
HOUR 5
Network Concepts
What You’ll Learn in This Hour:
• Principal hardware and software elements of a network
• The need for speed in computer networks
• Network hardware: routers (switches, bridges, hubs) and servers
• Network software: server operating systems
• Media options for the communications link
For the past four hours, we have examined the basic components of computers and how these components relate to networking. This hour expands this information and explains networking hardware and software in more depth. Some of the topics covered here were introduced earlier. For this hour, we take a closer look at them. The preceding discussions viewed them as standalone ingredients to the networking recipe. Now we mix them up a bit and discover how they interact to provide a coherent service to users. By necessity and because of their scope, we will parcel the subject of networking software into more than one hour. The latter part of this hour is an introduction to Server Operating Systems (SOS). In Part IV, “Network Operating Systems,” we return to SOS with more details.
Elements of a Network
A computer, such as a PC with special software, could fulfill the roles of the hardware and software described in this hour. However, the computer’s hardware and software have been designed to support an all-purpose computing environment. Thus, the conventional computer is a “generalist”: It performs generic services well but is not tailored for specific tasks, such as data communications networking. To illustrate this idea, we examine two key pieces of networking hardware: the router and the server. We follow this discussion with an examination of a key component of networking software: server operating systems. We preface these topics with a discussion about the speeds of computer networks.
The Need for Speed
We learned in Hour 1, “An Overview of Networking,” that the term “speed” refers to how quickly a packet’s contents are sent to a receiver. This time depends on how long it takes network machines to process a packet, such as receiving a packet from a communications link, examining its destination address, and forwarding it to another link. For our analysis here, speed does not mean the time it takes a packet to travel over the links. Traveling time, or propagation delay, is an aspect of speed governed by the laws of physics.
Whatever the definition of speed may be, users want “fast” networks. They want a quick response to their request for a new page during a Web session; they want quick turnaround to their request for a file transfer. Even if their electronic pen pal takes a while to key in a text message, they want an instant display of their partner’s happenstance input.
Thus, in addition to a computer network’s requirement to deliver accurate information to an end user, it must deliver this information in a timely manner. This task is no small feat. Consider the Internet, for example. It processes billions of packets 24/7, provides an average delay through the Internet of less than one-fourth of a second, and loses only about 2–3% of those billions of packets. And, don’t forget: Software in your computer ensures the lost packets (if needed) are re-sent. It’s an extraordinary service that most of us take for granted.
Speed Factors
Two factors contribute to speed...or the lack thereof: (a) delays in processing traffic in hardware and (b) delays in processing traffic in software. That stated, regardless of the efficiency and speed of hardware and software, ultimately they are slaves to the amount of data they must process in a given time.
For example, during certain times of the day, more users are logged on to a network than at other times, which, of course generates more traffic (packets) for the hardware and software to process. If the hardware and software cannot process each packet as it arrives, the data is placed into a queue in memory or on disk to await the availability of resources. The idea is the same as our waiting in line at a movie theater to purchase a ticket. We stay in this queue until the ticket seller can wait on us. If a lot of customers arrived before we did and are waiting in line ahead of us, we experience a delay in buying our tickets. Like data packets obtaining service from the CPU, we experience a longer response time obtaining service from the ticket seller.
This explanation also explains why you might experience longer response times when connected to a data network. There are more users logged on; they are generating more traffic; the queues are bigger. It’s almost that simple. The other factor is the blend of traffic being processed by the network. If many video and voice users are active, the network must process considerably more packets, because voice and video applications require more bandwidth (in bits per second) than email and text messaging.
Hardware and software speed can be measured in several ways—some performed on paper, others performed in a lab. The best tests measure real-world performance, or how data is processed in an existent situation. Fortunately for you, by the time you have made decisions about the hardware and software components of your network, your vendors have already expended many hours in the design and testing of their products—all with the goal of providing fast processing to minimize delay.
Hardware Considerations
Unless your specialty is network performance, you’re usually exempt from the need to perform tests on hardware speeds. That being the situation, what should you be aware of? What aspects of hardware performance might be a valid concern? If you have concerns, check your vendors’ performances on the following components:
• Capacity of CPU(s) (measured in clock rate, bits or floating point operations per second [FLOPS], or for networking, the number of packets processed per second)
• Amount of memory and its access performance (latency to fetch data from and send data to memory locations)
• Efficiency and speed of cache (latency to fetch data from and send data to the CPU)
• Amount of disk and time to access and transfer data into and out of the computer
• Network cards’ capacity in speed and buffering capabilities
Software Considerations
Likewise, given that you will usually be exempt from the need to perform tests on software efficiency, what should you be aware of? At the risk of oversimplification, other than purchasing a better-performing product, it’s likely an ill-performing piece of software will be beyond most remedial actions available to you. But some options are usually available in most software vendors’ products.
One option is increasing the amount of memory available to the program. This change can yield two benefits, both contributing to better performance. First, the program’s code might not have to be traded in and out of computer memory to and from disk. With limited memory, the operating system might be forced into paging operations: moving software modules to and from disk, a situation that can lead to poor performance. Second, for some software programs, the space for their queues is increased, thus allowing the software to better service its traffic load.
