
Chapter 11. SQL Server XML frequently asked questions
With the SQL Server 2005 release, Microsoft implemented new and exciting XML integration into SQL Server. These features include the following:
- A new native xml data type
- XML content indexing
- Improvements to the FOR XML clause
- Improvements to the OPENROWSET function
- Integrated support for XML Schema
- Native XQuery (XML Query Language) support
- Access to additional XML-specific functionality via SQL CLR integration
All of this functionality, with some additional improvements, is included in SQL Server 2008. Many developers have questions about how to take advantage of this new functionality. This chapter is structured in a frequently-asked-questions (FAQ) format, and will answer many of the most common questions raised by developers who want to use SQL Server–based XML functionality in their applications. We will start with the basics.
XML basics
XML introduces a lot of terminology and concepts that can be new and confusing to SQL developers, or developers coming from other languages. In this section we will discuss some of these basic concepts.
What’s XML?
XML is an acronym for Extensible Markup Language. XML is a specification for creating custom markup languages. A markup language is an artificial language that consists of textual annotations, or markup tags, that control the structure or display of textual data. XML allows you to create your own custom markup language, meaning you define the markup tags that give structure and additional context to your textual data. Listing 1 shows a simple XML document.
Listing 1. Sample XML document
<?xml version = "1.0"?>
<!-- This is a simple XML document -->
<country name = "United States of America">
<states>
<state>
<abbreviation>NJ</abbreviation>
<name>New Jersey</name>
</state>
<state>
<abbreviation>NY</abbreviation>
<name>New York</name>
</state>
</states>
</country>
This XML document consists of a root-level markup tag named country. Nested within this tag, in a hierarchical structure, is a states markup tag with additional state tags nested within it, and so on. XML is handy for representing hierarchical textual data, and is useful for manipulating and sharing text-based data over the internet.
The XML specification divides the different types of supported markup annotations into logical structures known as nodes. Nodes are a useful logical construct for working with XML content. A node can be one of the following types, as shown in the sample XML document:
- Element nodes— Element nodes consist of markup tags that wrap other nodes and textual data. The element <abbreviation>NJ</abbreviation> in the example is an element named abbreviation that contains the text data NJ.
- Attribute nodes— Attribute nodes are name/value pairs associated with element nodes. In the example, the country element has an associated attribute named name, which is assigned the value "United States of America".
- Text nodes— Text nodes are the bottom-level nodes that contain character data within element nodes. The second name element contains a text node containing the character data New York.
- Comment nodes— Comment nodes are human-readable comments that can appear anywhere in XML documents outside of other markup. The <!-- and --> delimiters are used to indicate a comment node, as in the example where the comment <!-- This is a simple XML document --> appears.
- Processing instructions— Processing instructions provide a means to pass additional information to the application parsing the XML data. Processing instructions are indicated by delimiting them with <? and ?>. In the example, a special processing instruction known as the prolog is used to indicate the version of the XML recommendation that this document conforms to. The prolog in this example is <?xml version = "1.0"?>.
XML data can be logically viewed as a set of nodes in a hierarchical tree structure. Figure 1 shows the sample XML document when viewed as a tree.
Figure 1. XML tree structure

The XML node tree structure works well in support of other XML-based processing and manipulation recommendations that logically view XML data as hierarchical treelike structures. These recommendations include XML Infoset, XML Schema, XML DOM, and XQuery/XPath Data Model, to name a few. Each of these recommendations can define extra node types in addition to these basic node types, such as document nodes and namespace nodes.
What’s “well-formed” XML?
XML data must conform to certain syntactical requirements. XML that follows the syntactical requirements below is considered well-formed:
- Well-formed XML data must contain one or more elements.
- Well-formed XML data must contain one, and only one, root element. In the sample XML document presented in the previous section, the country element is the root element. It contains all other elements within its start and end tags.
- Well-formed XML data must have all elements properly nested within one another. This means no overlapping start and end tags. The start and end tags of the states element don’t overlap the other tags, such as the nested state, abbreviation, and name tags.
