
CHAPTER 11
Security Operations
In this chapter, you will learn about
• Data classifications such as Confidential, Sensitive, Private, and Public
• The importance of marking and labeling data with its classification
• The difference between data at rest and data in motion
• Different elements of data management policies
• Components of a database such as tuples, rows, primary keys, and foreign keys
• Risks related to data inference and data diddling
• Regulatory requirements related to PII and PHI
• Asset management components
• The differences between certification and accreditation
• The Common Criteria and its evaluation levels
• Using a risk management framework with a certification and accreditation process
• Different phases of a system development lifecycle
Handling Data
Data is one of the most valuable resources an organization has, so it’s important to understand the value of data and some of the risks related to data. Different types of data have different values, so an organization protects data based on its value. Highly classified or sensitive data requires a higher level of protection. Similarly, when an organization no longer needs particular data, it uses one of several different methods to destroy the data depending on its value.
Classifying Data
One of the first steps in protecting data is identifying what data needs protection by classifying it. For example, an organization will often take additional steps to encrypt and protect highly classified data, such as research and development data that took years to develop. However, data published in company brochures or company websites does not deserve the same level of protection. By classifying data, it becomes easier for anyone within the organization to identify its worth to the organization and the level of protection it deserves.
For example, the U.S. government classifies data using terms such as Top Secret, Secret, Confidential, and Unclassified. The higher the classification, the more protection it requires. These aren’t the only U.S. government classifications, but they provide a good example. The following list shows the definitions assigned to each of these classifications:
• Top Secret The public disclosure of Top Secret material could cause exceptionally grave damage to U.S. national security.
• Secret The public disclosure of Secret material could cause serious damage to U.S. national security.
• Confidential The public disclosure of Confidential material could cause damage to U.S. national security.
• Unclassified The public disclosure of Unclassified material will not cause damage to U.S. national security. People can obtain information in this category through the Freedom of Information Act.
To have access to any of the classified material, an individual must have the associated clearance. For example, someone with a Secret clearance may be able to view Secret material, but not Top Secret material.

TIP The principle of need-to-know is widely used to protect data. For example, just because individuals have a Secret clearance doesn’t mean they can access all Secret material. The clearance level only indicates they are cleared to view the material if their job requires it, but it does not automatically grant access to the material. If their job does require access to the material, an administrator grants them appropriate access.
Many private organizations also classify data, although they rarely use the same Top Secret, Secret, Confidential, and Unclassified labels used by the U.S. government. An important point to remember is that organizations can use any labels they desire. For example, an organization can use Class 0, Class 1, Class 2, and Class 3. However, end users might find them to be a little mysterious. What’s the highest classification, Class 0 or Class 3? One organization might say Class 0 is highest, and another organization might say Class 3 is highest. Of course, both organizations are correct, because the organization defines the labels in a security policy or data policy.
Data owners are responsible for identifying data classifications. In civilian organizations, data owners are typically the chief executive officer (CEO), chief information officer (CIO), and/or department heads. A data owner ensures that a security policy or data policy includes the labels and accompanying descriptions.
Here are some examples of data classifications that organizations can implement, listed from highest classifications to lowest:
• Confidential, Private, Sensitive, Public
• Proprietary, Internal Use Only, Sensitive, Public
• Private Highly Restricted, Private Restricted, Private, Unrestricted
• Highly Confidential, Restricted, Private, Public
• Regulatory, Confidential, Internal Use Only, Public
• Confidential, Restricted, Internal Use Only, Public
• Highly Confidential, Restricted, Private, Unrestricted
Figure 11-1 shows the Confidential, Private, Sensitive, and Public labels that any organization can use. It also includes possible definitions that an organization can use within its security policy or data policy. Notice that Confidential data is at the core and deserves the highest level of protection.
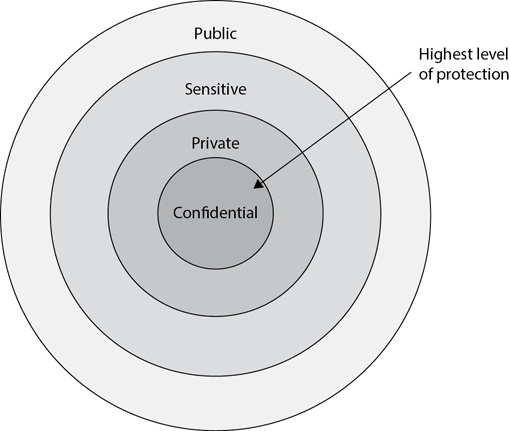
Figure 11-1 Data classifications used by some organizations
• Confidential This includes proprietary information central to the operation of a company. It could include research and development information for upcoming projects, trade secrets for products sold by the company, and so forth. If someone discloses an organization’s confidential data, it could result in an exceptionally grave negative impact on the mission of the organization.
• Private This includes information used privately within the company, such as employee records and customer data. Private data is intended for internal use only, and if it is disclosed, it could result in a serious negative impact on the mission of the organization.
• Sensitive This includes information that requires special precautions for its protection, such as financial information about a company. If someone discloses sensitive data, it could result in a negative impact for the organization.
• Public This is data that is either publicly available or would not cause any harm if it was publicly available. If disclosed, this data would not have any negative impact on the organization.
TIP Organizations aren’t required to use any specific data labels and there isn’t a universally accepted standard, so it’s entirely possible an organization could have different labels or define these a little differently. The important thing to grasp is that organizations do classify material and provide higher levels of protection for data that requires it.
Marking and Labeling Data
After identifying data classifications, personnel mark or label the data. In general, marking refers to using digital methods to identify the data classification. Labeling refers to using physical labels to identify the data classification. This ensures that users can immediately identify the classification files and media holding the files. For example, after printing classified data, users may be required to place it within a folder with a cover sheet indicating the classification of the data. Digital files can include watermarks, headers, or footers that show the classification so that it is easily identifiable after a user prints it.
It’s also important to label hardware that holds or processes classified information. This includes portable media such as USB drives and tapes, cabinets where portable media is stored, and computer systems that process classified data. Organizations commonly use color-coded stickers with the classification name. As an example, they could use red stickers with the label Proprietary. This allows employees to identify the classification based on the name and the color of the label.
An alternative is to purchase a large quantity of drives (such as red USB drives) and train employees to use only these drives for classified data. It’s also possible for administrators to configure technical policies to encrypt data on these drives automatically. These technical policies identify the drives using a universally unique identifier (UUID).
Roles and Responsibilities
Multiple people within an organization have different responsibilities for how data is handled, and those responsibilities can be identified by their role. Some of the common roles and responsibilities are
• Management Personnel in management and leadership positions define the data classifications and specify the requirements to protect data with different classifications. A data policy or security policy includes these definitions, and management personnel ensure the policy is available to everyone within the organization.
• Data owner Data owners have primary responsibility for protecting the data based on its classification and requirements stated within a security policy. When data owners create data, they identify the appropriate classification and mark or label the data according to requirements dictated in the data policy. They periodically review the data and modify the classification if necessary based on changes within the organization.
• Custodian In some cases, the data owner delegates various data-related tasks to a data custodian. For example, a data custodian could perform regular backups of the data based on requirements stated within a backup policy.
• Administrator Administrators use available access control mechanisms to provide access to the data to personnel who need access. For example, administrators assign permissions to personnel to grant access, typically by direction from the data owner.
• User Users access the data. Users are also responsible for protecting the data they handle.
TIP Data owners are ultimately responsible for protecting the data. This includes ensuring that it is marked or labeled correctly and that security controls match the requirements of the data classification.
Protecting Data from Cradle to Grave
Personnel protect classified data from the moment someone creates it until someone destroys it. The level of protection is based on the classification. If classified data is stored or processed on a computer system, then the system must be protected at least at the same level as the classified data. Similarly, if classified data is transmitted over a network, all access points on the network must also be protected to at least the same level.
If a system or hard drive fails, it’s important to remove all remnants of data before disposing of it. For example, just because a hard drive fails during normal operation, that doesn’t mean that all the data on the drive is inaccessible. Experts working in a clean room can open failed disks and often retrieve data remnants. Although using a clean room to access data on a failed disk is expensive, it can be worthwhile to attackers if they can retrieve sensitive data.
