
Locating scholarly papers of interest online
Abstract:
Discovering the existence of scholarly papers in an online environment has been possible since the middle of the last century and the retrieval of their full text reliably possible only in the last quarter of the century. Since then several public web-based scholarly search engines have become available and directly compete with the older proprietary database search services to aid scholars and researchers. This chapter compares three public services, Google Scholar, Academic Search and Scirus, with two proprietary services, Web of Science and Scopus, in their effectiveness as tools for communicating and raising awareness of scholarship. It examines the three main functions required at different times by scholars – the discovery and retrieval of scholarly literature, the analysis of journals for publishing decisions and citation analysis for mapping collaborative scholarly networks and communities.
Introduction
It is obvious that academics and researchers have always needed to find literature, particularly research literature, to alert them to new developments in their discipline(s), to further their own research and to pass this on to students through research-based teaching. Once upon a time the ‘literature’ was knowledge which was passed on by oral communication, and possibly messenger services, to one’s personal and scholarly ‘networks’. We have now come full circle – the passing on of scholarly knowledge through social media technologies. Along the way we have cycled through a number of innovative services and technologies. The digital environment has brought ‘qualitative and quantitative changes in the ways that scholars communicate with each other for informal conversations, for collaborating locally and over distances, for publishing and disseminating their work, and for constructing links between their work and that of others’ (Borgman and Furner, 2002, p. 4). It is within this context that this chapter examines the tools of such academic literature finders, as well as their use for bibliometric analysis and mapping.
This chapter concentrates on three public search systems – two general, multi-disciplinary ones: Google Scholar and Microsoft’s Academic Search (beta); and one specialized or vertical one: Scirus (science). For comparison, I measure two proprietary, fee-based subscription systems: Elsevier’s Scopus and Thomson’s Web of Science.
Overview of online scholarly search services
The rapid growth of the Internet began with three not quite concurrent events: the development of the World Wide Web in 1989; the lifting of the ban on commercial activity on the Internet (what was at that time NFSNet) in 1991; and the release of the first point and click browser, Mosaic, in 1993. In fact it was out of a need to collaborate and share scholarly information among the community of particle physicists at CERN (Conseil Européen pour la Recherche Nucléaire) in Switzerland that the team, led by Tim Berners-Lee, developed the web (Henninger, 2008).
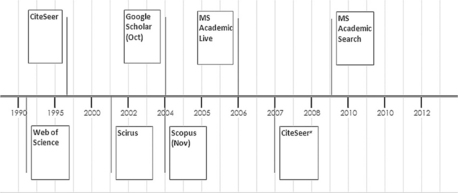
In the 1980s there were many publicly available collections, archives and repositories of scholarly documents such as NetLib, as well as the large proprietary indexing and abstracting databases. While the main system available to search across much of the content of individual databases was ISI’s Science Citation Index (at that time accessed via Lockheed’s Dialog service),1 in the public sphere, other than early systems such as Archie or Gopher, there were no tools for searching and retrieving scholarly articles.2 One of the earliest of the public scholarly search engines was CiteSeer, which was developed at the NEC Research Institute to provide access to cited scientific scholarly literature and was available on the web in 1997. It was really the first decade of this century, powered by robust search engine technology for crawling the Internet and access by agreement or joint venture to some of the large indexes of proprietary databases3 which saw the development of public, web-based scholarly search engines (see Figure 4.1).
Scholarly communication and social media
Before examining the search and retrieval systems, it is important to discuss the meaning of ‘scholarly literature’. At a basic level, it is writing done by scholars in the process of expanding knowledge through some review process. This writing may be research results or ponderings; by format it may be books, peer-reviewed journal articles, presentations at conferences, papers or documents deposited in electronic archives or repositories, to name some of the possibilities. As noted above, it’s a vehicle for publishing or otherwise disseminating their work. It is this somewhat flexible definition which at times can cause searchers confusion and which differentiates the various services. For example, Web of Science, now part of a broader service, the Web of Knowledge, with its access to many other Thomson databases, originally placed its emphasis on peer-reviewed journal articles and, in particular, those journals which had high-impact value. At the other end of the spectrum is Google Scholar which does not define other than in very general terms what it considers to be scholarly. The details, distinctions, advantages and disadvantages of each of these services are discussed below in the individual service sections.
Scholarly communication, in concept and practice by definition is social media. As Christine Borgman (2008) notes, online chat, researchers’ blogging and line items in grant proposals for Skype accounts are ubiquitous features in e-scholarship. Nevertheless, in some scholarly communities the uptake of the more informal social media has been reluctant. Christie Wilcox, a blogger at Scientific American, contends that the dissemination of scientific knowledge by social media is the scientist’s job, and yet ‘when it comes to social adaptation and technology, we’re [scientists] more than behind the curve. Although 72% of Internet-using Americans are on Facebook, less than 2/3 of college faculty are’ (Wilcox, 2011, para. 2).
