
CHAPTER 12
Tree Maps and Tree Sets
We begin this chapter by introducing another kind of balanced binary tree: the red-black tree. Red-black trees provide the underpinning for two extremely valuable classes: the TreeMap class and the TreeSet class, both of which are in the Java Collections Framework. Each element in a TreeMap object has two parts: a key part—by which the element is compared to other elements—and a value part consisting of the rest of the element. No two elements in a TreeMap object can have the same key. A TreeSet object is a TreeMap object in which all the elements have the same value part. There are applications of both the TreeMap class (a simple thesaurus) and the TreeSet class (a spell-checker). TreeMap objects and TreeSet objects are close to ideal: For inserting, removing and searching, worstTime(n) is logarithmic in n.
CHAPTER OBJECTIVES
- Be able to define what a red-black tree is, and be able to distinguish between a red-black tree and an AVL tree.
- Understand the Map interface and the overall idea of how the TreeMap implementation of the Map interface is based on red-black trees.
- Compare TreeMap and TreeSet objects.
12.1 Red-Black Trees
Basically, a red-black tree is a binary search tree in which we adopt a coloring convention for each element in the tree. Specifically, with each element we associate a color of either red or black, according to rules we will give shortly. One of the rules involves paths. Recall, from Chapter 9, that if element A is an ancestor of element B, the path from A to B is the sequence of elements, starting with A and ending with B, in which each element in the sequence (except the last) is the parent of the next element. Specifically, we will be interested in paths from the root to elements with no children or with one child1 For example, in the following tree, there are five paths from the root to an element (boxed) with no children or one child.

Note that one of the paths is to the element 40, which has one child. So the paths described are not necessarily to a leaf.
A red-black tree is a binary search tree that is empty or in which the root element is colored black, every other element is colored red or black and the following properties are satisfied:
Red Rule: If an element is colored red, none of its children can be colored red.
Path Rule: The number of black elements must be the same in all paths from the root element to elements with no children or with one child.
For example, Figure 12.1 shows a red-black tree in which the elements are values of Integer objects and colored red or black
Observe that this is a binary search tree with a black root. Since no red element has any red children, the Red Rule is satisfied. Also, there are two black elements in each of the five paths (one path ends at 40) from the root to an element with no children or one child, so the Path Rule is satisfied. In other words, the tree is a red-black tree.
The tree in Figure 12.2 is not a red-black tree even though the Red Rule is satisfied and every path from the root to a leaf has the same number of black elements. The Path Rule is violated because, for example, the path from 70 to 40 (an element with one child) has three black elements, but the path from 70 to 110 has four black elements. That tree is badly unbalanced: most of its elements have only one child. The Red and Path rules preclude most single children in red-black trees. In fact, if a red element has any children, it must have two children and they must be black. And if a black element has only one child, that child must be a red leaf.
The red-black tree in Figure 12.1 is fairly evenly balanced, but not every red-black tree has that characteristic. For example, Figure 12.3 shows one that droops to the left.
FIGURE 12.1 A red-black tree with eight elements
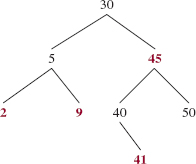
FIGURE 12.2 A binary search tree that is not a red-black tree
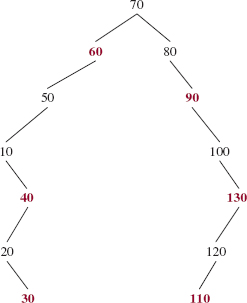
FIGURE 12.3 A red-black tree that is not "evenly" balanced
You can easily verify that this is a black-rooted binary search tree and that the Red Rule is satisfied. For the Path Rule, there are exactly two black elements in any path from the root to an element with no children or with one child. That is, the tree is a red-black tree. But there are limits to how unbalanced a red-black tree can be. For example, we could not hang another element under element 10 without rebalancing the tree. For if we tried to add a red element, the Red Rule would no longer be satisfied. And if we tried to add a black element, the Path Rule would fail.
If a red-black tree is complete, with all black elements except for red leaves at the lowest level, the height of that tree will be minimal, approximately log2 n. To get the maximum height for a given n, we would have as many red elements as possible on one path, and all other elements black. For example, Figure 12.3 contains one such tree, and Figure 12.4 contains another. The path with all of the red elements will be about twice as long as the path(s) with no red elements. These trees lead us to hypothesize that the maximum height of a red-black tree is less than 2 log2 n.
12.1.1 The Height of a Red Black Tree
Red-black trees are fairly bushy in the sense that almost all non-leaves have two children. In fact, as noted earlier, if a parent has only one child, that parent must be black and the child must be a red leaf. This bushiness leads us to believe that a red-black tree is balanced, that is, has height that is logarithmic in n, even in the worst case. Compare that with the worst-case height that is linear in n for a binary search tree. As shown in Example A2.6 of Appendix 2,
FIGURE 12.4 A red-black tree of 14 elements with maximum height, 5
The height of a red-black tree is always logarithmic in n, the size of the tree.
How do red-black trees compare to AVL trees? The height of an AVL tree is also logarithmic in n. The definition of a red-black tree is slightly more "relaxed" than the definition of an AVL tree. So any AVL tree can be colored to become a red-black tree, but the converse is not true (see Concept Exercises 12.6 and 12.7). That is, red-black trees can have larger heights than AVL trees with the same number of elements. It can be shown (see Weiss [2002]) that the average height of an AVL tree with n elements is, approximately, 1.44 log2 n, versus 2 log2 n for a red-black tree. For example, if n is one million, the average height of an AVL tree with n elements is about 29, and the average height of a red-black tree with n elements is about 40.
In Section 12.2, we introduce the Map interface, and in Section 12.3, a class that implements the Map interface. That class, the TreeMap class, is based on a red-black tree, and is part of the Java Collections Framework. The developers of the framework found that using a red-black tree for the underlying structure of the TreeMap class provided slightly faster insertions and removals than using an AVL tree.
12.2 The Map Interface
A map is a collection2 in which each element has two parts: a unique key part and a value part. The idea behind this definition is that there is a "mapping" from each key to the corresponding value. For example, we could have a map of social security numbers and names. The keys will be social security numbers and the values will be names. The social security numbers are unique: no two elements in the collection are allowed to have the same social security number. But two elements may have the same name. For example, we could have the following map, in which all of the social security numbers are unique, but two elements have the same name:
| 123-45-6789 | Builder, Jay |
| 222-22-2222 | Johnson, Alan |
| 555-55-5555 | Nguyen, Viet |
| 666-66-6666 | Chandramouli, Soumya |
| 888-88-8888 | Kalsi, Navdeep |
| 999-99-9999 | Johnson, Alan |
A dictionary is another example of a map. The key is the word being defined and the value consists of the definition, punctuation, and etymology. The term dictionary is sometimes used as a synonym for "map". In this sense, a dictionary is simply a collection of key-value pairs in which there are no duplicate keys.
The Java Collections Framework has a Map interface that provides method headings for the abstract-data-type map. The Map interface does not extend the Collection interface because many Map methods are oriented towards the key-value relationship. In fact, the type parameters are K (for the key class) and V (for the value class). But the Map interface has some standard methods such as size, equals, and clear. Here are specifications for several of the other methods in the Map interface—no time estimates are given because different implementations have substantially different estimates:
- The put method
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * * @return the previous value associated with key, or * null if there was no mapping for key. * (A null return can also indicate that the map * previously associated null with key.) * @throws ClassCastException if the specified key cannot be compared * with the keys currently in the map * @throws NullPointerException if the specified key is null * and this map uses natural ordering, or its comparator * does not permit null keys */ V put (K key, V value);
Note 1: The phrase "this map" refers to an object in a class that implements the Map interface.
Note 2: The put method is somewhat more versatile than an add method because the put method handles replacement—of the values associated with a given key—as well as insertion of a new key-value pair.
