
Chapter 7. Achieving Object-Oriented Design
In matters of style, swim with the current; in matters of principle, stand like a rock.
—Thomas Jefferson
How Writing a Test First Helps the Design
The design principles we outlined in the previous chapter apply to finding the right boundaries for an object so that it plays well with its neighbors—a caller wants to know what an object does and what it depends on, but not how it works. We also want an object to represent a coherent unit that makes sense in its larger environment. A system built from such components will have the flexibility to reconfigure and adapt as requirements change.
There are three aspects of TDD that help us achieve this scoping. First, starting with a test means that we have to describe what we want to achieve before we consider how. This focus helps us maintain the right level of abstraction for the target object. If the intention of the unit test is unclear then we’re probably mixing up concepts and not ready to start coding. It also helps us with information hiding as we have to decide what needs to be visible from outside the object.
Second, to keep unit tests understandable (and, so, maintainable), we have to limit their scope. We’ve seen unit tests that are dozens of lines long, burying the point of the test somewhere in its setup. Such tests tell us that the component they’re testing is too large and needs breaking up into smaller components. The resulting composite object should have a clearer separation of concerns as we tease out its implicit structure, and we can write simpler tests for the extracted objects.
Third, to construct an object for a unit test, we have to pass its dependencies to it, which means that we have to know what they are. This encourages context independence, since we have to be able to set up the target object’s environment before we can unit-test it—a unit test is just another context. We’ll notice that an object with implicit (or just too many) dependencies is painful to prepare for testing—and make a point of cleaning it up.
In this chapter, we describe how we use an incremental, test-driven approach to nudge our code towards the design principles we described in the previous chapter.
Communication over Classification
As we wrote in Chapter 2, we view a running system as a web of communicating objects, so we focus our design effort on how the objects collaborate to deliver the functionality we need. Obviously, we want to achieve a well-designed class structure, but we think the communication patterns between objects are more important.
In languages such as Java, we can use interfaces to define the available messages between objects, but we also need to define their patterns of communication—their communication protocols. We do what we can with naming and convention, but there’s nothing in the language to describe relationships between interfaces or methods within an interface, which leaves a significant part of the design implicit.
Interface and Protocol
![]()
Steve heard this useful distinction in a conference talk: an interface describes whether two components will fit together, while a protocol describes whether they will work together.
We use TDD with mock objects as a technique to make these communication protocols visible, both as a tool for discovering them during development and as a description when revisiting the code. For example, the unit test towards the end of Chapter 3 tells us that, given a certain input message, the translator should call listener.auctionClosed() exactly once—and nothing else. Although the listener interface has other methods, this test says that its protocol requires that auctionClosed() should be called on its own.

TDD with mock objects also encourages information hiding. We should mock an object’s peers—its dependencies, notifications, and adjustments we categorized on page 52—but not its internals. Tests that highlight an object’s neighbors help us to see whether they are peers, or should instead be internal to the target object. A test that is clumsy or unclear might be a hint that we’ve exposed too much implementation, and that we should rebalance the responsibilities between the object and its neighbors.
Value Types
Before we go further, we want to revisit the distinction we described in “Values and Objects” (page 13): values are immutable, so they’re simpler and have no meaningful identity; objects have state, so they have identity and relationships with each other.
The more code we write, the more we’re convinced that we should define types to represent value concepts in the domain, even if they don’t do much. It helps to create a consistent domain model that is more self-explanatory. If we create, for example, an Item type in a system, instead of just using String, we can find all the code that’s relevant for a change without having to chase through the method calls. Specific types also reduce the risk of confusion—as the Mars Climate Orbiter disaster showed, feet and metres may both be represented as numbers but they’re different things.1 Finally, once we have a type to represent a concept, it usually turns out to be a good place to hang behavior, guiding us towards using a more object-oriented approach instead of scattering related behavior across the code.
1. In 1999, NASA’s Mars Climate Orbiter burned up in the planet’s atmosphere because, amongst other problems, the navigation software confused metric with imperial units. There’s a brief description at http://news.bbc.co.uk/1/hi/sci/tech/514763.stm.
We use three basic techniques for introducing value types, which we’ve called (in a fit of alliteration): breaking out, budding off, and bundling up.
