
Chapter 14
Web Services
WHAT YOU WILL LEARN IN THIS CHAPTER:
- What a Remote Procedure Call (RPC) is
- Which RPC protocols exist
- Why web services provides more flexibility than previous RPC Protocols
- How XML-RPC works
- Why most web services implementations should use HTTP as a transport protocol
- How HTTP works under the hood
- How the specifications that surround web services fit together
So far, you’ve learned what XML is, how to create well-formed and valid XML documents, and you’ve even seen ways of programatically interfacing with XML documents. You also learned that XML isn’t really a language on its own; it’s a meta language, to be used when creating other languages.
This chapter takes a slightly different turn. Rather than discuss XML itself, it covers an application of XML: web services, which enable objects on one computer to call and make use of objects on other computers. In other words, web services are a means of performing distributed computing.
WHAT IS AN RPC?
It is often necessary to design distributed systems, whereby the code to run an application is spread across multiple computers. For example, to create a large transaction processing system, you might have a separate server for business logic objects, one for presentation logic objects, a database server, and so on, all of which need to talk to each other (see Figure 14-1).
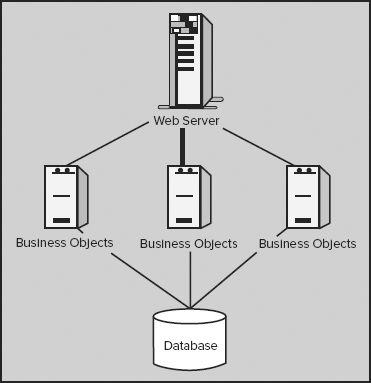
For a model like this to work, code on one computer needs to call code on another computer. For example, the code in the web server might need a list of orders for display on a web page, in which case it would call code on the business objects server to provide that list of orders. That code, in turn, might need to talk to the database. When code on one computer calls code on another computer, this is called a remote procedure call (RPC).
To make an RPC, you need to know the answer to the following questions:
- Where does the code you want to call reside? If you want to execute a particular piece of code, you need to know where that code is!
- Does the code need any parameters? If so, what type? For example, if you want to call a remote procedure to add two numbers, that procedure needs to know what numbers to add.
- Will the procedure return any data? If so, in what format? For example, a procedure to add two numbers would return a third number, which would be the result of the calculation, but some methods have no need to return a value.
In addition, you need to deal with networking issues, packaging any data for transport from computer to computer, and a number of other issues. For this reason, a number of RPC protocols have been developed.
These protocols specify how to provide an address for the remote computer, how to package data to be sent to the remote procedures, how to retrieve a response, how to initiate the call, how to deal with errors, and all of the other details that need to be addressed to enable multiple computers to communicate with each other. (Such RPC protocols often piggyback on other protocols; for example, an RPC protocol might specify that TCP/IP must be used as its network transport.)
RPC PROTOCOLS
Several protocols exist for performing remote procedure calls, but the most common are Distributed Component Object Model (DCOM), Internet Inter-ORB Protocol (IIOP) and Java RMI (you will learn more about these in the following sections). DCOM and IIOP are themselves extensions of earlier technologies, namely COM and CORBA respectively. Each of these protocols provides the functionality needed to perform remote procedure calls, although each has its drawbacks. The following sections discuss these protocols and those drawbacks, without providing too many technical details.
COM and DCOM
Microsoft developed a technology called the Component Object Model, or COM (see http://www.microsoft.com/com/default.mspx), to help facilitate component-based software, which is software that can be broken down into smaller, separate components that can then be shared across an application, or even across multiple applications. COM provides a standard way of writing objects so they can be discovered at run time and used by any application running on the computer. In addition, COM objects are language independent. That means you can write a COM object in virtually any programming language — C, C++, Visual Basic, and so on — and that object can talk to any other COM object, even if it was written in a different language.
A good example of COM in action is Microsoft Office. Because much of Office’s functionality is provided through COM objects, it is easy for one Office application to make use of another. For example, because Excel’s functionality is exposed through COM objects, you might create a Word document that contains an embedded Excel spreadsheet.
However, this functionality is not limited to Office applications; you could also write your own application that makes use of Excel’s functionality to perform complex calculations, or that uses Word’s spell-checking component. This enables you to write your applications faster, because you don’t have to write the functionality for a spell-checking component or a complex math component yourself. By extension, you could also write your own shareable components for use in others’ applications.
COM is a handy technology to use when creating reusable components, but it doesn’t tackle the problem of distributed applications. For your application to make use of a COM object, that object must reside on the same computer as your application. For this reason, Microsoft developed a technology called Distributed COM, or DCOM. DCOM extends the COM programming model, enabling applications to call COM objects that reside on remote computers. To an application, calling a remote object from a server using DCOM is just as easy as calling a local object on the same PC using COM — as long as the necessary configuration has been done ahead of time.
DCOM therefore enables you to manipulate COM objects on one machine from another. A common use of this is seen when querying data sources that reside on different computers using SQL Server’s distributed query mechanism. If you wish to make an update on one machine (only if you have first updated data on a second machine) then DCOM enables you to wrap both operations in a transaction which can be either rolled back if any step of the operation fails or committed if all steps are successful.
Nonetheless, as handy as COM and DCOM are for writing component-based software and distributed applications, they have one major drawback: both of these technologies are Microsoft-specific. The COM objects you write, or that you want to use, will work only on computers running Microsoft Windows; and even though you can call remote objects over DCOM, those objects also must be running on computers using Microsoft Windows.
For some people, this may not be a problem. For example, if you are developing an application for your company and you have already standardized on Microsoft Windows for your employees, using a Microsoft-specific technology might be fine. For others, however, this limitation means that DCOM is not an option.
CORBA and IIOP
Prior even to Microsoft’s work on COM, the Object Management Group, or OMG (see www.omg.org), developed a technology to solve the same problems that COM and DCOM try to solve, but in a platform-neutral way. They called this technology the Common Object Request Broker Architecture, or CORBA (see www.corba.org). As with COM, CORBA objects can be written in virtually any programming language, and any CORBA object can talk to any other, even if it was written in a different language. CORBA works similarly to COM, the main difference being who supplies the underlying architecture for the technology.
For COM objects, the underlying COM functionality is provided by the operating system (Windows), whereas with CORBA, an Object Request Broker (ORB) provides the underlying functionality (see Figure 14-2). In fact, the processes for instantiating COM and CORBA objects are similar.
