
4.5. Key Length Check
In step 1 of the CSDP we try to express information examples in terms of elementary facts. At that stage we rely on familiarity with the UoD to determine whether a fact type is simple or compound (splittable). Once uniqueness constraints are added, a formal check can be conducted in this regard. This section discusses a check based on uniqueness constraints, and the next section discusses the notions of projection and join, which may sometimes be used to perform a projection–join check.
Until we are experienced at conceptual schema design, we might include some fact types that are too long or too short. “Too long” means that the arity of the fact type is higher than it should be—the predicate has too many roles. In this case we must split the compound fact type up into two or more simple fact types. For example, the fact type Scientist was born in Country during Year should be split into two fact types: Scientist was born in Country; Scientist was born during Year.
“Too short” means the arity of some fact types is too small, resulting in loss of information—a fact type has been split even though it was elementary. In this case, the fact types resulting from the split need to be recombined into a fact type of higher arity.
For example, suppose that scientists may lecture in many countries in the same year. It would then be wrong to split the fact type Scientist lectured in Country during Year into the fact types: Scientist lectured in Country; Scientist lectured during Year. This kind of error is rare, but serious nevertheless.
For a given fact type, a minimal combination of roles spanned by a UC is called a “key” for that fact type. “Minimal” means the uniqueness constraint has no smaller UC inside it; if it did, it is implied by the smaller (but stronger) constraint and hence should not be shown. Role combinations for such longer, implied uniqueness constraints are called “proper superkeys”. However, as proper superkeys are not minimal, we do not count them as keys in our discussion.
Each role is associated with a column of the fact table for the fact type. Unless the fact type is unary, it is possible for it to have more than one key. Consider the cases shown in Figure 4.44. Here the binary has two one-role keys, the middle ternary has two two-role keys, and other ternary has one three-role key.
Figure 4.44. A fact type has one or more keys.
![]()
The first two predicates also have implied uniqueness constraints across their whole length, but these are not counted as keys for these predicates. The length of a role sequence is the number of roles it contains. A key of length 1 is a simple key. All other keys are composite.
We can imagine unaries or binaries that should be split, but in practice not even a novice designer is likely to verbalize one (e.g., “The Barrister with surname ‘Rum-pole’ smokes and drinks”). So the question of splittability is really an issue only with ternaries and longer fact types.
To help decide when to split in such cases, the so-called “n – 1 rule” may be used: each n-ary fact type has a key length of at least n–1. If this rule is violated, the fact type is not elementary, and hence should be split. Various cases of this rule are set out in Table 4.6. A proof is sketched later in the section.
| Arity of fact type | Minimum key length | Illegal key lengths |
|---|---|---|
| 3 | 2 | 1 |
| 4 | 3 | 1,2 |
| 5 | 4 | 1,2,3 |
| n | n-1 | 1. . . . . n – 2 |
If a fact type is elementary, all its keys must be of the same length. Either there is exactly one key, which spans the whole fact type, or there are one or more keys and each is one role shorter than the fact type. So, if two or more roles in a predicate are not part of a key, the fact type is compound and must be split.
To start with me simplest case, a ternary fact type can be split if it has a simple key. Consider the sample extract of geographic data shown in Table 4.7. The first row of data may be verbalized: “The Country with name ‘Australia’ has a Population of 20,600,856 people and an Area of 7,686,850 square kilometers”. The presence of “and” suggests that the fact is splittable. Suppose, however, that we ignore this linguistic clue and model using the ternary: Country has Population and Area.
| Country | Population | Area (sq. km) |
|---|---|---|
| Australia | 20 600 856 | 7 686 850 |
| Germany | 82 369 548 | 356 910 |
| United States | 303 824 646 | 9 372 610 |
Our familiarity with the UoD tells us that, at any given time, each country has at most one population and at most one area. So there is a uniqueness constraint on the Country column of the fact table. Although the populations and areas in Table 4.7 are unique, our common sense indicates that this is not significant. For example, the population of India is projected to soon equal China’s population, and it is certainly possible to have two countries of the same size. The combination of population and area need not be unique either. This leaves us with the simple UC on the Country role as shown in Figure 4.45.
Figure 4.45. This ternary is a compound fact type, and hence splittable.