However, within the context of this book, the tools of social media have not been readily available with the scholarly search and retrieval services. These services, while providing some insight into scholarly networks through applied citation indexing – ‘cited by’ and ‘related articles’ – do not allow tagging, annotating nor the ability to build shared personal or community collections; such functions are the foundations of Web 2.0 technologies. It was not until the mid-2000s that tools such as CiteULike, Mendeley and SearchGate began to fill this space and this development is fully covered in Chapter 5.
Use and purpose of scholarly search services
There are two ostensible uses for scholarly search engines: search and retrieval of literature; and the analysis of the citations in this scholarly literature (bibliometrics). In general, the scholarly search services were exactly that, search engines whose purpose was to search for scholarly literature and to retrieve the full citation. Gradually, they began to provide facilities to discover other similar literature (citation pearl-growing); currently, citation pearl-growing and the delivery of the full text of the document are the major services in both the proprietary and the web-based services.
However, systems which could provide access to very large citation databases enabled the ability to mine these rich resources for other purposes, in particular bibliometric analysis – scholars using these services to track their own citations and to find the most influential journals on a particular subject for promotion and publishing decision-making purposes – and visual mapping of scholarly collaborations and disciplinary networks. The visual maps enable further, and often unexpected, discovery of scholarly communication through citation and co-citation analysis, the work done by bibliometricians using the various versions of the Science Citation databases.4
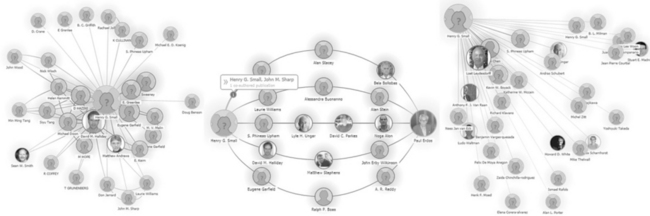
The gradual iterations and versions of the Science Citation databases now provide detailed citation analytical reports (see Figure 4.2) and interactive hyperbolic visualizations of the forward and backward citations, that is, the cited references and citing references of a scholarly paper (see Figure 4.3, p. 64). To date, among the public scholarly search engines, the only serious attempt at this functionality is the more recent versions of Microsoft’s Academic Search and, to a much lesser extent, Google Scholar.
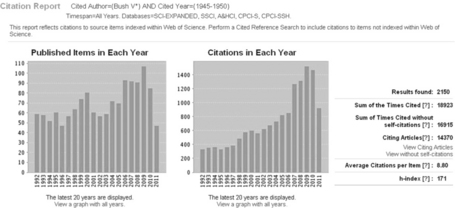
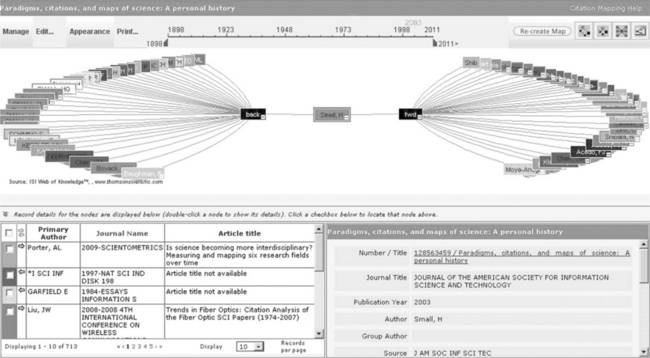
Figure 4.3 Web of Science interactive hyperbolic visualization of the forward and backward citation of a paper by Henry G. Small
It must be said that the use of the scholarly search services, both proprietary and public, for bibliometric analysis engenders much discussion and controversy. The variations in the included and excluded literature in each of the services have been the subject of many studies5 as well as comparative studies of the ranking algorithms for calculating impact factors, influential journals and citation tracking.
Impact of the Open Access movement
There is a third way, a movement, which provides a vehicle for access to scholarship. The Open Access (OA) movement has had an important impact on access to scholarly literature. This movement, which aims to make the corpus of scholarly literature freely accessible, accelerated with the expansion of the availability of the Internet. While there are initiatives such as PubMed (open access to medical literature) by the journal publishers to make their offerings available after a certain period of time, it is the self-archiving of scholarly papers, the OA green road, and the OA gold road of publishing in OA journals which have increased access to the full text of scholarly literature.6
Web-based public scholarly search engines can add this content since the online ejournals are open to search engine spiders. In the case of the e-repositories, in reality, it is the bibliographic metadata (title, author, subject, etc.) about the papers which is gathered using the Open Access Initiative-Protocol for Metadata Harvesting (OAI-PMH), the first stable version of which was released in 2003. Proprietary services are also able to use this method to add content to their databases; in the case of Scopus, however, this is not necessary since it owns the public scientific search engine, Scirus.