![]()
For hardware and software performance issues, the best approach is to talk to your vendors. It is in their interests to keep you happy. But this dialogue is usually not just a matter of the vendor maintaining a relationship with a specific customer. The vendor wants to solve the problem unto itself. Plus, and a very big plus, the vendor has in place sophisticated procedures to assist you in assessing the “speed” of your network. You’re paying for the product; make the best of your contract.
Notwithstanding these caveats, many networking hardware and software components provide users with diagnostic capabilities, which are available to you. In Part IV, we delve into this topic in more detail.
For the remainder of this hour, we turn our attention to several key hardware and software elements found in many data communications networks. First, we examine two hardware components: the router and the server. Next, we highlight server operating systems, with the emphasis on Microsoft Windows Server, UNIX and Linux, and Novell NetWare. The balance of this hour concludes with an introduction to commonly used media, such as copper wire and optic fibers.
Router
A router is a specialized hardware device with a tailored operating system—all designed to relay (route) packets between nodes in a data network. Although the term “data” is used in the previous sentence, routers routinely process packets containing voice, video, photos, and music. All user traffic has been encoded into binary images of 1s and 0s. Thus, the router does not care about the specific nature of the traffic. Nonetheless, network managers have tools to place priority parameters in the packet header to inform a router it is to treat certain packets, such as time-sensitive voice traffic, with a higher priority than, say, a file transfer.
Figure 1.3 in Hour 1 is an example of a simple router situation: one connecting two small home networks to the Internet to “low-end” routers. These routers usually support only a few Ethernet interfaces and a limited number of wireless devices. In contrast, the routers deployed in enterprises, such as banks and retail stores, are much more powerful. These “high-end” machines contain multiple processors and specialized hardware called application-specific integrated circuits (ASICs). As suggested by the name, these ICs are tailored to perform specialized tasks. For a router, they assist in the tasks of (a) finding a route to a destination and (b) forwarding the packets based on this route discovery. Regardless of the possible use of ASICs, all routers engage in their most important jobs: routing and forwarding.
Routing
Routing, or more accurately, route discovery, involves the building in router memory of a routing table or routing information base (RIB). This table provides the same service as a road map. A road map shows where (which road) to drive a vehicle to the next city toward a final destination city. Likewise, the routing table shows where (which communications link) to forward traffic (packets) to the next node toward a final destination computer. Entries in the routing table are created by a process called route advertising, shown in Figure 5.1.
FIGURE 5.1 Route advertising to create the routing table
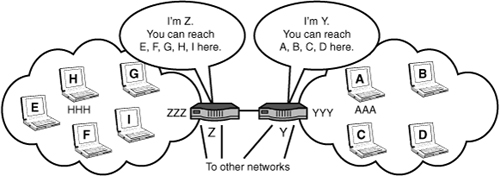
For simplicity, we examine the Internet Protocol (IP) and Media Access Control (MAC) addresses of four nodes with these abbreviated symbolic values. Recall from Hour 3, “Getting Data from Here to There: How Networking Works,” that the IP address is 32 bits long and the MAC address is 48 bits long.
• Node A has an IP address of A and a MAC address of AAA.
• Node Y has an IP address of Y and a MAC address of YYY.
• Node Z has an IP address of Z and a MAC address of ZZZ.
• Node H has an IP address of H and a MAC address of HHH.
The router with address Y knows about nodes A–D because these machines are attached to a local area network (LAN) interface on this router. When you turn on your computer, one of the initial operations performed by its software is the sending of packets to a locally attached router to inform the router your computer is up and running and to furnish the router with the IP address of your PC. Let’s assume it is IP address A. Likewise, the router informs your PC about its IP address. Additionally, the router and PC exchange their Ethernet MAC addresses. Shortly we will see why.
Another initiation operation takes place at router Y. It must inform all directly attached devices, such as computers, servers, and other routers, about its active presence (it’s turned on!) and about its IP address Y. This convention is appropriately called a “Hello” in the industry.
Next, router Y is obligated to advertise IP address A to other networks’ routers to which it is directly attached by a communications link.
In this example, it informs router Z the node with address A can be reached at address Y. The receiving router (Z) stores this information in a routing table. Router Z also stores which communications line (which physical port) can be used to reach A. After all, a high-end router might have scores of communications links in operation to other networks, as seen in Figure 5.1. Router Z must know the specific link to use to send packets to A.
Router Z then relays this advertisement to all the networks to which it is attached, but it changes the advertisement slightly. It informs its neighbor networks and the attached computers that address A is reachable through router Z and not router Y.
Notice this elegant subtlety. By advertising only the next network that can reach node A, nonadjacent networks are “hidden” from other networks. All that the router and nodes care about is the next hop toward a destination. This technique simplifies routing and provides a bit of privacy as well.
In a few milliseconds, the advertisement about A from router Y reaches router Z, which informs the nodes “behind it” about the ability to reach node A, through node Z. These computers store this information in their own routing tables.
In a matter of seconds (usually fractions of a second) the address of your computer is made known, at least conceptually, to any computer in the world. I say conceptually because security and privacy policies—as well as matters of efficiency—curtail how this advertisement is promulgated. Nonetheless, the basic operation is not much more complex than this explanation.