In addition to these requirements, XML character data must be properly entitized, which we will talk about in the next section. XML data that conforms to all of these rules is considered well-formed.
XML data that isn’t well-formed must still follow these rules, with one exception: it can have more than one root node. Consider, for example, extracting only the state elements from the previous sample data and creating an XML result like listing 2.
Listing 2. Extracting state elements from XML document
<state>
<abbreviation>NJ</abbreviation>
<name>New Jersey</name>
</state>
<state>
<abbreviation>NY</abbreviation>
<name>New York</name>
</state>
This XML document isn’t well-formed because it has multiple top-level elements. It still must conform to all other rules for well-formed documents, though. XML data that follows all of the rules for well-formedness, other than the requirement of a single root node, is sometimes referred to as an XML fragment.
What’s the prolog?
The prolog of an XML document is an optional special processing instruction at the top of the XML document (see the answer to “What’s XML?” for more information). When it is included, the prolog must be the first entry (no leading whitespace, data, or markup) of the XML document. The prolog generally includes a version number, and can also include an encoding specifier. The version number indicates the version of the W3C XML recommendation that your XML document conforms to. It is generally version 1.0 (or 1.1), as shown in the sample prolog in listing 3.
Listing 3. Sample prolog
<?xml version = "1.0"?>
The prolog can also include an encoding specifier. The encoding is generally ISO-8859-1, UTF-8, WINDOWS-1252, or UTF-16. If specified, the encoding must match the character encoding used in the source XML data. For instance, if your source XML is Unicode (nvarchar in SQL) data, you can’t use an 8-bit character encoding such as ISO-8859-1. The sample prolog in listing 4 includes both a version and a 16-bit encoding specifier.
Listing 4. Sample prolog with encoding specifier
<?xml version = "1.0" encoding = "UTF-16"?>
Keep in mind that the prolog isn’t required, but if it is included, it must match the source XML data’s encoding.
What’s an entity?
XML allows you to mark up textual data, but it assigns special meaning to certain characters, such as the greater-than and less-than symbols (< and >). Entitizing is the process of converting these characters that have special meaning in XML to special codes known as entities. The less-than symbol (<), for instance, must be converted to the entity <. XML defines five predeclared XML entities, which all programs that process XML must recognize. These predeclared XML entities are listed in table 1.
Table 1. Predeclared XML entities
|
Entity |
Description |
|---|---|
|
& |
Ampersand (&) |
|
' |
Apostrophe (') |
|
> |
Greater-than symbol (>) |
|
< |
Less-than symbol (<) |
|
" |
Quotation marks (") |
In addition to these predeclared XML entities, you can use numeric character references to represent any character in your XML data. Numeric character references resemble entities with a decimal or hexadecimal character code. The less-than character, for example, can be represented using any of the following forms in your XML data:
<
<
<
SQL Server’s XML parser automatically expands XML entities when you retrieve XML data.
What’s a DTD?
The XML standard supports a special construct known as a document type definition (DTD). In simple terms, the XML recommendation defines a DTD as a basic mechanism for constraining your XML structure and content. SQL Server supports a minimal subset of the DTD standard; specifically, you can use DTDs in your XML documents to declare your own user-defined entities. In order to process XML data that contains a DTD in SQL Server, you have to use the CONVERT function, as shown in listing 5. The result is shown in figure 2.
Figure 2. XML document with a DTD processed by the SQL Server XML parser

Listing 5. Converting XML with a DTD
DECLARE @x xml = CONVERT
(
xml,
N'
<!DOCTYPE bookdoc [
<!ENTITY manning "©2008 Manning Publications Co.">
]>
<book>
<title>C# In Depth</title>
<publisher>&manning;</publisher>
</book>
',
2
);
SELECT @x;
The CONVERT function accepts three parameters: the target data type (in this case xml), the source data (an XML document with DTD), and a third style parameter. The third parameter must be set to the number 2 or 3 when you want SQL Server to parse an XML document containing a DTD.
