
Chapter 3
XML Namespaces
WHAT YOU WILL LEARN IN THIS CHAPTER:
- What namespaces are
- Why you need namespaces
- How to choose a namespace
- How to declare a namespace
- How to show that items are in a namespace
- The relationship between namespaces and XML Schema
- When to use namespaces
- Common uses of namespaces
This chapter covers the thorny topic of XML Namespaces, something that should be quite simple and straightforward but often seems to lead to confusion, even among experienced developers. This chapter starts by explaining what is meant by the term namespace and how it’s not limited to the world of XML. It then details when and why you would need them and shows the problems you can experience if they were not available. Then you delve into the implementation of namespaces, how they are declared in an XML document, and how you specify that an item resides in a particular namespace. You are then introduced to one of the main uses of namespaces, XML Schemas, which enable you to validate that a particular document conforms to a pre-determined structure. The final section lists some real-world examples of namespace usage that you are likely to encounter and gives a brief description of where and why they are used.
DEFINING NAMESPACES
At their simplest, namespaces are a way of grouping elements and attributes under a common heading in order to differentiate them from similarly-named items.
Take the following scenario: You overhear two people talking and one says to the other, “You need a new table.” What does that mean? There could be quite a number of options depending on the context. For example it could be:
- Someone discussing a dinner party with their spouse and they need a bigger dining table.
- A database developer who’s been asked to design a system to store user preferences on a website — a new database table.
- An HTML developer who has been told to display some extra information on the user’s account page — an HTML table.
You can tell only if you know the context, or if the complete names are used — dining table, database table, or HTML table.
This is how namespaces work with elements and attributes. You can group these items under a namespace so that they keep their familiar name, such as user, but also have a namespace so that they can be differentiated, both by a human reader and a software application, from any other elements that may be called user by someone else.
WHY DO YOU NEED NAMESPACES?
For a more concrete example on the need for namespaces, take the following scenario: You have details about your company employees stored as XML and you want to be able to include a brief biography in the form of some HTML within the document. Your basic document looks something like Listing 3-1.
![]() LISTING 3-1: employees-base.xml
LISTING 3-1: employees-base.xml
<employees>
<employee id=”001”>
<firstName>Joe</firstName>
<lastName>Fawcett</lastName>
<title>Mr</title>
<dateOfBirth>1962-11-19</dateOfBirth>
<dateOfHire>2005-12-05</dateOfHire>
<position>Head of Software Development</position>
<biography><!-- biography here --></biography>
</employee>
<!-- more employee elements can be added here-->
</employees>
This document doesn’t use namespaces, and it still works fine. Now say you want to add the biography and you’re going to use XHTML. This is the perfect opportunity to use namespaces, but first, take a look at a document, shown in Listing 3-2, that doesn’t declare any namespaces and which illustrates the problem:
![]() LISTING 3-2: employees-with-bio.xml
LISTING 3-2: employees-with-bio.xml
<employees>
<employee id=”001”>
<firstName>Joe</firstName>
<lastName>Fawcett</lastName>
<title>Mr</title>
<dateOfBirth>1962-11-19</dateOfBirth>
<dateOfHire>2005-12-05</dateOfHire>
<position>Head of Software Development</position>
<biography>
<html>
<head>
<title>Joe's Biography</title>
</head>
<body>
<p>After graduating from the University of Life
Joe moved into software development,
originally working with COBOL on mainframes in the 1980s.</p>
</body>
</html>
</biography>
</employee>
<!-- more employee elements -->
</employees>
Now without namespaces you have a clash — two <title> elements performing two distinct functions. One is for the employee’s salutation and the other is for the title of the biography. For a human reader this isn’t a problem; you can see from the type of data and the general context what each <title> element represents, but to a software program that isn’t the case. If asked to find the employee’s title, for example a report showing the title, first name, and last name, there could be a conflict because it can’t choose the correct title without further help.
The way to get around this is to group the two sets of information — the employee data and the biographical information — into two different namespaces. You can see the final document later in the chapter, complete with namespaces, after you learn the methods by which you declare them.
If you didn’t want to use namespaces, you could use a different element name for the employee’s title — salutation perhaps. Given that you designed the format of the basic XML and decided the names of the elements, you’re perfectly entitled to use this approach; however, the elements that you are using in the biography section are part of the XHTML standard and so you can’t arbitrarily go and change the <title> element to be called something different.
However, the main reason why you would typically need namespaces is because you won’t always be using your own XML formats entirely within your own systems. If you did that, you wouldn’t have to worry about elements getting mixed up simply because they had the same name; you could ensure that all your element and attribute names were unique across all your systems. In the real world, though, it’s not like that. One of XML’s main purposes is to share data across systems and organizations. So, although you probably will invent some XML formats that are only for internal use, will never need to be shared, and will never come into contact with other formats, at some stage you are going to need namespaces.
HOW DO YOU CHOOSE A NAMESPACE?
Chapter 1, “What is XML?” mentioned how namespaces were already heavily used in many programming languages such as C# and Java. In C# they are actually called namespaces whereas Java prefers the term packages. So an example from C# could be the Timer class. The .NET library contains three different timers, each under its own namespace:
- System.Windows.Forms.Timer: Fires an event at regular intervals on the main user interface thread on a form.
- System.Timers.Timer: Fires an event on a worker thread.
- System.Threading.Timer: Designed for use in multi-threaded situations.
How these timers actually differ is unimportant. The point is that they all have a similar base name, Timer, but all live in a different namespace, respectively System.Windows.Forms, System.Timers, and System.Threading. When you declare one of these in code, the correct one is called because the full namespace name is used; if you don’t declare the namespace correctly the compiler emits an error message saying that it can’t find the Timer class that you need.
For XML you need a similar system, a way to make sure that your elements and attributes have a unique name. XML Namespaces provide a simple solution; you can choose virtually any string of characters to make sure your element’s full name is unique. So you could choose your element to be user, as before, and decide that it is in the BeginningXMLFifthEdition namespace. However, that doesn’t guarantee that the full name will be unique; several authors contributed to this book and one could also choose that string as the namespace. To avoid this problem in the real world you have two ways to create a unique namespace: using URIs or URNs. That’s not to say people don’t use other formats, but if you want to follow the W3C recommendation you’ll stick with one of these.
