
Chapter 11. Scripting Redis with Lua
- Adding functionality without writing C
- Rewriting locks and semaphores with Lua
- Doing away with WATCH/MULTI/EXEC
- Sharding LISTs with Lua
Over the last several chapters, you’ve built up a collection of tools that you can use in existing applications, while also encountering techniques you can use to solve a variety of problems. This chapter does much of the same, but will turn some of your expectations on their heads. As of Redis 2.6, Redis includes server-side scripting with the Lua programming language. This lets you perform a variety of operations inside Redis, which can both simplify your code and increase performance.
In this chapter, we’ll start by discussing some of the advantages of Lua over performing operations on the client, showing an example from the social network in chapter 8. We’ll then go through two problems from chapters 4 and 6 to show examples where using Lua can remove the need for WATCH/MULTI/EXEC transactions. Later, we’ll revisit our locks and semaphores from chapter 6 to show how they can be implemented using Lua for fair multiple client access and higher performance. Finally, we’ll build a sharded LIST using Lua that supports many (but not all) standard LIST command equivalents.
Let’s get started by learning about some of the things that we can do with Lua scripting.
11.1. Adding functionality without writing C
Prior to Redis 2.6 (and the unsupported scripting branch of Redis 2.4), if we wanted higher-level functionality that didn’t already exist in Redis, we’d either have to write client-side code (like we have through the last 10 chapters), or we’d have to edit the C source code of Redis itself. Though editing Redis’s source code isn’t too difficult, supporting such code in a business environment, or trying to convince management that running our own version of the Redis server is a good idea, could be challenging.
In this section, we’ll introduce methods by which we can execute Lua inside the Redis server. By scripting Redis with Lua, we can avoid some common pitfalls that slow down development or reduce performance.
The first step in executing Lua code in Redis is loading the code into Redis.
11.1.1. Loading Lua scripts into Redis
Some older (and still used) Python Redis libraries for Redis 2.6 don’t yet offer the capability to load or execute Lua scripts directly, so we’ll spend a few moments to create a loader for the scripts. To load scripts into Redis, there’s a two-part command called SCRIPT LOAD that, when provided with a string that’s a Lua script, will store the script for later execution and return the SHA1 hash of the script. Later, when we want to execute that script, we run the Redis command EVALSHA with the hash that was returned by Redis, along with any arguments that the script needs.
Our code for doing these operations will be inspired by the current Python Redis code. (We use our method primarily because it allows for using any connection we want without having to explicitly create new scripting objects, which can be useful when dealing with server sharding.) When we pass a string to our script_load() function, it’ll create a function that can later be called to execute the script in Redis. When calling the object to execute the script, we must provide a Redis connection, which will then call SCRIPT LOAD on its first call, followed by EVALSHA for all future calls. The script_load() function is shown in the following listing.
Listing 11.1. A function that loads scripts to be called later

You’ll notice that in addition to our SCRIPT LOAD and EVALSHA calls, we captured an exception that can happen if we’ve cached a script’s SHA1 hash locally, but the server doesn’t know about it. This can happen if the server were to be restarted, if someone had executed the SCRIPT FLUSH command to clean out the script cache, or if we provided connections to two different Redis servers to our function at different times. If we discover that the script is missing, we execute the script directly with EVAL, which caches the script in addition to executing it. Also, we allow clients to directly execute the script, which can be useful when executing a Lua script as part of a transaction or other pipelined sequence.
Keys and arguments to Lua scripts
Buried inside our script loader, you may have noticed that calling a script in Lua takes three arguments. The first is a Redis connection, which should be standard by now. The second argument is a list of keys. The third is a list of arguments to the function.
The difference between keys and arguments is that you’re supposed to pass all of the keys that the script will be reading or writing as part of the keys argument. This is to potentially let other layers verify that all of the keys are on the same shard if you were using multiserver sharding techniques like those described in chapter 10.
When Redis cluster is released, which will offer automatic multiserver sharding, keys will be checked before a script is run, and will return an error if any keys that aren’t on the same server are accessed.
The second list of arguments has no such limitation and is meant to hold data to be used inside the Lua call.
Let’s try it out in the console for a simple example to get started.