- The containsKey method
/** * Determines if this Map object contains a mapping for a specified key. * * @param key - the specified key. * * @return true - if there is at least one mapping for the specified key in * this Map object; otherwise, return false. * * @throws ClassCastException - if key cannot be compared with the keys * currently in the map. * * @throws NullPointerException - if key is null and this Map object uses * the natural order, or the comparator does not allow null keys. * */ boolean containsKey (Object key);
- The containsValue method
/** * Determines if there is at least one mapping with a specified value in this * Map object. * * @param value - the specified value for which a mapping is sought. * * @return true - if there is at least one mapping with the specified value * in this Map object; otherwise, return false. * */ boolean containsValue (Object value); - The get method
/** * Returns the value to which a specified key is mapped in this Map * object. * * @param key - the specified key. * * @return the value to which the specified key is mapped, if the specified * key is mapped to a value; otherwise, return null. * * @throws ClassCastException - if key cannot be compared with the keys * currently in the map. * * @throws NullPointerException - if key is null and this Map object uses * the natural order, or the comparator does not allow null keys. */ V get (Object key);
Note: The value null might also be returned if the given key maps to null. To distinguish between this situation and the no-matching-key situation, the containsKey method can be used. For example, if persons is an object in a class that implements the Map interface and key is an object in the key class, we can do the following:
- The remove method
/** * Removes the mapping with a specified key from this Map object, if there * was such a mapping. * * @param key - the specified key whose mapping, if present, is to be * removed from this Map object. * * @return the value to which the specified key is mapped, if there is such * a mapping; otherwise, return null (note that null could also be the * previous value associated with the specified key). * * @throws ClassCastException - if key cannot be compared with the keys * currently in the map. * * @throws NullPointerException - if key is null and this Map object uses * the natural order, or the comparator does not allow null keys. */ V remove (Object key);
- The entrySet method
/** * Returns a Set view of the key-map pairs in this Map object. * * @return a Set view of the key-map pairs in this Map object. * */ Set entrySet();
Note: Recall, from Chapter 10, that a set is a collection of elements in which duplicates are not allowed. We can view a Map object as just a set of key-value pairs. The advantage to this view is that we can then iterate over the Map object, and the elements returned will be the key-value pairs of the Map object. Why is this important? The Map interface does not have an iterator() method, so you cannot iterate over a Map object except through a view. And the interface has a public, nested Entry interface that has getKey() and getValue() methods.
For example, suppose that persons is an instance of a class that implements the Map interface, and that the element class has a social security number as the (Integer) key and a name as the (String) value. Then we can print out the name of each person whose social security number begins with 555 as follows:
for (Map.Entry<Integer, String> entry : persons.entrySet()) if (entry.getKey() / 1000000 == 555) System.out.println (entry.getValue());
There are also keySet() and values() methods that allow iterating over a Map viewed as a set of keys and as a collection of values, respectively. The term "collection of values" is appropriate instead of "set of values" because there may be duplicate values.
Section 12.3 has an implementation of the Map interface, namely, the TreeMap class. Chapter 14 has another implementation, the HashMap class. The TreeMap class, since it is based on a red-black tree, boasts logarithmic time, even in the worst case, for insertions, removals, and searches. The HashMap class's claim to fame is that, on average, it takes only constant time for insertions, removals and searches. But its worst-case performance is poor: linear in n.
The TreeMap class actually implements a slight extension of the Map interface, namely, the SortedMap interface. The SortedMap interface mandates that for any instance of any implementing class, the elements will be in "ascending" order of keys (for example, when iterating over an entry-set view). The ordering is either the natural ordering—if the key class implements the Comparable interface—or an ordering supplied by a comparator. Here are several new methods:
/**
* Returns the comparator for this sorted map, or null, if the map uses the
* keys' natural ordering. The comparator returned, if not null, must implement
* the Comparator interface for elements in any superclass of the key class.
*
* @return the comparator for this sorted map, or null, if this sorted
* map uses the keys- natural ordering.
*
*/
Comparator<? super K> comparator();
/**
* Returns the first (that is, smallest) key currently in this sorted map.
*
* @return the first (that is, smallest) key currently in this sorted map.
*
* @throws NoSuchElementException, if this sorted map is empty.
*
*/
K firstKey();
/**
* Returns the last (that is, largest) key currently in this sorted map.
*
* @return the last (that is, largest) key currently in this sorted map.
*
* @throws NoSuchElementException, if this sorted map is empty.
*
*/
K lastKey();
12.3 The TreeMap Implementation of the SortedMap Interface
The Java Collection Framework's TreeMap class implements the SortedMap interface. For the put, containsKey, get, and remove methods, worstTime(n) is logarithmic in n. Why? In a TreeMap object, the key-value pairs are stored in a red-black tree ordered by the keys. Can you figure out why, for the containsValue method, worstTime(n) is linear in n instead of logarithmic in n?
We will look at the fields and method definitions in Section 12.3.2. But our main emphasis is on the use of data structures, so let's start with a simple example. The following class creates a TreeMap object of students. Each student has a name and a grade point average; the ordering is alphabetical by student names. The method prints each student, each student whose grade point average is greater than 3.9, and the results of several removals and searches.
import java.util.*; public class TreeMapExample { public static void main (String[ ] args) { new TreeMapExample().run(); } // method main public void run() { TreeMap<String,Double> students = new TreeMap<String,Double>(); students.put ("Bogan, James", 3.85); students.put ("Zawada, Matt", 3.95); students.put ("Balan, Tavi", 4.00); students.put ("Nikolic, Lazar", 3.85); System.out.println (students); for (Map.Entry<String, Double> entry : students.entrySet()) if (entry.getValue() > 3.9) System.out.println (entry.getKey() + " " + entry.getValue()); System.out.println (students.remove ("Brown, Robert")); System.out.println (students.remove ("Zawada, Matt")); System.out.println (students.containsKey ("Tavi Balan")); System.out.println (students.containsKey ("Balan, Tavi")); System.out.println (students.containsValue (3.85)); } // method run } // class TreeMapExample
The output will be
{Balan, Tavi=4.0, Bogan, James=3.85, Nikolic, Lazar=3.85, Zawada, Matt=3.95}
Balan, Tavi 4.0
Zawada, Matt 3.95
null
3.95
false
true
true
The reason that the students object is alphabetically ordered by student names is that the key class is String. As we saw in Section 10.1.1, the String class implements the Comparable interface with a compareTo method that reflects an alphabetical ordering. For applications in which the "natural" ordering—through the Comparable interface—is inappropriate, elements can be compared with the Comparator interface, discussed in Section 11.3. In the TreeMap class, there is a special constructor:
/** * Initializes this TreeMap object to be empty, with keys to be compared * according to a specified Comparator object. * * @param c - the Comparator object by which the keys in this TreeMap * object are to be compared. * */ public TreeMap (Comparator<? super K> c)
We can implement the Comparator interface to override the natural ordering. For example, suppose we want to create a TreeMap of Integer keys (and Double values) in decreasing order. We cannot rely on the Integer class because that class implements the Comparable interface with a compareTo method that reflects increasing order. Instead, we create a class that implements the Comparator interface by reversing the meaning of the compareTo method in the Integer class:
public class Decreasing implements Comparator<Integer> { /** * Compares two specified Integer objects. * * @param i1 - one of the Integer objects to be compared. * @param i2 - the other Integer object. * * @return the value of i2-s int - the value of i1-s int. * */ public int compare (Integer i1, Integer i2) { return i2.compareTo (i1); } // method compare } // class Decreasing
Notice that the Decreasing class need not specify a type parameter since that class is implementing the Comparator interface parameterized with Integer.
A TreeMap object can then be constructed as follows:
TreeMap<Integer, Double> inventory =
new TreeMap<Integer, Double>(new Decreasing());
For another example, here is the ByLength class from Section 11.3:
public class ByLength implements Comparator<String> { /** * Compares two specified String objects lexicographically if they have the * same length, and otherwise returns the difference in their lengths. * * @param s1 - one of the specified String objects. * @param s2 - the other specified String object. * * @return s1.compareTo (s2) if s1 and s2 have the same length; * otherwise, return s1.length() - s2.length(). * */ public int compare (String s1, String s2) { int len1 = s1.length(), len2 = s2.length(); if (len1 == len2) return s1.compareTo (s2); return len1 - len2; } // method compare } // class ByLength
The following class utilizes the ByLength class with a TreeMap object in which the keys are words—stored in order of increasing word lengths—and the values are the number of letters in the words.
import java.util.*; public class TreeMapByLength { public static void main (String[ ] args) { new TreeMapByLength().run(); } // method main public void run() { TreeMap<String, Integer> wordLengths = new TreeMap<String, Integer>(new ByLength()); wordLengths.put ("serendipity", 11); wordLengths.put ("always", 6); wordLengths.put ("serenity", 8); wordLengths.put ("utopia", 6); System.out.println (wordLengths); } // method run } // class TreeMapByLength
The output will be
{always=6, utopia=6, serenity=8, serendipity=11}
Now that we have seen a user's view of the TreeMap class, Sections 12.3.1 and 12.3.2 will spend a little time looking "under the hood" at the fields, the embedded Entry class and the method definitions. Then Section 12.4 will present an application of the TreeMap class: creating a thesaurus.
