
9.1. Database file configuration
In previous chapters, we've seen how default SQL Server installations come with good out-of-the-box settings that lessen administration requirements, strengthen security, and maximize performance. When it comes to individual databases, there are a number of recommended configuration steps that SQL Server doesn't perform, in large part due to dependencies on disk configuration and unknown future usage of the databases.
Before covering specific file configuration recommendations, let's address some of the terms used when discussing database files:
Primary data file—The primary data file, and by default the only data file, contains system tables and information on all files within a database. By default, this file has an .mdf extension. If there are no other files in the database, the primary file also contains user objects such as tables and indexes.
Secondary data file—Secondary files, which usually have an .ndf extension, are optional files that can be added to a database for performance and/or administrative benefits, both of which we'll cover shortly. A database can contain one or more secondary files.
Filegroups—Every database contains a primary filegroup, containing at least the primary data file, and possibly all secondary data files unless other filegroups are created and used. Filegroups are logical containers that group together one or more data files, and as we'll see later in the chapter, provide several benefits.
Transaction log file—Typically using the .ldf extension, the transaction log file records details of each database modification and is used for various purposes, including transaction log shipping, replication, database mirroring, and recovery of a database to a consistent state.
With these terms in mind, let's cover some of the major file configuration recommendations, starting with separating a database's different storage objects across separate physical disk volumes.
9.1.1. Volume separation
By default, a database is created with a single data and transaction log file. Unless specified during installation or modified during database creation, both of these files will be created in the same directory, with the default size and growth rates inherited from the model database.
As shown in figure 9.1, an important database file configuration task, particularly for databases with direct-attached storage, is to provide separate physical RAID-protected disk volumes for data, transaction log, tempdb, and backup files.
As we covered in chapter 2, designing SAN-based virtualized storage is quite different from designing direct-attached storage; that being said, the principles of high performance and fault tolerance remain. In both cases, a good understanding of SQL Server's various storage objects is crucial in designing an appropriate storage system. Let's walk through these now, beginning with the transaction log file.
Figure 9.1. An example physical disk design with separate RAID volumes for data, log, tempdb, and backup files

Unlike random access to data files, transaction logs are written sequentially. If a disk is dedicated to a single database's transaction log, the disk heads can stay in position writing sequentially, thus increasing transaction throughput. In contrast, a disk that stores a combination of data and transaction logs won't achieve the same levels of throughput given that the disk heads will be moving between the conflicting requirements of random data access/updates and sequential transaction log entries. For database applications with high transaction rates, separation of data and transaction logs in this manner is crucial.
Backup files
A common (and recommended) backup technique, covered in detail in the next chapter, is to back up databases to disk files and archive the disk backup files to tape at a later point in the day. The most optimal method for doing this is to have dedicated disk(s) for the purpose of storing backups. Dedicated backup disks provide several benefits:
Disk protection—Consider a case where the database files and the backup files are on the same disk. Should the disk fail, both the database and the backups are lost, a disastrous situation! Storing backups on separate disk(s) prevents this situation from occurring—either the database or the backups will be available.
Increased throughput—Substantial performance gains come from multiple disks working in unison. During backup, the disks storing the database data files are dedicated to reading the files, and the backup disks are dedicated to writing backup file(s). In contrast, having both the data and backup files on the same disk will substantially slow the backup process.
Cost-effective—The backup disks may be lower-cost, higher-capacity SATA disks, with the data disks being more expensive, RAID-protected SCSI or SAS disks.
Containing growth—The last thing you want is a situation where a backup consumes all the space on the data disk, effectively stopping the database from being used. Having dedicated backup disks prevents this problem from occurring.
Tempdb database
Depending on the database usage profile, the tempdb database may come in for intense and sustained usage. By providing dedicated disks for tempdb, the impact on other databases will be reduced while increasing performance for databases heavily reliant on it.
Windows system and program files
SQL data files shouldn't be located on the same disks as Windows system and program files. The best way of ensuring this is to provide dedicated disks for SQL Server data, log, backups and tempdb.
