always needed, even though you didn’t realize it.
Installing redis and python
Look in appendix A for quick and dirty installation instructions for both Redis and Python.
Using redis from other languages
Though not included in this book, source code for all examples possible will be provided in Ruby, Java, and JavaScript (Node.js) shortly after all chapters have been completed. For users of the Spring framework, the author of Spring Data’s Redis interface, Costin Leau, has teamed up with Redis author Salvatore Sanfilippo to produce a one-hour introduction for using Spring with Redis available at http://www.springsource.org/spring-data/redis.
1.1. What is Redis?
When I say that Redis is a database, I’m only telling a partial truth. Redis is a very fast non-relational database that stores a mapping of keys to five different types of values. Redis supports in-memory persistent storage on disk, replication to scale read performance, and client-side sharding[1] to scale write performance. That was a mouthful, but I’ll break it down by parts.
1 Sharding is a method by which you partition your data into different pieces. In this case, you partition your data based on IDs embedded in the keys, based on the hash of keys, or some combination of the two. Through partitioning your data, you can store and fetch the data from multiple machines, which can allow a linear scaling in performance for certain problem domains.
1.1.1. Redis compared to other databases and software
If you’re familiar with relational databases, you’ll no doubt have written SQL queries to relate data between tables. Redis is a type of database that’s commonly referred to as NoSQL or non-relational. In Redis, there are no tables, and there’s no databasedefined or -enforced way of relating data in Redis with other data in Redis.
It’s not uncommon to hear Redis compared to memcached, which is a very high-performance, key-value cache server. Like memcached, Redis can also store a mapping of keys to values and can even achieve similar performance levels as memcached. But the similarities end quickly—Redis supports the writing of its data to disk automatically in two different ways, and can store data in four structures in addition to plain string keys as memcached does. These and other differences allow Redis to solve a wider range of problems, and allow Redis to be used either as a primary database or as an auxiliary database with other storage systems.
In later chapters, we’ll cover examples that show Redis being used for both a primary and a secondary storage medium for data, supporting a variety of use cases and query patterns. Generally speaking, many Redis users will choose to store data in Redis only when the performance or functionality of Redis is necessary, using other relational or non-relational data storage for data where slower performance is acceptable, or where data is too large to fit in memory economically. In practice, you’ll use your judgment as to where you want your data to be stored (primarily in Redis, or primarily somewhere else with a copy in Redis), how to ensure data integrity (replication, durability, and transactions), and whether Redis will fit your needs.
To get an idea of how Redis fits among the variety of database and cache software available, you can see an incomplete listing of a few different types of cache or database servers that Redis’s functionality overlaps in table 1.1.
Table 1.1. Features and functionality of some databases and cache servers
|
Name |
Type |
Data storage options |
Query types |
Additional features |
|---|---|---|---|---|
| Redis | In-memory non-relational database | Strings, lists, sets, hashes, sorted sets | Commands for each data type for common access patterns, with bulk operations, and partial transaction support | Publish/Subscribe, master/slave replication, disk persistence, scripting (stored procedures) |
| memcached | In-memory key-value cache | Mapping of keys to values | Commands for create, read, update, delete, and a few others | Multithreaded server for additional performance |
| MySQL | Relational database | Databases of tables of rows, views over tables, spatial and third-party extensions | SELECT, INSERT, UPDATE, DELETE, functions, stored procedures | ACID compliant (with InnoDB), master/slave and master/master replication |
| PostgreSQL | Relational database | Databases of tables of rows, views over tables, spatial and third-party extensions, customizable types | SELECT, INSERT, UPDATE, DELETE, built-in functions, custom stored procedures | ACID compliant, master/slave replication, multi-master replication (third party) |
| MongoDB | On-disk non-relational document store | Databases of tables of schema-less BSON documents | Commands for create, read, update, delete, conditional queries, and more | Supports map-reduce operations, master/slave replication, sharding, spatial indexes |
1.1.2. Other features
When using an in-memory database like Redis, one of the first questions that’s asked is “What happens when my server gets turned off?” Redis has two different forms of persistence available for writing in-memory data to disk in a compact format. The first method is a point-in-time dump either when certain conditions are met (a number of writes in a given period) or when one of the two dump-to-disk commands is called. The other method uses an append-only file that writes every command that alters data in Redis to disk as it happens. Depending on how careful you want to be with your data, append-only writing can be configured to never sync, sync once per second, or sync at the completion of every operation. We’ll discuss these persistence options in more depth in chapter 4.