12.3.1 The TreeMap Class's Fields and Embedded Entry Class
In the design of a class, the critical decision is the choice of fields. For the TreeMap class, two of the fields are the same as in the BinarySearchTree class of Chapter 10 (except that the framework designers prefer private visibility to protected visibility):
private transient Entry root = null; private transient int size = 0;
To flag illegal modifications (see Appendix 1) to the structure of the tree during an iteration:
private transient int modCount = 0;
The only other field in the TreeMap class is used for comparing elements:
private Comparator comparator = null;
This field gives a user of the TreeMap class a choice. If the user wants the "natural" ordering, such as alphabetical order for String keys or increasing order for Integer keys, the user creates a TreeMap instance with the default constructor. Then the keys' class must implement the Comparable interface, so comparisons are based on the compareTo method in the key class. Alternatively, as we saw in Section 12.3, a user can override the "natural" ordering by supplying a Comparator object in the constructor call:
TreeMap<String, Integer> wordLengths =
new TreeMap<String, Integer>(new ByLength());
The designers of the Java Collections Framework's TreeMap class chose a red-black tree as the underlying structure because it had a slight speed advantage over an AVL tree for insertions, removals, and searches. We will now start to get into the red-black aspects of the TreeMap class. There are two constant identifiers that supply the colors:
private static final boolean RED = false; private static final boolean BLACK = true;
These constant identifiers apply, not to the tree as a whole, but to the Entry objects in the tree. The Entry class, embedded in the TreeMap class, is similar to the Entry class that is embedded in the BinarySearchTree class, except that the TreeMap class's Entry class has key and value fields (instead of just an element field), and a color field:
static class Entry<K, V> implements Map.Entry<K, V> { K key; V value; Entry<K, V> left = null; Entry<K, V> right = null; Entry<K, V> parent; boolean color = BLACK; // ensures that root-s color will start out BLACK
Every Entry object's color field is initialized to BLACK. But during an insertion, the inserted Entry object is colored RED; this simplifies the maintenance of the Path Rule. The Entry class also has a default-visibility constructor to initialize the key, value, and parent fields. And there are a few public methods, such as getKey() and getValue(), which are useful in iterating over the entries in a TreeMap object after a call to the entrySet(), keySet(), or values(), methods.
To finish up our overview of the TreeMap implementation of the Map interface, we consider a few method definitions in Section 12.3.2.
12.3.2 Method Definitions in the TreeMap Class
We will focus on the definitions of the put and remove methods. As you might expect, the definitions of those methods are quite similar to the definitions of the add and remove methods in the AVLTree class. But one obvious difference is that, for the sake of simplicity, we restricted AVLTree elements to the "natural" ordering with an implementation of the Comparable interface. Users of the TreeMap class can guarantee the elements in a TreeMap instance will be ordered "naturally" by invoking the default constructor. Or, as we saw in Section 12.3.1, a user can override the natural ordering by invoking the constructor that takes a Comparator argument.
The definition of the put (K key, V value) method starts by initializing an Entry:
Entry<K, V> t = root;
Then, just as we did in the add method of the AVLTree class, we work our way down the tree until we find where key is or belongs. Except that the put method:
- splits off the Comparator case from the Comparable case;
- returns t.setValue (value) if key and t.key are the same, and then value replaces t.value and the old value is returned;
- after an insertion, calls a special method, fixAfterInsertion, to re-color and rotate the tree if the Red Rule is no longer satisfied (the Path Rule will still be satisfied because the newly inserted entry is colored RED at the start of fixAfterInsertion).
Here is the complete definition:
public V put (K key, V value) { Entry<K, V> t = root; if (t == null) { root = new Entry<K,V>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } // the keys are ordered by the comparator else { if (key == null) throw new NullPointerException(); Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null ); } // the keys are ordered "naturally" Entry<K,V> e = new Entry<K,V>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null ; } // method put
Notice that the fixAfterInsertion method is not called when an insertion is made at the root. So root remains BLACK in that case.
The definition of the fixAfterInsertion method is not intuitively obvious. In fact, even if you study the code, it makes no sense. Red-black trees were originally developed in Bayer [1972]. The algorithms for inserting and removing in these trees, called "2-3-4 trees," were lengthy but the overall strategy was easy to understand. Shorter but harder to follow methods were supplied when the red-black coloring was imposed on these structures in Guibas [1978].
Lab 19 investigates the fixAfterInsertion method in some detail.
You are now ready for Lab 19: The fixAfterInsertion Method
In Section 12.1.1, we stated that the height of any red-black tree is logarithmic in n, the number of elements in the tree. So for the part of the put method that finds where the element is to be inserted, worstTime(n) is logarithmic in n. Then a call to fixAfterInsertion is made, for which worstTime(n) is also logarithmic in n. We conclude that, for the entire put method, worstTime(n) is logarithmic in n.
The remove method, only slightly changed from that of the BinarySearchTree class, gets the Entry object corresponding to the given key and then deletes that Entry object from the tree:
public V remove (K key) { Entry<K, V> p = getEntry (key); if (p == null) return p; V oldValue = p.value; deleteEntry (p); return oldValue; } // method remove
The getEntry method is almost identical to the BinarySearchTree class's getEntry method except—as we saw with the put method—that there is a split of the Comparator and Comparable cases.
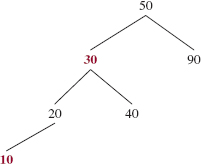
The deleteEntry method mimics the BinarySearchTree class's (and AVLTree class's) delete Entry method, except now we must ensure that the Path Rule is still satisfied after the deletion. To see how we might have a problem, suppose we want to delete the entry with key 50 from the TreeMap object in Figure 12.5. The value parts are omitted because they are irrelevant to this discussion, and we pretend that the keys are of type int; they are actually of type reference-to-Integer.
FIGURE 12.5 A TreeMap (with value parts not shown) from which 50 is to be deleted
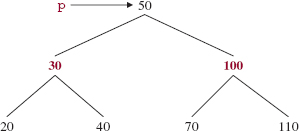
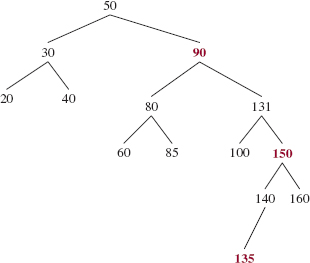
FIGURE 12.6 An intermediate stage in the deletion of 50 from the TreeMap object of Figure 12.5
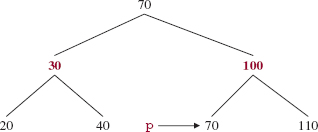
Just as we did with the BinarySearchTree class's deleteEntry method, the successor's key (namely, 70) replaces 50 and then p references that successor. See Figure 12.6 above.
If we were performing a BinarySearchTree -style deletion, we would simply unlink p's Entry object and be done. But if we unlink that Entry object from the TreeMap object of Figure 12.5, the Path Rule would be violated. Why? There would be only one black element in the path from the root to 100 (an element with one child), and two black elements in the path from the root to the leaf 110. To perform any necessary re-coloring and re-structuring, there is a fixAfterDeletion method.
Here is the definition of the deleteEntry method, which is very similar to the definition of the deleteEntry method in both the BinarySearchTree and AVLTree classes:
private void deleteEntry (Entry<K, V> p) { modCount++; size-; // If strictly internal, replace p-s element with its successor-s element // and then make p reference that successor. if (p.left != null && p.right != null) { Entry<K, V> s = successor (p); p.key = s.key; p.value = s.value; p = s; } // p has two children // Start fixup at replacement node, if it exists. Entry<K, V> replacement = (p.left != null? p.left : p.right); if (replacement != null) { // Link replacement to parent replacement.parent = p.parent; if (p.parent == null) root = replacement; else if (p == p.parent.left) p.parent.left = replacement; else p.parent.right = replacement; // Fix replacement if (p.color == BLACK) fixAfterDeletion(replacement); } else if (p.parent == null) { // return if we are the only node. root = null; } else { // No children. Use self as phantom replacement and unlink. if (p.color == BLACK) fixAfterDeletion(p); if (p.parent != null) { if (p == p.parent.left) p.parent.left = null; else if (p == p.parent.right) p.parent.right = null; } // non-null parent } // p has no children } // method deleteEntry
The fixAfterDeletion method, the subject of Lab 20, has even more cases than the fixAfterInsertion method.
You are now ready for Lab 20: The fixAfterDeletion Method
The ch12 directory on the book's website includes an applet that will help you to visualize insertions in and removals from a red-black tree:
In Section 12.4, we develop an application of the TreeMap class to print out the synonyms of given words.
12.4 Application of the TreeMap Class: a Simple Thesaurus
A thesaurus is a dictionary of synonyms. For example, here is a small thesaurus, with each word followed by its synonyms:
close near confined confined close cramped correct true cramped confined near close one singular unique singular one unique true correct unique singular one
The problem we want to solve is this: given a thesaurus file and a file of words whose synonyms are requested, print the synonym of each word entered to a file
Analysis If there is no file for either path input, or if the output file path is illegal, an error message should be printed, followed by a re-prompt. The thesaurus file will be in alphabetical order. For each word entered from the requests file, the synonyms of that word should be output to the synonyms file, provided the word's synonyms are in the thesaurus file. Otherwise, a synonyms-not-found message should be printed. In the following system test, assume that the thesaurus shown earlier in this section is in the file "thesaurus.in1", and "requests.in1" consists of
one two close System Test (input is boldfaced): Please enter the path for the thesaurus file: thesaraus.in1 java.io.FileNotFoundException: thesaraus.in1 (The system cannot find the file specified) Please enter the path for the thesaurus file: thesaurus.in1 Please enter the path for the requests file: requests.in1 Please enter the path for the synonyms file: synonyms.ou1 The contents of synonyms.ou1 are now: The synonyms of one are [singular, unique] two does not appear in the thesaurus. The synonyms of close are [near, confined]
We will create two classes to solve this problem: a Thesaurus class to store the synonym information, and a ThesaurusUser class to handle the input/output.
