
CHAPTER 16
Data Synchronization, MDM System Testing, and Other Implementation Concerns
This chapter deals with several complex implementation concerns facing MDM designers. We will discuss batch and real-time synchronization issues, MDM system testing concerns, options to consider when designing MDM application and presentation layers components, as well as concerns related to the MDM deployment infrastructure. Combined with the previous discussions on MDM architecture, design, key functional requirements, and specific features, as well as the in-depth review of how to build the MDM business case and define the MDM roadmap, this chapter should prepare readers to fully appreciate not just the complexity and magnitude of MDM, but also the need, the value, and the critical nature of data governance as a key enabler and a necessary component of any successful MDM initiative. We discuss key aspects of data governance in Chapter 17.
Goals of Data Synchronization
Data synchronization is one of the most difficult and frequently underestimated areas of Master Data Management. The purpose of this section is to describe a typical implementation of an MDM synchronization solution in the context of the following use case.
Note The discussion that follows offers a hypothetical implementation approach where many technical details/components represent a conceptual or logical view of the implementation solution rather than a specific vendor product or custom-built code. For consistency and continuity, wherever possible we tried to map these logical components to the various MDM Data Hub architecture components and services that we described in Parts II and IV of the book.
Technology Approach to Use Case Realization
When a customer initiates contact with the ABC Company, the customer has to provide some pieces of identification information. Depending on the customer service channels supported by the ABC Company, the identification information may vary from officially issued credentials such as SSN, driver license, or passport, to authentication credentials the user has to possess in order to access the website or a customer service call center. Regardless of the authentication method, the MDM Data Hub would have to map user credentials to the identification attributes that are required to perform user identification and matching (see Chapter 14 for details). The MDM Data Hub services are capable of recognizing the user as an existing or a new customer. The ABC Company business requirements specify that for existing customers, all relevant customer information and recent contact history are available for viewing and editing to the appropriate company personnel subject to the constraints imposed by the data visibility and security policy. Transactional information at each point of contact is captured in the legacy systems, while all updates and new pieces of identity information for the existing customers are captured and stored in the MDM Data Hub. At the same time, new customers will be recognized by the appropriate Data Hub service, and all relevant information will also be captured and stored in the MDM Data Hub using the transformation rules defined in the MDM Metadata Repository (see Chapter 5 for a discussion on the role of a metadata repository in MDM systems).
Given this overall process view, we will discuss the technology approach to developing an MDM solution in the context of the MDM design classification dimension, and specifically will focus on the MDM Data Hub architecture styles discussed in Chapter 4. Let’s start with the reconciliation engine style Hub, and then look at the additional considerations relevant to an MDM Data Hub style known as the Transaction Hub. Just to recap, in discussing MDM design classification dimensions and the corresponding architecture styles, we have shown that an MDM Data Hub system can act as a registry of key master attributes (Registry-style Hub), a pass-through “slave” (reconciliation engine) of the legacy systems, or it can be a master of some or all entity attributes (in our use case scenario, this entity represents customer profile data).
MDM Data Hub with Multiple Points of Entry for Entity Information
As stated in our use case scenario, a customer can interact with the ABC Company across a variety of different channels, including Web self-service, Interactive Voice Response (IVR) telephone system, customer service representative access via telephone or in person, in-branch interactions, and so on.
The ABC Company’s stated goal of the MDM project is to enable and ensure a consistent customer experience regardless of the channel or the interaction mode, and this experience should be achieved by creating a unified, holistic view of the customer and all of his or her relationships. Further, this holistic view has to be available on demand, in real time, to all channels supported by the ABC Company.
Let’s start with the reconciliation engine style design approach. This architecture style positions the MDM Data Hub as a “slave” (reconciliation engine) for the existing data sources and applications. With this background, let’s consider the specific process steps and Data Hub components involved when a customer interacts with one of the ABC Company’s customer touch points. Figure 16-1 illustrates the key logical steps of the integrated solution.
Note We focus on the process steps that involve or require Data Hub services directly. External systems interactions such as authentication and authorization actions to gain access to the channel via integration with or delegation to the enterprise security system are implied but not elaborated on for the sake of simplicity.
1. At the point of contact, the customer provides his or her identification information (for example, name and address or the user ID established at the time of enrollment in the service). The information is scanned or entered using a customer identification application (login) interface that should be designed to enforce data entry formats and attribute values whenever possible. In the case of a self-service channel, the information is entered by the customer; otherwise, it is done by an authorized employee of the ABC Company. The identification application uses one of the published Data Hub services to initiate a check to verify whether the customer record exists in the Data Hub. The service forms a message with the received identification information using a standard matching message format. The message is published to the Enterprise Message Bus (EMB)—a middleware technology that is often present as a component of the service-oriented architecture and frequently referred to as the Enterprise Service Bus (ESB). The first functional component to receive the message is the EMB Message Validator, which analyzes the message and confirms the correctness of the format. It also validates that the message context meets minimum data requirements. For flexibility and manageability, the MDM Data Hub system provides a management facility that allows users to configure minimum data requirements based on the appropriate metadata definitions.
2. The message is forwarded to the EMB Transaction Manager. The message gets assigned a unique transaction ID by the EMB Transaction Manager’s Key Generator.
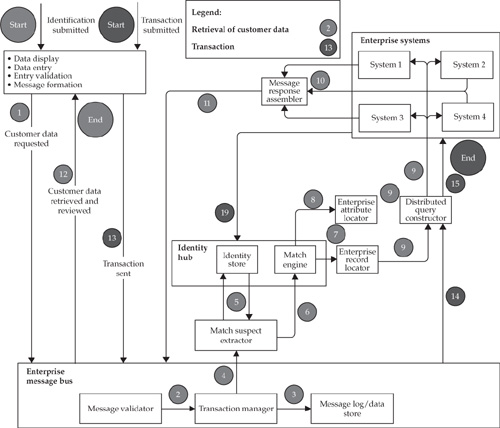
FIGURE 16-1 Data synchronization and key synchronization components
3. The Transaction Manager can optionally log transaction information, including the transaction type, transaction originator, time of origination, and possibly some other information about the transaction.
4. The Transaction Manager forwards the message to the Match Suspect Extractor.
5. The Match Suspect Extractor reads the identification parameters in the message and creates an MDM Data Hub extract with suspect matches. It can also contain records that were selected using various fuzzy matching algorithms.
6. The Match Suspect Extractor sends the extract message to the Match Engine. The Match Engine is an MDM Data Hub component that performs the match. It can return zero, one, or multiple matches. The engine computes the confidence level for the matched records. We assume that the matching engine is configured for two thresholds: T1 < T2 (the two-threshold model is discussed in Chapter 14).
a. If the confidence level is above T2 and only one match is found, then the Match Engine returns a unique customer ID along with additional data obtained from the Data Hub and/or external vendor knowledge bases. To improve the confidence of the match process, our ABC Company can choose to purchase and integrate an external information file (a knowledge base) that contains “trusted” information about the customer.
b. If the match confidence level is between T1 and T2 and multiple suspect matches are found, the identification application may initiate a workflow that prompts the user for additional identification information, or alternatively can ask the user to select the right customer record from the returned suspect match list. The latter can trigger another iteration of matching, usually described as a part of the information quality loop.
c. If the match confidence is below T1, the match service returns a notification that the customer record is not found. The user may choose to modify the identification information and resubmit the modified record for identification.
7. The Transaction Manager orchestrates other MDM Data Hub services to gather additional information about the identified customer. The customer identifier is sent to the Enterprise Record Locator, which contains a cross-reference facility with linkage information between the Data Hub keys and the source system keys. The source system keys are returned to the Transaction Manager (see Chapter 6 for a discussion on MDM Data Hub keys and services).
8. The Transaction Manager invokes the Enterprise Attribute Locator service to identify the best sources of data for each attribute in the enterprise data model.
