
13.9. Exploiting XML
SQL/XML
SQL:2003 introduced XML as a new built-in data type. XML data is strongly typed: XML values are assumed to be tree-like data structures that are distinct from their representation in the form of a text string. The XML type can be used wherever other SQL types are allowed: in table columns, as parameters of a routine, as variables, and so on. Although relational data and XML data are both structured, there are some significant differences between them. The Table 13.5 identifies a few distinctive points.
XML data can be stored in a database either in a text column (i.e., char, varchar, or dob) or in a column of data type xml. A textual representation might be preferred if it is important to retain the textual fidelity of a document (which may include text that has no relevance to the data structure) or if the XML is always entered and retrieved as a complete document. However, storing the data in an XML column allows efficient processing of the XML data in the database, rather than in a middle-tier application.
| Feature | Relational (SQL) | Basic XML |
|---|---|---|
| Primary structure | “Flat” sets | Hierarchical |
| Data sequencing | Row order is not significant | Nodes are ordered |
| Primary access mechanism | Set operations | Navigation through hierarchy |
| Data typing | Always typed | Typed or untyped |
| Missing values | NULL | Absent or empty element |
In addition to the XML data type, the SQL:2003 standard also introduced some related features, such as new XML operators, functions, and rules for mapping between SQL concepts and XML concepts. Most vendors broadly support these features, or their equivalents, but the need to integrate the additional XML features into different preexisting frameworks has inevitably resulted in some differences in syntactic detail. The fact that XML support is an area of keen competition for vendors is also likely to produce a variety of nonstandard extensions. The picture is further complicated by the need for interoperability with other standards, such as XQuery; discussed in more detail shortly. Fortunately, this competition is limited to the variety of operators, functions, and so on that are provided to integrate XML with SQL. The standards governing the structure of XML data are defined outside SQL, and so the XML values themselves are reasonably consistent from one database system to another.
In 2006, the part of the SQL standard dealing with XML (Part 14) was revised and extended to consolidate the features of SQL/XML, as it has come to be called. (The standard is sometimes referred to as SQL:2006, although this is a little misleading since only the XML part was revised in 2006.) Here we will use SQL/XML:2006 to specifically distinguish the more recent version where necessary. You also need to be aware that Microsoft’s XML database technology, as used in SQL Server, is referred to as SQLXML, but is not the same as SQL/XML!
In SQL/XML:2006 the xml data type is based on the XQuery data model[1]. Legal values are either null (indicating the absence of any XML) or any legal value of the XQuery data model. An instance of the XQuery data model is a sequenceof zero or more items, which are either atomic values of one of the defined data types, or a node.There are seven kinds of node: document, element, attribute, text, namespace, processing instruction,and comment.The xml data type can take optional modifiers that give a finer-grained definition of the XML structure. The general sequence structure is indicated by xml (sequence ). A sequence containing exactly one document node is termed XML content,with the type modifier xml (content). A special type of content is where the document node contains exactly one element node (plus, possibly comment and processing instruction nodes), and this is termed an XML document,with the type modifier xml (document). A secondary modifier can be added for xml (content) and xml (document) to indicate whether the content or document can contain both typed and untyped elements (any), only untyped elements (untyped), or elements defined by a schema (schema name). If a schema is de fined, the element and attribute nodes are guaranteed to be valid according to the schema. These distinctions are summarized in Figure 13.5. If the type xml is specified without a modifier, any default assumption about these more specialized subtypes is implementation dependent.
[1] To be more precise, SQL/XML is based on the XQuery 1.0 and XPath 2.0 Data Model.
Figure 13.5. XML Data Type Modifiers.