12.4.1 Design, Testing, and Implementation of the Thesaurus Class
The Thesaurus class will have four responsibilities: to initialize a thesaurus object, to add a line of synonyms to a thesaurus, to return the synonyms of a given word, and—for the sake of testing—to return a string representation of the thesaurus. The synonyms will be returned in a LinkedList object. In the specifications, n refers to the number of lines in the thesaurus file. Here are the method specifications:
/** * Initializes this Thesaurus object. * */ public Thesaurus( ) /** * Adds a specified line of synonyms to this Thesaurus object. * The worstTime(n) is O(log n). * * @param line - the specified line of synonyms to be added to this * Thesaurus object. * @throws NullPointerException - if line is null. * */ public void add (String line) /** * Finds the LinkedList of synonyms of a specified word in this Thesaurus. * The worstTime(n) is O(log n). * * @param word - the specified word, whose synonyms are to be * returned. * * @return the LinkedList of synonyms of word. * * @throws NullPointerException - if word is null. * */ public LinkedList<String> getSynonyms (String word) /** * Returns a String representation of this Thesaurus object. * The worstTime(n) is O(n). * * @return a String representation of this Thesaurus object in the * form {word1=[syn11, syn12,...], word2=[syn21, syn22,...],...}. * */ public String toString()
Here are two tests in the ThesaurusTest class, which has thesaurus (an instance of the Thesaurus class) as a field:
@Test (expected = NullPointerException.class) public void testAddLineNull() { thesaurus.add (null); } // method testAddLineNull @Test public void testAdd1() { thesaurus.add ("therefore since because ergo"); assertEquals ("{therefore=[since, because, ergo]}", thesaurus.toString()); } // method testAdd1
The complete test suite is available from the book's website.
The only field in the Thesaurus class is a TreeMap object in which the key is a word and the value is the linked list of synonyms of the word:
protected TreeMap<String, LinkedList<String>> thesaurusMap;
The implementation of the Thesaurus class is fairly straightforward; most of the work is done in the put and get methods of the TreeMap class. The Thesaurus class's add method tokenizes the line, saves the first token as the key, and saves the remaining tokens in a LinkedList object as the value.
Here are the method definitions and time estimates:
public Thesaurus() { thesaurusMap = new TreeMap<String, LinkedList<String>>(); } // default constructor public void add (String line) { LinkedList<String> synonymList = new LinkedList<String>(); Scanner sc = new Scanner (line); if (sc.hasNext()) { String word = sc.next(); while (sc.hasNext()) synonymList.add (sc.next()); thesaurusMap.put (word, synonymList); } //if } // method add
For the put method in the TreeMap class, worstTime(n) is logarithmic in n, and so that is also the time estimate for the add method. Note that the while loop takes constant time because it is independent of n, the number of lines in the thesaurus.
Here is the one-line getSynonyms method:
public LinkedList<String> getSynonyms (String word) { return thesaurusMap.get (word); } // method getSynonyms
For the getSynonyms method, worstTime(n) is logarithmic in n because that is the time estimate for the TreeMap class's get method.
The definition of the toString() method is just as simple:
public String toString() { return thesaurusMap.toString(); } // method toString
For this method, worstTime(n) is linear in n—the iteration over the entries accesses a key and value in constant time.
12.4.2 Design and Testing of the ThesaurusUser Class
The ThesaurusUser class's run method creates a thesaurus from a file whose file-path is scanned in from the keyboard, and then creates, from paths scanned in, a scanner for a requests file and a print writer for synonyms file. Then the findSynonyms method produces the synonyms file from the thesaurus and the requests file. Here are the corresponding method specifications:
/** * Constructs a thesaurus from a file whose path is read in from the keyboard * and creates, from paths scanned in, a scanner for a requests file and a print * writer for the synonyms file. * The worstTime(n) is O(n log n). * */ public void run() /** * Outputs the synonyms of the words in the file scanned to a specified file. * The worstTime(n, m) is O(m log n), where n is the number of lines in * the thesaurus, and m is the number of words in the file scanned. * * @param thesaurus - the thesaurus of words and synonyms. * @param requestFileScanner - the Scanner over the file that holds the * words whose synonyms are requested. * @param synonymPrintWriter - the PrintWriter for the file that will hold * the synonyms of the words in the request file. * */ public void findSynonyms (Thesaurus thesaurus, Scanner requestFileScanner, PrintWriter synonymPrintWriter)
The run method is not testable because it deals mainly with end-user input and output. The findSynonyms method is testable, and here is one of those tests (user, of type ThesaurusUser and line, of type String, are fields in ThesaurusUserTest):
@Test public void testProcessFilesNormal() throws IOException { Scanner thesaurusFileScanner = new Scanner (new File ("thesaurus.in1")), requestFileScanner = new Scanner (new File ("requests.in1")); PrintWriter synonymPrintWriter = new PrintWriter (new BufferedWriter (new FileWriter ("synonyms.ou1"))); Thesaurus thesaurus = new Thesaurus(); while (thesaurusFileScanner.hasNext()) thesaurus.add (thesaurusFileScanner.nextLine()); user.findSynonyms (thesaurus, requestFileScanner, synonymFileWriter); synonymFileWriter.close(); Scanner sc = new Scanner (new File ("synonyms.ou1")); line = sc.nextLine(); assertEquals ("Here are the synonyms of confined: [close, cramped]", line); line = sc.nextLine(); assertEquals ("Here are the synonyms of near: [close]", line); line = sc.nextLine(); assertEquals ("x does not appear in the thesaurus.", line); line = sc.nextLine(); assertEquals ("Here are the synonyms of singular: [one, unique]", line); } // method testProcessFilesNormal
The book's website includes the complete ThesaurusUserTest class.
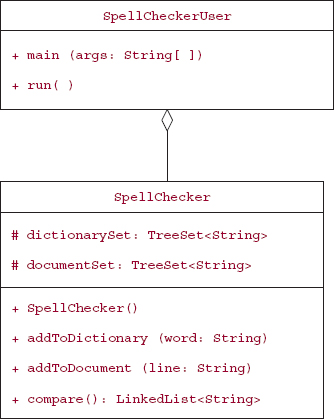
Figure 12.7 has the UML class diagrams for this project. The line just below the diagram for ThesaurusUser signifies that the ThesaurusUser class has an association—specifically, a method parameter—with the Thesaurus class.
FIGURE 12.7 Class diagrams for the Thesaurus project

12.4.3 Implementation of the ThesaurusUser Class
As always, the main method simply invokes the run method on a newly constructed ThesaurusUser object:
public static void main (String[] args) { new ThesaurusUser().run(); } // method main
The ThesaurusUser's run method scans a file path (and keeps scanning until a legal file path is scanned in), adds each line in the file to the thesaurus, and then finds the synonyms of each word in a file whose path is scanned in:
public void run() { final String THESAURUS_FILE_PROMPT = " Please enter the path for the thesaurus file: "; final String REQUEST_FILE_PROMPT = " Please enter the path for the file with the words " + "whose synonyms are requested: "; final String SYNONYM_FILE_PROMPT = " Please enter the path for the file that will " + "hold the synonyms of each word in the request file: "; final String NO_INPUT_FILE_FOUND_MESSAGE = "Error: there is no file with that path. "; Thesaurus thesaurus = new Thesaurus(); Scanner keyboardScanner = new Scanner (System.in), thesaurusFileScanner, requestFileScanner; PrintWriter synonymPrintWriter; String thesaurusFilePath, requestFilePath, synonymFilePath; boolean pathsOK = false; while (!pathsOK) { try { System.out.print (THESAURUS_FILE_PROMPT); thesaurusFilePath = keyboardScanner.nextLine(); thesaurusFileScanner = new Scanner (new File (thesaurusFilePath)); while (thesaurusFileScanner.hasNext()) thesaurus.add (thesaurusFileScanner.nextLine()); System.out.print (REQUEST_FILE_PROMPT); requestFilePath = keyboardScanner.nextLine(); requestFileScanner = new Scanner (new File (requestFilePath)); System.out.print (SYNONYM_FILE_PROMPT); synonymFilePath = keyboardScanner.nextLine(); synonymPrintWriter = new PrintWriter (new BufferedWriter (new FileWriter (synonymFilePath))); pathsOK = true; findSynonyms (thesaurus, requestFileScanner, synonymPrintWriter); synonymFileWriter.close(); } // try catch (IOException e) { System.out.println (e); } // catch } // while !pathsOK } // method run
Intuitively, since it takes logarithmic-in-n time for each insertion into the thesaurus, it should take linear-logarithmic-in-n time for n insertions. But the first insertion is into an empty tree, the second insertion is into a tree with one element, and so on. Specifically, for i = 1,2,..., n, it takes approximately log2 i loop iterations to insert the i th element into a red-black tree. To insert n elements, the total number of iterations is, approximately,

In other words, our intuition is correct, and worstTime(n) is linear-logarithmic in n for filling in the thesaurus. To estimate the worst time for the entire run method, we first need to develop and then estimate the worst time for the findSynonyms method, because findSynonyms is called by the run method.