As you can see in this example, we created a simple script whose only purpose is to return a value of 1. When we call it with the connection object, the script is loaded and then executed, resulting in the value 1 being returned.
Returning non-string and non-integer values from Lua
Due to limitations in how Lua allows data to be passed in and out of it, some data types that are available in Lua aren’t allowed to be passed out, or are altered before being returned. Table 11.1 shows how this data is altered upon return.
Table 11.1. Values returned from Lua and what they’re translated into
|
Lua value |
What happens during conversion to Python |
|---|---|
| true | Turns into 1 |
| false | Turns into None |
| nil | Doesn’t turn into anything, and stops remaining values in a table from being returned |
| 1.5 (or any other float) | Fractional part is discarded, turning it into an integer |
| 1e30 (or any other large float) | Is turned into the minimum integer for your version of Python |
| "strings" | Unchanged |
| 1 (or any other integer +/-253-1) | Integer is returned unchanged |
Because of the ambiguity that results when returning a variety of data types, you should do your best to explicitly return strings whenever possible, and perform any parsing manually. We’ll only be returning Booleans, strings, integers, and Lua tables (which are turned into Python lists) for our examples.
Now that we can load and execute scripts, let’s get started with a simple example from chapter 8, creating a status message.
11.1.2. Creating a new status message
As we build Lua scripts to perform a set of operations, it’s good to start with a short example that isn’t terribly complicated or structure-intensive. In this case, we’ll start by writing a Lua script combined with some wrapper code to post a status message.
Lua scripts—as atomic as single commands or MULTI/EXEC
As you already know, individual commands in Redis are atomic in that they’re run one at a time. With MULTI/EXEC, you can prevent other commands from running while you’re executing multiple commands. But to Redis, EVAL and EVALSHA are each considered to be a (very complicated) command, so they’re executed without letting any other structure operations occur.
Lua scripts—can’t be interrupted if they have modified structures
When executing a Lua script with EVAL or EVALSHA, Redis doesn’t allow any other read/write commands to run. This can be convenient. But because Lua is a general-purpose programming language, you can write scripts that never return, which could stop other clients from executing commands. To address this, Redis offers two options for stopping a script in Redis, depending on whether you’ve performed a Redis call that writes.
If your script hasn’t performed any calls that write (only reads), you can execute SCRIPT KILL if the script has been executing for longer than the configured lua-time-limit (check your Redis configuration file).
If your script has written to Redis, then killing the script could cause Redis to be in an inconsistent state. In that situation, the only way you can recover is to kill Redis with the SHUTDOWN NOSAVE command, which will cause Redis to lose any changes that have been made since the last snapshot, or since the last group of commands was written to the AOF.
Because of these limitations, you should always test your Lua scripts before running them in production.
As you may remember from chapter 8, listing 8.2 showed the creation of a status message. A copy of the original code we used for posting a status message appears next.
Listing 11.2. Our function from listing 8.2 that creates a status message HASH

Generally speaking, the performance penalty for making two round trips to Redis in order to post a status message isn’t very much—twice the latency of one round trip. But if we can reduce these two round trips to one, we may also be able to reduce the number of round trips for other examples where we make many round trips. Fewer round trips means lower latency for a given group of commands. Lower latency means less waiting, fewer required web servers, and higher performance for the entire system overall.
To review what happens when we post a new status message: we look up the user’s name in a HASH, increment a counter (to get a new ID), add data to a Redis HASH, and increment a counter in the user’s HASH. That doesn’t sound so bad in Lua; let’s give it a shot in the next listing, which shows the Lua script, with a Python wrapper that implements the same API as before.
Listing 11.3. Creating a status message with Lua

