
Chapter 19
Case Study: XML in Publishing
WHAT YOU WILL LEARN IN THIS CHAPTER:
- How XML fits into a publisher’s workflow
- How XSLT, XQuery, SVG, HTML and XML might be used together in practice
- How to generate SVG images with XSLT
- The purpose of XProc, XSL-FO and MathML
- How to generate PDF from XML with XSL-FO and XSLT
- How XML technologies are used together
This chapter is about a fictional publishing company making a move to an XML-based workflow. Although the company is fictional, the scenario is typical of an actual XML project and shows you how the various topics that you have studied in this book can be used together. You also encounter some new XML vocabularies and projects, such as the Text Encoding Initiative (TEI), MathML, the Darwin Information Typing Architecture (DITA), and DocBook, and learn a little about their strengths and how to discover more vocabularies yourself. This is the last chapter in this book, but it could also be the first chapter of a book about using XML in practice.
BACKGROUND
Hoy Books is a (fictional) reference book publisher operating out of the city of Lyness in Orkney, UK. It has recently purchased another publishing company, Halfdan Books, based in North Ronaldsay. The two companies have combined into a single office in nearby Kirkwall, and are in the process of trying to sort out who does what and what happened to the tea bags that were by the water cooler.
Halfdan Books has published a popular series of books on heraldry. Hoy Books, the larger company, publishes a series of Who’s Who reference books and a larger biographical dictionary, Hoy’s Who.
The chief technology officer of the amalgamated company has decided that the biographical books should incorporate heraldic information where available, and the business development officer has determined that, to keep the biographies more current and to reduce costs, a new production system should be installed.
The new system must enable remote writers on the various islands of Orkney to update articles, and must support creation of electronic books as well as the existing print publications.
PROJECT INTRODUCTION: CURRENT WORKFLOW
In the distant past, the editorial team in Lyness would determine the list of people, both living and historical, to include in a new edition of Hoy’s Who, and would send out letters to biographers. The biographers would research histories — sometimes transcribing old manuscripts or books and sometimes writing articles, all on neatly typed pages — and then send back what they had written to Lyness. The pages would be edited in-house and then typeset and printed as “galley proofs,” which would be sent back to the authors for corrections.
Currently, the authors send files using Microsoft Word and a template with named styles, but the process is essentially the same. The in-house editors at Hoy Books have to make sure that the styles have been used correctly, as well as making the same editorial corrections and suggestions that they did in the paper-based system.
Once the Word files are final they are imported to a page layout program (Adobe InDesign) and assembled into files, each representing 64 complete pages. These are then printed as PDF files, checked one last time, and sent to the company that does the printing. The printer must have even multiples of 64 pages to make “signatures” for the folding and binding machines.
Each time all the files are ready for a new edition to be made, the staff focus all their time on the editing, on sorting out conversion problems, and on getting everything ready; they are unable to accept new articles during this time, and the authors have had to learn that there’s a month in which there’s no new work for them. This situation proved to be less than ideal, therefore a New System Task Force (NSTF) was created at Hoy Books and tasked with finding and implementing a solution.
INTRODUCING A NEW XML-BASED WORKFLOW
To remain competitive, Hoy Books needed a more streamlined workflow. They had to reduce the time it took to make a new edition of their book, and also produce electronic books (e-books) and a searchable website.
To publish faster, the editorial staff needed to be able to edit incoming articles all the time without having to drop everything to become production managers; this would also help them to retain the external writers they hired. The new workflow also needed to incorporate the Halfden Books heraldry database publishing business.
The best technology for gluing together all of these components is XML, and because of this, Hoy Books decided to attempt a move to an XML-based workflow. In doing so, they chose to equip their external authors with a customized XML editor so that they would no longer need to convert the articles from the word processing format, as that process was error-prone and expensive.
The following sections describe some of the process that Hoy Books went through along their journey to an XML-based workflow. Similar processes are followed by many organizations when they adopt XML: identifying the people who would be affected, consulting with them to learn their needs and also to make them feel part of the project, building prototypes and testing, training staff as needed, documenting the work, and gradually adding functionality as the system grows.
Consultations
At Hoy Books a previous attempt to move to an expensive content management system failed because it relied on the authors having a fast Internet connection, something not always possible on the islands. The island-dwelling authors weren’t consulted in this matter before the new system was implemented, and as a result it was unsuccessful.
The single most important aspect to the success of a major new project is to get buy-in from everyone who will be affected. Because it’s often impossible to determine exactly who will be affected, it’s also essential to communicate clearly. Therefore, meetings to determine who should be involved, and why, must always be part of any XML project.
