
Chapter 13
RSS, Atom, and Content Syndication
WHAT YOU WILL LEARN IN THIS CHAPTER:
- Concepts and technologies of content syndication and meta data
- A brief look at the history of RSS, Atom, and related languages
- What the feed languages have in common and how they differ
- How to implement a simple newsreader/aggregator using Python
- Examples of XSLT used to generate and display news feeds
One of the interesting characteristics of the web is the way that certain ideas seem to arise spontaneously, without any centralized direction. Content syndication technologies definitely fall into this category, and they have emerged as a direct consequence of the linked structure of the web and general standardization regarding the use of XML.
This chapter focuses on a number of aspects of content syndication, including the RSS and Atom formats and their role in such areas as blogs, news services, and the like. It’s useful to understand them not just from an XML-format standpoint, but also in terms of how they are helping to shape the evolving Internet.
There is a lot more to RSS, Atom, and content syndication than can be covered in a single chapter, so the aim here is to give you a good grounding in the basic ideas, and then provide a taste of how XML tools such as SAX and XSLT can be used in this field.
SYNDICATION
Over the course of the twentieth century, newspapers evolved into different kinds of news organizations with the advent of each new medium. Initially, most newspapers operated independently, and coverage of anything beyond local information was usually handled by dedicated reporters in major cities. However, for most newspapers, such reporters are typically very costly to maintain. Consequently, these news organizations pool their resources together to create syndicates, feeding certain articles (and columns) to the syndicates, who would then license them out to other publishers. These news syndicates, or services, specialize in certain areas. Associated Press (AP) and United Press International (UPI) handle syndication within the United States, while Reuters evolved as a source for European news. Similarly, comic strips are usually handled by separate syndicates (such as King Features Syndicate).
The news services aggregate news from a wide variety of different sources and, hopefully alongside original material, publish the result as a unified whole, the newspaper. One advantage of this approach is that it is possible to bundle related content together, regardless of the initial source. For instance, a sports-dedicated publication may pull together all articles on baseball, football, and basketball, but the feed wouldn’t include finance articles unless they were sports-related.
A syndication feed is an online parallel to the syndicated publication of a cartoon strip or sports paper. If a website (or any other source) has information that appears in little, topically-categorized chunks over time, it’s probably a good idea to create a syndication feed for it. For the web publisher it offers another kind of exposure, and for the web consumer it offers alternative ways of getting up-to-date information. For the developer, it’s an established platform on which useful and interesting tools can be built.
In practice, syndication feeds are published as single XML files comprised of meta data elements and, in most cases, content as well. Several distinct standard formats exist. Each format shares a common basic model of a syndication feed. There is the feed itself, which has characteristics such as a title and publication date. The overall structure of a feed can be seen in Figure 13-1. The feed carries a series of discrete blocks of data, known as items or entries, each of which also has a set of individual characteristics, again such as title and date. These items are little chunks of information, which either describe a resource on the web (a link is provided) or are a self-contained unit, typically carrying content along with them.
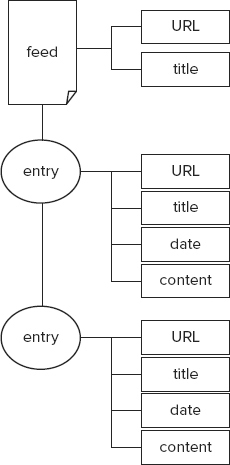
Typically, a feed contains 10–20 entries. Note that in addition to the elements described in the specifications, each of the format types support extensions through various mechanisms.
XML Syndication
The three primary XML formats for syndication are RSS 1.0, RSS 2.0, and Atom. Despite having a very similar data model (refer to Figure 13-1), they are largely incompatible with each other in terms of syntax. In practice they can generally be used interchangeably, and that’s how they’re mostly found in the wild. For the consumer of syndicated feeds, this is bad news: essentially you have to support all three species (and variants). For the producer it could be seen as good news; each format has advantages and may be best suited to a particular deployment. The syndication formats have a colorful history, which is worthwhile reviewing to see how the present state of affairs has come to be.
A Little History
Web syndication arguably began in the mid-1990s, with the development of the Meta Content Framework (MCF) at Apple, essentially a table of contents for a website. This was a significant precursor of the Resource Description Framework (RDF). Not long after, Microsoft entered the fray with its Content Definition Format (CDF). This was specifically targeted to be a comprehensive syndication format that would appeal to traditional broadcasters, and support for it was built into Internet Explorer (since discontinued).
The CDF model of a feed and its items is essentially the same model in use today in all syndication formats, and it contains features that found their way into RSS and have stayed there ever since — channel (feed), item, title, and so on.
RSS first got its initials with RDF Site Summary (RSS) 0.9 from Netscape in early 1999. However, Netscape soon backed away from its original RDF-oriented approach to RSS, and its RSS 0.91 was more conventional XML. Out went RDF and namespaces and in came a DTD and a new name: Rich Site Summary. Not long after this, Netscape dropped RSS altogether. Dave Winer of the pioneering content-management system company Userland then adopted RSS and made it his own, releasing a slightly different version of RSS 0.91.
However, around the same time Winer was working on the RSS 0.91 line, an informal mailing list sprang up, RSS-DEV, with a general consensus that the RDF-based approach of RSS 0.9 (and Netscape’s original planned future direction for RSS) was the best; and the result was the RSS 1.0 specification.
This proposal clashed head-on with the RDF/namespace-free 0.91 approach followed by Winer. Agreement wasn’t forthcoming on a way forward, and as a result, RSS forked. One thread carried the banner of simplicity, the other of interoperability. Winer rebranded his version of RSS to Really Simple Syndication.
Then in 2002 Winer delivered something of a marketing coup: he released an RSS 2.0 specification and declared it frozen. This followed the RSS 0.91 side of the fork, with syntax completely incompatible with RSS 1.0. Namespace support was reintroduced, but only for extensions. While people continued to publish (and still do) RSS 1.0 feeds, the RSS 2.0 version gained a significant amount of new adoption, due in no small part to the evangelism of the specification’s author.
The Self-Contained Feed
A lot of the development of RSS was driven by developments in web content management and publishing, notably the emergence of the blog (from “web log”). Similar to today, some early blogs were little more than lists of links, whereas others were more like online journals or magazines. This distinction is quite important in the context of syndication formats. The original RSS model contained a URL, title, and description, which all referred to the linked material, with its (remote) content. But increasingly the items in a feed corresponded with entries in a blog, to the extent that the feed became essentially another representation of the blog. The URL became the link to a (HTML) post sharing the same title, and the description became the actual content of that post, or a condensed version of it.
The demand for content in feeds highlighted a significant problem with the RSS 2.0 specification: It says that the <description> element may contain HTML, and that’s all it says. There is no way for applications to distinguish HTML from plaintext, so how do you tell what content is markup and what content is just talking about markup?
This and other perceived problems with RSS 2.0 led to another open community initiative that launched in the summer of 2003, with the aim of fixing the problems of RSS 2.0 and unifying the syndication world (including the RSS 1.0 developers). Accepting the roadmap for RSS presented in the RSS 2.0 specification meant the name RSS couldn’t be used, and after lengthy discussion the new project got a name: Atom. Before moving on to descriptions of what feed XML actually looks like, you should first know its purpose.
Syndication Systems
Like most other web systems, syndication systems are generally based around the client-server model. At one end you have a web server delivering data using the HyperText Transfer Protocol (HTTP), and at the other end is a client application receiving it. On the web, the server uses a piece of software such as Apache or IIS, and the client uses a browser such as Internet Explorer (IE) or Firefox. HTML-oriented web systems tend to have a clear distinction between the roles and location of the applications: the server is usually part of a remote system, and the client appears on the user’s desktop. HTML data is primarily intended for immediate rendering and display for users to read on their home computer. Data for syndication takes a slightly different approach.
The defining characteristic of web syndication systems is that they follow a publish-subscribe pattern. This is a form of communication where senders of messages, called publishers, create the messages without knowledge of what, if any, subscribers there may be. Subscribers express interest in the messages of particular types or from particular sources, and receive only messages that correspond to those choices.
In the case of web syndication, the publisher generates a structured document (the feed) at a given URL. Subscribers use a dedicated tool, known as a newsreader, feed reader, or aggregator, to subscribe to the URL. Typically the subscriber’s tool will periodically read (or poll) the document at the URL. The tool does this automatically; say once an hour or once a day. Over time the publisher will add new items to the feed (removing older ones), so that next time subscribers poll the feed, they receive the new material.
This isn’t unlike visiting a site periodically with a browser to find out what’s new. However, syndication material is designed to support automation and, hence, needs to be machine-readable. This means there is at least one extra stage of processing before the content appears on the user’s screen. The machine-readability means that it is possible to pass around and process the data relatively easily, allotting for a huge amount of versatility in systems. The net result is that applications that produce material for syndication purposes can appear either server side or client side (desktop), as can applications that consume this material.
Key to understanding the differences between syndication and typical web pages is the aspect of time. A syndicated resource (an item in a feed) is generally available only for a short period of time at a given point in the network, at which stage it disappears from the feed, although an archived version of the information is likely archived on the publisher’s site.
The different kinds of syndication software components can roughly be split into four categories: server-producer, client-consumer, client-producer, and server-consumer. In practice, software products may combine these different pieces of functionality, but it helps to look at these parts in isolation.
The following sections provide an overview of each, with the more familiar systems first.
Server-Producer
A server-producer, also known as a server-side system for publishing syndication material, is in essence no different from any typical web system used to publish regular HTML web pages. At minimum, this would be a static XML file in one of the syndication formats placed on a web server. More usefully, the XML data will be produced from some kind of content management system. The stereotypical content management systems in this context are blog tools. The main page of the (HTML) website features a series of diary-like entries, with the most recent entry appearing first. Behind the scenes is some kind of database containing the entry material, and the system presents this in reverse chronological order on a nicely formatted web page. In parallel with the HTML-generating subsystems of the application are syndication feed format (RSS and/or Atom) producing subsystems. These two subsystems are likely to be very similar, because the feed material is usually a bare-bones version of the HTML content. Many blogging systems include a common templating system, which may be used to produce either HTML or syndication-format XML.
Client-Consumer
Although it is possible to view certain kinds of syndicated feeds in a web browser, one of the major benefits of syndication comes into play with so-called newsreaders or aggregator tools. The reader application enables users to subscribe to a large number of different feeds, and present the material from these feeds in an integrated fashion. There are two common styles of a feed-reader user interface:
- Single pane styles present items from the feeds in sequence, as they might appear on a web log.
- Multipane styles are often modeled on e-mail applications, and present a selectable list of feeds in one panel and the content of the selected feed in another.
The techniques used to process and display this material vary considerably. Many pass the data directly to display, whereas others incorporate searching and filtering, usually with data storage behind the scenes; and occasionally, Semantic Web technologies are used to provide integration with other kinds of data.
Some newsreaders use a small web server running on the client machine to render content in a standard browser. Wide variations also exist in the sophistication of these tools. Some provide presentation of each feed as a whole; others do it item-by-item by date, through user-defined categories or any combination of these and other alternatives. You’ll see the code for a very simple aggregator later in this chapter.
There’s a useful page on Wikipedia containing lists of feed readers and comparing their characteristics at http://en.wikipedia.org/wiki/Comparison_of_feed_aggregators.