This function performs all of the same operations that the previous all-Python version performed, only instead of needing two round trips to Redis with every call, it should only need one (the first call will load the script into Redis and then call the loaded script, but subsequent calls will only require one). This isn’t a big issue for posting status messages, but for many other problems that we’ve gone through in previous chapters, making multiple round trips can take more time than is necessary, or lend to WATCH/MULTI/EXEC contention.
Writing keys that aren’t a part of the KEYS argument to the script
In the note in section 11.1.1, I mentioned that we should pass all keys to be modified as part of the keys argument of the script, yet here we’re writing a HASH based on a key that wasn’t passed. Doing this makes this Lua script incompatible with the future Redis cluster. Whether this operation is still correct in a noncluster sharded server scenario will depend on your sharding methods. I did this to highlight that you may need to do this kind of thing, but doing so prevents you from being able to use Redis cluster.
Script loaders and helpers
You’ll notice in this first example that we have two major pieces. We have a Python function that handles the translation of the earlier API into the Lua script call, and we have the Lua script that’s loaded from our earlier script_load() function. We’ll continue this pattern for the remainder of the chapter, since the native API for Lua scripting (KEYS and ARGV) can be difficult to call in multiple contexts.
Since Redis 2.6 has been completed and released, libraries that support Redis scripting with Lua in the major languages should get better and more complete. On the Python side of things, a script loader similar to what we’ve written is already available in the source code repository for the redis-py project, and is currently available from the Python Package Index. We use our script loader due to its flexibility and ease of use when confronted with sharded network connections.
As our volume of interactions with Redis increased over time, we switched to using locks and semaphores to help reduce contention issues surrounding WATCH/MULTI/EXEC transactions. Let’s take a look at rewriting locks and semaphores to see if we might be able to further improve performance.
11.2. Rewriting locks and semaphores with Lua
When I introduced locks and semaphores in chapter 6, I showed how locks can reduce contention compared to WATCH/MULTI/EXEC transactions by being pessimistic in heavy traffic scenarios. But locks themselves require two to three round trips to acquire or release a lock in the best case, and can suffer from contention in some situations.
In this section, we’ll revisit our lock from section 6.2 and rewrite it in Lua in order to further improve performance. We’ll then revisit our semaphore example from section 6.3 to implement a completely fair lock while also improving performance there.
Let’s first take a look at locks with Lua, and why we’d want to continue using locks at all.
11.2.1. Why locks in Lua?
Let’s first deal with the question of why we would decide to build a lock with Lua. There are two major reasons.
Technically speaking, when executing a Lua script with EVAL or EVALSHA, the first group of arguments after the script or hash is the keys that will be read or written within Lua (I mentioned this in two notes in sections 11.1.1 and 11.1.2). This is primarily to allow for later Redis cluster servers to reject scripts that read or write keys that aren’t available on a particular shard. If we don’t know what keys will be read/written in advance, we shouldn’t be using Lua (we should instead use WATCH/MULTI/EXEC or locks). As such, any time we’re reading or writing keys that weren’t provided as part of the KEYS argument to the script, we risk potential incompatibility or breakage if we transition to a Redis cluster later.
The second reason is because there are situations where manipulating data in Redis requires data that’s not available at the time of the initial call. One example would be fetching some HASH values from Redis, and then using those values to access information from a relational database, which then results in a write back to Redis. We saw this first when we were scheduling the caching of rows in Redis back in section 2.4. We didn’t bother locking in that situation because writing two copies of the same row twice wouldn’t have been a serious issue. But in other caching scenarios, reading the data to be cached multiple times can be more overhead than is acceptable, or could even cause newer data to be overwritten by older data.
Given these two reasons, let’s rewrite our lock to use Lua.
11.2.2. Rewriting our lock
As you may remember from section 6.2, locking involved generating an ID, conditionally setting a key with SETNX, and upon success setting the expiration time of the key. Though conceptually simple, we had to deal with failures and retries, which resulted in the original code shown in the next listing.
Listing 11.4. Our final acquire_lock_with_timeout() function from section 6.2.5

There’s nothing too surprising here if you remember how we built up to this lock in section 6.2. Let’s go ahead and offer the same functionality, but move the core locking into Lua.
Listing 11.5. A rewritten acquire_lock_with_timeout() that uses Lua
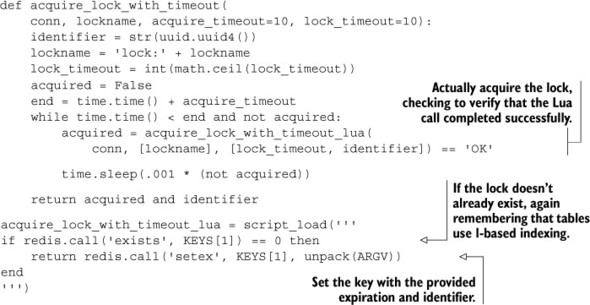
There aren’t any significant changes in the code, except that we change the commands we use so that if a lock is acquired, it always has a timeout. Let’s also go ahead and rewrite the release lock code to use Lua.
Previously, we watched the lock key, and then verified that the lock still had the same value. If it had the same value, we removed the lock; otherwise we’d say that the lock was lost. Our Lua version of release_lock() is shown next.
Listing 11.6. A rewritten release_lock() that uses Lua