This time the New System Task Force (NSTF) consulted the authors as well as the printers, external editors, and all of the staff.
People were consulted at every stage, representatives were interviewed, and careful notes were taken.
Documenting the Project
A traditional way of approaching a new project is to make a Requirements document and a Specification document, then implement the specifications and check that the requirements were met. In practice, as soon as people start to see the new system, the requirements will change. The Hoy Books team learned about a newer methodology called agile development, in which the requirements and design evolve continuously as the people on the project start to understand what they really need. The team thought this was a good idea, and kept both a Requirements document for tracking the needs they knew they had to meet, and a Current Issues document for tracking issues they needed to resolve.
Prototyping
Having sessions in which people who will use a new system walk through a mock-up, even if it’s just based on sketches on paper, can serve several goals. It can turn the new users into enthusiastic evangelists, telling their co-workers how good the new system will be, and it can lead to immediate and essential feedback for the designers. It’s important not to oversell a system at this stage, because the most ardent evangelist, when disappointed, can quickly become the most hardened opponent. The Hoy Books task force explained to employees and clients that they really valued the users’ opinions and experience, and that it was a learning experience for everyone, so no one should be worried if there were problems at early stages.
After the design mock-ups, the team built some web-based prototypes. However, at this point they had a major setback: the new chief technology officer had heard that XML was slow and unreliable and dropped by to insist that everyone use HTML 5. The task force spokeswoman explained that they had ruled out that approach for cost reasons, and she explained why they needed to use custom schema-based validation for the articles from the authors. She showed the chief technology officer the prototype and the workflow diagrams the task force had prepared, and he grudgingly admitted they had some good ideas. However, he then bet twelve bottles of 25-year-old Highland Park single malt that they would not have a working system within a year!
CREATING A NEW PROCESS
Once the Hoy Books New System Task Force introduced their plan to their employees, created the necessary documents to facilitate the transformation, and started getting employees to test out the new concepts in simulated environments, it was time to start creating the real thing. The NSTF started by deciding what they wanted their XML system to look like and how they wanted the new work flow system to function. They considered the available technologies, preferring a standards-based approach where possible, performed a cost-benefit analysis and estimated the amount of work needed, built and tested small-scale prototypes, and finally deployed the system. This model is a great one to follow if you too are introducing and creating a new XML-based system in your company.
Challenging Criteria
The NSTF identified several difficult criteria the new system would have to include:
- The new system had to be easy for the authors. It had been difficult to get the authors to use styles in Microsoft Word, and a constant problem was articles arriving with ad-hoc styles in them, or with unusual formatting such as a poem in the middle of a place name. Such articles would sometimes be sent off to pieceworkers to be fixed by hand rather than trying to deal with the authors, so they wanted to keep using Microsoft Word, or use something that sounded as easy but that had stricter control over formatting.
- With more than 20,000 articles, each of which could be in any of a number of production states, the system had to provide tracking and summaries.
- Being able to check consistency between articles, especially for things like the spelling of proper names in cross references and titles, would not only improve quality but also save work and money. At least one duplicate article was written every year because of a difference in spelling.
- The system needed a full-text search that was aware of the different sorts of information in the articles, especially place names, people, and dates.
- The new system needed to be able to include diagrams and some simple mathematics.
- The new system would need to expand its production from print books to e-books in a variety of formats.
- A subscription-based website, something that had been too difficult for them to do with their older workflow, would be another great improvement to the system.
- The new amalgamation also meant incorporating heraldic information into the biographies, connecting different publications together.
The development team wrote this up in a document that they circulated not only to their management, but also to everyone who had been involved in the consultation process. They included a short summary as well as notes about how the interviews with outside writers and selected customers were taken into account, so that no-one would feel left out and become a potential barrier in the future. Based on all their needs and on the information they had discovered so far, the team proposed a new workflow, described next.
The New Workflow
The team selected an XML-based content management system this time round, so that they could get the benefits of validated markup, which include the following:
- Better quality control on the input
- Semantic markup that supports the searches and integrity checks they need
- Multiple output formats
- A website that could support a search function
- Formatting for print based on the validated markup, so there would be no need to develop unneeded styles
- Standard and open scripting and programming languages such as XSLT, XQuery, JavaScript, and PHP
- Editorial comment system based on W3C XForms
- Reports generated by XQuery and using SVG for charts
They even found an open source program to format heraldic crests as SVG so that they could be included in web pages and for e-books! Their experts in heraldry were also able to contribute graphics to the open source program for some of the more obscure items.
Document Conversion and Technologies
After the initial checklists were made and workflow determined, at Hoy Books, the next question was, “What should the XML look like?”