TIP The “Removing Data Remnants” section later in this chapter covers various methods of removing residual data.
Data at Rest and Data in Motion
Data at rest is any data that is in computer storage, such as on system hard drives, portable USB drives, flash drives, storage area networks, backup tapes, and so on. Data in motion (sometimes called data in transit) is any data transmitted over a network. This includes data transmitted over an internal network using wired or wireless methods and data transmitted over public networks such as the Internet.
Encryption is often used to protect data at rest and data in motion. Encryption converts plain-text data into cipher text, making it unreadable until it is decrypted. Strong encryption algorithms ensure that unauthorized entities are unable to read encrypted data.

EXAM TIP Encryption protocols such as Advanced Encryption Standard (AES) encrypt data at rest. Protocols such as Transport Layer Security (TLS) and Internet Protocol security (IPsec) protect data in motion. Chapter 14 covers these and other encryption protocols.
Additionally, access control methods such as strong authentication and authorization practices help to protect data. Access controls help ensure that only authorized people have access to a network where data is stored and transmitted. However, access controls aren’t useful when transmitting data over a public network.
It’s also important to protect data during active processing (data in use), and this is a function of the application processing the data. For example, imagine a web application retrieves customer data from a database, including credit card data, to process a purchase. Application developers often use specific buffers for sensitive data and purge these buffers when the data is no longer needed. In this example, the data goes through several stages:
• Data at rest• Sensitive data is stored in an encrypted format within the database. However, the database decrypts it before sending it to the web application.
• Data in motion• The web server and database server create a secure channel to transfer the data. For example, they can use TLS to encrypt the sensitive data while transmitting it over the network.
• Data in use• The web server decrypts the sensitive data and the web application processes it in an unencrypted format. When the web application is done with the data, it clears the data buffers holding this data.
Data Management Policies
Many organizations implement data management policies to help employees understand the value of different types of data. These policies also identify methods of protecting sensitive data. These policies help an organization protect data from unauthorized disclosure and misuse throughout the lifetime of the data. The following subsections identify some of the common elements of data management policies.
Storage Media
Storage media refers to how data at rest is stored. It can refer to data on hard drives, solid state drives (SSDs), portable USB drives, USB flash drives, optical disks, backup tapes, or any other media storing data. Data management policies may restrict the use of some media and require special handling of any media that holds sensitive data.
One of the biggest risks of most storage media is that it’s highly portable. It’s very easy for someone to copy mass amounts of data onto the media, and the organization can lose control of it. For example, a malicious insider can steal valuable data by copying it onto a portable USB drive. It’s also possible for an honest employee to lose a USB flash drive after copying data onto it.
A common way to protect the confidentiality of sensitive data on storage media is with encryption. For example, many USB drives are available that automatically encrypt data when users copy data to them. Several technical security controls allow administrators to configure whole disk encryption for portable devices, and hard drives within computer systems.
In addition to encryption, the media should be labeled to indicate the highest classification of data stored on the media. When the media is not in use, employees should secure it in a storage cabinet or safe.
Transmission
Data transmitted over a network is data in motion. Attackers can use sniffers or protocol analyzers (covered in Chapter 5) to capture and read the data transmitted in cleartext. However, encrypting sensitive data before transmitting it thwarts a sniffing attack. Data management policies dictate the minimum encryption methods of specific types of data.
Chapter 3 introduced several encryption protocols that encrypt data before transmission. Secure Shell (SSH) is often used to encrypt traffic such as Telnet and File Transport Protocol (FTP) on internal networks. IPsec can be used to encrypt traffic in internal networks and traffic sent over the Internet, such as with virtual private networks (VPNs). TLS is commonly used to encrypt data transmitted over the Internet, such as with Hypertext Transport Protocol Secure (HTTPS).
Archiving and Retention Requirements
Archiving refers to making a backup of data and keeping it for long-term storage. Chapter 9 covers backup strategies in more depth. Retention refers to how long archives and other data are kept. Data policies often identify both archiving and retention requirements.
Laws or regulations may require an organization to keep data for a minimum timeframe, and sometimes indefinitely. For example, laws in the United States require that e-mails sent to and from officials in several U.S. public offices be kept forever. These archives are kept for historical purposes. Similarly, many banking regulations require institutions to keep certain data for three, five, or seven years.
Retention requirements also identify how long to retain backups. For example, an organization can decide to keep copies of backups for the last three years or the last 30 days. Many factors go into these decisions, and an important one is cost. The number of backup tapes required to keep archive copies of backups for the last three years can be quite high.
Additionally, many companies consider legal consequences of long-term storage of data. For example, a court order might direct a company to turn over all e-mail sent or received by a certain individual over the last five years. However, if the company retention policy states that e-mail is only kept for a year, the company only needs to retrieve e-mails from the last year. This assumes that personnel are following the policy and the company has only a year’s worth of e-mails. In contrast, if the organization retains e-mail for five years, IT personnel will have to sift through five years of e-mails to comply with the court order. This can be time consuming and labor intensive.
Removing Data Remnants
Data remnants refers to the residual data left on media. Data management policies usually include information on how to eliminate data remnants. This allows personnel to reuse the media or safely dispose of the media without losing confidentiality of the data. Methods of eliminating data remnants include sanitizing (or purging) the media and destroying it.
TIP Residual data is sometimes referred to as data remanence. However, remanence technically refers to residual magnetic flux on traditional hard drives. It does not apply to other media such as CDs, DVDs, and solid state drives.
• Sanitizing (or purging) Sanitization methods remove all residual elements of data, preventing someone from accessing it. After sanitizing media, personnel can reuse it or dispose of it.
• Destruction In some cases, sanitizing methods are not reliable enough, so personnel destroy the media instead. For example, if media holds highly classified data, an organization’s data policy may require personnel to destroy the media instead of using methods to purge it of all data remnants.
If employees throw paper documents into the trash, dumpster divers can retrieve them. Instead, employees should destroy paper documents containing sensitive data either by passing them through a crosscut shredder or by burning them in an incinerator. It’s important to use a crosscut shredder because it cuts the paper into smaller pieces that resemble confetti. In contrast, strip-cut shredders cut the paper into long strips, which a patient attacker can reconstruct more easily.
Most administrators understand that simply deleting a file or formatting a drive doesn’t remove the data. Someone with the right software and a little bit of expertise can often retrieve the data. To combat this, organizations implement different procedures to remove data. In some cases, an organization approves a specific application to write a pattern of ones and zeros to remove data. These programs can “shred” a single file by overwriting it, or completely erase the entire disk by overwriting it.
Magnetic-based media such as traditional hard drives and backup tapes store data by magnetizing elements of the media. Degaussing uses a powerful magnet to remove data and is an effective method of sanitizing backup tapes. You can also degauss hard drives, and this usually destroys the drives. Optical media such as DVDs and CDs do not use magnetic methods, so degaussing does not remove data from this type of media. Similarly, degaussing won’t remove data from an SSD because SSDs use integrated circuitry instead of the magnetic flux used on hard drives. Instead, optical media and SSDs must be physically destroyed.
SSDs present a serious risk to an organization when it is sanitizing systems. If you put a traditional hard drive next to an SSD, they look the same. Personnel might think that they can degauss both and then throw them away. However, the SSD will still hold all the data.
When destroying media, the goal is to ensure it is unusable, which is the most secure method of protecting confidentiality of data. Destruction methods include shredding it (for media such as optical media) and burning or incinerating it (for backup tapes). Policies often require personnel to open hard drives and destroy the platters. For example, personnel can remove the platters and send them through large shredders or incinerate them.
TIP Data policies identify how to destroy data and eliminate data remnants. It’s common to degauss backup tapes to remove data. Programs that repeatedly write a series of ones and zeros onto a drive overwrite or shred files.
Deduplication
It’s common for multiple individuals to have a copy of the same file. If this file is stored in multiple locations, it can take up a significant amount of wasted storage space. Deduplication refers to ensuring that a file is stored only once on a system, even if multiple users have access to the same file.
For example, employees commonly have private shares on servers where they can store their data. Imagine if 100 employees have shares on the same server, and each employee has a copy of a 5MB company policy document. This single file takes up 500MB of space if there are 100 separate copies of it. In contrast, with deduplication the file will be stored only once and take up only 5MB of storage. Each employee will appear to have a copy of the document in their private share. However, the file that the employees see acts as a pointer to the single document.