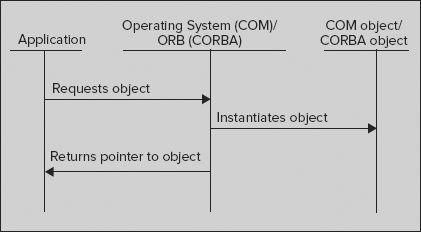
Although the concepts are the same, using an ORB instead of the operating system to provide the base object services offers one important advantage: it makes the CORBA platform independent. Any vendor that creates an ORB can create versions for Windows, UNIX, Linux, Mac, and so on.
Furthermore, the OMG created the Internet Inter-ORB Protocol (IIOP), which enables communication between different ORBs. This means that you not only have platform independence, but you also have ORB independence. You can combine ORBs from different vendors and have remote objects talking to each other over IIOP (as long as you avoid any vendor-specific extensions to IIOP).
Neither COM nor CORBA are easy to work with, which dramatically reduced their acceptance and take-up. Although COM classes are reasonably easy to use, and were the basis of thousands of applications including Microsoft Office, they are difficult to design and create. CORBA suffered similar problems, and these difficulties, as well as such scenarios as DLL hell in COM (mismatched incompatible versions of libraries of a machine) led to the design of other techniques.
Java RMI
Both DCOM and IIOP provide similar functionality: a language-independent way to call objects that reside on remote computers. IIOP goes a step further than DCOM, enabling components to run on different platforms. However, a language already exists that is specifically designed to enable you to write once, run anywhere: Java. (That was the theory; in practice it wasn’t that smooth and many people complained that it was more like write once, debug everywhere.)
Java provides the Remote Method Invocation, or RMI, system (see http://www.oracle.com/technetwork/java/javase/tech/index-jsp-136424.html) for distributed computing. Because Java objects can be run from any platform, the idea behind RMI is to just write everything in Java and then have those objects communicate with each other.
Although Java can be used to write CORBA objects that can be called over IIOP, or even to write COM objects using certain nonstandard Java language extensions, using RMI for distributed computing can provide a shorter learning curve because the programmer isn’t required to learn about CORBA and IIOP. All of the objects involved use the same programming language, so any data types are simply the built-in Java data types, and Java exceptions can be used for error handling. Finally, Java RMI can do one thing DCOM and IIOP can’t: it can transfer code with every call. That is, even when the remote computer you’re calling doesn’t have the code it needs, you can send it and still have the remote computer perform the processing.
The obvious drawback to Java RMI is that it ties the programmer to one programming language, Java, for all of the objects in the distributed system.
THE NEW RPC PROTOCOL: WEB SERVICES
Because the Internet has become the platform on which the majority of applications run, or at least partially run, it’s no surprise that a truly language- and platform-independent way of creating distributed applications would become the goal of software development. This aim has made itself known in the form of web services.
Web services are a means for requesting information or carrying out a processing task over the Internet, but, as stated, they often involve the encoding of both the request and the response in XML. Along with using standard Internet protocols for transport, this encoding makes messages universally available. That means that a Perl program running on Linux can call a .NET program running on Windows.NET, and nobody will be the wiser.
Of course, nothing’s ever quite that simple, especially when so many vendors, operating systems, and programming languages exist. To make these web services available, there must be standards so that everyone knows what information can be requested, how to request it, and what form the response will take.
XML web services have two main designs that differ in their approach to how the request is made. The first technique, known as XML-RPC, mimics how traditional function calls are made because the name of the method and individual parameters are wrapped in an XML format. The second version uses a document approach. This simply specifies that the service expects an XML document as its input, the format of which is predefined, usually by an XML Schema. The service then processes the document and carries out the necessary tasks.
The following sections look at XML-RPC, a simple form of web services. The discussion is then extended to look at the more heavy-duty protocols and how they fit together. The next chapter takes a closer look at two of the most commonly used protocols: SOAP and WSDL.
One topic that needs to be discussed before either method though is what’s known as the Same Origin policy.
The Same Origin Policy
One of the problems you may face when you want to use a web service from a browser arises because, by default, a browser will not be able to access a web service that resides on a different domain. For example, if your web page is accessed via http://www.myServer.com/customers.aspx, it will not be allowed to make a web call to http://www.AnotherDomain.com. Ostensibly, this means that you won’t be able to use the vast amount of web services that others have produced, many of which are free, from your own pages. Fortunately, you have a number of ways to work around the Same Origin policy.
Using a Server-Side Proxy
The restriction on calling services from a different domain applies only to code running in the client’s browser. This means that you can overcome the limitation by wrapping the service you want with one of your own that runs on the same domain as the page you want to use it. Then, when you call a method from your browser the request is passed to the service on your domain. This is, in turn, passed to the original service, which returns the response to your proxy, which finally returns the data to the web browser. It’s even often possible to create a generic proxy that can wrap many services with minimal configuration.
A secondary benefit of this sort of implementation is that you can often simplify the interface exposed by the original service. For example, to use Google’s search service directly you need to include a secret key with each request. With a proxy, this key can be stored in the proxy’s config file and the web browser doesn’t need to know it. Additionally, the response from the service can be massaged to make it easier to use from a browser; some services might return a lot of extra data that is of no use, and this can be filtered out by the proxy.
In general, a server-side proxy gives you the most power, but it can be overkill in some cases. There are a few other workarounds that may be preferable in other situations.
Using Script Blocks
Another way around the Same Origin policy is to take advantage of the fact that script blocks themselves are allowed to be pulled from a different domain. For example, to embed Google Analytics code in your page you need to include a JavaScript block that has its src attribute pointing to Google’s domain. You can use this facility to call simple web services that only need a GET request, that is, they rely on the URL carrying any additional data in the querystring. For example, follow these steps to get a service you may want to use to return the conversion rate for two currencies:
http://www.Currency.com/converter.asmx?from=USD&to=GBP
var conversionFactor = 0.638;
<script “type=text/javascript” src=”http://www.Currency.com/converter.asmx?from=USD&to=GBP”> </script>
<script type= “text/javascript”
src=”http://www.Currency.com/converter.asmx?from=USD&to=GBP”>
var conversionFactor = 0.638;
</script>You can now use the variable conversionFactor to turn any amount of dollars into pounds.
This process has been formalized and is known as JSONP. The technique is virtually identical, except that in JSONP the results are accessed via a function rather than a variable — for example, getConversionFactor() — and the data is in a JSON format. Helper methods are available to simplify the whole process in many client-side libraries; jQuery, for instance, makes the whole process very simple.
