
Chapter 16. Identity Data Architectures
As part of the State of Utah’s enterprise architecture efforts, we completed an inventory of data repositories in the state in early 2002. There were over 250 databases that contained information about individuals and over 175 that contained records about businesses, and this didn’t include spreadsheets, Access databases, and other minor repositories. The problem is that we couldn’t really tell which records in one database were related to the records in another.
Many people are happy to hear that their government can’t link database records, but it hampers many of the electronic government services that citizens would like to see. For example, there are over 20 different databases that keep track of information about health information for children in Utah. The end result is that when a mother brings her newborn in for immunization, the receptionist can’t say, “I see that Johnny hasn’t had his hearing and vision checked. Would you like me to schedule an appointment?” That sort of simple customer relationship management can’t happen when you keep information about your customers in 250 different places.
As you think about the data in your organization, you’ll probably find this story resonating with your experiences. Most organizations have volumes of data that has simply grown and expanded over time in a largely unguided fashion. While we like to think of databases as large repositories of multi-purposed information, most databases are simply persistent data storage for a single application.
Data is important in an identity management architecture (IMA), because identities are usually stored on computers as digital records of some kind. This chapter is about building data architectures for identity data. A data architecture links data to specific business goals and processes, categorizes it, identifies metadata, and defines important details about how it is represented.
Build a Data Architecture
Building a data architecture for identities requires that we consider three different concepts: categorizing identity data, exchanging identity data, and structuring identity data. Figure 16-1 shows these three components along with some of the issues we’ll address for each.
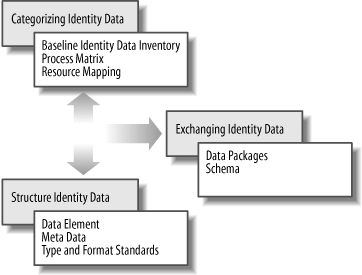
As we discussed in Chapter 2, a digital identity is a record that contains one or more names as well as attributes, preferences, and traits of some person or thing. For our purposes in this chapter, we’ll restrict that definition to records that contain some unique identifier. Moreover, we’ll just refer to the preferences, traits, and attributes as “properties.”
These identities might refer to people, applications, manufactured goods, or other things that the organization cares about. If I asked you to list the identities in your organization, you might include only records that identify people such as employee and customer records. You might miss billing records and might not even think of manufacturing data as a kind of identity data.
We commonly think of “identity management” being about authenticating and authorizing people to take certain actions, but for the purposes of this chapter, we need to expand this definition.
Processes Trump Data
We frequently hear the comment that an organization’s data is one of its most valuable assets. I think that’s probably true, but the fact is that data projects never go anywhere. There’s never money for a project to clean up the data and create enterprise data repositories. What do businesses care about? Processes, because processes achieve business results. Let me relate a story that illustrates this.
Utah, a relatively small state, manages over $1 billion per year in federal government welfare benefits. Each state is responsible for ensuring that welfare recipients are eligible for the benefits that that state distributes. The majority of these benefits are distributed in four major programs that have different eligibility requirements. The job is made more interesting by eligibility interactions—your eligibility for one program could be affected by benefits from another.
Utah, like most other states, had four different computer systems that automated at least part of the eligibility determination process. The lack of a common identity across these four systems was costing the state real money every year in lost time and improperly paid benefits. Utah had tried years before to create a master identifier and then use that identifier in the four separate data repositories so that records could be linked. That had limited success, largely because it relied on the ability of benefits coordinators to link the individuals across four separate systems as they submitted applications.
The IT departments in the three agencies that administer these four programs could never make the case to business leaders to invest in a common identifier, even though there was real need. What ultimately solved the problem was a proposal to revamp the processes that these agencies used to determine eligibility. The new processes provided more decision support to eligibility agents, making their jobs easier and less subjective. That’s something the business could understand. Utah decided to build a new eligibility system at the cost of tens of millions of dollars that served all four programs. Of course, the new system uses a single repository for client data, solving the problems with multiple identities.
When we build data architectures, we’re doing so in support of business processes. Business leaders in Utah’s health and human service agencies could relate to the process problems that their employees faced and saw real advantage (millions of dollars worth) in updating systems that served those processes, so they jumped on board. Process improvement drove the data architecture improvement.
The last chapter talked about using an identity management maturity model to improve processes. Our approach to data architectures is to drive identity data integrity by incrementally making the use of identities more consistent in business process. We’ll use the process inventory as a starting point and process improvement as a driver for changes in the data architecture.