9. The Transaction Manager sends inquiry messages to the source systems through the EMB, where it invokes the Distributed Query Constructor service, which generates a distributed query against multiple systems.
10. The source systems process the query request messages and send the messages to the Response Assembler. The Response Assembler assembles the messages received from the Data Hub and source systems into the Response Message.
11. The assembled message is published to the EMB. The Transaction Manager recognizes the message as part of the transaction that was initiated by the request in step 2. The Transaction Manager returns the message to the requestor and marks the transaction complete.
12. The ABC Company customer service employee who initiated this transaction in the first place can review the returned message and take advantage of the accurate and complete information about the customer and his or her transactions, which gives the customer service employee the required intelligence. Because the customer is identified with the appropriate degree of confidence, the customer service employee can initiate a business transaction to serve a customer request. For example, this could be a transaction that involves data changes to the customer information. Changes generated by the transaction are sent to the corresponding legacy system, whereas the customer identification information message is sent to the MDM Data Hub via the EMB.
13. The Data Hub initiates a change transaction by sending a transaction message to the EMB. The transaction may result in changes to the critical attributes used for matches. As we discussed in previous chapters, this in turn can trigger merges and splits in the MDM Data Hub. Splits can cause the creation of new customer IDs, whereas merges result in the deletion of some customer records.
a. Every time the customer keys stored in the MDM Data Hub change, the corresponding changes in the Enterprise Record Locator (also referred to as the Cross-Reference Record Locator) must be applied as a single transaction.
b. When the Data Hub and the Cross-Reference Record Locator are updated, the ABC Company’s auditors may request a detailed record of these changes. A sound practice is to design the MDM Data Hub to preserve the history and change activity of all updates to the Data Hub, including archiving business events that triggered the change in the first place. Thus, a good MDM Data Hub design should provide for configurable archival and purge components and services. Typically, operational needs for archival and logging are relatively short term and limited to a few days or a few weeks maximum. Audit requirements are driven by regulatory compliance and legal requirements and typically specify relatively long data retention terms that can cover a span of several years. Active access, retention, archival, and purge requirements could be quite significant and thus must be defined based on the needs of all stakeholder groups and accounted for in the MDM business case and the roadmap.
14. The EMB makes messages available to the source systems in either a push or pull mode. In either case, operational source systems can accept or reject a change. The data governance group, working with the business systems owners, should establish rules around the level of control each system will have in terms of the ability to reject the changes coming from the Data Hub. Because customer identity updates can come from multiple systems, the project design team must establish a set of rules that can resolve data synchronization conflicts for each attribute. Typically, the source and the date/time of the change at the attribute level are the most important factors that must be taken into account.
Considerations for the Transaction Hub Master Model
If our ABC Company plans to transition the MDM solution from the Hub Slave model to the Hub Master model, the resulting impact on the information flows and processes can be quite profound. In the Hub Master scenario, in order to support our use case, all customer profile data (whatever attributes are determined to constitute the customer profile) is entered through a new Customer Profile Management application pointed directly to the MDM Data Hub. Customer profile attributes that were previously editable through multiple legacy applications should now be protected from changes through these applications and should become read-only attributes. A typical scenario implementing this approach may be as follows:
• The end users can search for a customer using identity attributes.
• As soon as a customer is found and selected by the end user, all customer profile information may be retrieved from the Data Hub and displayed in the legacy application screen.
• With a single point of entry into the MDM Data Hub, data synchronization in the Hub Master scenario is easier, but in order to achieve this state, some significant work in legacy applications must be performed to ensure that they do not enter or change customer information. This may not be what the enterprise is willing to do.
Therefore, overall Hub Master implementations are quite difficult, particularly in organizations with large and heterogeneous legacy environments, multiple generations of legacy systems, and complex delta processing and synchronization that involves many legacy systems. In practice, legacy-rich organizations should start implementing MDM solutions in a Hub Slave (reconciliation engine) style, with the Data Hub providing identification services as discussed in the previous section. Conversely, for new organizations or brand-new business units, the legacy is not as big an issue, and a Transaction Hub (Hub Master) might be a viable option. Serious analysis is required to determine the right end-state of the MDM solution and the actionable implementation roadmap.
Real-Time/Near-Real-Time Synchronization Components
The ABC Company use case we described in the previous sections is useful to show not only the synchronization data flows but also MDM Data Hub components and services that should be in place to implement an enterprise-scale data synchronization solution. Let’s take a closer look at these components and services.
Legacy System Data Entry Validation Component This component serves as the first barrier preventing erroneous data entry into the system. Good information management practice shows that it is important to bring data validation upstream as close to the point of data entry or creation as possible. Data validation components restrict the formats and range of values entered on the user interface screen for a data entry application (for example, an account opening or user registration applications). Ideally, the MDM designers should strive to make data entry validation in the legacy systems consistent with the Data Hub validation requirements.
Legacy System Message Creation and Canonical Message Format Component Each legacy system that needs to be integrated into the real-time synchronization framework must have components responsible for creating and publishing the message to the Enterprise Message Bus. The message must conform to the canonical message format—that is, an enterprise standard message used for application-independent data exchange (the canonical data model and formats are discussed in Part II of the book). The canonical message format and the canonical data model are the enablers of effective data synchronization.
Legacy System Message-Processing Components Each legacy system should be able to receive and process messages in a canonical format. The processing includes message interpretation and orchestration in terms of native legacy system functions and procedures.
Message Validation and Translations Message validation components must be able to validate the message structure and message content (payload). These components should also be “code translation aware” in order to translate system-specific reference code semantics into enterprise values, and vice versa.
Transaction Manager and Transaction Logging Service As the name implies, the Transaction Manager is responsible for the execution and control of each transaction. The Transaction Manager registers each transaction by assigning a transaction identifier (transaction ID).
All transactions in the transaction life cycle are recorded in the Transaction Log using Transaction Logging Service, regardless of whether they are successful or not. Transaction Log structures, attributes, and service semantics are defined in the MDM Metadata Repository. The Transaction Manager orchestrates and coordinates the transaction processing of composite, complex transactions, and interfaces with the exception-processing and compensating transaction management components and services if a transaction fails for any reason.
Match Suspect Extractor When a new piece of customer information arrives (new customer record, change in the existing customer record, or deletion of an existing record), the matching engine needs to receive an extract with suspected records for which the match groups must be recalculated. It is a challenge to construct this extract to be small enough to support real-time or near-real-time match calculations and at the same time to capture all impacted records. Because the match rules and the attributes used for matching have a tendency to evolve over time, it is a good practice to make the Match Suspect Extractor a configurable component that uses metadata definitions provided and maintained in the MDM Metadata Repository through an administrative application interface.
Identity Store The Identity Store maintains the customer data with the superset of records that includes records from all participating systems in scope. The attributes are limited to the critical attributes needed for matching (see Chapter 14 for a detailed discussion on critical data attributes). Also, the Identity Store includes the Match Group keys. In a typical MDM system for a large enterprise, the Identity Store may have hundreds of millions of records. A lot of computer power and advanced performance optimization techniques are required to enable high throughput for both reads and updates. In addition, the Identity Store holds some amount of historical information. Typically, it is limited to recent history that enables error recovery and the resolution of operational issues.
Change Capture This component is responsible for capturing the record or records that have been changed, added, or deleted. Pointers to these records are the entry information required by the Match Suspect Extractor to begin match processing.
Purge, Archival, and Audit Support Purge and archival components are responsible for purging records to get rid of history records that exceeded the predefined retention threshold. The audit features allow MDM Data Hub solutions to archive purged records for potential audit or investigation purposes. More importantly, though, audit features are a required functionality to comply with regulatory requirements such as those of GLBA, the Sarbanes-Oxley Act, and many others. Similar to the Transaction Log Store described earlier, we recommend using a separate Data Store to maintain audit records and to support audit reporting. It should be noted that regulatory requirements for purging may apply to former customers whose records reside in multiple systems. In order to correctly tell present customers from former customers, a holistic cross-system view of a customer must be maintained to meet the purge requirements, which is the core MDM objective.