URLs, URIs, and URNs
Before you begin to choose your namespace you need to understand the difference between URLs, URIs, and URNs.
A URL is a Uniform Resource Locator. It specifies the location of a resource, for example a web page, and how it can be retrieved. It has the following format:
[Scheme]://[Domain]:[Port]/[Path]?[QueryString]#[FragmentId]
The terms in square brackets are replaced by their actual values and the rest of the items other than Scheme and Domain are optional. So a typical web URL would be http://www.wrox.com/remtitle.cgi?isbn=0470114878.
The scheme is http, the domain is www.wrox.com, followed by the path and a querystring. This URL enables you to locate a resource, in this case a web page about the previous edition of this book, using the HTTP protocol. You can use many other schemes, such as FTP and HTTPS, but the main point about URLs is that they enable you to locate a resource, whether that is a web page, a file, or something else.
A URI, on the other hand, is a Uniform Resource Identifier; it can have the same format as a URL or it can be in the URN format, which you learn about next. It doesn’t have to point to anything tangible — it’s just a unique string that identifies something. All URLs are also URIs but the opposite is not necessarily true. You’ll see that when designing your first namespace, you end up with a unique identifier, but one that does not have a physical representation on the Internet.
URNs are slightly different again; the letters stand for Uniform Resource Name. A URN is a name that uniquely defines something. In the non-computing world analogies would be Social Security numbers and ISBNs. They both uniquely identify something — U.S. citizens and editions of books, respectively.
URNs take the following format:
urn:[namespace identifier]:[namespace specific string]
As before, the items in square brackets need to be replaced by actual values and the three-character prefix, urn, is not case-sensitive.
The namespace identifier is a string of characters such as isbn, which identifies how the namespace specific string should be interpreted. Namespace identifiers can be registered with the Internet Assigned Numbers Authority (IANA) if they are expected to be utilized by many different organizations. The latter part of the URN, the namespace specific string, identifies the actual thing within the category set by the identifier. An example of a URN using a registered scheme would be:
urn:isbn:9780470114872
This URN uniquely identifies the fourth edition of this book, but because it’s a URN, not a URL, it doesn’t tell you anything about how to retrieve either the book itself or any information about it.
So, in brief, URLs and URNs are both URIs; a URL tells you the how and where of something, and the URN is simply a unique name. Both URLs and URNs are used to create XML Namespace URIs, as you’ll see next.
Creating Your First Namespace
When creating your first namespace you should use the URI format. As stated earlier, the URI must be unique because you don’t want it to clash with someone else’s choice. Because most companies and independent software developers have their own registered domain, it’s become fairly standard to use their domain name as a starting point. So your namespace starts with http://wrox.com/. Following the domain name you can use most any combination of characters you want, although you should avoid spaces and the question mark. The definitive list of what is and isn’t allowed depends on whether you’re using XML Namespace version 1.0 or version 1.1 (see the note in the later section on declaring namespaces for more details).
Now for your user element, which in the example scenario came from an application configuration file that may have been used by your HR system, you might choose the full namespace: http://wrox.com/namespaces/applications/hr/config.
This actual string of characters chosen is known as the namespace URI. Namespaces are case-sensitive so try to be consistent when inventing them; sticking to all lowercase can save having to remember which letters were capitalized.
HOW TO DECLARE A NAMESPACE
You can declare a namespace in two ways, depending on whether you want all the elements in a document to be under the namespace or just a few specific elements to be under it. If you want all elements to be included, you can use the following style:
xmlns= “http://wrox.com/namespaces/applications/hr/config“
Therefore, if you take your appUsers.xml file from Chapter 1 you have what’s shown in Listing 3-3.
![]() LISTING 3-3: appUsers.xml
LISTING 3-3: appUsers.xml
<applicationUsers> <user firstName=”Joe” lastName=”Fawcett” /> <user firstName=”Danny” lastName=”Ayers” /> <user firstName=”Catherine” lastName=”Middleton” /> </applicationUsers>
To add the namespace declaration, change it to the code shown in Listing 3-4.
![]() LISTING 3-4: appUsersWithDefaultNamespace.xml
LISTING 3-4: appUsersWithDefaultNamespace.xml
<applicationUsers
xmlns=”http://wrox.com/namespaces/applications/hr/config”>
<user firstName=”Joe” lastName=”Fawcett” />
<user firstName=”Danny” lastName=”Ayers” />
<user firstName=”Catherine” lastName=”Middleton” />
</applicationUsers>
This is known as declaring a default namespace, which is associated with the element on which it is declared, in this case <applicationUsers>, and any element contained within it. The namespace is said to be in scope for all these elements. Attributes, such as firstName, are not covered by a default namespace.
Once an element has an associated namespace it no longer has a simple name such as user; the namespace has to be taken into account as well. There is no W3C standard for showing the element’s full name but there is a convention, called Clark notation (after James Clark, one of the founding fathers of XML) that can be used. The Clark notation places the namespace URI in curly braces before what is known as the local name. Using Clark notation, the user element would have the full name:
{http://wrox.com/namespaces/applications/hr/config}user
As mentioned previously, a default namespace applies only to elements. Attributes need their namespaces to be specifically declared, and other components of an XML document, such as comments, don’t have associated namespaces at all.
To declare a namespace explicitly you have to choose a prefix to represent it. This is partly because it would be very onerous having to use the full name every time you created a tag or an attribute. The prefix can be more or less whatever you like; it follows the same naming rules as an element or attribute, but cannot contain a colon (:).
Say you decide to use hr as your prefix. You would then declare your namespace using the slightly modified form:
xmlns:hr=“http://wrox.com/namespaces/applications/hr/config“
Note the hr prefix follows the xmlns in the declaration.
Listing 3-5 shows the full file, now including the namespace declaration that has a prefix of hr.
