
CHAPTER 9
Controls and Countermeasures
In this chapter, you will learn about
• Security controls, safeguards, and countermeasures
• Differences between deterrent, preventive, detective, corrective, and compensating controls
• Differences between administrative, technical, and physical controls
• Common steps to harden systems
• Differences between policies, standards, procedures, and guidelines
• Basic controls such as change control, configuration management, and patching systems
• Mobile device management methods and other endpoint device security concepts
• Use of RAID subsystems to provide fault tolerance
• Use of failover of clusters to protect against the failure of a server
• Load balancing methods such as round robin and source address affinity
• Different types of backups, such as full, differential, and incremental
Using Security Controls, Safeguards, and Countermeasures
Chapter 7 provided information on risk and explained that risk is the probability or likelihood that a threat will exploit a vulnerability and cause a loss. Chapter 8 presented information on performing vulnerability assessments to detect vulnerabilities. Both chapters mentioned that an organization mitigates risk by implementing security controls. This chapter digs deeper into security controls.
Security professionals often use the terms controls, safeguards, and countermeasures interchangeably. They are the means, methods, actions, techniques, processes, procedures, or devices that reduce the vulnerability of a system or reduce the probability that a threat will exploit a vulnerability and cause a loss. In this chapter, I’ve primarily used the term controls. However, if you see the terms safeguards or countermeasures, it’s important to recognize they mean the same thing.
Security controls help prevent, detect, and correct problems related to security incidents. In general, a security incident is any event that results in a negative impact on the confidentiality, integrity, or availability of an organization’s assets. This includes losses from data breaches, denial of service (DoS) attacks, malicious software (malware) infections, power loss, and failure of environmental systems such as heating, ventilation, and air conditioning (HVAC) systems.
Figure 9-1 shows the two ways that controls are used. They can either reduce vulnerabilities to reduce losses from a risk, or attempt to neutralize a threat to reduce losses from a risk. For example, antivirus (AV) software protects against malware. When administrators install AV software and keep it up to date, the system is less vulnerable to malware attacks. The AV software also helps to neutralize the threat of malware.
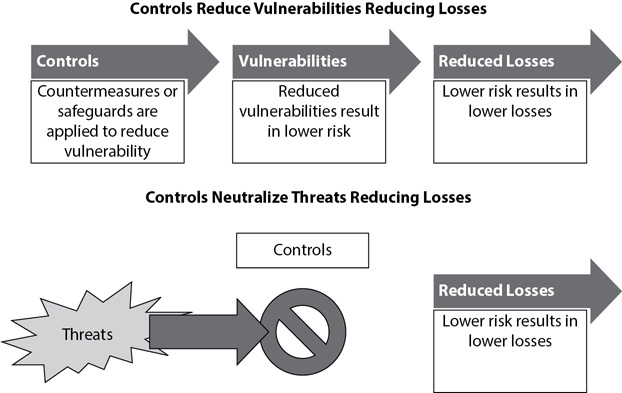
Figure 9-1 Controls reduce vulnerabilities, resulting in reduced losses.
Controls can be either technical or nontechnical. Technical controls use technical means to reduce risk and are merged with hardware, software, and firmware to either reduce vulnerabilities or reduce the impact of threats. Nontechnical controls are physical and administrative controls and include items such as written security policies, physical security controls, operational procedures, and personnel training.
For example, an intrusion prevention system (IPS), covered in Chapter 8, is an example of a technical control that attempts to detect and block attacks. User training is an example of a nontechnical control that attempts to educate users and encourage them to avoid risky behavior such as clicking a link within a phishing e-mail.
Performing a Cost-Benefit Analysis
Organizations have a finite amount of money, so they must evaluate controls and purchase controls they perceive as having the best value. A cost-benefit analysis (CBA) attempts to determine the value of a control to the organization. A CBA compares the cost of a control with the potential benefits of the control to help determine if the cost of the control is justified. The CBA also compares the cost of implementing a control with the cost associated with losses if the control is not implemented.
Personnel often perform a CBA for each recommend control. This makes it easier for management to make an educated decision about purchasing the control. Chapter 7 presents both quantitative analysis and qualitative analysis methods. A quantitative analysis uses monetary amounts that work well with a CBA.
When evaluating any control, it’s important to evaluate both its expected effectiveness in mitigating a risk and its cost. Further, when evaluating the cost of the control, you must consider more than just the initial cost. Controls have several costs that management must consider before approving the purchase. These additional costs include the following:
• Initial cost The cost of the product. It could be a one-time purchase price or could entail monthly or annual recurring costs. For example, AV software has both an initial cost and a subscription cost to update definitions regularly. Of course, not using any type of AV software results in recurring costs too.
• Implementation costs Costs required to implement the control. Technical controls often require additional costs to implement them. Personnel may need to test the control for compatibility, resulting in labor costs. A control may require a vendor to install it initially, or may require training for administrators before the administrators can install and implement the control.
• Compatibility costs The costs associated with the usability of a system after implementing a control. Although security often requires a balance with usability, it’s easy for security professionals to get overzealous and implement controls without considering the impact on usability. If the control negatively affects productivity or revenue, it can affect the mission of the organization.

EXAM TIP The cost of a control is justified if the cost of the control is significantly lower than the annual loss expectancy (ALE) without the control. The cost is usually not justified if the cost of the control is significantly higher than the ALE without the control. When the costs and savings are about the same, management may request a return on investment (ROI) analysis to determine whether the cost is justified. The ROI looks at the cost over a longer period of time.
Security Controls Lifecycle
Security controls go through a natural lifecycle. This includes selecting, implementing, assessing, and monitoring security controls. This is an ongoing process, and when monitoring indicates that a control is not effective, personnel must evaluate and select additional, or different, controls.
Figure 9-2 shows the overall steps of selecting, implementing, assessing, and monitoring security controls. These steps are derived from National Institute of Standards and Technology (NIST) Special Publication (SP) 800-53 Revision 4, Security and Privacy Controls for Federal Information Systems and Organizations. The steps are as follows:
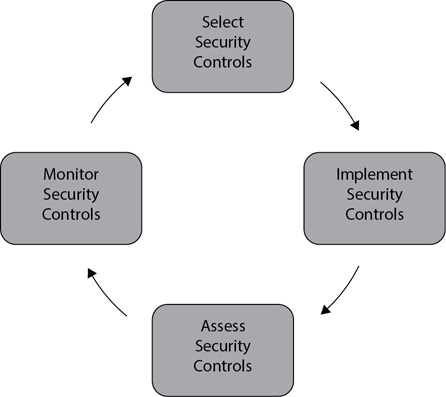
Figure 9-2 Security controls lifecycle
• Step 1: Select security controls After identifying the information system or process that an organization wants to protect, security personnel select and evaluate one or more security controls. The evaluation often includes a risk assessment, including either a quantitative analysis or a qualitative analysis, as described in Chapter 7, and a cost-benefit analysis to determine the benefit of the control. While security and administrative personnel recommend security controls, management ultimately selects the security controls.
• Step 2: Implement security controls Next, personnel implement the security controls. This can be relatively easy to do or extremely complex, depending on the control. For example, creating a failover cluster to protect availability of a server requires research to purchase the correct hardware, training for personnel to install and maintain the hardware, and a phased implementation plan to put the failover cluster into service.
• Step 3: Assess security controls After implementing the security controls, personnel evaluate them to verify they are implemented correctly, operating as expected, and meeting the intended security requirements.
• Step 4: Monitor security controls Personnel monitor the security controls on a continuing basis to determine their effectiveness. They also monitor additional factors such as changes to the protected system and changes to external laws, regulations, policies, and guidelines.
It’s worth stressing that the lifecycle of security controls is an ongoing process. Because threats are constantly changing, security personnel need to constantly monitor the environment for new threats and recommend security controls to mitigate associated risks.
Understanding Control Goals
Controls and countermeasures are primarily identified as one of the following three types: preventive, detective, or corrective. A preventive control attempts to prevent losses before they occur, a detective control detects violations, and a corrective control attempts to reverse the impact from a security incident. Other controls include compensating and deterrent controls, discussed later in this section.
Losses to confidentiality, integrity, or availability (CIA) can affect the organization’s mission. Figure 9-3 emphasizes that controls attempt to prevent, detect, and correct losses to any of these elements of the security triad.
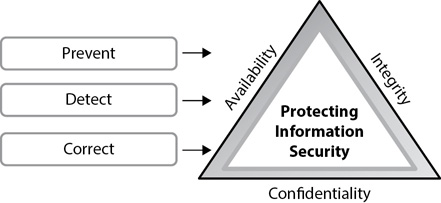
Figure 9-3 Controls prevent, detect, and/or correct losses to CIA.
Some controls combine all three objectives. For example, AV software running on an e-mail server can strip off malicious attachments to prevent them from reaching the user. AV software running on a user’s system can detect malware, such as when a user inserts an infected Universal Serial Bus (USB) flash drive into a system. This AV software can also correct the problem by removing the malware from the infected USB flash drive.
EXAM TIP Controls have three primary goals: prevention, detection, and correction. Some controls have only a single goal (prevention, detection, or correction), while other controls attempt to achieve multiple goals.
Preventive
Preventive controls focus on preventing losses due to risks. The most basic type of preventive controls consists of written security policies, standards, and procedures. For example, many of the basic controls, such as separation of duties, least privilege, and strong authentication, are preventive controls identified in written security policies and implemented with different types of controls. Some security controls, such as fences, security cameras, and guards, can deter threats, so can be classified as both preventive and deterrent controls.

NOTE Most documentation uses the term preventive. However, the SSCP objectives (and the CISSP objectives) use the term preventative. Both terms mean the same thing in this context.