Enterprise Record Locator The Enterprise Record Locator contains information about all system source keys and the Identity Store keys. The Enterprise Record Locator is the key component that stores cross-system reference information to maintain the integrity of the customer records. The Enterprise Record Locator can be implemented as a dedicated subject area of the Metadata Repository, and should support many-to-many relationships between source system keys. Services built around this component should cross-reference keys from all involved systems, including the Data Hub, and deliver this service with high throughput, low latency, and high concurrency.
Enterprise Attribute Locator This component enables the data governance group to specify the best trusted source of data for each attribute in the canonical data model. The Enterprise Attribute Locator stores pointers to the best source of data, and can be implemented as a subject area within the Metadata Repository. An administrative interface is required to maintain these pointers. The Enterprise Attribute Locator information can be defined at different levels of trust:
• System-level trust, when a certain system is selected as the trusted source for all profile data.
• Attribute-level trust, when a single trusted source is defined for each attribute in the canonical data model.
• Trust at the level of attributes and record types, when a single trusted source is defined for each attribute in the canonical data model with additional dependencies on the record type, account type, and so on.
• Trust at the level of attributes, record types, and timestamps is similar to the trust level defined in the previous bullet, except that it includes the timestamp of when the attribute was changed. This timestamp attribute is an additional factor that can impact the best source rules.
Race Condition Controller The Race Condition Controller is responsible for defining what change must prevail and survive when two or more changes conflict with each other. This component should resolve the conflicts based on the evaluation of business rules that consider, among other factors, the source of change by attribute and the timestamp at the attribute level. This component should be configurable, metadata driven, and have an administrative application interface for ease of administration.
Distributed or Federated Query Constructor When the customer data is distributed or federated across multiple data stores, this component should be able to parse a message and transform it into a number of queries or messages against legacy systems.
Message Response Assembler Once each of the source systems participating in creating a response successfully generates its portion of the response message, the complete response message must be assembled for return. This is the job that the Message Response Assembler is responsible for.
Error Processing, Transactional Integrity, and Compensating Transactions At a high level, there are two ways to handle transactional errors. The conservative approach enforces all-or-nothing transactional semantics of atomicity, consistency, isolation, and durability (ACID properties) and requires the entire distributed transaction to complete without any errors in order to succeed. If any step in this transaction fails, the entire transaction fails and all its uncommitted changes are rolled back to the pre-transaction state. The other transaction model is to support a complex multistep transaction in such a way that even though some steps may fail, the entire transaction may continue depending on the transactional context and the applicable business rules. Typically, these are long-running complex and composite business transactions that are more difficult to design and manage. The integrity of these transactions is not ensured via an automatic rollback and usually requires a design of what is known as “compensating transactions.”
Hub Master Components In the case of the Hub Master, such as the Transaction Hub, all attributes that are maintained in the Hub Master must be protected from the changes in the source systems. In this scenario, the Data Hub becomes the authoritative source, the point of entry, and the system of record for the data it manages. The MDM Master Data Hub should include a set of services, components, and interfaces designed to maintain the Master Hub attributes centrally. In other words, all other applications and systems in the scope of the MDM Customer Master (for example, supporting our use case scenario) should access customer data from the Data Hub. The Hub Master will typically require the maintenance of relationships, groups of customers, and other associations and aggregations (these topics are discussed in Chapter 15).
Batch Processing
In the previous section, we concentrated on a real-time data synchronization solution that works for both the slave and the master models of the MDM Data Hub. Let’s consider the question of whether the MDM system still needs a batch data synchronization facility that may use Extract, Transformation, and Load (ETL) processes and components. One way to think about this question is to decide whether the real-time messaging infrastructure and the appropriate MDM Data Hub services can be used to process large sets of data synchronization messages as a single large batch. The answer to this question consists of at least two parts.
The first part of the answer is based on the fact that almost any established enterprise must maintain reliable, mission-critical batch processes that are aligned with the business models of the industry the enterprise operates in (for example, nightly updates of inventory levels, trade settlements, insurance claim processing, and so on). This means that there will continue to be the need to process some aspects of Master Data Management in batch mode.
The second part of the answer is that in cases where the MDM Data Hub has to process millions of data changes at a time, batch processing is the right operational and technical approach, although the process itself has to be carefully designed and optimized to fit the available batch window. The latter point can be addressed effectively and efficiently by using mature technology such as ETL.
Indeed, the primary goal of ETL is to support large-scale batch transformations from one form of input data (for example, account-centric structure) to another, potentially higher level of the output or target data (for example, a customer-centric structure). Contemporary ETL technologies can parallelize the majority of transform and load operations and thus can achieve very high throughput and performance. This is particularly important for initial data load processing and for rapidly bringing additional data sources into the Data Hub. Very large batches are required not only to seed the Data Hub initially; mergers and acquisitions, changes in branch office hierarchies, new lines of business that have to be included in the scope of the MDM Data Hub, and other business events may result in creating very large data files that have to be cleansed, transformed, and loaded into the Data Hub. In other words, ETL-style batch data processing—including data load and, by extension, data synchronization—are required for any enterprise-scale MDM implementation. We discussed the architectural approach to data loading in Chapter 5, where we introduced the Data Zone architecture approach to data management (refer to Figure 5-2). A simplified high-level view of ETL processing from the data sources through the loading and staging areas to the Data Hub is shown in Figure 16-2.
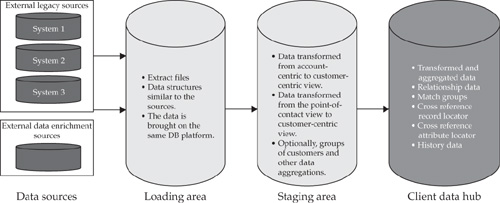
FIGURE 16-2 ETL processing
The process begins with file extraction from legacy systems. The file extracts are placed in the Loading Area and loaded into tables. The purpose of this area is to bring all the data onto a common platform. The Loading Area preserves the data in its original structure (in our example, account centric) and makes the data available for loading into the staging ares.
The following types of transformations occur when the data is loaded into the staging area:
• Core transformations to the customer-centric view. In addition, the staging area must preserve legacy system keys. They will be used to build the cross-reference Record Locator Service.
• Reference code translations are used to bring the codes into the Data Hub–specific format.
• Data validation occurs and the beginning of exception processing for records that do not comply with established standards. The records enter the exception processing framework from the staging area.
• The data defaults are checked against declared definitions.
• If data enrichment processing from an external vendor or vendors is in scope, it can optionally be done in the staging area. Otherwise, data enrichment occurs in the Data Hub.
From the staging area, the data is loaded into the MDM Data Hub. The Data Hub data load performance has to be compatible with the processing throughput maintained by ETL.
The Data Hub should support the following data transformations and manipulation functions:
• One of the most significant functions is the cross-reference record locator (Enterprise Record Locator). This component consists of the cross-reference registry and services that manage the linkages between the customer keys stored in the Data Hub and legacy systems in scope. In the batch-processing mode, this component must be able to generate the Data Hub keys, cross-reference them with the legacy keys stored in the staging area, and persist the cross-reference information in the Data Hub.
• The Match Suspect Extractor component must be able to work in batch mode. Besides this requirement, this component is quite similar to the match extract component described in the real-time processing section. The main functional difference between the two component types is that for real-time processing, the Match Suspect Extractor generates an extract based on a single record change, while the batch version of the Match Extractor operates on multiple records caused by processing changes in the batch.
• Matching is one of the core functions of the MDM Data Hub. This function should be available in real-time and batch modes, and it should support batch mode for the initial data load and delta processing.
• As mentioned earlier, if data enrichment processing from an external vendor or this chapter. The Data Hub also provides support for data aggregation, merging of matching records, and other data consolidation activities, including processing of entity groups and relationships.