Mount pointsA frequently cited reason for not creating dedicated disk volumes for the objects we've covered so far is the lack of available drive letters, particularly in clustered servers used for consolidating a large number of databases and/or database instances. Mount points address this problem by allowing a physically separate disk volume to be grafted onto an existing volume, therefore enabling a single drive letter to contain multiple physically separate volumes. Mount points are fully supported in Windows Server 2003 and 2008. |
For small databases with low usage, storing everything on a single disk may work perfectly fine, but as the usage and database size increases, file separation is a crucial configuration step in ensuring the ongoing performance and stability of database servers.
In addition to increasing throughput, creating physically separate storage volumes enables I/O bottlenecks to be spotted much more easily, particularly with the introduction of the new Activity Monitor, covered in chapter 14, which breaks down response time per disk volume.
As with object separation across physically separate disk volumes, using multiple data files isn't a default setting, yet deserves consideration given its various advantages.
9.1.2. Multiple data files
A common discussion point on database file configuration is based on the number of data files that should be created for a database. For example, should a 100GB database contain a single file, four 25GB files, or some other combination? In answering this question, we need to consider both performance and manageability.
Performance
A common performance-tuning recommendation is to create one file per CPU core available to the database instance. For example, a SQL Server instance with access to two quad-core CPUs should create eight database files. While having multiple data files is certainly recommended for the tempdb database, it isn't necessarily required for user databases.
The one file per CPU core suggestion is useful in avoiding allocation contention issues. As we'll see in chapter 12, each database file holds an allocation bitmap used for allocating space to objects within the file. The tempdb database, by its very nature, is used for the creation of short-term objects used for various purposes. Given tempdb is used by all databases within a SQL Server instance, there's potentially a very large number of objects being allocated each second; therefore, using multiple files enables contention on a single allocation bitmap to be reduced, resulting in higher throughput.
It's very rare for a user database to have allocation contention. Therefore, splitting a database into multiple files is primarily done to enable the use of filegroups (covered later in the chapter) and/or for manageability reasons.
Manageability
Consider a database configured with a single file stored on a 1TB disk partition with the database file currently 900GB. A migration project requires the database to be moved to a new server that has been allocated three 500GB drives. Obviously the 900GB file won't fit into any of the three new drives. There are various ways of addressing this problem, but avoiding it by using multiple smaller files is arguably the easiest.
In a similar manner, multiple smaller files enable additional flexibility in overcoming a number of other storage-related issues. For example, if a disk drive is approaching capacity, it's much easier (and quicker) to detach a database and move one or two smaller files than it is to move a single large file.
Transaction log
As we've covered earlier, transaction log files are written to in a sequential manner. Although it's possible to create more than one transaction log file per database, there's no benefit in doing so.
Some DBAs create multiple transaction log files in a futile attempt at increasing performance. Transaction log performance is obtained through other strategies we've already covered, such as using dedicated disk volumes, implementing faster disks, using a RAID 10 volume, and ensuring the disk controller has sufficient write cache.
For both transaction logs and data files, sizing the files correctly is crucial in avoiding disk fragmentation and poor performance.
9.1.3. Sizing database files
One of the major benefits of SQL Server is that it offers multiple features that enable databases to continue running with very little administrative effort, but such features often come with downsides. One such feature, as shown in figure 9.2, is the Enable Autogrowth option, which enables a database file to automatically expand when full.
Figure 9.2. Despite the lower administration overhead, the Enable Autogrowth option should not be used in place of database presizing and proactive maintenance routines.
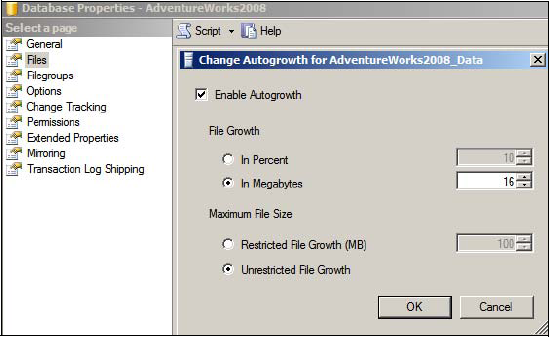
The problem with the autogrowth feature is that every time the file grows, all activity on the file is suspended until the growth operation is complete. If enabled, instant initialization (covered shortly) reduces the time required for such actions, but clearly the better alternative is to initialize the database files with an appropriate size before the database begins to be used. Doing so not only avoids autogrowth operations but also reduces disk fragmentation.