Additionally, many deduplication systems support multiple versions of the same file without keeping multiple copies of the file. Consider the same 5MB file. If five users make slight modifications to their copy, a deduplication system can record their changes in separate files. The system keeps the original 5MB file intact. If any of these five users opens the file, the system applies the changes that the specific user has made to the file. This is all automatic and often done without the user’s knowledge.
There is a trade-off between deduplication and encryption. If the files are encrypted (and the deduplication software cannot decrypt them), then the deduplication software cannot identify any two files that are the same. While there are methods of weakening the encryption so that the deduplication software can identify identical files, this sacrifices security. Any method of weakening the encryption increases the possibility that an attacker can decrypt the data. Unless you weaken security in encrypted files (certainly not recommended), you’ll rarely see gains from deduplication software.
Data Loss Prevention
Data loss prevention (DLP) systems attempt to monitor data usage and prevent the unauthorized use or transmission of sensitive data. Different types of DLP systems can monitor data in motion and data at rest.
Network-based DLP devices have the ability to scan all traffic that exits a network. This includes e-mail and attachments. These devices can look for specific data and block it before it leaves the network.
For example, a company may want to ensure that e-mail or attachments never include Social Security numbers. A Social Security number is in the format of xxx-xx-xxxx. The device can scan all outgoing traffic looking for this match. When it detects a match, it blocks the traffic from leaving the network and sends an alert to an administrator. Similarly, if a company uses classification labels such as Confidential, Private, and Sensitive, it can configure the device to look for these words along with any other words or patterns of interest.
Some DLP solutions can limit the use of hardware. For example, an organization may want to prevent users from copying certain data to external USB drives or printing this data to a printer. The DLP software scans the data before copying it or sending it to the printer. If it includes restricted data, such as Social Security numbers or specific classification labels, the DLP software blocks it.
Software DLP methods have the ability to scan data stored on a system to detect inappropriate data. As a simple example, an application can scan data stored on a shared server, looking for MP3 files or other data types that the company has stated should not be stored there. These applications can monitor all data stored on a system and periodically provide reports to administrators.
DLP systems can usually perform deep inspection of the data. For example, even if several files are embedded in a ZIP file or other archive file type, the DLP system can still extract the data to inspect it.
EXAM TIP Data loss prevention (DLP) systems help prevent data from leaving a network. A network-based DLP can scan all traffic looking for specific data and block transmissions when it detects restricted data transmissions.
Social Network Usage
Social networks also present risks related to the loss of data. These include sites such as Facebook, Twitter, and LinkedIn.
Chapter 5 mentions some of the risks with social networking sites in the context of social engineering and phishing. Attackers frequently send phishing messages to users of social networking sites, attempting to trick them into following a link to a malicious website or downloading malicious software. However, there are additional risks associated with data from social networking sites.
For example, a chain letter was floating around asking people on Facebook to list ten things about themselves that others don’t know. It included questions about the person’s favorite things (like favorite color or favorite movie), the school(s) from which they graduated, and the name of their first pet. Users were encouraged to fill out the questionnaire, send it back, and forward it to ten of their friends.
TIP Many websites use cognitive passwords created with multiple personal questions during registration. When users want to retrieve a forgotten password, the system queries them with these questions. As long as users answer the questions correctly, the system allows them to reset their password.
People who answered were at risk of giving out their answers to secret questions at banks and other online sites. For example, if you forget your password or log on to a bank’s website from a different computer, the site will often challenge you. You’re required to give the name of your first pet, for example, and if you can answer correctly, the system grants you access. If attackers have this information, they can use it to hack into your accounts.
Employees can accidentally provide inside information about their company when they spend time on these social networking sites. Because of the potential damage, many organizations prohibit the use of these types of sites on company computers. The rules are spelled out in acceptable use policies, which employees read and acknowledge at least once a year.
Individuals are often tricked into giving up highly personal information on themselves. As an example, Cambridge Analytica reportedly published one or more personality quizzes that captured information on over 50 million Facebook users as early as 2015. Users responded thinking it would be fun to get a free analysis of their personalities. However, Cambridge Analytica allegedly used this information to target ads to users based on their responses. While Cambridge Analytica’s practices made the headlines, many organizations are using similar practices to capture data about users.
Social media sites are free to use, and when they’re well designed, they can become quite popular. Facebook reportedly has over 2 billion users worldwide. And while the site is free to users, it’s worthwhile remembering the old phrase “if you’re not paying for the product, you are the product.” While the phrase doesn’t apply 100 percent to all free sites, it is worth remembering any time users are asked to provide personal information on themselves.
Information Rights Management
Information rights management (IRM) refers to the different methods used to protect sensitive information from unauthorized access. IRM is a subset of digital rights management (DRM). DRM is much broader and typically refers to protecting media such as music and video. IRM focuses on documents. It allows people to specify access permissions to different documents that they share, even after the documents leave their control.
For example, a user can protect a document with IRM before e-mailing it to an associate at a different company. IRM permissions can be applied to the document before it is sent, restricting what the recipient can do. IRM can prevent recipients from forwarding, copying, modifying, printing, faxing, or pasting the content if that’s what the sender wants to restrict. It’s also possible to restrict users from copying the content using the Print Screen functionality and to set expiration dates on files. After the expiration date, users are unable to open the file.
Understanding Databases
Databases are stores of information that users can easily access and modify as needed. Large databases require sophisticated database management systems (DBMSs) to manage database access. Some common DBMSs in use today include products from Oracle, IBM, and Microsoft. These systems provide access to relational databases.
Understanding Database Tables
In a relational database, data is stored in tables, and this data is linked to other tables based on predefined relations. As an example, Figure 11-2 shows a Parts table and a Suppliers table with different elements identified. The Parts table holds information on parts, such as parts used for manufacturing a bicycle. The Suppliers table holds information on the company that supplies these parts. The SupplierID field links the two tables.
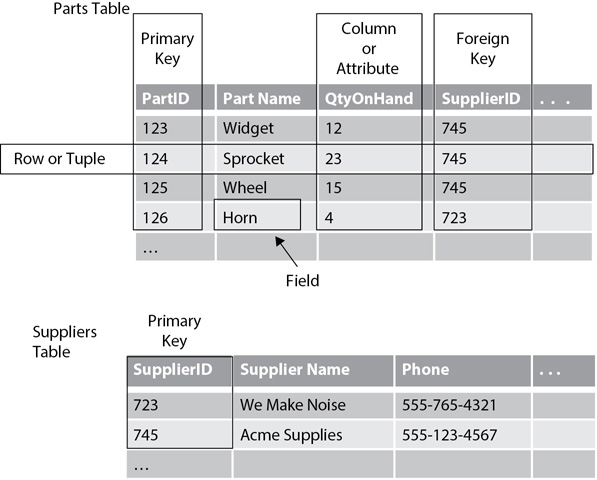
Figure 11-2 Tables in a database
TIP Actual databases will have many more than just two tables. Many production databases used within organizations have hundreds of tables. A data dictionary describes the purpose of each table and its relationship with other tables. The ellipsis (…) in Figure 11-2 indicates that the table can have many more columns and many more rows, but for brevity, the figure only shows a few of the columns and rows. Some tables have dozens of columns, and they can have millions of rows.
Key elements of relational databases include the following:
• Primary key The primary key is used to uniquely identify each row or tuple. It ensures that each item has only a single row and that the item can easily be identified using the primary key. A primary key is normally an integer, but it can be any string of characters. In the Parts table, the primary key for the sprocket is 124, which will always reference the sprocket part and nothing else.
• Row or tuple Each row, or tuple, contains a unique data element. For example, the row for a sprocket identifies details about a sprocket identified with a primary key of 124. The row also identifies how many sprockets are currently on hand in the QtyOnHand column.
• Column or attribute Columns, or attributes, provide additional details on the data. For example, the Parts table could have additional columns, such as the cost of the part, a description, the color, and more.