Unlike acquiring the lock, releasing the lock became shorter as we no longer needed to perform all of the typical WATCH/MULTI/EXEC steps.
Reducing the code is great, but we haven’t gotten far if we haven’t actually improved the performance of the lock itself. We’ve added some instrumentation to the locking code along with some benchmarking code that executes 1, 2, 5, and 10 parallel processes to acquire and release locks repeatedly. We count the number of attempts to acquire the lock and how many times the lock was acquired over 10 seconds, with both our original and Lua-based acquire and release lock functions. Table 11.2 shows the number of calls that were performed and succeeded.
Table 11.2. Performance of our original lock against a Lua-based lock over 10 seconds
|
Benchmark configuration |
Tries in 10 seconds |
Acquires in 10 seconds |
|---|---|---|
| Original lock, 1 client | 31,359 | 31,359 |
| Original lock, 2 clients | 30,085 | 22,507 |
| Original lock, 5 clients | 47,694 | 19,695 |
| Original lock, 10 clients | 71,917 | 14,361 |
| Lua lock, 1 client | 44,494 | 44,494 |
| Lua lock, 2 clients | 50,404 | 42,199 |
| Lua lock, 5 clients | 70,807 | 40,826 |
| Lua lock, 10 clients | 96,871 | 33,990 |
Looking at the data from our benchmark (pay attention to the right column), one thing to note is that Lua-based locks succeed in acquiring and releasing the lock in cycles significantly more often than our previous lock—by more than 40% with a single client, 87% with 2 clients, and over 100% with 5 or 10 clients attempting to acquire and release the same locks. Comparing the middle and right columns, we can also see how much faster attempts at locking are made with Lua, primarily due to the reduced number of round trips.
But even better than performance improvements, our code to acquire and release the locks is significantly easier to understand and verify as correct.
Another example where we built a synchronization primitive is with semaphores; let’s take a look at building them next.
11.2.3. Counting semaphores in Lua
As we worked through our counting semaphores in chapter 6, we spent a lot of time trying to ensure that our semaphores had some level of fairness. In the process, we used a counter to create a sort of numeric identifier for the client, which was then used to determine whether the client had been successful. But because we still had race conditions when acquiring the semaphore, we ultimately still needed to use a lock for the semaphore to function correctly.
Let’s look at our earlier implementation of the counting semaphore and think about what it may take to improve it using Lua.
Listing 11.7. The acquire_semaphore() function from section 6.3.2

In the process of translating this function into Lua, after cleaning out timed-out semaphores, it becomes possible to know whether a semaphore is available to acquire, so we can simplify our code in the case where a semaphore isn’t available. Also, because everything is occurring inside Redis, we don’t need the counter or the owner ZSET, since the first client to execute their Lua function should be the one to get the semaphore. The Lua version of acquire_semaphore() can be seen in the next listing.
Listing 11.8. The acquire_semaphore() function rewritten with Lua

This updated semaphore offers the same capabilities of the lock-wrapped acquire_fair_semaphore_with_lock(), including being completely fair. Further, because of the simplifications we’ve performed (no locks, no ZINTERSTORE, and no ZREMRANGEBYRANK), our new semaphore will operate significantly faster than the previous semaphore implementation, while at the same time reducing the complexity of the semaphore itself.
Due to our simplification, releasing the semaphore can be done using the original release_semaphore() code from section 6.3.1. We only need to create a Lua-based refresh semaphore function to replace the fair semaphore version from section 6.3.3, shown next.
Listing 11.9. A refresh_semaphore() function written with Lua