According to some critics the effectiveness of the web-based services may be compromised since they reparse the OAI metadata rather than simply using it.7 The OAI-PMH mandates the use of a standard metadata format, Dublin Core, which is more compatible with the metadata, such as subject, document type (article, thesis and review, etc.) and document format, which drives the proprietary services.8
Search engine functionality
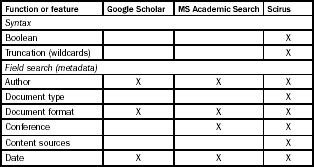
We now need to discuss briefly how search engines are used. As a rule, the most effective way to use a search engine, although not necessarily the most efficient as demonstrated by the ubiquity of the single search bar, is to utilize the advanced search facility. This allows you to leverage the metadata for more specific queries and provides good filtering and limiting of the results. In the case of general Internet search engines, the searchable metadata is restricted to title, URL, language, file type and sometimes date; these search fields are available in an advanced search interface but you can search in most of these fields in the single search bar, thus combining effectiveness and efficiency. For example,
and in most of the public scholarly search engines you can add ‘author:’ and ‘date:’.
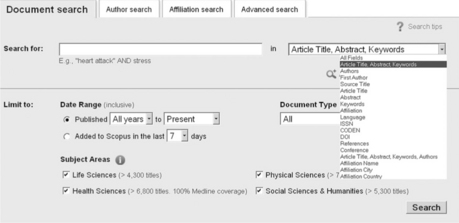
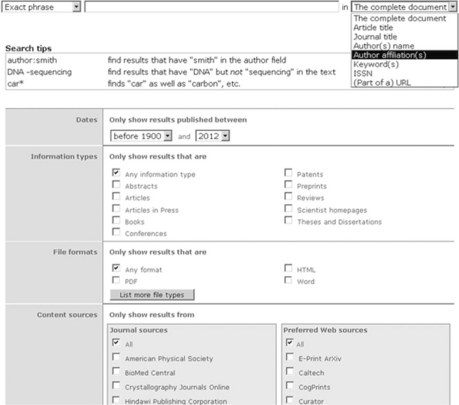
On the other hand, proprietary database search systems such as Scopus and Web of Science have highly granular descriptive metadata which is ‘on show’ in the advanced search interface (see Figure 4.4). As we shall see, the public scholarly search engines have been criticized for not using such rich metadata.
Public scholarly search services
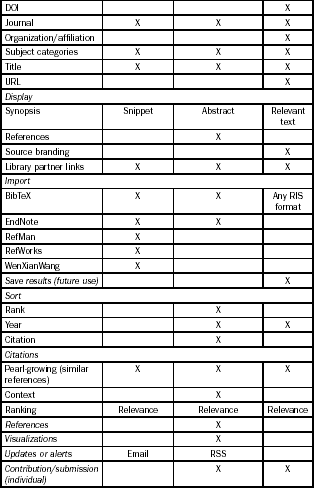
In this section we will examine the details of three public web-based scholarly search services: two multi-disciplinary services, Google Scholar and Microsoft Academic Search; and a specific disciplinary (scientific) service, Scirus. In each case, a brief history of the service is given, and a discussion of its content, ranking algorithms, usability, strengths and weaknesses, contribution to the dissemination of scholarly literature, and its use and opportunities within the space of social media are provided. For the specific functionality and features of the individual public search services see the Appendix: Features of web-based public scholarly search services.
Tips for using web-based public services
![]() If your library has a partnership agreement with the service then it is faster than searching in library databases to get the full-text document.
If your library has a partnership agreement with the service then it is faster than searching in library databases to get the full-text document.
![]() Use them when you know the exact title of a paper. It is a great way to build a citation database – it saves typing!
Use them when you know the exact title of a paper. It is a great way to build a citation database – it saves typing!
![]() In Google Scholar, to retrieve only master records once you have done your search filter the results to include ‘at least summaries’.
In Google Scholar, to retrieve only master records once you have done your search filter the results to include ‘at least summaries’.
Google Scholar
The beta version of this service was launched in October 2004. At that time, according to Anurag Acharya of Google, the content included ‘peer-reviewed papers, theses, books, preprints, abstracts and technical reports’ (Acharya, 2004, para. 1); it has since expanded the content – patents in November 2006 and United States legal information in November 2009. There is no doubt that ‘search’ is the strength of Google Scholar; in Peter Jacsó’s words, ‘for topical keyword searches, GS is most valuable. But it cannot be used to analyze the publishing performance and impact of researchers’ (Jacsó, 2009, para. 4). Part of the difficulty is, firstly, the lack of specificity of what is considered ‘scholarly’, and, secondly, the inclusion of multiple versions of individual documents, a factor which, conversely, is of great value to the searcher who wishes to be able to retrieve a copy of the full-text article when the original is locked behind a proprietary service.