Client-Producer
Now you know that the server-producer puts content on a web server and the client-consumer processes and displays this content, but where does the content come from in the first place? Again, blogging tools are the stereotype. Suppose an author of a blog uses a tool to compose posts containing his thoughts for the day plus various cat photos. Clicking a button submits this data to a content management system that will typically load the content into its database for subsequent display, as in the preceding server-producer. The client-producer category covers desktop blogging clients such as BlogEd, Ecto, and Microsoft Windows Live Writer, which run as conventional applications. (Note that availability of tools like these is changing all the time; a web search for “desktop blogging tools” should yield up-to-date information.) Several existing desktop authoring tools incorporate post-to-blog facilities (for example, you can find plug-ins for MS Word and OpenOffice). When the user clicks Submit (or similar), the material is sent over the web to the content management system. However, the four categories presented here break down a little at this point, because many blogging tools provide authoring tools from the web server as well, with users being presented a web form in which they can enter their content.
A technical issue should be mentioned at this point. When it comes to communications, the server-producer and client-consumer systems generally operate in exactly the same way as HTML-oriented web servers and clients using the HTTP protocol directly. The feed material is delivered in one of the syndication formats: RSS or Atom.
However, when it comes to posting material to a management system, other strategies are commonly used. In particular, developers of the Blogger blogging service designed a specification for transmitting blog material from the author’s client to the online service. Although the specification was intended only as a prototype; the “Blogger API” became the de facto standard for posting to blogging and similar content management systems. The Blogger API defines a small set of XML-RPC (remote procedure calling) elements to encode the material and pass it to the server. There were certain limitations of this specification, which led to the MetaWeblog API that extends the elements in a way that makes it possible to send all the most common pieces of data that might be required. There was a partial recognition in the MetaWeblog API that a degree of redundancy existed in the specifications. The data that is passed from an authoring tool is essentially the same, in structure and content, as the material passed from the server to newsreaders, so the MetaWeblog API uses some of the vocabulary of RSS 2.0 to describe the structural elements.
Since the XML-RPC blogging APIs came out, there has been a growing realization in the developer community that not only is there redundancy at the level of naming parts of the messages being passed around, but also in the fundamental techniques used to pass them around. To transfer syndicated material from a server to a client, the client sends an HTTP GET message to the server, and the server responds with a bunch of RSS/Atom-formatted data. On the other hand, when transferring material from the client to the server, the blogging APIs wrap the content in XML-RPC messages and use an HTTP POST to send that. The question is, why use the XML-RPC format when there is already a perfectly good RSS or Atom format? Recent developments have led to a gradual shift from XML-RPC to the passing of XML (or even JSON) data directly over HTTP, and more use of the less familiar HTTP verbs, such as PUT (to replace an XML document on the web) and DELETE (to remove a resource). Most established in the field is the Atom Publication Protocol (http://tools.ietf.org/html/rfc5023), a specification from the same group that produced the Atom format.
Server-Consumer
The notion of a server-consumer component covers several different kinds of functionality, such as the functionality needed to receive material sent from a client-producer, blog posts, and the like. This in itself isn’t particularly interesting; typically, it’s not much different than authoring directly on the server except the material is posted via HTML forms.
But it’s also possible to take material from other syndication servers and either render it directly, acting as an online equivalent of the desktop newsreader, or process the aggregated data further. This approach is increasingly common, and online newsreaders such as Google Reader are very popular. The fact that feed data is suitable for subsequent processing and integration means it offers considerable potential for the future. Various online services have used syndicated data to provide enhanced search capabilities, however two of the pioneers, PubSub and Tailrank, are no longer in operation. It’s interesting to note how similar functionality has found its way into systems like Twitter and Google Plus.
TechMeme (www.techmeme.com) is an example of a smarter aggregator, in that it uses heuristics (rules of thumb) on the data found on blogs to determine the most significant stories, treating an incoming link as a sign of importance for an entry. Plenty of fairly centralized, mass-appeal services are available, but there’s also been a lot of development in the open source world of tools that can offer similar services for special-interest groups, organizations, or even individuals. It’s relatively straightforward to set up your own “Planet” aggregations of topic-specific feeds by downloading and installing the Planet (www.planetplanet.org) or Chumpalogica (http://www.hackdiary.com/projects/chumpologica/) online aggregation applications. The Planet Venus aggregator (http://intertwingly.net/code/venus/docs/), an offshoot of Planet, includes various pieces of additional functionality, such as a personalized “meme-tracker” similar to TechMeme. An example of how such systems can be customized is Planète Web Sémantique (http://planete.websemantique.org/). This site uses Planet Venus to aggregate French-language posts on the topic of the Semantic Web. Because many of the bloggers on its subscription list also regularly post on other topics and in English, such material is filtered out (actually hidden by JavaScript).
Format Anatomy
Having heard how the mechanisms of syndication work, now it’s time to look at the formats themselves. To avoid getting lost in the markup, you may find it useful to refer back to the diagram in Figure 13-1 to keep a picture in your mind of the overall feed structure.
RSS 2.0
You can find the specification for RSS 2.0 at http://cyber.law.harvard.edu/rss/rss.html. It’s a fairly readable, informal document (which unfortunately has been a recurring criticism due to ambiguities in its language).
The format style of RSS 2.0 is hierarchical. The syntax structure looks like this:
rss
channel
(elements containing meta data about the feed)
item
(item content and meta data)
item
(item content and meta data)
...
In practice, most of the elements are optional; as long as the overall structure follows the preceding pattern, a reader should be able to make some sense of it.
The following is an extract from an RSS 2.0 feed. The original (taken from http://www.fromoldbooks.org/rss.xml) contained 20 items, but in the interests of space here all but one have been removed:
<?xml version=”1.0” encoding=”utf-8”?>
<rss version=”2.0”>
<channel>
<title>Words and Pictures From Old Books</title>
<link>http://www.fromoldbooks.org/</link>
<description>Recently added pictures scanned from old books</description>
<pubDate>Tue, 14 Feb 2012 08:28:00 GMT</pubDate>
<lastBuildDate>Tue, 14 Feb 2012 08:28:00 GMT</lastBuildDate>
<ttl>180</ttl>
<image>
<url>http://www.holoweb.net/~liam/presspics/Liam10-70x100-amazon.jpg</url>
<title>Words and Pictures From Old Books</title>
<link>http://www.fromoldbooks.org/</link>
</image>
<item>
<title>Winged Mermaid from p. 199 recto, from Buch der Natur
[Book of Nature] (1481), added on 14th Feb 2012</title>
<link>http://www.fromoldbooks.org/Megenberg-
BookderNatur/pages/0199r-detail-mermaid/</link>
<description>
<p>A fifteenth-century drawing of a mermaid with wings (and breast)
taken from <a href=”0199r-strange-creatures”>fol. 199r</a> of a (somewhat dubious) textbook
on natural history.</p> <p>The mermaid has the trunk and head of a woman, the tail of a fish, and wings, or possibly large fins.</p></description>
<pubDate>Tue, 14 Feb 2012 08:19:00 GMT</pubDate>
<author>liam@holoweb.net (Liam Quin)</author>
<guid isPermaLink=”true”>http://www.fromoldbooks.org/Megenberg-
BookderNatur/pages/0199r-detail-mermaid/</guid>
</item>
...
</channel>
</rss>
The document begins with the XML declaration followed by the outer <rss> element. Inside this is the <channel> element where the data begins:
<?xml version=”1.0” encoding=”utf-8”?>
<rss version=”2.0”>
<channel>
<title>Words and Pictures From Old Books</title>
<link>http://www.fromoldbooks.org/</link>
<description>Recently added pictures scanned from old books</description>
<pubDate>Tue, 14 Feb 2012 08:28:00 GMT</pubDate>
<lastBuildDate>Tue, 14 Feb 2012 08:28:00 GMT</lastBuildDate>
<ttl>180</ttl>
These elements nested directly inside the <channel> element describe the feed itself. The preceding code contains the self-explanatory <title> and <description> along with a link. Note that the link refers to the website corresponding to the feed; this will typically be the homepage. The official publication date for the feed is expressed in the <pubDate> element using the human-readable format defined in RFC 822 (this specification is actually obsolete; if in doubt it’s probably safest to refer to the more recent RFC 5322: http://tools.ietf.org/html/rfc5322#section-3.3).
The <lastBuildDate> refers to the last time the content of the feed changed (the purpose being to make it easy for consumers to check for changes, although best practice is to use the HTTP headers for this purpose).
The <ttl> element refers to “time to live.” It’s effectively a hint to any clients as to how frequently the feed changes, hence how often they should update.
The channel-level <image> element that follows enables a client to associate a picture or icon with the feed. As well as the URL of the image to be displayed, it also contains some meta data, which is usually identical to the corresponding elements referring to the feed:
<image>
<url>http://www.holoweb.net/~liam/presspics/Liam10-70x100-amazon.jpg</url>
<title>Words and Pictures From Old Books</title>
<link>http://www.fromoldbooks.org/</link>
</image>
Next, still nested inside <channel>, the syndication items appear as content and meta data. The order of the elements inside <item> doesn’t matter; they are rearranged a little here from the original for clarity:
<item>
<description>
<p>A fifteenth-century drawing of a mermaid with wings (and breast)
taken from <a href=”0199r-strange-creatures”>fol. 199r</a> of a
(somewhat dubious) textbook on natural history.</p> <p>The mermaid has the trunk and head of a woman, the tail of a fish, and wings, or possibly large fins.</p></description>
The RSS 2.0 specification says of the <description> element that it’s “the item synopsis.” Though it may be a shortened version of a longer piece, publishers often include the whole piece of content they want to syndicate. The specification is silent on the format of the content, but in practice most aggregators will assume that it is HTML and render it accordingly. But because this is XML, the markup has to be escaped, so <p> becomes <p> and so on.
There then follows the meta data associated with this piece of content:
<title>Winged Mermaid from p. 199 recto, from Buch der Natur
[Book of Nature] (1481), added on 14th Feb 2012</title>
<pubDate>Tue, 14 Feb 2012 08:19:00 GMT</pubDate>
<author>liam@holoweb.net (Liam Quin)</author>
<link>http://www.fromoldbooks.org/Megenberg-
BookderNatur/pages/0199r-detail-mermaid/</link>
<guid isPermaLink=”true”>http://www.fromoldbooks.org/Megenberg-
BookderNatur/pages/0199r-detail-mermaid/</guid>
</item>
The <title> and <pubDate> are those of the content, which typically is also found (as HTML) at the URL specified in the <link> element. The author is specified as the e-mail address and (optionally) the name of the person who wrote the content.
The <guid> is specified as a string that is the “globally unique identifier” of the item. Although this can be arbitrary, most of the time the item will appear elsewhere (as HTML) so that URL can be used. In RSS 2.0, such a URL is indicated by using the isPermaLink attribute with the value true.
Usually there will be a series of around 10–20 items, before the channel-level and outer elements are closed off like so:
</channel> </rss>
Atom
Atom was developed as an open project using the processes of the Internet Engineering Task Force (IETF). The initial aim might have been to fix the problems of RSS, but it was realized early on that any sane solution would not only look at the format, but also take into account the protocols used in authoring, editing, and publication. So the Atom Publishing Format and Protocol was formed in June 2004. The first deliverable of the group, the Atom Syndication Format (RFC 4287, www.ietf.org/rfc/rfc4287.txt) was published in December 2005 followed by the Atom Publishing Protocol (http://tools.ietf.org/html/rfc5023) in October 2007.