The findSynonyms method consists of a read-loop that continues as long as there are words left in the requests file. For each word scanned, the synonyms of that word are fetched from the thesaurus and output to the synonyms file; an error message is output if the word is not in the thesaurus. Here is the method definition:
public void findSynonyms (Thesaurus thesaurus, Scanner requestFileScanner, PrintWriter synonymPrintWriter) { final String WORD_NOT_FOUND_MESSAGE = " does not appear in the thesaurus."; final String SYNONYM_MESSAGE = "Here are the synonyms of "; String word; LinkedList<String> synonymList; while (requestFileScanner.hasNext()) { word = requestFileScanner.next(); synonymList = thesaurus.getSynonyms (word); if (synonymList == null) synonymPrintWriter.println (word + WORD_NOT_FOUND_MESSAGE); else synonymPrintWriter.println (SYNONYM_MESSAGE + word + ": " + synonymList); } // while } // method findSynonyms
To estimate how long the findSynonyms method takes, we must take into account the number of words entered from the requests file as well as the size of thesaurusMap. Assume there are m words entered from the requests file. (We cannot use n here because that represents the size of thesaurusMap.) Then the while loop in findSynonyms is executed O(m) times. During each iteration of the while loop, there is a call to the get method in the TreeMap class, and that call takes O(log n) time. So worstTime(n, m) is O(m logn); in fact, to utilize the notation from Chapter 3, worstTime(n, m) is Θ(m logn) because m log n provides a lower bound as well as an upper bound on worstTime(n, m). The worstTime function has two arguments because the total number of statements executed depends on both n and m.
We can now estimate the worst time for the run method. For the loop to fill in the thesaurus, worstTime(n) is linear-logarithmic in n, and for the call to findSynonyms, worstTime(n, m) is Θ(m logn). We assume that the number of requests will be less than the size of thesaurusMap. Then for the run method, worstTime(n, m) is Θ(n log n), that is, linear logarithmic in n.
The next topic in this chapter is the TreeSet class, which is implemented as a TreeMap in which each Entry object has the same dummy value-part.
12.5 The TreeSet Class
We need to go through a little bit of background before we can discuss the TreeSet class. Recall, from Chapter 10, that the Set interface extends the Collection interface by stipulating that duplicate elements are not allowed. The SortedSet interface extends the Set interface in two ways:
- by stipulating that its iterator must traverse the Set in order of ascending elements;
- by including a few new methods relating to the ordering, such as first(), which returns the smallest element in the instance, and last(), which returns the largest element in the instance.
The TreeSet class implements the SortedSet interface, and extends the AbstractSet class, which has a bare-bones implementation of the Set interface.
The bottom line is that a TreeSet is a Collection in which the elements are ordered from smallest to largest, and there are no duplicates. Most importantly, for the TreeSet class's contains, add, and remove methods, worstTime(n) is logarithmic in n. So if these criteria suit your application, use a TreeSet instead of an ArrayList, LinkedList, BinarySearchTree, or array. For those four collections, if the elements are to be maintained in order from smallest to largest, worstTime(n) is linear in n for insertions and removals.
How does the TreeSet class compare with the AVLTree class? The TreeSet class is superior because it is part of the Java Collections Framework. As a result, the class is available to you on any Java compiler. Also, the methods have been thoroughly tested. Finally, you are not restricted to the "natural" ordering of elements: You can override that ordering with a comparator.
We already saw most of the TreeSet methods when we studied the BinarySearchTree and AVLTree classes in Chapter 10.
The following class illustrates both the default constructor and the constructor with a comparator parameter, as well as a few other methods:
import java.util.*; public class TreeSetExample { public static void main (String[ ] args) { new TreeSetExample().run(); } // method main public void run() { final String START = "Here is the TreeSet: n"; final String ADD = " After adding "tranquil", here is the TreeSet: n"; final String REMOVE = " After removing "serene", here is the TreeSet: n"; final String REVERSE = " Here are the scores in decreasing order: "; final String SUM = "The sum of the scores is "; TreeSet<String> mySet = new TreeSet<String>(); TreeSet<Integer> scores = new TreeSet<Integer> (new Decreasing ()); mySet.add ("happy"); mySet.add ("always"); mySet.add ("yes"); mySet.add ("serene"); System.out.println (START + mySet); if (mySet.add ("happy")) System.out.println ("ooops"); else System.out.println (" "happy" was not added " + "because it was already there"); mySet.add ("tranquil"); System.out.println (ADD + mySet); System.out.println ("size = " + mySet.size()); if (mySet.contains ("no")) System.out.println ("How did "no " get in there?"); else System.out.println (" "no" is not in the TreeSet"); if (mySet.remove ("serene")) System.out.println (REMOVE + mySet); for (int i = 0; i < 5; i++) scores.add (i); System.out.println (REVERSE + scores); int sum = 0; for (Integer i : scores) sum += i; System.out.println (SUM + sum); } // method run } // class TreeSetExample
Here is the output:
Here is the TreeSet: [always, happy, serene, yes] "happy" was not added because it was already there After adding "tranquil", here is the TreeSet: [always, happy, serene, tranquil, yes] size = 5 "no" is not in the TreeSet After removing "serene", here is the TreeSet: [always, happy, tranquil, yes] Here are the scores in decreasing order: [4, 3, 2, 1, 0] The sum of the scores is 10
After we take a brief look at the implementation of the TreeSet class, we will return to a user's view by developing an application on spell checking.
12.5.1 Implementation of the TreeSet Class
The TreeSet class is based on the TreeMap class, which implements a red-black tree. Basically, a TreeSet object is a TreeMap object in which each element has the same dummy value. Recall that it is legal for different TreeMap elements to have the same values; it would be illegal for different TreeMap elements to have the same keys. Here is the start of the declaration of the TreeSet class:
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable { private transient NavigableMap<E, Object> m; // The backing Map // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object();
"Navigable" means that the set (or map) can be iterated over from back to front as well as from front to back.
To explicitly construct a TreeSet object from a given SortedSet object, usually a TreeSet object, there is a constructor with default visibility (that is, accessible only from within the package java.util):
/**
* Initializes this TreeSet object from a specified NavigableMap object.
*
* @param m - the NavigableMap that this TreeSet object is initialized from.
*
*/
TreeSet<E> (NavigableMap<E, Object> m)
{
this.m = m;
} // constructor with map parameter
Given the TreeSet fields and this constructor, we can straightforwardly implement the rest of the TreeSet methods. In fact, most of the definitions are one-liners. For example, here are the definitions of the default constructor, the constructor with a comparator parameter, and the contains, add, and remove methods:
/** * Initializes this TreeSet object to be empty, with the elements to be * ordered by the Comparable interface. * */ public TreeSet() { this (new TreeMap<E, Object>()); } // default constructor /** * Initializes this TreeSet object to be empty, with elements to be ordered * by a specified Comparator object. * * @param c - the specified Comparator object by which the elements in * this TreeSet object are to be ordered. * */ public TreeSet (Comparator<? super E> c) { this (new TreeMap<E, Object>(c)); } /** * Determines if this TreeSet object contains a specified element. * The worstTime(n) is O(log n). * * @param obj - the specified element sought in this TreeSet object. * * @return true - if obj is equal to at least one of the elements in this * TreeSet object; otherwise, return false. * * @throws ClassCastException - if obj cannot be compared to the * elements in this TreeSet object. * */ public boolean contains (Object obj) { return m.containsKey (obj); } // method contains /** * Inserts a specified element where it belongs in this TreeSet object, * unless the element is already in this TreeSet object. * The worstTime(n) is O(log n). * * @param element - the element to be inserted, unless already there, into * this TreeSet object. * * @return true - if this element was inserted; return false - if this element * was already in this TreeSet object. * */ public boolean add (E element) { return m.put (element, PRESENT) == null; } // method add /** * Removes a specified element from this TreeSet object, unless the * element was not in this TreeSet object just before this call. * The worstTime(n) is O (log n). * * @param element - the element to be removed, unless it is not there, * from this TreeSet object. * * @return true - if element was removed from this TreeSet object; * otherwise, return false. * public boolean remove (Object element) { return m.remove (element) == PRESENT; } // method remove
Section 12.5.2 has an application of the TreeSet class: developing a spell checker.