Content. Currently, ‘scholarly’ in Google Scholar is defined as follows: ‘journal and conference papers, theses and dissertations, academic books, pre-prints, abstracts, technical reports and other scholarly literature from all broad areas of research. You’ll find works from a wide variety of academic publishers (though not, unsurprisingly, from Elsevier), professional societies and university repositories, as well as scholarly articles available anywhere across the web’ (Google Scholar, 2011a, para. 1). We have already noted Google Scholar content of court opinions and patents. It also includes citations from social media sources Mendeley and CiteULike. It has been pointed out by Beel et al. that much of this content is from ‘trusted sources’ such as ‘publishers that cooperate directly with Google Scholar, as well as publishers and Webmasters who have requested that Google Scholar crawl their databases and Web sites’ (Beel et al., 2010, p. 183). However, as Google does not specify the sources of the citations, it cannot be assumed that all are from ‘trusted sources’.
The legal content is case law of the United States supreme, federal, state, and appellate courts, which is generally considered the scholarly output of judges. It is certainly easier to use than the traditional Westlaw or LexisNexis systems for case law searching; the ranking algorithm lists results by the highest court opinions first, then by number of citations. It not only returns the list of the citing documents, but it provides the added-value of contextual citations within the full text. However, according to Carol Ebbinghouse (2009), you do not get much of the other material such as the links to statutes and regulations that are available on the database systems.
Patent documents are available via Google’s vertical patent search which was added in November 2006 after an agreement with the United States Patent and Trademark Office (USPTO) for a complete download of US patents and trademarks. In Google Scholar you are able to ‘include patents’ in your search, although it appears that journal articles are ranked more highly than patents, that is, patents often appear after the scholarly articles. If you want to use Google Scholar for finding only patents simply add the word patent to your search.
Ranking and displaying. The ranking algorithm is a combination of several factors; Google states that it ‘rank[s] documents the way researchers do, weighing the full text of each document, where it was published, who it was written by, as well as how often and how recently it has been cited in other scholarly literature’ (Google Scholar, 2011a, para. 3). In other words, the more cited and relevant articles rise to the top of the results. It is this algorithm, and the fact that it does not make use of the publishers’ metadata to parse the documents, which made Peter Jacsó so critical in 2009. While Google appears to have corrected many of these inaccuracies, there is a disclaimer, for example, on authorship: ‘author names are often abbreviated and different people sometimes share similar names’ (Google Scholar, 2011b, para. 8). Nevertheless, using the available publishers’ metadata might ameliorate any residual problems.
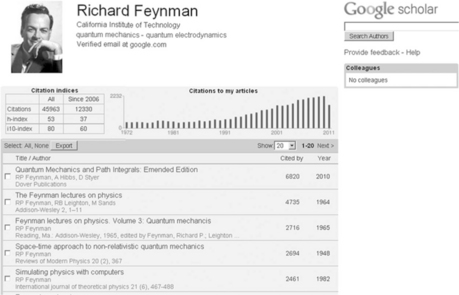
Bibliometric analysis. While the use of Google Scholar for bibliometric analysis may be troublesome, for reasons mentioned above, it does provide a gadget, available for online use or for download at http://code.Google.com/p/citations-gadget/, which enables a search on an author(s) and provides a total citation count, total number of cited publications and the h-index.9 You are able to use a variety of query statements in the gadget, for example the search below retrieves the results shown in Figure 4.5:

Social networking opportunities. There is nothing in the way of built-in social media tools in Google Scholar. However, a citation tracking function, Google Scholar Citations, was announced on 20 July 2011, and on 16 November 2011 the service was made available to everyone. The function builds a profile, which can be either public or private, of the researcher and includes three metrics, the h-index, the i10-index and the total number of citations to the authors’ articles. The citations may be sorted by the number of citations or by the date of the reference. It also enables the author to manually update his/her profile by adding a new article or missing articles, correcting bibliographic errors and merging duplicate entries. Figure 4.6 shows the example of a public profile that is available on Google Scholar.
Academic Search (Microsoft)
In April 2006 Microsoft released its original academic finder tool, Windows Live Academic, but suspended it in May 2008. It clearly went back to R&D mode and in late October 2009 launched a much better product, Academic Search, which concentrated on the discipline of computer science. Since its first release Microsoft has been constantly adding content and features, so that the latest release in March 2011 is a sophisticated product and the only one of the public scholarly search services that is moving into the information visualization and social media spaces.