The following are some examples of preventive controls:
• Intrusion prevention systems
• Written policies and procedures
• Background checks on prospective employees
• Implementation of separation of duties and least privilege policies
• Strong access control processes (starting with strong authentication)
• Technical password policies that force users to create strong passwords and change them periodically
• Termination processes that ensure personnel disable accounts for terminated employees
• Classification of data (such as public, private, and proprietary) and implementation of varying levels of protection based on the classification
• Encryption of data (both at rest and in transit)
• Security cameras, fences, and guards

TIP Separation of duties can also be detective in nature if it includes a reconciliation or audit function. For example, if accounts payable is separated from accounts receivable, and a third party periodically reconciles (or audits) the accounts payable and accounts receivable data, the reconciliation process is a detective control that can detect anomalies.
Detective
Detective controls identify the event either as it is occurring or after it has occurred. Such controls provide evidence that preventive controls are working (or not working). Information can be used as evidence that a loss has occurred and can be used to provide an immediate response by combining the detective control with a corrective control. The goal is to detect incidents as soon as possible so that either a technical control or a person can respond to resolve the problem.
The following are some examples of detective controls:
• Forensics analysis
• Physical inventories
• Intrusion detection systems
• Scripts to automate discovery of events of interest
• AV software that can detect malware installed on a system
• Audit logs (including logs on servers and network resources such as firewalls)
• Reconciliation (comparing different sets of data with each other, such as comparing a database inventory with a physical inventory)
NOTE Many of the controls mentioned throughout this chapter are covered in greater depth elsewhere in this book. I’ve pointed out the chapters for some of the controls in Notes or Tips. However, you can also use the Table of Contents and the Index to locate where I’ve covered any of these controls in more depth.
Corrective
A corrective control takes action to reverse the effects of an event and/or restore a disabled or failed control. Many corrective controls often work in conjunction with detective controls. After detecting the event, the corrective control goes into action. For example, after updating signatures on AV software, the AV software might detect an active virus and quarantine it. This reverses the infection. Similarly, a host-based intrusion detection system (HIDS) might detect that the host firewall is disabled and automatically enable it to correct the problem. The following are some examples of corrective controls:
• Intrusion detection systems (that can actively make changes)
• AV software that can remove or isolate malware
• Procedures to back up data and restore backups
• Disaster recovery and business continuity plans
• Scripts to automate corrective processes
EXAM TIP Many controls combine preventive, detective, and corrective measures. For example, AV software is detective when it identifies malware and corrective when it removes it. Similarly, a backup policy is a preventive control because it attempts to prevent the loss of data. The procedures to restore data from backups are corrective controls because they provide the means to restore data after a data loss.
Other Controls
Beyond preventive, detective, and corrective controls, you should also know about some additional controls, including compensating, deterrent, directive, and recovery controls. The SSCP objectives added compensating and deterrent controls in the previous edition and they are in this edition too. It could be argued that each of the following controls could be classified as preventive, detective, or corrective. However, classifying a control as compensating, deterrent, directive, or recovery provides a more focused classification:
• Compensating controls These controls are in place in case a primary control fails or is unavailable. For example, imagine a small organization employs the principle of separation of duties to ensure that no one employee controls an entire process in the accounting department. However, occasional illnesses or vacations require one person to do all the work. To compensate for this the organization can implement routine reconciliation audits as a compensating control. The audit will review and validate activity and can detect potential anomalies. You can also think of these as alternative controls that an organization implements when it isn’t feasible or desirable to use the primary control.
• Deterrent controls These controls attempt to deter would-be attackers from attempting an attack or even deter users from trying to circumvent policies. For example, just the presence of a guard can deter an attacker from attempting to tailgate into an organization. Similarly, when a proxy server blocks access to a site from within an organization, it could display a web page reminding users of the acceptable use policy (AUP) and informing them that the proxy server records all their online activity. This message can deter users from purposely accessing unauthorized pages. Note that a deterrent control is similar to a preventive control. The primary difference is that a deterrent control encourages someone to decide not to take a specific action. In contrast, a preventive control doesn’t rely on someone doing the right thing, but instead implements methods to prevent them from taking specific actions.
• Directive controls These are controls mandated by a higher authority. For example, the Health Insurance Portability and Accountability Act (HIPAA) directs organizations to implement specific safeguards to protect private health information (PHI). The controls that an organization implements to protect PHI are directive controls.
• Recovery controls These controls are focused on recovering a system or mission after an outage, such as after a disaster. For example, reliable backups, along with detailed procedures on how to restore backups, are recovery controls. These are often considered corrective controls.
EXAM TIP When preparing for the SSCP exam, focus primarily on the preventive, detective, corrective, deterrent, and compensating controls. You may see directive and recovery controls too, especially if you pursue the CISSP certification.
Comparing Security Control Implementation Methods
In addition to understanding security control goals (such as preventive or detective), you should also understand how controls are implemented. The three primary methods listed in the SSCP objectives are administrative, technical, and physical. Figure 9-4 provides an overview, and the following sections explain these methods in more depth.
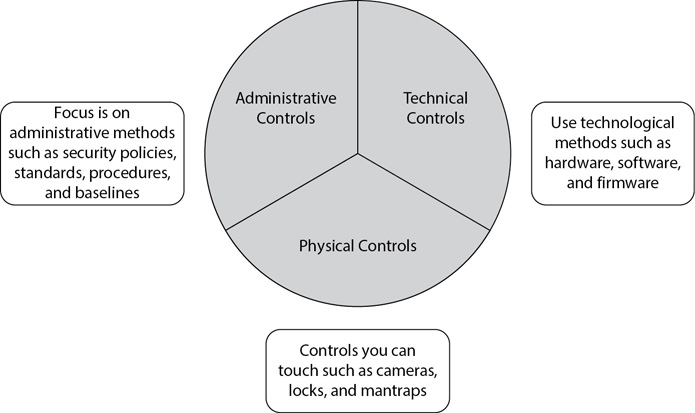
Figure 9-4 Control classes: administrative, technical, and physical
NIST SP 800-53 organizes controls into 18 families. In past versions, NIST attempted to match each of these families with specific control methods or classifications (such as management, technical, and operational). However, many controls apply to more than one control classification, so the current version has dropped that practice. Table 9-1 lists the 18 families. SP 800-53 lists and describes multiple controls within each of these families.
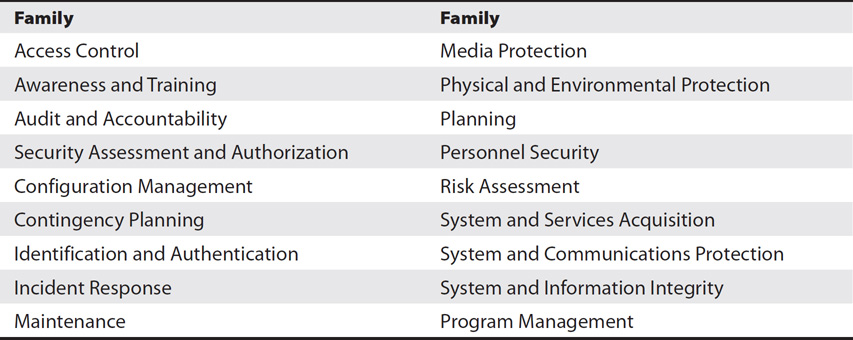
Table 9-1 Control Families
Administrative Security Controls
Administrative controls (sometimes called management or operational controls) focus on the management of risk and the management of IT security. They include security policies, standards, procedures, guidelines, baselines, and other administrative practices that an organization uses to implement security. The following list shows some examples:
• Written documents such as security policies and standards that provide direction to employees
• Step-by-step procedures for routine operations such as performing backups and verifying proper operation of fire prevention and detection equipment
• Baseline templates to provide a starting point for security controls
• Clear processes for configuration, change, and patch management
• Tests and assessments such as risk assessments and vulnerability assessments
• Plans (such as incident response plans) that help an organization respond to incidents
• User awareness and training programs to help users take an active role in security
NOTE Chapter 7 covers risk assessments and Chapter 8 covers vulnerability assessments. Other concepts mentioned in the previous list are discussed later in this chapter.
Technical Security Controls
Technical (sometimes called logical) controls are those that are implemented through technical methods such as hardware, software, or firmware components. The following list shows some examples:
• Identification and authentication controls that allow users to prove their identity
• Technical password policies that enforce the written security policies, such as password aging settings that force users to change their password periodically
• Access controls that ensure only authorized entities have access to systems and data
• Auditing and accountability controls that track activity and detect unauthorized access
• Network access controls that restrict access to networks to clients that do not meet minimum security requirements
• Encryption protocols that scramble data and provide confidentiality
• Session timeout settings that lock a user’s system or close a web browser session after a period of inactivity
Physical Security Controls
Physical security controls refer to the controls that you can touch. Many documents group them together with operational controls, and that is accurate. However, within the context of security, physical security controls are so important that it’s worth listing them separately. NIST SP 800-53 identifies a family of Physical and Environmental Protection controls that falls into this class of controls. These include any controls that control, restrict, and/or monitor physical access and provide environmental protection (such as temperature and humidity controls). The following list shows some examples:
• Perimeter barriers such as fences and bollards outside the building and locked doors inside the building
• Mantraps that control how many people can enter the restricted area at a time and help prevent tailgating
• Cameras that can record all activity for any area of interest
• Lighting to illuminate potential areas where intruders may try to break into a building
• Access badges that personnel wear while inside secure areas
• Primary and backup power sources, such as generators and uninterruptible power systems
• Heating, ventilation, and air conditioning systems that control temperature and humidity
When planning physical security controls, it’s important to consider personnel safety and always prioritize personnel safety over IT security. As an example, electronic door locks require power to open. If a building loses power, exit doors using electronic door locks should fail in such a way that the doors unlock. This allows personnel within the building to exit. In contrast, if the doors failed in such a way that they remained locked, a fire that affected power could trap personnel inside the room.
