
Chapter 7
Extracting Data from XML
WHAT YOU WILL LEARN IN THIS CHAPTER:
- How XML is usually represented in memory
- What the DOW and the XDM are
- What XPath is
- How to read and write XPath expressions
- How to learn more about the XPath language when you need it
There’s quite a lot packed into a small space here, but XPath is both important and useful. Most useful languages for querying and extracting data have fairly powerful expression languages and XPath is no exception. It’s everywhere, too: XPath “engines” are available for pretty much every programming environment, from JavaScript to Java, from PHP and Perl to Python, from C to SQL. XPath is also central to XSLT and XQuery.
DOCUMENT MODELS: REPRESENTING XML IN MEMORY
XML is a text-based way to represent documents, but once an XML document has been read into memory, it’s usually represented as a tree. To make developers’ lives easier, several standard ways exist to represent and access that tree. All of these ways have differences in implementation, but once you have seen a couple, the others will generally seem very similar.
This chapter briefly introduces three of the most widely used models; you learn more about each of them later in the book. You also learn how to avoid using these data models altogether using XPath (in this chapter) and XQuery (in Chapter 9).
Meet the Models: DOM, XDM, and PSVI
The best-known data model for storing and processing XML trees is called the W3C document object model, or the DOM for short. The DOM was originally designed for handling HTML in web browsers; the XML DOM is actually a separate specification, but it’s supported by all modern web browsers, and a host of other applications and libraries.
XPath 2 and 3, XQuery, and XSLT 2 all use the XQuery and XPath Data Model, or XDM, which is a slightly different data model than DOM. The XDM is more powerful than the DOM, includes support for objects with types described by W3C XML Schema, and also supports items such as floating-point numbers and sequences intermingled with the XML data.
Finally, W3C XML Schema defines an abstract model with the catchy name Post-Validation Information Set, or PSVI. The PSVI is the result of validating an XML document against a W3C XML Schema and “augmenting” the XML document with type annotations; for example, saying a <hatsize> element contains an integer. The term information set comes from a specification (the XML Information Set), which provides a standard set of terminology for other specifications (like XSD) to use. You will sometimes also hear people refer to the infoset as if it was a data model, but this is not strictly accurate.
This chapter focuses first on the DOM, and then on using XPath to get at XML elements and attributes, whether they are stored using the DOM or otherwise.
A Sample DOM Tree
There are three main reasons why it is important to talk about the DOM in this book:
- Some of the most widely used XPath implementations return DOM node lists.
- jQuery and other similar libraries are built on top of the DOM and described in terms of the DOM.
- The XDM used by XPath 2 and later is based on the same principles as DOM.
To start off, take a look at Listing 7-1 that shows how the XML text is taken to represent a tree in memory:
![]() LISTING 7-1: Armstrong.xml
LISTING 7-1: Armstrong.xml
<entry id=”armstrong-john”>
<title>Armstrong, John</title>
<body>
<p>, an English physician and poet,
was born in <born>1715</born> in the parish of Castleton in Roxburghshire,
where his father and brother were clergymen; and having
completed his education at the University of Edinburgh,
took his degree in physics, Feb. 4, 1732, with much reputation.
. . .
</p>
</body>
</entry>
Figure 7-1 illustrates how an implementation might represent this short snippet of XML in memory. In the diagram, the element nodes are drawn as circles, text nodes as pentagons, and attribute properties as boxes. The dotted part of the diagram is there to remind you that the illustration is not complete. The snippet includes only one entry, although the actual full dictionary has a <book> element and more than 10,000 entries. You see a larger example later in this chapter.
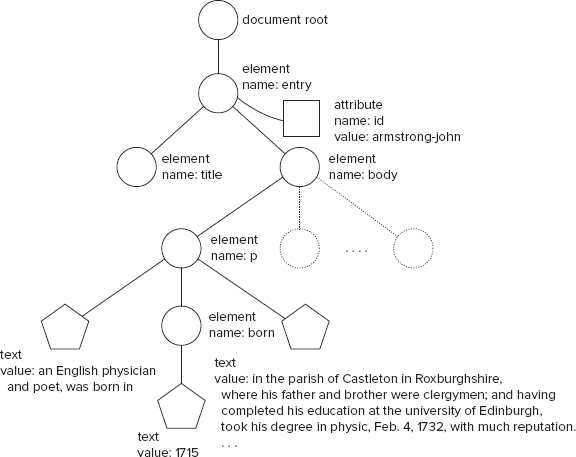
DOM Node Types
The in-memory representation of any XML item in a DOM tree such as an element, an attribute, a piece of text, and so on is called a node; XDM uses the word node in the same way. There are many different types of nodes; you take care not to get them confused. The following list helps spell the different node types out:
- Document Node: The node at the very top of the tree, Document, is special; it is not an element, it does not correspond to anything in the XML, but represents the entire document.