The SQL:2003 standard introduced the predicate is document to test whether or not an XML expression is a document. The basic syntax is:
xmlexpression is [ not ] document
Although the syntax of the predicate remained unchanged from SQL:2003, the meaning shifted somewhat because of the realignment of SQL/XML:2006 with the XQuery data model. Three more predicates were added: is content, xmlexists, and is valid. The is content predicate tests whether or not an XML expression is legitimate XML content, using the syntax:
xmlexpression is [not ] content
To test whether an expression contains valid XML, the xmlexists predicate can be used. The syntax, simplified a little, is as follows:
xmlexists ( XQuery-expression [ passing value-expression [ as identifier] [ { by ref i by value } ]] [ .... ] )
If the XQuery evaluation is of a value that turns out to be null (perhaps passed as an argument from SQL) then the predicate result is unknown. For nonnull values, if the XQuery evaluation returns an empty sequence, the predicate’s value is false, otherwise the result is true. The following example shows the use of xmlexists in a select statement to retrieve “id” values for customers in a given city, with the customer details being stored in a column of the xml type.
select c.custld from customer as c where xmlexists (' $d/*:customerinfo/*:addr[ *:city = "Salt Lake City"]' passing info as "d" )
The is valid predicate checks to see if an XML value is valid according to a given XML schema. The details of validity assessment are a little complex and are not covered here. The simplified syntax is:
xml-value-expression is [not ]valid [identity-constraint-option ] [ according to xmlschema { uri | registered-name } ] [ valid-element-clause ]
The xml-value-expression is checked according to the schema identified by the choice of namespace. If none is specified, each element is validated according to the schema associated with its namespace. If specified, the schema can be identified either by URI or by its registered name. The optional identity-constraint-option and valid-element-clause parameters provide for more detailed specification of exactly how schema checking should be done.
A number of built-in XML operators were introduced in the SQL:2003 standard. One of the operators, xmlroot, could be used to modify the version and standalone properties of an XML expression, but this was removed in SQL/XML:2006 so we don’t cover it here.
The first two SQL/XML operations we’ll look at, xmlparse and xmlserialize, convert back and forth between structuredand stringrepresentations of XML. The xmlparse operation takes an SQL string expression and produces the equivalent XML structure. A parameter defines whether the string expression is expected to represent a document or content. The basic syntax has remained consistent since SQL:2003.
xmlparse ( { document | content } stringexpression [ { preserve | strip } whitespace ] )
The result of the operation could be assigned to a variable of type xml or stored in an xml column. The precise way in which whitespace is handled is by xmlparse is subject to detailed rules that are not considered here.
The xmlserialize operation performs the inverse of xmlparse, producing a string version of a given XML expression. The SQL standard does not mandate the precise format of the resulting string, but does require that a subsequent xmlparse of a string produced by xmlserialize should reproduce the original XML expression. In other words, given an XML document called myXmlData, the following construct:
xmlparse ( document ( xmlserialize ( document myXmlData as varchar ( max ) ) ) )
should produce a result equal to myXmlData. The original SQL:2003 syntax of xmlserialize
has been extended in SQL/XML:2006.
xmlserialize ( { document | content } xmlexpression as SQlLdatatype [version string ] [including xmldeclaration | excluding xmldeclaration ] )
The SQL datatype for the result could be any SQL string type (char(n), varchar(n), ...), but serialized XML tends to be lengthy, and so a character large object (dob) type is likely to be a common choice. Optionally, an XML declaration ’< ?xml version=”1.0” encoding=”UTF-8”? >’ can be prepended to the result: the default is excluding xmldeclaration. The XML version can also be separately specified: at present this will be limited to ’1.0’.
The xmlconcat operation introduced in SQL:2003 has been retained in SQL:2006. It simply concatenates a list of XML expressions, producing a new XML expression.
xmlconcat (xmlexpression [ .... ] [ returning {content | sequence }])
The optional returning clause was added in SQL/XML:2006. If this is omitted, it is implementation defined whether returning content or sequence is implicit.
The SQL:2003 standard defined several “publishing” functions to generate XML expressions from SQL expressions. These have been extended in SQL/XML:2006, and new functions have been added. Here we cover only the SQL/XML:2006 definitions of the functions.