Combining Control Goals and Classes
When taking security tests such as the SSCP exam, you’re often required to know both the control goal (such as preventive, detective, or corrective) and the control class (administrative, technical, and physical). For example, a locked door to a room is a preventive, physical security control. It is a preventive control because it prevents individuals from going into the room, and it is a physical security control because you can touch the locked door.
Think about an audit log that security professionals use to identify security violations. How would you classify it? It is a detective, technical security control. It is a detective control because security professionals use it to detect security violations after they’ve occurred and been recorded in the log. It is a technical control because it uses technical means to record events.
It’s impossible to list all the possible controls along with their combinations in this chapter. However, if you understand the control goals (such as preventive, detective, and corrective) and you understand the control, you’ll find that it is relatively easy to match the two.
As an example, what is the goal of bollards placed by the entrance to a building? Bollards are vertical metal or cement poles. They act as barricades to prevent someone from driving a vehicle through the entrance, so they are preventive controls.
Similarly, if you understand the control classes (administrative, technical, and physical) and you understand the control, you’ll find that it is relatively easy to match the two. Bollards are a physical security control because they use physical methods (something you can touch) for security. In other words, bollards are preventive, physical security controls.
Exploring Some Basic Controls
There are thousands of different security controls, and most (if not all) are documented in NIST SP 800-53. Obviously, this chapter cannot include all the controls covered in NIST SP 800-53. However, the following sections introduce some common controls that you may see on the SSCP exam.
Hardening Systems
Hardening a system is the practice of making it more secure from its default configuration. Administrators harden systems by following basic security practices such as those in the following list:
• Remove or disable unused protocols If a protocol is not being used, it should not be installed. Many operating systems include default protocols. Administrators should verify whether a system needs all installed and enabled protocols, and then either remove or disable any unused protocols. Every installed protocol increases the attack surface of the system. In contrast, by removing unused protocols, administrators decrease the attack surface. Attackers cannot attack a protocol that is not installed and running on a system. However, in some cases attackers can enable a protocol, so just disabling it doesn’t provide the desired level of protection.
• Remove or disable unneeded services This is similar to removing or disabling unused protocols. Many systems include and enable default services. However, not all systems need these default services. Administrators should verify the services that are needed and disable unneeded services. Attackers cannot attack a disabled service. In some cases, administrators disable protocols by disabling the related service. However, if malware can get administrative access to a system, it can enable the protocol by starting the service. As an example, some malware has used Trivial File Transfer Protocol (TFTP) to infect other systems on a network. If the related TFTP service was disabled, the malware simply enabled the service, which enabled the protocol.
EXAM TIP You can reduce the attack surface of a system by removing or disabling unused protocols and services. With these protocols and services removed or disabled, an attacker has fewer opportunities to attack a system.
• Change defaults If the system starts with any default configurations that represent a risk, change them before putting the system into service. The classic example is default passwords. For example, wireless routers included a default password for years that, if not changed, was easily used by attackers to access the device and modify key settings.
• Keep systems up to date Both operating system software and application software develop bugs. Attackers can exploit many of these bugs, so it’s important to keep systems up to date. Vendors regularly release updates, patches, and fixes to resolve these bugs. These updates should be tested and applied as soon as possible.
• Enable firewalls Many systems have built-in firewalls, and many security suites provided by AV software companies include third-party firewalls. Enabling host-based firewalls reduces the possibility of successful attacks.
• Include AV software Threats from malware are constant today, and unprotected systems will quickly become infected. AV software protects systems from a wide variety of malware threats. It’s also important to keep the AV software signatures up to date.
Policies, Standards, Procedures, and Guidelines
Policies are high-level documents used to provide guidance to members of an organization. A policy provides direction to employees and is authoritative in nature. Standards document criteria such as a proven norm or method. They are typically external to an organization but can influence the organization’s policies, guidelines, and procedures. Guidelines provide recommendations to members of an organization but aren’t mandatory or authoritative in nature. Procedures provide individuals with specific action steps to accomplish tasks. Figure 9-5 shows the relationship among policies, standards, procedures, and guidelines.
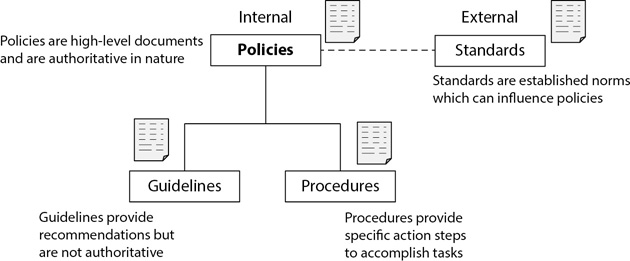
Figure 9-5 Relationship among policies, standards, procedures, and guidelines
EXAM TIP Policies are authoritative in nature and provide overall direction. Standards are established norms, which can influence policies. Guidelines and procedures are derived from policies. Guidelines provide recommendations but are not authoritative.
The following are some examples of policies:
• Security policy Many organizations have security policies that define the overall goals of security. A security policy defines what security means to an organization and outlines basic security requirements. Personnel within an organization create standards and procedures to meet the goals and requirements specified within a security policy.
NOTE Chapter 12 covers security policies in more depth.
• Acceptable use policy This lets users know what they can and cannot do with IT systems owned and controlled by the organization. For example, some organizations allow users to send and receive personal e-mails with their organizational account, while other organizations restrict this.
• Backup policy Many organizations use a backup policy to define the data that should be backed up and how long backups should be retained. A backup policy would also include a statement mentioning that a copy of backups must be kept in an offsite location to protect against a potential disaster.
An organization may use configuration control procedures to dictate the configuration of systems. For example, the organization may identify specific baseline configurations for servers and baseline configurations for desktop systems. At any time, the organization can compare the current configuration of these systems against the baseline to ensure that the system is still meeting the requirements of the standard.
An organization can often choose what standards to follow, so standards aren’t necessarily authoritative in nature. For example, the International Organization for Standardization (ISO)/International Electrotechnical Commission (IEC) 20000 (previously known as BS 15000) is a standard based on the Information Technology Infrastructure Library (ITIL). An organization can use this as an external standard when creating its security policy. Management would ensure that the security policy addresses relevant elements of ISO/IEC 20000. Similarly, organizations can use NIST special publications in the SP 800 series as standards when creating or updating their security policies.
Guidelines are more generic in nature. For example, a guideline related to backups may recommend backing up all databases. Notice this is different from having an authoritative backup policy that states that all customer databases must be backed up.
Policies are implemented with procedures. For example, written procedures identify how users acknowledge the acceptable use policy. It may specify that employees need to review and sign the policy when hired and annually thereafter. Backup procedures would itemize the steps required to back up different types of data, such as a database or individual files, and the steps required to restore backups.
Response Plans
Many organizations prepare for disasters by creating different types of plans. A business continuity plan (BCP) helps an organization prepare for emergencies that can interrupt the mission of the business. The BCP uses a business impact analysis (BIA) to identify critical functions for an organization and then includes plans to keep these critical functions operating. A disaster recovery plan (DRP) identifies steps to recover critical systems after a disaster.
Security incidents can cause a significant amount of damage, so organizations often create incident response plans to prepare for them. An incident response plan provides detailed guidance for personnel responding to security incidents.
NOTE Chapter 12 covers disaster preparation in more depth, including the differences between a BIA, BCP, and DRP. Chapter 13 covers incidents and incident response in more depth.
Change Control and Configuration Management
Change control helps prevent unintended outages from occurring as a result of changes. There are countless stories of well-meaning technicians and administrators modifying systems to resolve one problem, but inadvertently creating another problem. In the worst-case scenarios, they end up disabling an entire system or service.
Instead of making a change on impulse when a change is required or desired, administrators submit a change request. A group of experts on a change review board reviews the request and tries to predict potential problems from the change. They approve the change if they predict it will not cause any problems and reject the change if they determine it will be detrimental to operations.
Configuration management ensures that information about a system’s configuration is available and helps ensure that similar systems are configured similarly. Many organizations deploy systems using baseline configurations with images. In addition to ensuring that the system is deployed securely, configuration management ensures the system can later be checked and compared to the baseline to ensure that it hasn’t been reconfigured.
Administrators develop and maintain system and security control documentation as a part of their daily tasks. The documentation can be contained within a change control system, a configuration management system, or a combination of both. If systems are compromised in an attack or from a disaster, this documentation is invaluable when returning the system to the state it was in prior to the incident.
Some organizations combine change control and configuration management into the same process or control, while larger organizations sometimes separate it into separate processes.
NOTE Chapter 10 covers change management and configuration control in more depth, including the use of imaging to implement baselines.
Testing and Implementing Patches, Fixes, and Updates
As mentioned previously, vendors regularly release patches, fixes, and updates. Basic hardening practices ensure that systems have all relevant patches installed, including patches for operating systems and applications.
The systems development lifecycle (SDLC) is often used when planning, creating, testing, and deploying computing systems and computer applications. The SDLC includes five phases: design, implementation, maintenance, planning, and analysis. During the maintenance phase, personnel apply patches, fixes, and/or updates.