Forwarding
After the entry for the routing table has been created, the following operations take place. Please refer to Figure 5.2 during this discussion. Computer H wants to send data to computer A. Courtesy of route discovery, computer H has enough information in its routing table to know node A can be reached through node Z. It forms an IP packet with the packet header containing the following:
Source IP address = H
Destination IP address = A
FIGURE 5.2 Forwarding operations
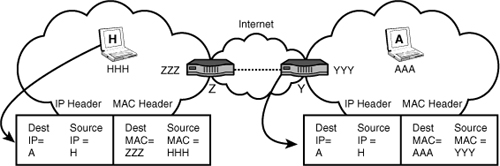
However, recall from Hour 3 that Layer 2 Ethernets (LANs) do not process Layer 3 IP addresses. Therefore, computer H must also place the MAC address of router Z in the Ethernet header’s destination address field. Let’s say it’s ZZZ, even though we know it’s really a 48-bit value. It also puts its own MAC address in the sending part of the Ethernet address. Let’s say it’s HHH. Thus, the Ethernet frame contains the following:
Source MAC address: HHH
Destination MAC address: ZZZ
We examine what happens between the routers in a later hour. For now, let’s look at the receiving site. The MAC addresses in the Ethernet frame going from router Y to node A have changed. They are
Source MAC address: YYY
Destination MAC address: AAA
However, the IP addresses have not changed. They remain
Source IP address = H
Destination IP address = A
What’s happened here? Look again. The MAC addresses have only local significance. They are not transported through the wide area network (WAN, or in this situation, the Internet). In contrast, the IP addresses have end-to-end significance. We see once again why Ethernet is thought of as a LAN. It isn’t just because of some of its technical underpinnings, but its address structure as well.
The communications links between routers Y and Z are not configured with Ethernet, because for this analysis, we assume it is a wide area connection. So what happens to Ethernet? The sending router strips it away for a wide area transport, and the receiving router reconstitutes it at the other end with the relevant local MAC addresses. That’s fine, but you could reasonably ask: What replaces Ethernet between the wide area routers? If the answer is nothing, this situation seems to contradict the OSI model discussed in Hour 3. The answer is that another protocol called the Asynchronous Transfer Mode (ATM) takes over for Ethernet for wide area links. This subject is covered in Hour 6, “Extending LANs with Wide Area Networks (WANs).”
Fortunately, unless you’re in charge of a large private network, you will not have to be concerned with how these addresses are set up and maintained by a router. However, enterprise networks and their network management personnel must have a keen knowledge of the router’s behavior in both routing and forwarding. Hundreds of configuration parameters must be fed into the router’s operating system (OS) for the machine to go about its tasks correctly.
Other Functions of Routers
In addition to the important tasks just explained, high-end routers provide extensive support for network integrity management, traffic management, and security management, which are subjects for subsequent hours. We now turn our attention to another specialized machine—the server—and the framework by which the server operates: the client/server model.
![]()
The router is one of several machines designed to relay traffic through networks. You might come across the terms switch, bridge, and hub. These devices also relay packets and interconnect servers and other computers. In the 1990s, the terms router, switch, bridge, and hub could be defined to identify a specific kind of hardware and its associated software. That’s not so today. For example, a router can perform the functions of a so-called ATM switch, a MAC bridge, or a wiring hub. Don’t be concerned with these terms unto themselves. As long as you know what they can or cannot do, the names associated with them are not all that important.
The Client/Server Model
In the early days of computer networks—back in the 1960s—most machines connected to a computer were quite limited in their capacity. They were called “dumb” terminals for good reason. They had no CPU; no memory; no disk. They depended on a large “mainframe” computer, often with an associated “terminal controller” to provide services. A terminal user keyed in a response for data, mail, and so on and received the response from a centralized mainframe.
As computers found their way into many companies in the 1970s, and as personal computers found their way into most homes in the 1980s, the mainframe’s job of servicing perhaps thousands of attached computers created bottleneck and performance problems. And, after all, it made no sense to keep the now highly capable personal computers from doing more of the computing.
However, the complete distribution of all work to each computer—including responsibility for the integrity of a company’s data (accounts receivable files, for example)—was viewed as too risky. As private industry migrated to electronic data and computer-based information, the industry came up with a compromise: Off-load some of the computing responsibilities to the distributed computers, but not all of them. Give freedom to the users of the computer network, but not unfettered freedom. What evolved from this situation was the client/server model, now used in many networking environments.
If you use the Web or email, your machine has client software providing this service. For example, when you click on a web page icon, your client program requests a service from a server program, located in another computer in a network. Usually, the server software fulfills the request and returns the response. The same type of operation takes place with a request to transfer funds from your bank account, or sending an email, and so on.
The client/server model provides a convenient method to place functions in distributed computers in one or many networks. The server doesn’t expend resources until it’s asked to do so. In addition, in many companies, all critical data and software are stored on servers, which translates to better security and control over a vital resource.
Client/server systems aren’t immune from problems. Because the server (or groups of servers, called server farms) must process all clients’ requests, the system is subject to bottlenecks during periods of high activity. Another approach, called peer-to-peer networking, avoids this problem by distributing the workload among multiple machines. Although this avoids bottlenecks, updating files—keeping them synchronized in a nanosecond environment—isn’t trivial. Anyway, our focus here is on servers that operate with the client/server model.
