
9.2. Filegroups
As we covered earlier, you can think of filegroups as logical containers for database disk files. As shown in figure 9.4, the default configuration for a new database is a single filegroup called primary, which contains one data file in which all database objects are stored.
Before we cover recommended filegroup configurations, let's look at some of the ways in which filegroups are used (and abused), beginning with controlling object placement.
9.2.1. Controlling object placement
A common performance-tuning recommendation is to create tables on one filegroup and indexes on another (or some other combination), with each filegroup containing files on dedicated disks. For example, Filegroup 1 (tables) contains files on a RAID volume containing 10 disks with Filegroup 2 (indexes) containing files on a separate RAID volume, also containing 10 disks.
The theory behind such configurations is that groups of disks will operate in parallel to improve throughput. For example, disks 1–10 will be dedicated to table scans and seeks while index scans and seeks can operate in parallel on another dedicated group of disks.
Although it's true that this can improve performance in some cases, it's also true that in most cases it's a much better option to have simpler filegroup structures containing more disks. In the previous example, the alternative to two filegroups each containing 10 disks is to have one filegroup containing 20. In simpler configurations such as this, each database object has more disk spindles to be striped across.
Generally speaking, unless the data access patterns are very well known, simpler filegroup structures are almost always a better alternative, unless alternate configurations can be proven in load-testing environments.
Another common use for filegroups is for backup and restore flexibility.
9.2.2. Backup and restore flexibility
As we'll cover in the next chapter, filegroups offer a way of bringing a database online before the full database restore operation is complete. Known as piecemeal restore, this feature is invaluable in reducing downtime in recovery situations.
Without going into too much detail (full coverage in the next chapter), piecemeal restores enable the restore process to be prioritized by filegroup. For example, after you restore a filegroup containing objects required for data entry, you can make a database available to users, after which you can restore an archive filegroup in the background. As long as the users don't require access to any of the data in the archive filegroup, they won't be affected. Therefore, the user impact is reduced by bringing the database online much faster than waiting for the full database to be restored.
Figure 9.5. A recommended filegroup structure with all user objects stored in a (default) secondary filegroup
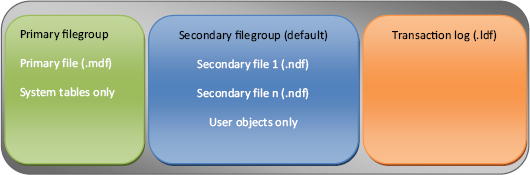
In the next chapter, we'll see how the first part of a piecemeal restore is to restore the primary filegroup, after which individual filegroups can be restored in priority order. To speed up this process, best practice dictates avoiding the use of the primary filegroup for storing user objects. The best way of enabling this is to create a secondary filegroup immediately after creating a database and marking it as the default filegroup. Such a configuration, as shown in figure 9.5, ensures that the only objects stored in the primary filegroup are system objects, therefore making this very small, and in turn providing the fastest piecemeal restore path.
Listing 9.1 contains the T-SQL code to create a Sales database using the filegroup structure just covered. We'll create two additional filegroups: one called POS (which we'll mark as the default) and the other called Archive. The POS filegroup will contain two files and the Archive filegroup a single file.
Example 9.1. Create a multi-filegroup database
CREATE DATABASE [SALES] ON PRIMARY ( NAME = N'Sales' , FILENAME = N'E:SQL DataMSSQL10.SALESMSSQLDATASalesDb.mdf' , SIZE = 51200KB , FILEGROWTH = 1024KB ) , FILEGROUP [POS] ( NAME = N'Sales1' , FILENAME = N'E:SQL DataMSSQL10.SALESMSSQLDATASalesDb1.mdf' , SIZE = 51200KB , FILEGROWTH = 1024KB ) ,( NAME = N'Sales2' , FILENAME = N'E:SQL DataMSSQL10.SALESMSSQLDATASalesDb2.mdf' , SIZE = 51200KB , FILEGROWTH = 1024KB ) , FILEGROUP [ARCHIVE] ( NAME = N'Sales3' , FILENAME = N'E:SQL DataMSSQL10.SALESMSSQLDATASalesDb3.mdf' , SIZE = 51200KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'SalesLog' , FILENAME = N'F:SQL LogSalesDbLog.ldf' , SIZE = 51200KB , FILEGROWTH = 1024KB ) GO ALTER DATABASE [SALES] MODIFY FILEGROUP [POS] DEFAULT GO |
By specifying POS as the default filegroup, we'll avoid storing user objects in the primary filegroup and thus enable the fastest piecemeal restore process. Any object creation statement (such as a CREATE TABLE command) will create the object in the POS filegroup unless another filegroup is explicitly specified as part of the creation statement.
Next up, you'll learn about a special type of filegroup in SQL Server 2008 that's used for storing FileStream data.