The team looked at existing standards and at inventing their own markup. In the end they decided on a hybrid: they would use markup from the Text Encoding Initiative (TEI) for the articles, because it already had the features they needed for transcriptions of old manuscripts for the more scholarly articles. They looked at DocBook, an industry standard maintained by the Oasis standards body, for the technical documentation. They also considered Oasis DITA, a more complex standard for documentation that comes with an information architecture methodology. In the end they settled on a subset of DocBook called Mallard, partly for simplicity and partly because it was used by the content-management system they chose.
After deciding what the XML should look like, Hoy Books needed to figure out how to deal with the twenty thousand main articles and many additional smaller articles, including how to categorize them, what format they needed to be in, and how to convert them into the desired format. When your core business asset is information, keeping your documents current sounds like a pretty important thing to do, but it’s often seen as an unwanted expense. You find publishers using decades-old word processors running on emulators of old operating systems to avoid training and conversion costs. Sometimes it’s because the profit margin is too low and sometimes it seems to be fear of the unknown! Hoy didn’t want to make this mistake with their articles.
The team did end up inventing their own RDF ontology to describe the various states of articles: requested from author, in process, received draft and awaiting edit, being copyedited, and so forth. Because their content management system used XQuery, they used an RDF XQuery module to produce editorial reports at first, but later moved to using SPARQL implemented in XQuery. The team was also able to use SPARQL to search the heraldry database that Hoy Books had bought, and to associate heraldic coats of arms and family crests with people in the Hoy’s Who books.
Once they had chosen the formats, the team was able to send data to a company in India that owned technology to convert Word files to XML. Because the Word files followed a rigid use of styles, the conversion ended up with very few problems and was inexpensive. An alternative suggested, made by a visiting consultant from Dublin they had, was to run XSLT on the Microsoft Word Office Open XML files, but most of the documents were in the proprietary binary format from older Word versions. It turned out that a few files would no longer open in recent versions of Word, but the conversion people in India had libraries that could recover the text and most of the styles.
The mathematics in the articles was another matter, and had to be re-keyed, but, luckily, that cost could be spread over several years, as and when the relatively few articles containing equations were needed.
Costs and Benefits Analysis
Most modern publishers need to produce electronic books in order to survive, and the market is no longer willing to accept just PDF images of printed pages: the pages must fit the width of the book reader. So the right question for the publisher (Hoy or any) is not “What’s the cheapest way to continue what we have been doing?” but rather, “How do we adapt to new technology without losing our reputation in the marketplace?”
With this view, the XML-based system is a sound investment. It supports the new technologies and is also adaptable to future technologies. In addition, publishing is a core strength of XML. The capability to pick data out of mixed content, such as fetching titles and dates of books that the biography subjects had written, and linking them to online copies of the books, is something that would likely have been considerably more expensive in a relational database system.
Deployment
When the NSTF was completely ready, they started implementing the new system with their entire company and the external authors. Most of the authors happily switched to using an XML editor; it was actually easier for them to concentrate on the content rather than the formatting. The team had expected one older writer in his late eighties, to whom they had given the nickname “the Old Man of Hoy,” to have problems, but, in fact, he loved the new system. They did lose one writer who took an early retirement rather than learn something new.
The formatter that Hoy Books chose was able to handle both SVG and MathML, and could produce high-quality PDF from XML input using W3C’s eXtensible Stylesheet Language Formatting Objects (XSL-FO) standard. Hoy Books hired a consultant for three months to set up the formatting, and although it was expensive because she came all the way from Dublin, the company actually saved more money than expected. The new system could produce PDF not only for print, but also for some of the older e-books.
The team spent a happy week in Oxford learning XSLT, and came back ready for the website challenge. They worked with their web design firm and soon had HTML 5 web pages. They used XQuery to generate XML summaries from their database, which were then formatted using XSLT for the Web.
The content management system used XProc, the XML Pipelining Language, to specify how the content for any given web page should be generated from the database, for example using XQuery to do a search or make an article summary, followed by running an XSLT transformation on the result of the query to turn it into HTML using the Hoy Books web template.
With the new production in place, Hoy Books could accept articles from the authors all the time, and because their new content-management system would keep track of the status of the articles for them, and because they didn’t have to convert the articles to the page layout program format any more, the staff had time to check the articles and keep the external authors paid. The new website had all of the articles available, and an unexpected benefit was that they were able to offer custom e-books to their users.
The end result was that time between an external author finishing an article and the article being available to the customers went from several weeks down to a few days, and, being much more responsive, the company was able to make better use of its assets to increase revenue. Therefore, the project was a success.