With acquire and refresh semaphore rewritten with Lua, we now have a completely fair semaphore that’s faster and easier to understand.
Now that we’ve rewritten locks and semaphores in Lua and have seen a bit of what they can do to improve performance, let’s try to remove WATCH/MULTI/EXEC transactions and locks from two of our previous examples to see how well we can make them perform.
11.3. Doing away with WATCH/MULTI/EXEC
In previous chapters, we used a combination of WATCH, MULTI, and EXEC in several cases to implement a form of transaction in Redis. Generally, when there are few writers modifying WATCHed data, these transactions complete without significant contention or retries. But if operations can take several round trips to execute, if contention is high, or if network latency is high, clients may need to perform many retries in order to complete operations.
In this section, we’ll revisit our autocomplete example from chapter 6 along with our marketplace example originally covered in chapter 4 to show how we can simplify our code and improve performance at the same time.
First up, let’s look at one of our autocomplete examples from chapter 6.
11.3.1. Revisiting group autocomplete
Back in chapter 6, we introduced an autocomplete procedure that used a ZSET to store user names to be autocompleted on.
As you may remember, we calculated a pair of strings that would surround all of the values that we wanted to autocomplete on. When we had those values, we’d insert our data into the ZSET, and then WATCH the ZSET for anyone else making similar changes. We’d then fetch 10 items between the two endpoints and remove them between a MULTI/EXEC pair. Let’s take a quick look at the code that we used.
Listing 11.10. Our autocomplete code from section 6.1.2

If few autocomplete operations are being performed at one time, this shouldn’t cause many retries. But regardless of retries, we still have a lot of code related to handling hopefully rare retries—roughly 40%, depending on how we count lines. Let’s get rid of all of that retry code, and move the core functionality of this function into a Lua script. The result of this change is shown in the next listing.
Listing 11.11. Autocomplete on prefix using Redis scripting

The body of the Lua script should be somewhat familiar; it’s a direct translation of the chapter 6 code. Not only is the resulting code significantly shorter, it also executes much faster. Using a similar benchmarking method to what we used in chapter 6, we ran 1, 2, 5, and 10 concurrent processes that performed autocomplete requests against the same guild as fast as possible. To keep our chart simple, we only calculated attempts to autocomplete and successful autocompletes, over the course of 10 seconds. Table 11.3 shows the results of this test.
Table 11.3. Performance of our original autocomplete versus our Lua-based autocomplete over 10 seconds
|
Benchmark configuration |
Tries in 10 seconds |
Autocompletes in 10 seconds |
|---|---|---|
| Original autocomplete, 1 client | 26,339 | 26,339 |
| Original autocomplete, 2 clients | 35,188 | 17,551 |
| Original autocomplete, 5 clients | 59,544 | 10,989 |
| Original autocomplete, 10 clients | 57,305 | 6,141 |
| Lua autocomplete, 1 client | 64,440 | 64,440 |
| Lua autocomplete, 2 clients | 89,140 | 89,140 |
| Lua autocomplete, 5 clients | 125,971 | 125,971 |
| Lua autocomplete, 10 clients | 128,217 | 128,217 |
Looking at our table, when executing the older autocomplete function that uses WATCH/MULTI/EXEC transactions, the probability of finishing a transaction is reduced as we add more clients, and the total attempts over 10 seconds hit a peak limit. On the other hand, our Lua autocomplete can attempt and finish far more times every second, primarily due to the reduced overhead of fewer network round trips, as well as not running into any WATCH errors due to contention. Looking at just the 10-client version of both, the 10-client Lua autocomplete is able to complete more than 20 times as many autocomplete operations as the original autocomplete.
Now that we’ve seen how well we can do on one of our simpler examples, let’s look at how we can improve our marketplace.
11.3.2. Improving the marketplace, again
In section 6.2, we revisited the marketplace example we introduced in section 4.4, replacing our use of WATCH, MULTI, and EXEC with locks, and showed how using coarse-grained and fine-grained locks in Redis can help reduce contention and improve performance.
In this section, we’ll again work on the marketplace, further improving performance by removing the locks completely and moving our code into a Lua script.
Let’s first look at our marketplace code with a lock. As a review of what goes on, first the lock is acquired, and then we watch the buyer’s user information HASH and let the buyer purchase the item if they have enough money. The original function from section 6.2 appears next.
Listing 11.12. The purchase item with lock function from section 6.2


Despite using a lock, we still needed to watch the buyer’s user information HASH to ensure that enough money was available at the time of purchase. And because of that, we have the worst of both worlds: chunks of code to handle locking, and other chunks of code to handle the potential WATCH errors. Of all of the solutions we’ve seen so far, this one is a prime candidate for rewriting in Lua.
When rewriting this function in Lua, we can do away with the locking, the WATCH/MULTI/EXEC transactions, and even timeouts. Our code becomes straightforward and simple: make sure the item is available, make sure the buyer has enough money, transfer the item to the buyer, and transfer the buyer’s money to the seller. The following listing shows the rewritten item-purchasing function.
Listing 11.13. The purchase item function rewritten with Lua

