
Nowadays, it's nice to have stemming algorithms (algorithms that will reduce words to their stem or root forms) in your application, which will allow you to find words such as cat and cats just by typing cat. However, let's imagine that you have a search engine that searches through contents of the books in a library. One of the requirements is changing the plural forms of the words from plural to singular; nothing less, nothing more. Can Solr do this? Yes, Solr can do this, and this recipe will show you how to do it.
- First, let's start with a simple, two-field index (add the following section to your
schema.xmlfile):<field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="description" type="text_light_stem" indexed="true" stored="true" />
- Now, let's define the
text_light_stemfield type, which should look like this (add this to yourschema.xmlfile):<fieldType name="text_light_stem" class="solr.TextField"> <analyzer> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.EnglishMinimalStemFilterFactory" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
- Then, let's check the analysis tool of Solr administration pages; you should see that words such as
ways,keys, andpopulationshave been changed to their singular forms: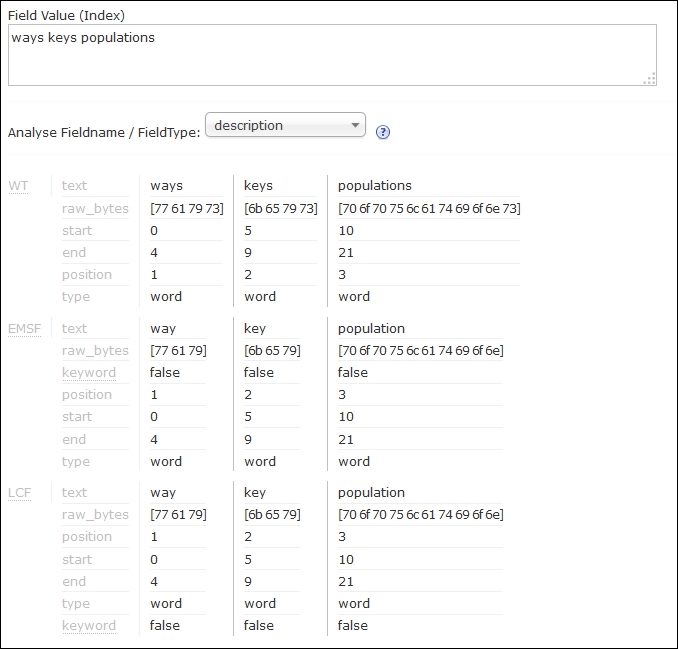
First, we need to define the fields in the schema.xml file. We do this by adding the contents from the first example into the schema.xml file. It tells Solr that our index will consist of two fields—the id field that will be responsible for holding information about the unique identifier of the document, and the description file that will be responsible for holding the document description.
The description field is where the magic is being done. We defined a new field type for this field, and we called it text_light_stem. The field definition consists of a tokenizer and two filters. The solr.WhitespaceTokenizerFactory tokenizer splits the words on the basis of whitespace characters. The first filter is the one we are interested in. This is the light-stemming filter that we will use to perform minimal stemming. In general, aggressive stemming can and will change the words more, while minimal stemming is usually about removing the plural forms. The class that enables Solr to use this filter is solr.EnglishMinimalStemFilterFactory. This filter takes care of the process of light stemming. You can see this by using analysis tools of the Solr administration panel. The second filter, solr.LowerCaseFilterFactory is responsible for lowercasing terms.
Light stemming supports a number of different languages. To use the light stemmers for your respective language, add the following filters to your type:
|
Language |
Filter |
|---|---|
|
Russian |
|
|
Portuguese |
|
|
French |
|
|
German |
|
|
Italian |
|
|
Spanish |
|
|
Hungarian |
|
|
Swedish |
|
|
Finish |
|
|
Indonesian |
|
|
Norwegian |
|
In the case of solr.IndonesianStemFilterFactory, you need to add the stemDerivational="false" attribute in order to have it working as a light stemmer.