- DocumentFragment Node: A DocumentFragment is a node used for holding part of a document, such as a buffer for copy and paste. It does not need to meet all of the well-formedness constraints — for example, it could contain multiple top-level elements.
- Element Node: An Element node in a DOM tree represents a single XML element and its contents.
- Attr (Attribute) Node: Attr nodes each represent a single attribute with its name, value, and possibly, type information. They are normally only found hidden inside element nodes, and you have to use a method such as getAttributeNode(name) to retrieve them.
- Text node: A text node is the textual content of an element.
- DocumentType, CDATASection, Notation, Entity, and Comment Nodes: These are for more advanced use of the DOM.
DOM nodes also have properties; you just saw an example of this in Figure 7-1 — an element node has a property called tagName. Most DOM programs will contain code that tests the various properties of a node, especially its type (element, attribute, text and so on) and behaves accordingly, even though this is not usual in object-oriented design.
Look at the previous code example to put all of this information about nodes together in context: <title>Armstrong, John</title> has a start tag (<title>), text content (Armstrong, John), and an end tag (</title>), and as a whole, represents an element called title.
The resulting part of the DOM tree has an element node whose tagName property has the value title, and that element node contains a reference to a text node whose text value is Armstrong, John.
So a tag, an element, and a node are three different things. This may seem subtle, but it will really help you with XPath and XSLT.
DOM Node Lists
When you access parts of a DOM tree from a program, you generally get back a node list. As the name suggests, this is simply a list of nodes. You often then use an iterator to march through the list one item at a time. In particular, XPath queries return a node list.
An unusual thing about DOM node lists is that they are live: the items in the list are really references or pointers into the tree, so that if you generate a node list and then change one of the nodes in that list, those changes are reflected in the tree, and also in any other lists containing that node. Not all implementations support live node lists, however, so you should check the environment you plan to use before relying on the feature.
For example, code using the DOM, depending on the programming language, often looks something like this:
foreach (e in document.getelementsbytagname(“p”)) {
if (e.attributes[“role”] = “introduction”) {
document.delete(e);
}
}
In this code, document.getelementsbytagname(“p”) is a DOM function that returns a node list, and the code then processes each element in turn, deleting the nodes whose role attribute is set to introduction. In some languages you would need to call string comparison functions to test against “introduction” and in others you might need to save the node list in a variable and iterate over it one item at a time using the length property of the node list. Although the details vary, the basic ideas are the same in all languages supporting the DOM.
The Limitations of DOM
The DOM provides a low-level application programming interface (API) for accessing a tree in memory. Although the DOM has some object-oriented features, it does not support the two most important features: information hiding (a concept alien to XML) and implicit dispatch, the idea that the compiler or interpreter chooses the right function or “method” to call based on the type or class of a target object. Therefore, since the DOM doesn’t support implicit dispatch, you have to write code that says, “if the node is an element, do this; if it’s a text node, do this,” and so on, and it can be easy to forget a node type. In fact, it feels like playing snooker by giving a robot verbal commands — “left a bit, further, slower, right a bit, that’s good.” With XPath and XQuery, you just pick up the snooker cue and hit the ball.
The DOM nodes also have a lot of methods and properties, which use a lot of memory in many programming languages. It’s not uncommon for DOM-based applications to get 10- to 100-times smaller when rewritten in XQuery, and for DOM expressions to find a node to get 10- to 100-times smaller and much easier to understand when they’re rewritten in XPath. Additionally, because code using the DOM is verbose and tedious it is often expensive to maintain and error-prone.
Older languages and APIs restrict you to using the DOM, but these days in most cases you should be able to avoid it and use something higher-level. If you do end up using the DOM, see if there’s a higher-level language or API that also returns a DOM node list. You should consider switching to XPath (described later in this chapter), XQuery (see Chapter 9), XSLT (see Chapter 8), or in JavaScript, jQuery. You will learn more about jQuery and JavaScript in Chapter 16, “AJAX”. The rest of this chapter focuses on a higher-level language for accessing parts of a document, XPath.
THE XPATH LANGUAGE
The XML Path Language, XPath, is used to point into XML documents and select parts of them for later use. XPath was designed to be embedded and used by other languages — in particular by XSLT, XLink, and XPointer, and later by XQuery — and this means that XPath isn’t a complete programming language. But when you use it from Python, PHP, Perl, C, C++, JavaScript, Schema, Java, Scala, XSLT, XQuery, and a host of other languages, you’ll quickly come to like it!