This project was fictional, of course, but it is based on real projects. Many of the world’s largest publishers (and some of the smallest) do use XML in the ways described in this chapter. Similar projects can also be found all over the world in documentation and engineering departments of large companies. In the next section of this chapter you read in more detail about some of the technologies that were mentioned here but that have not been covered in depth elsewhere in this book.
SOME TECHNICAL ASPECTS
The first part of this chapter mentioned a lot of technologies that were used in the example project at Hoy Books. The next part of this chapter is devoted to introducing you to some of those technologies in more detail, so that you can decide whether you need to learn more about them. Examples are included for some of the technologies but not for others — the decision on which to include was based on how much explanation you’d need for an example to make sense, not on the importance or usefulness of the technology. The tools that work in your situation are the most important for you, of course, and tens of thousands of XML vocabularies and tools are available! In some cases the technologies have been covered in more detail in earlier chapters, and are presented here to put them into a larger context of how they might be used.
XQuery and Modules
You learned about XQuery modules in Chapter 9. The team at Hoy Books used XQuery modules to make their own API; a set of XQuery functions for accessing both meta data and documents from the database. This enabled them to be flexible when they changed their RDF ontologies and XML Schemas from time to time, and kept the details hidden.
XInclude
XInclude is the W3C “XML Inclusions” specification. The Hoy Books XQuery module for reports generates XML elements with reference to some external XML documents that are included using an XInclude element like so:
<xi:include xmlns:xi=”http://www.w3.org/2001/XInclude”
href=”management-structure.html” />
An XInclude processor will replace the xi:include element with the document to which it refers. Of course, the URI could use the HTTP protocol, perhaps referring to a document generated by the database on the fly.
Equations and MathML
MathML is W3C’s XML vocabulary for representing equations. It has two subtypes: content and presentational. The content form uses markup that describes the meaning, whereas the presentational form describes the intended appearance. Because mathematics is open ended, and research mathematicians invent new symbols and notations constantly, you always have to use at least a little presentational markup. However, the content markup would suffice for school text books up to undergraduate level in most cases, and in some cases beyond that.
For Hoy Books, simple equations were usually enough: plenty of books and papers on science-related subjects have fragments of equations in their titles, and for historical notations the team at Hoy Books used a mixture of SVG and scanned images. Using MathML meant that they could generate e-books as well as print from the same source, and could also search on text included in the equations. Discovering that there was web browser support for MathML was the final piece in the puzzle that led them to move away from proprietary word-processing formats.
Although MathML is now incorporated into HTML 5, browser support has been slow to follow. Mozilla Firefox was first, and supports both content and presentational markup. You can use a JavaScript library from www.mathjax.org to support MathML on browsers such as Internet Explorer or Google Chrome, and XSLT style sheets are also available; see http://www.w3.org/Math/ for more details.
MathML also introduces literally hundreds of named symbols that can be used in HTML or XML documents via entity references. You can define additional symbols using SVG (see Chapter 18, “Scalable Vector Graphics (SVG)”), or you could use downloadable web fonts as described in Chapter 17, “XHTML and HTML 5.”
Listing 19-1 shows an example of an equation marked up in MathML, and Figure 19-1 shows the result in Firefox. The file shown in the browser also contains three additional equations whose markup is not included in the book, but the file on the accompanying website does include all four examples. The CSS in the example puts a dotted box around the equation.

![]() LISTING 19-1: mathml-in-html5.html
LISTING 19-1: mathml-in-html5.html
<!DOCTYPE html>
<html>
<head>
<title>MathML Examples</title>
<style type=”text/css”>
body {
color: #000;
background-color: #fff;
}
div.m {
float: left;
padding: 3em;
border: 1px dotted;
margin: 1em;
}
h2 {
text-size: 100%;
clear: both;
}
</style>
</head>
<body>
<h1>MathML Examples</h1>
<h2>Quadratic and Integral</h2>
<div class=”m”>
<math display=”block”>
<mrow>
<mi>x</mi>
<mo>=</mo>
<mfrac>
<mrow>
<mo form=”prefix”>−</mo>
<mi>b</mi>
<mo>±</mo>
<msqrt>
<msup>
<mi>b</mi>
<mn>2</mn>
</msup>
<mo>−</mo>
<mn>4</mn>
<mo>⁢</mo>
<mi>a</mi>
<mo>⁢</mo>
<mi>c</mi>
</msqrt>
</mrow>
<mrow>
<mn>2</mn>
<mo>⁢</mo>
<mi>a</mi>
</mrow>
</mfrac>
</mrow>
</math>
</div>
[. . .]