Breaking out
When we find that the code in an object is becoming complex, that’s often a sign that it’s implementing multiple concerns and that we can break out coherent units of behavior into helper types. There’s an example in “Tidying Up the Translator” (page 135) where we break a class that handles incoming messages into two parts: one to parse the message string, and one to interpret the result of the parsing.
Budding off
When we want to mark a new domain concept in the code, we often introduce a placeholder type that wraps a single field, or maybe has no fields at all. As the code grows, we fill in more detail in the new type by adding fields and methods. With each type that we add, we’re raising the level of abstraction of the code.
Bundling up
When we notice that a group of values are always used together, we take that as a suggestion that there’s a missing construct. A first step might be to create a new type with fixed public fields—just giving the group a name highlights the missing concept. Later we can migrate behavior to the new type, which might eventually allow us to hide its fields behind a clean interface, satisfying the “composite simpler than the sum of its parts” rule.
We find that the discovery of value types is usually motivated by trying to follow our design principles, rather than by responding to code stresses when writing tests.
Where Do Objects Come From?
The categories for discovering object types are similar (which is why we shoehorned them into these names), except that the design guidance we get from writing unit tests tends to be more important. As we wrote in “External and Internal Quality” (page 10), we use the effort of unit testing to maintain the code’s internal quality. There are more examples of the influence of testing on design in Chapter 20.
Breaking Out: Splitting a Large Object into a Group of Collaborating Objects
When starting a new area of code, we might temporarily suspend our design judgment and just write code without attempting to impose much structure. This allows us to gain some experience in the area and test our understanding of any external APIs we’re developing against. After a short while, we’ll find our code becoming too complex to understand and will want to clean it up. We can start pulling out cohesive units of functionality into smaller collaborating objects, which we can then unit-test independently. Splitting out a new object also forces us to look at the dependencies of the code we’re pulling out.
We have two concerns about deferring cleanup. The first is how long we should wait before doing something. Under time pressure, it’s tempting to leave the unstructured code as is and move on to the next thing (“after all, it works and it’s just one class...”). We’ve seen too much code where the intention wasn’t clear and the cost of cleanup kicked in when the team could least afford it. The second concern is that occasionally it’s better to treat this code as a spike—once we know what to do, just roll it back and reimplement cleanly. Code isn’t sacred just because it exists, and the second time won’t take as long.
The Tests Say...
![]()
Break up an object if it becomes too large to test easily, or if its test failures become difficult to interpret. Then unit-test the new parts separately.
Looking Ahead...
![]()
In Chapter 12, when extracting an AuctionMessageTranslator, we avoid including its interaction with MainWindow because that would give it too many responsibilities. Looking at the behavior of the new class, we identify a missing dependency, AuctionEventListener, which we define while writing the unit tests. We repackage the existing code in Main to provide an implementation for the new interface. AuctionMessageTranslator satisfies both our design heuristics: it introduces a separation of concerns by splitting message translation from auction display, and it abstracts message-handling code into a new domain-specific concept.
Budding Off: Defining a New Service That an Object Needs and Adding a New Object to Provide It
When the code is more stable and has some degree of structure, we often discover new types by “pulling” them into existence. We might be adding behavior to an object and find that, following our design principles, some new feature doesn’t belong inside it.
Our response is to create an interface to define the service that the object needs from the object’s point of view. We write tests for the new behavior as if the service already exists, using mock objects to help describe the relationship between the target object and its new collaborator; this is how we introduced the AuctionEventListener we mentioned in the previous section.
The development cycle goes like this. When implementing an object, we discover that it needs a service to be provided by another object. We give the new service a name and mock it out in the client object’s unit tests, to clarify the relationship between the two. Then we write an object to provide that service and, in doing so, discover what services that object needs. We follow this chain (or perhaps a directed graph) of collaborator relationships until we connect up to existing objects, either our own or from a third-party API. This is how we implement “Develop from the Inputs to the Outputs” (page 43).
We think of this as “on-demand” design: we “pull” interfaces and their implementations into existence from the needs of the client, rather than “pushing” out the features that we think a class should provide.
The Tests Say...
![]()
When writing a test, we ask ourselves, “If this worked, who would know?” If the right answer to that question is not in the target object, it’s probably time to introduce a new collaborator.
Looking Ahead...