• Foreign key A foreign key provides a relationship to another table. Notice that three of the parts have the same SupplierID of 745. The Suppliers table has the details of the supplier with a SupplierID of 745 (Acme Supplies). The foreign key in the Parts table points to the primary key in the Suppliers table. This allows you to enter the details for the suppliers once in the Suppliers table, instead of multiple times (in each row of the Parts table).
• Field A field provides an individual piece of information within any row or tuple. For example, the field that matches the primary key of 123 and the Part Name is Widget.
Understanding Relations
Tables are related to each other using the primary and foreign keys. The primary key ensures that each row or tuple within a table is unique. The foreign key in one table points to a unique primary key in another table to create the relationship. For example, Figure 11-3 shows the foreign key in the Parts table linked to, or related with, the primary key in the Suppliers table.
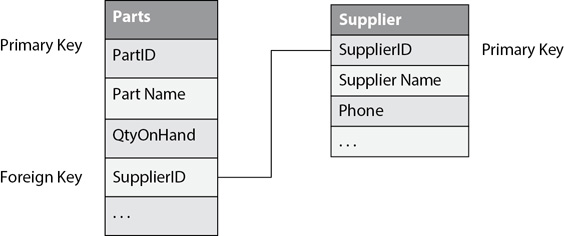
Figure 11-3 Table relationships
One of the benefits of the primary key and foreign key relationship is that data doesn’t need to be repeated. For example, if you look back at Figure 11-2, you can see that the supplier with a SupplierID of 745 is supplying the first three parts. The Suppliers table shows that SupplierID 745 is Acme Supplies. If you entered all of the information on Acme Supplies (such as name, phone number, address, sales contact, and so on) in each row of the Parts table, it would become a lot of needless work. You would have to repeat the same information in each of the rows, and each time that you reentered the data in a different row, the likelihood of making mistakes would increase.
However, by creating the relationship between the tables, you need to enter the data only once. If any of the data on Acme Supplies ever changes (such as a different sales contact or phone number), you only need to make the change once in the Suppliers table. If the supplier data were within the Parts table, you’d need to make the change in every relevant row or tuple of the Parts table.
Data normalization is the process of separating data into multiple related tables to reduce duplication of data. Duplicating the same data in more than one table creates dual entry (or multiple entry) problems, but data normalization eliminates these issues.
EXAM TIP Rows within a database are known as tuples. A primary key uniquely identifies each row in a table. A foreign key in one table points to a primary key in another table to link the tables together through a common relationship.
Using Views
One way that databases provide security is with views. A view is a virtual table that provides access to specific columns in one or more tables. It doesn’t actually hold any data but presents the data in the underlying table or tables. A database administrator can grant access to a view without granting access to a table, thereby limiting what a user can see and manipulate.
For example, imagine that people in the company need to access phone numbers for employees and this information is contained within a table named Employee in a company database. However, the Employee table holds more information (such as salary data), and administrators don’t want to grant users access to this additional information. Instead of granting access to the table, a database administrator can create a view and grant users access to the view, as shown in Figure 11-4.
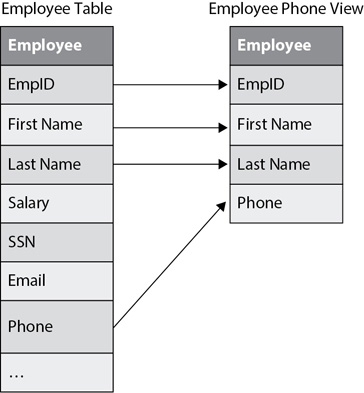
Figure 11-4 Database view
Notice that the Employee table has other information such as salary and Social Security number (SSN) data that should remain confidential. The view shows several columns from the table, including the employee’s name and phone number, without showing the confidential data.
Additionally, database administrators can grant access based on the users’ needs. For example, an administrator can grant access for users to read or modify the data in the view. A key point is that users will only be able to read and modify columns in the view. When users modify data in a view, they modify the data in the underlying table. However, the view still restricts their access to other columns in the underlying table.
Communicating with Databases
Relational databases have their own language used to communicate with them, known as Structured Query Language (SQL). Although different companies often include their own unique additions to enhance SQL, they share some commonalities. SQL statements are primarily divided into two categories:
• Data Definition Language (DDL) DDL statements are used to create the structure of the database, including tables, primary keys, and relationships among the tables.
• Data Manipulation Language (DML) DML statements are used to add, modify, retrieve, and delete data from the databases. For example, a SELECT statement retrieves data, an INSERT statement adds data, an UPDATE statement modifies data, and a DELETE statement deletes data.
OLTP vs. OLAP
Databases are organized differently depending on how they’re used. There are two primary methods:
• Online transaction processing (OLTP) E-commerce websites that access backend databases use OLTP. For example, each time a user makes a purchase, the web application records the transaction in the database as it occurs. OLTP databases need to be quick, and data normalization is one technique that ensures they provide the best performance. Additionally, OLTP databases record all transactions in logs before making the changes in the database. This allows the database management system to easily reverse failed transactions before writing them to the database.
• Online analytical processing (OLAP) Many organizations have very large databases known as data warehouses. Retrieving usable data from these data warehouses often requires additional steps. OLAP reorganizes data from data warehouses into multidimensional cubes for easier retrieval of useful information. These cubes are not normalized, but instead include redundant data. They are typically slower than OLTP databases, but speed isn’t the most important consideration. However, business managers are able to access a significant amount of information and convert it into actionable data from OLAP databases. For example, a manager might want to compare how many blue widgets the company sold last December to how many green widgets the company sold last December. This helps the manager determine how many widgets of each color to preorder for this December. This process is also known as data mining.
Data Inference
One of the security issues with data is data inference, the ability of someone to gain knowledge by piecing together unclassified data to determine classified or secret information.
As an example of data inference, the U.S. Air Force once had a problem with snipers taking potshots at jets as they flew sorties out of a certain airfield in a foreign country. The Air Force sent patrols out when sorties weren’t planned, but the snipers only appeared when the jets were flying sorties. Even though the times and dates of the sorties were highly classified, the enemy learned of these sorties by accessing unclassified information.
Because the times and dates of the sorties were not consistent from day to day or even week to week, pilots and crew were notified when to report to work through schedules posted on a bulletin board. A foreign worker was able to view these bulletin boards and passed the information on to other foreigners working as spies collecting information. The spies were able to deduce that the posted work times corresponded to the times of the sorties. Although this is a lesson that is sometimes forgotten, military organizations recognize that any piece of information can be valuable to an enemy and take steps to protect all information. The U.S. Navy had a simple phrase to emphasize this during World War II, “loose lips sink ships,” as part of a larger campaign known as “careless talk costs lives.”
EXAM TIP Data inference attacks attempt to collect public or unclassified pieces of information to predict or guess an outcome. They can also attempt to gather large quantities of information and attempt to learn details of the information through deduction.
Data inference can sometimes work in the reverse also. In other words, if people have access to summary data (also called aggregate data), they can sometimes use this to learn details. For example, if personnel in accounting have access to total payroll data for any given day, they wouldn’t necessarily know the actual pay for an individual. However, examining the total pay for the day before a person is hired with the total pay the day after a person is hired may allow someone to deduce the actual pay of the new hire.
Data Diddling
Data diddling is the unauthorized changing of data before entering it into a system or while entering it in a system. It is a form of fraud, and anyone involved with data entry has the opportunity to change it.
As an example, imagine Bob works in accounting and handles payroll. He is responsible for manually approving and entering overtime hours for employees. While entering the data, he adds more hours for his friend, which increases his friend’s paycheck. Similarly, he and his friend could decide to do this together. Bob would increase his friend’s overtime hours, and his friend would give him half of the extra pay.
Regulatory Requirements
Laws mandate the protection of some data. This includes personally identifiable information (PII), health- or medical-related data, and other types of data. This section covers some of the regulatory requirements related to different types of data.
Personally Identifiable Information
PII is information that personally identifies an individual. The National Institute of Standards and Technology (NIST) Special Publication (SP) 800-122, Guide to Protecting the Confidentiality of Personally Identifiable Information (PII), defines PII as
any information about an individual maintained by an agency, including:
(1) any information that can be used to distinguish or trace an individual’s identity, such as name, Social Security number, date and place of birth, mother’s maiden name, or biometric records; and
(2) any other information that is linked or linkable to an individual, such as medical, educational, financial, and employment information.