</body>
</html>
XProc: An XML Pipelining Language
The team at Hoy Books used a native XML database with XQuery to power their content-management system. To generate reports, they first extracted information from the database with XQuery and then ran XSLT to make a mixture of SVG and XHTML; in some cases this involved running more than one XSLT transformation. Remembering the steps for each report would be tedious. Utilities like ant or make could be used, or shell scripts or batch files, to automate the process, but XProc provides a clearer framework not tied to any one technology, and, being XML-based, was stored in the database, so it was a good fit for Hoy Books.
Listing 19-2 shows a sample pipeline that first extracts some data — perhaps a list of articles that are overdue from the authors, who of course are always late!
![]() LISTING 19-2: xproc.xml
LISTING 19-2: xproc.xml
<p:pipeline xmlns:p=”http://www.w3.org/ns/xproc” version=”1.0”> <!--∗ First run Query to get the data ∗--> <p:xquery> <p:input port=”query”> <p:data href=”reports/editorial-status.xq” /> </p:input> </p:xquery> <!--∗ The Query generates XML that can include some ∗ boilerplate text, so run XInclude next: ∗--> <p:xinclude/> <!--∗ Validate the result to make sure that we didn't ∗ make a mistake: ∗--> <p:validate-with-xml-schema> <p:input port=”schema”> <p:document href=”reports/editorial-status.xsd”/> </p:input> </p:validate-with-xml-schema> <!--∗ Generate SVG graphs of the data ∗--> <p:xslt> <p:input port=”stylesheet”> <p:document href=”reports/editorial-status-svg.xslt” /> </p:input> </p:xslt> <!--∗ Generate a report that can be viewed in a Web browser: ∗--> <p:xslt> <p:input port=”stylesheet”> <p:document href=”reports/editorial-html.xslt” /> </p:input> </p:xslt> </p:pipeline>
The XQuery (not shown) generates an XML document with the data, and also with XInclude elements that refer to some boilerplate documents for the reports. The pipeline explicitly includes an XProc xinclude step to handle this.
After the boilerplate text (the list of staff and their positions, in fact) is included, the resulting XML document is validated against a W3C XML Schema. This helps the developers know that everything worked as expected. The next step runs XSLT to turn the numeric data into SVG graphics, and then, finally, the XML document is turned into an HTML web page for viewing.
This modular approach can also be used for the printed books and for the website, of course, as well as for producing e-books.
See www.w3.org/TR/xproc/ for the latest XProc specification.
XForms, REST, and XQuery
The W3C XForms language provides a way for users to interact with a web page. It separates data using the model-view-controller system, avoiding unnecessary round trips to the server and reducing the need for scripting.
Hoy Books used XForms embedded within XHTML for an editorial comment interface; the form sends XML back to the content management system, which, being based on a native XML database powered by XQuery, can use it directly. You can learn more about Xforms at www.w3.org/MarkUp/Forms/.
REST, or REpresentational State Transfer, is a term coined by Roy Fielding to describe a way of using the World Wide Web. It describes how to write web applications, and although a detailed explanation is outside the scope of this book, you are strongly encouraged to read more about REST and “XRX” if you write applications that use XForms and XQuery. REST is the “R” that connects XForms and XQuery.
Formatting to PDF with XSL-FO
The W3C eXtensible Stylesheet Language Formatting Objects specification is a vocabulary for document formatting. It uses the idea of pouring a stream of content, called the flow, into a sequence of page templates. The elements in the flow are styled with CSS (and with some additional properties more suited to print work than CSS 2), and are positioned within the page templates by the formatting engine.
The XSL-FO specification assumes that you’re generating the input XML (in the FO vocabulary) using XSLT: you transform elements in your XML documents into formatting objects like <fo:block> and <fo:inline> with CSS style properties, and then run a formatter to make PDF or other output formats.
Listing 19-3 shows an XSLT style sheet that will convert either the tiny armstrong.xml file or the larger chalmers-biography-extract.xml file that you first saw in Chapter 9 into XSL-FO; you could then run a formatter such as the open source xmlroff or Apache FOP programs to make PDF. Hoy Books used a commercial XSL-FO formatter that also included MathML support. Figure 19-2 shows one page of a PDF document made by first running the XSLT stylesheet in Listing 19-3 on the chalmers-biography-extract.xml file and then taking the result of that and running it through the Apache FOP program.