Some small organizations configure systems to apply all patches as soon as the vendor releases them. However, midsize and large organizations implement a patch management process. When a vendor releases a patch, administrators in these larger organizations often take the following steps, described in the following sections:
1. Evaluate the patch to determine if it is needed.
2. Test the patch to verify that it doesn’t cause problems.
3. Apply the patch to systems that need it.
4. Audit systems to verify that the patch is applied.
5. Document the patch in a change management system.
Evaluating Patches
It’s important to note that it isn’t necessary to apply all patches to all systems. For example, a patch for a Microsoft Server product that implements a fix for Internet Information Services (IIS) is relevant for a server running the IIS web server application. However, it is not necessary or desired for a system not running IIS. Administrators first evaluate patches, fixes, and updates to determine what systems need them.
Testing Patches
Unfortunately, some fixes cause problems elsewhere. In the worst-case scenario, systems no longer boot after administrators apply a patch. If this happens to one or two desktop computers, it can be inconvenient, but if it happens to a critical server or hundreds of desktop computers, it can be catastrophic. Because of this, organizations test the patches before applying them to critical systems or to large numbers of computers.
Ideally, the patch won’t cause any problems. However, many patches have caused problems in the past. In one case, a hardware vendor used a specially configured image on a huge quantity of computers that it sold. Using images is common, but due to how the vendor created this image, an update caused these computers to go into an endless reboot cycle. Organizations that owned computers with this image had to recover each system individually after applying the patch. However, organizations that tested the patch on a single computer discovered the problem and did not apply the patch to other computers.
Some problems created by patches aren’t as extreme. For example, one patch prevented audio from working on a specific brand of computers. A smaller organization that I know of configured its computers to receive patches automatically (without testing). One of the patches disabled all audio on about 50 of its 80 computers. However, not everyone complained right away. Instead, the IT team (one full-time IT professional and one part-time intern) started getting random complaints. It took the team a couple of weeks to realize how many computers the patch affected and identify the source of the problem.
Some organizations use IT administrator computers for testing. In other words, after determining that systems need a patch, they deploy it to computers used by IT administrators. If the patch causes any major problems, administrators can troubleshoot and recover from the problem more easily than a typical end user could.
Applying Patches
If administrators determine that the patch is needed and doesn’t cause any unacceptable problems, administrators apply the patch. Many organizations use server applications to automate the deployment of the patches. Microsoft provides Windows Server Update Services (WSUS) as a free download to manage Microsoft updates. System Center Configuration Manager (SCCM or ConfigMgr) is a server application that organizations can purchase from Microsoft. ConfigMgr includes the features of WSUS plus many more, such as the ability to inventory systems and push out applications. Additionally, third-party applications are available that organizations can use to manage updates.
After applying the patch, these automated tools verify that the systems have accepted it. In some cases, a system will block the installation of the patch. For example, a firewall can block patches if it isn’t configured with an exception to accept them. It’s also possible for an existing application to cause a conflict and block the patch.
Auditing Systems
Automated deployment applications such as WSUS provide administrators with a listing of all computers that have accepted the patch and a listing of computers that remain unpatched. Additionally, they periodically audit the systems to ensure that they all have approved patches. If a system is rebuilt or a patch is removed, these applications discover the problem. Administrators can configure WSUS and similar third-party applications to redeploy the update when they discover an unpatched system.
Unpatched systems are often vulnerable to attacks, so many vulnerability scanners check systems for patches. A vulnerability scanner can’t deploy a patch, but it can provide an alert to security administrators that a patch is missing.
Documenting Patches
As mentioned previously, most organizations use a change management process to document any type of changes. This includes changes from patches, fixes, and updates. When administrators determine that a system needs a patch, they follow the change management procedures to apply the patch.
The change management system helps prevent unintended outages due to unapproved changes. It also provides documentation on approved changes. This documentation can be extremely useful if administrators need to rebuild a system from scratch.
EXAM TIP Whenever possible, it’s best to test patches before applying them. As a follow-up step, administrators should audit systems to verify that patches are applied. Additionally, personnel should document applied patches in a change management system.
Endpoint Device Security
Many organizations implement controls to protect against risks associated with endpoint devices. In this context, endpoint devices refer to devices used by end users. They include mobile devices (such as smartphones and tablets), USB devices, laptops, and desktop computers.
Chapter 3 includes a section on protecting mobile devices, such as smartphones and tablets, and some of the risks that can occur if they are lost. Common controls with these devices are password protection, encryption of data, remote wipe, and GPS capabilities. If devices are lost or stolen, these controls help reduce risks.
Other times, the risks are due to built-in cameras or phones transmitting audio without the user’s knowledge. Because of these risks, many organizations prohibit the use of mobile devices in certain areas of an organization. Some organizations have mini-lockers close to the entrances to secure areas and require employees to lock their mobile device in the locker before entering, and retrieve it when they leave.
Bring Your Own Device
A trend in recent years is that employees want to bring their personal smartphones and tablets to work and connect into the work network. Bring your own device (BYOD) policies allow users to connect their personally owned devices to the organization.
Some of the benefits to the organization include reduced costs because they don’t need to provide these devices to employees, and improved productivity for workers because they remain connected to the work network even when they aren’t at work. For example, employees can configure their devices with their work e-mail and be available to answer e-mails during nonwork hours. Of course, this availability brings with it the challenge of maintaining a work–life balance.
Unfortunately, BYOD policies present so many challenges that some administrators have nicknamed it as bring your own disaster. Keeping these devices up to date is one challenge. Organizations have processes in place to keep organization-owned devices up to date with current patches and updates. However, pushing updates to employee-owned devices presents other problems. First, because updates might change how the device operates or how applications function, employees might not want to update their devices to a new operating system or with a new patch. Second, there are many different types of mobile operating systems (such as Apple’s iOS and the Android operating system).
Android is the most popular operating system used worldwide on smartphones and tablets. However, it isn’t run on a single brand of device. The Android operating system is open source, and multiple companies use it on their devices. For example, Google uses Android on many mobile devices that it sells. Samsung is one of many other companies that uses the Android operating system on multiple smartphones and tablets. However, because Android is open source, many mobile device vendors modify it for their devices. If the IT department is tasked with keeping BYOD devices up to date, they need to be able to manage all the different versions of Android. This includes all the Google devices, Samsung devices, and the different devices manufactured by other companies using Android. This requires knowing which devices users have and then keeping up with the updates for all of them.
Another challenge is managing the data. The user owns the device. Who owns the data? Also, how is the organization’s data protected when it is on the user’s device? Organizations often implement BYOD policies to address these challenges and include elements of the BYOD policies in acceptable use policies.
Choose Your Own Device
Choose your own device (CYOD) is an alternative that many organizations have adopted. Management creates a list of approved mobile devices that employees can connect to the network. Employees that have these approved devices (or purchase one of these devices) can connect them to the network.
This is similar to a BYOD policy, but it limits the number of device types that the IT department needs to manage. However, because the devices are still owned by the employees, the organization needs to create an acceptable use policy and to address issues such as who owns the data and how it is protected.
Using Corporately Owned Devices
Another alternative to BYOD and CYOD is corporate-owned, personally enabled (COPE) devices. These are smartphones and tablets that the organization purchases and issues to employees for work purposes. A huge benefit of COPE devices is that an organization can control what devices it purchases. For example, instead of managing different devices owned by employees, an organization can purchase only one or two models and issue these to employees.
EXAM TIP A bring your own device (BYOD) policy allows employees to connect any personally owned device to the organization’s network. Choose your own device (CYOD) is similar to BYOD, but employees can only connect devices on a preapproved list. Organizations purchase the devices and issue them to employees when using a corporate-owned, personally enabled (COPE) policy.
Mobile Device Management
Organizations typically have strong patch management processes in place, as discussed earlier in this chapter. Similarly, they have automated methods to configure systems, push out applications to systems, and update these applications when necessary. Historically, technical methods only accessed internal computers owned by the organization. However, with the explosion of BYOD, CYOD, and COPE policies, organizations now have a need to implement similar methods for smartphones and tablets.
Mobile device management (MDM) solutions provide these services. As an example, Microsoft’s ConfigMgr (mentioned in the “Applying Patches” section earlier in this chapter) includes management services for some mobile operating systems, including iOS and Android. Administrators use ConfigMgr to deploy updates, applications, and configuration settings.
MDM solutions typically have an enrollment process to register the mobile devices with the MDM solution. When using a COPE policy, administrators may manually enroll the devices. However, many MDM applications allow administrators to configure settings so that users can enroll their own device without administrator intervention. These processes do require users to authenticate while enrolling their devices.
Operating system developers (such as Microsoft, Apple, and various Android version developers) create application programming interfaces (APIs) that MDM developers can integrate within an MDM solution. These APIs simplify the way that mobile devices can be managed.
It’s worth repeating that hardware vendors, such as Samsung and Motorola, typically modify the open source Android operating system to meet their own needs. In other words, ConfigMgr (or any MDM system) cannot necessarily modify any device running Android, but instead needs APIs specifically designed for the devices.
TIP You can visit this site for a list of Android devices: https://www.bluestacks.com/blog/app-reviews/archive/list-of-android-devices.html. Scroll down to the “Phones” or “Tablets” sections and you’ll see that devices are running many different operating system versions. Additionally, these vendors can update the operating system at any time. This becomes extremely challenging for administrators to manage without MDM software.
USB Devices
USB devices, such as USB flash drives and USB hard drives, are especially troublesome to many organizations. It’s easy to copy a significant amount of data to these devices, and it’s also easy to lose them. Lost USB devices can result in a significant amount of data loss or data leakage. Some organizations require the encryption of all data stored on any type of device, including USB devices, to protect against the loss of confidentiality.
Of course, another risk related to USB devices is the risk of transferring malware from system to system. If a USB device is infected with a virus, that virus can easily infect a system as soon as a user plugs the USB device into a computer. Similarly, if a system is infected with a virus, the virus can detect when a user plugs the USB device into the computer and infect the USB device.