![]() LISTING 3-5: appUsersWithNamespace.xml
LISTING 3-5: appUsersWithNamespace.xml
<applicationUsers xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”>
<user firstName=”Joe” lastName=”Fawcett” />
<user firstName=”Danny” lastName=”Ayers” />
<user firstName=”Catherine” lastName=”Middleton” />
</applicationUsers>
However, this just means that you have a namespace URI that is identified by a prefix of hr; so far none of the elements or attributes are grouped in that namespace. To associate the elements with the namespace you have to add the prefix to the elements’ tags. For example, start by showing that the <applicationUsers> element resides in the http://wrox.com/namespaces/applications/hr/config namespace (referred to from now on as the hr namespace). The document would then look like Listing 3-6.
![]() LISTING 3-6: appUsersWithNamespaceUsedOnRoot.xml
LISTING 3-6: appUsersWithNamespaceUsedOnRoot.xml
<hr:applicationUsers xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”> <user firstName=”Joe” lastName=”Fawcett” /> <user firstName=”Danny” lastName=”Ayers” /> <user firstName=”Catherine” lastName=”Middleton” /> </hr:applicationUsers>
Notice that the prefix, hr, has been added to both the start and the end tags and is followed by a colon and then the element’s local name.
If you want the attributes in the document to be also in the hr namespace you follow a similar procedure as shown in Listing 3-7:
![]() LISTING 3-7: appUsersWithNamespaceUsedOnAttributes.xml
LISTING 3-7: appUsersWithNamespaceUsedOnAttributes.xml
<hr:applicationUsers xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”> <user hr:firstName=”Joe” hr:lastName=”Fawcett” /> <user hr:firstName=”Danny”hr:lastName=”Ayers” /> <user hr:firstName=”Catherine” hr:lastName=”Middleton” /> </hr:applicationUsers>
Again the namespace prefix is prepended to the attribute’s name and followed by a colon. In most XML documents that use namespaces you’ll see that it’s very common that elements belong to a particular namespace, but less so for attributes. The reason for this is that attributes are always associated with an element; they can’t stand alone. Therefore, if the element itself is in a namespace, the attribute is already uniquely identifiable and there’s really no need for it to be a namespace.
Remember that the namespace declaration must come either on the element that uses it or on one higher in the tree, an ancestor as it’s often called. This means that the file in Listing 3-8 is not well-formed because the declaration is too far down the tree and therefore not in scope.
![]() LISTING 3-8: appUsersWithIncorrectDeclaration.xml
LISTING 3-8: appUsersWithIncorrectDeclaration.xml
<hr:applicationUsers>
<user
xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”
firstName=”Joe” lastName=”Fawcett” />
<user firstName=”Danny” lastName=”Ayers” />
<user firstName=”Catherine” lastName=”Middleton” />
</hr:applicationUsers>
It isn’t necessary to declare all your namespaces on the root element, but it is common practice to do so (unless you have a good reason not to) and usually makes the document that much easier to read.
If your document uses only one namespace and all the elements in the document belong to it, there’s little to choose between using a default namespace and one with a defined prefix. As far as the XML parser is concerned there is no difference between the document in Listing 3-4, which used a default namespace declaration, and the one in Listing 3-9, which uses an explicit declaration with the prefix hr.
![]() LISTING 3-9: appUsersWithExplicitNamespaceUsedThroughout.xml
LISTING 3-9: appUsersWithExplicitNamespaceUsedThroughout.xml
<hr:applicationUsers xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”> <hr:user firstName=”Joe” lastName=”Fawcett” /> <hr:user firstName=”Danny” lastName=”Ayers” /> <hr:user firstName=”Catherine” lastName=”Middleton” /> </hr:applicationUsers>
Notice how the declaration is made on the root element and all start and end tags have the hr prefix. This is a typical example of how a document with an explicitly-defined namespace looks and many of the documents you will encounter in real life follow this pattern.
How Exactly Does Scope Work?
The principle of being in scope applies to any namespaces declared in an XML document and it’s important to clearly understand this concept. In scope means the same for XML Namespaces as it does in more traditional programming settings — the namespace is available to be used. Just because a namespace is in scope doesn’t mean that an element belongs to it. Take Listing 3-10, which takes the current example and modifies it slightly, moving the declaration from the <applicationUsers> element.
![]() LISTING 3-10: appUsersWithNarrowScopeDeclaration.xml
LISTING 3-10: appUsersWithNarrowScopeDeclaration.xml
<applicationUsers>
<hr:user xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”
firstName=”Joe” lastName=”Fawcett” />
<user firstName=”Danny” lastName=”Ayers” />
<user firstName=”Catherine” lastName=”Middleton” />
</applicationUsers>
Now the namespace declaration is on the first <user> element. It is only in scope for that element, its attributes, and any elements it contains (in this case there aren’t any). Because of this the namespace cannot be used on either the <applicationUsers> element or any of the other <user> elements — trying to assign a prefix to these elements would lead to an error when parsing the XML. It is usually considered good practice when designing an XML document to limit the scope of any namespace declarations by declaring them at as low a level as possible in the document, as long as you still only have to declare them once. This maintains standard programming practice in other languages, where it is frowned on to declare all variables as global and better to declare them only when they are needed and therefore limit their scope.
Declaring More Than One Namespace
Many documents use more than one namespace to group their elements. Typically, you have a number of choices when you need to design XML in this fashion. One option is to choose a default namespace for some elements and an explicit one for others. You can stick with the example document but you need to incorporate a few changes:
![]() LISTING 3-11: appUsersWithTwoNamespaces.xml
LISTING 3-11: appUsersWithTwoNamespaces.xml
<applicationUsers
xmlns=”http://wrox.com/namespaces/applications/hr/config”
xmlns:ent=”http://wrox.com/namespaces/general/entities”>
<ent:user firstName=”Joe” lastName=”Fawcett” />
<ent:user firstName=”Danny” lastName=”Ayers” />
<ent:user firstName=”Catherine” lastName=”Middleton” />
</applicationUsers>
Because both declarations are on the root element they are in scope for the whole of the document. Therefore any elements without a prefix fall into the hr namespace and any with an ent prefix fall into the entities namespace. None of the attributes in this document are in a namespace. If you wanted you could just as easily have declared the entities namespace as the default and used the hr prefix for the other one; in real life you would probably choose the default for the namespace that was most used.
Alternatively, if you want to avoid a default namespace because you think it makes which element is grouped under which namespace clearer, you could make both namespace declarations explicit as shown in Listing 3-12.