Server
A server can perform a variety of operations, depending on the specific vendor product and the software loaded on the machine. Some products are specialized to perform one or few functions. For example, a network time server’s only job is to provide the network with an accurate clock. At the other end of the service spectrum, some servers provide a wide set of operations, such as hosting user applications; providing mail services; supporting telephony applications, such as voice over IP (VoIP) and PBX operations; providing directories that translate between an email name and its associated address; providing authentication and security services; managing user groups; providing backup and recovery for software and data files; offering web services; and managing printer pools.
RAID
One of the most important jobs of servers in enterprises is the caring of the company’s automated resources: its data and software. Most servers execute software to manage your databases. That’s good news. It’s even better news if you actually use the software. It does no good if you don’t take the time and effort to back up your data. Mark these words: Sooner or later, if you don’t take measures to protect your data, you’ll lose some or all of it. To that end, let’s examine an operation called redundant arrays of inexpensive disks, or RAID.
RAID operates using a variety of methods commonly referred to as “levels” of 0, 1, 5, and 6.
RAID 0
RAID 0 is best described as several hard drives connected to a computer with no redundancy. The purpose of RAID 0 is to increase throughput and response time. If data is spread over several drives, it can be read from and written to the drive more rapidly. However, multiple copies of data don’t exist. If the data is corrupted, it’s lost.
RAID 1
RAID 1 performs disk mirroring or duplexing. In disk mirroring, two small computer system interface (SCSI) drives of the same size connect to the RAID controller card, but OS sees them as one drive. For example, in a RAID 1 configuration, if you connect two 40-gigabyte (GB) drives to the computer, the computer sees only 40GB of disk space rather than 80GB. This happens because the RAID controller arranges the disks so that all data is written identically to both disks. In a RAID 1 configuration, one drive can fail and the other drive can continue working; the users never know that a drive has failed. In some systems, it’s possible to connect each drive to a separate SCSI controller so that there’s no single point of failure; either disk or either controller in a mirrored set can break, and no data or function will be lost.
RAID 5
RAID 5 requires a minimum of three disks of equal capacity (compared to RAID 1, which requires two disks), but the net improvement is worth the cost. In a RAID 5 configuration, all data is spread across multiple disks in a process called striping, which is the operation by which a RAID drive controller card writes data across multiple disks. Additionally, information about the file called parity data is saved on all three disks. Thus, a single drive in a RAID 5 set can fail, and the parity data on the other two drives can be used to reconstruct the data on the failed drive.
RAID 5 offers another advantage: raw speed. Because any given file is divided into smaller pieces and stored on multiple disks, any time a user requests a file from the server, three disks read it simultaneously. This means that the file is read in to memory and out to the network more rapidly, which keeps your users happy.
RAID 6
RAID 6 provides backup and recovery from two drive failures. This feature is important for large-capacity systems because the amount of disk space increases the time to recover from the failure of a single drive. RAID 6 is the latest RAID version and is sometimes called Advanced Data Guarding (ADG).
RAID controller capabilities vary widely. Some require a lot of human interaction for configuration operations, and some (such as HP’s AutoRAID units) can largely manage themselves after being given some basic parameters. HP’s product can be set up in a few minutes.
Vendors’ products might offer variations of RAID levels 0, 1, and 5. If you become involved with this aspect of networking, ask your prospective vendors about RAID level 0+1 and 5+1. RAID 6 might be your preference if you have a very large file system and are concerned about the time taken to perform backup and recovery. They are beyond our general descriptions, but keep this idea in mind for future reference.
High Availability and Fault Tolerance
Redundant RAID systems operate without interruption when one or more disks fail. If a corrupted disk is replaced, the data on the new device is rebuilt while the system continues to operate normally. Some RAID systems must be shut down when changing a disk; others allow drives to be replaced while the system is up and running, a technique called hot swapping.
Hot swapping is important in applications needing continuous availability. The air traffic control system comes to mind. Your network might not need RAID or hot swapping, but you should know enough about the nature of your automated resources to make an informed opinion. Also, be aware that RAID will take care of some of your data backup problems, but not all of them. It’s conceivable that the redundant data could be lost. On the TV program 24, Jack Bauer and his associates regularly blow up entire computer installations.
Jokes aside, many companies archive their data to remote sites, even storing the data files and supporting computers in secure air-conditioned vaults. Even more, some companies have adopted two programs to ensure their customers and users are never (almost never) denied service of the servers. They revolve around high availability and fault tolerance.
Some computer servers run applications so critical that downtime is not an option. Examples of such systems include 911 systems, banking systems, and the air traffic control systems cited earlier. These systems must be operational around the clock; when they aren’t, bad things happen.
But everyone knows that computers malfunction. So how do network and systems administrators get around the inevitability of computer failure? The answers are fault tolerance and high availability. These two terms refer to two methods to ensure that systems can stay online and active in the face of hardware and sometimes software failures.
With fault tolerance, every component is duplexed; there is two of each device. If one component fails, the other piece of hardware picks up the load and ensures users don’t see downtime. Fault-tolerant systems command a premium price, which many critical-system customers are willing to pay for their peace of mind and satisfied customers.