12.5.2 Application: A Simple Spell Checker
One of the most helpful features of modern word processors is spell checking: scanning a document for possible misspellings. We say "possible" misspellings because the document may contain words that are legal but not found in a dictionary. For example, "iterator" and "postorder" were cited as not found by the word processor (Microsoft Word) used in typing this chapter.
The overall problem is this: Given a dictionary and a document, in files whose names are provided by the end user, print out all words in the document that are not found in the dictionary.
Analysis We make some simplifying assumptions:
- The dictionary consists of lower-case words only, one per line (with no definitions).
- Each word in the document consists of letters only — some or all may be in upper-case.
- The words in the document are separated from each other by at least one non-alphabetic character (such as a punctuation symbol, a blank, or an end-of-line marker).
- The dictionary file is in alphabetical order. The document file, not necessarily in alphabetical order, will fit in memory (along with the dictionary file) if duplicates are excluded.
Here are the contents of a small dictionary file called "dictionary.dat", a small document file called "document.dat" and the words in the latter that are not in the former.
// the dictionary file: a algorithms asterisk coat equal he pied pile plus programs separate she structures wore // the document file: Alogrithms plus Data Structures equal Programs. She woar a pide coat. // the possibly misspelled words: alogrithms, data, pide, woar
To isolate the spell-checking details from the input/output aspects, we create two classes: SpellChecker and SpellCheckerUser.
12.5.2.1 Design, Testing, and Implementation of the SpellChecker Class
The SpellChecker class will have four responsibilities:
- to initialize a SpellChecker object
- to add a word to the set of dictionary words;
- to add the words in a line to the set of document words;
- to return a LinkedList of words from the document that are not in the dictionary.
The use of the term "set" in the second and third responsibilities implies that there will be no duplicates in either collection; there may have been duplicates in the dictionary or document files. Here are the method specifications for the methods in the SpellChecker class:
/** * Initializes this SpellChecker object. * */ public SpellChecker() /** * Inserts a specified word into the dictionary of words. * The worstTime(n) is O(log n), where n is the number of words in the * dictionary of words. * * @param word - the word to be inserted into the dictionary of words. * * @return a String representation of the dictionary. * * @throws NullPointerException - if word is null. * */ public String addToDictionary (String word) /** * Inserts all of the words in a specified line into the document of words. * The worstTime(m) is O(log m), where m is the number of (unique) words * in the document of words. * * @param line - the line whose words are added to the document of words. * * @return a String representation of the document * * @throws NullPointerException - if line is null. * */ public String addToDocument (String line) /** * Determines all words that are in the document but not in the dictionary. * The worstTime(m, n) is O(m log n), where m is the number of words * in the document, and n is the number of words in the dictionary. * * @return a LinkedList consisting of all the words in the document that * are not in the dictionary. * */ public LinkedList<String> compare()
Here are two of the tests in SpellCheckerTest, which has spellChecker (always initialized to an empty SpellChecker instance) as a field:
@Test public void testAddToDocument1() { String actual = spellChecker.addToDocument ("A man, a plan, a canal. Panama!"); assertEquals ("[a, canal, man, panama, plan]", actual); } // method testAddToDocument1 @Test public void testSeveralMisspellings1() { spellChecker.addToDictionarySet ("separate"); spellChecker.addToDictionarySet ("algorithms"); spellChecker.addToDictionarySet ("equals"); spellChecker.addToDictionarySet ("asterisk"); spellChecker.addToDictionarySet ("wore"); spellChecker.addToDictionarySet ("coat"); spellChecker.addToDictionarySet ("she"); spellChecker.addToDictionarySet ("equals"); spellChecker.addToDictionarySet ("plus"); spellChecker.addToDictionarySet ("he"); spellChecker.addToDictionarySet ("pied"); spellChecker.addToDictionarySet ("a"); spellChecker.addToDictionarySet ("pile"); spellChecker.addToDictionarySet ("programs"); spellChecker.addToDictionarySet ("structures"); spellChecker.addToDocumentSet ("Alogrithms plus Data Structures equal Programs."); String expected = "[alogrithms, data, equal]", actual = spellChecker.compare().toString(); assertEquals (expected, actual); } // method testSeveralMisspellings1
The SpellChecker class has only two fields:
protected TreeSet<String> dictionarySet,
documentSet;
The dictionarySet field holds the words in the dictionary file. The documentSet field holds each unique word in the document file—there is no purpose in storing multiple copies of any word.
The definitions of the default constructor and addToDictionarySet methods hold no surprises:
public SpellChecker() { dictionarySet = new TreeSet<String>(); documentSet = new TreeSet<String>(); } // default constructor public String addToDictionary (String word) { dictionarySet.add (word); return dictionarySet.toString(); } // method addToDictionary
The definition of addToDocumentSet (String line) is slightly more complicated. The line is tokenized, with delimiters that include punctuation symbols. Each word, as a token, is converted to lower-case and inserted into documentSet unless the word is already in documentSet. Here is the definition (see Section 0.2.5 of Chapter 0 for a discussion of the useDelimiter method):
public String addToDocument (String line) { final String DELIMITERS = "[ a-zA-Z]+"; Scanner sc = new Scanner (line).useDelimiter (DELIMITERS); String word; while (sc.hasNext()) { word = sc.next().toLowerCase(); documentSet.add (word); } // while line has more tokens return documentSet.toString(); } // method addToDocument
Let m represent the number of words in documentSet. Each call to the TreeSet class's add method takes logarithmic-in-m time. The number of words on a line is independent of m, so for the addToDocument method, worstTime(m) is logarithmic in m.
The compare method iterates through documentSet; each word that is not in dictionarySet is appended to a LinkedList object of (possibly) misspelled words. Here is the definition:
public LinkedList<String> compare() { LinkedList<String> misspelled = new LinkedList<String>(); for (String word : documentSet) if (!dictionarySet.contains (word)) misspelled.add (word); return misspelled; } // method compare
For iterating through documentSet, worstTime(m) is linear in m, and for each call to the TreeSet class's contains method, worstTime(n) is logarithmic in n. So for the compare method in the SpellChecker class, worstTime(n, m) is O(m logn). In fact, worstTime(n, m) is Θ(m log n).
In Chapter 14, we will encounter another class that implements the Set interface: the HashSet class. In this class, the average time for insertions, removals and searches is constant! So we can redo the above problem with HashSet object for dictionarySet and documentSet. No other changes need be made! For that version of the spell-check project, averageTime(n) would be constant for the addToDictionary method, and averageTime(m) would be constant for the addToDocument method. For the compare method, averageTime(m, n) would be linear in m. But don't sell your stock in TreeSets-R-Us. For the HashSet version of the SpellChecker class, the worstTime(m, n) for compare, for example, would be Θ(mn).
12.5.2.2 Design of the SpellCheckerUser Class
The SpellCheckerUser class has the usual main method that invokes a run method, which handles end-user input and output, creates the dictionary and document, and compares the two.
Figure 12.8 shows the class diagrams for this project.
12.5.2.3 Implementation of the SpellCheckerUser Class
The run method scans a file path from the keyboard and constructs a file scanner for that file. Then, depending on whether fileType is "dictionary" or "document," each line from the file is read and added to the dictionary set or the document set, respectively. Finally, the possibly misspelled words are printed. Here is the method definition:
public void run() { final int FILE_TYPES = 2; final String DICTIONARY = "dictionary"; final String DOCUMENT = "document"; final String ALL_CORRECT = " All the words are spelled correctly."; final String MISSPELLED = " The following words are misspelled:";
FIGURE 12.8 Class diagrams for the Spell Checker project
SpellChecker spellChecker = new SpellChecker(); Scanner keyboardScanner = new Scanner (System.in), fileScanner; String fileType = DICTIONARY, filePath; for (int i = 0; i < FILE_TYPES; i++) { final String FILE_PROMPT = " Please enter the path for the " + fileType + " file: "; boolean pathOK = false; while (!pathOK) { try { System.out.print (FILE_PROMPT); filePath = keyboardScanner.nextLine(); fileScanner = new Scanner (new File (filePath)); pathOK = true; if (fileType.equals (DICTIONARY)) while (fileScanner.hasNext()) spellChecker.addToDictionary (fileScanner.nextLine()); else if (fileType.equals (DOCUMENT)) while (fileScanner.hasNext()) spellChecker.addToDocument (fileScanner.nextLine()); }//try catch (IOException e) { System.out.println (e); } // catch } // while fileType = DOCUMENT; } // for LinkedList<String> misspelled = spellChecker.compare(); if (misspelled == null) System.out.println (ALL_CORRECT); else System.out.println (MISSPELLED + misspelled); } // method run
To create the dictionary, worstTime(n) is linear-logarithmic in n because each of the n words in the dictionary file is stored in a TreeSet object, and for each insertion in a TreeSet object, worstTime(n) is logarithmic in n. By the same reasoning, to create the document, worstTime(m) is linear-logarithmic in m (the size of the document file). Also, worstTime (m, n) is Θ(m log n) for the call to the SpellChecker class's compare method.