Content. Academic Search, which is still described as a prototype, initially focused on natural sciences such as mathematics, engineering, physics and life sciences, economics and business and claimed to have 36,684,204 publications and 18,831,925 authors as of 11 November, 2011 (Microsoft, n.d.). One can assume that this is because of the availability of large OA eprint repositories in these disciplines. It recently began to include scholarly papers in the domains of arts and humanities and social science. Nevertheless, from the features and functionalities that are available in this beta service, it is easy to see that it ‘also serves as a test-bed for many research ideas in data mining, named entity extraction and disambiguation, data visualization, etc.’ (Microsoft, 2011, para. 1) which is being done at Microsoft Research. The fact that the service has had several updates in the past two years, including the addition of content from other domains, leads to the assumption that it should be considered a serious search service.
Academic Search, like Google Scholar, does not specify its sources, therefore it is difficult to know exactly what it considers to be scholarly, other than what is mentioned in the broad statement ‘academic publications, authors, conferences, [and] journals’ (Microsoft, 2011, para. 2). As to the actual coverage of individual journals, this can be checked by searching on the journal and filter by year, for example:
Ranking and displaying. According to the help page, the documents are ranked in the search results according to two factors: their relevance to the query; and their global importance (similar to Google Scholar, i.e., the most cited and relevant rise to the top of the results). The search algorithm is based on objects, not documents, usually recognizable concepts, such as authors, papers, conferences, or journals (this was the basis of the original work that Microsoft Research was doing in the development of Libra, an academic search engine that was the early prototype of Academic Search) (Nie et al., 2005). In practice, this allows good use of the object metadata to display the results in a variety of ways. For example, results are clustered by domains, by a keyword tag cloud, by journal or conference, and by co-authors. The results may be filtered as well as sorted by year. An individual author’s results, however, can be sorted in other ways – year, citation and rank – as shown in Figure 4.7.
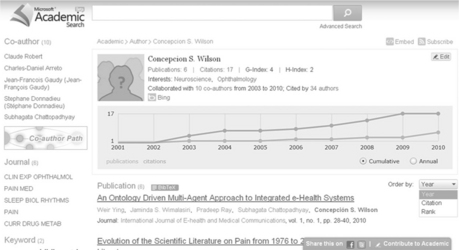
Bibliographic analysis. As can be seen in Figure 4.7, Academic Search provides a good profile of individual authors, giving information such as number of publications, number of citations, collaborative authors over a period of time, interest domains, and his/her g-index and h-index. Academic Search has some very good visualization features – domain trends, co-author graph, co-author path, and citation graph (see Figure 4.8) – and also has a suite of APIs (application programming interfaces), for example, to build your own ranking of institutions or to build a visual explorer for browsing academic papers in a particular subject.
Social networking opportunities. Currently, of the services discussed in this chapter, Academic Scholar is the only one which has built in a social networking tool – the results of a search can be posted to Facebook (to your own wall, to a friend’s wall, or to a Group) and to Twitter.
Scirus
This service, developed by Elsevier in conjunction with the Fast search engine, was first released in March 2001. In a sneak preview of the service it stated it would index scientific websites as well as incorporate proprietary content sources (Scirus, 2001). Today, it is still owned by Elsevier and claims to index over 410 million scientific documents.
Content. Scirus indexes several types of content: scientific websites, institutional and OA repositories’ articles, and journal articles from the Elsevier journals, as well as a range of different information types, including all the patents from five patent databases, theses and dissertations, books, conferences and articles in press. Unlike Google Scholar and Academic Search, Scirus not only lists the sources of its content, but provides a complete list of the journals (About Scirus, 2001). Of the academic web-based search services, Scirus has the most content and arguably provides the most complete access to scientific scholarly literature.
Ranking and displaying. By default, the results are sorted by relevance. For websites, Scirus uses an algorithm similar to other general web search engines, that is, term frequency and link analysis. However, it also appears to use the publishers’ metadata for the proprietary journal articles and for the e-repository content. The searchable metadata options for Scirus can be seen in Figure 4.9 below.
Bibliographic analysis. Scirus has no bibliographic analytical tools, nor does it provide any social networking opportunities. However, there is a link to SciTopics, also an Elsevier product, which is a ‘free, wiki-like knowledge-sharing service for the scientific community. It offers distilled, authoritative and up-to-date research summaries on a wide range of scientific topics … and designed to be a starting point for researchers to gain an introductory overview of a particular topic’ (SciTopics, n.d., paras 1–2).
Proprietary scholarly search services
Scopus
Scopus, now officially SciVerse Scopus, is a product from Elsevier and was launched in November 2004 (coincidently within a month of the release of Google Scholar) to be a major competitor to Web of Science. At the time, the service was ‘covering 14,000 scientific titles plus 167 million scientific web pages, and delivering the largest collection of abstracts ever collected online in one place, going back forty years” (Elsevier, 2004, para. 3).