Allowing Different Domain Requests from the Server
You can call a service on a different domain in a few other ways that all have one thing in common: the server must be configured to allow such connections. Internet Explorer, from version 8 onward, has a native object called XDomainRequest that works in a similar manner to the more familiar XMLHttpRequest that is available in all modern browsers. The difference is that it enables cross-domain requests if the server that hosts the service includes a special heading, named Access-Control-Allow-Origin, to the browser’s initial request that contains the domain name of the request. There are various ways to configure this header; you can find more information on usage at http://msdn.microsoft.com/en-us/library/dd573303(v=vs.85).aspx.
Another alternative to any of these workarounds in the Same Origin policy is to use Adobe’s Flash component to make the request. Again, this plug-in can make cross-domain requests if the server is configured with a cross-domain policy file. The full details are available at http://www.adobe.com/devnet/articles/crossdomain_policy_file_spec.html.
Finally, Microsoft’s IIS web server enables you to add a cross-domain policy file similar to Adobe’s version, but with more options that lets you service calls from other domains. This is primarily intended to be used from Silverlight, a browser plug-in similar to Flash. You can find the details here: http://msdn.microsoft.com/en-us/scriptjunkie/gg624360.
Now that you’ve seen some of the hurdles in calling services on other domains, the next section returns to the XML-RPC scenario.
Understanding XML-RPC
One of the easiest ways to see web services in action is to look at the XML-RPC protocol. Designed to be simple, it provides a means for calling a remote procedure by specifying the procedure to call and the parameters to pass. The client sends a command, encoded as XML, to the server, which performs the remote procedure call and returns a response, also encoded as XML.
The protocol is simple, but the process — sending an XML request over the Web and getting back an XML response — is the foundation of web services, so understanding how it works will help you understand more complex protocols such as SOAP.
To practice eliminating the need for cross-domain workarounds, you’ll use a service hosted on the same domain as the client in the following activity. The service is a simple math one; two numbers can be passed in, and an arithmetic operation performed on them. The service exposes two methods, which are identified as MathService.Add and MathService.Subtract.
 <methodCall>
<methodName>MathService.Add</methodName>
<params>
<param>
<value>
<double>17</double>
</value>
</param>
<param>
<value>
<double>29</double>
</value>
</param>
</params>
</methodCall>
<methodCall>
<methodName>MathService.Add</methodName>
<params>
<param>
<value>
<double>17</double>
</value>
</param>
<param>
<value>
<double>29</double>
</value>
</param>
</params>
</methodCall>XML-RPC Demo
double result = Add(double operand1, double operand2)
<methodCall>
<methodName>MathService.Add</methodName>
<params>
<param>
<value>
<struct>
<member>
<name>Operand1</name>
<value>
<double>17</double>
</value>
</member>
<member>
<name>Operand2</name>
<value>
<double>29</double>
</value>
</member>
</struct>
</value>
</param>
</params>
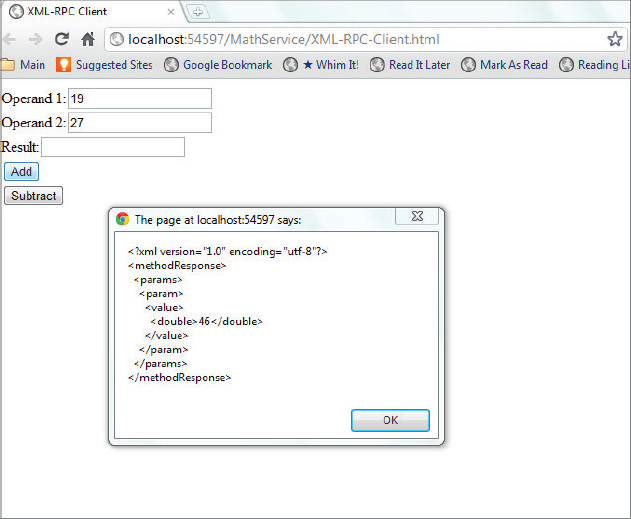
</methodCall><methodResponse>
<params>
<param>
<value>
<double>46</double>
</value>
</param>
</params>
</methodResponse>
Before you use this information to create a client that uses an XML-RPC service, take a closer look at what happens behind the scenes when you make a request and receive the response. The first thing to consider is how do you deliver the request?
Choosing a Network Transport
Generally, web services specifications enable you to use any network transport to send and receive messages. For example, you could use IBM MQSeries or Microsoft Message Queue (MSMQ) to send XML messages asynchronously over a queue, or even use SMTP to send messages via e-mail. However, the most common protocol used is probably HTTP. In fact, the XML-RPC specification requires it, so that is what you concentrate on in this section.
HTTP
Many readers may already be somewhat familiar with the HTTP protocol, because it is used almost every time you request a web page in your browser. Most web services implementations use HTTP as their underlying protocol, so take a look at how it works under the hood.
The Hypertext Transfer Protocol (HTTP) is a request/response protocol. This means that when you make an HTTP request, at its most basic, the following steps occur:
An HTTP message contains two parts: a set of headers, followed by an optional body. The headers are simply text, with each header separated from the next by a newline character, whereas the body might be text or binary information. The body is separated from the headers by two newline characters.
For example, suppose you attempt to load an HTML page, located at http://www.wiley.com/WileyCDA/Section/index.html (Wiley’s homepage) into your browser, which in this case is Internet Explorer 9.0. The browser sends a request similar to the following to the www.wiley.com server:
GET /WileyCDA/Section/index.html HTTP/1.1 Accept: */* Accept-Language: en-us Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Win32) Host: www.wiley.com
The first line of your request specifies the method to be performed by the HTTP server. HTTP defines a few types of requests, but this code has specified GET, indicating to the server that you want the resource specified, which in this case is /WileyCDA/Section/index.html. (Another common method is POST, covered in a moment.) This line also specifies that you’re using the HTTP/1.1 version of the protocol. Several other headers are there as well, which specify to the web server a few pieces of information about the browser, such as what types of information it can receive. Those are as follows:
- Accept tells the server what MIME types this browser accepts — in this case, */*, meaning any MIME types.
- Accept-Language tells the server what language this browser is using. Servers can potentially use this information to customize the content returned. In this case, the browser is specifying that it is the United States (us) dialect of the English (en) language.
- Accept-Encoding specifies to the server whether the content can be encoded before being sent to the browser. In this case, the browser has specified that it can accept documents that are encoded using gzip or deflate. These technologies are used to compress the data, which is then decompressed on the client.