These specifications are written a lot more formally than that of RSS 2.0, but are still quite approachable.
The Atom format is structurally and conceptually very much like its RSS predecessors, and its practical design lies somewhere between the RSS 1.0 and 2.0 versions. The syntax isn’t RDF/XML, but it does have a namespace itself and includes flexible extension mechanisms. Most of the elements are direct descendants of those found in RSS, although considerable work has given it robust support for inline content, using a new <content> element.
Most of the elements of Atom are self-explanatory, although the naming of parts differs from RSS, so an Atom feed corresponds to an RSS channel, an Atom entry corresponds to an RSS item, and so on. Here’s an example:
<feed xmlns=”http://www.w3.org/2005/Atom”>
<link rel=”self” href=”http://example.org/blog/index.atom”/>
<id>http://example.org/blog/index.atom</id>
<icon>../favicon.ico</icon>
<title>An Atom Sampler</title>
<subtitle>No Splitting</subtitle>
<author>
<name>Ernie Rutherford </name>
<email>[email protected]</email>
<uri>.</uri>
</author>
<updated>2006-10-25T03:38:08-04:00</updated>
<link href=”.”/>
<entry>
<id>tag:example.org,2004:2417</id>
<link href=”2006/10/23/moonshine”/>
<title>Moonshine</title>
<content type=”text”>
Anyone who expects a source of power from the transformation of the atom
is talking moonshine.
</content>
<published>2006-10-23T15:33:00-04:00</published>
<updated>2006-10-23T15:47:31-04:00</updated>
</entry>
<entry>
<id>>tag:example.org,2004:2416</id>
<link href=”2006/10/21/think”/>
<title type=”html”><strong>Think!</strong></title>
<content type=”xhtml”>
<div xmlns=”http://www.w3.org/1999/xhtml”>
<p>We haven't got the money, so we've got to think!</p>
</div>
</content>
<updated>2006-10-21T06:02:39-04:00</updated>
</entry>
</feed>
The first real enhancement is the <id> element, which roughly corresponds to the <guid> of RSS 2.0 and the rdf:about attribute found in RSS 1.0 (discussed in the net section) to identify entities. Rather than leave it to chance that this will be a unique string, the specification makes this a URI, which by definition is unique (to be more precise, it’s defined as an Internationalized Resource Identifier or IRI — for typical usage there’s no difference). Note the use of a tag: scheme URI in the example; these are not retrievable like http: scheme URIs. In effect, the identifiers (URIs) and locators (URLs) of entities within the format have been separated. This was a slightly controversial move, because many would argue that the two should be interchangeable. Time will tell whether or not this is a good idea. It is acceptable to use an http: URI in the <id> element, though in practice it’s probably better to follow the spirit of the Atom specification. Whereas the <id> element identifies, the <link> element locates. The Atom <link> element is modeled on its namesake in HTML, to provide a link and information about related resources.
Whereas the <id> makes it considerably easier and more reliable to determine whether two entries are the same, the <content> element offers a significant enhancement in the description of the material being published. It’s designed to allow virtually anything that can be passed over XML. In the first entry in the preceding example, the <entry> element has the attribute type=”text”. This explicitly states that the material within the element should not be treated as markup (and must not contain any child elements). The common case of HTML content is taken care of by making the attribute type=”html”. Again, there should be no child elements, and any HTML in the content should be escaped according to XML rules, so it would be <h1> (or one of the equivalent alternatives), rather than <h1>. However, although HTML content may be common, it’s not the most useful. Atom is an XML format, and namespaces make it possible for it to carry data in other XML formats, which can be addressed using standard XML tools. The third kind of content support built into Atom is type=”xhtml”. To use XHTML in Atom, it has to be wrapped in a (namespace-qualified) <div> element. The <div> itself should be ignored by any rendering or processing tool that consumes the feed; it’s only there for demarcation purposes.
Additionally, it’s possible to include other kinds of content by specifying the type attribute as the media type. For XML-based formats this is straightforward; for example, the Description of a Project (DOAP) format (https://github.com/edumbill/doap/wiki) uses RDF/XML, which has a media type of “application/rdf+xml”, and the DOAP vocabulary has the namespace “http://usefulinc.com/ns/doap#”. For example, a project description payload in Atom would look something like the following:
<content type=”application/rdf+xml”>
<doap:Project xmlns:doap=”http://usefulinc.com/ns/doap#”>
<doap:name>My Blogging Tool</doap:name>
...
</doap:Project>
</content>
Of course, not all data is found in XML formats. Text-based formats (that is, those with a type that begins “text/”) can be included as content directly, as long as only legal XML characters are used and the usual escaping is applied to reserved characters. Other data formats can be represented in Atom using Base 64 encoding. (This is a mapping from arbitrary sequences of binary data into a 65-character subset of US-ASCII.)
RSS 1.0
You can find the specification for RSS 1.0 at http://web.resource.org/rss/1.0/spec. The following code is an example of RSS 1.0 format :
<?xml version=”1.0” encoding=”UTF-8”?>
<rdf:RDF xmlns=”http://purl.org/rss/1.0/”
xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:dc=”http://purl.org/dc/elements/1.1/”
xmlns:sy=”http://purl.org/rss/1.0/modules/syndication/”
xmlns:content=”http://purl.org/rss/1.0/modules/content/”>
<channel rdf:about=”http://journal.dajobe.org/journal”>
<title>Dave Beckett - Journalblog</title>
<link>http://journal.dajobe.org/journal</link>
<description>Hacking the semantic linked data web</description>
<dc:date>2011-08-15T20:15:08Z</dc:date>
<items>
<rdf:Seq>
<rdf:li rdf:resource=”http://journal.dajobe.org/journal/posts/2010/06/28/happy-
10th-birthday-redland/”/>
<rdf:li
rdf:resource=”http://journal.dajobe.org/journal/posts/2010/03/20/command-line-semantic-web-with-redland/”/>
</rdf:Seq>
</items>
</channel>
<item rdf:about=”http://journal.dajobe.org/journal/posts/2010/06/28/happy-
10th-birthday-redland/”>
<title>Happy 10th Birthday Redland</title>
<link>http://journal.dajobe.org/journal/posts/2010/06/28/happy-10th-
birthday-redland/</link>
<dc:date>2010-06-28T16:03:54Z</dc:date>
<dc:creator>Dave Beckett</dc:creator>
<description>Redland‘s 10th year source code commit birthday is
today 28th Jun at 9:05am PST – the first commit was Wed Jun 28 17:04:57 2000 UTC. Happy 10th Birthday! Please celebrate with tea and
cake.</description>
<content:encoded><![CDATA[<p><a
href=”http://librdf.org/”>Redland</a>‘s 10th year source code commit birthday is today 28th Jun at 9:05am PST – the <a
href=”http://git.librdf.org/view?p=librdf.git;a=commit;h=8df358fb2bc1f4a69de08bc3fb4ae7d784395521”>first commit</a> was Wed Jun 28 17:04:57 2000 UTC.</p>
<p>Happy 10th Birthday! Please celebrate with tea and cake.</p>
]]></content:encoded>
</item>
</rdf:RDF>
To a human with a text editor, this format appears considerably more complex than RSS 2.0 or Atom. That’s because it’s RDF/XML, a syntax notorious for its complex nature. But despite the ugliness, it does have several advantages over RSS 2.0 and even Atom. These benefits all stem from the fact that a valid RSS 1.0 document is also a valid RDF document (and, not coincidentally, a valid XML document). Whatever a human might think, to a computer (for example, either a namespace-aware XML parser or an RDF tool), it contains the same kind of information as “simple” RSS but expressed in a less ambiguous and more interoperable form.
The XML has an outer <rdf:RDF> element (which incidentally is no longer a requirement of RDF/XML in general). Following the namespace declarations is a channel block, which first describes the channel feed itself and then lists the individual items found in the feed. The channel resource is identified with a URI, which makes the information portable. There’s no doubt what the title, description, and so on refer to. Title, link, description, and language are all defined in the core RSS 1.0 specification. XML namespaces (with the RDF interpretation) are employed to provide properties defined in the Dublin Core (dc:date) and Syndication (sy:updatePeriod, sy:updateFrequency) modules.
Take a look at the following snippet from the RSS 1.0 code example:
<items>
<rdf:Seq>
<rdf:li
rdf:resource=”http://journal.dajobe.org/journal/posts/2010/06/28/happy-10th-birthday-redland/”/>
<rdf:li
rdf:resource=”http://journal.dajobe.org/journal/posts/2010/03/20/command-line-semantic-web-with-redland/”/>
</rdf:Seq>
</items>
The channel here has an items property, which has the rdf:Seq type. The RSS 1.0 specification describes this as a sequence used to contain all the items, and to denote item order for rendering and reconstruction. After this statement, the items contained in the feed are listed, each identified with a URI. Therefore, the channel block describes this feed, specifying which items it contains.
The items themselves are listed separately: each is identified by a URI, and the channel block associates these resources with the channel, so there’s no need for XML element nesting to group them together. Each item has its own set of properties, a title, and a description, as shown in the preceding RSS formats, along with a link that is defined as the item’s URL. Usually, this is the same as the URI specified by the item’s own rdf:about attribute.
Now recall the following code from the source:
<item rdf:about=”http://journal.dajobe.org/journal/posts/2010/06/28/happy-
10th-birthday-redland/”>
<title>Happy 10th Birthday Redland</title>
<link>http://journal.dajobe.org/journal/posts/2010/06/28/happy-10th-
birthday-redland/</link>
Again, terms from Dublin Core are used for the subject, creator (author), and date. This makes it much better suited for broad-scale syndication, because Dublin Core has become the de facto standard for dealing with document-descriptive content. The properties look like this:
<dc:date>2010-06-28T16:03:54Z</dc:date>
<dc:creator>Dave Beckett</dc:creator>
The example given here includes both a <description> and a <content:encoded> element, each with a slightly different version of the content text (plain text and escaped-XML, respectively). This is fairly redundant, but does improve the chances of particular feed readers being able to use the data. There are no hard-and-fast rules for which elements should be included in an RSS 1.0 feed, as long as they follow the general structural rules of RDF/XML. RDF generally follows a principal of “missing isn’t broken,” and according to that you can leave out any elements for which you don’t have suitable values. By the same token, if you have extra data that may be relevant (for example links to the homepages of contributing authors) it may be useful to include that (see Chapter 14, “Web Services” for more information). Although a feed reader may not understand the elements in the RSS feed, a more generic RDF consumer may be able to use the data.
Looking again from an RDF perspective, note that the object of the statements that list the item URIs become the subject of the statements that describe the items themselves. In most XML languages, this kind of connection is made through element nesting, and it’s clear that tree structures can be built this way. However, using identifiers for the points of interest (the resource URIs) in RDF also makes it possible for any resource to be related to any other resource, allowing arbitrary node and arc graph structures. Loops and self-references can occur. This versatility is an important feature of RDF, and is very similar to the arbitrary hyperlinking of the web. The downside is that there isn’t any elegant way to represent graph structures in a tree-oriented syntax like XML, which is a major reason why RDF/XML syntax can be hard on the eye.