Now let’s apply the n – 1 rule. Here the key has length 1, which is 2 less than the length of the fact type. So the fact type is not elementary and must be split. But how do we split it? Examining our verbalization of row 1, we find a conjunction of two facts about the same country. Assuming that our interpretation of the output report is correct, we must split the fact type into two fact types as shown in Figure 4.46. Since the common entity type is Country, the original ternary fact type is “split on Country”.
Figure 4.46. The previous ternary splits into these two elementary fact types

If we have captured the semantics of the output report in step 1 correctly, then it would be wrong to split this fact type in any other way. Before considering this point further, let’s see why the splittability rule works in this case.
Look back at Table 4.7. A uniqueness constraint on the Country column means that, given any state of the database, no country can be listed more than once in this column. Each country has at most one population and each country has at most one area. So for any given country, if we are given as separate pieces of information that country’s population and that country’s area we can reconstruct that country’s row in the output report. Since the ternary fact type of the output report can be split and recombined without information loss, it is not elementary.
If a fact type violates the n - 1 rule, it is essentially a conjunction of smaller fact types even if its predicate has no conjunctive operator such as “and”. Suppose we verbalized the previous ternary as Country with Population has Area. This still means the same, so is really a conjunction in disguise. Similarly, the ternary “Invoice was issued to Customer on Date” has a uniqueness constraint on its first role and can be split into two fact types: Invoice was issued to Customer; Invoice was issued on Date. In general, if a fact type can be rephrased as a conjunction, it should be split, since it is not elementary.
Before considering other examples, let’s review some terminology used in the normalization approach to database design. For a given fact table, let X denote a single column or combinations of columns, and let Y denote a single column. Then we say that Y is functionally dependent on X if and only if, for each value of X there is at most one value of Y. In other words, Fis & function ofX. A function is just a many:l relation (including 1:1 as a special case). If Y is a function of X, we say that X functionally determines Y, written X → Y. This constraint is a functional dependency (FD). Although FD arrows are not used directly in ORM schemas, the theory of FDs provides another way to understand uniqueness constraints.
Now consider the sample output report shown in Table 4.8. If this population is significant, then any functional dependencies should be exposed here. Note that Degree is functionally dependent on Person, since for any given person there is only one degree. Moreover, Gender is a function of Person since for any given person there is only one gender. But can you spot any other functional dependencies?
| Person | Degree | Gender |
|---|---|---|
| Adams | BS | M |
| Brown | BA | F |
| Collins | BS | M |
If the population is significant, then Gender is a function of Degree, and Degree is a function of Gender! Does this make sense? To answer this question we need to know more about the semantics of the UoD. Spotting a functional dependency within a population is a formal game. Knowing whether this dependency reflects an actual constraint in the UoD is not. To assume the population is significant begs the question. Only someone who understands the UoD, a domain expert, can resolve the issue.
In Section 14.6, we extend the traditional treatment of dependencies on individual table populations to dependencies representing actual constraints in the business domain (and hence applying to all possible populations of the table schemes). Some of the following discussion anticipates this extension.
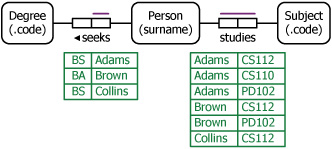
If one column functionally determines another column, this reflects a many: 1 association (or 1 :many depending on the direction of reading) that can be given a meaningful name by the domain expert. Normally we would interpret the table in terms of degree and gender facts about specific persons. But suppose instead that the domain expert says row 1 of the output report should be read as “The Person with surname ‘Adams’ seeks the Degree with code ‘BS’, and the Degree with code ‘BS’ is sought by people of Gender with code ‘M’” With this unusual interpretation, we have two facts about the same degree. Hence we split on Degree rather than Person (see Figure 4.47).
Figure 4.47. A weird UoD where Degree and Gender are functions of each other.
![]()
If Gender really is a function of Degree, then any given degree is restricted to one gender (e.g., only males can seek a BS). If Degree really is a function of Gender then all people of a given gender seek the same degree (e.g., all females seek just a BA). These two FDs are captured in Figure 4.47 by the two uniqueness constraints on the relationship type between Degree and Gender.