The xmlelement function is used to create an XML element from a given set of parameters. Recall that an XML element has the basic form:
<tagname optionalAttributes> optionalElementContent >/tagname>
So, for example, an element representing a customer might look something like:
<cust custid = "1234"> Widgets Inc </cust>
If required, the tagname can be further qualified by prefixing it with a namespace, in which case the namespace URI must also be specified. The xmlelement function constructs an individual XML element from the parameters provided and returns it as an xml value. The basic syntax for character strings is shown here. There is also a variant for binary strings that we won’t consider.
xmlelement (name xmlelementname [,xmlnamespaces(namespace-declaration-item [ .... ])] [, xmlattributes ( attributevalue [as attributename ] [ .... ] ) [, elementcontent[ .... ] [ option { null on null | empty on null | absent on null | nil on null | nil on no content } ]] [ returning { content | sequence }])
The embedded xmlnamespaces and xmlattributes functions are optionally used in the context of a given element to add any required namespace declarations or attributes to the element. The element content is defined by a list of expressions which is optional, so it’s possible to create an empty element. Also optional is the returning clause which we’ve already seen.
The content option requires a little more explanation. In SQL a missing optional value is explicitly marked as null. This is not a value recognized in XML, although null is legitimate for the SQL xml data type. Depending on the desired result, a missing value could be indicated in XML by simply omitting the relevant element or by including the element’s begin/end tags with no contained value. If an explicit indicator equivalent to null is required, a further option is the “nil” mechanism specified in the XML Schema For Instances namespace. The namespace is typically introduced with a declaration such as:
xmlns:xsi = "http://www.w3.org/2OO1/XMLSchema-instance"
The xsi prefix is used by convention, but some other prefix could be substituted. Once this is defined, the nil attribute defined in XMLSchema-instance can be set to True to indicate that the element content is nil, as in:
<myElement xsi:nil = "true"></myElement>
An element attributed in this way may not have any element content, but may still carry other attributes. The SQL:2003 standard acknowledged the xsi:nil option, but did not prescribe how this should be specified in conjunction with operations such as xmlelement. SQL/XML:2006 now provides close control over these choices, as summarized in Table13.6.
| Option | Result when the function is applied to an SQL null |
|---|---|
| null on null | A null SQL value results in a null XML value |
| empty on null | A null SQL value results in an empty XML element |
| absent on null | A null SQL value results in no element (i.e., an empty sequence) |
| nil on null | A null SQL value results in a XML element marked with xsi:nil = "true" |
| nil on no content | An element being created with no children is marked with xsi:nil = "true" |
As a simple example of the use of xmlelement, consider a Customers table that is purely relational (it contains no XML). We could produce a result table containing a mixture of relational data and XML representing selected customer information in the following way:
select c.id, xmlelement( name "cust", xmlattributes (c.id as "custid"), custName) as Xcust from Customers as c where custid = 1234
which would produce a result such as:
| id | Xcust |
|---|---|
| 1234 | <cust custid = "1234"> Widgets Inc </cust> |
where the data contained in the Xcust column is of type xml. Calls to xmlelement can be nested, so that elements can be created within elements, producing the characteristic hierarchical structure of XML.
The xmlforest function is basically a convenient way of applying xmlconcat to a sequence of xmlelement results: it produces a sequence of elements from a list of expressions. The elements can be named explicitly or implicitly. As with xmlelement, calls to xmlforest can also be nested. The basic syntax is as follows:
xmlforest ( [ xmlnamespaces (namespace-declaration-item,), ] elementvalue [as elementname ] [ .... ] [ option { null on null | empty on null | absent on null | nil on null | nil on no content } ]] [returning { content | sequence }])
The parameters are used in the same way as xmlelement. For example,
select o.orderld, xmlelement ( name "order", xmlforest ( o.custName as "customer", o.date ) ) as Xorder from Orders as o where orderid > 9800
would produce a result such as:
| orderld | Xorder |
|---|---|
| 9876 | <order> <customer> Widgets Inc </customer> <date> 2007-12-12 </date> </order> |
| 9877 | <order> <customer> Thingummy Co </customer> <date> 2007-08-15 </date> </order> |
If preservation of the case in SQL names is case is important, they should be aliased as delimited identifiers. Regular identifiers are likely to be mapped to all uppercase in some implementations. For example, the dateelement in the example just given could appear as <DATE> ... </DATE> instead of <date> ... </date>.
To give an impression of the differences in syntax between different implementations, the result table just given could be produced in SQL Server by using a construct such as:
select o.orderld, (select o,custName 'customer', o.date 'date' from orders as o for xml path ('order'), type) as Xorder from orders as o where orderid > 9800
SQL Server uses various for xml ... constructs to convert relational data to XML. The for xml path variant gives full control over how the XML structure is to be generated on a column by column basis. The type parameter specifies that the result should be of type xml, as opposed to its string equivalent.