Even though Redis is able to perform well, due to its in-memory design there are situations where you may need Redis to process more read queries than a single Redis server can handle. To support higher rates of read performance (along with handling failover if the server that Redis is running on crashes), Redis supports master/slave replication where slaves connect to the master and receive an initial copy of the full database. As writes are performed on the master, they’re sent to all connected slaves for updating the slave datasets in real time. With continuously updated data on the slaves, clients can then connect to any slave for reads instead of making requests to the master. We’ll discuss Redis slaves more thoroughly in chapter 4.
1.1.3. Why Redis?
If you’ve used memcached before, you probably know that you can add data to the end of an existing string with APPEND. The documentation for memcached states that APPEND can be used for managing lists of items. Great! You add items to the end of the string you’re treating as a list. But then how do you remove items? The memcached answer is to use a blacklist to hide items, in order to avoid read/update/write (or a database query and memcached write). In Redis, you’d either use a LIST or a SET and then add and remove items directly.
By using Redis instead of memcached for this and other problems, not only can your code be shorter, easier to understand, and easier to maintain, but it’s faster (because you don’t need to read a database to update your data). You’ll see that there are also many other cases where Redis is more efficient and/or easier to use than relational databases.
One common use of databases is to store long-term reporting data as aggregates over fixed time ranges. To collect these aggregates, it’s not uncommon to insert rows into a reporting table and then later to scan over those rows to collect the aggregates, which then update existing rows in an aggregation table. Rows are inserted because, for most databases, inserting rows is a very fast operation (inserts write to the end of an on-disk file, not unlike Redis’s append-only log). But updating an existing row in a table is fairly slow (it can cause a random read and may cause a random write). In Redis, you’d calculate the aggregates directly using one of the atomic INCR commands—random writes to Redis data are always fast, because data is always in memory,[2] and queries to Redis don’t need to go through a typical query parser/optimizer.
2 To be fair, memcached could also be used in this simple scenario, but with Redis, your aggregates can be placed in structures that keep associated aggregates together for easy access; the aggregates can be a part of a sorted sequence of aggregates for keeping a toplist in real time; and the aggregates can be integer or floating point.
By using Redis instead of a relational or other primarily on-disk database, you can avoid writing unnecessary temporary data, avoid needing to scan over and delete this temporary data, and ultimately improve performance. These are both simple examples, but they demonstrate how your choice of tool can greatly affect the way you solve your problems.
As you continue to read about Redis, try to remember that almost everything that we do is an attempt to solve a problem in real time (except for task queues in chapter 6). I show techniques and provide working code for helping you remove bottlenecks, simplify your code, collect data, distribute data, build utilities, and, overall, to make your task of building software easier. When done right, your software can even scale to levels that would make other users of so-called web-scale technologies blush.
We could keep talking about what Redis has, what it can do, or even why. Or I could show you. In the next section, we’ll discuss the structures available in Redis, what they can do, and some of the commands used to access them.
1.2. What Redis data structures look like
As shown in table 1.1, Redis allows us to store keys that map to any one of five different data structure types; STRINGs, LISTs, SETs, HASHes, and ZSETs. Each of the five different structures have some shared commands (DEL, TYPE, RENAME, and others), as well as some commands that can only be used by one or two of the structures. We’ll dig more deeply into the available commands in chapter 3.
Among the five structures available in Redis, STRINGs, LISTs, and HASHes should be familiar to most programmers. Their implementation and semantics are similar to those same structures built in a variety of other languages. Some programming languages also have a set data structure, comparable to Redis SETs in implementation and semantics. ZSETs are somewhat unique to Redis, but are handy when we get around to using them. A comparison of the five structures available in Redis, what they contain, and a brief description of their semantics can be seen in table 1.2.