Just comparing the two code listings, the Lua-based item-purchase code is far easier to understand. And without the multiple round trips to complete a single purchase (locking, watching, fetching price and available money, then the purchase, and then the unlocking), it’s obvious that purchasing an item will be even faster than the fine-grained locking that we used in chapter 6. But how much faster?
We rewrote the purchase-item function in Lua for our benchmarks, but can you rewrite the original item-listing function from section 4.4.2 into Lua? Hint: The source code for this chapter includes the answer to this exercise, just as the source code for each of the other chapters includes the solutions to almost all of the exercises.
We now have an item-purchase function rewritten in Lua, and if you perform the exercise, you’ll also have an item-listing function written in Lua. If you read the hint to our exercise, you’ll notice that we also rewrote the item-listing function in Lua. You may remember that at the end of section 6.2.4, we ran some benchmarks to compare the performance of WATCH/MULTI/EXEC transactions against coarse-grained and fine-grained locks. We reran the benchmark for five listing and five buying processes using our newly rewritten Lua versions, to produce the last row in table 11.4.
Table 11.4. Performance of Lua compared with no locking, coarse-grained locks, and fine-grained locks over 60 seconds
|
Listed items |
Bought items |
Purchase retries |
Average wait per purchase |
|
|---|---|---|---|---|
| 5 listers, 5 buyers, no lock | 206,000 | <600 | 161,000 | 498ms |
| 5 listers, 5 buyers, with lock | 21,000 | 20,500 | 0 | 14ms |
| 5 listers, 5 buyers, with fine-grained lock | 116,000 | 111,000 | 0 | <3ms |
| 5 listers, 5 buyers, using Lua | 505,000 | 480,000 | 0 | <1ms |
As in other cases where we’ve moved functionality into Lua, we see a substantial performance increase. Numerically, we see an improvement in listing and buying performance of more than 4.25 times compared with fine-grained locking, and see latencies of under 1 millisecond to execute a purchase (actual latencies were consistently around .61 milliseconds). From this table, we can see the performance advantages of coarse-grained locks over WATCH/MULTI/EXEC, fine-grained locks over coarse-grained locks, and Lua over fine-grained locks. That said, try to remember that while Lua can offer extraordinary performance advantages (and substantial code simplification in some cases), Lua scripting in Redis is limited to data we can access from within Lua and Redis, whereas there are no such limits when using locks or WATCH/MULTI/EXEC transactions.
Now that you’ve seen some of the amazing performance advantages that are available with Lua, let’s look at an example where we can save memory with Lua.
11.4. Sharding LISTs with Lua
Back in sections 9.2 and 9.3, we sharded HASHes, SETs, and even STRINGs as a way of reducing memory. In section 10.3, we sharded ZSETs to allow for search indexes to grow beyond one machine’s memory and to improve performance.
As promised in section 9.2, in this section we’ll create a sharded LIST in order to reduce memory use for long LISTs. We’ll support pushing to both ends of the LIST, and we’ll support blocking and nonblocking pops from both ends of the list.
Before we get started on actually implementing these features, we’ll look at how to structure the data itself.
11.4.1. Structuring a sharded LIST
In order to store a sharded LIST in a way that allows for pushing and popping from both ends, we need the IDs for the first and last shard, as well as the LIST shards themselves.
To store information about the first and last shards, we’ll keep two numbers stored as standard Redis strings. These keys will be named <listname>:first and <listname>:last. Any time the sharded LIST is empty, both of these numbers will be the same. Figure 11.1 shows the first and last shard IDs.
Figure 11.1. First and last shard IDs for sharded LISTs
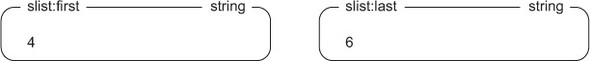
Additionally, each shard will be named <listname>:<shardid>, and shards will be assigned sequentially. More specifically, if items are popped from the left, then as items are pushed onto the right, the last shard index will increase, and more shards with higher shard IDs will be used. Similarly, if items are popped from the right, then as items are pushed onto the left, the first shard index will decrease, and more shards with lower shard IDs will be used. Figure 11.2 shows some example shards as part of the same sharded LIST.
Figure 11.2. LIST shards with data
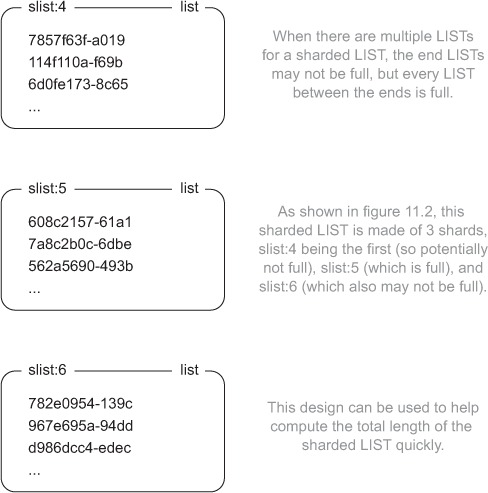
The structures that we’ll use for sharded LISTs shouldn’t seem strange. The only interesting thing that we’re doing is splitting a single LIST into multiple pieces and keeping track of the IDs of the first and last shards. But actually implementing our operations? That’s where things get interesting.
11.4.2. Pushing items onto the sharded LIST
It turns out that one of the simplest operations that we’ll perform will be pushing items onto either end of the sharded LIST. Because of some small semantic changes to the way that blocking pop operations work in Redis 2.6, we have to do some work to ensure that we don’t accidentally overflow a shard. I’ll explain when we talk more about the code.
In order to push items onto either end of a sharded LIST, we must first prepare the data for sending by breaking it up into chunks. This is because if we’re sending to a sharded LIST, we may know the total capacity, but we won’t know if any clients are waiting on a blocking pop from that LIST,[1] so we may need to take multiple passes for large LIST pushes.
1 In earlier versions of Redis, pushing to a LIST with blocking clients waiting on them would cause the item to be pushed immediately, and subsequent calls to LLEN would tell the length of the LIST after those items had been sent to the blocking clients. In Redis 2.6, this is no longer the case—the blocking pops are handled after the current command has completed. In this context, that means that blocking pops are handled after the current Lua call has finished.
After we’ve prepared our data, we pass it on to the underlying Lua script. And in Lua, we only need to find the first/last shards, and then push the item(s) onto that LIST until it’s full, returning the number of items that were pushed. The Python and Lua code to push items onto either end of a sharded LIST is shown in the following listing.
Listing 11.14. Functions for pushing items onto a sharded LIST