Content. Currently, Scopus is an enormous database and according to Elsevier has access to ‘over 18,500 titles from more than 5,000 international publishers … 14.4 million records’ (Elsevier, 2011, p. 4). It has its basis in the scientific fields using the citations from its own publications which include peer-reviewed journals, book series and conference proceedings. There is also the advantage of being able to include access to articles-in-press from Elsevier’s list of 2,199 journal titles.10 Recently, Scopus began adding citations in the arts and humanities, thus moving towards a more multi-disciplinary coverage. Scopus, from the search interface, provides a list of all journals and other sources, categorized by journals, conference proceedings, trade publications, and book series.
We have already noted that the web-based scholarly search engines have added listings to their content by agreement and/or joint ventures with proprietary database vendors. In the case of Scopus, the content is extended by the additional harvested listing available on Scirus (see above) which it owns.
Ranking and displaying. By default, Scopus displays the results of a subject search by year in descending order; however, the user has the option of reversing this order, as well as sorting by number of citations, relevance, first author, and source title. There is a very nice feature for selecting items from the results’ list and printing a bibliography without having to first export the references into a bibliographic software package.
Bibliographic analysis. Scopus ranks journals according to the h-index, not the impact factor (the formula devised by Eugene Garfield) as done by the Web of Science; however, the data is available to calculate the impact factor. According to Elsevier, Scopus uses a ‘next generation context-based’ metrics, SNIP (source-normalized impact per paper) and SJR (SCImago Journal Rank).11 Scopus has some excellent tools for analysis and visualization. For example, there is the usual citation tracker to find, check and track citations, an author identifier to automatically match an author’s published research including the h-index and a journal analyser which shows journal performance, which is helpful for publishing decisions (Figure 4.10 gives some examples).
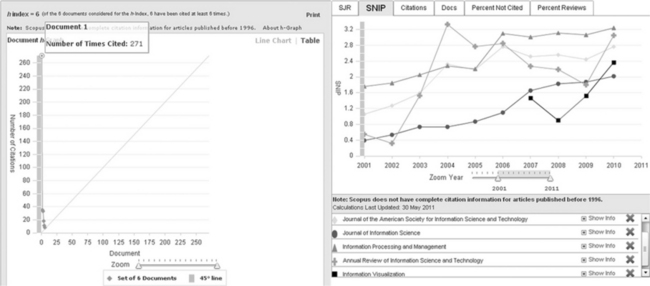
Figure 4.10 Scopus bibliometric visualizations: 1) h-index graph of 7 documents with self-citations removed, and 2) the SNIP (contextual citation impact) analysis of four journals12
Social networking opportunities. Scopus provides no intrinsic social networking tools. However, Elsevier does have an add-on service, SciVal Experts, which is a directory of research expertise within an organization. It scans and analyses the Scopus publications to produce individual profiles which potentially can be used for collaboration within the organization or to identify external collaborators.
Web of Science
This is the oldest of the proprietary scholarly literature search services which are built around the concept of citation indexing. Its recent incarnation under Thomson Reuters, the Web of Science, was released in 1992, and while it was long regarded as a premier source for literature discovery, it has been the benchmark service for citation tracking and bibliometric analysis.
Content. The Web of Science consists of five databases covering scholarly literature from 1898 to the present: the three citation indexes of journal articles in science, social sciences and arts and humanities (this last one begins in 1975); and conference proceedings in both science and the social sciences beginning in 1990, covering international conferences, symposia, seminars, colloquia, workshops, and conventions. Web of Science, like Scopus, provides a list of journals included in the different databases; however, you are able to get journal title abbreviations within the search interface, the master list of journals is available at Thomson Reuters.13 There is also an option within Web of Science to pass your search over to a beta service, Scientific WebPlus, to find web-based documents. This service is a collaborative one with Microsoft and various Thomson editors;14 and the results come from repositories, news and blogs.
Ranking and displaying. By default, the results are listed by date (newest to oldest); however, the user can select several other sorts, for example times cited, first author, source title. You can also sort by relevance, which is a statistical ranking that considers how many of the search terms are found in each record. In addition, there are options to filter a subject search by almost any piece of metadata (see Figure 4.11).