Returning to SQL/XML, the xmlagg function is an aggregate function, similar to SQL’s sum, avg, etc. It returns a single value from a given bag of values, which must be the result of an xml type expression. The resulting xml values are concatenated to produce a single xml value. Optionally, an order by clause can be used to order the results before concatenating, using a similar syntax to SQL. Any null produced is dropped before concatenating. If all of the results of the expression are null, or the bag is empty, the result of the xmlagg function is the null value. The basic syntax is as follows:
xmlagg ( XML-value-expression [ order by sort-specification ] [ returning { content | sequence }])
As an example of the xmlagg function, suppose we have an “Orders” table and want to group by customer, showing, for each customer, an element for each order placed by that customer. For simplicity, we’ll just assume that both orders and customers are represented by a simple ID value. We could construct the result as follows:
select xmlelement ( name "Customer", xmlattributes ( o.custld as "customerld" ), xmlagg ( xmlelement ( name "order", o.orderld ) order by o.orderld ) ) as Xcust0rders from Orders as o group by o.custld
which would give a result resembling:
| XcustOrders |
|---|
<Customer customerld = 1234>
<order> AB123 </order>
<order> CD456 </order>
</Customer>
|
<Customer customerld = 5678>
<order> BC345 </order>
</Customer>
etc.
|
The xmlpi function generates a single XQuery processing instruction node, as follows:
xmlpi ( name target [, string-expression ] [ returning { content | sequence } ] )
The target identifier (name) cannot be ’xml’ (in any case combination) and the string expression cannot contain the substring ’?>’. The xmlcomment and xmltext functions are also straightforward, each simply producing a node of the appropriate type. Here are some examples of the use of these functions
xmlpi ( name "Warning", 'Turn off now') produces <?Warning Turn off now?> xmlcomment ('This is my comment') produces <!-- This is my comment -->
xmltext ('Here is my text') produces Here is my text
The xmldocument function returns a document node (as defined by the XQuery data model) that has the given XML value as its content. This is useful for converting an arbitrary XQuery sequence into an XML document.
xmldocument ( xmlvalue [ returning { content | sequence } ])
A separate casting function, xmlcast, is provided for casting to and from XML values. This works in the same way as the standard SQL cast function, except that at least one of the data types involved must be xml. It’s also possible to cast between the subtypes of xml, subject to certain rules that we won’t go into here. Note that casting backward and forward between XML values and strings is not the same as using the xmlparse and xmlserial- ize functions.
Like the valid predicate, the xmlvalidate function ensures that a given XML expression is valid according to the related schema definitions. As with the valid predicate, schemas can optionally be explicitly specified. However, unlike the valid predicate, the xmlvalidate function also persistently annotates the XML expression with type information. The syntax is:
xmlvalidate( { document | content | sequence } xmlexpression [ according to xmlschema { uri | registered-name } ] [ valid-element-clause ])
We saw earlier how the xmlnamespaces function could be used in the context of xmlele-ment and xmlforest functions. A more complete syntax for xmlnamespaces is:
xmlnamespaces ( { XML-namespace-URI as namespace-prefix I default XML-namespace-URI | no default } [ .... ] )
The default option applies the namespace definition to any nested elements, unless overridden by a lower level no default. Similarly, the no default option can be overridden buy a lower level default. The default and the no default options can be specified at most once in an xmlnamespaces argument list.
The SQL:2003 standard introduced an extensive set of mapping rules to define how SQL entities map from SQL to XML (and the reverse). The specification of the rules is quite extensive, and some aspects are implementation dependent, so we won’t cover all of the details here. Broadly speaking, SQL data types are mapped to the closest equivalent type defined in XML Schema. XML Schema facets and annotations can be used to indicate distinctions in certain areas: for example, basic XML Schema does not distinguish between character varying and character large object, which are distinct types in SQL. Delimited identifiers in SQL are mapped as defined, preserving the upper/lower case of characters. Case is not guaranteed to be preserved for regular identifiers.