![]() LISTING 3-12: appUsersWithTwoExplicitNamespaces.xml
LISTING 3-12: appUsersWithTwoExplicitNamespaces.xml
<hr:applicationUsers
xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”
xmlns:ent=”http://wrox.com/namespaces/general/entities”>
<ent:user firstName=”Joe” lastName=”Fawcett” />
<ent:user firstName=”Danny” lastName=”Ayers” />
<ent:user firstName=”Catherine” lastName=”Middleton” />
</hr:applicationUsers>
However, there is a third option to consider when dealing with multiple namespaces that occurs less commonly: declaring a namespace twice with different prefixes, as shown in Listing 3-13.
![]() LISTING 3-13: appUsersWithNamespaceDeclaredTwice.xml
LISTING 3-13: appUsersWithNamespaceDeclaredTwice.xml
<hr1:applicationUsers xmlns:hr1=”http://wrox.com/namespaces/applications/hr/config” xmlns:hr2=”http://wrox.com/namespaces/applications/hr/config”> <hr2:user firstName=”Joe” lastName=”Fawcett” /> <hr2:user firstName=”Danny” lastName=”Ayers” /> <hr2:user firstName=”Catherine” lastName=”Middleton” /> </hr1:applicationUsers>
Notice how both prefixes, hr1 and hr2, point to the same namespace URI. The document element, <applicationUsers>, uses the hr1 prefix whereas the other elements use hr2. It’s not something you’re likely to need but you do occasionally come across it when two different applications have had a part in creating an XML file and the prefixes were chosen independently.
What you can’t have, though, is the same prefix pointing to different namespace URIs, as shown in Listing 3-14.
![]() LISTING 3-14: appUsersWithPrefixedMappedTwiceIllegally.xml
LISTING 3-14: appUsersWithPrefixedMappedTwiceIllegally.xml
<hr:applicationUsers xmlns:hr=”http://wrox.com/namespaces/applications/hr/config” xmlns:hr=”http://wrox.com/namespaces/general/entities”> <hr:user firstName=”Joe” lastName=”Fawcett” /> <hr:user firstName=”Danny” lastName=”Ayers” /> <hr:user firstName=”Catherine” lastName=”Middleton” /> </hr:applicationUsers>
In this example, the parser can’t tell which namespace URI to use when it encounters the hr prefix, so the XML is not well-formed or, to use the full technical terminology, it’s not namespace–well-formed.
Changing a Namespace Declaration
Although it’s not something that you would want to do regularly, there are a few instances in which you would want to change a namespace declaration; this is most likely when a document has been created from components coming from different sources. You can do this in one of three ways:
- Change the mapping between a prefix and a namespace URI
- Change the default namespace
- Remove a namespace from scope by undeclaring it
First, take an example of changing the mapping between a prefix and its namespace URI. In a realistic scenario, you need an XML document with at least two levels of nesting, shown in Listing 3-15.
![]() LISTING 3-15: ChangingNamespaceBindings.xml
LISTING 3-15: ChangingNamespaceBindings.xml
<hr:config xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”>
<hr:applicationUsers xmlns:hr=”http://wrox.com/namespaces/general/entities”>
<hr:user firstName=”Joe” lastName=”Fawcett” />
<hr:user firstName=”Danny” lastName=”Ayers” />
<hr:user firstName=”Catherine” lastName=”Middleton” />
</hr:applicationUsers>
</hr:config>
This is not a good practice, so this example is a little contrived, but it shows the namespace declaration on the <config> element being mapped to the hr prefix and then, on the <applicationUsers> element, a different namespace URI is mapped to the same prefix. Although this is confusing, it can happen when you receive different parts of an XML file from separate sources. There are certainly no benefits to using this technique unless it’s absolutely necessary and, although a software application should have no trouble reading the document, it makes human consumption difficult.
You can also use this technique to change the document’s default namespace as shown in Listing 3-16.
![]() LISTING 3-16: ChangingDefaultNamespaceBindings.xml
LISTING 3-16: ChangingDefaultNamespaceBindings.xml
<config xmlns=”http://wrox.com/namespaces/applications/hr/config”>
<applicationUsers xmlns=”http://wrox.com/namespaces/general/entities”>
<user firstName=”Joe” lastName=”Fawcett” />
<user firstName=”Danny” lastName=”Ayers” />
<user firstName=”Catherine” lastName=”Middleton” />
</applicationUsers>
</config>
Now the <config> element is in the http://wrox.com/namespaces/applications/hr/config namespace but the other elements contained within it are in the http://wrox.com/namespaces/general/entities one. Again, this is not something you’d strive for yourself but it’s a scenario that might occur in files you receive from others. For example you may have two documents that both use a default namespace but you need to embed one inside the other. As you know, an application can cope with reading this sort of hybrid document but if you also want humans to edit it, using more than one default namespace is definitely something to avoid.
A slightly different scenario occurs when you want to undeclare a namespace mapping completely. Whether you can do this depends on if it’s a default mapping and which version of the XML Namespaces recommendation you are using. The default mapping can be undeclared in all versions (currently there are versions 1.0 and 1.1) and you just need to use an empty namespace URI as shown in Listing 3-17.
![]() LISTING 3-17: UndeclaringTheDefaultNamespaceMapping.xml
LISTING 3-17: UndeclaringTheDefaultNamespaceMapping.xml
<config xmlns=”http://wrox.com/namespaces/applications/hr/config”>
<applicationUsers xmlns=””>
<user firstName=”Joe” lastName=”Fawcett” />
<user firstName=”Danny” lastName=”Ayers” />
<user firstName=”Catherine” lastName=”Middleton” />
</applicationUsers>
</config>
In this variation the <config> element is in the http://wrox.com/namespaces/applications/hr/config namespace, but the other elements are not in any namespace (otherwise known as being in the empty or null namespace). This is because the xmlns=”” on the <applicationUsers> element undeclares the namespace mapping.
If you want to do a similar operation when using an explicit namespace — one with a prefix defined — you need to specify that you’re using version 1.1 in the XML declaration. This means that you need to check that the XML parser you’re intending to use supports this newer version. Most of the big names do, although Microsoft’s .NET parser doesn’t and many other lesser-known ones don’t either. Listing 3-18 shows an XML document that declares the correct version and then maps and unmaps a namespace to a prefix.