WORKING WITH NEWS FEEDS
To get a handle on the practicalities of how syndication works, it’s worth looking at the technology from both the perspective of the publisher and that of the consumer of feeds. The rest of the chapter is devoted to practical code, so you will see in practice most of the key issues encountered when developing in this field. It is really simple to set up a syndication feed, but that phrase can be misleading. Without a little care, the result can be really bad. Because of this, first you see development from a consumer’s point of view. It’s the harder part of the equation (after all, you could simply write an RSS feed manually and call it done), but the best way of seeing where potential problems lie.
Newsreaders
Tools are available so that anyone can set up their own personal “newspaper,” with content selected from the millions of syndicated feeds published on the web.
These aggregators are usually known as newsreaders, applications that enable you to both add and otherwise manage RSS feeds into a single “newspaper” of articles. Although public awareness of feed reading probably isn’t very sophisticated, the technology is becoming ubiquitous and many web users are almost certainly reading material that has passed through RSS/Atom syndication without realizing it.
Data Quality
Whenever you work with material on the web, keep in mind that not all data purporting to be XML actually is XML. It’s relatively common to find RSS feeds that are not well formed. One of the most common failings is that the characters in the XML document aren’t from the declared encoding (UTF-8, ISO-8859-1, or something similar). Another likely corruption is that characters within the textual content of the feed are incorrectly escaped. A stray < instead of a < is enough to trip up a standard XML processor. Unfortunately, many of the popular blogging tools make it extremely easy to produce an ill-formed feed, a factor not really taken into account by the “simple” philosophy of syndication.
There was considerable discussion by the Atom developers on this issue, and responses ranged from the creation of an “ultra-liberal” parser that does its best to read anything, to the suggestion that aggregation tools simply reject ill-formed feeds to discourage their production. For pragmatic reasons, current newsreaders tend very much toward the liberal, though for applications where data fidelity is a priority, strict XML (and the clear rules of Atom) is always an option.
A SIMPLE AGGREGATOR
This section describes how you can build a simple newsreader application in the Python language that will aggregate news items from several channels. The program uses a configuration file that contains a list of feed addresses and, when run, presents the most recent five items from those feeds. To keep things simple, the reader has only a command-line user interface and won’t remember what it has read from the feeds previously.
Modeling Feeds
The programmer has many options for dealing with XML data, and the choice of approach often depends on the complexity of the data structures. In many circumstances the data can be read directly into a DOM model and processed from there, but there is a complication with syndicated material — the source data can be in one of three completely different syntaxes: RSS 1.0, RSS 2.0 (and its predecessors), and Atom. Because the application is only a simple newsreader, the sophistication offered by the RDF model behind RSS 1.0 isn’t needed, but a simple model is implicit in news feeds: a feed comprises a number of items, and each of those items has a set of properties (refer to Figure 13-1).
Therefore, at the heart of the aggregator you will be building is an object-oriented version of that model. A feed is represented by a Feed object, and items are represented by Item objects. Each Item object has member variables to represent the various properties of that item. To keep things simple, the feed Item has only three properties: title, date, and content. The Item itself and these three properties can be mapped to an XML element in each of the three main syntaxes, as shown in Table 13-1.
TABLE 13-1: Core Item Terms in the Major Feed Syntaxes
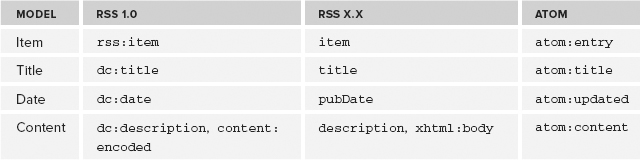
The namespaces of the elements are identified by their usual prefixes as follows (note that the “simple” RSS dialects don’t have a namespace):
- rss is RSS 1.0 (http://purl.org/rss/1.0/)
- dc is Dublin Core (http://purl.org/dc/elements/1.1/)
- xhtml is XHTML (www.w3.org/1999/xhtml)
- content is the content module for RSS 1.0 (http://purl.org/rss/1.0/modules/content/)
- atom is, you guessed it, Atom (www.w3.org/2005/Atom)
The correspondence between the different syntaxes is only approximate. Each version has its own definitions, and although they don’t coincide exactly, they are close enough in practice to be used in a basic newsreader.
Syntax Isn’t Model
Though there’s a reasonable alignment between the different elements listed in Table 13-1, this doesn’t hold for the overall structure of the different syndication syntaxes. In particular, both plain XML RSS and Atom use element nesting to associate the items with the feed. If you look back at the sample of RSS 1.0, it’s clear that something different is going on. RSS 1.0 uses the interpretation of RDF in XML to indicate that the channel resource has a property called items, which points to a Seq (sequence) of item instances. The item instances in the Seq are identified with URIs, as are the individual item entries themselves, which enables an RDF processor to know that the same resources are being referred to. In short, the structural interpretation is completely different.
Two pieces of information, implicit in the XML structure of simple RSS, are made explicit in RSS 1.0. In addition to the association between the feed and its component items, there is also the order of the items. The use of a Seq in RSS 1.0 and the document order of the XML elements in the “simple” RSS dialects provide an ordering, though there isn’t any common agreement on what this ordering signifies. Atom explicitly states that the order of entries shouldn’t be considered significant.
To keep the code simple in the aggregator presented here, two assumptions are made about the material represented in the various syntaxes:
- The items in the file obtained from a particular location are all part of the same conceptual feed. This may seem obvious; in fact, it has to be the case in plain XML RSS, which can have only one root <rss> element, but in RDF/XML (on which RSS 1.0 is based), it is possible to represent practically anything in an individual file. In practice, though, it’s a relatively safe assumption.
- The second assumption is that in a news-reading application, the end user won’t be interested in the order of the items in the feed (element or Seq order), but instead will want to know the dates on which the items were published.
The first assumption means there is no need to check where in the document structure individual items appear, and the second means there is no need to interpret the Seq or remember the element order. There is little or no cost to these assumptions in practice, yet it enables considerable code simplification. The only thing that needs to occur is to recognize when an element corresponding to an item (rss:item, item, or atom:entry) occurs within a feed, and to start recording its properties. In all the syntaxes the main properties are provided in child elements of the <item> element, so only a very simple structure has to be managed.
In other words, although there are three different syntaxes, a part of the structure is common to all of them despite differences in element naming. An object model can be constructed from a simple one-to-one mapping from each set of elements. On encountering a particular element in the XML, a corresponding action needs to be carried out on the objects. An XML programming tool is ideally suited to this situation: SAX.
SAX to the Rescue!
SAX (the Simple API for XML) works by responding to method calls generated when various entities within the XML document are encountered. The Python language supports SAX out of the box (in the modules xml.sax). Given that, the main tasks for feed parsing are to decide which elements should be recognized, and what actions should be applied when encountering them.
The entities of interest for this simple application are the following:
- The elements corresponding to items
- The elements corresponding to the properties of the items and the values of those properties
Three SAX methods can provide all the information the application needs about these elements:
- startElement
- characters
- endElement
The startElement method signals which element has been encountered, providing its name and namespace (if it has one). It’s easy enough to tell if that element corresponds to an item. Refer to Table 13-1, and you know its name will either be item or entry. Similarly, each of the three kinds of properties of elements can be identified. The data sent to characters is the text content of the elements, which are the values of the properties. A call to the endElement method signals that the element’s closing tag has been encountered, so the program can deal with whatever is inside it.
Again, using Table 13-1, you can derive the following simple rules that determine the nature of the elements encountered:
- rss:item | item | atom:entry = item
- dc:title | title | atom:title = title
- dc:date | pubDate | atom:updated = date
- dc:description | content:encoded | description | xhtml:body | atom:content = content
If startElement has been called, any subsequent calls matching the last three elements will pass on the values of that particular property of that element, until the endElement method is called. There may be calls to the elements describing properties outside of an item block, and you can reasonably assume that those properties apply to the feed as a whole. This makes it straightforward to extract the title of the feed.
Program Flow
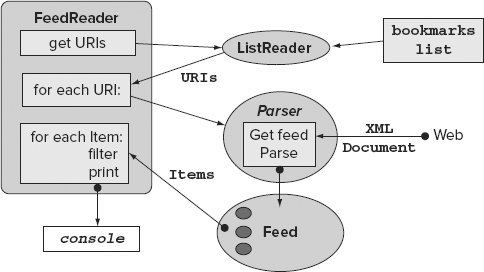
When your application is run, the list of feeds is picked up from the text file. Each of the addresses, in turn, is passed to an XML parser. The aggregator then reads the data found on the web at that address. In more sophisticated aggregators, you will find a considerable amount of code devoted to the reading of data over HTTP in a way that both respects the feed publisher, and makes the system as efficient as possible. The XML parsers in Python however, are capable of reading data directly from a web address. Therefore, to keep things simple, a Python XML parser is shown in Figure 13-2. Python XML is discussed in the following section.
Implementation
Your feed reader is written in Python, a language that has reasonably sophisticated XML support. Everything you need to run it is available in the code downloads for this chapter, or as a free download from www.python.org. If you’re not familiar with Python, don’t worry — it’s a very simple language, and the code is largely self-explanatory. All you really need to know is that it uses indentation to separate functional blocks (whitespace is significant), rather than braces {}. In addition, the # character means that the rest of the line is a comment. Python is explained in greater detail shortly in the next Try It Out, but before you begin using Python to run your feed reader, you need to take a few preparatory steps.
 feed_reader.py controls the operation.
feed_reader.py controls the operation.- feed.py models the feed and items.
- feed_handler.py constructs objects from the content of the feed.
- list_reader.py reads a list of feed addresses.
![]() LISTING 13-1: feeds.txt
LISTING 13-1: feeds.txt
http://www.fromoldbooks.org/rss.xml http://www.25hoursaday.com/weblog/SyndicationService.asmx/GetRss http://journal.dajobe.org/journal/index.rdf http://planetrdf.com/index.rdf
An aggregator should be able to deal with all the major formats. In Listing 13-1 you have a selection: the first feed is in RSS 2.0 format, the second is Atom, and the third and fourth are in RSS 1.0. A text list is the simplest format in which the URIs can be supplied. For convenience, a little string manipulation makes it possible to use an IE, Chrome, or Firefox bookmarks file to supply the list of URIs. The addresses of the syndication feeds should be added to a regular bookmark folder in the browser. With IE, it’s possible to export a single bookmark folder to use as the URI list, but with Chrome or Firefox, all the bookmarks are exported in one go.
The first code file you’ll use is shown in Listing 13-2, and is set up to only read the links in the first folder in the aforementioned bookmark file. This source file contains a single class, ListReader, with a single method, get_uris:
![]() LISTING 13-2: list_reader.py
LISTING 13-2: list_reader.py
import re
class ListReader:
“”” Reads URIs from file “””
def get_uris(self, filename):
“”” Returns a list of the URIs contained in the named file “””
file = open(filename, 'r')
text = file.read()
file.close()
# get the first block of a Netscape file
text = text.split('</DL>')[0]
# get the uris
pattern = 'http://S*w'
return re.findall(pattern,text)
You can now begin your adventures with Python by using a simple utility class to load a list of feed URIs into the application.