Although this definition is focused on a federal agency, it applies equally well to any organization that holds information on employees or customers that can identify an individual personally. This also extends to information such as credit card data, any type of account access data, and driver’s license numbers.
Several laws mandate the protection of PII, and if an attack compromises PII, organizations have a responsibility to inform the affected individuals. Some businesses consider these laws unnecessary and a barrier to business growth because they add expenses. On the other side of the fence, some people suggest that without laws forcing companies to disclose this information, they may not readily do so.
EXAM TIP Several laws mandate the protection of PII. Companies face serious fines if they do not protect PII. Additionally, if a data breach occurs, companies are obligated to let customers know of the breach.
As an example, Equifax suffered a significant data breach in 2017 exposing private data for as many as 143 million people. In March 2018, Equifax reported that as many as 2.4 million additional Americans had partial driver’s license information exposed. This partial driver’s license information wasn’t as sensitive as the private data exposed in the 2017 data breach. The following list provides a rough timeline of the incident:
• May 14, 2017 Attackers breached Equifax servers.
• July 29, 2017 Equifax detected the security breach.
• July 30, 2017 Administrators patched the vulnerability.
• September 7, 2017 Equifax officially announced the security breach.
• September 11, 2017 U.S. senators asked Equifax to provide information on the attack.
• September 13, 2017 The Equifax CEO testifies before Congress.
• September 14, 2017 The Federal Trade Commission (FTC) states it is investigating the incident.
• September 26, 2017 The Equifax CEO retires.
• September 27, 2017 San Francisco is the first city to sue Equifax for failing to notify consumers in a timely manner.
The company ultimately faced over 70 class-action lawsuits for not protecting PII and not reporting the data breach in a timely manner. They also were also investigated by the Consumer Financial Protection Bureau, the House Financial Services Committee, the Senate Finance Committee, the New York Attorney General, and the New York Department of Financial Services.
This example raises a question that people have often debated after a data breach: Did Equifax reveal the information due to legislative requirements or out of genuine concern for its customers?
HIPAA
The Health Insurance Portability and Accountability Act (HIPAA) of 1996 mandates protection of health-related data within the United States. Prior to HIPAA becoming law, it was possible for just about anyone to call your doctor to ask for information on your health, and the doctor’s office may have given it out freely. Today, any organization that gives out health-related data about a patient without authorization is subject to serious fines.
HIPAA identifies protected health information (PHI) as any information concerning the health status, provision of health care, or payment of health care for an individual. Although this primarily affects medical organizations such as hospitals, laboratories, and doctor’s offices, it also extends to other, nonmedical organizations. For example, any organization that offers a health care plan and collects information about employees related to the plan also falls under the HIPAA rules.
EXAM TIP HIPAA covers any U.S. organization that processes health information. Failure to follow the requirements of HIPAA can result in significant fines and penalties.
SOX
The Sarbanes-Oxley (SOX) Act of 2002 mandates specific protections for data related to publicly held companies (companies registered with the U.S. Securities and Exchange Commission). SOX requires high-level officers (such as CEOs and CFOs) to verify personally the accuracy of financial data. Part of the goal is to prevent some of the fraud that was apparent in companies such as Enron and Tyco International.
For example, the Enron scandal resulted in a loss of $11 billion to shareholders after the company’s stock price plummeted from over $90 per share to less than $1 a share when it went bankrupt. Many experts attributed the failure to corrupt accounting practices. Later, several Enron executives were indicted and sentenced to prison.
Because the officers must personally verify the data, organizations are required to take extra precautions to ensure the accuracy and integrity of the data. Both internal and external audits are also required to ensure that these publicly held companies are in compliance.
GDPR
The General Data Protection Regulation (GDPR) is a European Union (EU) regulation. It supersedes the Data Protection Directive (also known as Directive 95/46/EC). Both mandate the protection of personal data of EU residents. The GDPR was adopted in April 2016 and became enforceable in May 2018. The transition period was intended to allow organizations to adopt relevant practices to comply with the law.
A primary purpose of the GDPR is to protect personal data of EU residents and it strictly restricts the transfer of data of EU residents outside of the EU. Organizations that collect or process personal data on EU citizens must comply with all elements of the GDPR, and this includes organizations that operate outside of the EU. As an example, Facebook and Google are U.S.-based companies that routinely collect data on users. Both companies must comply with the GDPR when collecting and exporting data on any EU citizens. If they violate the privacy rules in the GDPR, they can be fined up to 4 percent of their global revenue.
With 11 chapters and 99 articles, the GDPR is rather complex and filled with typical legislative legalese. Many organizations seek outside specialists to help them ensure they are complying with all elements of the regulation.
Training
Higher authorities sometimes mandate specific awareness and training requirements related to data. For example, Federal Information Processing Standards Publication 200 (FIPS Pub 200), Minimum Security Requirements for Federal Information and Information Systems, published by NIST, specifies that organizations must meet at least the following minimum requirements for awareness and training:
(i) ensure that managers and users of organizational information systems are made aware of the security risks associated with their activities and of the applicable laws, Executive Orders, directives, policies, standards, instructions, regulations, or procedures related to the security of organizational information systems; and
(ii) ensure that organizational personnel are adequately trained to carry out their assigned information security-related duties and responsibilities.
This compliance starts with the organization defining data classifications. The U.S. government has done this with data classifications such as Top Secret, Secret, Confidential, and Unclassified. Next, the organization ensures that users are aware of the different types of data classifications. Training helps users understand the classifications, how the organization protects the data, and the users’ responsibilities and requirements for protecting the data. Audits (internal and external) often use documentation of training to help verify that an organization is complying with basic requirements.
Managing Assets Through the Lifecycle
Asset management refers to the steps used to manage important assets within an organization throughout their lifecycle. It helps the organization maintain control of its assets. In this context, assets include hardware, software, and data. The lifecycle refers to the time period from when the asset is first obtained or created to when it is discarded or destroyed.
On a larger scale, asset management is often associated with configuration and change management. In other words, an organization identifies all of its systems, but it also has documentation that identifies the current configuration of these systems. When a system is changed, the change management process ensures that the configuration documentation is kept up to date.
TIP Asset management systems help an organization track its assets. It’s common for asset management systems to track hardware and software owned by an organization.
Hardware Inventory
Hardware management entails identifying relevant hardware that arrives at a company, periodically inventorying the hardware, and removing the hardware from the inventory when it is disposed of. This includes items such as desktop computers, laptops, servers, routers, and switches.
Not all hardware is added to an inventory. For example, a mouse is very inexpensive and the labor required to inventory all the mice in an organization is much more expensive than the cost of replacing a few stolen or lost mice. Internal policies drive the decision to add hardware to the inventory. For example, a company policy may state that all hardware valued at more than $100 should be added to the inventory and anything less than $100 should not be added.
There are many different ways to manage a hardware inventory. A basic method is to record the model and serial number of each piece of hardware, place that information into a spreadsheet, and periodically inventory the hardware. Small organizations may use this method. Another inventory method labels systems with bar codes when the hardware arrives. The organization then periodically scans all the systems to verify that they haven’t disappeared.
Some organizations use radio-frequency identification (RFID) tags. The RFID tags transmit information on each inventory item, and RFID receivers can read data from the RFID tags. This is much easier than using bar codes. An individual has to scan each system manually with a bar code system. However, with RFID tags, an individual can just walk around the room with an RFID receiver to complete an inventory.
When an organization wants to combine the system with configuration management, it often has enterprise tools that it periodically uses to inventory the systems electronically. For example, an enterprise application will periodically check systems over the network to ensure that they all have relevant patches applied. This same application can be used as part of the hardware inventory.
Before disposing of hardware, it’s important to ensure that it doesn’t include any sensitive data. It’s common to remove and destroy hard drives, or use methods to purge data before disposing of systems. The “Removing Data Remnants” section earlier in this chapter provides specifics of how to do so.
Software Inventory and Licenses
Some asset management systems track software. This helps an organization track operating systems and software applications throughout their lifecycle. It also helps administrators ensure that they are not violating licensing terms. For example, if an organization purchased 100 copies of an application, it needs to be certain that the number of installed copies of the application is 100 or less. Installing 200 copies of the application would be the same as software piracy.