Table 1.2. The five structures available in Redis
|
Structure type |
What it contains |
Structure read/write ability |
|---|---|---|
| STRING | Strings, integers, or floating-point values | Operate on the whole string, parts, increment/decrement the integers and floats |
| LIST | Linked list of strings | Push or pop items from both ends, trim based on offsets, read individual or multiple items, find or remove items by value |
| SET | Unordered collection of unique strings | Add, fetch, or remove individual items, check membership, intersect, union, difference, fetch random items |
| HASH | Unordered hash table of keys to values | Add, fetch, or remove individual items, fetch the whole hash |
| ZSET (sorted set) | Ordered mapping of string members to floating-point scores, ordered by score | Add, fetch, or remove individual values, fetch items based on score ranges or member value |
Command listing
As we discuss each data type in this section, you’ll find small tables of commands. A more complete (but partial) listing of commands for each type can be found in chapter 3. If you need a complete command listing with documentation, you can visit http://redis.io/commands.
Throughout this section, you’ll see how to represent all five of these structures, and you’ll get a chance to start using Redis commands in preparation for later chapters. In this book, all of the examples are provided in Python. If you’ve installed Redis as described in appendix A, you should also have installed Python and the necessary libraries to use Redis from Python as part of that process. If possible, you should have a computer with Redis, Python, and the redis-py library installed so that you can try everything out while reading.
Reminder About Installing Redis and Python
Before you continue, you’ll want to install Redis and Python. Again, quick and dirty installation instructions for both Redis and Python can be found in appendix A. Even quicker and dirtier instructions for Debian-based Linux distributions are as follows: download Redis from http://redis.io/download, extract, run make && sudo make install, and then run sudo python -m easy_install redis hiredis (hiredis is an optional performance-improving C library).
If you’re familiar with procedural or object-oriented programming languages, Python should be understandable, even if you haven’t used it before. If you’re using another language with Redis, you should be able to translate everything we’re doing with Python to your language, though method names for Redis commands and the arguments they take may be spelled (or ordered) differently.
Redis with Other Languages
Though not included in this book, all code listings that can be converted have translations to Ruby, JavaScript, and Java available for download from the Manning website or linked from this book’s Manning forum. This translated code also includes similar descriptive annotations so that you can follow along in your language of choice.
As a matter of style, I attempt to keep the use of more advanced features of Python to a minimum, writing functions to perform operations against Redis instead of constructing classes or otherwise. I do this to keep the syntax of Python from interfering with the focal point of this book, which is solving problems with Redis, and not “look at this cool stuff we can do with Python.” For this section, we’ll use a redis-cli console to interact with Redis. Let’s get started with the first and simplest structure available in Redis: STRINGs.
1.2.1. Strings in Redis
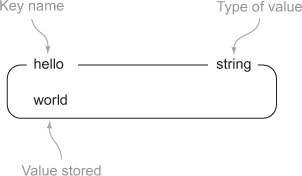
In Redis, STRINGs are similar to strings that we see in other languages or other key-value stores. Generally, when I show diagrams that represent keys and values, the diagrams have the key name and the type of the value along the top of a box, with the value inside the box. I’ve labeled which part is which as an example in figure 1.1, which shows a STRING with key hello and value world.
Figure 1.1. An example of a STRING, world, stored under a key, hello
The operations available to STRINGs start with what’s available in other key-value stores. We can GET values, SET values, and DEL values. After you have installed and tested Redis as described in appendix A, within redis-cli you can try to SET, GET, and DEL values in Redis, as shown in listing 1.1, with the basic meanings of the functions described in table 1.3.