We conclude that, for the run method, worstTime (m, n) is linear-logarithmic in max (m, n).
The book's website includes the SpellCheckerTest class. There is no SpellCheckerUserTest class because SpellCheckerUser's main and run methods are untestable.
SUMMARY
A red-black tree is a binary search tree that is empty or in which the root element is colored black, every other element is colored either red or black, and for which the following two rules hold:
- Red Rule: if an element is colored red, none of its children can be colored red.
- Path Rule: the number of black elements is the same in all paths from the root to elements with one child or with no children.
The height of a red-black tree is always logarithmic in n, the number of elements in the tree.
The Java Collections Framework implements red-black trees in the TreeMap class. In a TreeMap object each element has a key part—by which the element is identified—and a value part, which contains the rest of the element. The elements are stored in a red-black tree in key-ascending order, according to their "natural" order (implementing the Comparable interface) or by the order specified by a user-supplied Comparator object (there is a constructor in which the Comparator object is supplied). For the containsKey, get, put, and remove methods, worstTime(n) is logarithmic in n.
A TreeSet object is a Collection object in which duplicate elements are not allowed and in which the elements are stored in order (according to the Comparable ordering or a user-supplied Comparator). The TreeSet class is implemented in the Java Collections Framework as a TreeMap in which each element has the same dummy value-part. For the contains, add, and remove methods, worstTime(n) is logarithmic in n.
CROSSWORD PUZZLE

| ACROSS | DOWN |
| 7. The two components of each element in a map collection | 1. The TreeMap field used to compare elements (by their keys) |
| 8. In the TreeMap class, the value returned by the put method when an element with a new key is inserted | 2. In the simple thesaurus project, the class that handles input and output |
| 9. What a TreeSet object never has | 3. For the containskey, get, put and remove methods in the TreeMap class, worstTime(n) is in n. |
| 10. In a red-black tree, what the only child of a black element must be | 4. The type of the constant identifiers RED and BLACK |
| 5. The kind of search in the contains Value method of the TreeMap class | |
| 6. The Path Rule states that the number of black elements must be the same in all paths from the root element to elements with _____ or with one child. |
CONCEPT EXERCISES
12.1 Construct a red-black tree of height 2 with six elements. Construct a red-black tree of height 3 with six elements.
12.2 Construct two different red-black trees with the same three elements.
12.3 What is the maximum number of black elements in a red-black tree of height 4? What is the minimum number of black elements in a red-black tree of height 4?
12.4 It is impossible to construct a red-black tree of size 20 with no red elements. Explain.
12.5 Suppose v is an element with one child in a red-black tree. Explain why v must be black and v 's child must be a red leaf.
12.6 Construct a red-black tree that (when the colors are ignored) is not an AVL tree.
12.7 Guibas and Sedgewick [1978] provide a simple algorithm for coloring any AVL tree into a red-black tree: For each element in the AVL tree, if the height of the subtree rooted at that element is an even integer and the height of its parent s subtree is odd, color the element red; otherwise, color the element black.
For example, here is an AVL tree from Chapter 10:
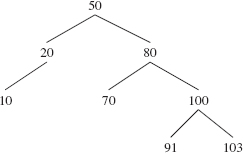
In this tree, 20 s subtree has a height of 1, 80 s subtree has a height of 2, 10 s subtree has a height of 0 and 70 s subtree has a height of 0. Note that since the root of the entire tree has no parent, this algorithm guarantees that the root will be colored black. Here is that AVL tree, colorized to a red-black tree:
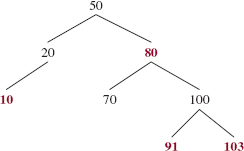
Create an AVL tree of height 4 with min4 elements (that is, the minimum number of elements for an AVL tree of height 4), and then colorize that tree to a red-black tree.
12.8 Suppose, in the definition of red-black tree, we replace the Path Rule with the following:
Pathetic Rule: The number of black elements must be the same in all paths from the root element to a leaf.
- With this new definition, describe how to construct a red-black tree of 101 elements whose height is 50.
- Give an example of a binary search tree that cannot be colored to make it a red-black tree (even with this new definition).
12.9 Show the effect of making the following insertions into an initially empty TreeSet object:
30, 40, 20, 90, 10, 50, 70, 60, 80
12.10 Delete 20 and 40 from the TreeSet object in Exercise 12.8. Show the complete tree after each deletion.
12.11 Pick any integer h ≥ 1, and create a TreeSet object as follows:
let k = 2h+1 + 2h − 2.
Insert 1, 2, 3, ..., k. Remove k, k − 1, k − 2,...,2h. Try this with h = 1, 2 and 3. What is unusual about the red-black trees that you end up with? Alexandru Balan developed this formula.
12.12 From a user's point of view, what is the difference between the TreeMap class and the TreeSet class?
12.13 From a developer's point of view, what is the relationship between the TreeMap class and the TreeSet class?
PROGRAMMING EXERCISES
12.1 Suppose we are given the name and division number for each employee in a company. There are no duplicate names. We would like to store this information alphabetically, by name. For example, part of the input might be the following:
| Misino, John | 8 |
| Nguyen, Viet | 14 |
| Panchenko, Eric | 6 |
| Dunn, Michael | 6 |
| Deusenbery, Amanda | 14 |
| Taoubina, Xenia | 6 |
We want these elements stored in the following order:
| Deusenbery, Amanda | 14 |
| Dunn, Michael | 6 |
| Misino, John | 8 |
| Nguyen, Viet | 14 |
| Panchenko, Eric | 6 |
| Taoubina, Xenia | 6 |
How should this be done? TreeMap? TreeSet? Comparable? Comparator? Develop a small unit-test to test your hypotheses.
12.2 Re-do Programming Exercise 12.1, but now the ordering should be by increasing division numbers, and within each division number, by alphabetical order of names. For example, part of the input might be the following:
| Misino, John | 8 |
| Nguyen, Viet | 14 |
| Panchenko, Eric | 6 |
| Dunn, Michael | 6 |
| Deusenbery, Amanda | 14 |
| Taoubina, Xenia | 6 |
We want these elements stored in the following order:
| Dunn, Michael | 6 |
| Panchenko, Eric | 6 |
| Taoubina, Xenia | 6 |
| Misino, John | 8 |
| Deusenbery, Amanda | 14 |
| Nguyen, Viet | 14 |
How should this be done? TreeMap? TreeSet? Comparable? Comparator? Develop a small unit-test to test your hypotheses.
12.3 Declare two TreeSet objects, setl and set2, whose elements come from the same Student class. Each student has a name and grade point average. In setl, the students are in alphabetical order. In set2, the students are in decreasing order of GPAs. Insert a few students into each set and then print out the set. Include everything needed for this to work, including the two declarations of TreeSet objects, the insertion messages, the declaration of the Student class, and any other necessary class(es).
Programming Project 12.1: Spell Check, Revisited
Modify the spell-check project and unit-test your modified methods. If document word x is not in the dictionary but word y is in the dictionary and x differs from y either by an adjacent transposition or by a single letter, then y should be proposed as an alternative for x. For example, suppose the document word is "asteriks" and the dictionary contains "asterisk." By transposing the adjacent letters "s" and "k" in "asteriks," we get "asterisk." So "asterisk" should be proposed as an alternative. Similarly, if the document word is "seperate" or "seprate" and the dictionary word is "separate," then "separate" should be offered as an alternative in either case.
Here are the dictionary words for both system tests:
a
algorithms
asterisk
equal
he
pied
pile
plus
programs
separate
structures
wore
Here is document file doc1.dat:
She woar a pide coat.
And here is document file doc2.dat
Alogrithms plus Data Structures equal Pograms
System Test 1 (with input in boldface):
Please enter the name of the dictionary file. dictionary.dat Please enter the name of the document file. doc1.dat Possible Misspellings Possible Alternatives pide pied, pile she he woar
System Test 2:
Please enter the name of the dictionary file. dictionary.dat In the Input line, please enter the name of the document file. doc2.dat Possible Misspellings Possible Alternatives alogrithms algorithms dat pograms programs
Programming Project 12.2: Word Frequencies
Design, test, and implement a program to solve the following problem: Given a text, determine the frequency of each word, that is, the number of times each word occurs in the text. Include Big-Θ time estimates of all method definitions.
Analysis
- The first line of input will contain the path to the text file. The second line of input will contain the path to the output file.
- Each word in the text consists of letters only (some or all may be in upper-case), except that a word may also have an apostrophe.
- Words in the text are separated from each other by at least one non-alphabetic character, such as a punctuation symbol, a blank, or an end-of-line marker.
- The output should consist of the words, lower-cased and in alphabetical order; each word is followed by its frequency.
- For the entire program, worstTime(n) is O(n log n), where n is the number of distinct words in the text.
Assume that doc1.in contains the following file:
This program counts the
number of words in a text.
The text may have many words
in it, including big words.
Also, assume that doc2.in contains the following file:
Fuzzy Wuzzy was a bear.