Just as enterprise applications can check systems for hardware inventory and patch management, many can also inventory the systems and identify software installed on each system. For example, Microsoft systems support Windows Management Instrumentation (WMI). By sending WMI queries to devices over the network, administrators can retrieve a significant amount of information on the systems. This includes the hardware, operating system version, updates, and installed applications. Enterprise applications also use WMI queries to retrieve this information.
Data Storage
Adding data to an asset management system is more difficult because it’s so easy to make a copy of files. However, it is possible to add media to asset management systems. This includes external drives and backup tapes.
It’s also important to follow procedures mentioned earlier in this chapter related to handling data. This includes ensuring the data is properly classified, marked, and labeled, and ensuring the data is properly destroyed when it is no longer needed.
Certification and Accreditation
Certification and accreditation are two separate processes used to test, evaluate, and approve systems for specific purposes. The certification process includes several steps to evaluate, describe, and test a system. This includes all the security controls that are used to mitigate risks to the system. Once a system is certified, an accrediting authority provides a formal declaration, which approves the system operation.
TIP Systems are often operating during the certification process. However, there may be specific restrictions on what the system can be used for until it is formally accredited.
The certification and accreditation process provides a level of checks and balances for systems. A single entity doesn’t certify and accredit systems. Instead, one entity certifies them, and then another entity has the responsibility of verifying that the information is accurate and, if so, accrediting the system. A management authority normally completes the accreditation. When the authority accredits the system, it takes responsibility for the risks associated with the system and any losses associated with the system. Because the accrediting authority takes responsibility for the approval, this discourages simple “rubber stamp” approval. Instead, the accrediting authority verifies the authenticity of information provided by the certification process. Of course, because an organization expects the accrediting authority to examine the data closely, personnel take extra steps to ensure the data’s accuracy before submitting the certification paperwork.
EXAM TIP Within the U.S. government, a Designated Approving Authority (DAA) provides official accreditation by approving a system for operation at a specific level of risk. It does not guarantee that a system is free of risk.
The U.S. government uses several publications from the NIST SP 800 series as standards for the certification process. For example, NIST SP 800-47, Security Guide for Interconnecting Information Technology Systems, provides information on the certification and accreditation of interconnected systems.
Certification, Accreditation, and Security Assessments
In addition to NIST SP 800 documents, FIPS Pub 200 mandates specific requirements related to certification, accreditation, and security assessments as follows:
(i) periodically assess the security controls in organizational information systems to determine if the controls are effective in their application;
(ii) develop and implement plans of action designed to correct deficiencies and reduce or eliminate vulnerabilities in organizational information systems;
(iii) authorize the operation of organizational information systems and any associated information system connections; and
(iv) monitor information system security controls on an ongoing basis to ensure the continued effectiveness of the controls.
TIP Chapter 10 mentioned FIPS Pub 200 in the context of accounting and configuration management. Recall that it specifies minimum requirements that federal agencies must meet in several different IT security areas. Nongovernment organizations often adopt these same standards as best practices for IT security.
Common Criteria
The Common Criteria for Information Technology Security Evaluation (commonly called Common Criteria or simply CC) is a framework used to evaluate systems. It provides assurances that the specification, implementation, and evaluation of a system’s security has gone through a rigorous and standardized process. The Common Criteria was created with the help of several government organizations, including those of the United States, Canada, United Kingdom, France, and Germany. It’s recognized as an international standard and has superseded several other standards.
Evaluation Assurance Levels (EALs) provide a level of assurance for a product or a system. EAL has seven levels that indicate the level of quality assurance steps that personnel have taken to ensure the reliability of security features:
• EAL1 Functionally tested. The threats to security are low, so a high level of security assurance is not required.
• EAL2 Structurally tested.
• EAL3 Methodically tested and checked.
• EAL4 Methodically designed, tested, and reviewed. Many commercial operating systems achieve EAL4.
• EAL5 Semiformally designed and tested.
• EAL6 Semiformally verified design and tested.
• EAL7 Formally verified design and tested. This provides the highest level of assurance. It’s applicable in extremely high-risk situations, where the assets have exceptionally high value or when the impact of a threat can result in catastrophic losses.
EXAM TIP The Common Criteria uses EALs to determine the level of assurance of a system or product. EAL1 is the lowest level of assurance and EAL7 is the highest level. Many commercial operating systems achieve EAL4.
There’s a trade-off in both cost and time to achieve higher levels of assurance. For example, the U.S. Government Accountability Office (GAO) indicates that it can take between 10 and 25 months to develop a system at EAL4, and the cost can range between $150,000 and $350,000.
Using a Risk Management Framework
NIST SP 800-37, Guide for Applying the Risk Management Framework to Federal Information Systems: A Security Life Cycle Approach, provides guidelines on transforming the traditional certification and accreditation process into a six-step risk management framework. Figure 11-5 shows the steps in the framework, and the following text provides an overview of each of these steps:
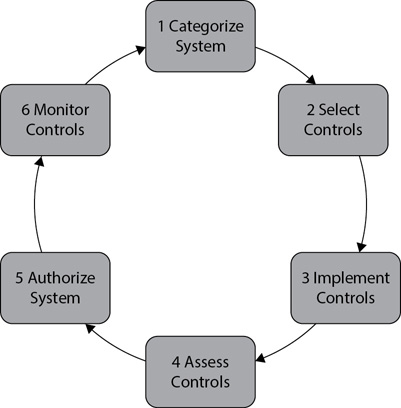
Figure 11-5 Risk management framework
1. Categorize system. Personnel examine the system, including the data it processes, stores, and transmits. They combine this information with an impact analysis to determine the security category of a system.
2. Select controls. Personnel select a set of baseline security controls based on the category of the system. For example, a system processing confidential data would start with a baseline of controls to protect confidential data. Personnel then tailor or supplement these controls based on the system and the needs of the organization.
3. Implement controls. In this step, personnel implement the selected security controls. They also document information on the controls to show how they are used within the system and what risks they mitigate.
4. Access controls. Personnel periodically examine the security controls to verify they are implemented correctly, operating as intended, and working as expected.
5. Authorize system. If the level of risk is determined to be acceptable based on the assessment of the implemented controls, the system is authorized. Note that the system is often already operating before this formal authorization.
6. Monitor controls. Personnel monitor security controls on a continuing basis to determine their effectiveness against new threats and system changes. For example, any system change documented through a change control process may require a repeat of the six-step process.
The risk management framework recognizes that there are specific tasks required during different phases of the certification and accreditation process, but it also allows an ongoing reevaluation of the system on a regular basis. Risk doesn’t stand still. Threats continue to morph, and mitigation controls implemented yesterday don’t necessarily thwart the threats of today. Many security professionals believe that the risk management framework is better able to address these changes than the two-step certification and accreditation process.
Understanding Security Within the System Development Lifecycle
The system development lifecycle (SDLC) is a model used to track systems (and sometimes software projects) from cradle to grave. In other words, the model identifies each of the different phases from the initiation of the project through to the ultimate disposition of the project at the end of its lifetime.
TIP Different sources sometimes show different phases for the SDLC. This discussion centers on the phases documented in NIST SP 800-64, Security Considerations in the System Development Life Cycle, of initiation, development/acquisition, implementation/assessment, operations/maintenance, and disposal.
Figure 11-6 shows the SDLC phases, and the following list provides a short overview:
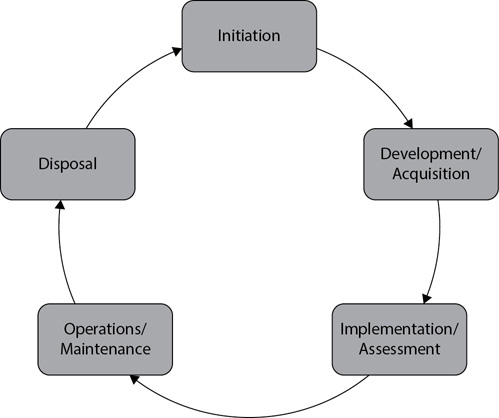
Figure 11-6 SDLC phases
• Initiation Personnel identify the need for the system in this phase. This includes documenting the purpose of the system and high-level requirements.