Table 1.3. Commands used on STRING values
|
Command |
What it does |
|---|---|
| GET | Fetches the data stored at the given key |
| SET | Sets the value stored at the given key |
| DEL | Deletes the value stored at the given key (works for all types) |
Listing 1.1. An example showing the SET, GET, and DEL commands in Redis
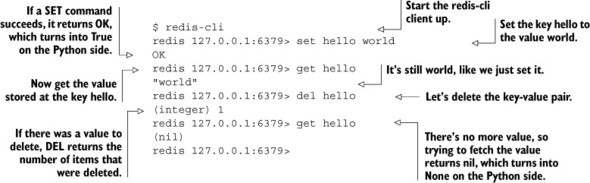
Using redis-cli
In this first chapter, I introduce Redis and some commands using the redis-cli interactive client that comes with Redis. This allows you to get started interacting with Redis quickly and easily.
In addition to being able to GET, SET, and DEL STRING values, there are a handful of other commands for reading and writing parts of STRINGs, and commands that allow us to treat strings as numbers to increment/decrement them. We’ll talk about many of those commands in chapter 3. But we still have a lot of ground to cover, so let’s move on to take a peek at LISTs and what we can do with them.
1.2.2. Lists in Redis
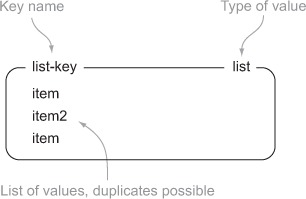
In the world of key-value stores, Redis is unique in that it supports a linked-list structure. LISTs in Redis store an ordered sequence of strings, and like STRINGs, I represent figures of LISTs as a labeled box with list items inside. An example of a LIST can be seen in figure 1.2.
Figure 1.2. An example of a LIST with three items under the key, list-key. Note that item can be in the list more than once.
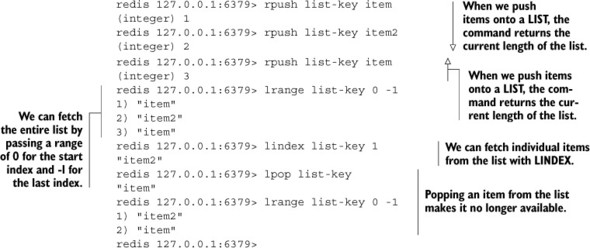
The operations that can be performed on LISTs are typical of what we find in almost any programming language. We can push items to the front and the back of the LIST with LPUSH/RPUSH; we can pop items from the front and back of the list with LPOP/RPOP; we can fetch an item at a given position with LINDEX; and we can fetch a range of items with LRANGE. Let’s continue our Redis client interactions by following along with interactions on LISTs, as shown in listing 1.2. Table 1.4 gives a brief description of the commands we can use on lists.
Table 1.4. Commands used on LIST values
|
Command |
What it does |
|---|---|
| RPUSH | Pushes the value onto the right end of the list |
| LRANGE | Fetches a range of values from the list |
| LINDEX | Fetches an item at a given position in the list |
| LPOP | Pops the value from the left end of the list and returns it |
Listing 1.2. The RPUSH, LRANGE, LINDEX, and LPOP commands in Redis
Even if that was all that we could do with LISTs, Redis would already be a useful platform for solving a variety of problems. But we can also remove items, insert items in the middle, trim the list to be a particular size (discarding items from one or both ends), and more. We’ll talk about many of those commands in chapter 3, but for now let’s keep going to see what SETs can offer us.
1.2.3. Sets in Redis
In Redis, SETs are similar to LISTs in that they’re a sequence of strings, but unlike LISTs, Redis SETs use a hash table to keep all strings unique (though there are no associated values). My visual representation of SETs will be similar to LISTs, and figure 1.3 shows an example SET with three items.
Figure 1.3. An example of a SET with three items under the key, set-key
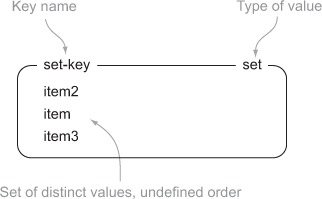
Because Redis SETs are unordered, we can’t push and pop items from the ends like we did with LISTs. Instead, we add and remove items by value with the SADD and SREM commands. We can also find out whether an item is in the SET quickly with SISMEMBER, or fetch the entire set with SMEMBERS (this can be slow for large SETs, so be careful). You can follow along with listing 1.3 in your Redis client console to get a feel for how SETs work, and table 1.5 describes the commands used here.