![]() LISTING 3-18: UndeclaringAPrefixedNamespaceMapping.xml
LISTING 3-18: UndeclaringAPrefixedNamespaceMapping.xml
<?xml version=”1.1” ?>
<hr:config xmlns:hr=”http://wrox.com/namespaces/applications/hr/config”>
<applicationUsers xmlns:hr=≫≫>
<user firstName=≫Joe≫ lastName=≫Fawcett≫ />
<user firstName=≫Danny≫ lastName=≫Ayers≫ />
<user firstName=≫Catherine≫ lastName=≫Middleton≫ />
</applicationUsers>
</hr:config>
Here the hr prefix is mapped to a namespace URI on the <config> element and then unmapped on the <applicationUsers> element. This means that it would be illegal to try to use the prefix from this point. Note that for this to be legal syntax you must declare that you’re using version 1.1 as shown on the first line of the listing.
Returning to the XML file showing the employee data example from earlier, you can see how you separate the two sets of information using namespaces. You use an explicit declaration for the basic employee data and a default declaration for the biographical data that uses elements from the XHTML namespace, as shown in Listing 3-19:
![]() LISTING 3-19: employees.xml
LISTING 3-19: employees.xml
<emp:employees xmlns:emp=”http://wrox.com/namespaces/general/employee”> <emp:employee id=”001”> <emp:firstName>Joe</emp:firstName> <emp:lastName>Fawcett</emp:lastName> <emp:title>Mr</emp:title> <emp:dateOfBirth>1962-11-19</emp:dateOfBirth> <emp:dateOfHire>2005-12-05</emp:dateOfHire> <emp:position>Head of Software Development</emp:position> <emp:biography> <html xmlns=”http://www.w3.org/1999/xhtml”> <head> <title>Joe's Biography</title> </head> <body> <p>After graduating from the University of Life Joe moved into software development, originally working with COBOL on mainframes in the 1980s.</p> </body> </html> </emp:biography> </emp:employee> <!-- more employee elements can be added here --> </emp:employees>
The first declaration is on the <emp:employees> element, so it is in scope for the whole document. The second declaration is on the <html> element, so it applies only to this element and those contained within it. Now any software processing this document can easily differentiate between the two <title> elements because one has the full name of:
{ http://wrox.com/namespaces/general/employee}title
And the other has:
{ http://www.w3.org/1999/xhtml}title
Thus far you have learned the following important concepts about namespaces:
- Their main purpose is to group elements and to differentiate an element from others with a similar name.
- You can choose any string of characters for the namespace URI, although it’s common practice to start it with your domain name.
- You can choose between a default namespace, where all elements are included automatically, or a prefixed namespace declaration, where you need to add the prefix to the start and end tags of any elements you wish to include.
- Your prefix can be more or less what you want, with the exception of being unable to use colons; it makes sense to use a short, simple character string.
The next section will introduce you to a number of real-world applications that make use of namespaces.
NAMESPACE USAGE IN THE REAL WORLD
You will most likely encounter namespaces whenever you use XML that has been designed for mass consumption rather than for just one application. Although the primary reason to use namespaces is still to group elements that are used together and to differentiate them from others with the same name, there are other common uses as well. These include the following:
- XML Schemas: Defining the structure of a document.
- Combination documents: Merging documents from more than one source.
- Versioning: Differentiating between different versions of an XML format.
This section shows some common uses of namespaces in some real-life situations, starting with XML Schema.
XML Schema
XML Schema gets a whole chapter to itself later in this book so this section just gives a quick overview of the basics and how namespaces are used within this branch of XML.
The basic idea behind XML Schemas is that they describe the legitimate format that an XML document can take. This goes beyond being well-formed, which is discussed in Chapter 2, and moves on to exactly which elements and attributes are allowed where, and what sort of content these items can contain. For example, an attribute of creationDate on an element of <logEntry> would normally be expected to contain a date or possibly a date and time. The schema associated with this document would detail that requirement. Besides the date and time data types there are a host of others such as decimal, string, and Boolean.
XML Schema works by assigning the format and content type based on namespaces; any rules target a single given namespace. If your XML format deals with elements from different namespaces, you need to create a schema for each one and then merge these together using techniques you learn in Chapter 5.
Given that the XML Schema recommendation has already declared a broad range of types dealing with numbers, text, dates, and times, it’s handy to be able to use these types in other documents, not just when you’re describing the content of elements and attributes. For example, XSLT, which is described in Chapter 8, was primarily designed to convert one XML format into another. It has the facility to create functions to help in this matter and these functions need a way to specify their return type, as is common in most programming languages. Rather than reinvent the wheel and come out with another long list of types that may be returned, XSLT can use the same types as XML Schema. You simply have to declare the XML Schema namespace, which is http://www.w3.org/2001/XMLSchema, and assign a prefix such as xs in your XSLT document. You can then declare that your function returns an xs:string or an xs:boolean, for example. You see some full examples of this in Chapter 8, which covers XSLT in depth.
Documents with Multiple Namespaces
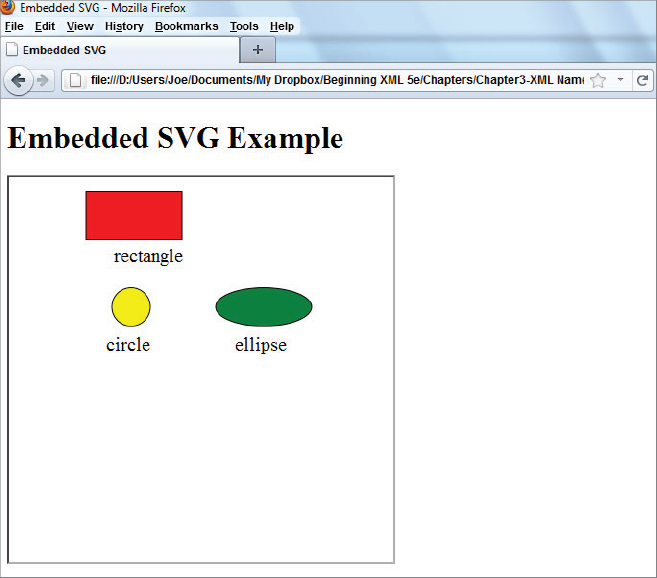
Another common example of needing a document with more than one namespace is when you want to embed XML into a web page. For example, Scalable Vector Graphics (SVG) provides for a standardized XML representation of graphics. The advantages of being able to describe these as XML are that any manipulation of them, such as stretching or changing the colors or rotation, is now a relatively simple process of transforming the XML rather than processor-hungry manipulation of bitmaps. You can use SVG from within a web page but you need to be careful to make sure the browser knows which part is to be rendered as traditional HTML and which part needs to be processed by the SVG plug-in. You do this by creating different namespaces for the two distinct parts of the document. The following Try It Out takes you through the process of creating a simple web page and then adding extra content, in the form of SVG. It shows how the browser needs this extra content defined in the SVG namespace so that it can choose which plug-in parses the XML and renders it as an image.