Some special treatment is given to characters that would result in illegal names in XML. The general technique is the replace the character by _xNNNN_ or _xNNNNNN_, where N is a hexadecimal digit and NNNN or NNNNNN is the Unicode representation of the character. There are two variants of the identifier mapping: partially escapedand fully escaped. The key differences between these are in the treatment of noninitial colons and identifiers beginning with the letters “xml” (in any combination of uppercase or lowercase). The differences are summarized in the examples in Table 13.7.
Using XQuery
XQuery is a language for manipulating XML values. Roughly speaking, XQuery is partnered with XML data in the same way that SQL is partnered with relational data. Like SQL, XQuery is declarative: it expresses the data sources and the processing rules to be applied, but it does not specify the explicit procedure by which the results should be produced. One of the most important aspects introduced in SQL/XML:2006 was the ability to integrate XQuery into the established relational database framework—a key motivator in moving SQL/XML to the XQuery data model.
We’ll return to SQL integration later, but first we’ll look at some aspects of how XQuery works. It’s important to understand some of the main features of XQuery in order to make sense of the SML/XML integration, but we won’t attempt to cover every detail here. Some of the features we’ll discuss are actually defined in the XPath standard, not the XQuery standard, but we’ll gloss over that distinction and use “XQuery” as an umbrella term. The Chapter Notes give some pointers to the particulars if you need them. One point of caution: if you have a background in SQL, you will need to remember that, unlike SQL, XQuery is case sensitive, and so a little care is needed in specifying expressions. It’s also important to keep in mind that we will be operating on XML values and not their serialized representations. So, for example, we’re not trying to textually process “angle brackets”, although these may be useful in denoting structures for human readability.
The crucial distinction between relational and XML data is that XML structure is inherently hierarchical. Interestingly, early hierarchical database systems were commercially successful—IBM’s IMS being a prominent example—before they became overtaken by later developments. The rigidity of these earlier hierarchical systems proved to be uncompetitive against alternatives (especially the relational model) and so they became obsolete. XML does not set out to imitate these earlier systems, but there seems to be something compelling about the hierarchical notion that just won’t go away.
| Mode | SQL identifier | XML name |
|---|---|---|
| Partially escaped | xmlthing
XMLTHING :ab:cd | xmlthing
XMLTHING xOO3A ab:cd |
| Fully escaped | xmlthing
XMLTHING :ab:cd | _x0078 mlthing
_x0058 mlthing _xOO3A ab_xOO3A cd |
For example, the directory structure of most operating systems is organized on the same basis. Even in a graphical interface we have become used to a system of “folders” that can contain a combination of other “folders” and leaf nodes called “files”.
The file system analogy is particularly relevant here, because the XQuery expressions (actually, XPath, but we’re not being picky) that are used to navigate the XML structures resemble the textual commands used to navigate directory structures in non-GUI environments. The basic concepts are shown in Figure 13.6.
Figure 13.6. A node in a hierarchy.
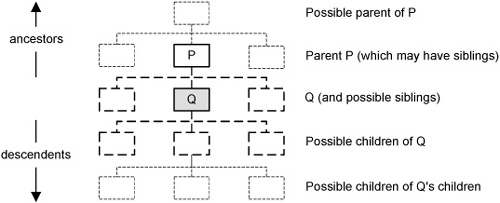
We’re going to be navigating from node Q, which provides the “context” for our path expression. Node Q might be the top of the hierarchy we’re considering, in which case it can be taken to represent the whole of our XML document. Apart from that special case, we can always go up one level from Q to the node P, the parentof Q. If Q has siblings (nodes that also have the parent P) we can navigate sideways. If Q has children, then we can navigate down. Some combination of up/sideways/down movements can take us to a new node. Once we get there, the newly selected node can become the context for some other navigation.
Most of the time, we’re going to be concerned with relationships between XML elements, so, for example, we might want to know about all elements that are “contained in” element Q (i.e., they are descendent nodes of the node Q). But we might also want to know about all elements that have some specific attribute, or all elements related to some particular namespace, and so on. All of these possible dimensions are known in XQuery as axes, and Xquery has a sophisticated notation for the precise definition of navigation along various combinations of axes. Unfortunately, the full notation is a little cumbersome. Fortunately, there are short-form notations that cover the main possibilities, and we’ll concentrate on those.