Table 1.5. Commands used on SET values
|
Command |
What it does |
|---|---|
| SADD | Adds the item to the set |
| SMEMBERS | Returns the entire set of items |
| SISMEMBER | Checks if an item is in the set |
| SREM | Removes the item from the set, if it exists |
Listing 1.3. The SADD, SMEMBERS, SISMEMBER, and SREM commands in Redis

As you can probably guess based on the STRING and LIST sections, SETs have many other uses beyond adding and removing items. Three commonly used operations with SETs include intersection, union, and difference (SINTER, SUNION, and SDIFF, respectively). We’ll get into more detail about SET commands in chapter 3, and over half of chapter 7 involves problems that can be solved almost entirely with Redis SETs. But let’s not get ahead of ourselves; we’ve still got two more structures to go. Keep reading to learn about Redis HASHes.
1.2.4. Hashes in Redis
Whereas LISTs and SETs in Redis hold sequences of items, Redis HASHes store a mapping of keys to values. The values that can be stored in HASHes are the same as what can be stored as normal STRINGs: strings themselves, or if a value can be interpreted as a number, that value can be incremented or decremented. Figure 1.4 shows a diagram of a hash with two values.
Figure 1.4. An example of a HASH with two keys/values under the key hash-key
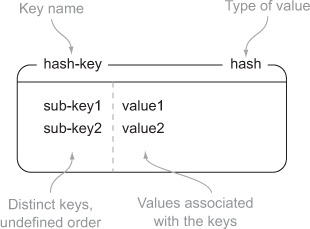
In a lot of ways, we can think of HASHes in Redis as miniature versions of Redis itself. Some of the same commands that we can perform on STRINGs, we can perform on the values inside HASHes with slightly different commands. Try to follow listing 1.4 to see some commands that we can use to insert, fetch, and remove items from HASHes. Table 1.6 describes the commands.
Table 1.6. Commands used on HASH values
|
Command |
What it does |
|---|---|
| HSET | Stores the value at the key in the hash |
| HGET | Fetches the value at the given hash key |
| HGETALL | Fetches the entire hash |
| HDEL | Removes a key from the hash, if it exists |
Listing 1.4. The HSET, HGET, HGETALL, and HDEL commands in Redis

For those who are familiar with document stores or relational databases, we can consider a Redis HASH as being similar to a document in a document store, or a row in a relational database, in that we can access or change individual or multiple fields at a time. We’re now one structure from having seen all of the structures available in Redis. Keep reading to learn what ZSETs are and a few things that we can do with them.
1.2.5. Sorted sets in Redis
Like Redis HASHes, ZSETs also hold a type of key and value. The keys (called members) are unique, and the values (called scores) are limited to floating-point numbers. ZSETs have the unique property in Redis of being able to be accessed by member (like a HASH), but items can also be accessed by the sorted order and values of the scores. Figure 1.5 shows an example ZSET with two items.
Figure 1.5. An example of a ZSET with two members/scores under the key zset-key
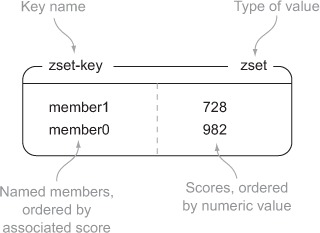
As is the case with all of the other structures, we need to be able to add, remove, and fetch items from ZSETs. Listing 1.5 offers add, remove, and fetching commands for ZSETs similar to those for the other structures, and table 1.7 describes the commands that we’ll use.