![]() LISTING 19-3: make-xsl-fo.xsl
LISTING 19-3: make-xsl-fo.xsl
<?xml version=”1.0” encoding=”utf-8” ?>
<xsl:stylesheet version=”1.0”
xmlns:xsl=”http://www.w3.org/1999/XSL/Transform”
xmlns:fo=”http://www.w3.org/1999/XSL/Format”>
<xsl:strip-space elements=”dictionary entry body” />
<xsl:template match=”/”>
<fo:root font-family=”Times”
font-size=”10pt” line-height=”12pt”>
<fo:layout-master-set>
<fo:simple-page-master master-name=”dictpage”
page-width=”8.5in” page-height=”11in”
margin-top=”0.5in” margin-bottom=”0in”
margin-left=”1in” margin-right=”0.75in”>
<fo:region-body margin-bottom=”0.75in”
column-count=”2” column-gap=”0.5in” />
<fo:region-after extent=”0.5in” />
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference=”dictpage”>
<fo:static-content flow-name=”xsl-region-after”>
<fo:block text-align=”center”>Page <fo:page-number /></fo:block>
</fo:static-content>
<fo:flow flow-name=”xsl-region-body”>
<!--∗ generate the content here ∗-->
<xsl:apply-templates/>
</fo:flow>
</fo:page-sequence>
</fo:root>
</xsl:template>
<xsl:template match=”dictionary”><xsl:apply-templates/></xsl:template>
<xsl:template match=”entry”>
<fo:block text-indent=”-2em” margin-bottom=”12pt”>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match=”entry/title”>
<fo:inline font-style=”italic”>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match=”entry/body”><xsl:apply-templates/></xsl:template>
<xsl:template match=”p”>
<fo:block keep-together=”auto” text-indent=”1.5em”>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match=”body/p[1]”>
<fo:inline><xsl:apply-templates/></fo:inline>
</xsl:template>
<!--∗ note: the Apache Fop renderer does not support small caps ∗-->
<xsl:template match=”entry/title/csc”>
<fo:inline font-variant=”small-caps”>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match=”i”>
<fo:inline font-style=”italic”>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
</xsl:stylesheet>
XML Markup for Documentation
An undocumented project often becomes a problem when key people leave the company or change roles. The Hoy Books team knew this and documented not only the final system but also the decision process, so that people changing the system would understand not only how it worked but why.
They used Oasis DocBook as an XML format for their documentation, and some open source XSLT style sheets that converted DocBook documents into XHTML and PDF.
They could have used the same markup that was used for the dictionary entries, and although that was tempting, the needs were different. The biographical dictionary does not contain code listings or sequences of instructions, for example, but the documentation probably does.
Another format widely used for documentation is the Darwin Information Typing Architecture (DITA), also produced by Oasis. DITA is a framework for topic-based authoring, and is best suited for use when the end product is documentation. At the (fictional) Hoy Books company the end product is, of course, world-class biographical dictionaries, and the team felt that DITA was too much for them to take on to document their system.
Markup for the Humanities: TEI
The Text Encoding Initiative is a consortium that produces guidelines for markup of scholarly texts in XML. The Hoy Books team chose the TEI P5 guidelines because it met their needs for transcriptions of manuscripts, books, and articles, because work had already been done on biographical dictionaries, and because there was already support for the markup in existing tools and editors. The oXygen XML Editor you used in earlier chapters, for example, includes TEI support (as well as support for DocBook and DITA). The Text Encoding Initiative Guidelines (both P4 and P5) are by far the most widely used XML vocabularies in humanities computing.
You should choose markup that suits your own projects, so rather than read an example in this book you are referred to www.tei-c.org to learn more.
THE HOY BOOKS WEBSITE
For their website, the Hoy Books team used a copy of their XML database rather than the original, partly fearing that production might be affected in an attack, and partly so that the server could be located in nearby Scotland, where the Internet connections were stronger.
They used XSL-FO on the server so that users could download PDF versions of articles, and they used XQuery Full Text to provide searching. Their content management system could run XSLT using XProc, so the Hoy Books staff made some pipelines that added interactive SVG content to the dictionary entries.
They included heraldic shields using the open source “drawshield” program, SVG time lines showing when people in the articles were born and died, and marking other events such as publications of their woks. They also made a visualization showing clusters of people’s colleagues and likely acquaintances.
There was an RSS feed so people could see new or updated articles as they were published; this was made using XQuery to generate RDF on the fly, and the flexibility this gave them meant they could easily generate customized RSS feeds based on users’ searches.
Connections between the RDF meta data in the biography articles and the RDF for the heraldry information in the Halfdan Books database enabled automatic links from biographies to genealogies and to entries for family members, which was an unexpected benefit.