Processes Link Identities
The first step in creating data architectures is to gather baseline information about identities in your organization. The baseline inventory identifies high-level data sources and documents pertinent information about them. To do that, we’ll start with the processes that we identified in the process inventory and find the identity records that are critical to performing those processes. Let’s run through an example to see how that might work.
Employee Provisioning
Suppose you’ve identified “employee provisioning " as one of the processes important to your organization. That process starts when the decision is made to hire an applicant and includes steps such as the following:
Enter applicant data into the HR system.
Identify the hiring manager (e.g., the person who will be the new employee’s boss).
Create a 401K account, payroll account, health insurance, and other benefits.
Assign the employee an office.
Order, install, and set up a computer including application software.
Set up an email account and access.
Set up network access.
Order and install a phone.
Update the right directory or directories with the new telephone number, email address, and office location.
Set up a voicemail account.
Establish access controls for all of the enterprise applications that the employee will need to work.
Issue a credit card for travel expenses.
When you look at the steps in this process, the employee is right up front. Consequently, it’s easy to identify the employee record in the HR database as one of the identity records in this process, but there are others. Here are some of them:
Employee record in the HR system. The employee has an SSN that serves as a unique identifier. Most large organizations also assign a unique employee ID.
Employee record at the 401K, payroll, and benefit providers. These accounts would all have their own unique identifiers. The employee’s SSN can be used to tie them all together depending on your privacy policy and that of your partners.
Record of offices with their location, size, and other properties. Offices might be assigned to certain groups or departments and would need to be associated with their occupants. The identifier is proprietary.
Record of the computer and any installed software. These all have serial numbers. In addition, each network adapter has a MAC address that uniquely identifies it.
Email and network access record in the proper directory or directories. There would be an email address and network identifier assigned as part of this record.
The phone system has records that identify phone lines. The telephone equipment has a serial number, and the phone number itself represents an endpoint on the telephone network. The phone number would need to be mapped to the office where it’s installed.
The voicemail account would have an identifier and be tied to the phone number.
Each enterprise application that the employee needs access to (such as the CRM system) would have some way of identifying the employee.
The credit card represents a separate identity document that the company or its payment partner may track. The credit card number is the unique identifier in this case, and your financial services will likely assign others for online access to the account information.
As we consider a single business process, it’s amazing to see how it can translate into multiple identity records. Process links these records even if the infrastructure does not.
The Identity Data Inventory
Going through the process inventory to find identity records creates an initial identity data inventory . The data inventory is a listing of each identity data source and its contents and other important meta-information. The following attributes should be recorded as part of creating the inventory.
- Name of the data store
This could be something created at the time of the inventory, or it may be a name that the owner or custodian uses to identify the data record.
- Version
Your organization might not think of data stores as something that is under version control, but it’s a useful idea and one you can start with the baseline inventory.
- Definition
Define the data record and its purpose; limit to one or two sentences.
- Process
What process (or processes) does the data record support?
- Identifiers
What fields in the data record are uniquely identifying. There can be more than one identifier. For example, in an HR data record, the SSN and employee number are both identifiers. Many database records have a record number that is unique but has no real identity meaning other than for the record itself. Avoid listing this unless it’s meaningful to the business.
- Properties
These are all of the other attributes, traits, preferences, and characteristics that are included in the record and are used as part of the identity.
- Owner
Who is the owner of the information?
- Custodian
Who is the custodian of the information?
- Notes
Any other relevant information about the identity record should be recorded here.
One approach to creating the data inventory is to have business units create inventories for identity data they own and then to aggregate the results. Be careful, however, to train the people performing the inventory so that you get consistent results. You will also have to take care to ensure you don’t miss data sources that are jointly owned or owned at the enterprise level. As we’ve seen, business function and, hence, process do not always fall within neat organizational boundaries. You may find that it’s more convenient to create the baseline data inventory in conjunction with the process evaluation that we discussed in the last chapter, instead of doing it as a separate step.
Data Categorization
Once a baseline identity inventory has been created, the next step is to categorize the data. We do that using three different techniques. The first is called the identity data audit and asks additional questions about the data in the inventory. The second technique creates an identity map that specializes the identity lifecycle for each data source. The final technique is a process-to-identity matrix that helps us to easily see which identities support which processes.
Identity Data Audit
The purpose of the identity data audit is to answer additional questions about the baseline identity inventory. Identity data audits should be done periodically, say, once a year, as part of maintaining the IMA. During these audits, the inventory is updated and additional data is gathered that is useful in managing the identity data, doing risk assessments for security and privacy purposes, and protecting against loss.