You will notice three important things about the result shown in figure 2. First, the SQL Server XML parser replaces the XML entities in your document with the equivalent character data. Second, the SQL Server XML parser strips away the DTD when it has finished parsing the XML data. Finally, note that SQL Server doesn’t natively support external DTDs, or DTDs that are stored outside of the current XML document.
The xml data type
The cornerstone of SQL Server 2005 and SQL Server 2008 XML functionality is the xml large object (LOB) data type. This data type provides a lot of native XML functionality through its various built-in methods, it can be validated via an XML schema, and its contents can be indexed with XML indexes. We will consider the xml data type in this section.
Why does SQL Server remove the DTD from my XML data?
When you store XML data using SQL Server’s xml data type, SQL Server converts it to an internal binary representation based on the XQuery/XPath Data Model (XDM) recommendation. The XDM recommendation defines a hierarchical representation for XML data. When you retrieve XML data stored as the xml data type, SQL Server literally re-creates the XML text based on the XDM instance contents. The XDM allows for several changes to be made to the textual representation of the XML data, including the following:
- The DTD is used to expand entities in the XML data, and then the DTD is stripped from the XML data. The DTD isn’t stored with the XML data. See the answer to “What’s a DTD?”
- CDATA sections are expanded and the CDATA markers are stripped from the XML data.
- Insignificant whitespace (spaces, tabs, linefeeds, and carriage returns between markup tags) is removed. See the answer to “How do I preserve whitespace in my XML?”
- Entities are expanded to their textual representations.
In addition, typed data, such as integers, is stored in an internal binary format. An integer such as 00150 can be stored in a numeric representation, returning the textual representation 150 (creating a typed representation of your XML data requires storing the data in a typed xml instance).
Note
The W3C XQuery/XPath Data Model recommendation is available at http://www.w3.org/TR/xpath-datamodel.
If you need to store exact copies of the text of your XML data with DTD, CDATA sections, insignificant whitespace, entities, and exact character-for-character representations of data, store your XML data using a character or binary data type such as varbinary(max), varchar(max), or nvarchar(max). The downside to this method of storing XML data in SQL Server is that you will not have access to the xml data type methods that allow you to query and manipulate your XML data.
How do I preserve whitespace in my XML?
As mentioned in the answer to “Why does SQL Server remove the DTD from my XML data?” SQL Server also strips away insignificant whitespace. Insignificant whitespace consists of tab characters, spaces, linefeeds, and carriage returns between XML markup tags. By default, when SQL Server converts your XML data to an internal XDM representation, it strips away insignificant whitespace. You can use the CONVERT function with 3 specified for the style option to convert your text-based XML data to an xml instance and preserve insignificant whitespace in the process. This conversion using CONVERT with style 3 isn’t 100 percent exact, and some whitespace characters may not be preserved in the conversion process.
Note
See the answer to “What’s a DTD?” for an example of using the CONVERT function to convert text-based XML to the xml data type.
Why am I getting strange characters in my XML?
XML supports different character encodings, such as ISO-8859-1 or UTF-8 for single-byte character encodings and UTF-16 for Unicode character representations. The code in listing 6 contains Chinese characters, which can’t be represented with single-byte character encodings. The problem in this example is that the text-based XML is being converted from a single-byte varchar encoding to the xml data type. The result of the code in listing 6 is shown in figure 3.
Figure 3. Result of single-byte encoding applied to Chinese characters
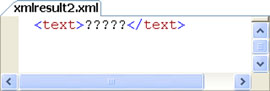
Listing 6. Applying single-byte encoding to Unicode characters
DECLARE @x xml = '<?xml version="1.0"?>
<text></text>';
SELECT @x;
As you can see in the example, there’s a mismatch when trying to store or convert Chinese characters to single-byte encodings. SQL Server replaces the Chinese characters with question marks to indicate that it couldn’t convert them to a single-byte encoding. The fix for this problem is simple: use nvarchar as the source when you need to represent character data that requires Unicode encoding. To do so, you can prefix string literals with the N prefix, as shown in listing 7. The result is shown in figure 4.