Table 1.7. Commands used on ZSET values
|
Command |
What it does |
|---|---|
| ZADD | Adds member with the given score to the ZSET |
| ZRANGE | Fetches the items in the ZSET from their positions in sorted order |
| ZRANGEBYSCORE | Fetches items in the ZSET based on a range of scores |
| ZREM | Removes the item from the ZSET, if it exists |
Listing 1.5. The ZADD, ZRANGE, ZRANGEBYSCORE, and ZREM commands in Redis

Now that you’ve seen ZSETs and a little of what they can do, you’ve learned the basics of what structures are available in Redis. In the next section, we’ll combine the data storage ability of HASHes with the built-in sorting ability of ZSETs to solve a common problem.
1.3. Hello Redis
Now that you’re more familiar with the structures that Redis offers, it’s time to use Redis on a real problem. In recent years, a growing number of sites have offered the ability to vote on web page links, articles, or questions, including sites such as reddit and Stack Overflow, as shown in figures 1.6 and 1.7. By taking into consideration the votes that were cast, posts are ranked and displayed based on a score relating those votes and when the link was submitted. In this section, we’ll build a Redis-based back end for a simple version of this kind of site.
Figure 1.6. Reddit, a site that offers the ability to vote on articles
Figure 1.7. Stack Overflow, a site that offers the ability to vote on questions
1.3.1. Voting on articles
First, let’s start with some numbers and limitations on our problem, so we can solve the problem without losing sight of what we’re trying to do. Let’s say that 1,000 articles are submitted each day. Of those 1,000 articles, about 50 of them are interesting enough that we want them to be in the top-100 articles for at least one day. All of those 50 articles will receive at least 200 up votes. We won’t worry about down votes for this version.
When dealing with scores that go down over time, we need to make the posting time, the current time, or both relevant to the overall score. To keep things simple, we’ll say that the score of an item is a function of the time that the article was posted, plus a constant multiplier times the number of votes that the article has received.
The time we’ll use the number of seconds since January 1, 1970, in the UTC time zone, which is commonly referred to as Unix time. We’ll use Unix time because it can be fetched easily in most programming languages and on every platform that we may use Redis on. For our constant, we’ll take the number of seconds in a day (86,400) divided by the number of votes required (200) to last a full day, which gives us 432 “points” added to the score per vote.
To actually build this, we need to start thinking of structures to use in Redis. For starters, we need to store article information like the title, the link to the article, who posted it, the time it was posted, and the number of votes received. We can use a Redis HASH to store this information, and an example article can be seen in figure 1.8.
Figure 1.8. An example article stored as a HASH for our article voting system

Using the Colon Character as a Separator
Throughout this and other chapters, you’ll find that we use the colon character (:) as a separator between parts of names; for example, in figure 1.8, we used it to separate article from the ID of the article, creating a sort of namespace. The choice of : is subjective, but common among Redis users. Other common choices include a period (.), forward slash (/), and even occasionally the pipe character (|). Regardless of what you choose, be consistent, and note how we use colons to define nested namespaces throughout the examples in the book.
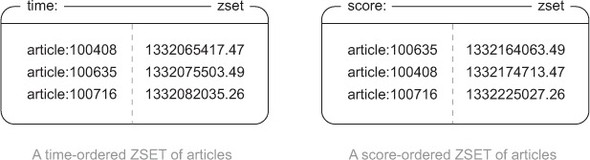
To store a sorted set of articles themselves, we’ll use a ZSET, which keeps items ordered by the item scores. We can use our article ID as the member, with the ZSET score being the article score itself. While we’re at it, we’ll create another ZSET with the score being just the times that the articles were posted, which gives us an option of browsing articles based on article score or time. We can see a small example of time- and score-ordered article ZSETs in figure 1.9.
Figure 1.9. Two sorted sets representing time-ordered and score-ordered article indexes
In order to prevent users from voting for the same article more than once, we need to store a unique listing of users who have voted for each article. For this, we’ll use a SET for each article, and store the member IDs of all users who have voted on the given article. An example SET of users who have voted on an article is shown in figure 1.10.
Figure 1.10. Some users who have voted for article 100408

For the sake of memory use over time, we’ll say that after a week users can no longer vote on an article and its score is fixed. After that week has passed, we’ll delete the SET of users who have voted on the article.
Before we build this, let’s take a look at what would happen if user 115423 were to vote for article 100408 in figure 1.11.