While such a UoD is possible, our knowledge about degree awarding institutions makes this interpretation highly unlikely. To resolve our doubts, we could add test rows to the population. Although this is best done on conceptual fact tables, we could also test this example using the original output report. For example, if the domain expert accepts the population of Table 4.9 as being consistent with the UoD, then no FDs occur between Degree and Gender.
| Person | Degree | Gender |
|---|---|---|
| Adams | BS | M |
| Brown | BA | F |
| Collins | BS | M |
| Davis | BS | F |
This by itself does not guarantee that Gender should be related to Person rather than Degree. For example, the schema of Figure 4.47 with the 1:1 constraint changed to a many-.many constraint is still a remote possibility; but it would be silly to have a report with so much redundancy (e.g., the fact that the BS is sought by males would be shown twice already). The only way to be sure is to perform step 1 properly, verbalizing the facts and having them confirmed by the domain expert.
While the notion of FD is useful, it is impractical to treat fact tables in a purely formal way, hunting for FDs. The number of dependencies to check increases rapidly with the fact type length. Although our conceptual focus on elementary fact types constrains this length, the search for FDs can still be laborious. While an automated FD checker can be of use, this kind of exhaustive checking is not fit for humans. We can short-circuit this work by taking advantage of human knowledge of the UoD.
As another simple example, consider the output report of Table 4.10. Suppose that, with the help of the domain expert, we express row 1 thus: the Lecturer with surname “Halpin” works for the Department coded “CS” which is located in the Building numbered “69”. Is this fact splittable, and if so, how?
| Lecturer | Department | Building |
|---|---|---|
| Halpin | CS | 69 |
| Okimura | JA | 1 |
| Orlowska | CS | 69 |
| Wang | CN | 1 |
Here the pronoun “which” introduces a non-restrictive clause about the department that may be stated separately. So this can be rephrased as two facts about the department: Halpin works for the CS department; and the CS department is located in building 69. So we should split on Department to get two fact types (Figure 4.48).
Figure 4.48. Populated conceptual schema for Table 4.10.

As a challenge question, would it also be acceptable to split on Lecturer (e.g., Lecturer works for Department; Lecturer works in Building)? The logical derivation theory discussed in the next chapter shows that it is unwise to split on Lecturer. If the population is significant, then each lecturer works for only one department, and each department is located in only one building. If these constraints are confirmed by the domain expert, they are added to the schema as shown.
An outline proof of the n – 1 rule is now sketched. An n-ary fact type with a key of length less than n – 1 has at least two columns in its fact table that are functionally dependent on this key. Split the table by pairing the key with exactly one of these columns in turn. Recombining by join on this key must generate the original table since only one combined row is possible (otherwise the common key portion would not be a key). Although the n-ary fact table thus formally splits in this way, in practice the splitting might need to be made on part of the key or even a nonkey column if an FD applies there (consider the previous examples).
As an example of a quaternary case, consider the report shown in Table 4.11. Suppose we did a bad job at step 1 and schematized this situation as in Figure 4.49. Notice the uniqueness constraint. Here we have a fact type of length 4, and a key of length 2. Since two roles are excluded from this key, we must split the fact type. How do we split it? Each person seeks at most one degree, but this constraint is not captured by the two-role uniqueness constraint. Hence we split on Person. In terms of FD theory, the Person role functionally determines the Degree role (shown in Figure 4.49 as a solid arrow).
| Person | Degree | Subject | Rating |
|---|---|---|---|
| Adams | BS | CS112
CSll0 PD102 | 7
6 7 |
| Brown | BA | CS112 PD102 | 6 7 |
| Collins | BS | CS 112 | 7 |
Figure 4.49. A quaternary fact type that is splittable (FD added).

If an FD like this is involved, splitting takes place on its source. So the quaternary splits on Person into a binary (Person seeks Degree) and a ternary (Person for Subject scored Rating). As an exercise, draw these, being sure to include all constraints. In any correct ORM schema, all FDs should be captured by uniqueness constraints. So FD arrows are not used on final conceptual schema diagrams. Any quaternary splits if it has a key of length 1 or 2.
Now consider the populated schema in Figure 4.50. Suppose this interpretation of the UoD is correct. For example, suppose the first row of the output report behind this schema really does express the information “The Person with surname ‘Adams’ seeking the Degree with code ‘BS’ studies the Subject with code ‘CS112’”. Should the ternary be split?
Figure 4.50. Is this ternary splittable?