 <!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml” >
<head>
<title>Embedded SVG</title>
</head>
<body>
<h1>Embedded SVG Example</h1>
<!-- SVG will go here -->
</body>
</html>
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml” >
<head>
<title>Embedded SVG</title>
</head>
<body>
<h1>Embedded SVG Example</h1>
<!-- SVG will go here -->
</body>
</html>EmbeddedSVG.htm
<?xml version=”1.0” encoding=”utf-8” standalone=”no”?> <!DOCTYPE svg PUBLIC “-//W3C//DTD SVG 1.0//EN” “http://www.w3.org/TR/SVG/DTD/svg10.dtd”> <svg viewBox=”0 0 270 400” width=”100%” height=”100%” xmlns=”http://www.w3.org/2000/svg”> <!-- body of svg document --> </svg>
<g id=”mainlayer”>
<rect fill=”red” stroke=”black” x=”15” y=”15” width=”100” height=”50”/>
<circle fill=”yellow” stroke=”black” cx=”62” cy=”135” r=”20”/>
<ellipse fill=”green” stroke=”black” cx=”200” cy=”135” rx=”50” ry=”20”/>
<!-- shape descriptions -->
</g><g font-size=”20px”>
<text x=”44” y=”88”>rectangle</text>
<text x=”36” y=”180”>circle</text>
<text x=”170” y=”180”>ellipse</text>
</g> <?xml version=”1.0” encoding=”utf-8” standalone=”no”?>
<!DOCTYPE svg PUBLIC “-//W3C//DTD SVG 1.0//EN”
“http://www.w3.org/TR/SVG/DTD/svg10.dtd”>
<svg viewBox=”0 0 270 400” width=”100%” height=”100%”
xmlns=”http://www.w3.org/2000/svg”>
<g id=”mainlayer”>
<rect fill=”red” stroke=”black” x=”15” y=”15” width=”100” height=”50”/>
<circle fill=”yellow” stroke=”black” cx=”62” cy=”135” r=”20”/>
<ellipse fill=”green” stroke=”black” cx=”200” cy=”135” rx=”50” ry=”20”/>
<g font-size=”20px”>
<text x=”44” y=”88”>rectangle</text>
<text x=”36” y=”180”>circle</text>
<text x=”170” y=”180”>ellipse</text>
</g>
</g>
</svg >
Shapes.svg
- Use an <embed> element. This works in most browsers but isn’t part of strict XHTML.
- Use an <object> element. This works in Firefox and Chrome but can be problematic in Internet Explorer.
- Use an <iframe> element. Probably the simplest technique and one that you’ll use here. It works in all browsers capable of displaying SVG.
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<title>Embedded SVG</title>
</head>
<body>
<h1>
Embedded SVG Example</h1>
<iframe src=”shapes.svg” width=”400” height=”400”></iframe>
</body>
</html>
WHEN TO USE AND NOT USE NAMESPACES
When designing an XML format for some data that doesn’t already possess a standard representation, you should consider carefully whether or not the document should use a namespace. Although there are a number of good reasons to use one there are also scenarios where a namespace will only add to the work involved in designing and utilizing your XML. In general the case normally favors using a namespace, and the extra work involved is usually offset by the flexibility achieved as well as future-proofing your design; it’s almost impossible to tell for example, when designing data formats, how long they will remain in existence and how they will be used in situations other than the ones which initially warranted their creation. For a concrete example of this, cast your mind back to the Millennium Bug. Masses of software rewriting was caused by developers in the 1970s not appreciating that the chosen date format using just two digits for the year limited their work to a twenty to thirty year life span. The next two sections cover common situations for when you should use namespaces and when you shouldn’t.
When Namespaces are Needed
You’ve seen the main reason for using namespaces: to differentiate between elements that have the same name. This is one of the main reasons for using namespaces in your documents. The other reasons to do so are discussed in this section. Once you have got the hang of XML Namespaces you’ll naturally assume that documents generally use them, and it’s certainly unusual to find XML made for consumption by more than one client to not have any.
When There’s No Choice
The first situation is the easiest; sometimes you have no choice in the matter. For example, if you choose to use a format designed by someone else to represent your data, the chances are that the format insists on the elements being in a namespace. If you decide to change this and just use the prescribed format but without namespaces, you’ll find three things:
- You won’t be able to validate whether the documents you create are in the correct format because, as was pointed out earlier, any XML Schema that describes the document’s format will be targeting items in the relevant namespace.
- You won’t be able to share these documents outside your own systems; others will expect the namespaced version.
- Your system won’t accept documents from external sources because these will be namespaced.
If you decide that a previously-developed format suits your data, you should adopt it completely and not try to change it. This will leave you capable of using standard tools designed to work with that format and increase the chances of interoperability.
When You Need Interoperability
If you decide that an XML format is the best way to represent your data, your next question may well be, “Do I need to share this data with other systems, particularly those not developed externally?”
If the answer to this question is yes, you should probably group your elements under a namespace. Even if, in your local systems the document will always stand alone and there’s no danger of a clash of element names, you can’t tell how other systems will use this information. They may well need to embed your XML into a larger document and need the namespaces to differentiate your data from the complete structure.