EXAM TIP Two significant risks related to USB devices are data leakage and infection with malware. Losses due to data leakage can be mitigated by encrypting data at rest. Malware infections can be mitigated with antivirus software.
Virtualization
Virtualization was mentioned in Chapter 4 with cloud computing. It is becoming more and more common today, and not just with cloud computing. Many organizations are realizing that they can get some significant benefits from virtualizing servers.
For example, an organization may have 500 servers hosted in a data center. The organization could instead purchase 50 very powerful servers, with each server hosting 10 virtual servers. Although the host servers are more expensive initially, they cost less in the long term. It’s cheaper to provide power and cooling to 50 servers than to 500. Virtualizing a data center also requires less space and less physical security requirements.
One of the biggest risks with virtual machines (VMs) comes from VM escape attacks. VM escape attacks give an attacker access to the physical system from within a VM. In other words, the attacker “escapes” from the VM. When successful, the attacker can gain full control over all the VMs on the host in a successful VM escape attack. The primary protection against VM escape attacks is to keep the host system and all VMs up to date with current patches.
Thin Clients
The price of computers is low enough that it’s common for each user to have his or her own computer. However, in some cases, it’s better to use a thin client to reduce some risks. A thin client has very little hardware and only minimal software installed on it. It connects over a network to a server for all its data and applications. If the thin client is stolen, no data is lost. In contrast, a computer with an operating system and applications is a thick client.
Virtual desktop infrastructure (VDI) is one method used with thin clients. Users connect to the server and access a VDI that includes an operating system and all the applications needed by the user. Because the VDI is stored on the server, the clients do not need much processing power. Some VDIs can serve desktops to users running mobile devices.
The primary consideration when using a VDI is deciding on persistent or nonpersistent desktops. A persistent desktop will save all user changes and require more resources to host different desktops for each user. A nonpersistent desktop will not save any user changes. Each user will see the same desktop each time they log on.
Application Whitelisting and Blacklisting
Application whitelisting includes a list of approved applications. When implemented, it prevents users from installing or running any applications that are not on the list. Blacklisting includes a list of nonauthorized applications. It prevents users from installing or running any application on the list. Some MDM applications support both whitelisting and blacklisting. Administrators create a list and configure the MDM application to use it. The MDM application can then scan devices to ensure they are in compliance.
Apple maintains the App Store, which is effectively a massive whitelist. Apple employees review all apps before publishing them in the App Store. Unless users jailbreak their Apple devices to bypass security, they can only install apps from the App Store. An exception to this is that an organization can create apps for its employees and configure Apple devices to accept these apps.
Endpoint Encryption
Many devices support whole disk or full device encryption. This helps prevent attackers from accessing data on stolen or lost devices. As an example, the iOS operating system encrypts all data on the device. This includes text messages, photos, contacts, notes, and more. The data is encrypted automatically as long as the device includes a screen lock, which the iOS enables automatically. Similarly, Android devices support encryption and automatically encrypt user data.
TIP Apple previously had a backdoor to encrypted data, which represented a potential risk. Apple personnel could unlock any device with a key they controlled. However, since the release of iOS 8, Apple no longer includes this backdoor key. This ensures iOS 8 isn’t accessible to potential attackers too. Similarly, Android devices create the encryption key on the device, and this key isn’t accessible by the manufacturer.
Trusted Platform Module
Many laptop computers support disk encryption using a Trusted Platform Module (TPM), which is a hardware chip embedded in the computer’s motherboard. If the laptop includes the TPM, users can enable it via the operating system. However, if the laptop didn’t ship with a TPM, you’d need to replace the motherboard to add one. The TPM stores cryptographic keys, which the operating system can use to encrypt and decrypt data.
The TPM includes a unique RSA asymmetric key (called an endorsement key), which the manufacturer embeds into the TPM before shipping it. When users enable the TPM, it creates a storage root key, which encrypts application keys. Applications (such as Microsoft BitLocker) create application keys to encrypt an entire disk. Note that it doesn’t encrypt the entire disk drive. Instead, it partitions the disk drive into separate disks. The BitLocker partition remains unencrypted, but BitLocker encrypts the other partition where the data resides.
Sandboxing for Secure Browsing
Many web browsers (such as Google Chrome and Apple Safari) support sandboxing, which ensures that web pages and web applications have limited access to your system. Think of a sandbox in a children’s playground. Parents can place their children in the sandbox and let them play. They know their children will remain safe as long as their children stay in the sandbox, which is isolated from any risks outside of the sandbox.
Similarly, web browsers run within isolated areas of a computer, which function as a virtual sandbox. The sandbox prevents web applications from accessing your personal files or hardware such as your webcam. Additionally, web browsers have limited permissions within the sandbox. These limited permissions are sometimes called protected mode or low integrity mode. Even if a user visits a malicious website that downloads malicious code, the malicious code isn’t able to do any damage without first breaking out of the sandbox.
User Awareness and Training Programs
User awareness programs attempt to help users within the organization understand security procedures and practices. These programs help users understand their responsibilities related to security, recognize risky behaviors, and change their behavior if they are engaging in unsafe computing practices.
For example, without security training and education programs, many users don’t understand the tactics used by social engineers and may readily give up important information to them. Similarly, users may not understand the risks of jailbreaking a device and installing apps from other app stores. Training topics are sprinkled through this book to stress the importance of awareness and training programs.
Understanding Fault Tolerance
A single point of failure is any component within a system that may cause a significant system outage if it fails. Fault-tolerant controls help eliminate outages from single points of failure by adding redundancies. If a system develops a fault, the system can tolerate the fault and continue to operate. Organizations often add fault tolerance for disks, servers, connections, and sites.
NOTE This section covers fault tolerance for disks, servers, and connections. Chapter 12 covers alternative sites and how they can provide fault tolerance for entire locations.
Fault Tolerance for Disks
A Redundant Array of Independent Disks (RAID) uses multiple disks to improve the performance of the disk subsystem, and most RAID systems provide fault tolerance for the disks. You can implement RAID with software or hardware. For example, some operating systems have built-in support for software RAID. Some motherboards have built-in support for hardware RAID, and you can purchase external hardware RAID disk subsystems.
Whenever possible, use hardware RAID to get better performance. In software RAID, the operating system provides the services to support the RAID and that can slow down overall system performance. Some of the common RAID configurations are RAID-0, RAID-1, RAID-5, RAID-6, and RAID-10.
RAID-0
RAID-0 uses two or more disks in an array to improve the performance of both read and write operations. However, RAID-0 does not provide any fault tolerance. If one drive in a RAID-0 disk subsystem fails, the entire array fails.
RAID-1
RAID-1 uses two disks in a mirror configuration, as shown in Figure 9-6. Each file is written completely to each drive in the array. If one of the drives ever fails, the other drive still includes complete copies of all of the files.
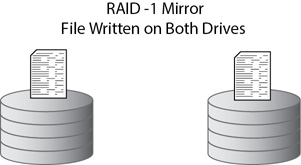
Figure 9-6 RAID-1 mirror
Most RAID-1 disk subsystems also include the ability to read from both drives at the same time. This improves read performance because the disk controller can read half the file from one drive while simultaneously reading the other half of the file from the other drive.
Hardware RAID-1 disk subsystems can typically recover automatically when a drive fails. For example, if one of the drives fails, the system recognizes the failure and stops using the failed drive. However, because all the data is on the drive that didn’t fail, the system continues to operate without interruption. Of course, if one of the drives fails, the array is no longer providing fault tolerance. Administrators should replace the failed hard drive as soon as possible.
EXAM TIP A RAID-1 mirror provides fault tolerance by mirroring data on one drive to a second drive.
RAID-5
RAID-5 uses three or more drives in an array and uses striping with parity. It writes data onto the drives in stripes, and it uses the equivalent of one drive for parity data. If any single drive fails, the array can use the parity information to reconstruct the data and the array continues to operate.
RAID-5 uses either odd or even parity to give the number of bits in a stripe either an odd or even value. For example, if odd parity is used and the number of 1 bits in the stripe is even (such as two 1 bits or four 1 bits), then the parity bit will be a 1 to make the total number of 1 bits odd (such as three or five). If odd parity is used and the number of 1 bits in the stripe is odd (such as one 1 bit or three 1 bits), then the parity bit is a 0 to keep the total number of 1 bits odd.
Consider Table 9-2. It shows the decimal values of 0 through 3 and their binary equivalent represented as data bits. In the second data row (considered a stripe in RAID-5), a decimal value of one (1) has the data bits of 0 and 1, giving an odd number of 1 bits. The parity bit is 0, so the number of 1 bits remains odd. In the fourth stripe with a decimal value of three (3), the data bits are 1 and 1, which is an even number of 1 bits, so the parity bit is a 1.
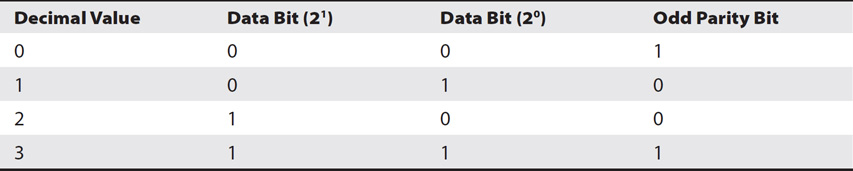
Table 9-2 Odd Parity
Now imagine that each of these columns represents a disk drive and each of the rows represents a stripe of data, as shown in Table 9-3. The equivalent of two drives carries the data, while the equivalent of one drive carries the parity bits.