Figure 4. Result of properly encoding international characters in source XML

Listing 7. Eliminating single-byte-to-Unicode conversion problems
DECLARE @x xml = N'<?xml version="1.0"?>
<text></text>';
SELECT @x;
If you specify the wrong encoding in your XML, as shown in listing 8, you’ll get an error.
Listing 8. Invalid single-byte-to-Unicode conversion
DECLARE @x xml = '<?xml version="1.0" encoding="UTF-16"?>
<Music>
<Band>Wu Tang Clan</Band>
</Music>';
This statement returns an error like the following:
Msg 9402, Level 16, State 1, Line 1
XML parsing: line 1, character 39, unable to switch the encoding
The problem is that the character data you are converting to XML is single-byte varchar data, whereas the prolog specifies a Unicode UTF-16 encoding. SQL Server’s XML parser can’t reconcile this conflict. You can fix this by changing your source XML data to nvarchar Unicode data. In the case of a string literal, as in the example, prefix your string with the N character, as shown in listing 9.
Listing 9. Avoiding single-byte-to-Unicode conversion problems
DECLARE @x xml = N'<?xml version="1.0" encoding="UTF-16"?>
<Music>
<Band>Wu Tang Clan</Band>
</Music>';
I recommend always using Unicode, or binary format with the proper encoding specified in the prolog, to accurately represent your XML data and prevent conversion problems like these. See the answer to “What’s the prolog?” for more information about the XML prolog.
How do I query XML data?
You can query XML data using the .query() method of the xml data type. This method allows you to query XML data using XQuery path expressions. The code sample in listing 10 creates a simple XML document and uses the .query() method to return the book with ISBN 1430215941. Results are shown in figure 5.
Figure 5. Result of executing an XQuery query against XML data

Listing 10. Querying XML data
DECLARE @x xml = N'
<books>
<book isbn = "1590599837">
<title>Pro SQL Server 2008 XML</title>
</book>
<book isbn = "143021001X">
<title>Pro T-SQL 2008 Programmer's Guide</title>
</book>
<book isbn = "1430215941">
<title>Pro Full-Text Search in SQL Server 2008</title>
</book>
</books>
';
SELECT @x.query
(
N'/books/book[@isbn = "1430215941"]'
);
The results of the .query() method return entire XML nodes as xml data type instances.
How do I query a single value from my XML data?
Sometimes you might want to grab a single scalar value from your XML data instead of entire XML nodes. The xml data type .value() method provides this functionality. As with the .query() method, you pass an XQuery query to the .value() method. You also need to pass a T-SQL data type to the method. After SQL Server retrieves the scalar value from your XML data, it converts it to a T-SQL data type. The example in listing 11 retrieves the name of the book with ISBN 143021001X. The scalar value returned is converted to an nvarchar result. Results are shown in figure 6.
Figure 6. Result of retrieving a scalar value from XML data

Listing 11. Retrieving a single scalar value from XML
DECLARE @x xml = N'
<books>
<book isbn = "1590599837">
<title>Pro SQL Server 2008 XML</title>
</book>
<book isbn = "143021001X">
<title>Pro T-SQL 2008 Programmer's Guide</title>
</book>
<book isbn = "1430215941">
<title>Pro Full-Text Search in SQL Server 2008</title>
</book>
</books>
';
SELECT @x.value
(
N'(/books/book[@isbn = "143021001X"]/title)[1]',
N'nvarchar(100)'
);
How do I shred XML data?
Shredding is the process of converting XML documents to relational format—viewing your XML data as if it were a relational table. SQL Server provides two options for shredding XML data. The first, simplest option takes advantage of the xml data type .nodes() method. This method accepts an XPath-style path expression and returns a rowset consisting of xml data type values. The example in listing 12 shows how to use the .nodes() method to shred your XML data. The results are shown in figure 7.