Most of the concepts here have already been illustrated in this book. To understand them in context, the following activity demonstrates generating an SVG visualization from documents in the database using both XQuery and XSLT.
java -cp saxon9he.jar net.sf.saxon.Query timelines.xq > timelines.xml
basex/7.1/bin/basex -w timelines.xq > timelines.xml
![]() LISTING 19-4: timelines.xq
LISTING 19-4: timelines.xq
xquery version “1.0”;
(: read dict. of biog. and extract timelines. :)
<timelines>{
for $e in doc(“chalmers-biography-extract.xml”)//entry
where $e[xs:integer(@born) gt 1250] and $e[@died]
return
<entry born=”{$e/@born}” died=”{$e/@died}” id=”{$e/@id}”>
{ normalize-space(string-join($e/title//text(), “”) }
</entry>
}</timelines>
<timelines> <entry born=”1616” died=”1664” id=”aagard-christian”>Aagard, Christian</entry> <entry born=”1572” died=”1641” id=”aarsens-francis”>Aarsens, Francis</entry> <entry born=”1648” died=”1718” id=”abeille-gaspar”>Abeille, Gaspar</entry> <entry born=”1676” died=”1763” id=”abel-gaspar”>Abel, Gaspar</entry> <entry born=”1603” died=”1691” id=”abelli-louis”>Abelli, Louis</entry> <entry born=”1589” died=”1655” id=”abraham-nicholas”>Abraham, Nicholas</entry> <entry born=”1428” died=”1478” id=”acciaioli-donato”>Acciaioli, Donato</entry> <entry born=”1418” died=”1483” id=”accolti-francis”>Accolti, Francis</entry> <entry born=”1455” died=”1532” id=”accolti-peter”>Accolti, Peter</entry> <entry born=”1696” died=”1772” id=”achard-anthony”>Achard, Anthony</entry> <entry born=”1556” died=”1621” id=”achen-john-van”>Achen, John Van</entry> </timelines>
timelines-short.xml
![]() LISTING 19-5: timelines.xsl
LISTING 19-5: timelines.xsl
<xsl:stylesheet version=”2.0”
xmlns:svg=”http://www.w3.org/2000/svg”
xmlns:xs=”http://www.w3.org/2001/XMLSchema”
xmlns:xsl=”http://www.w3.org/1999/XSL/Transform”>
<xsl:variable name=”itemwidth” select=”10” as=”xs:integer” />
<xsl:variable name=”height” select=”600” as=”xs:integer” />
<xsl:variable name=”labeloffset” select=”200” as=”xs:integer” />
<xsl:variable name=”lineoffset” select=”230” as=”xs:integer” />
<xsl:variable name=”earliest”
select=”min(for $y in //entry/@born return xs:integer($y))” />
<xsl:variable name=”latest”
select=”max(for $y in //entry/@died return xs:integer($y))” />
<xsl:variable name=”yscale”
select=”($height - 200) div ($latest - $earliest)” />
<xsl:template match=”timelines”>
<svg xmlns=”http://www.w3.org/2000/svg”
style=”font-size:10pt;background-color:white;color:black;”>
<xsl:apply-templates />
</svg>
</xsl:template>
<xsl:template match=”entry”>
<xsl:variable name=”x” select=”$itemwidth ∗ position()” />
<xsl:variable name=”y1”
select=”$lineoffset + (@born - $earliest) ∗ $yscale” />
<xsl:variable name=”y2”
select=”$lineoffset + (@died - $earliest) ∗ $yscale” />
<xsl:if test=”position() mod 5 eq 0”>
<svg:line x1=”{$x - $itemwidth div 2}” y1=”{$lineoffset}”
x2=”{$x - $itemwidth div 2}” y2=”{$height + 60}”
style=”stroke-width:1px;stroke:#CCCCCC;stroke-dasharray=2,2”/>
</xsl:if>
<svg:text x=”0” y=”0”
transform=”translate({$x}, {$labeloffset}) rotate(-60)”>
<xsl:apply-templates />
</svg:text>
<svg:line x1=”{$x}” y1=”{$y1}” x2=”{$x}” y2=”{$y2}”
style=”stroke-width:4pt;stroke:#CCCCCC” />
<svg:circle cx=”{$x}” cy=”{$y1}” r=”{$itemwidth idiv 3}”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000”
title=”born {@born}” />
<svg:circle cx=”{$x}” cy=”{$y2}”