High availability, also called clustering, is an arrangement using several computers to ensure an application never shuts down because a computer fails. In this cluster, typically two or more computers are connected to a shared disk. At any point, one of the computers is running an application stored on the shared disk. If the computer running the application fails, control of the shared disk passes to another computer, which starts the application so that users can continue to work. Unlike fault-tolerant systems, highly available systems don’t run continuously through component failure. A highly available system shows a brief interruption in service and then continues.
Neither fault tolerance nor high availability is better than the other. Both are useful, and their proper use depends on the criteria brought to the network design. We’ll discuss network design later in this book, including how to define the criteria for building a network.
Server Operating Systems
Just as network clients must have operating systems loaded for the client machines to function, a network server must have an operating system. (Refer to Hour 4, “Computer Concepts,” for explanations of prevalent client OSs.) The chief differences between desktop operating systems and Server Operating Systems (SOS) are, not surprisingly, scale and resources.
Typically, SOSs are optimized differently than desktop operating systems. A desktop operating system is designed to provide the user at this desktop workstation with the best possible performance for the application currently being used. By contrast, an SOS’s charge is to balance the needs of all users accessing the server rather than giving priority to any one of them.
Prominent features of SOSs are
• Support port interfaces for Ethernet and other protocols
• Manage traffic coming into and out of the machine
• Provide authentication, authorization, and logon filters
• Furnish name and directory services
• Support file, print, web services, and backup mechanisms for data (fault tolerance systems discussed earlier)
Be aware that an SOS is not the same as an OS, such as DOS, Windows XP, and Vista. The SOS is a more specialized piece of software. Certainly, Windows and other OSs offer some of the support features of an SOS, but not to the extent of those offered by the SOS. Also, some literature and vendors use the terms Network Operating System (NOS) and SOS to describe the same software. Others use NOS to describe yet another specialized OS: one concerning itself even more with the management of LAN and WAN traffic. An example is Cisco’s Internet Operating System (IOS), which runs in Cisco routers. From the view of the OSI seven-layer model, the focus of an SOS is on the upper layers, whereas an IOS is concerned with the lower layers—especially Layer 3, where routing and forwarding operations take place. As one example, an IOS creates routing tables; a SOS does not. In the following sections, we will examine prominent SOSs.
Novell NetWare
Novell NetWare is the oldest PC-based product in the SOS category. In the early 1980s, Novell (founded and led by Raymond Noorda) led the charge into personal-computer networking. NetWare is a rich and complex product. In contrast with other, newer SOSs such as Microsoft Windows XP, NetWare is less intuitive.
In the file, print, and directory services arena, NetWare is a formidable performer, offering a full suite of file, print, and web services. Novell has also made forays into the Linux arena, an important move discussed shortly.
NetWare was not designed with the Internet in mind. A great many of the design choices Novell made appear to have been an attempt to simplify networking enough to make it palatable for PC users. In the first place, Novell did not build native support for Transmission Control Protocol/Internet Protocol (TCP/IP), the basic protocols computers use to communicate across the Internet. Novell had good reason for this approach: When NetWare was developed, TCP/IP was a relatively new and immature protocol standard; it required manual configuration, and maintaining it was difficult.
Given the complexity of TCP/IP and the technical skills of its target market group, Novell decided to develop a simpler protocol. Novell’s proprietary network protocol is called Internetworking Packet Exchange/Sequenced Packet Exchange (IPX/SPX); in many ways, it was ideal for PC networking. IPX was and is largely self-configuring, easy to install, and simple to maintain.
As the Internet revolution picked up steam (and TCP/IP with it), Novell’s position suffered some because the original NetWare was founded on IPX networking. However, current versions of NetWare natively use IP, and this has helped NetWare’s popularity. Logically enough, as stated in Hour 3, NetWare’s IPX user base is diminishing as customers migrate to NetWare’s use of IP.
The NetWare product has been superseded by the Open Enterprise Server (OES). This system provides all the services of a typical SOS, and it can run over either Linux or a NetWare core platform. It appears the NetWare community might migrate to Linux, but as of this writing, it’s too soon to read these tea leaves. Presently, NetWare has a large customer base, and Novell is unlikely to do anything to alienate this population. There’s good reason for NetWare’s popularity: It’s a fine product.
Microsoft Windows Server 2003
Beginning in the late 1980s, Microsoft decided it needed a high-end SOS to compete with NetWare and UNIX. After a three-to-four year struggle (described in Pascal Zachary’s book Showstopper), Microsoft had what it had set out to create: Windows NT.
Initially, Windows NT version 3.1 (the first version, but renumbered to match the existing version of 16- bit Windows) was all one product; there was initially little differentiation between versions used for servers and versions used for workstations. By the time Microsoft released Windows NT 3.5 in 1995, Microsoft had created two versions of the operating system: Windows NT Workstation and Windows NT Server.
To date, these products have evolved into Windows XP Professional for the workstation market and Windows Server 2003 for the server market. Both operating systems are built on the same platform, but Microsoft’s Server products have a rich set of utilities and tools that the Workstation product lacks. The ability to connect a variety of networks was built into Windows XP from the start. Additionally, Windows Server 2003 can handle the server portion of network application work, which makes it an ideal application server platform. It uses the familiar Windows interface that simplifies administration. Windows XP is well suited to small organizations because of its point-and-click features.