To provide some concrete examples, we’ll return to the Movies example from Chapter 1. There we saw how the content of a report could be captured as relational tables. Figure 13.7 shows similar information (with slightly different data from the example in Chapter 1) represented as an XML fragment. This is not an XML document because it lacks a root node. The XQuery doc() function can be used to turn such fragments into documents.
Figure 13.7. Movie information in XML.
<movie movieNr="l ">
<title>Cosmology </title >
<released>2006</released>
<director>Lee Lafferty</director>
</movie>
<movie movieNr="2">
<title>Kung Fu Hustle</title>
<released>2004</released>
<director>Stephen Chow</director>
<star gender="M">Stephen Chow</star>
</movie>
<movie movieNr="3">
<title>The Secret Garden</title>
<released>1987</released>
<director>Alan Grint</director>
<star gender="F">Gennie James</star>
<star gender="M">Barret Oliver</star>
</movie>
<movie movieNr="4">
<title>The Secret Garden</title>
<released>1993</released>
<director>Agnieszka Holland</director>
<star gender="F">Kate Maberley</star>
<star gender="M">Heydon Prowse</star>
</movie>
<movie movieNr="5">
<title>The Da Vinci Code</title>
<released>2006</released>
<director>Ron Howard</director>
<star gender="M">Tom Hanks</star>
<star gender="M">lan McKellen</star>
<star gender="F">Audrey Tautou</star>
</movie>
<movie movieNr="6">
<title>Cast Away</title>
<released>2000</released>
<director>Robert Zemeckis</director>
<star gender="M">Tom Hanks</star>
</movie>
|
Navigation is relative to a given node in an XQuery sequence. The basic navigational notation resembles that of a conventional file system. A period or full stop ” . “means “the current node”, “..” means “the parent of the current node”. A slash or solidus character “/” without further qualification means “go down one level”; “ //” means go down any number of levels. Names are taken to refer to elements unless prefixed with “@”, in which case they refer to attributes. At any step in the path a predicate can be introduced in square brackets. This will filter the resulting nodes: only those for which the predicate is “True” will be included. Table 13.8 shows some example expressions.
| Expression | Result |
|---|---|
| Find all directors | <director>Lee Lafferty</director> <director>Stephen Chow</director> |
| movie/director | <director>Alan Grint</director>
<director>Agnieszka Holland</director> <director>Ron Howard</director> <director>Robert Zemeckis</director> |
| Find one star from each movie | <star gender="M">Stephen Chow</star> <star gender="F">Gennie James</star> |
| movie/star [ 1 ] | <star gender="F">Kate Maberley</star>
<star gender="M">Tom Hanks</star> <star gender="M">Tom Hanks</star> |
| Find the titles of all movies with a female | <title>The Secret Garden</title> |
| star | <title>The Secret Garden</title> |
| movie/star [ @gender = "F" ] /../title | <title>The Da Vinci Code</title> |
| Find the release year of all movies starring | <released>2006</released> |
| Tom Hanks | <released>2000</released> |
| movie [ star = "Tom Hanks"] / released |
Now that we have some idea of how to move around an XML hierarchy, we can consider how to query XML data. In simple cases the result of the path expression may be sufficient, but in general we will need more powerful expressions. XQuery is a functional language, so we must specify what we want to do in functional terms. Most software developers are familiar with the concept of a function. A function has a name, zero or more input parameters, and a body that computes some result to be returned. From a functional programming perspective, the arguments to a function can be constants, or the results produced by other functions (i.e., a parameter can be a call to another function). Now we have another hierarchy: functions that provide results to functions that provide ... and so on. This function hierarchy may be established dynamically and may bear no direct relationship to the data hierarchy. The top level of the function hierarchy computes the result we are seeking: the lower level functions provide results to their parents to (ultimately) enable the top level computation. XQuery defines over a hundred built-in functions, but commercial systems may not yet implement all of these.