Unlike the quaternary example, this ternary satisfies the n–1 rule. Violating the n–1 rule is a sufficient condition for splittability, but it is not a necessary condition. The ternary in this example does actually split. One way to see this is to realize that there is an embedded FD (i.e., an FD not captured by the uniqueness constraint(s)). In this case there is an embedded FD from the Person role to the Degree role, shown as an arrow in Figure 4.50.
However, every FD corresponds to a uniqueness constraint on some predicate, and it is better to verbalize this. Here the fact type behind the embedded FD is: Person seeks Degree. The remaining information can then be expressed with another fact type. Here that is Person studies Subject.
We can achieve the same effect without talking about FDs, by simply answering the question: Can you rephrase the information in terms of a conjunction? This approach was used earlier with the Country example. With our current example, instead of using the present participle “seeking”, we can rephrase the information on the first row as:
The Person with surname ‘Adams’ seeks the Degree with code ‘BS’ and studies the Subject with code ‘CS112’.
which is equivalent to:
The Person with surname ‘Adams’ seeks the Degree with code ‘BS’ and the Person with surname ‘Adams’ studies the Subject with code ‘CS112’.
This is obviously a conjunction with Person common to each conjunct. So the ternary should be split on Person into two binaries (see Figure 4.51).
Figure 4.51. The ternary in Figure 4.50 should be split like this.
In general, given a significant fact table, the fact type is splittable if a column is functionally dependent on only some of the other columns. The phrase “only some” means “some but not all”. This result corresponds to a basic rule in normalization theory (discussed in Section 12.6). With our present example, because the Degree column is functionally dependent on the Person column only, it should not be combined in a fact type with Subject information.
Another way to test for splittability is to perform a redundancy check by determining whether some fact is (unnecessarily) duplicated in the fact table. For example, in Figure 4.50 the pair (Adams, BS) occurs three times. Using our semantic insight, we see that this pair corresponds to a fact of interest (Adams seeks a BS degree). Since this fact has been duplicated, the ternary is not elementary.
Redundancy is not a necessary requirement for splittability. For example, the ternary in Table 4.9 has no redundancy but is splittable.
Whichever method is used to spot splittability, we still need to phrase the information as a conjunction of simpler facts. Notice how the redundancy within the ternary of Figure 4.47 has been eliminated by splitting it into two binaries in Figure 4.50. Although we may allow redundancy in output reports, we should avoid redundancy in the actual tables stored in the database.
Our examples so far have avoided nested fact types. Recall that nesting is not the same as splitting. If nesting is used, the following spanning rule can be used to avoid splittable fact types: the uniqueness constraint on an objectified association should normally span all its roles.
This rule simply adapts earlier results to the nested case. Suppose the objectified predicate has a UC over only some of its roles. If an attached, outside role has a uniqueness constraint on it, when the outer predicate is flattened we have at least two roles not spanned by a uniqueness constraint.
If an attached role has no UC, then flattening generates a predicate with an embedded FD not expressed as a uniqueness constraint (consider the cases of Figure 4.49 and Figure 4.50). In either case, the flattened version must split because it is not elementary. Hence to be elementary in this sense, the nested version must obey the spanning rule.
In the previous version of ORM, the only exception to the spanning rule was to allow 1:1 binaries to be objectified (e.g., Person is husband of / is wife of Person may be objectified as “Marriage”).
The second generation ORM discussed in this book allows any fact type to be objectified, regardless of its uniqueness constraint pattern, and is similar to UML in this aspect (e.g. n: associations may be objectified). Although allowed for pragmatic reasons, such exceptions violate elementarity and require special treatment when mapped to logical models. Moreover, objectification without spanning uniqueness often makes the model more complicated than needed.
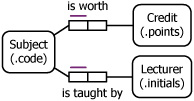
Consider the output report of Table 4.12. Here the credit for a given subject is measured in points. The “?” on the second row is a null, indicating that a real value is not recorded (e.g., a lecturer for CS109 might not yet have been assigned).
| Subject | Credit | Lecturer |
|---|---|---|
| CS 100 | 8 | DBJ |
| CS109 | 5 | ? |
| CSl12 | 8 | TAH |
| CSl13 | 8 | TAH |
Recall that elementary fact tables can’t contain nulls (because you can’t record half a fact). However, since output reports can group facts of different kinds in the one table, they often do contain nulls (indicating absence of a fact instance).