• Batch processing has to be able to resolve the race conditions mentioned earlier in this chapter. The Data Hub also provides support for data aggregation, merging of matching records, and other data consolidation activities, including processing of entity groups and relationships.
The distribution of MDM data manipulation functions and components between the staging area and the Data Hub often depends on the business requirements, legacy data landscape, and infrastructure requirements. The demarcation line is therefore flexible, and it can be moved.
A significant practical consideration for designing and deploying these components is the type of vendor solutions that the project team selected. The choice is usually between an ETL and an MDM vendor’s products. Some MDM vendors offer functionality that traditionally belongs to the ETL and/or messaging vendor space. For instance, some MDM vendors offer their own staging area implementation and the corresponding procedures. A question that has to be answered is whether it is a good idea to bundle ETL transformation inside the MDM vendor solution. What follows is a list of considerations that have to be taken into account when answering this question.
Pros:
• Some MDM vendors provide a common framework, metadata, and component reuse capabilities for both batch ETL and real-time processing. In general, however, ETL vendor products can complement but do not replace real-time data transformation vendor products. Therefore, we can recommend that data validation components, match extractors, race condition components, and others must be evaluated, designed, and developed for both real-time and batch modes.
• This common synchronization framework offers a shared standard exception–processing facility.
Cons:
• Most of the MDM vendor products are relatively young and the Data Hub solution space has lots of room to mature. It is not unreasonable to assume that even if the organization is building an MDM solution today using a particular technology choice, it may decide to replace it tomorrow. Given this level of uncertainty, we believe it’ll be preferable to use an industry-proven ETL vendor solution to handle the functions that are native to ETL.
• It is reasonable to assume that the performance of ETL tools and real-time components will not be equal, leading to a decision to use these tools and techniques separately to satisfy specific business and operational requirements.
Synchronization and Considerations for Exceptions Processing
Real-life operational data processing often encounters conditions different from the expected outcome of “normal” processing. These conditions can be caused by unexpected data values, violations of referential integrity, violations of sequence of record processing, access problems, system or object availability problems, and so on. These conditions are known as exceptions. Exceptions can impact and even disrupt operations. Thus, the MDM Data Hub architecture should include exception capture, management, and root-cause impact analysis and reporting.
Having a common standard framework for exception processing is a great idea. In its absence, different development groups may create their own disparate exception-processing solutions. A systematic approach to exception processing that will include batch and real-time operations will pay off multiple times. This framework should be able to create and maintain an exception-processing flow by orchestrating exception-processing scenarios. Like many other Data Hub services and processes, the exception-processing framework has to be metadata driven, and, at a minimum, the framework should define a number of steps that have to be performed for each exception or error capture. In addition, such a framework should define a common format for the exception messages that contains:
• The process type and identifier (real time or ETL)
• The transaction identifier
• The module where the error occurred (for example, staging area, matching engine, Data Validator)
• The error message
Once the exceptions are captured, they have to be presented to the appropriate users and applications designed for exception handling and resolution. Exception handling and resolution may require separate administrative applications and exception-processing workflows.
An interesting concern about the exception-processing framework and its boundaries has to do with the scope of the exceptions—for example, should the exception framework go beyond the synchronization components? We believe that it should. For example, consider exceptions caused by unauthorized users or invalid requests.
It is true that data visibility and security (discussed in detail in Part III of the book) can significantly impact the processes surrounding an MDM Data Hub by applying additional constraints to the already complicated Data Hub services, ad-hoc queries, and predefined access routines. To state it differently, many data exceptions are caused by data security controls. In this case, exception processing needs to capture all relevant information about the user identity, the content of the request, and a statement of the security policies and rules that the system has to follow to process the request. The result of this analysis could indicate not a technology failure but rather an attempt at the unauthorized request or an incorrect, incomplete, or contradictory set of policies and rules.
The variety of exception types leads to the creation of numerous exception-processing workflows and organizational roles that are to be involved in exception handling. Therefore, exception processing requires robust and configurable mechanism distributing and routing the exceptions to the right organizational roles. Data exceptions may also contain sensitive information requiring visibility and security constraints to be imposed on the access to exception processing data.
As we discussed in Chapter 14, the MDM Data Hub supports many attributes that can be used to identify an individual and/or organization. From the synchronization perspective, a decision must be made as to when an identity of the party must be reevaluated. For example, if a name, phone number, address, and credit card number are used for identification, should we recompute the Match Group identifiers every time one of these attributes changes? If a phone number change occurs because the phone number was initially incorrect, then this may be a reason for the match group recomputation. On the other hand, if a correction has been made because a well-known customer changes his or her phone number, there is no need to trigger the match group identifier recomputation. A good practice in this case is to make sure that attribute changes are tagged with the reason for the change, a timestamp of the change, and other decision-driving attributes. These attributes should be used by the MDM Data Hub to help make a decision about whether the change should trigger the match process. Typically, as soon as a customer record is identified with a sufficient level of confidence, it should not change the associated identity. This simplifies data synchronization considerably.
Given that large companies have many systems that are to be integrated within the MDM framework, a significant milestone from the data synchronization perspective would be a detailed definition of system on-boarding. This term refers to a set of standards and processes that determine what applications and attributes each system should adjust, modify, or extend as a prerequisite to being integrated into the enterprise MDM solution. These standards and processes should typically cover multiple scenarios—for example, real-time vs. batch integration, service integration using SOA principles vs. native APIs, integration in a pure “slave” scenario or as a master for certain attributes, and so on.
The granularity of the standard messages for inter-application exchange of master data must also be considered. In general, a standard message is typically defined at the entity (for example, customer) level. This message is represented by multiple data model entities that, in the case of a Customer or Party Domain, may include customer name, address, and many other entities and attributes comprising the customer profile. Similar considerations apply to other domains (for example, Products). If some entity or entities are updated much more often than others, it may be a good idea to consider a separate message that handles only the frequently changing entities. It is always a trade-off between the simplicity of having a single standard message and enterprise MDM system performance considerations, and the decision has to be made only after a careful analysis of the nature of the attribute change, attribute change frequency, number of applications/components/services that consume these attributes, the throughput of the messaging infrastructure, and so on. In some cases, the analysis may indicate that more complex hierarchies of standard synchronization messages may be required.
Testing Considerations
Testing is a critical work stream that is often underestimated, especially in the context of an MDM Data Hub. When we discuss the topic of testing, we include several testing categories and dimensions. On the one hand, testing should include functional testing, data testing, and nonfunctional testing (the latter includes performance, scalability, throughput, manageability, resilience to failure, interface compliance, and so on). On the other hand, testing is an iterative process that should be defined and implemented as a sequence of iterative steps that may include a unit test, a system test, an integration test, a QA test, and a user acceptance test (UAT). When embarking on an MDM project, the project team has to make sure that the scope of testing is clearly defined and mapped to the business requirements for traceability, and to the project acceptance criteria for project management and stakeholder buy-in.
We further suggest that regression testing be performed for each testing type (there are numerous definitions and published works related to regression testing1). Testing activities should begin very early in the project’s life cycle. The testing team should develop a comprehensive test strategy as soon as the business requirements are defined and some initial technical elaboration is complete. Best practices suggest that the test cases should be developed in parallel with the software requirement and design specifications. For example, when the team uses a Rational Unified Process2 and defines use cases to articulate software requirements, the test cases can be (and should be) developed at the same time as the use cases.
MDM technologies and MDM use cases introduce additional complexities to the test strategy. In order to illustrate this complexity, let’s consider the following categories of test-related issues:
• MDM testing of data and services
• Match group testing
• Creation and protection of test data
Testing of MDM Data and Services
The high-level approach to testing MDM data and services has to follow a standard testing methodology that at a minimum defines the following test levels:
• Unit testing This testing is performed by developers, who verify and certify their own work. They have to come up with their own test cases. Typically, these test cases are executed automatically. Some manual testing may also be involved. Unit testing is limited in scope and often tests only individual components rather than the end-to-end solution. Unit testing also addresses the validity of internal components that may not be included in other test groups (for example, internally called functions, procedures, and services).