XPath Basics
The most common way to use XPath is to pass an XPath expression and one or more XML documents to an XPath engine: the XPath engine evaluates the expression and gives you back the result. This can be via a programming language API, using a standalone command-line program, or indirectly, as when XPath is included in another language such as XQuery or XSLT.
With XPath version 1.0, the result of evaluating an XPath expression is a node list, and in practice this is often a DOM node list. With later versions of XPath you are more likely to get back an XDM sequence, but it depends on the exact API and environment of the language embedding the XPath engine. As of 2012, web browsers are still using XPath 1.
XPath is deceptively simple at first, and can be very easy to use. Following is an example from the start of the chapter showing how to get at John Armstrong’s date of birth:
/entry/body/p/born
If there was a whole book with lots of entries, and you just wanted the one for John Armstrong, then you would use this instead:
/book/entry[@id = “armstrong-john”]/body/p/born
Each level of this XPath expression, from the root element down to born is a separate call to a DOM API, with a loop needed to handle the test for the attribute value. But what’s equally as important is that an XPath engine has the freedom to evaluate this expression in any order, so, for example, it could start with the <born> element and work upward, which is sometimes a much faster strategy.
Understanding Context
In many environments using XPath you can “navigate” through the document and evaluate an XPath expression against any node in the tree. When an environment enables navigation and evaluation, the node becomes the context item.
The XPath context item can be set in three places: the first one you have seen before in the previous XPath examples that have all started with a slash (/), explicitly setting the initial context to the document node. The context can also be set before evaluation by the language or environment embedding XPath. You’ll see examples of the “host language” setting the initial context outside XPath in Chapter 8, “XSLT” with xsl:for-each and xsl:apply-templates. Finally, when you use a predicate, the context is set by XPath inside the predicate. See the following example:
/book/entry[@id = “armstrong-john”]
Conceptually, the XPath engine finds the top-level <book> element, then makes a list of all <entry> elements underneath that <book> element. Then, for each of those <entry> elements, the XPath engine evaluates the predicate and keeps only the <entry> nodes for which the predicate is true — in this case, it keeps those <entry> elements having an id attribute whose value is equal to “armstrong-john”. The context for the predicate each time is a different <entry> element.
You’ll see later that you can access the initial context node with the current() function, and that you can get at the current context node with a period (.). The names make more sense when XPath is used within XSLT, but for now all you need to remember is that there’s always a context and you can access it explicitly if you need to.
XPath Node Types and Node Tests
So far you’ve seen XPath used only with XML elements, attributes, and text nodes, but XML documents can also contain node types such as processing instructions and comments. In addition, XPath 2 introduced typed nodes: all the types defined by W3C XML Schema are available.
Just as entry matches an element of that name, and @id matches an attribute called id, you can test for various node types including processing instructions, comments, and text. You can also match an element that was validated against a schema and assigned a particular type. Table 7-1 contains a list of all the different node tests you can use in XPath.
TABLE 7-1: XPath Node Types and Node Tests
| NODE TEST | NODE TYPES MATCHED |
| node() | Matches any node at all. |
| text() | A text node. |
| processing-instruction() | A processing instruction. |
| comment() | A comment node (if the XML processor didn’t remove them from the input!). |
| prefix:name | This is called a QName, and matches any element with the same namespace URI as that to which the prefix is bound and the same “local name” as name (see the section “XPath and Namespaces” later in this chapter for an English translation of this!). Examples: svg:circle, html:div. |
| name | An element with the given name (entry, body, and so on). |
| @attr | An attribute of the given name (id, href, and so on); can be prefixed as a QName, for example, @xlink:href, but remember that attributes are not in any namespace by default. |
| * | Any element. |
| element(name, type) | An element of given name (use * for any), and of the given schema type, for example, xs:decimal. Examples: entry/p/element(*, xs:gYear) to find any element declared with XSD to have content of type xs:gYear; entry/p/element(born, *), which is essentially the same as entry/p/born. |
| attribute(name, type) | Same as element() but for attributes. |
You can use any of these node tests in a path. In Listing 7-1, for example, /entry/body/title/text() would match the text node inside the <title> element. The parentheses in text() are needed to show it’s a test for a text node, and not looking for an element called text instead.
XPath Predicates: The Full Story
Earlier in this chapter you saw a predicate used to select <entry> elements having an attribute called id with a particular value. The general pattern is that you can apply a predicate to any node list. The result is those nodes for which the predicate evaluated to a true, or non-zero, value. You can even combine predicates like so:
/book/chapter[position() = 2]/p[@class = 'footnote'][position() = 1]
This example finds all <chapter> elements in a book, then uses a predicate to pick out only those chapters that are the second child of the book (this is just the second chapter of the book). It then finds all the <p> children of that chapter, and uses a predicate to filter out all except those <p> elements that have a class attribute with the value footnote, Finally, it uses yet another predicate to choose only the first node in the list — that is, the first such <p> element.