Now let’s play the part of an inexperienced, and not very clever, schema designer, so that we can learn by the mistakes made. Looking just at the first row, we might be tempted to treat the information as a ternary:
Subject (.code) ‘CS100’ worth Credit (.points) 8 is taught by Lecturer (.initials) ‘DBJ’.
If we drew the schema diagram now and populated it we would discover an error, since the second row doesn’t fit this pattern (since we don’t allow nulls in our fact tables). The second row reveals the need to be able to record the credit points for a subject without indicating the lecturer. So we then rephrase the first row as follows:
Subject (.code) ‘CS100’ is worth Credit (.points) 8. This SubjectCredit is taught by Lecturer (.initials) ‘DBJ’.
This overcomes the problem with the second row, since we can now express the information there simply as “Subject ‘CS109’ is worth Credit 5”. Using this approach, we can now develop the schema shown in Figure 4.52.
Figure 4.52. A faulty schema.

Assuming that the population of the output report is significant, we mark the uniqueness constraints as shown. Note that a simple UC has been added to the objectified association. This breaks the spanning rule: an objectified association has no key shorter than itself. So something may be wrong. Since the schema follows from our handling of step 1, this means that we may have made a mistake at step 1.
Have another look at the way we set out the information for row 1. The second sentence here is the problem. In this UoD each subject has exactly one credit point value, so this is independent of who teaches the subject. As a result, there is no need to mention the credit point value of a subject when we indicate the lecturer. In FD terminology, the Credit and Lecturer columns are each functionally dependent on the Subject column alone.
The information on the first row can be set out in terms of two simple binaries:
Subject (.code) ‘CS100” is worth Credit (.points) 8. Subject (.code) ‘CS100’ is taught by Lecturer (.initials) ‘DBJ’.
This leads to the correct schema shown in Figure 4.53. Note that Lecturer depends only on Subject, not Credit. The nested schema suggested incorrectly that Lecturer was dependent on both, by relating Lecturer to the objectified association. With this example, Lecturer is a function of Subject, but this has no bearing on the splittability. We should use two binaries even if the same subject can have many lecturers. It is the functional dependency of Credit on Subject that disqualifies the nested approach.
Figure 4.53. The corrected schema for Figure 4.52.
In a case like this where it is difficult to come up with a natural name for the objectified association, such nesting errors are unlikely to occur in practice. When a natural name for the nested object type is available however, it is easier to make the error. For example, we might objectify the fact type Person was bom in Country as “Birth”, and then add the fact type: Birth occurred on Date. Although it sounds reasonable, this nesting violates the spanning rule, and should normally be replaced by the unnested binary: Person was born on Date.
In some cases, it is reasonable to objectify associations with no spanning uniqueness (e.g., if the uniqueness constraint is likely to later change to a spanning constraint or if many related roles are played by the objectified association). We discuss such cases in Chapter 10 and provide heuristics for choosing when to objectify.
One lesson to be learned from this section is to look out for uniqueness constraints even when performing step 1. Consider the output report of Table 4.13. If told the population is significant, how would you model this?
| Person | Subject | Rating |
|---|---|---|
| Adams | CS112 | 7 |
| Brown | CS112 | 5 |
| Collins | PD102 | 5 |
If you used either a ternary or a nested fact type, you made a mistake! Although similar to an earlier example, the UoD described by this table is more restricted. Given that the population is significant, the lack of duplicates in the Person column indicates that, at any given time, each person can be enrolled in only one subject.
For example, these people might be your employees, and you are funding their studies and want to ensure that they don’t take on so much study that it interferes with their work performance.
Since we store information only about the current enrollments, and each person is enrolled in only one subject, it follows that each person can get only one rating. So if we know the subject in which a person is enrolled and we know the rating obtained by the person, we do know the subject in which this rating is obtained by that person. To begin with, we might express the information on the first row of the table in terms of the ternary “Person (surname) ‘Adams’ scores Rating (.nr) 7 for Subject (.code) ‘CS112’. However, because of the uniqueness constraint on Person we should rephrase this information as the conjunction:
Person (surname) ‘Adams’ studies Subject (.code) ‘CS112’
and
Person (surname) ‘Adams’ scores Rating (.nr) 7.
This leads to a conceptual schema with two binary fact types. Because of this unusual UC, the ternary has the same truth value as the conjunction of binaries for all possible states of this UoD.