For a GET request, there is no body in the HTTP message. In response, the server sends something similar to the following:
HTTP/1.1 200 OK Server: Microsoft-IIS/5.0 Date: Fri, 09 Dec 2011 14:30:52 GMT Content-Type: text/html Last-Modified: Thu, 08 Dec 2011 16:19:57 GMT Content-Length: 98 <html> <head><title>Hello world</title></head> <body> <p>Hello world</p> </body> </html>
Again, there is a set of HTTP headers, this time followed by the body. Obviously, the real Wiley homepage is a little more complicated than this, but in this case, some of the headers sent by the HTTP server were as follows:
- A status code, 200, indicating that the request was successful. The HTTP specification defines a number of valid status codes that can be sent in an HTTP response, such as the famous (or infamous) 404 code, which means that the resource being requested could not be found. You can find a full list of status codes at http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.
- A Content-Type header, indicating what type of content is contained in the body of the message. A client application (such as a web browser) uses this header to decide what to do with the item; for example, if the content type were a .wav file, the browser might load an external sound program to play it, or give the user the option of saving it to the hard drive instead.
- A Content-Length header, which indicates the length of the body of the message.
There are many other possible headers but these three will always be included in the response. To make the initial request you have a choice of methods (or verbs as they are often called). These verbs offer ways to request content, send data, and delete resources from the web server.
The GET method is the most common HTTP method used in regular everyday surfing. The second most common is the POST method. When you do a POST, information is sent to the HTTP server in the body of the message. For example, when you fill out a form on a web page and click the Submit button, the web browser will usually POST that information to the web server, which processes it before sending back the results. Suppose you create an HTML page that includes a form like this:
<html> <head> <title>Test form</title> </head> <body> <form action=”acceptform.aspx” method=”POST”> Enter your first name: <input name=”txtFirstName” /><br /> Enter your last name: <input name=”txtLastName” /><br /> <input type=“submit” /> </form> </body> </html>
This form will POST any information to a page called acceptform.aspx, in the same location as this HTML file, similar to the following:
POST /acceptform.aspx HTTP/1.1 Accept: */* Referer: http://www.wiley.com/myform.htm Accept-Language: en-us Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Win32) Host: www.wiley.com Content-Length: 36 txtFirstName=Joe&txtLastName=Fawcett
Whereas the GET method provides for basic surfing the Internet, it’s the POST method that enables things like e-commerce, because information can be passed back and forth.
Why Use HTTP for Web Services?
It was mentioned earlier that most web services implementations probably use HTTP as their transport. Here are a few reasons why:
- HTTP is already a widely implemented, and well understood, protocol.
- The request/response paradigm lends itself well to RPC.
- Most firewalls are already configured to work with HTTP.
- HTTP makes it easy to build in security by using Secure Sockets Layer (SSL).
HTTP is Widely Implemented
One of the primary reasons for the explosive growth of the Internet was the availability of the World Wide Web, which runs over the HTTP protocol. Millions of web servers are in existence, serving up HTML and other content over HTTP, and many, many companies use HTTP for e-commerce.
HTTP is a relatively easy protocol to implement, which is one of the reasons why the Web works as smoothly as it does. If HTTP had been hard to implement, a number of implementers would have probably gotten it wrong, meaning some web browsers wouldn’t have worked with some web servers.
Using HTTP for web services implementations is therefore easier than other network protocols would have been. This is especially true because web services implementations can piggyback on existing web servers — in other words, use their HTTP implementation. This means you don’t have to worry about the HTTP implementation at all.
Request/Response Works with RPC
Typically, when a client makes an RPC call, it needs to receive some kind of response. For example, if you make a call to the MathService.Add method, you need to get a result back or it wouldn’t be a very useful procedure to call. In other instances, such as submitting a new blog post, you may not need data returned from the RPC call, but you may still need confirmation that the procedure executed successfully. As a common example, an order to a back-end database may not require data to be returned, but you should know whether the submission failed or succeeded.
HTTP’s request/response paradigm lends itself easily to this type of situation. For your MathService.Add remote procedure, you must do the following:
In some cases, such as in the SOAP specification, messages are one-way instead of two-way. This means two separate messages must be sent: one from the client to the server with, say, numbers to add, and one from the server back to the client with the result of the calculation. In most cases, however, when a specification requires the use of two one-way messages, it also specifies that when a request/response protocol such as HTTP is used, these two messages can be combined in the request/response of the protocol.
HTTP is Firewall-Ready
Most companies protect themselves from outside hackers by placing a firewall between their internal systems and the external Internet. Firewalls are designed to protect a network by blocking certain types of network traffic. Most firewalls allow HTTP traffic (the type of network traffic that would be generated by browsing the Web) but disallow other types of traffic.
These firewalls protect the company’s data, but they make it more difficult to provide web-based services to the outside world. For example, consider a company selling goods over the Web. This web-based service would need certain information, such as which items are available in stock, which it would have to get from the company’s internal systems. To provide this service, the company probably needs to create an environment such as the one shown in Figure 14-3.
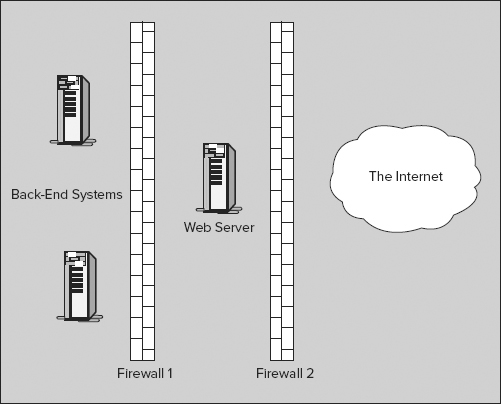
This is a very common configuration, in which the web server is placed between two firewalls. (This section, between the two firewalls, is often called a demilitarized zone, or DMZ.) Firewall 1 protects the company’s internal systems and must be carefully configured to allow the proper communication between the web server and the internal systems, without letting any other traffic get through. Firewall 2 is configured to let traffic through between the web server and the Internet, but no other traffic.
This arrangement protects the company’s internal systems, but because of the complexity added by these firewalls — especially for the communication between the web server and the back-end servers — it makes it a bit more difficult for the developers creating this web-based service. However, because firewalls are configured to let HTTP traffic go through, it’s much easier to provide the necessary functionality if all of the communication between the web server and the other servers uses this protocol.
HTTP Security
Because there is already an existing security model for HTTP, the Secure Sockets Layer (SSL), it is very easy to make transactions over HTTP secure. SSL encrypts traffic as it passes over the Web to protect it from prying eyes, so it’s perfect for web transactions, such as credit card orders. In fact, SSL is so common that hardware accelerators are available to speed up SSL transactions.