• System testing, also known as integration testing or system integration testing (SIT) This process tests multiple components of a system in an integrated fashion, with the test cases defining initial conditions, test sequences, and expected outcome from executing all of the components required to implement a complete business function or a service. Integration testing provides an insight into the overall system behavior as well as performance and throughput characteristics.
• Quality assurance (QA) testing This level of testing provides the technology organization and the business community with an assessment and measurement of the quality of the developed system. QA testing can be further broken down into Technical QA and Business QA. These tests are executed independently from each other, and by different groups:
• Technical QA is performed by a Technology QA group that uses independently developed test cases. The goal of the Technical QA is to certify that the solution is developed in compliance with approved technical requirements. Technical QA testing is focused primarily on the technical behavior of the system under test, and does not test technical features and functions at the same level as unit testing. The intent of Technical QA is to test end-to-end applications and systems in accordance with the technical software requirements documentation and based on the testers’ interpretation of the requirements. The Technology QA group interacts closely with the development organization in order to resolve issues discovered during testing. From the process point of view, defects identified by the Technology QA group should be formally logged into the dedicated system used for defect resolution. If defects are found and fixed by the development group, regression testing may be required to validate the corrected code. On completion of regression testing, the results are documented and certified by Technology QA.
• Business QA tests are performed by a dedicated Business QA team. The Business QA team executes end-to-end test cases and compares the results with the business requirements as well as with specific examples derived from running real-life production applications. In addition to validating test results against business requirements, the Business QA team works closely with the Technology QA team and business stakeholders to refine both the business requirements and their technical interpretations. The resulting changes have to be retested, which, in turn, may require a cycle of regression testing at the Unit, System, and QA levels.
• Joint Technical QA/Business QA testing is especially important when the MDM Data Hub data security and visibility implementation are being tested (see the detailed discussion on data security and visibility in Chapter 11). The project team has to work closely with the enterprise security organization and the policy administration team to make sure that access controls are implemented and enforced according to the policy statements and users’ roles and entitlements, and that every authorization decision can be traced back to the appropriate policy. In addition, when developing testing scenarios for data visibility, the team has to make sure that these scenarios include both necessary and sufficient conditions. To state it differently, when a visibility engine allows access to a particular set of Data Hub data, the QA teams have to make sure that all data that was supposed to be accessed based on the policy is granted such an access, and that there are no additional records or attributes that can be accessed by mistake.
MDM solutions put additional emphasis on testing not only services and components, but often the data itself. Not surprisingly, one of the key testing targets of an MDM system is data quality. If the data quality of the source system is a part of the testing process, it should include definition, measurement, and defect-resolution steps. The entire test suite should include clearly defined assumptions, pre- and post-conditions, defect-tracking tools and procedures, and acceptance criteria. At a minimum, testing deliverables should include test cases, reports used for testing, test scripts, test execution results, traceability matrices, and defect-management logs.
Typically, data testing is performed using either or both of the following approaches:
• Bulk statistical analysis executed against all data The fact that all data is covered by the analysis contributes to its strength. A common weakness is that it is not easy to resolve abnormalities if and when they are found.
• Scenario-based testing performed on a small subset of records It is always a question of how many records need to be tested and how to select the subset optimally to cover a representative set of scenarios. Because we are dealing with projects where the number of records is typically in excess of seven digits, manual processing is not an option and automation is not always feasible either.
When we perform data testing in the MDM environment, we have to select the source and the target data files for testing. Let’s use a typical data transformation sequence that the data undergoes during the initial load process into the Data Hub. We discussed this topic in the beginning of this chapter, and Figure 16-2 illustrates the process. An important choice facing the MDM designers is whether the testing routines should be performed at each data migration step (the loading area, staging area, record locator metadata store, and so on). If the decision is negative, then all test cases should compare the initial source (the legacy source systems) with the content of the ultimate, post-transformation target (the MDM Data Hub). This amounts to the end-to-end testing that is typically a province of Technical and/or Business QA.
However, end-to-end data testing is somewhat different from functional testing in that it requires a low level of detail in order to discover data defects and trace their origins. This can be a very complex task given the variety and scope of various data transformation steps. Therefore, an effective approach to Technical QA and Business QA testing is to implement it as a step-wise process, where testing of some steps could be quite complex.
Bulk Statistical Testing Challenges
Let’s consider a “simple” example of testing one-step data transformations between the loading and staging areas of the Data Hub, using bulk statistical testing to confirm the number of records where a certain attribute is blank (see Figures 16-3 and 16-4). As before, we’ll use the example of testing data from a Customer domain to illustrate the details of the problem.
The goal is to reconcile the number of records where the ZIP Code is blank (NULL). The account-centric structure shown in Figure 16-3 (the source) contains three customer records and two different account numbers.
The customer-reporting application would show three customer records: Mary Turner, Mary L. Turner, and Paul Turner, with three addresses, two of them having ZIP Code NULL (we assume that two records for Mary Turner belong to the same individual).
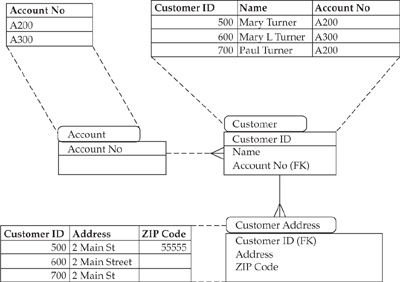
FIGURE 16-3 An account-centric data model
In contrast, the customer/account data in the customer-centric structure, shown in Figure 16-4, has a single address that belongs to the aggregated customer.
As a result of the transformation to a customer-centric model and customer and address de-duping, the two records indicate that one person (Mary Turner) and the three addresses are recognized as one. In the customer-centric structure there are no records with ZIP Code equal to NULL. Therefore, a direct comparison of NULL counts in the two data structures would not provide meaningful testing results.
Even this simple example taken in the context of the Customer domain shows that records that are rejected during the transformation operation drive additional complexity into the process of bulk statistical testing. This complexity may be even higher for other master data domains.
In order to reconcile record counts where a certain attribute is blank (NULL), the source should be compared with the target corrected by the rejected records. A combination of data transformation, data cleansing, de-duping, and record rejection makes bulk comparison difficult. We are not trying to discourage the reader from using this approach, but rather want to make sure that the difficulties of bulk testing are correctly understood.
Looking at the problem of attribute testing in more general terms, we suggest the following attribute transformation categories that have to be tested:
• Attributes that are expected to be unchanged after the transformation
• Attributes that changed only due to the code translation
• Attributes created in new entities due to new levels of aggregation
Testing should cover both real-time/near-real-time processing and batch processing.
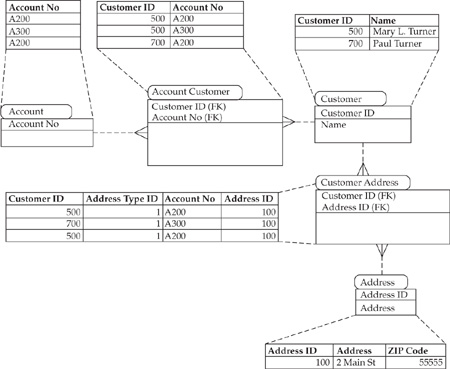
FIGURE 16-4 A customer-centric data model
Scenario-Based Testing
This approach requires very tedious analysis and specifications for all transformation scenarios. In a typical MDM environment, hundreds or even thousands of scenarios have to be tested. In some cases, if there is no data in the test data set to support certain test conditions, these conditions and the corresponding test data have to be created.
