
There are many real-life situations when you have to clean your data. Let's assume that you want to index web pages that your client sends you. You don't know anything about the structure of the page; one thing you know is that you must provide a search mechanism that will enable searching through the content of the pages. Of course, you can index the whole page splitting it by whitespaces, but then you will probably hear the client complain about the HTML tags being searchable, and so on. So, before we enable searching on the contents of the page, we need to clean the data. In this recipe, we will see how to remove the HTML tags with Solr.
Now, let's take a look at the steps needed to remove the HTML tags from our data.
- We start by assuming that our data looks like this:
<add> <doc> <field name="id">1</field> <field name="html"><![CDATA[<html><head><title>My page</title></head><body><p>This is a <b>my</b><i>sample</i> page</body></html>]]></field> </doc> </add>
- Now, let's take care of the
schema.xmlfile. First, we need to add the type definition to theschema.xmlfile:<fieldType name="html_strip" class="solr.TextField"> <analyzer> <charFilter class="solr.HTMLStripCharFilterFactory"/> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
- The next step is to add the following to the field definition part of the
schema.xmlfile:<field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="html" type="html_strip" indexed="true" stored="false" />
- We can now index our data and have the HTML tags removed. Let's check this by going to the
analysissection of Solr administration pages and passing the<html><head><title>My page</title></head><body><p>This is a <b>my</b><i>sample</i> page</body></html>text to analyze, as shown in the following screenshot: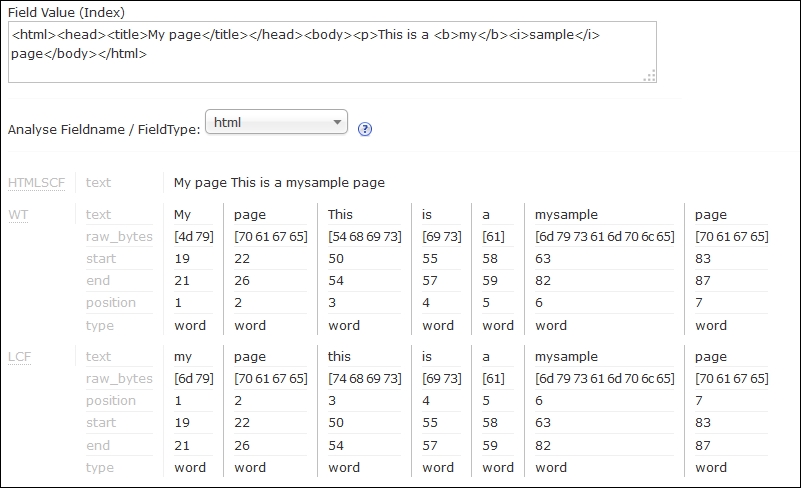
First, we have the data example. In the example, we see one file with two fields, the identifier, and some HTML data nested in the CDATA section. You must remember to surround the HTML data with CDATA tags if they are full pages and start from HTML tags, as shown in our example. Otherwise, Solr will have problems parsing the data. However, if you only have some tags present in the data, you shouldn't worry.
Next, we have the html_strip field type definition. It is based on solr.TextField to enable a full-field analysis. Following this we have a character filter that handles the HTML and XML tag stripping. The character filters are invoked before the data is sent to the tokenizer. This way, they can operate on untokenized data. In our case, the character filter strips the HTML and XML tags, attributes, and so on, and then sends the data to the tokenizer that splits it by whitespace characters. The one and only filter defined in our type makes the tokens lowercase to simplify the search.
If you want to check how your data was indexed, remember not to be mistaken when you choose to store the field contents (the stored="true" attribute). The stored value is the original one sent to Solr, so you won't be able to see the filters in action.
If you wish to check the actual data structures, take a look at the Luke utility (a utility that lets you see the index structure and field values and operates on the index). Luke can be found by visiting http://code.google.com/p/luke. Instead of using Luke, I decided to use the analysis capabilities of Solr administration pages and see how the html field behaves when we pass the example value provided in the example data file.
There is one additional thing that I would like to mention, which is mentioned in the following section.
Sometimes, you might want to preserve some of the tags that are part of the input document. To do this, you can include the escapedTags property that should contain a comma-separated list of tags we want to preserve. For example, if you want Solr to preserve and escape the title tags, our solr.HTMLStripCharFilterFactory configuration will look as follows:
<charFilter class="solr.HTMLStripCharFilterFactory" escapedTags="a, title" />
Instead of using the char filter factory, we can use the update request processor for removing the HTML tags. It might be useful if you only need to remove HTML tags from some documents. In such cases, you should define multiple update request processor chains, but only one will have the HTML tag removing processor. If you want to do this, refer to the solr.HTMLStripFieldUpdateProcessorFactory Javadoc available at http://lucene.apache.org/solr/4_10_0/solr-core/org/apache/solr/update/processor/HTMLStripFieldUpdateProcessorFactory.html.