Using HTTP for XML-RPC
Using HTTP for XML-RPC messages is very easy. You need to do only two things with the client:
- For the HTTP method, use POST.
- For the body of the message, include an XML document comprising the XML-RPC request.
For example, consider the following:
POST /RPC2 HTTP/1.1 Accept: */* Accept-Language: en-us Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) Host: www.wiley.com Content-Length: 180 <methodCall><methodName>MathService.Add</methodName><params> <param><value><double>17</double></value></param> <param><value><double>29</double></value></param> </params></methodCall>
The headers define the request, and the XML-RPC request makes up the body. The server knows how to retrieve that body and process it. In the next chapter, you look at processing the actual request, but for now you just send an XML-RPC request and process the response.
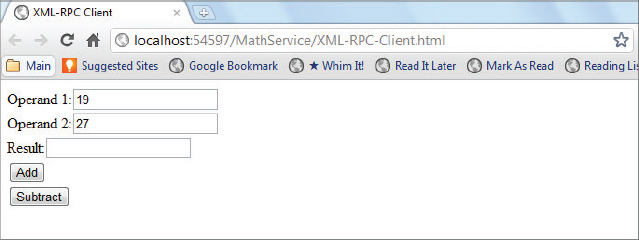
The following Try It Out shows how an XML-RPC service can be called from a simple web page using HTTP’s POST method.
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<title>XML-RPC Client</title>
<!-- script will go here -->
</head>
<body>
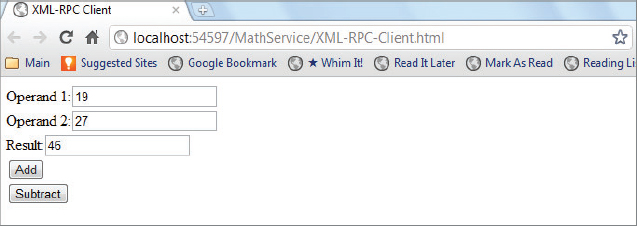
<label for=”txtOperand1”>Operand 1:</label>
<input type=”text” id=”txtOperand1” /><br />
<label for=”txtOperand2”>Operand 2:</label>
<input type=”text” id=”txtOperand2” /><br />
<label for=”txtResult”>Result:</label>
<input type=”text” id=”txtResult” readonly=”readonly” /><br />
<input type=”button” value=”Add” onclick=”doAdd();” /><br />
<input type=”button” value=”Subtract” onclick=”doSubtract();” /><br />
</body>
</html>
XML-RPC-Client.html
<head> <title>XML-RPC Client</title> <script type=”text/javascript” src=”http://code.jquery.com/jquery-1.6.4.js”></script> <!-- rest of script will go here --> </head>
XML-RPC-Client.html
<script type=”text/javascript”>
function doAdd()
{
var response = callService(“MathService.Add”);
}
function doSubtract()
{
var response = callService(“MathService.Subtract”);
}
function callService(methodName)
{
$(“#txtResult”).val(“”);
var operand1 = $(“#txtOperand1”).val();
var operand2 = $(“#txtOperand2”).val();
var request = getRequest(methodName, operand1, operand2);
//alert(request);
$.ajax({ url: “Service.aspx”,
type: “post”,
data: request,
processData: false,
contentType: “text/xml”,
success: handleServiceResponse });
}
function getRequest(methodName, operand1, operand2)
{
var sRequest = “<methodCall>”
+ “<methodName>” + methodName + “</methodName>”
+ “<params>”
+ “<param><value><double>”
+ operand1
+ “</double></value></param>”
+ “<param><value><double>”
+ operand2
+ “</double></value></param>”
+ “</params>”
+ “</methodCall>”;
return sRequest;
}
function handleServiceResponse(data, textStatus, jqXHR)
{
if (textStatus == “success”)
{
alert(jqXHR.responseText)
var result = $(“[nodeName=double]”, jqXHR.responseXML).text();
$(“#txtResult”).val(result);
}
else
{
alert(“Error retrieving web service response”);
}
}
</script>
XML-RPC-Client.html
function callService(methodName)
{
$(“#txtResult”).val(“”);
var operand1 = $(“#txtOperand1”).val();
var operand2 = $(“#txtOperand2”).val();
var request = getRequest(methodName, operand1, operand2);
//alert(request);
$.ajax({ url: “Service.aspx”,
type: “post”,
data: request,
processData: false,
contentType: “text/xml”,
success: handleServiceResponse });
}
function getRequest(methodName, operand1, operand2)
{
var sRequest = “<methodCall>”
+ “<methodName>” + methodName + “</methodName>”
+ “<params>”
+ “<param><value><double>”
+ operand1
+ “</double></value></param>”
+ “<param><value><double>”
+ operand2
+ “</double></value></param>”
+ “</params>”
+ “</methodCall>”;
return sRequest;
}
$.ajax({ url: “Service.aspx”,
type: “post”,
data: request,
processData: false,
contentType: “text/xml”,
success: handleServiceResponse });
}
- url: Contains the URL of the web service being called.
- type: Contains the type of HTML request, usually GET or POST.
- data: Contains the actual XML message.
- processData: Says whether the data needs conversion from the format it is in. In this case that’s false, otherwise the XML would be escaped using < for <, and so on.
- contentType: The content type of the data being posted.
- success: Defines which function to use if the web call is successful. As stated before, the possibility of an error is ignored in this simplified demo.
function handleServiceResponse(data, textStatus, jqXHR)
{
if (textStatus == “success”)
{
alert(jqXHR.responseText)
var result = $(“[nodeName=double]”, jqXHR.responseXML).text();
$(“#txtResult”).val(result);
}
else
{
alert(“Error retrieving web service response”);
}
}
The next section describes a different way of using web services than XML-RPC: REST.
Understanding REST Services
REST stands for Representational State Transfer and is a framework for creating web services that can, but do not have to, use XML. Following are two important principles of REST:
The first principle is easy to understand. If I want to retrieve a customer’s details, I might use a URL such as http://myServer.com/customers/123, where 123 is the customer’s unique identifier. The second principle relies on the fact that the HTTP protocol defines a number of verbs, or commands, indicating how a resource is treated. The most common verb is GET, which simply retrieves the resource based entirely on the URL requested. The next most common is POST, which passes a block of data, as seen in the preceding section, to a specified URL. A number of other less well-known verbs exist, such as PUT, which creates a resource, DELETE, which removes a resource, and HEAD, which asks for information about a resource without actually fetching it. REST uses these verbs along with the specified URL to fetch, create, and delete online resources. For example, to create a new customer you might POST the relevant data to a URL and the server would process the request and create a new customer in your sales database, or you might PUT the details instead. To delete an existing customer you might issue a DELETE request along with the URL of the customer to be removed, such as the customer already mentioned, http://myServer.com/customers/123.