When You Need Validation
Validation is covered in the next two chapters, but earlier you saw that XML Schemas provide a way to dictate the structure of an XML document and which content types the elements and attributes can contain. Although it’s possible to have a schema that works without using namespaces it’s quite rare and can cause problems when document collation is needed. So if you want to be able validate your document, it needs to use namespaces.
When Namespaces Are Not Needed
The main case for avoiding namespaces is when you have the need to store or exchange data for relatively small documents that will be seen only by a limited number of systems, ideally those developed internally by yourself or others in your organization.
A typical example of this situation might be when a web page needs to retrieve snippets of data from a web service using Ajax. If you have a page that accepts two numeric values and two currency descriptors that are used to convert from one denomination to another, you might be expecting a response that looks something like:
<conversion amount= “100” from= “USD” to= “GBP”>60.86</conversion>
In this case the response is so small and the chance of the service being used externally is so low that it doesn’t make sense to add the complexity of namespaces.
Versioning and Namespaces
One way in that people have used namespaces in the past is to differentiate between various versions of their formats. For example, if you go back to the employees.xml file from earlier, you used a namespace of http://wrox.com/namespaces/general/employee. Suppose you come out with a newer version of the format — you may decide to change it to http://wrox.com/namespaces/general/employee/v2. Superficially this seems like a good idea because the two formats will probably only differ slightly; there may be some extra elements and attributes in the later version but the general structure is likely to be similar. In practice, though, it rarely is.
The reason for this becomes clear when you ask the question, “How do I want the application to handle the two different versions?” There are four different scenarios:
- Version one of the application opens a version one file.
- Version one of the application opens a version two file.
- Version two of the application opens a version one file.
- Version two of the application opens a version two file.
The first and the last cases are easy, but the other two need some thought. If version one of the software opens a version two file, would you expect it to be able to read it or not? Will it just ignore any elements it does not recognize and process the rest as normal, or just reject the file out of hand? A similar issue applies in the third case. Should the version two system recognize an earlier XML version and just add some defaults for any missing values, or should it just announce that the file is not the correct format?
If you’re happy for the applications to reject a mismatching file, you can safely use different namespaces for each version. It won’t matter because, for all intents and purposes, to the version two application a version one file may as well be a random XML document such as an XHTML page; it’s just not going to read it. If, however, you want the applications to be able to cope with both the earlier and the later formats it’s important that the two namespaces are the same. If this isn’t the case, the systems would need to know the namespaces of all possible future XML formats that could be accepted. This isn’t very practical; in fact, the best way to cope with versioning is to have something like a separate attribute on the file, something like this:
<emp:employees xmlns:emp=”http://wrox.com/namespaces/general/employee” version=”1.0”> <!-- rest of data --> </emp:employee>
As stated earlier, more experienced XML developers tend to veer towards using namespaces in their documents as opposed to using their own formats, but ultimately the choice is up to you. And this choice isn’t set in stone by any means. There are plenty of public data formats that began by not using namespaces in earlier versions but changed to using them in subsequent designs. There are also examples that show the opposite — documents that originally used a namespace but then decided that it wasn’t needed and reverted to a simpler format. Now that you’ve seen the pros and cons regarding using namespaces in your own documents you should be in a better position to make your own decision. Next you look at some common namespaces used in XML documents.
COMMON NAMESPACES
Hundreds, possibly thousands, of namespaces are accepted as standard for different XML formats. However, you will likely find yourself using many of the same ones over and over. This section just discusses some of the most common namespaces you’ll encounter if your systems accept documents from external sources.
The XML Namespace
The XML Namespace is a special case. The prefix xml is bound to the URI http://www.w3.org/XML/1998/namespace and this is hard-coded into all XML parsers so you don’t need to declare it yourself. This means that you can use various special attributes in your XML document, such as xml:lang, which is used to denote which natural language an element’s content is in. For example, you may want to store phrases in multiple languages, as shown in Listing 3-20.
![]() LISTING 3-20: UsingXmlLangAttribute.xml
LISTING 3-20: UsingXmlLangAttribute.xml
<phrases>
<phrase id=”1”>
<text xml:lang=”en-gb”>Please choose a colour</text>
<text xml:lang=”en-us”>Please choose a color</text>
<text xml:lang=”es-es”>Por favor, elija un color</text>
</phrase>
<phrase id=”2”>
<text xml:lang=”en-gb”>How large is your organisation?</text>
<text xml:lang=”en-us”>>How large is your organization?</text>
<text xml:lang=”es-es”>¿Qué tan grande es su organización?</text>
</phrase>
</phrases>
Here the translations can be found by using a combination of the id attribute and the contents of xml:lang, which uses the first two letters for the language and the second two for the region where it’s spoken. So you have each phrase in British English, U.S. English, and Spanish as spoken in Spain. Of course, you could just use your own attribute, such as lang, but using the standard one means that you’ll get alerted if you choose an invalid language-region combination such as en-fr because there’s no official version of English particular to France.
The other attributes and identifiers you might encounter that are in the XML Namespace are:
- xml:space: You met this in Chapter 2. It is used so the author of the document can specify whether whitespace is significant or not. It takes the values preserve or default.
- xml:base: This is used in a similar way to the base attribute in HTML. It enables you to specify a base URL from which any relative URLs in the document will be resolved.
- xml:id: This specifies that the value of this attribute is a unique identifier within the document.
- xml:Father: Although rarely seen in practice, its existence proves that the W3C’s XML committee is actually human. It refers to Jon Bosak, a leading light in the XML community who chaired the original XML working group. It could be used, for example, when specifying a document’s author such as <document author=”xml:Father” />.
There’s no reason for you to declare the XML Namespace but you can if want to; what you must not do is either try to bind the xml prefix to another URI or undeclare it — that would lead to the parser throwing an error.
The XMLNS Namespace
As you’ve seen throughout this chapter the xmlns prefix is used to declare a prefixed namespace in an XML document. Again it is hard-coded into parsers and is bound to the URI http://www.w3.org/2000/xmlns/. Trying to declare it yourself, or trying to bind it to another URI, is an error. This makes sense because how would you do this anyway? You need the xmlns prefix itself to declare or undeclare so you’re creating an infinite loop if you try to bind it yourself.