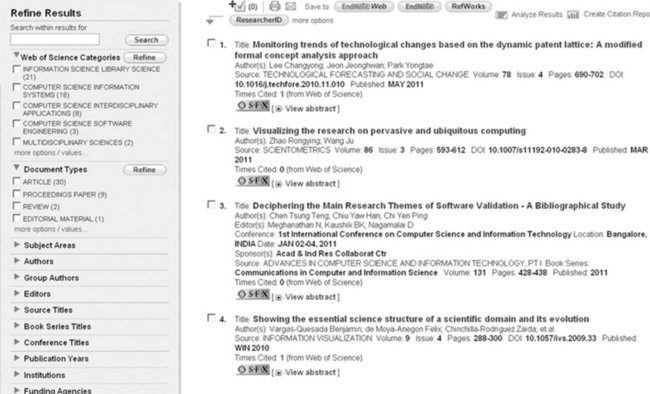
Bibliographic analysis. While both Web of Science and Scopus have excellent analytical tools, Web of Science provides the very powerful cited reference searching – the ability to track a specific author’s work to analyse the extent of the scholarly network in a particular field. This is particularly useful as a starting point in understanding the impact of a seminal piece of scholarship, invaluable for literature reviews for doctoral theses, for example (see Figure 4.3 on p. 64 to view the impact of the work of Henry Small in the discipline of bibliometrics). The service provides many other analytical reports such as citation reports (as shown in Figure 4.2 on p. 63).
Social networking opportunities. Web of Science does not have any built-in Web 2.0 social media tools. However, the beta service, Scientific WebPlus, provides a full range of tools – tagging, bookmarking, commenting, and voting (see Figure 4.12).
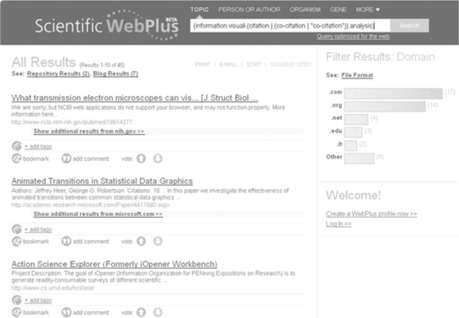
Social media and public scholarly search
The concept of the social graph, used by social scientists in graph theory, was co-opted by Mark Zuckerberg at the f8 Conference in 2007 to explain the connections made by people within the social networking space of Facebook. While in this context the social graph is metaphorical, in reality social graphs may be visualized using the techniques of visualization from the bibliometrics and scholarly communication communities. Such graphs have been available tools in the Web of Science and now Scopus; however, in the public scholarly search services, only Microsoft Academic Search has the ability to create actual graphical visualizations. Metaphorical social graphs, as will be seen in the next chapter, are the foundations of specific social media reference tracking and sharing tools.
Conclusions
The scholarly literature search services are essential tools for scholarly communication; researchers, academics and students use them for a variety of purposes. These include: the completeness of a literature search; to find out how often his or her own publications are cited since such metrics are considered in hiring, promotion and grant decisions; to find a seminal work as background information; for a few good articles; for mapping scholarly networks. Currently, none of the scholarly services examined uses to any large extent the Web 2.0 social media tools; it is the new web-based services which have moved into this space. Microsoft Academic Search, with its Twitter facility, is the only service which has caught up with Web 2.0 by incorporating social media tools, rather than using an add-on such as Web of Science’s pass-through to Scientific WebPlus. Perhaps this functionality comes with ‘newness’ and, in the case of Academic Search, because of its original function of a ‘test bed’. It remains to be seen if the other services, particularly the proprietary ones, Web of Science and Scopus, will see the need to fully incorporate social media communication tools or if they will continue to focus on their strengths of huge databases of scholarly literature and sophisticated tools for citation analysis and the visualization of scholarly networks.
References
Acharya, A., Scholarly pursuits [blog post]. 2004. Retrieved from. http://googleblog.blogspot.com/2004/10/scholarly-pursuits.html
Beel, J., Gipp, B., Wilde, E. Academic search engine optimization (ASEO). Journal of Scholarly Publishing. 2010; 41(2):176–190.
Borgman, C.L. Supporting the ‘scholarship’ in e-scholarship. EDUCAUSE Review. 2008; 43(6):2.
Borgman, C.L., Furner, J., Scholarly communication and bibliometricsCronin, B., Shaw, R., eds. Annual Review of Information Science and Technology; 36. Information Today, Medford, NJ, 2002:2–72.
Ebbinghouse, C., Judicial opinions now available in Google Scholar [blog post]. 2009. Retrieved from. http://newsbreaks.infoday.com/NewsBreaks/
Elsevier, Scopus comes of age [press release]. 2004. Retrieved from. http://www.elsevier.com/wps/find/authored_newsitem.cws_home/companynews05_00203
Elsevier, Content coverage guide: SciVerse Scopus. 2011. Retrieved from. http://www.info.sciverse.com/UserFiles/sciverse_scopus_content_coverage_0.pdf
Scholar, Google, About Google Scholar. 2011. Retrieved from. http://scholar.google.com/intl/en/scholar/about.html
Scholar, Google, Citations. 2011. Retrieved from. http://scholar.google.com.au/intl/en/scholar/citations.html
Henninger, M. The Hidden Web: Finding Quality Information on the Net. Sydney, NSW: UNSW Press; 2008.