$ python Python 2.7.2+ (default, Oct 4 2011, 20:03:08) [GCC 4.6.1] on linux2 Type “help”, “copyright”, “credits” or “license” for more information. >>>
>>> from list_reader import ListReader >>> reader = ListReader() >>> print reader.get_uris(“feeds.txt”)
['http://www.fromoldbooks.org/rss.xml', 'http://www.25hoursaday.com/weblog/SyndicationService.asmx/GetRss', 'http://journal.dajobe.org/journal/index.rdf', 'http://planetrdf.com/index.rdf'] >>>
from list_reader import ListReader
reader = ListReader()
print reader.get_uris(“feeds.txt”)
['http://www.fromoldbooks.org/rss.xml', 'http://www.25hoursaday.com/weblog/SyndicationService.asmx/GetRss', 'http://journal.dajobe.org/journal/index.rdf', 'http://planetrdf.com/index.rdf']
import re
class ListReader:
“”” Reads URIs from file “””
def get_uris(self, filename):
“”” Returns a list of the URIs contained in the named file “””
file = open(filename, 'r')
text = file.read()
file.close()
# get the first block of a Netscape file
text = text.split('</DL>')[0]
# get the uris
pattern = 'http://S*w'
return re.findall(pattern,text)
Application Controller: FeedReader
The list of URIs is the starting point for the main control block of the program, which is the FeedReader class contained in feed_reader.py. If you refer to Figure 13-2, you should be able to see how the functional parts of the application are tied together. Here are the first few lines of feed_reader.py, which acts as the overall controller of the application:
import urllib2
import xml.sax
import list_reader
import feed_handler
import feed
feedlist_filename = 'feeds.txt'
def main():
“”” Runs the application “””
FeedReader().read(feedlist_filename)
feed_reader.py
The code starts with the library imports. urllib2 and xml.sax are used here only to provide error messages if something goes wrong with HTTP reading or parsing. list_reader is the previous URI list reader code (in list_reader.py), feed_handler contains the custom SAX handler (which you see shortly), and feed contains the class that models the feeds.
The name of the file containing the URI list is given as a constant. You can either save your list with this filename or change it here. Because Python is an interpreted language, any change takes effect the next time you run the program. The main() function runs the application by creating a new instance of the FeedReader class and telling it to read the named file. When the new instance of FeedReader is created, the init method is called automatically, which is used here to initialize a list that will contain all the items obtained from the feeds:
class FeedReader:
“”” Controls the reading of feeds “””
def __init__(self):
“”” Initializes the list of items “””
self.all_items = []
The read method looks after the primary operations of the aggregator and begins by obtaining a parser from a local helper method, create_parser, and then getting the list of URIs contained in the supplied file, as shown in the following code:
def read(self, feedlist_filename):
“”” Reads each of the feeds listed in the file “””
parser = self.create_parser()
feed_uris = self.get_feed_uris(feedlist_filename)
The next block of code selects each URI in turn and does what is necessary to get the items out of that feed, which is to create a SAX handler and attach it to the parser to be called as the parser reads through the feed’s XML. The magic of the SAX handler code will appear shortly, but reading data from the web and parsing it is a risky business, so the single command that initiates these actions, parser.parse(uri), is wrapped in a try...except block to catch any errors. Once the reading and parsing occur, the feed_handler instance contains a feed object, which in turn contains the items found in the feed (you see the source to these classes in a moment). To indicate the success of the reading/parsing, the number of items contained in the feed is then printed. The items are available as a list of handler.feed.items, the length of this list (len) is the number of items, and the standard str function is used to convert this number to a string for printing to the console:
for uri in feed_uris:
print 'Reading '+uri,
handler = feed_handler.FeedHandler()
parser.setContentHandler(handler)
try:
parser.parse(uri)
print ' : ' + str(len(handler.feed.items)) + ' items'
self.all_items.extend(handler.feed.items)
except xml.sax.SAXParseException:
print '
XML error reading feed : '+uri
parser = self.create_parser()
except urllib2.HTTPError:
print '
HTTP error reading feed : '+uri
parser = self.create_parser()
self.print_items()
If an error occurs while either reading from the web or parsing, a corresponding exception is raised, and a simple error message is printed to the console. The parser is likely to have been trashed by the error, so a new instance is created. Whether or not the reading/parsing was successful, the program now loops back and starts work on the next URI on the list. Once all the URIs have been read, a helper method, print_items (shown in an upcoming code example), is called to show the required items on the console. The following methods in FeedReader are all helpers used by the read method in the previous listing.
The get_feed_uris method creates an instance of the ListReader class shown earlier, and its get_uris method returns a list of the URIs found in the file, like so:
def get_feed_uris(self, filename):
“”” Use the list reader to obtain feed addresses “””
lr = list_reader.ListReader()
return lr.get_uris(filename)
The create_parser method makes standard calls to Python’s SAX library to create a fully namespace-aware parser as follows:
def create_parser(self):
“”” Creates a namespace-aware SAX parser “””
parser = xml.sax.make_parser()
parser.setFeature(xml.sax.handler.feature_namespaces, 1)
return parser
The next method is used in the item sorting process, using the built-in cmp function to compare two values — in this case, the date properties of two items. Given the two values x and y, the return value is a number less than zero if x < y, zero if x = y, and greater than zero if x > y. The date properties are represented as the number of seconds since a preset date (usually January 1, 1970), so a newer item here will actually have a larger numeric date value. Here is the code that does the comparison:
def newer_than(self, itemA, itemB):
“”” Compares the two items “””
return cmp(itemB.date, itemA.date)
The get_newest_items method uses the sort method built into Python lists to reorganize the contents of the all_items list. The comparison used in the sort is the newer_than method from earlier, and a Python “slice” ([:5]) is used to obtain the last five items in the list. Putting this together, you have the following:
def get_newest_items(self):
“”” Sorts items using the newer_than comparison “””
self.all_items.sort(self.newer_than)
return self.all_items[:5]
The print_items method applies the sorting and slicing previously mentioned and then prints the resultant five items to the console, as illustrated in the following code:
def print_items(self):
“”” Prints the filtered items to console “””
print '
*** Newest 5 Items ***
'
for item in self.get_newest_items():
print item
The final part of feed_reader.py is a Python idiom used to call the initial main() function when this file is executed:
if __name__ == '__main__':
“”” Program entry point “””
main()
Model: Feed and Item
The preceding FeedReader class uses a SAX handler to create representations of feeds and their items. Before looking at the handler code, following is the feed.py file, which contains the code that defines those representations. It contains two classes: Feed and Item. The plain XML RSS dialects generally use the older RFC 2822 date format used in e-mails, whereas RSS 1.0 and Atom use a specific version of the ISO 8601 format used in many XML systems, known as W3CDTF. As mentioned earlier, the dates are represented within the application as the number of seconds since a specific date, so libraries that include methods for conversion of the e-mail and ISO 8601 formats to this number are included in the imports. To simplify coding around the ISO 8601, a utility library will be used (dateutil).
The significance of BAD_TIME_HANDICAP is explained next, but first take a look at the following code:
import email.Utils
import dateutil.parser
import time
BAD_TIME_HANDICAP = 43200
feed.py
The Feed class in the following code is initialized with a list called items to hold individual items found in a feed, and a string called title to hold the title of the feed (with the title initialized to an empty string):
class Feed:
“”” Simple model of a syndication feed data file “””
def __init__(self):
“”” Initialize storage “””
self.items = []
self.title = “
Although items are free-standing entities in a sense, they are initially derived from a specific feed, which is reflected in the code by having the Item instances created by the Feed class. The create_item method creates an Item object and then passes the title of the feed to the Item object’s source property. Once initialized in this way, the Item is added to the list of items maintained by the Feed object like so:
def create_item(self):
“”” Returns a new Item object “””
item = Item()
item.source = self.title
self.items.append(item)
return item
To make testing easier, the Feed object overrides the standard Python __str__ method to provide a useful string representation of itself. All the method here does is run through each of the items in its list and add the string representation of them to a combined string:
def __str__(self):
“”” Custom 'toString()' method to pretty-print “””
string =”
for item in self.items:
string.append(item.__str__())
return string
The item class essentially wraps four properties that will be extracted from the XML: title, content, source (the title of the feed it came from), and date. Each of these is maintained as an instance variable, the values of the first three being initialized to an empty string. It’s common to encounter date values in feeds that aren’t well formatted, so it’s possible to initialize the date value to the current time (given by time.time()). The only problem with this approach is that any items with bad date values appear newer than all the others. As a little hack to prevent this without excluding the items altogether, a handicap value is subtracted from the current time. At the start, the constant BAD_TIME_HANDICAP was set to 43,200, represented here in seconds, which corresponds to 12 hours, so any item with a bad date is considered 12 hours old, as shown here:
class Item:
“”” Simple model of a single item within a syndication feed “””
def __init__(self):
“”” Initialize properties to defaults “””
self.title = “
self.content = “
self.source = “
self.date = time.time() - BAD_TIME_HANDICAP # seconds from the Epoch
The next two methods make up the setter for the value of the date. The first, set_rfc2822_time, uses methods from the e-mail utility library to convert a string (like Sat, 10 Apr 2004 21:13:28 PDT) to the number of seconds since 01/01/1970 (1081656808). Similarly, the set_w3cdtf_time method converts an ISO 8601–compliant string (for example, 2004-04-10T21:13:28-00:00) into seconds. The method call is a little convoluted, but it works! If either conversion fails, an error message is printed, and the value of date remains at its initial (handicapped) value, as illustrated in the following code:
def set_rfc2822_time(self, old_date):
“”” Set email-format time “””
try:
temp = email.Utils.parsedate_tz(old_date)
self.date = email.Utils.mktime_tz(temp)
except ValueError:
print “Bad date : \%s” \% (old_date)
def set_w3cdtf_time(self, new_date):
“”” Set web-format time “””
try:
self.date = time.mktime(dateutil.parser.parse(new_date).timetuple())
except ValueError:
print “Bad date : \%s” \% (new_date)
The get_formatted_date method uses the e-mail library again to convert the number of seconds into a human-friendly form — for example, Sat, 10 Apr 2004 23:13:28 +0200 — as follows:
def get_formatted_date(self):
“”” Returns human-readable date string “””
return email.Utils.formatdate(self.date, True)
# RFC 822 date, adjusted to local time
Like the Feed class, Item also has a custom — str — method to provide a nice representation of the object. This is simply the title of the feed it came from and the title of the item itself, followed by the content of the item and finally the date, as shown in the following code:
def __str__(self):
“”” Custom 'toString()' method to pretty-print “””
return (self.source + ' : '
+ self.title +'
'
+ self.content + '
'
+ self.get_formatted_date() + '
')
That’s how feeds and items are represented, and you will soon see the tastiest part of the code, the SAX handler that builds Feed and Item objects based on what appears in the feed XML document. This file (feed_handler.py) contains a single class, FeedHandler, which is a subclass of xlm.sax.ContentHandler. An instance of this class is passed to the parser every time a feed document is to be read; and as the parser encounters appropriate entities in the feed, three specific methods are called automatically: startElementNS, characters, and endElementNS. The namespace-enhanced versions of these methods are used because the elements in feeds can come from different namespaces.
XML Markup Handler: FeedHandler
As a SAX parser runs through an XML document, events are triggered as different parts of the markup are encountered. A set of methods are used to respond to (handle) these events. For your feed reader, all the necessary methods will be contained in a single class, FeedHandler.