![]()
In Chapter 13, we introduce an Auction interface. The concept of making a bid would have been an additional responsibility for AuctionSniper, so we introduce a new service for bidding—just an interface without any implementation. We write a new test to show the relationship between AuctionSniper and Auction. Then we write a concrete implementation of Auction—initially as an anonymous class in Main, later as XMPPAuction.
Bundling Up: Hiding Related Objects into a Containing Object
This is the application of the “composite simpler than the sum of its parts” rule (page 53). When we have a cluster of related objects that work together, we can package them up in a containing object. The new object hides the complexity in an abstraction that allows us to program at a higher level.
The process of making an implicit concept concrete has some other nice effects. First, we have to give it a name which helps us understand the domain a little better. Second, we can scope dependencies more clearly, since we can see the boundaries of the concept. Third, we can be more precise with our unit testing. We can test the new composite object directly, and use a mock implementation to simplify the tests for code from which it was extracted (since, of course, we added an interface for the role the new object plays).
The Tests Say...
![]()
When the test for an object becomes too complicated to set up—when there are too many moving parts to get the code into the relevant state—consider bundling up some of the collaborating objects. There’s an example in “Bloated Constructor” (page 238).
Looking Ahead...
![]()
In Chapter 17, we introduce XMPPAuctionHouse to package up everything to do with the messaging infrastructure, and SniperLauncher for constructing and attaching a Sniper. Once extracted, the references to Swing behavior in SniperLauncher stand out as inappropriate, so we introduce SniperCollector to decouple the domains.
Identify Relationships with Interfaces
We use Java interfaces more liberally than some other developers. This reflects our emphasis on the relationships between objects, as defined by their communication protocols. We use interfaces to name the roles that objects can play and to describe the messages they’ll accept.
We also prefer interfaces to be as narrow as possible, even though that means we need more of them. The fewer methods there are on an interface, the more obvious is its role in the calling object. We don’t have to worry which other methods are relevant to a particular call and which were included for convenience. Narrow interfaces are also easier to write adapters and decorators for; there’s less to implement, so it’s easier to write objects that compose together well.
“Pulling” interfaces into existence, as we described in “Budding Off,” helps us keep them as narrow as possible. Driving an interface from its client avoids leaking excess information about its implementers, which minimizes any implicit coupling between objects and so keeps the code malleable.
Refactor Interfaces Too
Once we have interfaces for protocols, we can start to pay attention to similarities and differences. In a reasonably large codebase, we often start to find interfaces that look similar. This means we should look at whether they represent a single concept and should be merged. Extracting common roles makes the design more malleable because more components will be “plug-compatible,” so we can work at a higher level of abstraction. For the developer, there’s a secondary advantage that there will be fewer concepts that cost time to understand.
Alternatively, if similar interfaces turn out to represent different concepts, we can make a point of making them distinct, so that the compiler can ensure that we only combine objects correctly. A decision to separate similar-looking interfaces is a good time to reconsider their naming. It’s likely that there’s a more appropriate name for at least one of them.
Finally, another time to consider refactoring interfaces is when we start implementing them. For example, if we find that the structure of an implementing class is unclear, perhaps it has too many responsibilities which might be a hint that the interface is unfocused too and should be split up.
Compose Objects to Describe System Behavior
TDD at the unit level guides us to decompose our system into value types and loosely coupled computational objects. The tests give us a good understanding of how each object behaves and how it can be combined with others. We then use lower-level objects as the building blocks of more capable objects; this is the web of objects we described in Chapter 2.
In jMock, for example, we assemble a description of the expected calls for a test in a context object called a Mockery. During a test run, the Mockery will pass calls made to any of its mocked objects to its Expectations, each of which will attempt to match the call. If an Expectation matches, that part of the test succeeds. If none matches, then each Expectation reports its disagreement and the test fails. At runtime, the assembled objects look like Figure 7.1:
Figure 7.1 jMock Expectations are assembled from many objects
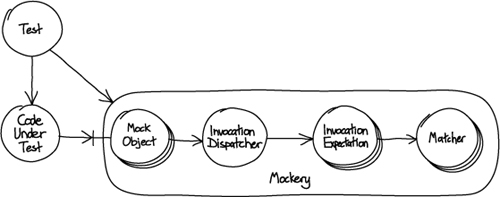
The advantage of this approach is that we end up with a flexible application structure built from relatively little code. It’s particularly suitable where the code has to support many related scenarios. For each scenario, we provide a different assembly of components to build, in effect, a subsystem to plug into the rest of the application. Such designs are also easy to extend—just write a new plug-compatible component and add it in; you’ll see us write several new Hamcrest matchers in Part III.