Someone other than the owner or custodian of the identity data should do the audit, although it might be done on the owner’s behalf. In a large organization, the CIO’s office would be responsible for performing the audit. The audit consists of gathering information through a series of questions and then evaluating the information gathered. The questions we ask are very similar to the kinds of questions we discussed for privacy audits in Chapter 4. A privacy audit can easily be folded into the identity data audit, but be sure to include a specific evaluation of privacy in the results.
Here are some of the questions you might want to ask:
What is the purpose of collecting this data?
How is this data being collected?
Were special conditions on its use, such as privacy policies or non-disclosure agreements, established at any time?
Who are the data owner and custodian, if not recorded in the inventory?
Who else can make changes to or administer the data?
Who uses the data, why, and how do they usually access it (i.e., remotely, via the Web, from home, etc.)?
Where and how is it stored?
Is the data dependent on other sources of identity data (such as another directory)? If so, who owns those stores?
Is this data record the canonical or authoritative source for this information? If not, which data record is?
What is the schema for the data?
Is there a related domain model?
How large are the records?
How many records are stored? What is the maximum expected?
What are the data transactions (SQL or other queries) routinely performed on the data store?
Is any of the data stored on devices that are routinely transported off-site such as a laptop or PDA?
Are there backups? If so, you need to answer these same questions about the backups.
How critical is the data to the business?
What are the tolerances for data loss or corruption?
Where and how is encryption used in the record?
Is the data synchronized to another repository or regularly accessed through a bulk data transfer? If so, you need to answer these same questions about any other repository for this data.
Are their access logs for the data?
Where are the logs stored?
Are the logs protected and who has access and administrative rights to the logs?
What other security measures (firewalls, intrusion detection systems, and so on) are used to protect the data?
Who administers those systems?
These are only example questions. You may think of others that need to be asked that are specific to your organization or the data in the inventory. Using the results of the audit, you should evaluate the maturity level of this identity data. Don’t hesitate to assign different maturity levels to different aspects of the identity data. The results of the audit should be shared with the owner and custodian of the identity data so that they can offer feedback and correct misperceptions or mistakes.
As you conduct the audits, you should be on the lookout for the following kinds of issues:
Identity data that is never used
Identity data that is owned by someone who doesn’t use it
Owners at the wrong level (e.g., identity data that has strategic importance but is controlled by a small tactical organization)
Incomplete relationships between identity records or relationships that are enforced outside the system
Identity data that is not located on the same system where it is used
Identity data for which there are multiple copies and no canonical source
Audit data should be stored in a data repository to which multiple people can be given access. For example, some of the information in the audit will be useful for capacity planning, while other information will be useful for security audits. Sharing the data as widely as possible will build support for the process.
Identity Mapping
In Chapter 5, we discussed the lifecycle for digital identities. The purpose of creating an identity map is to instantiate that general model for each identity record. This should result in a flowchart that shows how and where the identity record is created, how it is used, and where it ends up. Figure 16-2 shows an example identity map for an employee record.
The map in Figure 16-2 is greatly simplified from what would really happen to an employee record in even a small organization. However, it illustrates the point that the identity map is an instance of the general lifecycle. The important parts of the diagram show:
Details about how the record is created
Specific instances of how the record used
The process by which the record is updated
How the record is eventually deleted
All of the dependencies between this record and other systems are recorded in the map, as well as the critical systems that can modify the record. Note that in this simple diagram, the HR system is the only system shown that updates the record, but that’s not likely to be the typical case. For example, the payroll system may have access to and update portions of the employee record.

Identity maps are especially useful when you are trying to find the interactions between identity systems and rearchitecting them as part of system or infrastructure upgrades. You may not complete identity maps for every identity record in your organization all at one time, but rather build them as process improvement plans dictate.
Process-to-Identity Matrix
The purpose of the process-to-identity matrix is to relate identities to the processes that they support in a visual way. Using the matrix, we can easily identify records that are used by multiple processes as well as identifying areas where different records are serving the same purpose in different processes and might be combined.
Table 16-1 shows an example process-to-identity matrix drawn from the employee provisioning process that we discussed earlier in this chapter. In this matrix, we can see the identity records used by the employee provisioning process as well as how some of those same records are used by the asset management process, the financial audit process, and the enterprise sales process.
|
Employee record (HR) |
Employee record (payroll) |
Building record |
Computer inventory record |
Email and network record |
Software inventory record |
Phone record |
Voicemail record |
CRM directory |
Travel/card |
Salesman performance record | |
|
Employee provisioning |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ | |
|
Asset management |
✓ |
✓ |
✓ |
✓ | |||||||
|
Financial auditing |
✓ |
✓ |
✓ | ||||||||
|
Enterprise sales |
✓ |
✓ |
✓ |
Notice that the enterprise sales process doesn’t use the employee record or phone record. At the same time, if we were to dig into the inventory and audit data for the salesman performance record, we might find that it contains employee and phone information for the sales team. This illustrates how we can use the matrix to improve processes by normalizing data so that the enterprise sales process derives important employee data from canonical sources.