As discussed earlier, there isn’t much data structure in a feed to deal with — just the feed and contained items — but there is a complication not mentioned earlier. The <title> and <content> elements of items may contain markup. This shouldn’t happen with RSS 1.0; the value of content:encoded is enclosed in a CDATA section or the individual characters escaped as needed. However, the parent RDF/XML specification does describe XML Literals, and material found in the wild often varies from the spec. In any case, the rich content model of Atom is designed to allow XML, and the RSS 2.0 specification is unclear on the issue, so markup should be expected. If the markup is, for example, HTML 3.2 and isn’t escaped, the whole document won’t be well formed and by definition won’t be XML — a different kettle of fish. However, if the markup is well-formed XML (for example, XHTML), there will be a call to the SAX start and end element methods for each element within the content.
The code in feed_handler.py will have an instance variable, state, to keep track of where the parser is within an XML document’s structure. This variable can take the value of one of the three constants. If its value is IN_ITEM, the parser is reading somewhere inside an element that corresponds to an item. If its value is IN_CONTENT, the parser is somewhere inside an element that contains the body content of the item. If neither of these is the case, the variable will have the value IN_NONE.
The code itself begins with imports from several libraries, including the SAX material you might have expected as well as the regular expression library re and the codecs library, which contain tools that are used for cleaning up the content data. The constant TRIM_LENGTH determines the maximum amount of content text to include for each item. For demonstration purposes and to save paper, this is set to a very low 100 characters. This constant is followed by the three alternative state constants, as shown in the following code:
import xml.sax
import xml.sax.saxutils
import feed
import re
import codecs
# Maximum length of item content
TRIM_LENGTH = 100
# Parser state
IN_NONE = 0
IN_ITEM = 1
IN_CONTENT = 2
feed_handler.py
The content is stripped of markup, and a regular expression is provided to match any XML-like tag (for example, <this>). However, if the content is HTML, it’s desirable to retain a little of the original formatting, so another regular expression is used to recognize <br> and <p> tags, which are replaced with newline characters, as shown in the following code:
# Regular expressions for cleaning data TAG_PATTERN = re.compile(“<(.rt )+?>”) NEWLINE_PATTERN = re.compile(“(<br.*>)rt(<p.*>)”)
The FeedHandler class itself begins by creating a new instance of the Feed class to hold whatever data is extracted from the feed being parsed. The state variable begins with a value of IN_NONE, and an instance variable, text, is initialized to the empty string. The text variable is used to accumulate text encountered between the element tags, as shown here:
# Subclass from ContentHandler in order to gain default behaviors
class FeedHandler(xml.sax.ContentHandler):
“”” Extracts data from feeds, in response to SAX events “””
def __init__(self):
“Initialize feed object, interpreter state and content”
self.feed = feed.Feed()
self.state = IN_NONE
self.text = “
return
The next method, startElementNS, is called by the parser whenever an opening element tag is encountered and receives values for the element name — the prefix-qualified name of the element along with an object containing the element’s attributes. The name variable actually contains two values (it’s a Python tuple): the namespace of the element and its local name. These values are extracted into the separate namespace, localname strings. If the feed being read were RSS 1.0, a <title> element would cause the method to be called with the values name = ('http://purl.org/rss/1.0/', 'title'), qname = 'title'. (If the element uses a namespace prefix, like <dc:title>, the qname string includes that prefix, such as dc:title in this case.) In this simple application the attributes aren’t used, but SAX makes them available as an NSAttributes object.
The startElementNS method determines whether the parser is inside content by checking whether the state is IN_CONTENT. If this isn’t the case, the content accumulator text is emptied by setting it to an empty string. If the name of the element is one of those that corresponds to an item in the simple model (item or entry), a new item is created, and the state changes to reflect the parser’s position within an item block. The last check here tests whether the parser is already inside an item block, and if it is, whether the element is one that corresponds to the content. The actual string comparison is done by a separate method to keep the code tidy, because several alternatives exist. If the element name matches, the state is switched into IN_CONTENT, as shown in the following code:
def startElementNS(self, name, qname, attributes):
“Identifies nature of element in feed (called by SAX parser)”
(namespace, localname) = name
if self.state != IN_CONTENT:
self.text = “ # new element, not in content
if localname == 'item' or localname == “entry”: # RSS or Atom
self.current_item = self.feed.create_item()
self.state = IN_ITEM
return
if self.state == IN_ITEM:
if self.is_content_element(localname):
self.state = IN_CONTENT
return
The characters method merely adds any text encountered within the elements to the text accumulator like so:
def characters(self, text):
“Accumulates text (called by SAX parser)”
self.text = self.text + text
The endElementNS method is called when the parser encounters a closing tag, such as </this>. It receives the values of the element’s name and qname, and once again the name tuple is split into its component namespace, localname parts. What follows are a lot of statements, which are conditional based on the name of the element and/or the current state (which corresponds to the parser’s position in the XML). This essentially carries out the matching rules between the different kinds of elements that may be encountered in RSS 1.0, 2.0, or Atom, and the Item properties in the application’s representation. You may want to refer to the table of near equivalents shown earlier, and the examples of feed data to see why the choices are made where they are. Here is the endElementNS method:
def endElementNS(self, name, qname):
“Collects element content, switches state as appropriate
(called by SAX parser)”
(namespace, localname) = name
Now it is time to ask some questions:
if localname == 'item' or localname == 'entry': # end of item
self.state = IN_NONE
returnif self.state == IN_CONTENT:
if self.is_content_element(localname): # end of content
self.current_item.content = self.cleanup_text(self.text)
self.state = IN_ITEM
returnIf you aren’t in content, the flow continues.
Now that the content is out of the way, with its possible nested elements, the rest of the text that makes it this far represents the simple content of an element. You can clean it up, as outlined in the following code:
# cleanup text - we probably want it
text = self.cleanup_text(self.text)
At this point, if the parser isn’t within an item block and the element name is title, what you have here is the title of the feed. Pass it on as follows:
if self.state != IN_ITEM: # feed title
if localname == “title”:
self.feed.title = self.text
return
The parser must now be within an item block thanks to the last choice, so if there’s a title element here, it must refer to the item. Pass that on too:
if localname == “title”:
self.current_item.title = text
return
Now you get to the tricky issue of dates. If the parser finds an RSS 1.0 date (dc:date) or an Atom date (atom:updated), it will be in ISO 8601 format, so you need to pass it to the item through the appropriate converter:
if localname == “date” or localname == “updated”:
self.current_item.set_w3cdtf_time(text)
return
RSS 2.0 and most of its relatives use a pubDate element in RFC 2822 e-mail format, so pass that through the appropriate converter as shown here:
if localname == “pubDate”:
self.current_item.set_rfc2822_time(text)
return
These last few snippets of code have been checking the SAX parser’s position within the feed document structure, and depending on that position applying different processes to the content it finds.
Helper Methods
The rest of feed_handler.py is devoted to little utility or helper methods that wrap up blocks of functionality, separating some of the processing from the flow logic found in the preceding code. The first helper method, is_content_element, which checks the alternatives to determine whether the local name of the element corresponds to that of an item like so:
def is_content_element(self, localname):
“Checks if element may contain item/entry content”
return (localname == “description” or # most RSS x.x
localname == “encoded” or # RSS 1.0 content:encoded
localname == “body” or # RSS 2.0 xhtml:body
localname == “content”) # Atom
feed_handler.py
The next three methods are related to tidying up text nodes (which may include escaped markup) found within the content. Cleaning up the text begins by stripping whitespace from each end. This is more important than it might seem, because depending on the layout of the feed data there may be a host of newlines and tabs to make the feed look nice, but which only get in the way of the content. These unnecessary newlines should be replaced by a single space.
Next, a utility method, unescape, in the SAX library is used to unescape characters such as <this> to <this>. This is followed by a class to another helper method, process_tags, to do a little more stripping. If this application used a browser to view the content, this step wouldn’t be needed (or even desirable), but markup displayed to the console just looks bad, and <a href=”...”> hyperlinks <a> won’t work.
The next piece of cleaning is a little controversial. The content delivered in feeds can be Unicode, with characters from any international character set, but most consoles are ill prepared to display such material. The standard string encode method is used to flatten everything down to plain old ASCII. This is rather drastic, and there may well be characters that don’t fit in this small character set. The second value determines what should happen in this case — possible values are strict (default), ignore, or replace. The replace alternative swaps the character for a question mark, hardly improving legibility. The strict option throws an error whenever a character won’t fit, and it’s not really appropriate here either. The third option, ignore, simply leaves out any characters that can’t be correctly represented in the chosen ASCII encoding. The following code shows the sequence of method calls used to make the text more presentable:
def cleanup_text(self, text):
“Strips material that won't look good in plain text”
text = text.strip()
text = text.replace('
', ' ')
text = xml.sax.saxutils.unescape(text)
text = self.process_tags(text)
text = text.encode('ascii','ignore')
text = self.trim(text)
return text
The process_tags method (called from cleanup_text) uses regular expressions to first replace any <br> or <p> tags in the content with newline characters, and then to replace any remaining tags with a single space character:
def process_tags(self, string):
“”” Turns <br/> into
then removes all <tags> “””
re.sub(NEWLINE_PATTERN, '
', string)
return re.sub(TAG_PATTERN, ' ', string)
The cleaning done by the last method in the FeedHandler class is really a matter of taste. The amount of text found in each post varies greatly between different sources. You may not want to read whole essays through your newsreader, so the trim method cuts the string length down to a preset size determined by the TRIM_LENGTH constant. However, just counting characters and chopping when the desired length has been reached results in some words being cut in half, so this method looks for the first space character in the text after the TRIM_LENGTH index and cuts there. If there aren’t any spaces in between that index and the end of the text, the method chops anyway. Other strategies are possible, such as looking for paragraph breaks and cutting there. Although it’s fairly crude, the result is quite effective. The code that does the trimming is as follows:
def trim(self, text):
“Trim string length neatly”
end_space = text.find(' ', TRIM_LENGTH)
if end_space != -1:
text = text[:end_space] + “ ...”
else:
text = text[:TRIM_LENGTH] # hard cut
return text
That’s it, the whole of the aggregator application. There isn’t a lot of code, largely thanks to libraries taking care of the details. Now, with your code in place you can try it out.
python feed_reader.py$ python feed_reader.py
Reading http://www.fromoldbooks.org/rss.xml : 20 items
Reading
http://www.25hoursaday.com/weblog/SyndicationService.asmx/GetRss : 10 items
Reading http://journal.dajobe.org/journal/index.rdf : 10 items
Reading http://planetrdf.com/index.rdf : 27 items
*** Newest 5 Items ***
Words and Pictures From Old Books : Strange and Fantastical
Creatures, from Buch der Natur [Book of Nature] (1481), added on 13th Feb 20
I cannot read the text (it’s in medieval German), so
these descriptions are arbitrary; I’d ...
[email protected] (Liam Quin)
Mon, 13 Feb 2012 10:15:00 +0100
Dare Obasanjo aka Carnage4Life : Some Thoughts on Address Book
Privacy and Hashing as an Alternative to Gathering Raw Email Addresses
If you hang around technology blogs and news sites, you may have seen the
recent dust up after it was ...
Sun, 12 Feb 2012 21:29:28 +0100
- A list of feed addresses is loaded from a text file.
- Each of the addresses is visited in turn, and the data is passed to a SAX handler.