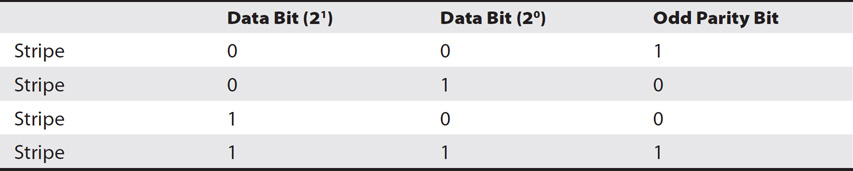
Table 9-3 RAID-5 with Odd Parity
If any of these drives fails, the system can still calculate the contents of the drive simply by calculating the remaining data. If the remaining data in a stripe has an odd number of 1 bits, the missing data in the stripe is a 0. Similarly, if the remaining data in a stripe has an even number of 1 bits, the missing data in the stripe is a 1.
Table 9-4 shows the same RAID-5 array with a failed drive. Even if you don’t know what the data was originally but you do know that the RAID is using odd parity, you can easily calculate the data in each of the stripes. This allows a RAID-5 array to suffer the loss of an entire drive and continue to operate.
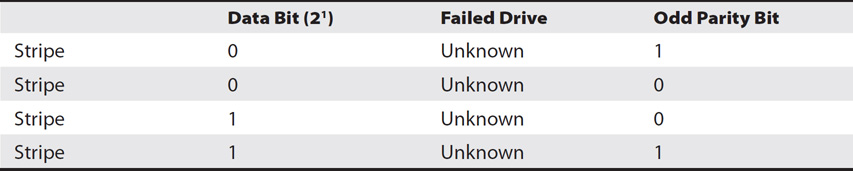
Table 9-4 RAID-5 with Odd Parity and a Failed Drive
TIP RAID-5 stripes hold more than a single bit in each stripe, but for illustration purposes, it’s much easier to show the values as single bits. RAID-5 stripes are typically 64KB.
It’s important to stress that while a RAID-5 has the equivalent of one drive devoted to parity, the parity data is not written on a single drive. Figure 9-7 shows a three-drive RAID-5 array with multiple stripes. Notice that each stripe has two drives holding the data, with one drive holding the parity, but the parity data for different stripes is contained on different drives. Early implementations of striping with parity put the parity bit on a single drive, but engineers discovered that the drives performed better when the engineers spread the parity bit across multiple drives.
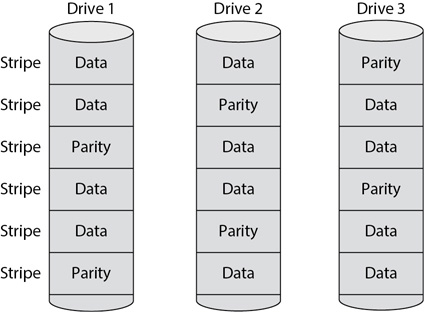
Figure 9-7 RAID-5 striping with parity
Both software-based and hardware-based RAID-5 disk subsystems can automatically detect when a drive fails and automatically continue to operate. However, hardware-based RAID-5 disk subsystems often have extra spare drives in the array. If a drive fails, the system detects the failure, logically removes the failed drive, logically adds a spare drive into the array, and rebuilds it. This all occurs automatically without any human intervention. The array also provides some type of notification to administrators of the failure so that they can replace the failed drive.
RAID-6
RAID-6 is an extension of RAID-5. The formal definition of RAID-6 is a RAID that uses two parity blocks, though the parity blocks can be implemented differently. As a simple example, the second parity block can be a copy of the first parity block but stored on a different disk. The benefit is that a RAID-6 can survive the failure of two disk drives. RAID-6 requires a minimum of four disks, with the equivalent of two disks dedicated to parity.
Many storage vendors recommend the use of RAID-6 over RAID-5 today. This is partly due to the unrecoverable read error (URE) rate of standard SATA drives and the size of current drives. As an example, think of a seven-disk RAID-5 with each disk 2TB in size. While UREs are relatively low, one URE can prevent the reconstruction of a RAID-5 disk subsystem. Further, the chance of a single URE from the 12TB of storage on the remaining six drives after a hard drive failure is as high as 62 percent.
However, with RAID-6, the disk subsystem will survive the failure of a single hard drive and a URE. If administrators quickly replace the single failed hard drive, they will be able to re-create the RAID.
Interestingly, most vendors gloss over the URE problem and instead stress that the RAID-6 can survive the failure of two hard disks. Technically, it can continue to operate with two failed disks. However, the disk subsystem is likely to experience a URE with two failed hard disks, and administrators will not be able to rebuild the array.
TIP More advanced RAID implementations are also available. For example, RAID-10 combines the benefits of a RAID-1 mirror with a RAID-0 striped array and uses at least four drives. This provides both increased performance and increased fault tolerance.
Failover Clusters
A failover cluster provides fault tolerance for one or more servers. A simple two-node failover cluster ensures a service continues to operate even if a server fails. For example, if an organization is hosting a database and wants to ensure that the database is always available, even if a server fails, the organization could use a failover cluster.
EXAM TIP Failover clusters allow a service to continue to operate even if a server fails. A failover cluster provides fault tolerance at the server level.
Figure 9-8 shows a simple two-node cluster with Node 1 active and Node 2 inactive. In this configuration, Node 1 is running the database management software and accesses the database on an external drive. When users query the database, they contact an apparent server for the cluster, and the clustering software routes the traffic to the active node.
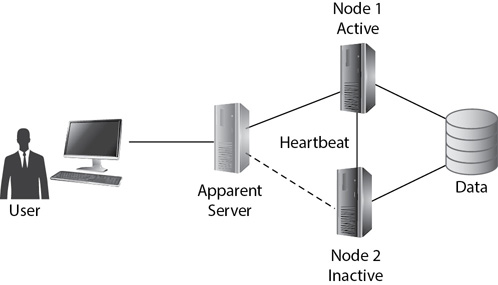
Figure 9-8 Two-node failover cluster
NOTE Node 1 and Node 2 are both physical servers that you can touch. However, the apparent server is only an outward representation of the failover cluster. The clustering software presents this outward representation to users and internally routes all traffic to the active node.
Node 2 in this cluster is currently inactive. It is running the same database management software and has access to the same database on the external drive. More importantly, it is constantly monitoring the health of Node 1 using a heartbeat signal. If Node 1 ever fails, Node 2 will know about it immediately. Depending on how administrators configure the failover cluster, Node 2 may try to restart services on Node 1 or take over services as the active node for the failover cluster.
If Node 2 takes over the services, the cluster software reroutes all requests to the failover cluster to Node 2. At this point, Node 1 is inactive and Node 2 is active. Users may notice a momentary glitch, but overall there is no loss of data.
Although a two-node cluster is easier to illustrate and conceptualize, clusters can be much more complex. For example, a two-node cluster can support two services instead of just one, with each node being active for one service and inactive for the other service. If either of the services fails, the other node can take over for both services. As another example, an eight-node cluster can support multiple services, with each node hosting one or more services and every other node capable of supporting the additional load if any other server fails.
Load Balancing
Load-balancing clusters are another type of cluster, but their primary purpose isn’t to provide fault tolerance. Instead, a load-balancing cluster spreads the operations load among multiple servers, increasing their ability to handle larger loads. This allows you to add more and more servers to compensate for increased demand.
As an example, an e-commerce site may be extremely busy during the holiday season. A load-balancing cluster allows the organization to add more servers to handle the additional website load. When the holiday season is over, the organization can remove the additional servers. Load balancing can be managed by a hardware load balancer or by software installed on each of the servers in the load-balancing cluster.
Figure 9-9 shows a sample load-balancing cluster. Each of the web servers hosts the same web applications and websites. When a user accesses the website, the connection is sent to the load balancer. The load balancer then directs the connection to one of the web servers. There are two primary methods that load balancers use to distribute the load: round robin and source address affinity.
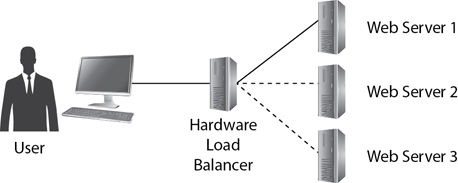
Figure 9-9 Load balancing
In a round-robin configuration, the load balancer directs the first connection to Web Server 1, the next one to Web Server 2, and the next one to Web Server 3. The load balancer continues to redirect the connections in the same rotating pattern. Some load balancers can detect the load on servers and redirect new connections to the least used server.
Source address affinity redirects traffic based on the user’s source IP address. Some web applications need users to contact the same server throughout the session. As an example, one application may store data on the server when a user adds items to a shopping cart during a session. In this scenario, the load balancer uses the customer’s IP address and source IP address affinity to ensure that the connection is redirected to the same server throughout the session.
Redundant Connections
If an organization must stay connected to the Internet, it can implement two or more connections to ensure connectivity. Similarly, an organization can implement redundant connections to ensure that a main location remains connected to a remote office.
Organizations that use two or more connections often use one high-speed connection for primary use and a second, lower-speed connection as a redundant connection in case the first connection fails. For example, one connection might be a broadband connection, and the second connection might be a slower fractional T1 connection (which is only a fraction of a full 1.54-Mbps T1 connection).
Understanding Backups
The importance of backing up data cannot be overstated. Data will be lost at some point if an organization is using computers. Hardware failures, software bugs, accidental deletions, natural disasters, and malicious attacks can all destroy or corrupt data. However, the difference between a minor inconvenience and a major catastrophe is the existence of a backup. If a reliable backup exists, personnel can restore the lost data. If a backup isn’t available, the lost data can result in significant losses.