Figure 7. Result of shredding XML data

Listing 12. Shredding XML data
DECLARE @x xml = N'<inventory store-num = "1983">
<product ean = "0051500241776">
<name>Jif Creamy Peanut Butter</name>
<size>28 oz</size>
</product>
<product ean = "0024600010030">
<name>Morton Iodized Sale</name>
<size>26 oz</size>
</product>
<product ean = "0086600000138">
<name>Bumble Bee Chunked White Albacore in Water</name>
<size>6 oz</size>
</product>
</inventory>';
SELECT Col.value(N'./@ean[1]', N'nvarchar(15)') AS EAN,
Col.value(N'./name[1]', N'nvarchar(100)') AS Name,
Col.value(N'./size[1]', 'nvarchar(100)') AS Size
FROM @x.nodes(N'//product') Tab(Col);
Note
The values returned by the .nodes() method are a functionally limited version of the xml data type. You can’t access or retrieve these values directly; instead you have to use the xml data type methods, such as .query() and .value(), to access the content of the xml data type values returned by .nodes().
As you can see, the .nodes() method has to be aliased with both a table name and a column name. In this case, we used the alias Tab(Col) for simplicity. We used the xml data type .value() method to retrieve scalar values from the Col column of the result set.
The xml data type .nodes() method is a fairly simple way to shred your XML data, but there’s a second option. The OPENXML rowset provider function is backward-compatible with SQL Server 2000. Like the .nodes() method, the OPENXML rowset provider OPENXML can be used to shred any binary or character data type, or (beginning with SQL Server 2005) the xml data type. OPENXML is a little more complicated than the .nodes() method. To use it, you first have to call the sp_xml_preparedocument stored procedure, which returns a handle to the XML document. This procedure invokes the COM-based Microsoft XML Core Services Library (MSXML) to convert your textual XML data to an internal XML Document Object Model (XML DOM) representation. sp_xml_preparedocument allocates memory for the XML DOM representation of your XML and returns an integer identifier, known as a document handle.
Once you’ve created the XML DOM representation of your XML data, you can call the OPENXML function to shred it. OPENXML takes three parameters: the document handle you generated previously with the call to sp_xml_preparedocument, an XPath-style path expression to indicate the nodes to shred, and an optional integer flag value that determines whether the input XML is element-centric or attribute-centric. The OPENXML function WITH clause allows you to specify the structure of the output rowset. Each column of the rowset can be defined with a column name, T-SQL data type, and a path expression indicating where the data should be pulled from relative to the current context node.
Finally, OPENXML requires you to clean up after yourself by calling sp_xml_removedocument with the previously generated document handle. This procedure removes the XML DOM representation of your XML data and frees up the memory MSXML was using.
The example in listing 13 shows how to shred the same XML document we shredded previously, with the exact same result, but this time we will use OPENXML instead of the .nodes() method.
Listing 13. Shredding XML with OPENXML
DECLARE @x xml = N'<inventory store-num = "1983">
<product ean = "0051500241776">
<name>Jif Creamy Peanut Butter</name>
<size>28 oz</size>
</product>
<product ean = "0024600010030">
<name>Morton Iodized Sale</name>
<size>26 oz</size>
</product>
<product ean = "0086600000138">
<name>Bumble Bee Chunked White Albacore in Water</name>
<size>6 oz</size>
</product>
</inventory>';
DECLARE @handle int;
EXEC sys.sp_xml_preparedocument @handle OUTPUT, @x;
SELECT *
FROM OPENXML
(
@handle,
N'//product',
3
)
WITH
(
EAN nvarchar(15) N'./@ean[1]',
Name nvarchar(100) N'./name[1]',
Size nvarchar(100) N'./size[1]'
);
EXEC sys.sp_xml_removedocument @handle;
Advanced query topics
Many frequently asked questions about SQL Server XML concern advanced topics such as using XML namespaces and retrieving all element names and values from an XML document. In this section, we will cover some of these advanced query topics.
How do I specify an XML namespace in my XQuery queries?
Different XML-based standards may have element names in common. It is not uncommon to see different XML-based standards that specify elements named Name and Price, for instance. Each of these element names can have a completely different meaning, depending on the standard. In one standard, the Name element might be a customer name; in another standard, it might be a product name.
