
Let's assume that we want to search inside user blog posts. We need to prepare a simple search returning only the identifier of the documents that were matched. However, we will want to remove some words because of explicit language. Of course, we can do this using the stop words functionality, but what if we want to know how many documents have their contents censored with compute statistics on. In such a case, we can't use the stop words functionality, we need something more, which means that we need regular expressions. This recipe will show you how to achieve such requirements using Solr and one of its filters.
To achieve our needs, we will use the solr.PatternReplaceFilterFactory filter. Let's assume that we want to remove all the words that start with the word prefix. These are the steps needed:
- First, we need to create our index structure, so the fields we add to the
schema.xmlfile are as follows:<field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="post" type="text_ignore" indexed="true" stored="false" />
- We also need to define the
text_ignorefield type by adding the following section to theschema.xmlfile:<fieldType name="text_ignore" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory" /> <filter class="solr.PatternReplaceFilterFactory" pattern="word[a-zA-Z0-9]*" replacement="[censored]" /> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
- Now, we can index our test data that looks as follows:
<add> <doc> <field name="id">1</field> <field name="post">First post</field> </doc> <doc> <field name="id">2</field> <field name="post">Second post single word</field> </doc> <doc> <field name="id">3</field> <field name="post">Third post and the word1</field> </doc> </add>
- First, before running our query, let's see if we are actually changing tokens starting with the
wordprefix to[censored], just like we want to. We do this using the analysis tool from the Solr admin panel. The result can be seen in the following screenshot: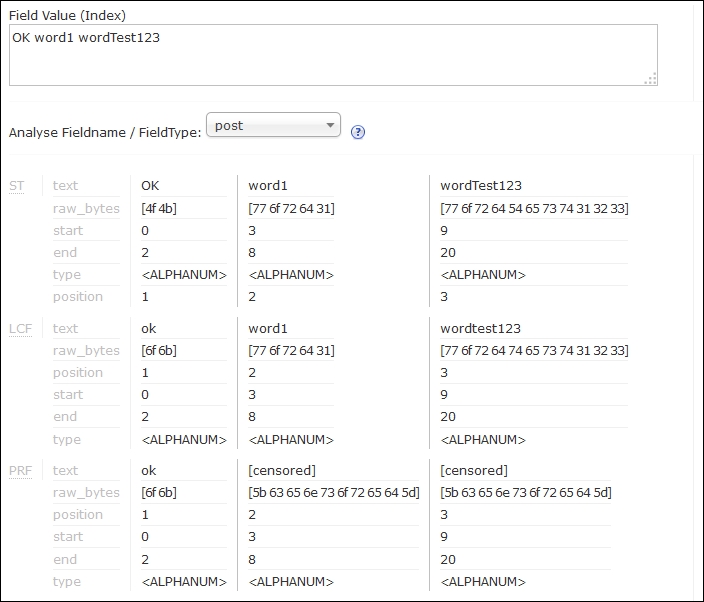
- Now, let's compute the statistics we are looking for. To do this, we will use the following query:
http://localhost:8983/solr/cookbook/select?q=*:*&rows=0&facet=true&facet.query={!raw f=post}[censored] - The results returned by Solr are as follows:
<?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">1</int> <lst name="params"> <str name="facet.query">{!raw f=post}[censored]</str> <str name="q">*:*</str> <str name="rows">0</str> <str name="facet">true</str> </lst> </lst> <result name="response" numFound="3" start="0"> </result> <lst name="facet_counts"> <lst name="facet_queries"> <int name="{!raw f=post}[censored]">2</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> <lst name="facet_ranges"/> </lst> </response>
As we can see, everything works, so now let's look at how all of this was achieved.
As we already said, our index structure is very simple. We only need two things; the first is the document identifier, which is held by the id field, which we store and return in the results, and the second is the post field that holds the post contents.
The post field uses our new type, text_ignore. The type itself is rather simple, it uses solr.StandardTokenizerFactory to tokenize data (both during querying and indexing); we then lowercase the data by using solr.LowerCaseFilterFactory. On the indexing side, however, we do one more thing—we use the solr.PatternReplaceFilterFactory filter. We use it because it allows us to not only remove some words but also to replace them. Of course, we can use synonyms (described in the Using synonyms recipe of this chapter), but they only work on whole words, not on patterns in which we want them to work. Basically, what we do here is replace every word starting with the word pattern with the [censored] term. We achieve this by specifying a simple regular expression (pattern="word[a-zA-Z0-9]*"), telling Solr to match every word starting with the given prefix and followed by characters or numbers (yes, I know that the regex can be more complicated, but this is only an example). In addition to this, we said that we want the matched word to be replaced by the [censored] term (replacement="[censored]").
As you can see in the preceding screenshot, our filter is working as it should. During indexing, a term that starts with the word prefix is changed to the term [censored].
Now, let's look into our analysis query. We are interested in all the documents that are in our collection (q=*:*), and we will use faceting to get the information about the number of documents with the[censored] term (facet.query={!raw f=post}[censored]). We used the raw query parser and sent the facet query against the post field (f=post) to easily pass a term with the two Lucene special characters—[ and ]. As you can see, we got the count in the results—two documents out of three have at least a single word censored.
There is one additional thing I will like to mention, check the next section.
Sometimes, we want to do an analysis before the field text is actually tokenized. Solr allows us to do this by providing the solr.PatternReplaceCharFilterFactory char filter, which can be used to do the analysis on the whole text before it is passed to the tokenizer. If we want our recipe example to use the char filter instead of the token filter, we need to change our text_ignore type definition as follows:
<fieldType name="text_ignore" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <charFilter class="solr.PatternReplaceCharFilterFactory" pattern="word[a-zA-Z0-9]*" replacement="[censored]" /> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
You might want to follow this method if you need to operate on the whole text and not on the tokens produced by the tokenizer.