- The handler creates objects corresponding to the feed and items within the feed.
- The individual items from all feeds are combined into a single list and sorted.
- The items are printed in the command window.
Extending the Aggregator
You could do a thousand and one things to improve this application, but whatever enhancement is made to the processing or user interface, you are still dependent on the material pumped out to feeds. XML is defined by its acronym as extensible, which means that elements outside of the core language can be included with the aid of XML namespaces. According to the underlying XML namespaces specification, producers can potentially put material from other namespaces pretty much where they like, but this isn’t as simple as it sounds because consumers have to know what to do with them. So far, two approaches have been taken toward extensibility in syndication:
- RSS 2.0 leaves the specification of extensions entirely up to developers. This sounds desirable but has significant drawbacks because nothing within the specification indicates how an element from an extension relates to other elements in a feed. One drawback is that each extension appears like a completely custom application, needing all-new code at both the producer and consumer ends. Another drawback is that without full cooperation between developers, there’s no way of guaranteeing that the two extensions will work together.
- The RSS 1.0 approach is to fall back on RDF, specifically the structural interpretation of RDF/XML. The structure in which elements and attributes appear within an RDF/XML document gives an unambiguous interpretation according to the RDF model, irrespective of the namespaces. You can tell that certain elements/attributes correspond to resources, and that others correspond to relationships between those resources. The advantage here is that much of the lower-level code for dealing with feed data can be reused across extensions, because the basic interpretation will be the same. It also means that independently developed extensions for RSS 1.0 are automatically compatible with each other.
Atom takes a compromise approach to extensions, through the specification of two constructs: Simple Extension Elements and Structured Extension Elements. The Structured Extension Element provides something similar to the extensibility of RSS 2.0, in that a block of XML that is in a foreign (that is, not Atom) namespace relies on the definition of the extension for interpretation (or to be ignored). Unlike RSS 2.0, some restrictions exist on where such a block of markup may appear in the feed, but otherwise it’s open-ended. The Simple Extension Element provides something similar to the extensibility of RSS 1.0 in that it is interpreted as a property of its enclosing element, as shown here:
<feed xmlns=”http://www.w3.org/2005/Atom”
xmlns:im=”http://example.org/im/”>
...
<author>
<name>John Smith</name>
<im:nickname>smiffy</im:nickname>
</author>
...
</feed>
The Simple Extension Element, <im:nickname> here, must be in a foreign namespace. The namespace (http://example.org/im/ with prefix im:) is given in this example on the root <feed> element, although following XML conventions it could be specified in any of the ancestor elements of the extension element, or even on the extension element itself. A Simple Extension Element can’t have any child nodes, except for a mandatory text node that provides the value of the property, so this example indicates that the author has a property called im:nickname with the value “smiffy”.
To give you an idea of how you might incorporate support for extensions in the tools you build, here is a simple practical example for the demo application. As mentioned at the start of this chapter, a growing class of tools takes material from one feed (or site) and quotes it directly in another feed (or site). Of particular relevance here are online aggregators, such as the “Planet” sites: Planet Gnome, Planet Debian, Planet RDF, and so on. These are blog–like sites, the posts of which come directly from the syndication feeds of existing blogs or news sites. They each have syndication feeds of their own. You may want to take a moment to look at Planet RDF: the human-readable site is at http://planetrdf.com, and it has an RSS 1.0 feed at http://planetrdf.com/index.rdf. The main page contains a list of the source feeds from which the system aggregates. The RSS is very much like regular feeds, except the developers behind it played nice and included a reference back to the original site from which the material came. This appears in the feed as a per-item element from the Dublin Core vocabulary, as shown in the following:
... <dc:source>Lost Boy by Leigh Dodds</dc:source> ...
The text inside this element is the title of the feed from which the item was extracted. It’s pretty easy to capture this in the aggregator described here. To include the material from this element in the aggregated display, two things are needed: a way to extract the data from the feed and a suitable place to put it in the display.
Like the other elements the application uses, the local name of the element is enough to recognize it. It is certainly possible to have a naming clash on “source,” though it’s unlikely. This element is used to describe an item, and the code already has a way to handle this kind of information. Additionally, the code picks out the immediate source of the item (the title of the feed from whence it came) and uses this in the title line of the displayed results. All that is needed is another conditional, inserted at the appropriate point, and the source information can be added to the title line of the results.
In the following activity you see how such an extension can be supported by your feed reader application with a minor addition to the code.
...
if localname == “pubDate”:
self.current_item.set_rfc2822_time(text)
return
if localname == “source”:
self.current_item.source = '('+self.current_item.source+') '+text
return
def is_content_element(self, localname):
“Checks if element may contain item/entry content”
... (Planet RDF) Tim Berners-Lee : Reinventing HTML
Making standards is hard work. It's hard because it involves listening
to other people and figuring ...
Tim Berners-Lee
Fri, 27 Oct 2006 23:14:10 +0200
TRANSFORMING RSS WITH XSLT
Because syndicated feeds are usually XML, you can process them using XSLT directly (turn to Chapter 8, "XSLT" for more on XSLT). Here are three common situations in which you might want to do this:
- Generating a feed from existing data
- Processing feed data for display
- Browser Processing
- Preprocessing feed data for other purposes
The first situation assumes you have some XML available for transformation, although because this could be XHTML from cleaned-up HTML, it isn’t a major assumption. The other two situations are similar to each other, taking syndication feed XML as input. The difference is that the desired output of the second is likely to be something suitable for immediate rendering, whereas the third situation translates data into a format appropriate for subsequent processing.
Generating a Feed from Existing Data
One additional application worth mentioning is that an XSLT transformation can be used to generate other feed formats when only one is available. If your blogging software produces only RSS 1.0, a standard transformation can provide your site with feeds for Atom and RSS 2.0. A web search will provide you with several examples (names like rss2rdf.xsl are popular!).
Be warned that the different formats may carry different amounts of information. For example, in RSS 2.0 most elements are optional, in Atom most elements are mandatory, virtually anything can appear in RSS 1.0, and there isn’t one-to-one correspondence of many elements. Therefore, a conversion from one to the other may be lossy, or may demand that you artificially create values for elements. For demonstration purposes, the examples here use only RSS 2.0, a particularly undemanding specification for the publisher.
Listing 13-3 XSLT transformation generates RSS from an XHTML document (xhtml2rss.xsl):
![]() LISTING 13-3: xhtml2rss.xsl
LISTING 13-3: xhtml2rss.xsl
<xsl:stylesheet version=”1.0”
xmlns:xsl=”http://www.w3.org/1999/XSL/Transform”
xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
<xsl:output method=”xml” indent=”yes”/>
<xsl:template match=”/xhtml:html”>
<rss version=”2.0”>
<channel>
<description>This will not change</description>
<link>http://example.org</link>
<xsl:apply-templates />
</channel>
</rss>
</xsl:template>
<xsl:template match=”xhtml:title”>
<title>
<xsl:value-of select=”.” />
</title>
</xsl:template>
<xsl:template match=”xhtml:body/xhtml:h1”>
<item>
<title>
<xsl:value-of select=”.” />
</title>
<description>
<xsl:value-of select=”following-sibling::xhtml:p” />
</description>
</item>
</xsl:template>
<xsl:template match=”text()” />
</xsl:stylesheet>
This code can now be applied to your XHTML documents, as you will now see.
<?xml version=”1.0” encoding=”UTF-8”?>
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Strict//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<title>My Example Document</title>
</head>
<body>
<h1>A first discussion point</h1>
<p>Something related to the first point.</p>
<h1>A second discussion point</h1>
<p>Something related to the second point.</p>
</body>
</html>
document.html
java -jar saxon9he.jar -s:document.html -xsl:xhtml2rss.xsl -o:document.rss
<?xml version=”1.0” encoding=”UTF-8”?>
<rss version=”2.0” xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
<channel>
<description>This will not change</description>
<link>http://example.org</link>
<title>My Example Document</title>
<item>
<title>A first discussion point</title>
<description>Something related to the first point.</description>
</item>
<item>
<title>A second discussion point</title>
<description>Something related to the second point.</description>
</item>
</channel>
</rss><xsl:stylesheet version=”1.0”
xmlns:xsl=”http://www.w3.org/1999/XSL/Transform”
xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
<xsl:output method=”xml” indent=”yes”/>
<xsl:template match=”/xhtml:html”>
<rss version=”2.0”>
<channel>
<description>This will not change</description>
<link>http://example.org</link>
<xsl:apply-templates />
</channel>
</rss>
</xsl:template>
<xsl:template match=”xhtml:title”>
<title>
<xsl:value-of select=”.” />
</title>
</xsl:template>
<h1>Item Title</h1>
<p>Item Description</p>
<xsl:template match=”xhtml:body/xhtml:h1”>
<item>
<title>
<xsl:value-of select=”.” />
</title>
<description>
<xsl:value-of select=”following-sibling::xhtml:p” />
</description>
</item>
</xsl:template>
<xsl:template match=”text()” /> </xsl:stylesheet>
If the authoring of the original XHTML is under your control, you can take more control over the conversion process. You can add markers to the document to indicate which parts correspond to items, descriptions, and so on. This is the approach taken in the Atom microformat (http://microformats.org/wiki/hatom) — for example, <div class=”hentry”>. This enables an Atom feed to be generated from the XHTML and is likely to be convenient for CSS styling.
One final point: although this general technique for generating a feed has a lot in common with screen scraping techniques (which generally break when the page author makes a minor change to the layout), it’s most useful when the authors of the original document are involved. The fact that the source document is XML greatly expands the possibilities. Research is ongoing into methods of embedding more general metadata in XHTML and other XML documents, with recent proposals available at the following sites:
- http://microformats.org (microformats)
- www.w3.org/2004/01/rdxh/spec (Gleaning Resource Descriptions from Dialects of Languages, or GRDDL)
Processing Feed Data for Display
What better way to follow a demonstration of XHTML-to-RSS conversion than an RSS-to-XHTMLstyle sheet? This isn’t quite as perverse as it may sound — it’s useful to be able to render your own feed for browser viewing, and this conversion offers a simple way to view other people’s feeds. Though it is relatively straightforward to display material from someone else’s syndication feed on your own site this way, it certainly isn’t a good idea without obtaining permission first. Aside from copyright issues, every time your page is loaded it will call the remote site, adding to its bandwidth load. You have ways around this — basically, caching the data locally — but that’s beyond the scope of this chapter (see for example http://stackoverflow.com/questions/3463383/php-rss-caching).