Testing MDM Services
MDM testing is not limited to data testing. Because an MDM Data Hub is built on the foundation of a service-oriented architecture (SOA), testers must be able to test Data Hub services, especially Web Services (see Chapter 4 on the SOA approach to MDM architecture). Testing Web Services is a challenge because the testing processes, procedures, and test cases should take into account the different styles of Web Services (SOAP based or REST based), the disconnected nature of the services, the protocols used to publish and consume services, and many other concerns, including the following:
• Testing SOAP3 and REST4 messages
• Testing WSDL5 files and using them for test plan generation
• Web Service consumer and producer emulation
• Testing the Publish, Find, and Bind capabilities of an SOA-based solution
• Testing the asynchronous capabilities of Web Services
• Testing the dynamic run-time capabilities of Web Services
• Web Services orchestration testing
• Web Services versioning testing
Considering these and other challenges of testing MDM solutions, components, data, and services, we have to conclude that the skill set that the Technical QA team should possess is quite diverse and hard to come by. The Technical QA team skill set should include the following:
• Test-strategy development skills that cover both data-testing capabilities and testing of services.
• Knowledge and hands-on experience with best-in-class testing methodologies and tools.
• Ability to develop test cases that require strong data analysis skills. This includes batch processing and real-time/near-real-time data flows.
• Reporting and query-building skills that require experience with reporting and business intelligence tools.
• Application and process testing for new customer-centric applications.
These testing qualifications can be difficult to find. Usually, the variety of skills required for testing leads to very little overlap in experience among the Technical QA team members, which in turn leads to a necessarily large Technical QA team. The rule of thumb for MDM projects is that the number of testing resources should be about 75 percent of the number of developers.
Match Group Testing
Another MDM-specific functional area of testing is the verification of Match Group assignments. As we discussed in previous chapters, the Match Groups are created to identify and link the records that belong to one Party (that is, an individual or an organization). The process of creating and testing Match Groups is critical for any MDM project. Because typical matching algorithms are iteratively tuned throughout the testing cycles in order to optimize matching accuracy and performance, it is very important to have a process that verifies the results of matching and discovers errors and issues.
We suggest a simple process successfully used by the authors on multiple projects. Assume that the Match Groups have been computed as a result of the matching process and the Match Group identifier has been assigned to each record in the Data Hub.
• The process begins with a search for false positives. In order to do that, the match results are sorted by the Match Group. If the match is based on scoring, the match score should be displayed next to the Match Group ID. In this case, the correctness of the score could be verified for each combination of attributes that should be treated as a test case. Alternatively, if the match is based on business rules defined as conditional statements, the match results should also be tested for each scenario. From the testing perspective, the use of scoring systems for matching is more convenient and enables faster test processing.
• False negatives are tested as soon as the analysis of false positives is complete. Assume that there are a few attributes such that at least one of them must match in order for two records to acquire the same match identifier. If fuzzy logic is used for attribute comparison, the index generated by fuzzy logic should be used instead of the attribute value. Let’s assume that three attributes are most critical: credit card number, phone number, and address. Thus:
• Only records for which the credit card number is the same but the Match Group identifiers are different are included. The results are sorted by credit card number and analyzed.
• Only records for which the phone number is the same but the Match Group identifiers are different are included. The results are sorted by phone number and analyzed.
• Only records for which the address is the same but the Match Group identifiers are different are included. The results are sorted by address and analyzed.
In order to come up with conclusive results on match testing, the test must cover a representative set of scenarios. Scenarios should be defined on a case-by-case basis. Unlike transformation test processing, where most scenarios are at the record level, match-testing scenarios, by their nature, include multiple records, which may result in an unmanageably high number of scenarios. If matching requirements are clearly defined, they can be used to construct appropriate test scenarios. A report representing the results of match testing should include an analysis of what attributes and matching conditions have been covered within the test data set.
Some vendors and MDM practitioners question the value of the detailed scenario-level or attribute-level requirements. We recommend that business users identify matching requirements and guidelines at a high level, and leave the matching details to the implementation team. Once the matching design is completed and the tool is selected and/or configured, a match audit process should be invoked to assess the accuracy of the match. This match audit process usually involves an independent, often external, match audit provider. Responsibilities of a match audit provider include the following:
• Perform an independent match and identify the Match Groups.
• Compare the results with the results obtained by the match process under audit.
• Recommend improvements in business rules, data quality, profiling by attributes, and so on.
Creation and Protection of Test Data
Today, companies have to comply with numerous global and local data privacy and confidentiality rules and regulations. Many organizations treat the need to protect sensitive data such as material nonpublic financial information and personally identifiable customer information very seriously. These organizations develop information security strategies and implement the appropriate auditable security controls as required by regulations such as the Sarbanes-Oxley Act and the Gramm-Leach-Bliley Act. These steps are designed to protect sensitive data from external attacks. However, a slew of recent security breaches shows that the threat to data privacy and confidentiality comes from outside the corporation as well as from internal users (disgruntled employees, lack of security awareness, improper sharing of access privileges, and so on). What makes this data security problem even more alarming is the large number of incidents where a security-aware organization focused on protecting sensitive production data may allow copies of that data to be used for testing of new systems and applications, even though it is a known fact that test environments are rarely protected as strongly as the ones used for production. OCC Regulation 2001-47 and other regulations have been developed specifically to address the issue of third-party data sharing, because many companies are outsourcing large-data-volume system testing to third-party service or solution providers.
All these concerns lead many organizations to adopt processes that protect test data from potential compromise. And these concerns and processes apply directly to MDM solutions: MDM test data tends to “look” almost like production data in its content and volumes. To avoid the security exposure discussed earlier, an MDM project team has to recognize test data security issues at the beginning of the project, and develop approaches to protect not just production data but also test data. These approaches usually fall into two major categories: protecting or hardening the test environment, and protecting or sufficiently modifying the test data content to avoid security compromise.
Let’s look at the latter because it deals with the data content and thus may affect the way the MDM testing is performed. Test data protection can be achieved by anonymizing (obfuscating or cloaking) data at the file, record, or attribute level. The level of obfuscating is determined by the company’s security and privacy policy and the nature of the data. In the case of customer data protection, the goal is to protect those PII attributes that can directly or indirectly identify individuals (that is, names, social security numbers, credit card numbers, bank account numbers, medical information, and other personal information). From the regulatory compliance point of view, companies should be aware that if material nonpublic information (MNPI) and personally identifiable information (PII) is compromised even outside the company walls (for example, the data security is breached at the outsourced third-party vendor site), the company is still responsible for data confidentiality protection. But because the security violation happened outside the company walls, the risk to the company’s reputation is even greater.
The key challenges in using data anonymization techniques include:
• The ability to preserve logic potentially embedded in data structures and attributes to ensure that application logic continues to function.
• The ability to provide a consistent transformation outcome for the same data. In other words, many obfuscation techniques transform a particular attribute value into a different but predictable value consistently (for example, “Alex” always gets converted into “Larry”).
In some situations, however, the data sensitivity is so high that the transformations are designed to provide random, nonrepeatable values.
• Support for enterprise-scale data sets at the required levels of performance, scalability, and throughput.
The most popular anonymization techniques include the following:
• Nullification All attribute values are replaced with NULL. The solution is simple and easily implementable. The primary disadvantage is that the data is lost and cannot be tested.
• Masking data All attribute values are replaced with masking characters. The solution is also simple and easily implementable. Only limited testing is possible (for instance, on the number of characters). The primary disadvantage is that the logic embedded in the data or driven by the data is lost, and thus application or functional testing may be infeasible.
• Substitution Replace the data values with similar-looking data created in separate stand-alone tables. For instance, if last names must be anonymized, all last names will be replaced with different last names in a cross-reference table. The algorithm is reasonably fast and preserves consistency across records; for example, if the last name Smith is replaced with the last name Johns, this replacement will occur consistently for all records with the last name Smith. The last name lookup table serves as the key and must be protected. This approach allows for testing of entity matching, although fuzzy matching may require additional in-depth analysis of the testing outcome.
• Shuffling records This method is similar to substitution, but, unlike the substitution method where the lookup table stores the cross-reference values, the record-shuffling method stores cross-reference pointers that randomly point to the records in the table that contains the anonymized data.