Identity Data Structure and Metadata
The inventory has created a database of the identity data in use, and the audit has gathered a lot of information about each data source. One of our goals is to establish an authoritative source for each identity. One of the barriers is inconsistent usage and content for identities that should be the same. There are five basic ways that identities can be inconsistent across different data sources:
Inconsistent use of identifiers for the same data. Your organization might have several data records that are used to store customer identities. The identifier in one might be the database record number, another might use the SSN, and a third might use a company-assigned customer number.
Inconsistent values for the same data in a field. The customer’s name might be stored as a single value in one identity record, split into first and last name in a second, and a third might store middle initial and suffix.
Inconsistent names for fields that carry the same data. One identity record may store the customer’s last name in a field called
lnameand another might call itlastname. These are called synonym fields.Inconsistent meaning for field names. Two identity records might use the field name
phone, but one might use it to store the phone number of the customer and the other might use it as a flag to indicate that the salesperson should make a follow-up phone call to the customer. These are called homonym fields.Inconsistent representation. One customer identity record might store the customer number as a number and another might store it as a series of characters.
As you identify elements of identity records that have the same business purpose, you have the opportunity solve these inconsistencies. In most organizations, this will require meetings between the respective owners and custodians of the identity records to hash out a common format for the data elements and choose an authoritative source. The owner of the authoritative source becomes the owner of this data element.
Authoritative metadata records are stored in a metadata repository. As the data elements of identity records are made consistent, metadata records for those elements should be entered in the metadata repository. New projects should be encouraged to use the metadata repository to find identity information they need. Projects should also submit new data element definitions to the metadata repository as they are defined so that other projects can use existing data element definitions instead of creating new inconsistencies that have to be ironed out later.
Even if all of the various data sources can’t be made consistent right now, it’s useful to create the metadata record to store the common format as a goal state so that existing projects can refer to it as legacy systems are maintained and updated.
Table 16-2 shows the metadata fields, describes their purpose, and gives examples of what might be stored in each field for a Social Security number (SSN) element in a hypothetical organization.
|
Field |
Purpose |
SSN example |
|
Data element name |
The field name for this data element |
SSN |
|
Element definition |
The human definition of this data element |
A nine-digit number used by the Social Security Administration and IRS to identify individuals |
|
Owner |
The individual (usually by role) who owns this data element |
HR manager |
|
Scope |
The geographic or organizational scope where this data element has meaning |
U.S. |
|
Business format |
The standard business requirement for the format of this data element |
999-99-9999 |
|
Business length |
The length of the standard business format |
11 characters |
|
Business type |
The common way that business thinks of this data element |
Number |
|
Usage and audit requirements |
List any business restrictions on using or requirements for auditing this data such as privacy policy, HIPPA, etc. |
Example Company, Inc. Policy on Privacy |
|
Exchange format |
The standard format for exchanging this data in the organization |
999999999 |
|
Exchange length |
Length of the exchange format |
9 bytes |
|
Exchange type |
The type of the exchange format |
Character |
|
Storage format |
The format for storing this data element |
999999999 |
|
Storage length |
The length of the storage format |
9 bytes |
|
Storage type |
The type of the storage format |
CHAR or VARCHAR |
|
Storage location |
Location of the authoritative source |
HR employee record system |
|
Encrypted |
Whether this data element should be encrypted |
Yes |
|
Encryption algorithm |
The encryption method used to encrypt this data element |
Blowfish |
The information in the metadata repository represents a valuable resource to system developers. Using the metadata repository, they can find out where to get identity data for their applications, who owns it, and what formats should be used. The metadata repository is also the basis for exchanging identity data .
There are numerous tools and methodologies available for creating metadata repositories. Large organizations will probably have the time and money to invest in these tools and train IT personnel in their use, but even small organizations will benefit from creating a simple metadata repository as the canonical source of information about identity data elements.
In creating the repository, it’s important that it be accessible and that the rules for creating or updating records not be overly onerous. The goal is to create a tool that system architects and others can use to guide their work. For example, the repository should probably be online rather than stored in a spreadsheet on someone’s personal machine.
Exchanging Identity Data
Our goal of creating consistent sources of identity data, combined with the realities of modern distributed organizations, means that there is not likely to be a centralized source of all identity data. Consequently identities will be exchanged between systems, and we should plan for that as part of our data architecture.