To differentiate between the different uses for the same name in different standards, XML provides the concept of XML namespace. An XML namespace is a qualifier for XML elements and attributes that allows you to associate them with XML documents. Using an XML namespace, you can differentiate between the Name elements used in different standards, as shown in listing 14.
Listing 14. Sample XML with namespaces
<customers:Name>John Jacob Jingleheimer-Smith</customers:Name>
<products:Name>Little Red Wagon</products:Name>
The XML namespace associates a namespace prefix (customers and products in listing 14) with a URI for a document. If you are using XQuery to query data that contains one or more explicit namespaces, you can use the XQuery declare element’s namespace option to define the namespace in your query, as shown in listing 15. The results are shown in figure 8.
Figure 8. Querying XML with namespaces defined
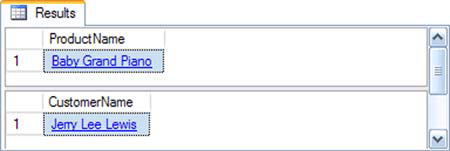
Listing 15. Querying XML with namespaces
DECLARE @x xml = N'
<sale xmlns:products = "urn:store:products"
xmlns:customers = "http://www.tempuri.org/customerdata">
<customers:Name>Jerry Lee Lewis</customers:Name>
<products:Name>Baby Grand Piano</products:Name>
</sale>';
SELECT @x.query(N'declare namespace products = "urn:store:products";
/sale/products:Name/text()') AS ProductName;
SELECT @x.query(N'declare namespace customers = "http://www.tempuri.org/customerdata";
/sale/customers:Name/text()') AS CustomerName;
In this example, we’ve defined two namespaces in the XML document: one to denote customer-specific elements and another for product-specific elements. When we query the data we use the XQuery declare namespace statement to assign a namespace prefix to a URI before we define the path expression. Once we’ve declared the namespace, we can use the namespace prefix to differentiate between elements in the path expression—even elements with the same local name (like the Name element in our example).
SQL Server also provides a WITH XMLNAMESPACES clause that can be used with queries, common table expressions (CTEs), and data manipulation language (DML) statements to declare your XML namespaces. The example in listing 16 modifies the previous example to use the WITH XMLNAMESPACES clause to generate the same result.
Listing 16. Using WITH XMLNAMESPACES clause
DECLARE @x xml = N'
<sale xmlns:products = "urn:store:products"
xmlns:customers = "http://www.tempuri.org/customerdata">
<customers:Name>Jerry Lee Lewis</customers:Name>
<products:Name>Baby Grand Piano</products:Name>
</sale>';
WITH XMLNAMESPACES('urn:store:products' AS products)
SELECT @x.query(N'/sale/products:Name/text()') AS ProductName;
WITH XMLNAMESPACES('http://www.tempuri.org/customerdata' AS customers)
SELECT @x.query(N'/sale/customers:Name/text()') AS CustomerName;
How do I get all element names and values from my XML document?
XQuery is a handy query language when you know the structure of your XML document in advance, because you can specify the hierarchical path structure to get to the elements you are interested in. But what happens when you don’t know the XML document structure in advance? In some cases you might want to grab the names and values of the elements in your XML document no matter where they occur. In those cases, you can take advantage of the xml data type’s .nodes() method and XQuery wildcard querying. In XQuery, the asterisk (*) can stand in as a wildcard in your path expressions. The example in listing 17 grabs the XML namespace, name, and text content of every element in any XML document. The results are shown in figure 9.