Consider a worst case scenario: a database is created with all of the default settings. The file size and autogrowth properties will be inherited from the model database, which by default has a 3MB data file set to autogrow in 1MB increments and a 1MB log file with 10 percent autogrowth increments. If the database is subjected to a heavy workload, autogrowth increments will occur every time the file is increased by 1MB, which could be many times per second. Worse, the transaction log increases by 10 percent per autogrowth; after many autogrowth operations, the transaction log will be increasing by large amounts for each autogrowth, a problem exacerbated by the fact that transaction logs can't use instant initialization.
In addition to appropriate presizing, part of a proactive database maintenance routine should be regular inspections of space usage within a database and transaction log. By observing growth patterns, the files can be manually expanded by an appropriate size ahead of autogrowth operations.
Despite the negative aspects of autogrowth, it's useful in handling unexpected surges in growth that can otherwise result in out-of-space errors and subsequent downtime. The best use of this feature is for emergencies only, and not as a replacement for adequate presizing and proactive maintenance. Further, the autogrowth amounts should be set to appropriate amounts; for example, setting a database to autogrow in 1MB increments isn't appropriate for a database that grows by 10GB per day.
Given its unique nature, presizing database files is of particular importance for the tempdb database.
Tempdb
The tempdb database, used for the temporary storage of various objects, is unique in that it's re-created each time SQL Server starts. Unless tempdb's file sizes are manually altered, the database will be re-created with default (very small) file sizes each time SQL Server is restarted. For databases that make heavy use of tempdb, this often manifests itself as very sluggish performance for quite some time after a SQL Server restart, with many autogrowth operations required before an appropriate tempdb size is reached.
To obtain the ideal starting size of tempdb files, pay attention to the size of tempdb once the server has been up and running for enough time to cover the full range of database usage scenarios, such as index rebuilds, DBCC operations, and user activity. Ideally these observations come from load simulation in volume-testing environments before a server is commissioned for production. Bear in mind that any given SQL Server instance has a single tempdb database shared by all user databases, so use across all databases must be taken into account during any load simulation.
Figure 9.3. SQL Server's proportional fill algorithm aims to keep the same amount of free space in each file in a filegroup.
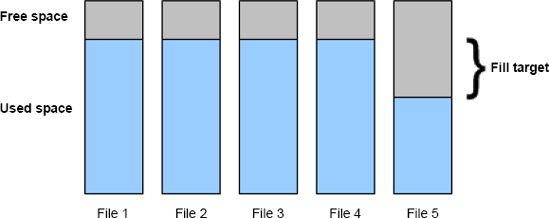
One other aspect you should consider when sizing database files, particularly when using multiple files, is SQL Server's proportional fill algorithm.
Proportional fill
When a database filegroup (covered shortly) uses multiple data files, SQL Server fills each file evenly using a technique called proportional fill, as shown in figure 9.3.
If one file has significantly more free space than others, SQL Server will use that file until the free space is roughly the same as the other files. If using multiple database files in order to overcome allocation contention, this is particularly important and care should be taken to size each database file the same and grow each database file by the same amount.
We've mentioned instant initialization a number of times in this chapter. In closing this section, let's take a closer look at this important feature.
9.1.4. Instant initialization
In versions of SQL Server prior to 2005, files were zero padded on creation and during manual or autogrowth operations. In SQL Server 2005 and above, the instant initialization feature avoids the need for this process, resulting in faster database initialization, growth, and restore operations.
Other than reducing the impact of autogrowth operations, a particularly beneficial aspect of instant initialization is in disaster-recovery situations. Assuming a database is being restored as a new database, the files must first be created before the data can be restored; for recovering very large databases, creating and zero padding files can take a significant amount of time, therefore increasing downtime. In contrast, instant initialization avoids the zero pad process and therefore reduces downtime, the benefits of which increase linearly with the size of the database being restored.
The instant initialization feature, available only for data files (not transaction log files), requires the SQL Server service account to have the Perform Volume Maintenance Tasks privilege. Local Admin accounts automatically have this privilege, but as we discussed in chapter 6, this isn't recommended from a least privilege perspective; therefore, you have to manually grant the service account this permission to take advantage of the instant initialization feature.
Earlier in the section we explored the various reasons for using multiple data files for a database. A common reason for doing so is to enable us to use filegroups.
Figure 9.4. The default filegroup structure consists of a single filegroup called primary with a single file containing all system and user-created objects.