As I mentioned before, because we don’t know about whether clients are blocking on pops, we can’t push all items in a single call, so we choose a modestly sized block of 64 at a time, though you should feel free to adjust it up or down depending on the size of your maximum ziplist-encoded LIST configuration.
Limitations to this sharded LIST
Earlier in this chapter, I mentioned that in order to properly check keys for sharded databases (like in the future Redis cluster), we’re supposed to pass all of the keys that will be modified as part of the KEYS argument to the Redis script. But since the shards we’re supposed to write to aren’t necessarily known in advance, we can’t do that here. As a result, this sharded LIST is only able to be contained on a single actual Redis server, not sharded onto multiple servers.
You’ll notice that for our sharded push, we may loop in order to go to another shard when the first is full. Because no other commands can execute while the script is executing, the loop should take at most two passes: one to notice that the initial shard is full, the second to push items onto the empty shard.
Now that you can create a sharded LIST, knowing how long your LIST has grown can be useful, especially if you’re using sharded LISTs for very long task queues. Can you write a function (with or without Lua) that can return the size of a sharded LIST?
Let’s work on popping items from the LIST next.
11.4.3. Popping items from the sharded LIST
When popping items from a sharded LIST, we technically don’t need to use Lua. Redis already has everything we need to pop items: WATCH, MULTI, and EXEC. But like we’ve seen in other situations, when there’s high contention (which could definitely be the case for a LIST that grows long enough to need sharding), WATCH/MULTI/EXEC transactions may be slow.
To pop items in a nonblocking manner from a sharded LIST in Lua, we only need to find the endmost shard, pop an item (if one is available), and if the resulting LIST shard is empty, adjust the end shard information, as demonstrated in the next listing.
Listing 11.15. The Lua script for pushing items onto a sharded LIST