EXAM TIP Backups are useful only if they can be restored. Organizations typically include test restore procedures in their backup plan. A test restore goes through the steps to restore data from a backup and verifies the usefulness of the backup.
A backup policy identifies the data that is important to an organization, which identifies the data personnel need to back up. Backup policies include retention policies that identify how long the organization should keep backed-up data. These policies are authoritative in nature and can help justify the purchase of backup materials. Tape drives, tapes, backup software, and dedicated backup servers can all add up to significant costs. However, if a backup policy dictates the need for the backups, the policy provides justification for the costs.
In contrast, without a backup policy, administrators will make their own decisions on what to back up based on their own experience. These decisions are often driven by recent data losses. For example, if a high-ranking user recently lost data, then administrators might decide that backing up user data is most important. However, if no user data is permanently lost over a year’s timeframe, administrators might decide that backing up user data isn’t as important. Also, without a backup policy, administrators may never test these backups until someone loses data. If the backups aren’t reliable, this is too late. The data is lost. Worse, when administrators ask for funds to replace worn-out tapes, management might decide not to approve the purchase.
A backup policy also stresses the importance of keeping a copy of backups in a separate geographical location. If backup tapes are kept with the server and a fire in the server room destroys the server, it will also destroy the backups. Even if the backups are stored elsewhere in the same building, a tornado or flood or other disaster can destroy all the backups. However, if the backups are stored offsite, they will be available even if a catastrophe destroys the site.
Traditional backups use full backups combined with either differential or incremental backups. These backups often store the backups on tapes, but the use of disks for backups is becoming more common. Backing up to tape is much slower, but it provides more data storage at an overall lower cost. As an alternative, many organizations use a disk-to-disk-to-tape strategy. This is useful when backing up online databases because the backup can slow down database performance. Administrators back up the data to a disk, taking advantage of the fast disk speed. They then back up the data from the second disk to tape.
Full Backups
A full backup simply backs up the entire contents of the target data. This is useful if there isn’t much data to back up or the data doesn’t change very often. If the backups are small, you can back up the data every day.
However, most backups are rather large and it takes a long time to back up the data and a long time to restore it. Alternatives to full backups include full/incremental backup strategies and full/differential backup strategies. If you want to minimize the amount of time that it takes to back up the data, you can use a full/incremental backup strategy. If you want to minimize the amount of time that it takes to restore the data, you can use a full/differential backup strategy. Both strategies start with a full backup.
Full/Incremental Backup Strategy
In a full/incremental backup strategy, you back up all the data to start the backup plan. Then on a regular basis you back up only the data that has changed since the last backup. For example, consider Table 9-5 as you read the following list, which describes the backups performed on each day:

Table 9-5 Full/Incremental Backup Strategy
• Full backups are completed early on Sunday morning at 1 A.M. using an automated system.
• At 1 A.M. on Monday morning, the incremental backup backs up only the changes made since the last backup (the full backup on Sunday, in this case).
• At 1 A.M. on Tuesday morning, the incremental backup backs up only the changes since the last backup (the incremental backup on Monday, in this case).
• At 1 A.M. on Wednesday morning, the incremental backup backs up only the changes since the last backup (the incremental backup on Tuesday, in this case).
• Throughout the week, the incremental backups would be about the same size.
NOTE Table 9-5 shows backups until Wednesday for brevity, but administrators would continue with the backups through the rest of the week (on Thursday, Friday, and Saturday). On Sunday the process starts again with a full backup.
If a data loss occurs, you can use the backups from Sunday and then use each of the backups from individual days to restore the data. For example, imagine that a hard drive failure occurs on Wednesday afternoon. You would restore the full backup from Sunday, then the incremental backup from Monday morning, then the incremental backup from Tuesday morning, and then the incremental backup from Wednesday morning.
Some of the recovered data would only be included in the full backup, while some of the recovered data would only be included in the backup from Tuesday, and some would only be included in the backup from Wednesday. Here a few examples:
• One person might create a monthly report but not modify it on Monday, Tuesday, or Wednesday. It would only be in the full backup.
• Another person might create a weekly report every Monday but not modify it on Tuesday, Wednesday, or any other day of the week. It would only be included in the Tuesday incremental backup.
• Help desk personnel might modify files seven days a week. Changes would be included in each incremental backup file (Monday morning, Tuesday morning, and Wednesday morning).
TIP A full/incremental backup strategy minimizes the time needed for backups during the week. However, the recovery can take longer because multiple backups typically need to be restored when recovering the data.
Full/Differential Backup Strategy
In a full/differential backup strategy, you back up all the data to start the plan, and then on a regular basis you back up all of the data that has changed since the last full backup. For example, consider Table 9-6 as you read the following list, which describes the backups performed on each day:

Table 9-6 Full/Differential Backup Strategy
• Full backups are completed early on Sunday morning at 1 A.M using an automated system.
• At 1 A.M. on Monday morning, the differential backup backs up all the changes since the last full backup on Sunday.
• At 1 A.M. on Tuesday morning, the differential backup backs up all the changes since the last full backup on Sunday, including the changes from Monday.
• At 1 A.M. on Wednesday morning, the differential backup backs up all the changes since the last full backup on Sunday, including the changes from Monday and Tuesday.
Throughout the week, the differential backups would steadily increase in size.
If a data loss occurs, you can use the backups from Sunday and then the most recent differential backup. For example, imagine data was lost due to a hard drive failure on Wednesday afternoon. You would need to restore the full backup from Sunday and then restore the differential backup from Wednesday morning.
TIP A full/differential backup strategy takes longer to back up during the week than a full/incremental strategy. However, the recovery time is reduced because a maximum of two backups are needed to recover the data.
Image-based Backups
Image-based backups create a backup of the operating system and all data. They are commonly used to back up virtual machines (VMs) but can also be used on regular computers or servers. The backup creates a single file, called an image, of the system at a point in time.
Administrators often use image-based backups before performing a risky operation such as an upgrade to the operating system or software. If the upgrade causes problems, administrators can re-create the server using the image backup.
Some image-based backups run in differential mode. After the image is captured, the backup system tracks all changes to the image until the image is removed. These differential-based images can significantly slow down the system if they’re allowed to track changes indefinitely.
Chapter Review
Security controls include both countermeasures and safeguards, and security professionals use these terms interchangeably. They are the means, methods, actions, techniques, processes, procedures, or devices that reduce the vulnerability of a system or the possibility of a threat exploiting a vulnerability in a system. The primary goals of security controls are to prevent, detect, and correct loss of confidentiality, loss of integrity, and loss of availability of a system.
Preventive controls attempt to prevent losses before they occur, detective controls attempt to detect violations either as they are occurring or after they’ve occurred, and corrective controls attempt to reverse the impact of the event. Compensating controls provide an alternative if circumstances prevent an organization from implementing a primary control. Deterrent controls encourage people to decide not to take certain undesirable actions that could result in an incident.
Control methods (or classifications) include administrative, technical, and physical. Administrative controls focus on the management of risk and the management of IT security. Technical controls are implemented using technical methods, such as hardware, software, or firmware components. Physical controls refer to the controls you can touch.
System hardening is the practice of making a system more secure from the default settings and includes removing or disabling unused services and protocols, changing defaults, keeping systems up to date, enabling firewalls, and using AV software.
Policies are high-level documents used to provide overall guidance to an organization. Standards document criteria such as a proven norm or method and are typically external to an organization, but they can influence an organization’s security policies. Guidelines and procedures are derived directly from the organization’s security policy.
Business continuity plans and disaster recovery plans are examples of response plans that help an organization respond to a disaster. Change control procedures help prevent outages due to unauthorized changes. Configuration management procedures help ensure that systems are configured similarly using baselines. Patch management procedures evaluate patches, test relevant patches, and apply relevant patches that don’t cause unacceptable problems. Automated tools audit systems to ensure patches are applied and change management systems document approved patches.
Endpoint device security typically focuses on mobile devices such as smartphones and tablets. If an organization allows employees to connect their personally owned devices to the organization’s network, it will typically create a bring your own device (BYOD) or a choose your own device (CYOD) policy and add elements of the policy to an acceptable use policy. Alternatively, an organization may opt for corporate-owned, personally enabled (COPE) devices to maintain more control of mobile devices. Mobile device management helps ensure that BYOD, CYOD, and COPE devices are kept up to date.
User awareness and training programs raise the overall security posture of an organization by helping users understand their responsibilities associated with security and reduce risky behaviors.
Fault tolerance helps eliminate outages from single points of failure by adding redundancies. Redundant disk systems (such as RAID-1, RAID-5, RAID-6, and RAID-10) allow a system to continue to function even if a disk fails. Failover cluster configurations allow a server to continue to operate even if a server fails. Load-balancing solutions spread the load among multiple servers. Redundant connections allow an organization to stay connected to the Internet or to other locations, even if a connection fails.
Backups ensure that data is not lost even if the original data is lost due to a hardware failure, software bug, accidental deletion, natural disaster, or malicious attack. Backup policies identify what data to back up, how long to retain backups, and the importance of storing backups in separate geographical locations.
Backup types include full backups, incremental backups, and differential backups. Each strategy includes a full backup, which backs up all the important data. A full/incremental backup strategy completes a full backup and then backs up only the data that has changed since the last full or incremental backup. Incremental backups are about the same size and take the least amount of time to back up. However, they can take longer to restore because multiple incremental backups may need to be included in the restoration.
A full/differential backup strategy starts with a full backup and then backs up all the changes since the last full backup without regard to what was backed up during previous differential backups. Differential backups get steadily larger because they are backing up more and more data, requiring more time to complete as the week progresses. A full/differential backup strategy is the quickest to restore because only the full and the last differential backups are needed. Image-based backups create an image of the entire operating system and all applications.