r=”{$itemwidth idiv 3}”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000”
title=”died {@died}” />
</xsl:template>
</xsl:stylesheet> saxon timelines.xml timelines.xsl > timelines.svg
![]() LISTING 19-6: timelines.svg
LISTING 19-6: timelines.svg
<?xml version=”1.0” encoding=”UTF-8”?>
<svg xmlns:xs=”http://www.w3.org/2001/XMLSchema”
xmlns:svg=”http://www.w3.org/2000/svg” xmlns=”http://www.w3.org/2000/svg”
style=”font-size:10pt;background-color:white;color:black;”>
<svg:text x=”0” y=”0” transform=”translate(20, 200) rotate(-60)”>
Aagard, Christian</svg:text>
<svg:line x1=”20” y1=”453.728813559322” x2=”20” y2=”507.96610169491527”
style=”stroke-width:4pt;stroke:#CCCCCC”/>
<svg:circle cx=”20” cy=”453.728813559322” r=”3”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000” title=”born 1616”/>
<svg:circle cx=”20” cy=”507.96610169491527” r=”3”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000” title=”died 1664”/>
<svg:text x=”0” y=”0” transform=”translate(40, 200) rotate(-60)”> Aarsens,
Francis</svg:text> <svg:line x1=”40” y1=”404.01129943502826” x2=”40”
y2=”481.9774011299435” style=”stroke-width:4pt;stroke:#CCCCCC”/>
<svg:circle cx=”40” cy=”404.01129943502826” r=”3”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000” title=”born 1572”/>
<svg:circle cx=”40” cy=”481.9774011299435” r=”3”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000” title=”died 1641”/>
<svg:text x=”0” y=”0” transform=”translate(60, 200) rotate(-60)”> Abeille,
Gaspar</svg:text> <svg:line x1=”60” y1=”489.88700564971754” x2=”60”
y2=”568.9830508474577” style=”stroke-width:4pt;stroke:#CCCCCC”/>
<svg:circle cx=”60” cy=”489.88700564971754” r=”3”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000” title=”born 1648”/>
<svg:circle cx=”60” cy=”568.9830508474577” r=”3”
style=”fill:#CCCCCC;stroke-width:1pt;stroke:#000” title=”died 1718”/>
</svg> 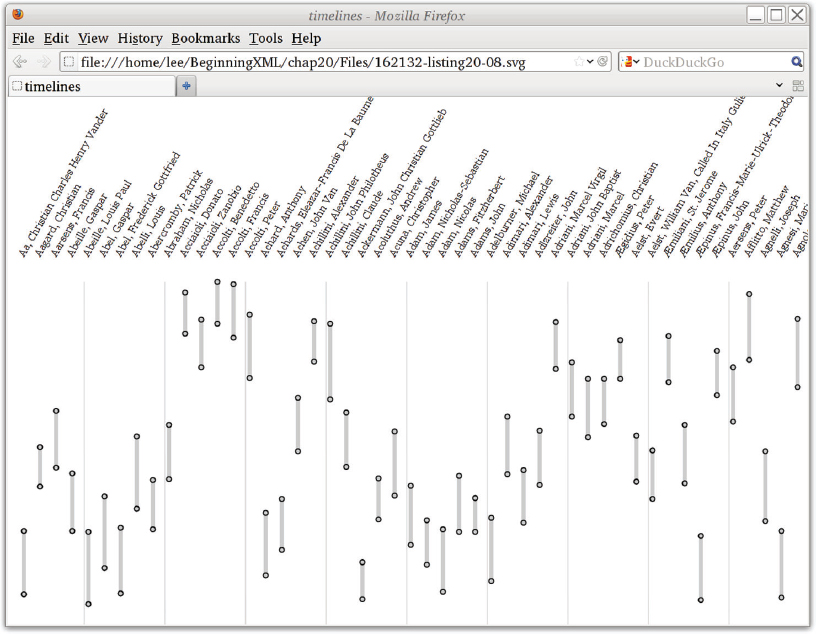
SUMMARY
- An organization can use XML technologies to reduce costs, have a faster turnaround, do its own typesetting in-house, produce e-books and a website from the same content, and generally became immersed in XML!
- A number of XML vocabularies and standards not covered in chapters of their own exist, including XSL-FO, XProc, and MathML.
- You can generate SVG by combining XQuery and XSLT.
Hoy Books has entered the Modern Era, and if some of its staff still keep sheep or sail out in fishing boats from time to time, it is a reminder that technology alone cannot replace people’s interests and needs. It’s time for you to go build, make and, on the way, enjoy XML.
EXERCISES
You can find possible solutions to these exercises in Appendix A.
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY POINTS |
| XML content management | XML-native databases can offer a cost-effective solution. XQuery, XSLT, XForms, and XHTML make a powerful combination. |
| XQuery and XSLT | Use XQuery to extract data from collections. Use XSLT when entire documents will be processed. |
| Markup vocabularies | DocBook is primarily for technical documentation of systems, or for technical books. DITA is especially suitable when the documents are the primary product of a department or organization. The Text Encoding Initiative Guidelines are designed primarily for humanities computing, including transcriptions and critical editions. |
| XSL-FO | XSL-FO is a W3C XML vocabulary for formatting; it uses (and extends) CSS for print. |