We’ve discussed XML standards for exchanging identity data in Chapter 6 and 11. SAML is a standard for exchanging assertions about identity, including access-control information and properties of the identity record. SPML is used to exchange identity data for purposes of provisioning identity systems. XrML is used to exchange information about rights for digital resources.
These standards and others like them should be the basis for your data exchange strategy. Don’t discount the power of standard exchange formats for your data. Whenever you need to exchange identity data, look first at the external standards that are available and choose one of those. Using an external standard is always preferable to creating proprietary internal standards for several important reasons:
You can buy tools that support those standards.
You can hire consultants who understand them.
Thousands of people all over the world are thinking of interesting ways to use them.
Also remember that many XML-based standards are extensible through namespaces and can probably be adapted to suit your needs even when they don’t match exactly.
But, suppose that you can’t find an external standard that meets your needs. The two documents we’ve created so far will help to create your own exchange format. The identity inventory gives the data elements for each identity record in your organization, and the metadata repository gives details, including preferred formats, of the structure for each data element. These two resources can be used to generate XML schema that support the exchange. If the inventory and metadata repository are structured correctly, tools can be bought or written to automatically generate the XML schema. The URL for any exchange schema should be documented in the identity inventory.
When should you avoid XML? XML’s biggest drawback is not that it’s verbose, although it is; it’s the serialization and deserialization of the data in and out of the XML format. To maximize flexibility, you should pay the price of serialization whenever you can afford it, but always under any of the following conditions:
When the data formats have the potential to change in the future.
When the data is being exchanged with an external partner.
When the systems exchanging the data are separated by a WAN. Network latency is likely going to mask any latency introduced through serialization.
When you’re using asynchronous transport for the data. Again, latency in the transport will likely mask the serialization latency.
If you do decide to forego XML, the format can still be derived from the data in the inventory and the metadata repository. Be sure to document the exchange format using some agreed upon standard and reference it in the inventory.
Principles for Identity Data
As you review, consolidate, and create identity data, there are several important principles that you should keep in mind. Some of these are adapted from The Practical Guide to Enterprise Architecture by James McGovern, et al. (Prentice Hall).
- Don’t replicate identities
Wherever possible, you should avoid replicating identity data and ask for it from its canonical source instead. For example, if you need the SSN for an application, it would be better to retrieve it using a SAML request or database query from the HR employee record.
- Business requirements should drive identity replication
If you can’t avoid replicating identity information, you should do so only because the business requirements force the replication. Application developer convenience is never a good reason for replication. One of the primary reasons for this principle is that identity data is often subject to internal and external audit, security, and privacy requirements that will have to be monitored and paid for by the business unit. Replicating identity data increases the cost of these external requirements and so that cost ought to be traded off against business requirements.
- Replicated identities should be read-only
Break this principle at your own peril. As soon as multiple systems can change replicated data, the data will be guaranteed to be out of sync.
- Identity data should be locationally transparent
Applications should be constructed so that they don’t rely on the identity data being in a particular data source or on a particular machine. This will increase flexibility in future application changes. Using SAML, for example, to request properties of a particular identity over the network, rather than reading them using an SQL query over JDBC makes it easy to change out the database for another application without breaking the system.
- Enforce the consistency and integrity of identity data with policies, processes, and tools
The more you can build consistency into the infrastructure, the more likely it is that the data will remain consistent. We’ll discuss the role of policy in this principle in the next chapter.
- Don’t rely on a single validation to check the integrity of identities
Whenever identity data will be collected and used in multiple locations, each system should perform validity checks on the identity data as part of its processing. These checks should ensure that the identities conform to the relevant schema and any business rules documented in the inventory or metadata repository.
- Use open standards rather than proprietary standards
As we’ve discussed, open standards have a number of advantages over proprietary standards.
- Use encryption to protect sensitive identity elements
Sensitive identity data should never be stored unencrypted. Usually, encrypting the entire record is too disruptive, because it has to be unencrypted each time any part of it is used. A better strategy is to encrypt just the data elements that are sensitive. As we saw in Chapter 6, the XML Encryption standard can be used to encrypt only certain elements in an XML record.
Conclusion
We’ve discussed creating data architectures for identities by performing a baseline inventory, categorizing the results, creating a common data representation standard in the form of a metadata repository, and establishing exchange standards for important data. The final word of advice I’d give on data architectures is to approach them piecemeal. Nothing will kill your data architecture efforts faster than trying to create a huge monolithic project. Drive the effort from process improvement projects that fall out of the process inventory. Scope them so that no project requires “solve all our data inconsistency problems” as the first step.