XQuery allows information to be combined from multiple sources and restructured to produce a new result. The most common expressions of this kind in XQuery are called FLWOR expressions, from the first letter of the clause types that may appear in the expression: for, let, where, order by, and return. FLWOR expressions are the XQuery equivalent of select statements in SQL.
The clauses in a FLWOR expression are defined in terms of tuples. The tuples are created by binding variables to values in for and/or let clauses, and so every FLWOR expression must have at least one for or let clause. The difference between the two is that for iterates over the items in an expression, producing a tuple for each, and let produces one tuple for the entire result of an expression. As a simple example, the following FLWOR expression produces the same result as the last path example in Table 13.8. The dollar sign “$” indicates a variable in XQuery.
for $m in movie where $m/star = "Tom Hanks" return $m/released
As a slightly more complex example, let’s assume that we want to invert the hierarchy of the source XML. For our Movies XML fragment, we could list the movies in which an actor starred under each actor, instead of listing the stars under each movie. An XQuery expression to do this might look like:
for $s in distinct-values ( movie/star ) order by $s descending return <starring> <actor> { $s } </actor> <movies> { for $m in movie where Sin/star = $s return $m/title } </movies> </starring>
Here we’ve used the distinct-values () function to make sure that each actor only appears once and sorted the result in descending order of actor name. The query contains constructors, indicated by braces around an inner expression, which are used to build element content. Evaluating the query produces the result:
<starring>
<actor>Tom Hanks</actor>
<movies>
<title>The Da Vinci Code</title>
<title>Cast Away</title>
</movies>
</starring>
<starring>
<actor>Stephen Chow</actor>
<movies>
<title>Kung Fu Hustle</title>
</movies>
</starring>
...etc.
Of course, we’re not limited to using a single XML document or fragment. Let’s say we have some XML data containing reviews of the movies, which might follow a structure similar to the example shown in Figure 13.8.
Figure 13.8. Movie reviews in XML.
<review reviewNr="1">
<movieNr>4</movieNr>
<rating>4</rating>
<comments>Classic story</comments>
</review>
<review reviewNr="2">
<movieNr>5</movieNr>
<rating>4</rating>
<comments>Great movie!</comments>
</review>
<review reviewNr="3">
<movieNr>5</movieNr>
<rating>5</rating>
<comments>Superb</comments>
</review>
<review reviewNr="4">
<movieNr>5</movie N r>
<rating>1</rating>
<comments>Not my kind of movie</comments>
</review>
|
The reviews are related to the movies by the unique movieNr reference. In standard SQL, if we wanted to show the movie titles along with the rating scores for each movie, we could use a join. We can do the same kind of thing in XQuery.
Here’s one way of doing the equivalent of an inner join between the movie data and the review data.
for $m in movie where some $r in review satisfies( $m/@movieNr = $r/movieNr ) return <reviewscore> { $m/title, $m/released } { for $r in review where $m/@movieNr = $r/movieNr return $r/rating } </reviewscore>
The query includes the release year as well as the title to avoid ambiguities between movies with the same name. The ”where some ... satisfies (...)...” construct is an existential quantifier test, so that we only get results for movies that have had a review. XQuery also has a ”where every... satisfies (...)” universal quantifier construct, which we don’t need here. The query produces the following result:
<reviewscore>
<title>The Secret Garden</title>
<released>1993</released>
<rating>4</rating>
</reviewscore>
<reviewscore>
<title>The Da Vinci Code</title>
<released>2006</released>
<rating>4</rating>
<rating>5</rating>
<rating> 1 </rating>
</reviewscore>
To get the equivalent of an outer join, which would also include the movies with no reviews, we would simply need to omit the existential quantifier test in the second line of the query.
As a final XQuery example, we’ll show the equivalents of the aggregate or bagfunctions in SQL, which include sum (), count (), avg (), max (), and min (). Let’s suppose we want to produce a summary element for each movie, showing the total number of reviews and the average score as attributes. The following query would be one way of producing the required result.
for $m in movie return <reviewsummary total = "{ count ( review [ movieNr = $m/@movieNr ] ) }" avg = "{ avg ( review [ movieNr = $m/@movieNr]/rating ) }"> { Sm/title, $m/released } </reviewsummary>
Here, we’ve used the XQuery functions count () and avg (), which operate in a similar way to their SQL counterparts. For an empty list of elements (in this case, movies that have no reviews) the count () function returns zero and the avg ( ) function returns an empty result. Running the query produces the following XML fragment.