Fuzzy Wuzzy had no hair.
Fuzzy Wuzzy wasn t fuzzy.
Was he?
System Test 1:
Please enter the path to the text file, dod.in Please enter the path to the output file. doc1.out
(Here are the contents of doc1.out after the completion of the program.)
Here are the words and their frequencies:
a: 1 big: l counts: l have: 1 in: 2 including: 1 it: 1 many: 1 may: 1 number: 1 of: 1 program: 1 text: 2 the: 2 this: 1 words: 3
System Test 2:
Please enter the path to the text file. doc2.in Please enter the path to the output file. doc2.out
(Here are the contents of doc2.out after the completion of the program.)
Here are the words and their frequencies:
a: 1 bear: 1 fuzzy: 4 had: 1 hair: 1 he: 1 no: 1 was: 2 wasn't: 1 wuzzy: 3
Programming Project 12.3: Building a Concordance
Design, test, and implement a program to solve the following problem: Given a text, develop a concordance for the words in the text. A concordance consists of each word in the text and, for each word, each line number that the word occurs in. Include Big-Θ time estimates of all methods.
- The first line of input will contain the path to the text file. The second line of input will contain the path to the output file.
- Each word in the text consists of letters only (some or all may be in upper-case), except that a word may also have an apostrophe.
- The words in the text are separated from each other by at least one non-alphabetic character, such as a punctuation symbol, a blank, or an end-of-line marker.
- The output should consist of the words, lower-cased and in alphabetical order; each word is followed by each line number that the word occurs in. The line numbers should be separated by commas.
- The line numbers in the text start at 1.
- For the entire program, worstTime(n) is O(n log n), where n is the number of distinct words in the text. Assume that doc1.in contains the following file:
This program counts the
number of words in a text.
The text may have many words
in it, including big words.
Also, assume that doc2.in contains the following file:
Fuzzy Wuzzy was a bear.
Fuzzy Wuzzy had no hair.
Fuzzy Wuzzy wasn t fuzzy.
Was he?
System Test 1:
Please enter the path to the text file.
doc1.in
Please enter the path to the output file.
doc1.out
(Here are the contents of doc1.out after the completion of the program.)
Here is the concordance:
a: 2
big: 4
counts: 1
have: 3
in: 2, 4
including: 4
it: 4
many: 3
may: 3
number: 2
program: 1
text: 2, 3
the: 1, 3
this: 1
words: 2, 3, 4
System Test 2:
Please enter the path to the text file.
doc2.in
Please enter the path to the output file.
doc2.out
(Here are the contents of doc2.out after the completion of the program.)
Here is the concordance:
a: 1
bear: 1
fuzzy:1,2,3
had: 2
hair: 2
he: 4
no: 2
was: 1, 4
wasn't: 3
wuzzy:1,2,3
Programming Project 12.4: Approval Voting
Design, test, and implement a program to handle approval voting. In approval voting, each voter specifies which candidates are acceptable. The winning candidate is the one who is voted to be acceptable on the most ballots. For example, suppose there are four candidates: Larry, Curly, Moe, and Gerry. The seven voters' ballots are as follows:
| Voter | Ballot |
| 1 | Moe, Curly |
| 2 | Curly, Larry |
| 3 | Larry |
| 4 | Gerry, Larry, Moe |
| 5 | Larry, Moe, Gerry, Curly |
| 6 | Gerry, Moe |
| 7 | Curly, Moe |
The number of ballots on which each candidate was listed is as follows:
| Candidate | Number of Ballots |
| Curly | 4 |
| Gerry | 3 |
| Larry | 4 |
| Moe | 5 |
In this example, the winner is Moe. If there is a tie for most approvals, all of those tied candidates are considered winners—there may then be a run-off election to determine the final winner.
For a given file of ballots, the output—in the console window—should have:
- the candidate(s) with the most votes, in alphabetical order of candidates' names;
- the vote totals for all candidates, in alphabetical order of candidates' names;
- the vote totals for all candidates, in decreasing order of votes; for candidates with equal vote total, the ordering should be alphabetical.
Let C represent the number of candidates, and V represent the number of voters. For the entire program, worstTime(C, V) is O(V log C). You may assume that C is (much) smaller than V. Assume that p5.in1 contains the following:
Moe, Curly
Curly, Larry
Larry
Gerry, Larry, Moe
Larry, Moe, Gerry, Curly
Gerry, Moe
Curly, Moe
Assume that p5.in2 contains the following:
Karen
Tara, Courtney
Courtney, Tara
System Test 1 (Input in boldface):
Please enter the input file path: p5.in1
The winner is Moe, with 5 votes.
Here are the totals for all candidates, in alphabetical order:
| Candidate | Number of Ballots |
| Curly | 4 |
| Gerry | 3 |
| Larry | 4 |
| Moe | 5 |
Here are the vote totals for all candidates, in decreasing order of vote totals:
| Candidate | Number of Ballots |
| Moe | 5 |
| Curly | 4 |
| Larry | 4 |
| Gerry | 3 |
System Test 2 (Input in boldface):
Please enter the input file path: p5.in2
The winners are Courtney and Tara, with 2 votes.
Here are the totals for all candidates, in alphabetical order:
| Candidate | Number of Ballots |
| Courtney | 2 |
| Karen | 1 |
| Tara | 2 |
Here are the vote totals for all candidates, in decreasing order of vote totals:
| Candidate | Number of Ballots |
| Courtney | 2 |
| Tara | 2 |
| Karen | 1 |
Keep re-prompting until a legal file path is entered.
The input file may have millions of ballots, so do not re-read the input.
Programming Project 12.5: An Integrated Web Browser and Search Engine, Part 4
In this part of the project, you will add functionality to the Search button. Assume the file search.in1 consists of file names (for web pages), one per line. Each time the end-user clicks on the Search button, the output window is cleared and then a prompt is printed in the Output window to request that a search string be entered in the Input window followed by a pressing of the Enter key.
For each file name in search.in1, the web page corresponding to that file is then searched for the individual words in the search string. Then the link is printed in the Output window, along with the relevance count: the sum of the word frequencies of each word in the search string. For example, suppose the search string is "neural network", the file name is "browser.in6", and that web page has
A network is a network, neural or not. If every neural network were combined, that would be a large neural network for networking.
The output corresponding to that web page would be
browser.in6 7
because "neural" appears 3 times on the web page, and "network" appears 4 times ("networking" does not count). The end user may now click on browser.in6 to display that page.
Start with your definition of the two specified methods in your Filter class from Part 2 of this project. Use those methods to get each word in the web page—excluding an expanded file of common words, and so on—and determine the frequency of each such word on that web page. Then, for each word in the search string, add up the frequencies.
The only class you will modify is your listener class. Here is the expanded file of common words, which will be stored in the file common.in1:
a
all
an
and
be
but
did
down
for
if
in
not
or
that
the
through
to
were
where
would
For each of the n words in the web page, the worstTime(n) for incrementing that word's frequency must be logarithmic in n. Also, for each word in the search string, calculating its frequency in the web page must also take logarithmic-in-n time, even in the worst case.
For testing, assume search.in1 contains just a few files, for example,
browser.in6
browser.in7
browser.in8
Here are the contents of those files:
browser.in6:
A network is a network, neural or not. If every neural network were combined, that would be a large neural network for networking.
browser.in7:
In Xanadu did Kubla Khan A stately pleasure-dome decree: Where Alph, the sacred river, ran Through caverns<a href=browser.in2>browser2</a> measureless to man Down to a sunless sea.
browser.in8:
In Xanadu did Kubla Khan A stately network pleasure-dome decree: Where Alph, the sacred river, ran Through caverns <a href=browser.in2>browser2</a>measureless to man Down to a sunless neural.
System Test 1(user input in boldface):
Please enter a search string in the input line and then press the Enter key.
neural network
Here are the files and relevance frequencies
browser.in6 7
browser.in7 0
browser.in8 2
Please enter a search string in the input line and then press the Enter key.
neural
Here are the files and relevance frequencies
browser.in6 3
browser.in7 0
browser.in8 1
If the end-user now clicks on the Back button, the input prompt should appear in the output window. If the end-user clicks on the Back button again, the search page for "neural network" should re-appear.
System Test 2:
Please enter a search string in the input line and then press the Enter key.
network
Here are the files and relevance frequencies:
browser.in6 4
browser.in7 0
browser.in8 1
NOTE: The Search button should be green as soon as the GUI window is opened, and only one search string can be entered for each press of the Search button.
1 Equivalently, we could define the rule in terms of paths from the root element to an empty subtree, because an element with one child also has an empty subtree, and a leaf has two empty subtrees. When this approach is taken, the binary search tree is expanded to include a special kind of element, a stub leaf, for each such empty subtree.
2 Recall, from Chapter 4, that a collection is an object that is composed of elements. A collection is not necessarily a Collection object, that is, a collection need not implement the Collection interface. For example, an array is a collection but not a Collection object.