Figure 9. Retrieving all element names and nodes from an XML document

Listing 17. Retrieving all element names and values from XML
DECLARE @x xml = N'
<Companies xmlns:info = "urn:corp:info"
xmlns:address = "urn:corp:address">
<info:Company>
<info:Ticker>MSFT</info:Ticker>
<info:Name>Microsoft Corporation</info:Name>
<address:Address>One Microsoft Way, Redmond, WA</address:Address>
</info:Company>
<info:Company>
<info:Ticker>IBM</info:Ticker>
<info:Name>International Business Machines</info:Name>
<address:Address>1 New Orchard Road, Armonk, NY</address:Address>
</info:Company>
</Companies>';
SELECT CASE NodeUri WHEN N'' THEN N''
ELSE N'{' + NodeUri + N'}' END + NodeName AS [Name],
NodeUri,
NodeName,
NodeValue
FROM
(
SELECT node.value(N'fn:namespace-uri(.[1])', N'nvarchar(1000)') AS NodeUri,
node.value(N'fn:local-name(.[1])', N'nvarchar(1000)') AS NodeName,
node.query(N'./text()') AS NodeValue
FROM @x.nodes(N'//*') T(node)
) sub;
This sample query takes advantage of the XQuery wildcard character to match every node in the XML data, regardless of location or XML namespace. We also use the XQuery fn:namespace-uri and fn:local-name functions to retrieve the XML namespace URI and local name for every element found.
Note
XML automatically expands XML namespace prefixes (internally) to their matching namespace URIs whenever it encounters them in your XML data. To represent this, we’ve included a column that shows the fully expanded element names in the results. This column looks like this: {urn:corp:info}Company.
How do I load XML documents from the filesystem?
The OPENROWSET function has a BULK option that allows you to load data into SQL Server directly from the filesystem. Using this option, you can load a single file from the filesystem directly into a variable or column in a table. For our example, we will assume an XML file named state-list.xml exists in the root directory of your C: drive. This file looks something like listing 18.
Listing 18. Sample state-list.xml file
<?xml version="1.0"?>
<capitals>
<state name="Alabama"
abbreviation="AL"
capital="Montgomery"
flag="AL.gif"
date="December 14, 1819"
fact="Rosa Parks refused to give up her seat on a Montgomery bus in
1955. The Montgomery Bus Boycott kicked off the Civil Rights era a few
days later."
address="600 Dexter Ave"
zip="36130"
long="-86.301963"
lat="32.377189" />
<state name="Alaska"
abbreviation="AK"
capital="Juneau"
flag="AK.gif"
date="January 3, 1959"
fact="In 1867 United States Secretary of State William H. Seward
offered Russia $7,200,000, or two cents per acre, for Alaska."
address="120 4th Street"
zip="99801"
long="-134.410699"
lat="58.301072" />
...
</capitals>
You can use the OPENROWSET function with BULK option to load this XML file from the filesystem into an xml variable, as shown in listing 19. Partial results are shown in figure 10.
Figure 10. XML file loaded from filesystem into SQL Server

Listing 19. Loading XML data from the filesystem
DECLARE @xml XML;
-- Use OPENROWSET to read an XML file from the filesystem
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'c:state-list.xml', SINGLE_BLOB) TempXML
-- View the result
SELECT @xml;
A few things you need to keep in mind with this method:
- The SQL Server service must have access to the drive, directory, and file you are trying to load.
- The source file name must be a string literal. You can’t replace it with a variable name. If you want to use a variable name, you’ll have to use this method with dynamic SQL.
- We used the SINGLE_BLOB option in this example—it is the preferred method, because SINGLE_BLOB supports all Windows encoding conversions. You can also use SINGLE_CLOB for character files or SINGLE_NCLOB for national character (Unicode) files.
Summary
This concludes my answers to some of the most frequently asked questions about SQL Server XML. SQL Server provides powerful XML functionality, especially with the introduction of the xml data type in SQL Server 2005. Now that SQL Server supports XQuery via the xml data type methods, improved FOR XML capabilities, and additional improved support for XML via SQL CLR and other functions, you can easily query, manipulate, modify, and process XML server-side.
About the author

Michael Coles is a SQL Server MVP and consultant based in New York City. Michael has written several articles and books on a wide variety of SQL Server topics, including Pro SQL Server 2008 XML and the Pro T-SQL 2008 Programmer’s Guide. He can be reached at http://www.sergeantsql.com.