• Number variance The algorithm multiplies each value by a random number.
• Gibberish generation This is often accomplished by the random substitution of characters. The length of the data will be preserved. One-to-one relationships between the original code values and the anonymized code values can be preserved.
• Encryption/decryption This is a classical approach, and many vendor solutions that perform encryption/decryption of data are available. The biggest challenge of this approach is related to the performance and key management of the crypto algorithm. Indeed, if the encryption/decryption keys are lost or destroyed, the data may not be useable at all.
Many organizations decide to implement a combination of various techniques in order to meet all anonymization requirements.
Considerations for the MDM Application and Presentation Layers
Once the MDM system is ready to be deployed, we have to consider MDM implications on the design of Data Hub Management, Configuration, and Administration applications as well data-consuming applications and reporting solutions.
The data-consuming applications include those applications that can be designed to take advantage of the data and services provided by the MDM Data Hub, including applications that can leverage new entity-centric (for example, customer-centric) views of the master and reference data both for traditional entity management functionality (such as customer on-boarding and reporting applications) as well as new applications that are designed specifically to use and support entity centricity. The availability of aggregated, cleansed master data may not only have some impact on the existing applications but can also drive the development of new, purpose-built business applications that can impact and/or take advantage of new workflows and business processes. In general, an MDM Data Hub enables new entity-centric (for example, customer-centric) applications to search, access, and manage entity information not just via an account number, invoice number, confirmation number, and so on, but via relevant entity identifiers. The choice of identifiers and the overall design impact on these existing and new applications are highly dependent on the business purpose of a given application, the enterprise system architecture, and a number of other factors, and are usually assessed and considered in the context of business requirements by the application development teams that work together with the MDM development team. In all cases, though, these applications leverage published Data Hub services such as Entity Resolution, Search services, Authoring services, Interfaces services, and others. In general, business applications using an MDM Data Hub have to be designed as instances of a service-oriented architecture that interact with the MDM Data Hub via a well-known set of coarse-grained and fine-grained Data Hub services (see Chapters 4–6 for more details on these services).
The Data Hub Management, Configuration, and Administration applications, on the other hand, are directly influenced by the MDM system capabilities, work with and manage MDM Data Hub services, and therefore have to be designed to make the MDM Data Hub system manageable, configurable, and an operation-ready platform.
Let’s briefly look at the types and requirements of the Data Hub Management, Configuration, and Administration applications. We’ll conclude this section with a short discussion on the approach to designing and deploying business intelligence and reporting applications.
Data Hub Management, Configuration, and Administration Applications
In order to understand the requirements for the MDM Management, Configuration, and Administration applications, let’s review once again the conceptual MDM architecture framework discussed in Chapter 4 and illustrated in Figure 4-6 and, for ease of reference, repeated again as in Figure 16-5.
The Data Management layer of the framework contains components that are typically managed by a suite of administrative applications and user interfaces regardless of whether we consider an MDM vendor product or internally developed MDM Data Hub. Key components in this layer that are managed by the administrative application suite include Identification Configuration services (part of the Entity Resolution and Lifecycle Management Service), Search services, Master Entity Authoring services, Metadata Management services, and Hierarchy Management services. The suite of administration and configuration applications that manages these components is designed to manage the configuration complexity of the Data Hub environment by making Data Hub operational parameters “data driven.” Some of the applications in this suite are briefly discussed next:
• Master Data Authoring This is a specialized application that manages MDM Authoring services and provides MDM administrators and data stewards with the capabilities to create (author), manage, customize/change, and approve definitions of master data (metadata) as well as to create, read, update, and delete (for example, support CRUD services) specific instances of master data.
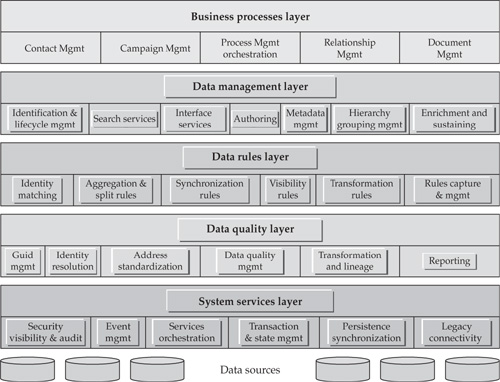
FIGURE 16-5 Conceptual MDM architecture framework
• Adjustment application This is a user-friendly component of the Authoring application designed specifically to enter and apply adjustments to either specific instances of master entities or to some attributes of reference data. Usually, an adjustment application supports a purpose-build user interface that allows for effective navigation of adjustment activities and seamless integration with appropriate workflow to receive adjustment approval (if appropriate), apply the adjustment, and create a record of the adjustment action for audit and traceability purposes.
• Reference code maintenance application This application is a subset of the more general-purpose Adjustment application and is designed specifically to maintain allowed code values in the MDM Data Hub.
• Hierarchy management application This is a very important component of the MDM Management, Configuration, and Administration suite. The design and implementation approaches for hierarchy management vary widely, based on the ability to support single vs. multiple data domains as well as support for alternate hierarchies, custom aggregation, groupings, and other factors (an additional discussion on hierarchy management is offered in Part II of the book). In principle, though, we can describe a conceptual hierarchy management application in terms of commonly recognized functional and user interface (UI) requirements as follows:
• The hierarchy management UI should present a reference data hierarchy using a tree metaphor (perhaps similar to the popular Windows Explorer).
• The UI should allow users to copy, cut, paste, move, drag, and drop nodes of a given hierarchy in order to change an existing hierarchy or create an alternative hierarchy.
• The UI should allow users to perform a “one-click” action to see or change properties and definitions of the nodes in the hierarchy, including editing of the metadata rules describing the content of each node (for example, the value of a given node can be defined via a simple or complex formula).
• The application should allow for the creation of a view of the hierarchy that includes data lineage that can be traced back to the source of the reference data.
• The tool should support the creation of a data change capture record that could be used to deliver hierarchy changes as instructions or data manipulation statements to the downstream systems.
• The application should support and make available the change log and audit trail for all actions performed on a given hierarchy, including the identity of the user who performed these actions.
• Operations/scheduling controller This application allows the MDM Data Hub system administrator to request, initiate, or control certain operational activities such as running on-demand reports, creating file extracts that are used as input into downstream systems, loading or reloading the Data Hub, and changing the location of a particular data source.
• Metadata Management application This is a user-facing composite application that is focused on managing various aspects of the Data Hub metadata facility.
• Matching Attributes Maintenance application This application defines what attributes are used as critical data attributes. The extract for the matching engine is generated based on the entries from this application.
• Rules Configurator This is an application that allows an authorized administrative user or an MDM steward to author, change, or delete data management rules that govern certain Data Hub services, such as the establishment of the match threshold or the rules of attribute survivorship.
• Data Locator and Attribute Locator Registry Editor As the name implies, this application provides a rich user interface to define, create, or change the content of the data and attribute locator registries that are implemented as dedicated areas of the MDM Data Hub metadata store.
• Exception-Processing support This application allows an MDM system administrator to define new error types and exception-processing flows and create appropriate metadata records.
• Default Value Management application This application allows MDM administrators and data stewards to define and maintain default values.
• Master Search application This is an administrative application that allows data stewards and other authorized users to effectively search for master data entities or reference data records based on fully qualified search criteria or by using a fuzzy, generic, or proximity search. If desired, this application or its variant can be made available to all authorized MDM Data Hub users as a business application focused on searching entities (for example, customers, parties, products) that are maintained in the Data Hub.
Reporting
MDM solutions tend to be optimized for real-time/near-real-time operations but not necessarily for batch reporting. Experience in implementing large data warehouses and business intelligence applications proves that running complex queries against very large databases (and, of course, an MDM solution usually ends up having to support a very large data store known as a Data Hub) may have serious performance and throughput implications on the technical infrastructure and end-user application response times.