The XML Schema Namespace
This namespace, with a URI of http://www.w3.org/2001/XMLSchema, is used in schema documents describing the legitimate structure of a particular XML format. As mentioned earlier, the data types in this namespace, such as decimal, string, and Boolean, are often used by other schemas instead of having to re-invent the list themselves. They are usually bound to the prefix xs or xsd but that’s purely a personal choice. With the exception of the xml and xmlns you can choose whatever prefix you like when binding a namespace. So it is perfectly acceptable if you want a document that looks like the following:
<myVeryLongPrefix:schema xmlns:myVeryLongPrefix=”http://www.w3.org/2001/XMLSchema”> <!-- rest of document here --> </myVeryLongPrefix:schema>
The XSLT Namespace
XSLT, covered in Chapter 8, is primarily used to convert XML into a different format, either a differently-formatted XML or perhaps HTML or just plain text. Because XSLT is XML itself, it’s essential that its elements are in a namespace; otherwise it would be impossible to tell which parts of the document are instructions for processing and which are new elements to be output. All but the most trivial XSLT documents, therefore, have elements in multiple namespaces. The XSLT Namespace URI is http://www.w3.org/1999/XSL/Transform and is most commonly bound to the xsl or xslt prefix.
The SOAP Namespaces
SOAP is covered in depth in Chapters 15 and 16. It’s an XML format designed to enable method calls between a client and a web service. There are two namespaces depending on which version you use (presumably, as discussed in the section on versioning using namespaces, the authors of the specifications didn’t want interoperability between the two formats). The original namespace URI for SOAP 1.1 is http://schemas.xmlsoap.org/soap/envelope/ and is usually bound to the prefix soap. The later one, for version 1.2, is http://www.w3.org/2003/05/soap-envelope, which is commonly bound to the prefix soap12. The SOAP namespace contains such elements as <soap:Envelope>, which wraps the entire message; <soap:Header>, which contains details such as user credentials; and <soap:Body>, which contains the method being called and its arguments.
The WSDL Namespace
The Web Services Description Language (WSDL) is used to describe a web service in such a way that clients can programmatically connect to a server, know what methods are available, and format their method calls appropriately. It’s closely associated with the SOAP specification from the preceding paragraph. The URI is http://www.w3.org/ns/wsdl for both versions 1.0 and 2.0 of this format and is usually bound to the prefix wsdl if it’s not used as the default namespace.
The Atom Namespace
This namespace is used for publishing information (such as newsfeeds) and has also been adopted by Microsoft for use in ODATA, a format where results from database queries can be presented in an XML format. The URI is http://www.w3.org/2005/Atom.
Atom is a rival format to RSS, which has long been used for the XML formatting of informational lists, such as blog posts or news.
The MathML Namespace
MathML is used to describe mathematical notations such as equations and their content and structure. It uses the namespace URI http://www.w3.org/1998/Math/MathML. It is a rather verbose language compared to traditional ways of representation but is designed to be consumed only by suitable software applications. For example, the simple equation ax2 + bx + c could be represented by Listing 3-21.
LISTING 3-21: SimpleEquationInMathML.xml
<!DOCTYPE math
PUBLIC “-//W3C//DTD MathML 2.0//EN”
“http://www.w3.org/Math/DTD/mathml2/mathml2.dtd”>
<math xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink” overflow=”scroll”>
<mrow xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>
<mi xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>a</mi>
- <mo xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>
?
<!-- ⁢
-->
</mo>
<msup xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>
<mi xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>x</mi>
<mn xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>2</mn>
</msup>
<mo xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>+</mo>
<mi xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>b</mi>
- <mo xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>
?
- <!-- ⁢
-->
</mo>
<mi xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>x</mi>
<mo xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>+</mo>
<mi xmlns=”http://www.w3.org/1998/Math/MathML”
xmlns:xlink=”http://www.w3.org/1999/xlink”>c</mi>
</mrow>
</math>
If you have Word 2007 or greater you can try this XML by pasting it into a new document. Word understands MathML and will simply show the equation rather than the markup.
The Docbook Namespace
Finally, the Docbook namespace is normally used to mark up such things as technical publications and software and hardware manuals, although there’s no reason it can’t be used for other topics. It has elements such as <book>, <title>, <chapter>, and <para> to represent the various stories of a document. The namespace URI is http://docbook.org/ns/docbook.
SUMMARY
This chapter introduced you to XML Namespaces. You should now understand:
- The primary purpose of namespaces is to group related elements and to differentiate them from elements with the same name that were designed to represent different types of data.
- The accepted way to choose a unique namespace is to use a domain name that you control combined with a unique string of characters indicating its usage.
- There are differences between URLs, URNs, and URIs; namespaces are not URLs.
- How to declare a namespace using xmlns.
- There are two ways of specifying namespaces: default and prefixed.
- Documents can have more than one namespace; this makes it possible for software applications to treat the two content types differently.
- The basics of XML Schemas and how they use namespaces.
The next few chapters cover how to describe the format and content types of an XML document and how to determine if it has the correct structure.
EXERCISES
Answers to Exercises can be found in Appendix A.
<xmlData:document>
<xmlData:item xmlns:xmlData=”http://www.wrox.com/chapter3/exercise1/data”>
<ns:details>What's wrong with this document?</ns:details>
</xmlData:item>
</xmldata:document>
Exercise1-question.xml
http://www.wrox.com/namespaces/HR application/%7eConfig
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY POINTS |
| The reason for namespaces | Namespaces exist to group-related elements and to differentiate them from other elements with the same name. |
| Choosing namespaces | Use a unique character string; for example, a domain that you control followed by a string giving an idea of what area it is used in. |
| Types of namespaces | There are two types: default namespaces and those using prefixes. |
| Declaring default namespaces | Add xmlns=”your namespace URI here”. The element on which this declaration appears and any under it will be in this namespace; attributes will not be in a namespace. |
| Declaring prefixed namespaces | Add xmlns:prefix=”your namespace URI here”. Elements must now be written as <prefix:myElement/> to be included in the namespace. |
| Reasons to use namespaces in your own documents | You are following a predefined schema. You need to incorporate your document into another XML format. You want to make validation easier. You expect your document to be consumed by many different applications. |
| Reasons not to use namespaces in your own documents | You are only using the documents internally on one system. You don’t need to validate the documents. |