You can find the original article on REST, written by its architect, Roy Fielding, at http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm.
The following Try It Out demonstrates how to call a REST style web service using Fiddler, a free web development and debugging tool.
<?xml version=”1.0” encoding=”UTF-8”?>
<feed gd:kind=”shopping#products”
gd:etag=”"czKOfew9E3svi7vOBQ3vsAgGZzo/9wsxV-m1LokeaXtPG67Dj-pgCUI"”
xmlns=”http://www.w3.org/2005/Atom” xmlns:gd=”http://schemas.google.com/g/2005”
xmlns:openSearch=”http://a9.com/-/spec/opensearchrss/1.0/”
xmlns:s=”http://www.google.com/shopping/api/schemas/2010”>
<id>tag:google.com,2010:shopping/products</id>
<updated>2011-12-12T17:02:55.909Z</updated>
<title>Shopping Products</title>
<generator version=”v1”
uri=”https://www.googleapis.com/shopping/search/”>Search API for
Shopping</generator>
<link rel=”alternate” type=”text/html”
href=”https://www.googleapis.com/shopping/search/”/>
<link rel=”http://schemas.google.com/g/2005#feed”
type=”application/atom+xml”
href=”https://www.googleapis.com/shopping/search/v1/public/products?alt=atom”/>
<link rel=”self” type=”application/atom+xml”
href=”https://www.googleapis.com/shopping/search/v1/
public/products?country=US&q=digital+camera&alt=atom&
startIndex=1&maxResults=25”/>
<link rel=”next” type=”application/atom+xml”
href=”https://www.googleapis.com/shopping/search/v1/
public/products?country=US&q=digital+camera&alt=atom&
startIndex=26&maxResults=25”/>
<link rel=”previous” type=”application/atom+xml”/>
<openSearch:totalResults>745713</openSearch:totalResults>
<openSearch:startIndex>1</openSearch:startIndex>
<openSearch:itemsPerPage>25</openSearch:itemsPerPage>
<entry gd:kind=”shopping#product”>
<id>tag:google.com,2010:shopping/products/1172711/68751086469788882</id>
<author>
<name>B&H Photo-Video-Audio</name>
</author>
<published>2011-10-12T14:56:40.000Z</published>
<updated>2011-12-12T04:48:51.000Z</updated>
<title>Canon EOS 5D Mark II Digital Camera (Body Only)</title>
<content type=”text”>The Canon EOS 5D Mark II (Body Only) improves upon the EOS
5D by increasing the resolution by about 40% to 21.1 megapixels and adds a Live
View feature that allows users to preview shots on the camera's high
resolution 3.0 LCD display. It even incorporates the ability to record full motion HD Video with sound so you can capture the action as well as superb images </content>
<link rel=”alternate” type=”text/html”
href=”http://www.bhphotovideo.com/c/product/583953-REG/Canon_2764B003_EOS_5D_Mark_II.html/BI/1239/kw/CAE5D2”/>
<link rel=”self” type=”application/atom+xml”
href=”https://www.googleapis.com/shopping/search/v1/public/products/1172711/gid/68751086469788882?alt=atom”/>
<s:product>
<s:googleId>68751086469788882</s:googleId>
<s:author>
<s:name>B&H Photo-Video-Audio</s:name>
<s:accountId>1172711</s:accountId>
</s:author>
<s:creationTime>2011-10-12T14:56:40.000Z</s:creationTime>
<s:modificationTime>2011-12-12T04:48:51.000Z</s:modificationTime>
<s:country>US</s:country>
<s:language>en</s:language>
<s:title>Canon EOS 5D Mark II Digital Camera (Body Only)</s:title>
<s:description>The Canon EOS 5D Mark II (Body Only) improves upon the EOS 5D by
increasing the resolution by about 40% to 21.1 megapixels and adds a Live View
feature that allows users to preview shots on the camera's high resolution
3.0 LCD display </s:description>
<s:link>http://www.bhphotovideo.com/c/product/
583953-REG/Canon_2764B003_EOS_5D_Mark_II.html/BI/1239/kw/CAE5D2</s:link>
<s:brand>Canon</s:brand>
<s:condition>new</s:condition>
<s:gtin>00013803105384</s:gtin>
<s:gtins>
<s:gtin>00013803105384</s:gtin>
</s:gtins>
<s:inventories>
<s:inventory channel=”online” availability=”inStock”>
<s:price shipping=”0.0” currency=”USD”>2209.95</s:price>
</s:inventory>
</s:inventories>
<s:images>
<s:image link=”http://www.bhphotovideo.com/images/nowm/583953.jpg”/>
</s:images>
</s:product>
</entry>
<entry gd:kind=”shopping#product”>
<id>tag:google.com,2010:shopping/products/1113342/13850367466326274615</id>
<author>
<name>Walmart</name>
</author>
<published>2011-07-04T19:48:28.000Z</published>
<updated>2011-12-10T05:11:44.000Z</updated>
<title>Canon Powershot Sx130-is Black 12.1mp Digital Camera W/ 12x Optical</title>
<content type=”text”>Canon PowerShot SX130-IS 12.1MP Digital Camera:12.1-
megapixel </content>
<link rel=”alternate” type=”text/html”
href=”http://www.walmart.com/catalog/product.do?product_id=14972582&sourceid=1500000000000003142050&ci_src=14110944&ci_sku=14972582”/>
<link rel=”self” type=”application/atom+xml”
href=”https://www.googleapis.com/shopping/search/v1/
public/products/1113342/gid/13850367466326274615?alt=atom”/>
<s:product>
<s:googleId>13850367466326274615</s:googleId>
<s:author>
<s:name>Walmart</s:name>
<s:accountId>1113342</s:accountId>
</s:author>
<s:creationTime>2011-07-04T19:48:28.000Z</s:creationTime>
<s:modificationTime>2011-12-10T05:11:44.000Z</s:modificationTime>
<s:country>US</s:country>
<s:language>en</s:language>
<s:title>Canon Powershot Sx130-is Black
12.1mp Digital Camera W/ 12x Optical</s:title>
<s:description>Canon PowerShot SX130-IS 12.1MP Digital Camera:
12.1-megapixel resolutionDelivers excellent picture </s:description>
<s:link>http://www.walmart.com/catalog/product.do?