If the MDM project specifies the need for extensive entity-centric reporting, the project architects may consider implementing a separate reporting environment that loads a performance-optimized reporting data mart from the Data Hub and makes its data available to the end-user BI and reporting application suite. This approach is valid for any MDM Data Hub architecture style because Data Hub design is rarely optimized for data warehousing–type queries.
These considerations apply to end-user BI-style reporting. Of course, there are other types of reports that need to be developed to support Data Hub and application testing and operations. In fact, testing relies heavily on reporting. The good news is that the majority of the reports developed for testing can be leveraged and sometimes reused for operational controls when the MDM system is deployed in production.
Additional Technical and Operational Concerns
In addition to the issues discussed in the previous sections, we have to mention a few technical considerations that MDM projects need to take into account when building Data Hub systems.
Environment and Infrastructure Considerations
In general, building and deploying an MDM Data Hub platform should be done using the same approaches, processes, and procedures that are common in any large enterprise initiative. Here are some examples:
• The Enterprise Database Administrator (DBA) and the infrastructure team should be adequately staffed. DBAs and infrastructure architects should work proactively to gather, understand, document, and integrate requirements from all work streams participating in the MDM project (the list of typical work streams is discussed in Chapter 13).
• Given the number of work streams, the diversity of software, the requirements for parallel processing, and the need to support multiple system environments (for example, test, QA, production), each of which should be able to store very large amounts of data, the success of the MDM project would depend on the availability of a dedicated and appropriately resourced infrastructure and architecture work stream.
• Some or all of the following infrastructure environments have to be set up:
• Development
• Unit testing
• Integration testing
• Technology QA
• Business QA
• Performance testing
• UAT environment
• Production
• Disaster recovery (DR)
Typically, one or two additional environments are required specifically for data testing. These environments support snapshots of data and provide basic data management capabilities but may not include all MDM services and application components.
The following logical components must be acquired, installed, and configured as part of the MDM technical architecture definition step (these logical components may be represented by a different number of physical infrastructure components):
• Database servers These servers support the relational database management systems used by the MDM project (for example, an enterprise may decide to use Oracle DBMS for the Data Hub, and SQL Server for the loading and staging areas of the data architecture). Regardless of the DBMS technology, these servers should be able to support the operations and recovery of very large volumes of data, possibly on the terabyte or even petabyte scale.
• Message server (Enterprise Message Bus) This server supports real-time or near-real-time messaging and data synchronization requirements.
• ETL servers These servers are focused on supporting Extract, Transform, and Load data flows and corresponding processes.
• Core MDM Data Hub and Entity-Matching server This is a type of an application server that supports core MDM services, including record matching.
• Web and Application servers These servers provide traditional functionality required to process web interactions and application services.
• Test Management server This server is used for test planning, execution, and defect management.
• Reporting server
• Change Management server
• Knowledge Management server This server would support project documentation and a searchable shared knowledge library for the project (for example, an internal Wiki server).
Deployment
As we have stated repeatedly throughout the book, Master Data Management is an enterprise-wide initiative that may have a profound impact on how an enterprise manages its core data. The deployment of any enterprise-wide structural change that impacts established business processes is a significant technical, organizational, and political challenge. The deployment complexity grows as the MDM solution evolves from the Registry Hub to the Transaction Hub, and begins to support more than one master data domain. Indeed, we have shown in the previous chapters that the Transaction Hub requires more invasive modifications of the data structures and radical changes to established business processes. Managing change and managing expectations of an MDM project should go hand in hand. Thus, the MDM project team should consider these typical deployment options:
• The “Big Bang” scenario includes MDM and new applications deployment across the entire enterprise in a single system release.
• Pros: The enterprise-wide change avoids potential inconsistencies that are inevitable if only some of the processes and systems are migrated to the new customer-centric world.
• Cons: High implementation risk of changing the entire organization at once. If the transition to entity centricity runs into any kind of problem (organizational, technical, budgetary, and so on), the resulting risk of project failure will be high.
• Deployment by line of business or geography.
• Pros: This deployment strategy makes sense if the entire MDM master file (for example, a customer base) can be partitioned, and if the new applications can process smaller segments of data independently from each other. Partitioning the data files allows for more manageable chunks of data to be handled by new applications. Moreover, smaller data partitions allow for smaller groups of users to be trained on their familiar data segments in parallel.
• Cons: During the deployment rollout, some parts of the enterprise will be transitioned onto a new MDM platform while others may still be using legacy systems. If not planned and carefully coordinated, this coexistence of the two modes of operations can cause significant problems. Multiple releases may be required to complete the enterprise-wide transition.
• Deployment for new transactions only.
• Pros: This deployment strategy involves the entire enterprise and completes the transition in a single release.
• Cons: This deployment strategy has similar implementation and management issues as the LOB and geography deployment options discussed earlier. The main concern is the necessity to manage both new and old environments and transactions concurrently until the migration to the new systems is completed.
Considerations for the MDM Data Hub Data Model and Services
This section offers a brief discussion on what to look for if the organization decides to acquire an MDM product instead of building one in-house.
An important consideration in evaluating MDM Data Hub products deals with the Data Hub data model. We discussed MDM data model concerns and approaches extensively in Chapter 7 of this book. One school of thought on this topic states that a business-domain–specific, proven data model should be at the top of the MDM Data Hub selection criteria list. Is that always the right approach?
There are two competing MDM Data Hub product approaches as they relate to the Data Hub data model:
• The first one is based on a vendor-developed, out-of-the-box data model. It is very attractive for most firms to have the “right” data model. The “correctness” of the data model is a point-in-time decision because data models tend to evolve over time. The majority of MDM solutions available in the marketplace today provide a mechanism by which the model can be customized, but these customizations may be quite complex, and the resulting data model may have to be tuned and customized again and again until all business and technical requirements are met. This is particularly true if the core MDM data model includes hundreds or even thousands of entities, whereas only 10 to 30 entities (that is, tables) are required to support an MDM implementation that is based on the enterprise canonical data model.
• The second approach is “data-model agnostic.” A chosen MDM product can instantiate any data model that better fits the organization. When the data model is instantiated, the MDM Data Hub automatically generates prerequisite core Hub services. Such products provide a higher level of flexibility, but the data model needs to be defined separately. Also, the set of services generated automatically is often limited to low-level services. More complex composite services have to be developed by the project team and the enterprise application developers where appropriate. These data-model-agnostic products are in fact tools designed for accelerated MDM development. Figure 16-6 illustrates the idea of the data model for the Data Hub data-model-agnostic solution architecture.
In reality, some vendors of MDM solutions offer a hybrid approach where a product is data-model-agnostic but also offers several “out-of-the-box” data models that can be used with some customizations. We offer additional discussion on various categories and types of the MDM Data Hub products in Part V of the book.
FIGURE 16-6 Data-model-agnostic solution architecture
To sum up, this chapter offered a brief discussion of several implementation considerations for MDM solutions. We started this discussion with the example of a use case that defined the need for real-time and batch data synchronization across various customer touch points. The use case helped us to illustrate typical components that system designers should be considering when developing an MDM data synchronization solution. We showed that the synchronization, although vitally important to the success of the MDM project, is not the only concern of the MDM implementers. We showed that other, equally important considerations include issues related to building Data Hub Management applications, reporting, testing, and other operational and deployment concerns. The major takeaway from these discussions is that these concerns are some of the keys to a successful MDM implementation, and, if underestimated, these areas of concerns can represent significant project risks and can ultimately cause a project to fail. We discuss some of the key reasons for MDM project failures in Chapter 19.
References
1. http://en.wikipedia.org/wiki/Regression_testing.
2. Kruchten, Philippe. The Rational Unified Process: An Introduction, Second Edition. Addison-Wesley Longman Publishing Co., Inc. (2000).
3. http://www.w3schools.com/SOAP/soap_syntax.asp.
4. http://java.sun.com/developer/technicalArticles/WebServices/restful/.