
DICTIONARIES
A dictionary is a collection that associates keys with values. You look up a key, and the dictionary provides you with the corresponding value. This is similar to the way a NameValueCollection works, except that a dictionary’s keys and values need not be strings, and a dictionary associates each key with a single value object.
Visual Studio provides several different kinds of dictionary classes that are optimized for different uses. Their differences come largely from the ways in which they store data internally. Although you don’t need to understand the details of how the dictionaries work internally, you do need to know how they behave so that you can pick the best one for a particular purpose.
Because all of the dictionary classes provide the same service (associating keys with values), they have roughly the same properties and methods. The following table describes some of the most useful of these.
| PROPERTY/METHOD | DESCRIPTION |
| Add | Adds a key/value pair to the dictionary. |
| Clear | Removes all key/value pairs from the dictionary. |
| Contains | Returns True if the dictionary contains a specific key. |
| CopyTo | Copies the dictionary’s data starting at a particular position into a one-dimensional array of DictionaryEntry objects. The DictionaryEntry class has Key and Value properties. |
| Count | Returns the number of key/value pairs in the dictionary. |
| Item | Gets or sets the value associated with a key. |
| Keys | Returns a collection containing all of the dictionary’s keys. |
| Remove | Removes the key/value pair with a specific key. |
| Values | Returns a collection containing all of the dictionary’s values. |
The following sections describe different Visual Studio dictionary classes in more detail.
ListDictionary
A ListDictionary stores its data in a linked list. In a linked list, each item is held in an object that contains its data plus a reference or link to the next item in the list.
Figure 25-2 illustrates a linked list. This list contains the key/value pairs Appetizer/Salad, Entrée/Sandwich, Drink/Water, and Dessert/Cupcake. The link out of the Dessert/Cupcake item is set to Nothing, so the program can tell when it has reached the end of the list. A reference variable inside the ListDictionary class, labeled Top in Figure 25-2, points to the first item in the list.
FIGURE 25-2: Each item in a linked list keeps a reference to the next item in the list.
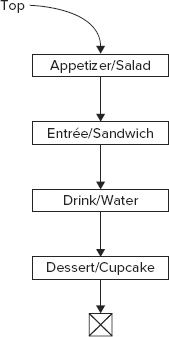
The links in a linked list make adding and removing items relatively easy. The ListDictionary simply moves the links to point to new objects, add objects, remove objects, or insert objects between two others. For example, to add a new item at the top of the list, you create the new item, set its link to point to the item that is currently at the top, and then make the list’s Top variable point to the new item. Other rearrangements are almost as easy. For more information on how linked lists work, see a book on algorithms and data structures such as Data Structures and Algorithms Using Visual Basic.NET (McMillan, Cambridge University Press, 2005).
Unfortunately, if the list grows long, finding items in it can take a long time. To find an item in the list, the program starts at the top and works its way down, following the links between items, until it finds the one it wants. If the list is short, that doesn’t take very long. If the list holds 100,000 items, this means potentially a 100,000-item crawl from top to bottom. That means a ListDictionary object’s performance degrades if it contains too many items.
If you need to store only a few hundred items in the dictionary and you don’t need to access them frequently, a ListDictionary is fine. If you need to store 100,000 entries, or if you need to access the dictionary’s entries a huge number of times, you may get better performance using a “heavier” object such as a Hashtable. A Hashtable has more overhead than a ListDictionary but is faster at accessing its entries.
Hashtable
A Hashtable looks a lot like a ListDictionary on the outside, but internally it stores its data in a very different way. Rather than using a linked list, this class uses a hash table to hold data.
A hash table is a data structure that allows extremely fast access to items using their keys. Exactly how hash tables work is interesting but outside the scope of this book. For more information, see a book on algorithms and data structures such as Data Structures and Algorithms Using Visual Basic.NET (McMillan, Cambridge University Press, 2005).
To use a hash table, however, you should know a few of their external characteristics.
Hash tables provide extremely fast lookup but they require a fair amount of extra space. If a hash table becomes too full, it must resize itself and rearrange the items it contains to remain efficient.
Resizing a hash table can take some time so the Hashtable class provides some extra tools to help you avoid resizing.
One overloaded version of the Hashtable class’s constructor takes a parameter that tells how many items the table should initially be able to hold. If you know you are going to load 1000 items into the Hashtable, you might initially give it enough room to hold 1500 items. Then the program could add all 1000 items without filling the table too much, so it would still give good performance. If you don’t set an initial size, the hash table might start out too small and need to resize itself many times before it could hold 1000 items, and that will slow it down.
Another version of the constructor lets you specify the hash table’s load factor. The load factor is a number between 0.1 and 1.0 that gives the largest ratio of elements to spots in the table that the Hashtable will allow before it enlarges its internal table. You can use the load factor to prevent a Hashtable from becoming too full, which degrades its performance. For example, suppose that the Hashtable’s capacity is 100 and its load factor is 0.8. Then when it holds 80 elements, the Hashtable will enlarge its internal table to make more room.
For high-performance lookups, the Hashtable class is a great solution as long as it doesn’t resize too often and doesn’t become too full.
HybridDictionary
A HybridDictionary is a cross between a ListDictionary and a Hashtable. If the dictionary is small, the HybridDictionary stores its data in a ListDictionary. If the dictionary grows too large, HybridDictionary switches to a Hashtable.
If you know that you will only need a few items, use a ListDictionary. If you know you will need to use a very large number of items, use a Hashtable. If you are unsure whether you will have few or many items, you can hedge your bet with a HybridDictionary. It’ll take a bit of extra time to switch from a list to a Hashtable if you add a lot of items, but you’ll save time in the long run if the list does turn out to be enormous.
StringDictionary
The StringDictionary class uses a hash table to manage keys and values that are all strings. Because it uses a hash table, it can handle very large data sets quickly.
Its methods are strongly typed to require strings, so they provide extra type checking that can make finding potential bugs easier. For that reason, you should use a StringDictionary instead of a generic ListDictionary or Hashtable if you want to work exclusively with strings.
SortedList
The SortedList class acts as a Hashtable/Array hybrid. When you access a value by key, it acts as a hash table. When you access a value by index, it acts as an array containing items sorted by key value. For example, suppose that you add a number of Job objects to a SortedList named jobs using their priorities as keys. Then jobs(0) always returns the job with the smallest priority value.
Example program UseSortedList, which is available for download on the book’s website, demonstrates the SortedList class.
A SortedList is more complicated than a Hashtable or an array, so you should only use it if you need its special properties.