• Development/Acquisition Personnel design, purchase, program, develop, or create the system. In many models, this phase includes other processes such as an acquisition cycle or a software development cycle.
• Implementation/Assessment Personnel install, configure, and test the system in this phase. Testing and evaluation steps determine whether the system meets the originally identified need.
• Operations/Maintenance During this phase, the system performs its primary mission. Personnel perform regular maintenance on the system to ensure it continues to operate as desired.
• Disposal In this phase, personnel remove the system from service. A key component of this phase is sanitizing all media. If it is being replaced by another system, it should be removed only after the other system has completed the implementation/assessment phase. Personnel should also update inventory records to reflect the final disposition.
While it’s informative to understand the tasks required at different phases, much of this is outside the scope of the SSCP exam. From the perspective of the SSCP exam, the most important element is to understand the security issues at each of these stages. The following sections focus on the security elements.
Initiation Phase
Personnel focus on security concerns throughout the SDLC, and this includes the very beginning, the initiation phase. If security issues are not addressed early, then it’s very possible that security fixes you try to add later will not be adequate or will cost too much to implement. It’s important to look at the data that will be processed, transmitted, or stored on the system and understand the value of the data to the organization. As a reminder, the system should be protected at least at the level of the classification of the data. By identifying the classification of the data that the system processes, the organization then knows the minimum level of protection required by the system.
EXAM TIP Security issues should be addressed starting in the initiation phase and continuing all the way through to the disposal phase. Ignoring security early in any project makes it much more difficult to address problems adequately later.
Development/Acquisition Phase
During the development/acquisition phase, an organization conducts a risk assessment to identify baseline controls to protect the system and its data. The risk assessment allows the organization to identify risks, develop security requirements to address these risks, and evaluate security controls to ensure they mitigate risks to an acceptable level.
Implementation/Assessment Phase
In the implementation/assessment phase, the organization installs the system and begins testing it. In addition to testing the system to ensure that it meets the needs of the organization, personnel test the security controls to ensure that they meet the required security specifications. If the security controls don’t meet the requirements, it’s appropriate to add more security controls. However, these new controls should go through the same testing process.
Operations/Maintenance Phase
The operations/maintenance phase is normally the longest phase of a system. One of the biggest risks during this phase is that changes to the system will reduce the effectiveness of security controls. Organizations use change management and configuration management practices to ensure that changes to a system do not reduce the system’s security. Configuration management often includes an auditing component to check a system periodically. These checks not only ensure the system retains the required configuration, but also can detect unauthorized changes.
Disposal Phase
When the system’s lifetime ends, personnel sanitize it prior to disposal. Also, it’s common to migrate data from the system to ensure that the data will be available after the system has been disposed of.
Personnel use various methods to sanitize media, as described in the earlier “Removing Data Remnants” section. The method they use is dependent on the data held and processed by the systems. Higher classifications require more stringent sanitization methods, such as destroying the media. Personnel may use programs to remove files with lower classifications. The key here is that they need to sanitize all media to ensure that there are not any data remnants on the media prior to disposal. This includes all disk drives, tapes, and nonvolatile memory. Systems should also be checked to ensure that optical media (such as CDs and DVDs) have been removed from the systems before disposing of them.
EXAM TIP If data remnants are not removed from systems, anyone who has access to the system after it has been thrown away will be able to read the data. Drives with data that has a higher level of classification may have to be destroyed, while drives with data of lower levels of classification may be scrubbed with programs that write different patterns of ones and zeros onto the media repeatedly.
During the disposal phase, it’s also valuable to review the useful lifetime of data. Just because you can save data indefinitely doesn’t mean you should. If data doesn’t have any long-term use, it’s often a good idea to dispose of it at some point. Of course, if requirements such as laws mandate keeping data for a specific period, it should not be disposed of until this time has passed.
Chapter Review
One of the first steps used to manage and protect data is to classify it based on its value to the organization. The classification drives the steps required to protect the data. Higher-classified data deserves greater protection, while lower-classified data does not warrant the extra costs associated with extra protection.
Some data classifications in the U.S. government are Top Secret, Secret, Confidential, and Unclassified. The private sector doesn’t have standard terms for classifying data. However, some common classifications used in the private sector are Confidential (or Proprietary), Private, Sensitive, and Public, with Confidential representing the highest level. Organizations commonly implement data management policies to help protect data throughout its lifetime. Policies identify requirements when storing, transmitting, archiving, and retaining data. Access controls and encryption methods protect data at rest and data in motion.
Data is commonly stored in databases, and more specifically, in related tables within a database. Rows within a table are known as tuples. Tables have a primary key column to identify the row uniquely, and tables are related to each other by using a foreign key in one table to point to a primary key in another table. Database normalization separates data into multiple tables to prevent the duplication of data. SQL commands are used to communicate with databases. The two primary methods of organizing databases are online transaction processing (OLTP) and online analytical processing (OLAP). Web e-commerce applications typically use OLTP databases because of their high transaction processing speed and store transactions in transaction logs. Managers use OLAP databases to retrieve actionable data.
Data inference is a risk with data that allows an individual to gather individual unclassified pieces of data to predict or guess an outcome. Similarly, inference may allow someone to view summary or aggregate data and identify details though deduction.
Personally identifiable information (PII) is protected through several laws, and organizations are often required to disclose whether control of any PII is lost or a database has been breached. The Health Insurance Portability and Accountability Act (HIPAA) mandates the protection of certain health information, and the Sarbanes-Oxley (SOX) Act mandates that executives of publicly held companies vouch for the integrity of a company’s financial data. The General Data Protection Regulation (GDPR) is an EU regulation that mandates the protection of personal data of individuals within the EU.
Asset management ensures that an organization knows what hardware, software, and data it owns and helps protect those assets. It’s common to tie asset management systems to configuration management and/or change management systems.
Certification and accreditation are processes used to test, evaluate, and approve systems for specific purposes. Certification includes steps to evaluate, describe, and test a system to identify and mitigate risks. After certification, an accrediting authority provides a formal declaration approving the system for operation. In the U.S. government, a Designated Approving Authority (DAA) provides the official accreditation of systems.
Some organizations are applying lifecycle approaches to certification and accreditation. For example, NIST SP 800-37 provides a risk management framework used to identify specific tasks required during the certification and accreditation process. NIST SP 800-64 uses the SDLC model to track systems throughout their lifetime. When using any model, it’s important to address security in every stage of the lifecycle, including the very first stage.
Questions
1. Of the following choices, what type of data requires the least amount of protection?
A. Confidential
B. Public
C. Private
D. Sensitive
2. Which of the following provides the best confidentiality protection for data at rest?
A. Marking it
B. Labeling it
C. Backing it up
D. Encrypting it
3. Who is responsible for classifying data?
A. Management
B. User
C. Administrator
D. Owner
4. An organization wants to reduce risks associated with proprietary data transmitted over the network. What can it do in its data management policy to achieve this objective?
A. Restrict how long data is retained
B. Specify how data is deleted from storage media
C. Require the encryption of data in motion
D. Require the encryption of data at rest
5. Which of the following methods will reliably remove all data from a backup tape?
A. Erasing
B. Degaussing
C. Diddling
D. Sanitizing
6. Which of the following is a secure method of sanitizing optical media?
A. Degaussing
B. Overwriting
C. Shining
D. Destroying
7. A company wants to reduce the amount of space used to store files used and shared by employees. What can it use to reduce the amount of storage space used?
A. Data loss prevention (DLP) systems
B. Deduplication
C. Information rights management (IRM)
D. Retention policies
8. Users within an organization have recently sent sensitive data outside the organization in e-mail attachments. Management believes this was an accident, but they want to prevent a recurrence. Which of the following is the best method to do so?
A. Implement a network-based intrusion prevention system (IPS)
B. Provide training to users
C. Ensure the data is marked appropriately
D. Implement a network-based data loss prevention (DLP) system
9. Of the following choices, what best describes a tuple?
A. A column in a database
B. A row in a database
C. A primary key
D. A foreign key
10. Which of the following is a virtual table and allows a user access to a limited amount of data within a table?
A. View
B. Tuple
C. Row
D. Foreign key
11. An attacker has collected several pieces of unclassified information to deduce a conclusion. What is this called?
A. Data mining
B. Database normalization
C. OLAP
D. Data inference
12. An employee makes unauthorized changes to data as he is entering it. What is this?
A. Data diddling
B. Data entry
C. Data inference
D. Data deduplication
13. A database includes information on customers. This information can be used to distinguish or trace a customer’s identity. Of the following choices, what best describes this data?