For the majority of beginning networkers, Windows Server 2003 is likely the easiest enterprise-class network OS to install and maintain. Do not construe that statement to mean that Windows SOS is simple; it isn’t. But compared to other SOSs, Windows Server 2003 has a certain amount of familiarity because it uses the ubiquitous Windows interface.
Microsoft Windows Server 2008
Microsoft intends Windows Server 2008 to eventually replace its 2003 platform. It combines the features of Windows Server 2003 (Release 2) and Microsoft’s new OS, Vista. It is a complex and rich SOS, and newcomers will find the learning curve steep, but worth the effort. It has many enhanced features relative to Server 2003, including increased security measures, task scheduling, firewalls, and wireless networking. Also, its diagnostics are quite good. Microsoft has made further progress with Server 2008 by fully adapting the Internet standards, notably TCP/IP, Dynamic Host Configuration Protocol (DHCP), and Domain Name System (DNS).
For both Windows Server 2003 and 2008, your network should have an experienced system administrator to handle the management of this software. Its complexity makes it unsuitable for the casual user or part-time system administrator, but in the hands of a knowledgeable system administrator, Microsoft’s SOSs are quite effective.
UNIX
As mentioned in Hour 4, UNIX was developed at AT&T’s Bell Labs. UNIX is a preemptive SOS with a rich user interface. However, with this richness comes a degree of complexity. UNIX can accomplish many tasks with ease and efficiency, but the initial complexity of the user interface led to UNIX being tagged as “user unfriendly.”
As with Windows server products, UNIX can operate as either a client or a server on a network. For the most part, there’s little difference between a client UNIX system and a server UNIX system except for the power of the hardware—the server should be more powerful than the workstation—and the tightness of the security. UNIX comes with such a rich feature set that it seldom needs third-party software to administer its users.
UNIX is designed for a multitasking, multiuser environment. It provides a large inventory of software tools to complement its OS. In spite of an undeserved reputation for difficulty (at least for professional programmers), UNIX provides fast file and print server operations.
The UNIX operating system consists of many software modules and a master program, the kernel. The kernel starts and stops programs and handles the file and printer systems. The kernel also plays the key role in scheduling access to a hardware component to avoid a potential conflict between contending programs.
Because of its age, UNIX is a stable platform. However, it isn’t produced by a single vendor; instead, a host of vendors purvey UNIX, and each version is slightly different. As a result, there’s a lack of shrink-wrapped applications or applications ready to install right out of the shrink-wrapped box. In recent years, UNIX vendors have attempted to create a standard for it. This effort has met with only limited success because several versions of UNIX are supported by various vendors and standards groups.
UNIX is best suited to networks in which an experienced system administrator is in charge. Its complexity makes it unsuitable for the casual user or part-time system administrator, but in the hands of a knowledgeable system administrator, UNIX can accomplish its tasks reliably and fast.
Linux
In the late 1980s and early 1990s, UNIX became a dominant force in the computer industry. However, the cost of UNIX was beyond many individuals’ budgets and usually restricted it to running only on company machines. The few UNIX-like operating systems of reasonable cost (such as Minix, an operating system designed by a Dutch professor for teaching purposes) were judged inadequate by the user community.
In 1991, Linus Torvalds created a new UNIX-like operating system that he fancifully called Linux. The fledgling operating system was rapidly adopted by the Internet community, which extended Linus’s creation.
Linux operates on a variety of computer hardware, including desktops, large mainframe computers, mobile phones, routers, E-books, and video game systems, such as PlayStation. TiVo also uses Linux.
Linux is inexpensive, it’s open source (that is, when you buy the programs, you also get the source code and the rights to modify and rebuild, or recompile the programs to make them do what you want), and it’s supported by a cast of an untold number of programmers who voluntarily contribute their ideas and time. In addition, Linux Users Groups (LUGs) are located in many cities to promote the use of the operating system. These groups provide training, demonstrations, and technical support to new users. Chat rooms and newsgroups are also part of the Linux community.
Where possible, Linux adheres to International Organization for Standardization (ISO), Institute of Electronic and Electrical Engineers (IEEE), and American National Standards Institute (ANSI) standards. It also has all the tools that UNIX does: shell scripts, C, C++, Java, Expect, Perl, and Eiffel. From a networking perspective, Linux has tools to hook up to most prevalent networks. It can network using TCP/IP. It can use SMB (server message block) and act like a Windows server. It can run IPX and act like a NetWare server. Linux is arguably the most popular web- and mail-server platform on the Internet, in large part because it is inexpensive and open.
As mentioned, Linux is not a proprietary product available from just one vendor. It’s typically available in distributions from vendors who package the software and source code with some of their own improvements. Often, software compiled on one distribution of Linux can run on another without porting, or working on the source code to ensure compatibility. Even if it doesn’t, Linux’s software development tools are second to none, and debugging problems is relatively straightforward.