<reviewsummary total="O" avg="">
<title >Cosmology </title >
<released>2006</released>
</reviewsummary>
<reviewsummary total="O" avg="">
<title>Kung Fu Hustle</title>
<released>2004</released>
</reviewsummary>
<reviewsummary total="O" avg="">
<title>The Secret Garden</title>
<released> 1987</released>
</reviewsummary>
<reviewsummary total="1" avg="4">
<title>The Secret Garden</title>
<released> 1993</released>
</reviewsummary>
<reviewsummary total="3" avg="3.33333333333333">
<title>The Da Vinci Code</title>
<released>2006</released>
</reviewsummary>
<reviewsummary total="O" avg="">
<title>Cast Away</title>
<released>2000</released>
</reviewsummary>
XQuery has many other features, and a more complete description would require a book in its own right. Some references to further information sources are included in the chapter notes.
Finally, we’ll look at some mechanisms provided in SQL/XML that help integrate XQuery into the relational framework. The most important of these is the xmlquery function, which allows an XQuery expression to be evaluated from within an SQL context. SQL alone cannot operate on parts of an XML document: the whole document is treated as a single value. With the xmlquery function it’s possible to query inside an XML document so that XML data can participate in SQL queries and SQL processing can be applied to returned XML values (for instance, using order by to order the results). The basic syntax of xmlquery is as follows. The arguments are used in a similar way to the equivalents we have already seen in other functions.
xmlquery ( XQuery-expression [passing [ { by refl by value } ] XML-query-argument [ .... ] ] [ returning { content | sequence } ] [ { by ref | by value } ] [ { null on empty | empty on empty } ])
Another function, xmltable, provides a useful way to integrate XQuery results back into SQL. Normally, an XQuery expression would return a sequence, but using xmltable we can execute an XQuery expression and return values as a table instead. The returned table can contain columns of any SQL data type, including XML, although values inserted into xml columns in xmltable must be well formed with a single root node. The basic syntax is:.
xmltable ([ xmlnamespaces ( namespace-declaration-item [ .... ] ), ] row-pattern [passing [ { by ref | by value } ] XMLquery-argument [ .... ]] columns { { colname for ordinality | colname datatype [by ref | by value ] path column-pattern} [ .... ] })
The row-pattern defines an expression that produces a sequence of elements. Each element in this sequence will become a row in the resulting table. The columns clause lists the column definitions and the path expression used to find the column value within each element of the row-pattern. The for ordinality option creates a column with an automatic ordinal reference to the row, so the first row is 1, the second row 2, and so on. An example is shown here. This assumes that we have an xml value called movieXML; the contents of which are similar to the examples we used when discussing XQuery. If this xmltable function call is contained in a select statement, the value being passed could be selected from a suitable xml column in a table.
xmltable ('//movies' passing movieXML columns "Seqno" for ordinality, "MovieNr" int path '@movieNr', "Movie Name" varchar (50) path 'title', "Release Year" char(4) path 'released' "Director" varchar(50) path 'director')
The resulting table would have the following form, and could be aliased and so on, in the same way as a table produced by other means. In this case, values in the automatically generated SeqNo column and the retrieved MovieNr column are coincidentally the same. Had the XML data been in a different order, the SeqNo column would remain unchanged but the MovieNr column (and the other retrieved columns) would reflect the XML element ordering.
| SeqNo | MovieNr | Movie Name | Release year | Director |
|---|---|---|---|---|
| 1 | 1 | Cosmology | 2006 | Lee Lafferty |
| 2 | 2 | Kung Fu Hustle | 2004 | Stephen Chow |
| 3 | 3 | The Secret Garden | 1987 | Alan Grint |
| 4 | 4 | The Secret Garden | 1993 | Agnieszka Holland |
| 5 | 5 | The Da Vinci Code | 2006 | Ron Howard |
Exercise 13.9
The following schema shows part of a database that holds information about repair technicians and the types of assemblies that they are competent to repair. Different technicians may be competent at repairing different assemblies.