Questions
1. Which of the following provides the best definition of a security control?
A. The means, methods, actions, techniques, processes, procedures, or devices used to prevent attackers from launching attacks on systems
B. A detective method that identifies threats
C. A corrective method that reverses the impact of an incident
D. The means, methods, actions, techniques, processes, procedures, or devices used to reduce the vulnerability of a system or the possibility of a threat exploiting a vulnerability
2. Your organization is considering adding a security control. The CBA indicates that the ALE without the control is approximately 25 percent the cost of the control. Which of the following is the best choice given these results?
A. Implement the control.
B. Do not implement the control.
C. Start a configuration management request.
D. Start a change management request.
3. What are the primary objectives of security controls?
A. Prevent, detect, and correct
B. Prevent, detect, and block
C. Detect, correct, and block
D. Detect, correct, and remove
4. Which of the following security controls attempts to avoid security incidents?
A. Preventive
B. Compensating
C. Corrective
D. Detective
5. What type of security control is an audit log?
A. Technical
B. Corrective
C. Detective
D. Preventive
6. Which of the following security controls can restore a failed or disabled control?
A. Preventive
B. Corrective
C. Detective
D. Deterrent
7. What type of control are procedures to back up and restore data?
A. Administrative
B. Corrective
C. Detective
D. Deterrent
8. Which of the following choices best describes an administrative security control?
A. A control that you can physically touch
B. A control implemented using hardware, software, or firmware
C. A control that focuses on the management of risk and the management of IT security
D. A control that focuses on preventing losses due to risks
9. A computer system records events into a security log, and administrators periodically review the log for security incidents. Which of the following best describes this security control?
A. A preventive, technical security control
B. A detective, physical security control
C. A preventive, physical security control
D. A detective, technical security control
10. Which of the following tasks would administrators complete when hardening a server? (Select all that apply.)
A. Removing unneeded protocols
B. Keeping a system up to date
C. Disabling firewalls
D. Adding AV software
E. Disabling unused services
11. Of the following choices, which provides high-level guidance to employees?
A. Procedure
B. Policy
C. Action steps
D. Disaster recovery plan
12. What is the overall goal of a change management process?
A. To slow down changes
B. To ensure that systems are configured similarly
C. To enable stakeholders to deny unwanted changes
D. To reduce unintended outages from unauthorized changes
13. What should administrators do after learning that a vendor has released a patch that is relevant for servers they manage?
A. Apply the patch.
B. Test the patch.
C. Audit systems to see whether the patch is applied.
D. Document the systems where the patch is applied.
14. Which of the following helps ensure that mobile devices have all relevant patches?
A. BYOD
B. CYOD
C. MDM
D. COPE
15. Your organization has recently implemented a CYOD policy. Management wants to ensure that devices are kept up to date with current patches and fixes. Which of the following should be implemented?
A. Use a change management policy.
B. Create a list of preapproved devices.
C. Implement an MDM solution.
D. Implement a COPE policy.
16. What is an important benefit to organizations that use virtual servers? (Choose all that apply.)
A. VM escape capabilities
B. Better control of data with cloud computing
C. Reduction of costs associated with power and cooling
D. Reduction of costs for physical security
17. You have two disk drives and you want to provide fault tolerance by mirroring the two drives. What should you use?
A. RAID-0
B. RAID-1
C. RAID-5
D. RAID-6
18. You need to ensure that a service continues to run even if a server fails. What should you implement?
A. RAID-1
B. RAID-6
C. Failover cluster
D. Warm site
19. Administrators are configuring a group of e-commerce-based web servers in a load-balancing configuration. Customers need to return to the same server each time they visit within a session. Which of the following configurations will support this goal?
A. Source address affinity
B. Round-robin
C. Failover cluster
D. Incremental
20. You don’t have enough maintenance time during the week to perform full backups, so you decide to implement a backup strategy that takes less time to do backups during the week. Of the following choices, what strategy will minimize the amount of time needed to restore a backup after a failure?
A. Full
B. Incremental
C. Full/incremental
D. Full/differential
Answers
1. D. A security control provides the means, methods, actions, techniques, processes, procedures, or devices that reduce the vulnerability of a system or the possibility of a threat exploiting a vulnerability in a system. You can’t prevent attackers from launching an attack, but you can reduce their possibilities of success by either reducing vulnerabilities or reducing the impact of the threat. Security controls can be preventive, detective, and/or corrective, but it isn’t accurate to limit a control to only one of these types.
2. B. Based on the results of the cost-benefit analysis (CBA), the most likely choice is to not implement the control. A CBA identifies the cost. If the cost of the control is significantly lower than the annual loss expectancy (ALE) without the control, the cost is justified, but the scenario indicates the ALE is 25 percent the cost of the control (indicating the control cost is four times the ALE). Configuration management refers to the starting point of a system and doesn’t use configuration management requests. You would start a change management request if you planned to implement the control.
3. A. Security controls attempt to prevent, detect, and/or correct losses to confidentiality, availability, or integrity. Some preventive controls attempt to block threats, and some corrective controls attempt to remove vulnerabilities, but neither blocking nor removing is referred to as a primary objective of security controls.
4. A. A preventive security control attempts to avoid security incidents by preventing them. A compensating control provides an alternative when a primary control fails or is unavailable. A corrective control attempts to reverse the effects of an incident and can restore a failed or disabled control. A detective control attempts to detect incidents either as they are occurring or after they’ve occurred.
5. C. An audit log is a detective security control because it identifies events either as they are occurring or after they’ve occurred. Technical is a method or class of control. A corrective control acts to reverse the effects or impact of an incident. A preventive control prevents the event from occurring.
6. B. A corrective control can restore a failed or disabled control. A preventive control attempts to prevent incidents and a detective control attempts to detect incidents. A deterrent control attempts to dissuade or deter personnel from trying to circumvent security policies or otherwise cause an incident.
7. B. Procedures to back up and restore data are corrective controls because they take action to reverse the effects of data loss. Administrative is a method or class of control. Deterrent controls attempt to deter personnel from causing a security incident. A detective control identifies events either as they are occurring or after they’ve occurred.
8. C. An administrative security control focuses on the management of risk and the management of IT security. A physical control is one that you can touch. A technical control is implemented with hardware, software, or firmware. A preventive control focuses on preventing losses due to risks.
9. D. This describes an audit log, which is a detective, technical security control. It is detective because it identifies incidents after they’ve occurred. It is technical because it is implemented with technology. It doesn’t prevent the events, and the log is a digital file, not a physical item that you can touch.
10. A, B, D, E. Some common steps when hardening a server include removing unneeded protocols, keeping a system up to date, adding antivirus (AV) software, and disabling unused services. Disabling firewalls is not a method used to harden a server.
11. B. Policies provide high-level guidance to employees and are authoritative in nature. Procedures include action steps to accomplish tasks. A disaster recovery plan can include one or more procedures to use in response to a disaster.
12. D. The overall goal of a change management process is to reduce unintended outages from unauthorized changes. The intent isn’t to slow down changes, but that is often a side effect. A change management process gives stakeholders the ability to propose changes, but several entities within the organization grant or deny changes. A configuration management process ensures that systems are configured similarly.
13. B. Administrators should test patches before applying them to detect potential problems. If the patch is applied as soon as it is released, it can result in unforeseen problems. Systems are audited after the patch is applied to ensure that the patch was successfully applied. Change management and configuration control procedures are used to document patches.
14. C. Mobile device management (MDM) solutions help ensure that mobile devices (such as smartphones and tablets) have all relevant patches. A bring your own device (BYOD) policy allows employees to bring their own devices to work and connect them to an organization’s network. A choose your own device (CYOD) policy is similar to a BYOD policy, but employees can only connect devices on a preapproved list. Corporate-owned, personally enabled (COPE) devices refer to mobile devices that an organization purchases and issues to employees.
15. C. A mobile device management (MDM) solution can manage mobile devices that connect to an organization’s network. This includes ensuring they are kept up to date with current patches and fixes. None of the other answers ensures that devices are kept up to date. A change management policy would be used to approve changes before they are deployed. A choose your own device (CYOD) policy includes a list of preapproved devices. A corporate-owned, personally enabled (COPE) policy is different from a CYOD policy.
16. C, D. Organizations often use virtualization to reduce costs associated with power and cooling and associated with physical security. Virtualization requires fewer physical servers to power, cool, and physically secure. Virtual machine (VM) escape is one of the biggest risks associated with virtual servers. Virtual servers can be used with cloud computing, but cloud computing reduces control of data.
17. B. RAID-1 provides fault tolerance by mirroring two drives. RAID-0 does not provide fault tolerance. RAID-5 uses three or more drives. RAID-6 is an alternative to RAID-5 and uses four or more drives.
18. C. A failover cluster includes two or more servers (called nodes), and if one server fails, the other server can handle the load for that server. RAID-1 and RAID-6 provide fault tolerance for disk drives. A warm site is a type of alternative site used to provide fault tolerance for an entire location.
19. A. A source address affinity configuration uses the customer’s IP address to ensure the customer returns to the same web server during a session. A round-robin configuration directs connections to the servers, one after another. A failover cluster provides fault tolerance, not load balancing. Incremental refers to a backup strategy.
20. D. A full/differential backup strategy takes the least amount of time to restore because it will require only two backups to restore: the full backup and the last differential backup. The scenario says that there isn’t enough time to do a full backup during the week, and you can’t do an incremental backup by itself. A full/incremental would require you to restore the full backup and each of the incremental backups since the last full backup, which usually requires restoring more than just two backups.