Figure 1.11. What happens to our structures when user 115423 votes for article 100408

Now that you know what we’re going to build, let’s build it! First, let’s handle voting. When someone tries to vote on an article, we first verify that the article was posted within the last week by checking the article’s post time with ZSCORE. If we still have time, we then try to add the user to the article’s voted SET with SADD. Finally, if the user didn’t previously vote on that article, we increment the score of the article by 432 (which we calculated earlier) with ZINCRBY (a command that increments the score of a member), and update the vote count in the HASH with HINCRBY (a command that increments a value in a hash). The voting code is shown in listing 1.6.
Listing 1.6. The article_vote() function

Redis Transactions
In order to be correct, technically our SADD, ZINCRBY, and HINCRBY calls should be in a transaction. But since we don’t cover transactions until chapter 4, we won’t worry about them for now.
Voting isn’t so bad, is it? But what about posting an article?
1.3.2. Posting and fetching articles
To post an article, we first create an article ID by incrementing a counter with INCR. We then create the voted SET by adding the poster’s ID to the SET with SADD. To ensure that the SET is removed after one week, we’ll give it an expiration time with the EXPIRE command, which lets Redis automatically delete it. We then store the article information with HMSET. Finally, we add the initial score and posting time to the relevant ZSETs with ZADD. We can see the code for posting an article in listing 1.7.
Listing 1.7. The post_article() function

Okay, so we can vote, and we can post articles. But what about fetching the current top-scoring or most recent articles? For that, we can use ZRANGE to fetch the article IDs, and then we can make calls to HGETALL to fetch information about each article. The only tricky part is that we must remember that ZSETs are sorted in ascending order by their score. But we can fetch items based on the reverse order with ZREVRANGEBYSCORE. The function to fetch a page of articles is shown in listing 1.8.
Listing 1.8. The get_articles() function

Default arguments and keyword arguments
Inside listing 1.8, we used an argument named order, and we gave it a default value of score:. Some of the details of default arguments and passing arguments as names (instead of by position) can be strange to newcomers to the Python language. If you’re having difficulty understanding what’s going on with function definition or argument passing, the Python language tutorial offers a good introduction to what’s going on, and you can jump right to the particular section by visiting this shortened URL: http://mng.bz/KM5x.
We can now get the top-scoring articles across the entire site. But many of these article voting sites have groups that only deal with articles of a particular topic like cute animals, politics, programming in Java, and even the use of Redis. How could we add or alter our code to offer these topical groups?
1.3.3. Grouping articles
To offer groups requires two steps. The first step is to add information about which articles are in which groups, and the second is to actually fetch articles from a group. We’ll use a SET for each group, which stores the article IDs of all articles in that group. In listing 1.9, we see a function that allows us to add and remove articles from groups.
Listing 1.9. The add_remove_groups() function

At first glance, these SETs with article information may not seem that useful. So far, you’ve only seen the ability to check whether a SET has an item. But Redis has the capability to perform operations involving multiple SETs, and in some cases, Redis can perform operations between SETs and ZSETs.
When we’re browsing a specific group, we want to be able to see the scores of all of the articles in that group. Or, really, we want them to be in a ZSET so that we can have the scores already sorted and ready for paging over. Redis has a command called ZINTERSTORE, which, when provided with SETs and ZSETs, will find those entries that are in all of the SETs and ZSETs, combining their scores in a few different ways (items in SETs are considered to have scores equal to 1). In our case, we want the maximum score from each item (which will be either the article score or when the article was posted, depending on the sorting option chosen).
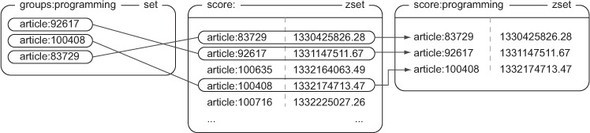
To visualize what is going on, let’s look at figure 1.12. This figure shows an example ZINTERSTORE operation on a small group of articles stored as a SET with the much larger (but not completely shown) ZSET of scored articles. Notice how only those articles that are in both the SET and the ZSET make it into the result ZSET?