When popping items from a sharded LIST, we need to remember that if we pop from an empty shard, we don’t know if it’s because the whole sharded LIST is empty or just the shard itself. In this situation, we need to verify that we still have space between the endpoints, in order to know if we can adjust one end or the other. In the situation where just this one shard is empty, we have an opportunity to pop an item from the proper shard, which we do.
The only remaining piece for our promised API is blocking pop operations.
11.4.4. Performing blocking pops from the sharded LIST
We’ve stepped through pushing items onto both ends of a long LIST, popping items off both ends, and even written a function to get the total length of a sharded LIST. In this section, we’ll build a method to perform blocking pops from both ends of the sharded LIST. In previous chapters, we’ve used blocking pops to implement messaging and task queues, though other uses are also possible.
Whenever possible, if we don’t need to actually block and wait on a request, we should use the nonblocking versions of the sharded LIST pop methods. This is because, with the current semantics and commands available to Lua scripting and WATCH/MULTI/EXEC transactions, there are still some situations where we may receive incorrect data. These situations are rare, and we’ll go through a few steps to try to prevent them from happening, but every system has limitations.
In order to perform a blocking pop, we’ll cheat somewhat. First, we’ll try to perform a nonblocking pop in a loop until we run out of time, or until we get an item. If that works, then we’re done. If that doesn’t get an item, then we’ll loop over a few steps until we get an item, or until our timeout is up.
The specific sequence of operations we’ll perform is to start by trying the nonblocking pop. If that fails, then we fetch information about the first and last shard IDs. If the IDs are the same, we then perform a blocking pop on that shard ID. Well, sort of.
Because the shard ID of the end we want to pop from could’ve changed since we fetched the endpoints (due to round-trip latencies), we insert a pipelined Lua script EVAL call just before the blocking pop. This script verifies whether we’re trying to pop from the correct LIST. If we are, then it does nothing, and our blocking pop operation occurs without issue. But if it’s the wrong LIST, then the script will push an extra “dummy” item onto the LIST, which will then be popped with the blocking pop operation immediately following.
There’s a potential race between when the Lua script is executed and when the blocking pop operation is executed. If someone attempts to pop or push an item from that same shard between when the Lua script is executed and when the blocking pop operation is executed, then we could get bad data (the other popping client getting our dummy item), or we could end up blocking on the wrong shard.
Why not use a MULTI/EXEC transaction?
We’ve talked a lot about MULTI/EXEC transactions as a way of preventing race conditions through the other chapters. So why don’t we use WATCH/MULTI/EXEC to prepare information, and then use a BLPOP/BRPOP operation as the last command before EXEC? This is because if a BLPOP/BRPOP operation occurs on an empty LIST as part of a MULTI/EXEC transaction, it’d block forever because no other commands can be run in that time. To prevent such an error, BLPOP/BRPOP operations within a MULTI/EXEC block will execute as their nonblocking LPOP/RPOP versions (except allowing the client to pass multiple lists to attempt to pop from).
To address the issue with blocking on the wrong shard, we’ll only ever block for one second at a time (even if we’re supposed to block forever). And to address the issue with our blocking pop operations getting data that wasn’t actually on the end shard, we’ll operate under the assumption that if data came in between two non-transactional pipelined calls, it’s close enough to being correct. Our functions for handling blocking pops can be seen in the next listing.
Listing 11.16. Our code to perform a blocking pop from a sharded LIST


There are a lot of pieces that come together to make this actually work, but remember that there are three basic pieces. The first piece is a helper that handles the loop to actually fetch the item. Inside this loop, we call the second piece, which is the helper/blocking pop pair of functions, which handles the blocking portion of the calls. The third piece is the API that users will actually call, which handles passing all of the proper arguments to the helper.
For each of the commands operating on sharded LISTs, we could implement them with WATCH/MULTI/EXEC transactions. But a practical issue comes up when there’s a modest amount of contention, because each of these operations manipulates multiple structures simultaneously, and will manipulate structures that are calculated as part of the transaction itself. Using a lock over the entire structure can help somewhat, but using Lua improves performance significantly.
11.5. Summary
If there’s one idea that you should take away from this chapter, it’s that scripting with Lua can greatly improve performance and can simplify the operations that you need to perform. Though there are some limitations with Redis scripting across shards that aren’t limitations when using locks or WATCH/MULTI/EXEC transactions in some scenarios, Lua scripting is a significant win in the majority of situations.
Sadly, we’ve come to the end of our chapters. Up next you’ll find appendixes that offer installation instructions for three major platforms; references to potentially useful software, libraries, and documentation; and an index to help you find relevant topics in this or other chapters.