A. PII
B. Tuple
C. Data inference
D. PHI
14. A database includes health-related information on employees of a U.S. organization. Management wants to ensure it protects this data and complies with relevant laws. Of the following choices, which one identifies the regulation they should follow?
A. SOX
B. HIPAA
C. Equifax
D. PII
15. The CEO of a publicly held company in the United States is required to verify the accuracy of a company’s financial data. What requires this activity?
A. HIPAA
B. SOX
C. NIST SP 800-64
D. NIST SP 800-37
16. A U.S. company collects information on customers and users around the world and stores much of it in databases in the United States. Management wants to ensure the company is complying with relevant laws in the EU. Which of the following is the most relevant law?
A. GDPR
B. Directive 95/46/EC
C. HIPAA
D. SOX
17. Within the U.S. government, who can formally approve a system for operation at a specific level of risk?
A. Certification authority
B. NIST
C. Senator
D. Designated Approving Authority (DAA)
18. Which of the following EALs indicates a system was methodically designed, tested, and reviewed, and is the level of assurance assigned to many commercial operating systems?
A. EAL0
B. EAL1
C. EAL4
D. EAL7
19. Which of the following is an international standard that provides a framework to evaluate the security of IT systems?
A. ITSEC
B. TCSEC
C. Common Criteria
D. Orange book
20. Of the following choices, what is a primary task to accomplish in the disposal phase of a system’s lifecycle?
A. Migrate all data to other systems
B. Delete all data
C. Remove data remnants from systems before disposal
D. Back up all data to tape
Answers
1. B. Public data requires the least amount of protection. An organization would want to ensure that public data on a website is not modified, but the organization puts the data on the website to make it available to the public. The other choices indicate sensitive data that is important to an organization and deserves varying levels of protection.
2. D. Encryption provides the best confidentiality protection for data at rest. While it is appropriate to mark or label it, this isn’t as strong as encrypting it. Backing it up provides protection for availability.
3. D. The data owner is responsible for classifying data. Management is responsible for defining data classifications, such as in a data policy. Users access the data, but they are not responsible for assigning or modifying data classifications. Administrators grant access to users based on the individual user’s need and often at the direction from the data owner.
4. C. Encrypting data in motion can protect it against loss of confidentiality when it is transmitted over a network. Retention policies restrict how long data is retained, but do not affect data in motion. Destruction policies dictate how to delete data or destroy media but aren’t related to data in motion. Encrypting data at rest doesn’t ensure that it is encrypted when it is transmitted. Some data-at-rest encryption methods will decrypt the data before transmitting it over a network.
5. B. Degaussing will reliably remove all data from a backup tape. Degaussing uses a powerful magnet to erase the data. Other methods of erasing data from a tape don’t necessarily erase all the data. Data diddling is the unauthorized changing of data before or while entering it into a system and is unrelated to removing data from a tape. Sanitizing the tape is the goal, but it is not a method.
6. D. Optical media must be destroyed to ensure it doesn’t include any remaining data. Degaussing isn’t effective because optical media doesn’t use magnetic methods of storing data. Overwriting isn’t effective because the media might still have data remaining after overwriting it. Shining is not a valid method of sanitizing media.
7. B. Deduplication ensures that a file is stored only once on a system, even if multiple users have access to the same file. DLP systems attempt to monitor data usage and prevent the unauthorized use or transmission of sensitive data. IRM refers to the different methods used to protect sensitive information from unauthorized access. Retention policies restrict how long data is retained.
8. D. The best solution is to implement a network-based DLP system. It can scan outgoing data to look for sensitive data and block any it finds. An IPS focuses on incoming traffic to block attacks and doesn’t necessarily scan outgoing traffic. Thus, it wouldn’t necessarily stop data sent as an e-mail attachment. Training is appropriate, but training doesn’t necessarily prevent accidents. Also, training wouldn’t stop a malicious insider from this action. The data should be marked with its appropriate classification, but there isn’t any indication that it isn’t. Also, even if the data is marked, it doesn’t necessarily prevent accidents.
9. B. A tuple is a row in a database. Columns are also known as attributes. A primary key uniquely identifies a row in a table and is related to a foreign key in another table to create a relationship between two tables.
10. A. A view is a virtual table that provides access to specific columns in one or more tables, allowing a user to access a limited amount of data. A tuple is the same as a row and it contains a single record, but it is not a virtual table. Tables are linked together with foreign keys.
11. D. Data inference occurs when someone is able to piece together unclassified information to predict or guess an outcome. Data mining is the process of retrieving relevant data from a large database. Database normalization is the process of dividing the data into multiple tables in a database to reduce duplication of data. Online analytical processing (OLAP) uses techniques to make it easier to retrieve data.
12. A. Data diddling is the unauthorized changing of data before entering it into a system or while entering it into a system. While the employee is involved with data entry, data entry by itself doesn’t indicate the employee is making unauthorized changes. Data inference occurs when someone is able to put together unclassified pieces of information to predict or guess an outcome. Data deduplication stores a file only once on a system, even if users attempt to store copies in multiple locations.
13. A. Personally identifiable information (PII) is any information that can be used to distinguish or trace an individual’s identity and includes items such as their name, Social Security number, birthdate, birthplace, and more. A tuple is a row in a database table. Data inference occurs when someone is able to piece together unclassified information to predict or guess an outcome. Protected health information (PHI) is information referring to an individual’s health and is protected by HIPAA.
14. B. The Health Insurance Portability and Accountability Act (HIPAA) mandates the protection of health-related information. The Sarbanes-Oxley (SOX) Act mandates specific requirements to guarantee the accuracy of data held by companies registered with the U.S. Securities and Exchange Commission. Equifax is a U.S.-based company that suffered a data breach and was required to report the loss to customers based on laws that protect personally identifiable information (PII).
15. B. The Sarbanes-Oxley (SOX) Act requires high-level officers (such as the CEO and CFO) to verify personally the accuracy of a company’s financial data. The Health Insurance Portability and Accountability Act (HIPAA) mandates the protection of protected health information. NIST publishes documents that provide guidance to federal agencies and can be used by private companies, but these documents do not require any actions by private companies.
16. A. The General Data Protection Regulation (GDPR) is a European Union (EU) regulation that mandates the protection of EU residents personal data. The GDPR supersedes Directive 95/46/EC (also known as the Data Protection Directive). The Health Insurance Portability and Accountability Act (HIPAA) mandates the protection of health-related information. The Sarbanes-Oxley (SOX) Act requires high-level officers (such as the CEO and CFO) to verify personally the accuracy of a company’s financial data.
17. D. A DAA provides official accreditation by approving a system for operation at a specific level of risk. The certification authority does not approve a system, but instead evaluates, describes, and tests a system. The National Institute of Standards and Technology (NIST) provides recommendations of standard best practices, but it does not certify or accredit systems. Senators do not certify or accredit systems.
18. C. Most commercial operating systems achieve Evaluation Assurance Level 4 (EAL4) when evaluated by the Common Criteria (CC). EAL4 indicates the operating system has been methodically designed, tested, and reviewed. EAL0 is not a valid level of CC. EAL1, the lowest level of assurance, indicates the system has been functionally tested. EAL7 is the highest level of assurance and indicates the system has a formally verified design and has been tested, but EAL7 ratings are not as common as EAL4, especially for operating systems.
19. C. The Common Criteria provides a framework for evaluating the security of IT systems, and several countries (including the United States, Canada, United Kingdom, and France) have adopted it. The Information Technology Security Evaluation Criteria (ITSEC) is a standard used in Europe, but it has been largely replaced by the Common Criteria. The Trusted Computer System Evaluation Criteria (TCSEC or orange book) was used by the U.S. government, but it has been superseded by the Common Criteria.
20. C. Data remnants should be removed before disposal to ensure that data does not fall into the wrong hands. Depending on the value of the data, it could be migrated, deleted, or backed up, but this does not remove the need to ensure that data does not remain on the system before disposing of it.