product_id=14972582&
sourceid=1500000000000003142050&ci_src=14110944&ci_sku=14972582</s:link>
<s:brand>Canon</s:brand>
<s:condition>new</s:condition>
<s:gtin>00013803127386</s:gtin>
<s:gtins>
<s:gtin>00013803127386</s:gtin>
</s:gtins>
<s:inventories>
<s:inventory channel=”online” availability=”inStock”>
<s:price shipping=”0.0” currency=”USD”>169.0</s:price>
</s:inventory>
</s:inventories>
<s:images>
<s:image
link=”http://i.walmartimages.com/i/p/00/01/38/03/12/0001380312738_500X500.jpg”/>
</s:images>
</s:product>
</entry>
<s:requestId>0CIjh9NiB_awCFUcEtAod6jsAAA</s:requestId>
</feed>THE WEB SERVICES STACK
If you’ve been having trouble keeping track of all of the web services–related specifications out there and just how they all fit together, don’t feel bad, it’s not just you. In fact, literally dozens of specs exist, with a considerable amount of duplication as companies jockey for position in this field. Lately it’s gotten so bad that even Don Box, one of the creators of the major web services protocol, SOAP, commented at a conference that the proliferation in standards has led to a “cacophony” in the field and that developers should write fewer specs and more applications. It’s also led to a profusion of frameworks that try to make things easier for you by hiding much of the plumbing and letting you concentrate on the business logic. Many succeed, but often the frameworks themselves are so difficult to learn that they only end up making the tasks harder.
Not that some standardization isn’t necessary, of course. That’s the whole purpose of the evolution of web services as an area of work — to find a way to standardize communications between systems. This section discusses the major standards you must know in order to implement most web services systems, and then addresses some of the emerging standards and how they all fit together.
SOAP
If you learn only one web services–related protocol, SOAP is probably your best bet. Originally conceived as the Simple Object Access Protocol, SOAP has now been adapted for so many different uses that its acronym is no longer applicable.
SOAP is an XML-based language that provides a way for two different systems to exchange information relating to a remote procedure call or other operation. SOAP messages consist of a Header, which contains information about the request, and a Body, which contains the request itself. Both the Header and Body are contained within an Envelope.
SOAP calls are more robust than, say, XML-RPC calls, because you can use arbitrary XML. This enables you to structure the call in a way that’s best for your application. For example, say your application ultimately needs an XML node such as the following:
<totals>
<dept id=”2332”>
<gross>433229.03</gross>
<net>23272.39</net>
</dept>
<dept id=”4001”>
<gross>993882.98</gross>
<net>388209.27</net>
</dept>
</totals>
Rather than try to squeeze your data into an arbitrary format such as XML-RPC, you can create a SOAP message such as the following:
<?xml version=”1.0” encoding=“UTF-8”?>
<SOAP:Envelope xmlns:SOAP=”http://www.w3.org/2003/05/soap-envelope”>
<SOAP:Header></SOAP:Header>
<SOAP:Body>
<totals xmlns=”http://www.wiley.com/SOAP/accounting”>
<dept id=”2332”>
<gross>433229.03</gross>
<net>23272.39</net>
</dept>
<dept id=”4001”>
<gross>993882.98</gross>
<net>388209.27</net>
</dept>
</totals>
</SOAP:Body>
</SOAP:Envelope>
SOAP also has the capability to take advantage of technologies such as XML-Signature for security. You can also use attachments with SOAP, so a request could conceivably return, say, a document or other information. In Chapter 15, “SOAP and WSDL” you create a complete SOAP server and client, and look at the syntax of a SOAP message.
Of course, this suggests another problem: How do you know what a SOAP request should look like, and what it will return as a result? As you’ll see next, WSDL solves that problem.
WSDL
The Web Services Description Language (WSDL) is an XML-based language that provides a contract between a web service and the outside world. To understand this better, recall the discussion of COM and CORBA. The reason why COM and CORBA objects can be so readily shared is that they have defined contracts with the outside world. This contract defines the methods an object provides, as well as the parameters to those methods and their return values. Interfaces for both COM and CORBA are written in variants of the Interface Definition Language (IDL). Code can then be written to look at an object’s interface to determine what functions are provided. In practice, this dynamic investigation of an object’s interface often happens at design time, as a programmer is writing the code that calls another object. A programmer would find out what interface an object supports and then write code that properly calls that interface.
Web services have a similar contract with the outside world, except that the contract is written in WSDL instead of IDL. This WSDL document outlines what messages the SOAP server expects in order to provide services, as well as what messages it returns. Again, in practice, WSDL is likely used at design time. A programmer would use WSDL to figure out what procedures are available from the SOAP server and what format of XML is expected by that procedure, and then write the code to call it.
To take things a step further, programmers might never have to look at WSDL directly or even deal with the underlying SOAP protocol. Already available are several SOAP toolkits that can hide the complexities of SOAP. If you point one of these toolkits at a WSDL document, it can automatically generate code to make the SOAP call for you! At that point, working with SOAP is as easy as calling any other local object on your machine. Chapter 15 of this book looks at the syntax for a WSDL document. After you’ve built it, how do you let others know that it’s out there? Enter UDDI.
UDDI
The Universal Discovery, Description, and Integration (UDDI) protocol enables web services to be registered so that they can be discovered by programmers and other web services. For example, if you’re going to create a web service that serves a particular function, such as providing up-to-the-minute traffic reports by GPS coordinates, you can register that service with a UDDI registry. The global UDDI registry system consists of several different servers that all mirror each other, so by registering your company with one, you add it to all the others.
The advantage of registering with the UDDI registry is twofold. First, your company’s contact information is available, so when another company wants to do business with you, it can use the white pages type of lookup to get the necessary contact information. A company’s listing not only includes the usual name, phone number, and address type of information, but also information on the services available. For example, it might include a link to a WSDL file describing the traffic reporting system.
The UDDI registry system also enables companies to find each other based on the types of web services they offer. This is called a green pages type of listing. For example, you could use the green pages to find a company that uses web services to take orders for widgets. Listings would also include information on what the widget order request should look like and the structure of the order confirmation, or, at the very least, a link to that information.
Many of the SOAP toolkits available, such as IBM’s Web Services Toolkit, provide tools to work with UDDI. UDDI seems to be another of those seemed like a good idea at the time specifications. Most real-world developers naturally prefer to build their applications knowing that the web services they will consume are available, and are unwilling to risk having to discover them dynamically. This is one of the reasons why UDDI has never really taken off.