To gain a sense of the impact and value of Linux, consider these statistics, taken from several websites: A study of Red Hat’s Linux 7.1 estimates that if this OS (with 30 million lines of source code) had been developed by the conventional vendor proprietary methods, roughly 8,000 man-hours would have been expended at a cost of about $1 billion (in 2000 dollars). This study reflects a conservative estimate. Other studies claim bigger Linux OSs, under conventional developments, would have cost $6 or 7 billion! Software developers don’t come cheaply, and having free input from thousands of programmers gives Linux notable leverage in the server OS marketplace.
For the story of the development and rise of Linux, read Just for Fun: The Story of an Accidental Revolutionary by Linus Torvalds and David Diamond. It’s Torvalds’s first-person perspective and is a quick and entertaining read.
That’s it for now for SOSs. We’ve touched the surface of their capabilities and operations, but we’ve not explained how to use them and how to get the best performance out of them. We’ll do just that in Hours 16 and 17.
Media
For the installation of your network, you might be able to determine the media to be used to transport your traffic. The word “might” is noted, because some network products and protocols require a specific media. For example, switched Ethernet stipulates the use of copper wire or optic fiber. Although an enterprising engineer could install, say, coaxial cable, instead of twisted copper pairs in a LAN, it would not be a good idea to do so. First, the physical layer of the OSI model would have to be redone, entailing hardware changes. Second, the line drivers would have to be rewritten. Third, the data link layer, while remaining mostly intact, would still need some changes.
On the other hand, you often have a choice about the quality (and cost) of the media. Shop around; look for a good buy, but don’t compromise quality for a few dollars saved. The difference in price between high-quality and lower-quality wire is small, and you might save yourself some headaches later by paying a bit more up front.
I grant that spending a few cents more per meter of cable can translate into a big budget item if an enterprise is pulling cable through a new skyscraper. Still, be careful about pulling low-quality cable. Keep in mind the old saw, “Penny-wise, pound-foolish.”
Copper Wire
Under most conditions, your decisions on media will focus on the category of copper wire that will be installed for your network. Twisted-pair1 wiring comes in several levels, ranging from Level 1 (or Category 1), formerly used for older telephone applications, to Level 6 (or Category 6), which is certified for data transmission up to 350 megabits per second (Mbps).
1 The wire is twisted to enhance the quality of the electrical signals.
Twisted-pair cables are explained in more detail shortly.
Before we examine these categories, let’s take a brief detour to discuss a LAN technology you will likely come across: 10BASE-T. (We cover variations of this technology in Hour 11, “Selecting Network Hardware and Software.”) This term is constructed as follows:
• 10—Speed in Mbps
• BASE—Uses a baseband signaling technique (binary, digital images)
• T—Uses twisted-pair cable for the media
Many Ethernet products are based on the 10BASE-T technology. Others use optical fiber. Again, in Hour 11, we examine other Ethernets. For now, let’s examine the twisted-pair categories:
• Category 1 is not rated for performance and is no longer rated by the standards groups. Previously, it was used for telephone systems and doorbells.
• Category 2 is also no longer rated by the standards groups. In the past, it was used on token-ring LANs.
• Category 3 is the lowest level that can be used for networking. It’s used for Ethernet 10BASE-T and has a maximum data rate of 16Mbps. Although Category 3 is rated for 10BASE-T, Category 5 is now much more common because it supports both 10BASE-T and faster speeds such as 100BASE-T.
• Category 4 is used for 16Mbps token-ring and Ethernet 10BASE-T networks. Its maximum data rate is 20Mbps.
• Category 5 (and 5e) is used for Ethernet 100BASE-T and has a maximum data rate of 155Mbps. This is currently the most common cable. In fact, many companies are wiring everything in their offices (both phone and data) with Category 5 cable because it can be used for everything from basic two-wire phone services to ATM.
• Category 6 is used for Ethernet 1000BASE-T (gigabit Ethernet). It’s rated for 350Mbps over 4-pair unshielded twisted-pair wire. And Category 6a, a relative newcomer, is suitable for 10GBASE-T Ethernets.
To maintain the maximum data rate, you must string and terminate the wires according to the Electronics Industries Association (EIA) 568B standards. If the wires are not correctly installed, their potential data rate can be jeopardized. Generally, the vendors provide guidance about the installation of their products, such as recommended distances for a wire span. Their specifications error on the side of caution. Follow their guidelines, and you’ll be well within the EIA standards.
![]()
If you’re building a copper-wire-based network, it doesn’t make sense to install cable less than Category 5 because installing Category 5 wire can extend the life of your media. Category 5 standards specify the wires in twisted-pair cabling maintain their twist within one-half inch of the final termination point. Category 5 also has strict standards for the radius of bends in Category 5 wire and other stipulations leading to enhanced performance.
Optical Fiber
Because of the huge success of switched Ethernet and its use of copper wire, it’s unlikely you’ll be faced with installing, using, or maintaining optical fiber cable. Exceptions to this last statement might apply to some of your nonnetworking activities. You might be tasked with assembling your optical cable Christmas tree, or your children might be tossing around Frisbees illuminated with fiber optics. But these optical products come in shrink-wrapped boxes and require none of your networking expertise for their use.