Generating XHTML from RSS isn’t very different from the other way around, as you can see in Listing 13-4:
![]() LISTING 13-4: rss2xhtml.xsl
LISTING 13-4: rss2xhtml.xsl
<xsl:stylesheet version=”1.0”
xmlns:xsl=”http://www.w3.org/1999/XSL/Transform”
xmlns=”http://www.w3.org/1999/xhtml”>
<xsl:output method=”html” indent=”yes”/>
<xsl:template match=”rss”>
<xsl:text disable-output-escaping=”yes”>
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Strict//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd”>
</xsl:text>
<html>
<xsl:apply-templates />
</html>
</xsl:template>
<xsl:template match=”channel”>
<head>
<title>
<xsl:value-of select=”title” />
</title>
</head>
<body>
<xsl:apply-templates />
</body>
</xsl:template>
<xsl:template match=”item”>
<h1><xsl:value-of select=”title” /></h1>
<p><xsl:value-of select=”description” /></p>
</xsl:template>
<xsl:template match=”text()” />
</xsl:stylesheet>
As you will now see, the same process can be used to make XHTML out of RSS that is used for making RSS out of XHTML.
java -jar saxon9he.jar -s:document.rss -xsl:rss2xhtml.xsl -o:document.html
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Strict//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<title>My Example Document</title>
</head>
<body>
<h1>A first discussion point</h1>
<p>Something related to the first point.</p>
<h1>A second discussion point</h1>
<p>Something related to the second point.</p>
</body>
</html><xsl:stylesheet version=”1.0”
xmlns:xsl=”http://www.w3.org/1999/XSL/Transform”
xmlns=”http://www.w3.org/1999/xhtml”>
<xsl:output method=”html” indent=”yes”/>
<xsl:template match=”rss”>
<xsl:text disable-output-escaping=”yes”>
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Strict//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd”>
</xsl:text>
<html>
<xsl:apply-templates />
</html>
</xsl:template>
<xsl:template match=”channel”>
<head>
<title>
<xsl:value-of select=”title” />
</title>
</head>
<body>
<xsl:apply-templates />
</body>
</xsl:template>
<xsl:template match=”item”> <h1><xsl:value-of select=”title” /></h1> <p><xsl:value-of select=”description” /></p> </xsl:template>
<xsl:template match=”text()” /> </xsl:stylesheet>
Browser Processing
A bonus feature of modern web browsers, such as Mozilla and IE, is that they have XSLT engines built in. This means it’s possible to style a feed format document in the browser. All that’s needed is an XML Processing Instruction that points toward the style sheet. This is very straightforward, as shown here, modifying document.rss:
<?xml version=”1.0”?> <?xml-stylesheet type=”text/xsl” href=”rss2xhtml.xsl”?> <rss version=”2.0”> <channel> ...
If you save this modified version as document.xml and open it with your browser, you’ll see a rendering that’s exactly the same as what you see with the XHTML version listed earlier.
When it comes to displaying XML (such as RSS and Atom) in a browser, the world’s your oyster — you can generate XHTML using a style sheet, and the resulting document can be additionally styled using CSS. There’s no real need for anyone to see raw XML in his or her browser. This is one reason the Atom group has created the <info> element, which can be used along with client-side styling to present an informative message about the feed alongside a human-readable rendering of the XML.
Preprocessing Feed Data
Another reason you might want to process feed data with XSLT is to interface easily with existing systems. For example, if you wanted to store the feed items in a database, you can set up a transformation to extract the content from a feed and format it as SQL statements, as follows:
INSERT INTO feed-table VALUES (item-id, “This is the title”, “This is the item description”);
One particularly useful application of XSLT is to use transformation to “normalize” the data from the various formats into a common representation, which can then be passed on to subsequent processing. This is, in effect, the same technique used in the aggregator application just shown, except there the normalization is to the application’s internal representation of a feed model.
A quick web search should yield something suitable for most requirements like this, or at least something that you can modify to fit your specific needs. Two examples of existing work are Morten Frederiksen’s anything-to-RSS 1.0 converter (http://purl.org/net/syndication/subscribe/feed-rss1.0.xsl) and Aaron Straup Cope’s Atom-to-RSS 1.0 and 2.0 style sheets (www.aaronland.info/xsl/atom/0.3/).
Reviewing the Different Formats
A feed consumer must deal with at least three different syndication formats, and you may want to build different subsystems to deal with each individually. Even when XSLT is available this can be desirable, because no single feed model can really do justice to all the variations. How do you tell what format a feed is? Following are the addresses of some syndication feeds:
http://news.bbc.co.uk/rss/newsonline_world_edition/front_page/rss091.xml http://blogs.it/0100198/rss.xml http://purl.org/net/morten/blog/feed/rdf/ http://swordfish.rdfweb.org/people/libby/rdfweb/webwho.xrdf http://icite.net/blog/?flavor=atom&smm=y
You might suppose a rough rule of thumb is to examine the filename; however, this is pretty unreliable for any format on the web. A marginally more reliable approach (and one that counts as good practice against the web specifications) is to examine the MIME type of the data. A convenient way of doing this is to use the wget command-line application to download the files (this is a standard UNIX utility; a Windows version is available from http://unxutils.sourceforge.net/).
In use, wget looks like this:
D:
ss-samples>wget http://blogs.it/0100198/rss.xml
–16:23:35– http://blogs.it/0100198/rss.xml
=> 'rss.xml'
Resolving blogs.it... 213.92.76.66
Connecting to blogs.it[213.92.76.66]:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 87,810 [text/xml]
100%[====================================>] 87,810 7.51K/s ETA 00:00
16:23:48 (7.91 KB/s) - 'rss.xml' saved [87810/87810]
It provides a lot of useful information: the IP address of the host called, the HTTP response (200 OK), the length of the file in bytes (87,810), and then the part of interest, [text/xml]. If you run wget with each of the previous addresses, you can see the MIME types are as follows:
[application/atom+xml ] http://news.bbc.co.uk/rss/
newsonline_world_edition/front_page/rss091.xml
[text/xml] http://blogs.it/0100198/rss.xml
[application/rdf+xml] http://purl.org/net/morten/blog/feed/rdf/
[text/plain] http://swordfish.rdfweb.org/people/libby/rdfweb/webwho.xrdf
[application/atom+xml] http://icite.net/blog/?flavor=atom&smm=y
In addition to the preceding MIME types, it’s not uncommon to see application/rss+xml used, although that has no official standing.
However, this has still not helped determine what formats these are. The only reliable way to find out is to look inside the files and see what it says there (and even then it can be tricky). To do this you run wget to get the previous files, and have a look inside with a text editor. Snipping off the XML prolog (and irrelevant namespaces), the data files begin like this (this one is from http://news.bbc.co.uk/rss/newsonline_world_edition/front_page/rss091.xml):
<rss version=”0.91”> <channel> <title>BBC News News Front Page World Edition</title> ...
This example is clearly RSS, flagged by the root element. It even tells you that it’s version 0.91. Here’s another from http://blogs.it/0100198/rss.xml:
<rss version=”2.0”> <channel> <title>Marc's Voice</title> ...
Again, a helpful root tells you this is RSS 2.0. Now here’s one from http://purl.org/net/morten/blog/feed/rdf/:
<rdf:RDF xmlns=” http://purl.org/rss/1.0/” xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”> <channel rdf:about=”http://purl.org/net/morten/blog/rdf”> <title>Binary Relations</title> ...
The rdf:RDF root suggests, and the rss:channel element confirms, that this is RSS 1.0. However, the following from http://swordfish.rdfweb.org/people/libby/rdfweb/webwho.xrdf is a bit vaguer:
<rdf:RDF
xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:foaf=”http://xmlns.com/foaf/0.1/”>
...>
<rdf:Description rdf:about=””>
<foaf:maker>
<foaf:Person>
<foaf:name>Libby Miller</foaf:name>
...
The rdf:RDF root and a lot of namespaces could indicate that this is RSS 1.0 using a bunch of extension modules. You might have to go a long way through this file to be sure. The interchangeability of RDF vocabularies means that RSS 1.0 terms can crop up almost anywhere; whether or not you want to count any document as a whole as a syndication feed is another matter. As it happens, there aren’t any RSS elements in this particular file; it’s a FOAF (Friend-of-a-Friend) Personal Profile Document. It’s perfectly valid data; it’s just simply not a syndication feed as such.
Now for a last example from http://icite.net/blog/?flavor=atom&smm=y:
<feed version=”0.3”
xmlns=”http://purl.org/atom/ns#”
xmlns:dc=”http://purl.org/dc/elements/1.1/”
xml:lang=”en”>
<title>the iCite net development blog</title>
...
The <feed> gives this away from the start: this is Atom. The version is only 0.3, but chances are good it will make it to version 1.0 without changing that root element.
These examples were chosen because they are all good examples — that is to say, they conform to their individual specifications. In the wild, things might get messy, but at least the preceding checks give you a place to start.
USEFUL RESOURCES
Here’s a selection of some additional resources for further information on the topics discussed in this chapter. The following sites are good specifications resources:
- RSS 1.0: http://purl.org/rss/1.0/spec
- RSS 2.0: http://blogs.law.harvard.edu/tech/rss
- Atom: www.ietf.org/rfc/rfc4287.txt
- Atom Wiki: www.intertwingly.net/wiki/pie/FrontPage
- RDF: www.w3.org/RDF/
These sites offer tutorials:
- rdf:about: www.rdfabout.com
- Atom Enabled: www.atomenabled.org
- Syndication Best Practices: www.ariadne.ac.uk/issue35/miller/
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!), by Joel Spolsky: www.joelonsoftware.com/articles/Unicode.html
Some miscellaneous resources include the following:
- http://code.google.com/p/feedparser/
- Feed Validator: http://feedvalidator.org
- RDF Validator: www.w3.org/RDF/Validator/
- Dave Beckett’s RDF Resource Guide: www.ilrt.bris.ac.uk/discovery/rdf/resources/
- RSS-DEV Mailing List: http://groups.yahoo.com/group/rss-dev/
SUMMARY
- Current ideas of content syndication grew out of “push” technologies and early meta data efforts, the foundations laid by CDF and MCF followed by Netscape’s RSS 0.9 and Scripting News format.
- The components of syndication systems carry out different roles: server-producer, client-consumer, client-producer, and server-consumer.
- RSS 1.0 is based on RDF using the RDF/XML syntax.
- RSS 2.0 is now more prevalent and uses a simpler XML model.
- Atom is the most recent XML feed format and is designed according to known best practices on the Web.
- Building an aggregator is straightforward using a standard programming language (Python).
- XSLT transformations can be used to convert between RSS and another format (XHTML).
EXERCISES
You can find suggested solutions to these questions in Appendix A.
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY POINTS |
| Syndication | Syndication of web feeds is similar to syndication in traditional publishing where a new item is added to the publication/feed. |
| XML feed formats | For historical reasons, three different formats are in common use: RSS 1.0, RSS 2.0, and Atom. Although the philosophy, style, and syntax of each approach is different, the data they carry is essentially the same. |
| RSS 1.0 characteristics | RSS 1.0 is based on the RDF data model, with names for the elements coming from different vocabularies. It’s extremely versatile but at the cost of complexity in its syntax. |
| RSS 2.0 characteristics | RSS 2.0 is the simplest feed format and probably the most widely deployed. However, its specification is rather loose and somewhat antiquated. |
| Atom characteristics | Atom is a straightforward XML format but it has a very solid, modern specification. |
| Data quality | There is considerable variation in the quality of feed data on the Web. Software built to consume feeds should take this into consideration. |
| Syndication systems | Syndication is, like the Web on which it operates, a client-server system. However, individual components may act as publishers or consumers of feed data. For example, an online aggregator will operate server-side, but consume data from remote feeds. |
| Aggregation | A common component of feed systems is the aggregator, which polls different feeds and merges the entries it finds into a single display (and/or feed). Aggregators are relatively straightforward to build using regular programming languages. |
| Transformation | As the common feed formats are XML, standard XML tools such as XSLT can be put to good use. (Although RSS 1.0 uses the RDF model, the actual XML for feeds is simple enough that this still applies). |