Surrounding Specifications
So far this chapter has described a landscape in which you can use a UDDI registry to discover a web service for which a WSDL file describes the SOAP messages used by the service. For all practical purposes, you could stop right there, because you have all of the pieces that are absolutely necessary, but as you start building your applications, you will discover that other issues need to be addressed.
For example, just because a web service is built using such specifications as SOAP and WSDL doesn’t mean that your client is going to flawlessly interact with it. Interoperability continues to be a challenge between systems, from locating the appropriate resource to making sure types are correctly implemented. Numerous specifications have emerged in an attempt to choreograph the increasingly complex dance between web service providers and consumers. Moreover, any activity that involves business eventually needs security.
This section looks at some of the many specifications that have been working their way into the marketplace. Only time will tell which will survive and which will ultimately wither, but it helps to understand what’s out there and how it all fits together.
Interoperability
At the time of this writing, the big name in interoperability is the Web Services Interoperability Organization, or WS-I (www.ws-i.org). This industry group includes companies such as IBM, Microsoft, and Sun Microsystems, and the purpose of the organization is to define specific “profiles” for web services and provide testing tools so that companies can be certain that their implementations don’t contain any hidden “gotchas.” WS-I has released a Basic Profile as well as a number of use cases and sample implementations.
Some other interoperability-related specifications include the following:
- WS-Addressing (www.w3.org/Submission/ws-addressing/) provides a way to specify the location of a web service. Remember this doesn’t necessarily refer to HTTP. WS-Addressing defines an XML document that indicates how to find a service, no matter how many firewalls, proxies, or other devices and gateways lie between you and that service.
- WS-Eventing (www.w3.org/Submission/WS-Eventing/) describes protocols that involve a publish/subscribe pattern, in which web services subscribe to or provide event notifications.
Coordination
For a while, it looked like the winner in coordination and choreography was going to be ebXML (www.ebxml.org), a web services version of Electronic Data Interchange (EDI), in which companies become “trading partners” and define their interactions individually. ebXML consists of a number of different modules specifying the ways in which businesses can define not only what information they’re looking for and the form it should take, but the types of messages that should be sent from a multiple-step process. Although ebXML is very specific and seems to work well in the arena for which it was designed, it doesn’t necessarily generalize well in order to cover web services outside the EDI realm.
As such, Business Process Execution Language for Web Services (BPEL4WS) (http://msdn2.microsoft.com/en-us/library/aa479359.aspx) has been proposed by a coalition of companies, including Microsoft and IBM. BPEL4WS defines a notation for specifying a business process ultimately implemented as web services. Business processes fall into two categories: executable business processes and business protocols. Executable business processes are actual actions performed in an interaction, whereas business protocols describe the effects (for example, orders placed) without specifying how they’re actually accomplished. When BPEL4WS was introduced in 2002, it wasn’t under the watchful eye of any standards body, which was a concern for many developers, so work is currently ongoing within the Web Services Business Process Execution Language (WS-BPEL) (www.oasis-open.org/committees/tc_home.php?wg_abbrev=wsbpel) group at the OASIS standards body.
Not to be outdone, the World Wide Web Consortium has opened the WS-Choreography (www.w3.org/2002/ws/chor/) activity, which is developing a way for companies to describe their interactions with trading partners. In other words, they’re not actually defining how data is exchanged, but rather the language to describe how data is exchanged. In fact, Choreography Definition Language is one of the group’s deliverables. However, the group hasn’t produced much since it started and the last main publication was 2004.
In the meantime, Microsoft, IBM, and BEA are also proposing WS-Coordination (http://www.ibm.com/developerworks/library/specification/ws-tx/), which is also intended to provide a way to describe these interactions. This specification involves the WS-AtomicTransaction specification for describing individual components of a transaction.
Security
Given its importance, perhaps it should come as no surprise that security is currently another hotly contested area. In addition to the basic specifications set out by the World Wide Web Consortium, such as XML Encryption (www.w3.org/Encryption/2001/) and XML Signature (www.w3.org/Signature/), the industry is currently working on standards for identity recognition, reliable messaging, and overall security policies.
All the major players such as IBM and Microsoft are working to simplify and standardize identity management for such tasks as provisioning users and authentication. A number of non-commercial organizations such as Kantara (http://kantarainitiative.org/) are also looking at the problem.
Perhaps the most confusing competition is between WS Reliable Messaging (www.oasis-open.org/committees/tc_home.php?wg_abbrev=wsrm) and WS-ReliableMessaging (http://www.ibm.com/developerworks/library/specification/ws-rm/). In essence, both specifications are trying to describe a protocol for reliably delivering messages between distributed applications within a particular tolerance, or Quality of Service. These specifications deal with message order, retransmission, and ensuring that both parties to a transaction are aware of whether a message has been successfully received.
Two other specifications to consider are WS-Security and WS-Policy:
- WS-Security (http://www.ibm.com/developerworks/library/specification/ws-secpol/) is designed to provide enhancements to SOAP that make it easier to control issues such as message integrity, message confidentiality, and authentication, no matter what security model or encryption method you use.
- WS-Policy (http://www.ibm.com/developerworks/library/specification/ws-polfram/) is a specification meant to help people writing other specifications, and it provides a way to specify the “requirements, preferences, and capabilities” of a web service.
SUMMARY
- Web services arose from a need for a cross-platform way for one machine to be able to invoke processes on a separate machine.
- The Same Origin policy means that under normal circumstances only pages residing in the same domain as the web service, can use that service.
- XML remote procedure calls were the original web services; they enable methods to be called across a network by wrapping parameters and returned values in a standard XML format.
- With REST services, when the URL of the service defines a specific resource, the HTTP verb used defines the action required, and the body of the request can contain any supplementary data.
- It is relatively simple to utilize web services, especially from a web page. There are many libraries, such as jQuery, that hide the underlying protocols and formats and just let you specify the service and any parameters.
Exercises
You can find suggested solutions to these questions in the Appendix A.
cust_id: 3263827 order_id: THX1138
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY POINTS |
| Before web services | Many technologies such as DCOM and IIOP existed to enable cross-network method requests. However, they were not cross-platform. |
| Same origin policy | This policy means that a web service can only be consumed by a page in the same domain. There are ways to get around this restriction such as server-side proxies and client-access policies. |
| XML-RPC | XML remote procedure calls were an early attempt to solve the cross-platform issue. They wrap method calls and return values in a standard XML format. |
| REST services | REST services use a web URL as a resource identifier and the HTTP verb to specify what sort of action is required. They are generally the easiest type of service to use. |
| Consuming services | With the many libraries around, both script and code, it’s relatively easy to create clients that can utilize remote services. |