Jokes aside, optical fiber has replaced most of the wire-based media in “core” networks around the world, such as the telephone networks. Moreover, you might want to consider using fiber optics if you need very secure communications links for your network or you need extraordinarily high data rates—well beyond the Gbps rates quoted earlier.
For security, the light images carrying pulses of 1s and 0s are contained within the cable. Unlike electromagnetic signals, this media releases no stray energy. Thus, the optical cable is not subject to snoopers detecting “residual intelligence” emanating from the cable. It’s generally accepted that an optic fiber cable can be tapped without detection, but this discussion assumes you aren’t into the spy business. In any case, Hour 20, “Security,” will explain how you can secure your transmissions.
For capacity, it’s likely that your LAN will perform just fine with standard Ethernet hardware and software. To transport your data through an internet or the Internet, most of the links operate in the gigabit range, using optical fibers. For example, in Hour 6, we examine the Synchronous Optical Network (SONET) technology, which can provide an optical link operating at 389,813.12Mbps. What’s more, systems are coming out of the lab that transmit at 14 terabits per second (Tbps). Consulting Figure 4.1 in Hour 4, in visual terms, this is 14,000,000,000,000 bits per second; a capacity (eventually?) needed for core networks, but certainly not for LANs and other enterprise systems.
Therefore, aside from those optical Christmas trees and Frisbees, it’s likely you will not have to become proficient with this technology.
Coaxial Cable
We can make the same claim with coaxial cable. Other than its presence in the cable TV network, it has ceased to be much of a factor in networks in general, and data networks specifically. I used to deal with coaxial cable when the original Ethernet specification stipulated its use. No longer. Now it’s copper wire.
Wireless Media
Unlike coaxial cable, a network manager should be versed in wireless media technologies—if not the wide area cellular system, then certainly the more localized Bluetooth and Wi-Fi standards and products. In many offices and homes, they offer attractive alternatives to copper wire. We will touch on Bluetooth and Wi-Fi with an introduction, and provide more details in Hour 7, “Mobile Wireless Networking.”
Bluetooth
Bluetooth is a technology whose time (to come) was long overdue. The networking industry needed Bluetooth many years ago. It offers an inexpensive, high-capacity media and low-power consumption device for short distances, without the need to pull wire around a room. In addition, Bluetooth is not a line-of-sight medium. If the devices are close enough, the radio waves will provide correct communications. Also, Bluetooth contains an extensive protocol suite, enabling devices to discover each other, as well as discover each other’s attributes.
Because of these features, Bluetooth is now used in mobile phone ear sets, laptops, printers, digital cameras, video games, telephones, and many other devices.
Wi-Fi
Wi-Fi is more expensive than Bluetooth because it operates at a higher capacity, consumes more power, and covers greater distances. Some people refer to Wi-Fi as a “wireless Ethernet” because it provides many of the services of a conventional wire-based Ethernet. Wi-Fi will present you with more challenges as a network manager, but as we shall see in Hour 20, it has more features than Bluetooth.
Summary
During this hour, we learned about the main hardware and software components that make up a computer-based network. We examined routers and the important jobs they perform pertaining to route discovery and forwarding. Server operating systems were introduced, with a highlight on those that dominate the marketplace. The importance of “speed” was emphasized because of its effects on throughput and response time. The hour concluded with a survey of the most widely used media for the communications channel.
Q&A
Q. Although the efficiency of hardware and software is key to high-speed networks that offer fast response times, these components are at the mercy of what?
A. Regardless of the efficiency and speed of hardware and software, ultimately they are slaves to the amount of data they must process in a given time. Thus, a network with a large population of users will not experience the performance of a lightly loaded network.
Q. Name two factors pertaining to software you might influence to improve the performance of your network.
A. Installing more memory in your machines and increasing the queue sizes of components such as servers and routers can improve network performance.
Q. Two of the principal responsibilities of a router are routing and forwarding. Do they provide different services? If not, contrast these two operations.
A. They do not perform different services; rather, they provide complimentary services. Routing, or more accurately, route discovery, is the process by which the router discovers the “best” route to a destination address. Route discovery entails the building of a routing table, or a routing information base (RIB). On the other hand, forwarding entails the router examining the destination address in a packet and matching this address to an entry in the routing table to determine the next node to receive the packet as it makes its way to the final destination.
Q. One inexpensive way to help ensure that a company’s data is protected is through a technique called __________.
A. Redundant arrays of inexpensive disks, or RAID, can do this.
Q. List the major services provided by Server Operating Systems (SOSs).
A. Server Operating Systems
Support port interfaces for Ethernet and other protocols
Manage traffic coming into and out of the machine
Provide authentication, authorization, and logon filters
Furnish name and directory services
Support file, print, web services, and backup mechanisms for data
Q. Technically speaking, your local area network (LAN) can be configured at the physical layer (L_1) with optical fiber, copper wire, coaxial cable, infrared, and wireless. Given cost and product availability, which of these media would you “lean toward” for your LAN?
A. For Ethernets, which dominate the industry, the coaxial implementations are pretty much a thing of the past. Optical fiber is likely overkill. Infrared might be an alternative for a line-of-sight link. But for practical purposes, copper wire and wireless Ethernets will most likely serve you the best. For short distances, a wireless connection is quite attractive, except it might not provide the throughput to that of copper wire.