Figure 1.12. The newly created ZSET, score:programming, is an intersection of the SET and ZSET. Intersection will only keep members from SETs/ZSETs when the members exist in all of the input SETs/ ZSETs. When intersecting SETs and ZSETs, SETs act as though they have a score of 1, so when intersecting with an aggregate of MAX, we’re only using the scores from the score: input ZSET, because they’re all greater than 1.
To calculate the scores of all of the items in a group, we only need to make a ZINTERSTORE call with the group and the scored or recent ZSETs. Because a group may be large, it may take some time to calculate, so we’ll keep the ZSET around for 60 seconds to reduce the amount of work that Redis is doing. If we’re careful (and we are), we can even use our existing get_articles() function to handle pagination and article data fetching so we don’t need to rewrite it. We can see the function for fetching a page of articles from a group in listing 1.10.
Listing 1.10. The get_group_articles() function

On some sites, articles are typically only in one or two groups at most (“all articles” and whatever group best matches the article). In that situation, it would make more sense to keep the group that the article is in as part of the article’s HASH, and add one more ZINCRBY call to the end of our article_vote() function. But in our case, we chose to allow articles to be a part of multiple groups at the same time (maybe a picture can be both cute and funny), so to update scores for articles in multiple groups, we’d need to increment all of those groups at the same time. For an article in many groups, that could be expensive, so we instead occasionally perform an intersection. How we choose to offer flexibility or limitations can change how we store and update our data in any database, and Redis is no exception.
In our example, we only counted people who voted positively for an article. But on many sites, negative votes can offer useful feedback to everyone. Can you think of a way of adding down-voting support to article_vote() and post_article()? If possible, try to allow users to switch their votes. Hint: if you’re stuck on vote switching, check out SMOVE, which I introduce briefly in chapter 3.
Now that we can get articles, post articles, vote on articles, and even have the ability to group articles, we’ve built a back end for surfacing popular links or articles. Congratulations on getting this far! If you had any difficulty in following along, understanding the examples, or getting the solutions to work, keep reading to find out where you can get help.
1.4. Getting help
If you’re having problems with Redis, don’t be afraid to look for or ask for help. Many others will probably have had a similar issue. First try searching with your favorite search engine for the particular error message you’re seeing.
If you can’t find a solution to your problem and are having problems with an example in this book, go ahead and ask your question on the Manning forums: http://www.manning-sandbox.com/forum.jspa?forumID=809. Either I or someone else who’s familiar with the book should be able to help.
If you’re having issues with Redis or solving a problem with Redis that isn’t in this book, please join and post your question to the Redis mailing list at https://groups.google.com/d/forum/redis-db/. Again, either I or someone who’s familiar with Redis should be able to help.
And finally, if you’re having difficulties with a particular language or library, you can also try the Redis mailing list, but you may have better luck searching the mailing list or forum for the library you’re using.
1.5. Summary
In this chapter, we covered the basics of what Redis is, and how it’s both similar to and different from other databases. We also talked about a few reasons why you’ll want to use Redis in your next project. When reading through the upcoming chapters, try to remember that we aren’t building toward a single ultimate application or tool; we’re looking at a variety of problems that Redis can help you to solve.
If there’s one concept that you should take away from this chapter, it’s that Redis is another tool that you can use to solve problems. Redis has structures that no other database offers, and because Redis is in-memory (making it fast), remote (making it accessible to multiple clients/servers), persistent (giving you the opportunity to keep data between reboots), and scalable (via slaving and sharding) you can build solutions to a variety of problems in ways that you’re already used to.
As you read the rest of the book, try to pay attention to how your approach to solving problems changes. You may find that your way of thinking about data-driven problems moves from “How can I bend my idea to fit into the world of tables and rows?” to “Which structures in Redis will result in an easier-to-maintain solution?”
In chapter 2, we’ll use Redis to solve problems that come up in the world of web applications, so keep reading to get an even bigger sense of what Redis can help you do.