Jacsó, P. Google Scholar’s ghost authors. Library Journal. 2009; 134(18):26.
Microsoft, What is Microsoft Academic Search?. 2011. Retrieved from. http://academic.research.microsoft.com/About/Help.htm
Microsoft (n.d.) Microsoft Academic Search. Retrieved from http://academic.research.microsoft.com/.
Nie, Z., Zhang, Y., Wen, J.-R., Ma, W.-Y., Object-level ranking: bringing order to web objects. World Wide Web Conference Series. 2005:567–574.
Scirus, About Scirus. 2001. Retrieved from. http://web.archive.org/web/200102042351/http://www.scirus.com/about.php
SciTopics (n.d.) About SciTopics. Retrieved from http://www.scitopics.com/about.jsp.
Wilcox, C., Social media for scientists Part 1: it’s our job [blog post]. 2011, 27 September. Retrieved from. http://blogs.scientificamerican.com/science-sushi/2011/09/27/social-media-for-scientists-part-1-its-our-job/
1For a history of online information services see Bourne, C.P. and Hahn, T.B. (2003) A History of Online Information Services, 1963–1976. Cambridge, MA: MIT Press.
2By coincidence, Science Citation Index may have included some of the full-text scientific eprints available in early digital archives and repositories. In 1992, Science Citation Index was sold to Thomson Health Systems and became available by subscription as Web of Science.
3Scirus was developed by Elsevier and therefore had access to their scientific indexes.
4For example, see Small, H. (1990) Bibliometrics of Basic Research. Philadeplphia, PA: Institute for Scientific Information, Inc.; Chen, C. and Boyack, K.W. (2003) Visualizing knowledge domains. Annual Review of Information Science and Technology, 37(1): 179–255; and Robert, C., Wilson, C.S., Gaudy, J.-F. and Arreto, C.-D. (2006) A year in review: bibliometric glance at sleep research literature in medicine and biology. Sleep and Biological Rhythms, 4(2): 160–70.
5For differing points of view see, for example, Jacsó, P. (2009) Google Scholar’s ghost authors. Library Journal, 134(18): 26; Smith, A.G. (2008) Benchmarking Google Scholar with the New Zealand PBRF research assessment exercise. Scientometrics, 74(2): 309–16; Meho, L.I. and Yang, K. (2007) Impact of data sources on citation counts and rankings of LIS faculty: Web of Science versus Scopus and Google Scholar. Journal of the American Society for Information Science and Technology, 58(13): 2105–25; and Harzing, A.W. (2007, last updated 20 December 2008) Google Scholar – a new data source for citation analysis. Retrieved 13 September 2011, from http://www.harzing.com/pop_gs.htm.
6For further details see the Budapest Open Access Initiative of 2002, http://www.soros.org/openaccess/; and Suber, P. (2008) Open Access in 2007. Journal of Electronic Publishing, 11(1).
7However, other studies show Google Scholar to be effective. According to Walters, ‘Google Scholar found 93% of [a specified reference set of articles in OA repositories] covering 27% more than Social Sciences Citation Index.’ See Walters, W.H. (2007) Google Scholar coverage of a multidisciplinary field. Information Processing & Management, 43(4): 1121–32.
8Currently, among the public search services only Scirus when harvesting OA content appears to harvest the OAI metadata; see Elsevier (2004, September) How Scirus Works: White Paper. Retrieved from http://www.Scirus.com/press/pdf/WhitePaper_Scirus.pdf.
9A relatively simple metric which says that a scholar with an index of h has published h papers, each of which has been cited in other papers at least h times.
10The current list can be found at http://www.info.sciverse.com/sciencedirect/content/journals/titles.
11See Elsevier (2011) JournalM3Metrics research analytics refined. Retrieved from http://www.info.sciverse.com/documents/files/scopus-training/resourcelibrary/pdf/journalmetrics_factsheet_web.pdf, and the white paper, Glänzel, W. (2010) The Evolution of Journal Assessment: How Research Performance Assessment has Changed Over the Past 50 Years. Retrieved from http://www.info.sciverse.com/documents/files/scopus-training/resourcelibrary/pdf/whitepaper9_com.pdf.
12For a discussion of Elsevier’s SNIP metric see Moed, H.F. (2010) Measuring contextual citation impact of scientific journals. Journal of Informetrics, 4(3): 265–77.
13See master journal list at http://science.thomsonreuters.com/mjl/. A nice feature of this list is that within each index the journals are categorized by discipline, e.g., archaeology, with the social sciences.
14The documentation refers to the Microsoft Live search; presumably this is now using Microsoft Academic Search.