For example, to have jMock check that a method example.doSomething() is called exactly once with an argument of type String, we set up our test context like this:

Building Up to Higher-Level Programming
You have probably spotted a difficulty with the code fragment above: it doesn’t explain very well what the expectation is testing. Conceptually, assembling a web of objects is straightforward. Unfortunately, the mainstream languages we usually work with bury the information we care about (objects and their relationships) in a morass of keywords, setters, punctuation, and the like. Just assigning and linking objects, as in this example, doesn’t help us understand the behavior of the system we’re assembling—it doesn’t express our intent.2
2. Nor does the common alternative of moving the object construction into a separate XML file.
Our response is to organize the code into two layers: an implementation layer which is the graph of objects, its behavior is the combined result of how its objects respond to events; and, a declarative layer which builds up the objects in the implementation layer, using small “sugar” methods and syntax to describe the purpose of each fragment. The declarative layer describes what the code will do, while the implementation layer describes how the code does it. The declarative layer is, in effect, a small domain-specific language embedded (in this case) in Java.3
3. This became clear to us when working on jMock. We wrote up our experiences in [Freeman06].
The different purposes of the two layers mean that we use a different coding style for each. For the implementation layer we stick to the conventional object-oriented style guidelines we described in the previous chapter. We’re more flexible for the declarative layer—we might even use “train wreck” chaining of method calls or static methods to help get the point across.
A good example is jMock itself. We can rewrite the example from the previous section as:
The Expectations object is a Builder [Gamma94] that constructs expectations. It defines “sugar” methods that construct the assembly of expectations and matchers and load it into the Mockery, as shown in Figure 7.2.
Figure 7.2 A syntax-layer constructs the interpreter
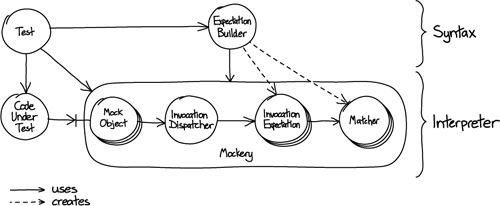
Most of the time, such a declarative layer emerges from continual “merciless” refactoring. We start by writing code that directly composes objects and keep factoring out duplication. We also add helper methods to push the syntax noise out of the main body of the code and to add explanation. Taking care to notice when an area of code is not clear, we add or move structure until it is; this is very easy to do in a modern refactoring IDE. Eventually, we find we have our two-layer structure. Occasionally, we start from the declarative code we’d like to have and work down to fill in its implementation, as we do with the first end-to-end test in Chapter 10.
Our purpose, in the end, is to achieve more with less code. We aspire to raise ourselves from programming in terms of control flow and data manipulation, to composing programs from smaller programs—where objects form the smallest unit of behavior. None of this is new—it’s the same concept as programming Unix by composing utilities with pipes [Kernighan76],4 or building up layers of language in Lisp [Graham93]—but we still don’t see it in the field as often as we would like.
4. Kernighan and Plauger attribute the idea of pipes to Douglas McIlroy, who wrote a memo in 1964 suggesting the metaphor of data passing through a segmented garden hose. It’s currently available at http://plan9.bell-labs.com/who/dmr/mdmpipe.pdf.
And What about Classes?
One last point. Unusually for a book on object-oriented software, we haven’t said much about classes and inheritance. It should be obvious by now that we’ve been pushing the application domain into the gaps between the objects, the communication protocols. We emphasize interfaces more than classes because that’s what other objects see: an object’s type is defined by the roles it plays.
We view classes for objects as an “implementation detail”—a way of implementing types, not the types themselves. We discover object class hierarchies by factoring out common behavior, but prefer to refactor to delegation if possible since we find that it makes our code more flexible and easier to understand.5 Value types, on the other hand, are less likely to use delegation since they don’t have peers.
5. The design forces, of course, are different in languages that support multiple inheritance well, such as Eiffel [Meyer91].
There’s plenty of good advice on how to work with classes in, for example, [Fowler99], [Kerievsky04], and [Evans03].