The expression inside the predicate can actually be any XPath expression! Wow! So you could write something like this:
/entries/entry[body/p/born = /entries/entry/@born]
This expression finds all the entry elements that contain a born element whose value is equal to the born attribute on some (possibly different) entry element. You’ll see more examples like this in Chapter 9, “XQuery”). For now, just notice that you can have fairly complex expressions inside predicates.
Positional Predicates
Let’s slow down a bit and look at a simpler example for a moment. The simplest predicate is just a number, like [17], which selects only the seventeenth node. You could write /book/chapter[2] to select the second chapter: that’s because it’s exactly the same as writing /book/chapter[position() = 2]. This is often called a positional predicate. It’s really still a boolean (true or false) expression because of the way it expands to position() = 17.
So the full story on XPath predicates is that they can have any XPath expression in them, and that it will be evaluated to true or false for each node in the current list, winnowing down the list to leave only the nodes for which the predicate was true. And a plain number will be true if it matches the position in the list.
The Context in Predicates
At the start of this chapter you learned how every XPath expression is evaluated in a context. The step (/) and the predicate change the context. For example, if the initial context is the top-level document node in Figure 7-1, then given the expression /entry[@id], the context for the predicate after /entry will be the <entry> element, and so the expression looks for an id element on each entry node in turn; in this example there’s only one such node, so it won’t take long!
The shorthand “.” (a dot, or period) refers to the context node (the <entry> element), and the function current() refers to the initial context (the document node in this example).
For example, if you’re processing an SVG document you might want to know if a definition is used, so, in the context of a <def> element, you might look for
//*[@use = current()/@id]
to find every element with an attribute called use whose value is equal to the id attribute on the current <def> element. You couldn’t just write
//*[@use = @id]
because that would look for every element having use and id attributes with the same value, which is not at all what you want.
Effective Boolean Value
You’ve learned, informally, that a predicate is evaluated for each node, and that if it’s true the node is kept. Formally this is called the effective boolean value of the expression in the predicate. Here are the rules XPath uses for working out whether a predicate is true (add the node to the list of results) or false (don’t add the node to the list):
- An empty sequence is false.
- Any sequence whose first item is a node is true.
- A boolean value, true() or false(), returns its value.
- A string or string-like value is false if it is zero length, and true otherwise. String-like values are xs:string, xs:anyURI, xs:untypedAtomic, and types derived from them using XML Schema.
- Numeric values are false if they are zero or NaN, and true otherwise.
XPath Steps and Axes
An XPath axis is really just a direction, like up or down. (Note that the plural, axes, is pronounced akseez and is not related to chopping wood.) And a step moves you along the axis you have chosen.
The most common XPath axis is called child, and is the direction the XPath engine goes when you use a slash. Formally,
/book/chapter
is just a shorthand for
/child::book/child::chapter
You won’t need the long form of the child axis very often, but it’s there for completeness. The slash (/) is the actual step. Similarly, there’s an attribute axis, and you can probably guess that the shorthand for it is the at sign (@).
Table 7-2 shows all of the different XPath axes, together with the short forms where they exist.
TABLE 7-2: XPath Axes
| SHORTHAND | FULL NAME | MEANING |
| name | child:: | The default axis; /a/child::b matches <a> elements that contain one or more <b> elements. |
| // | descendant:: | descendant::born is true if there’s at least one born element anywhere in the tree beneath the context node. a//b matches all b elements anywhere under a in the tree; a leading // searches the whole document. |
| @ | attribute:: | Matches an attribute of the context node, with the given name; for example, @href. |
| self:: | Matches the context node. For example, self::p is true if the context node is an element named “p.” | |
| descendant-or-self:: | Matches the current node or any child or child’s child, all the way to the bottom. p/descendant-or-self::p matches the first p as well as the descendants called p. | |
| following-sibling:: | Elements that come after the context node in the document are at the same level and have the same immediate parent. | |
| following:: | Elements anywhere in the document after the current node. | |
| .. | parent:: | The parent of the current node. |
| ancestor:: | Parent, grandparent, and so on up to the top. For example, ancestor::div returns all the div elements that enclose (are above) the context node. | |
| preceding-sibling:: | The reverse of following-sibling. | |
| preceding:: | The reverse of following. | |
| ancestor-or-self:: | The reverse of descendant-or-self. | |
| namespace:: | See Chapter 8 on XSLT. |
Now take a look at an example XPath expression that uses some of these axes:
//a[preceding-sibling::a/@href = ./@href]
This expression matches <a> elements anywhere in the document (because //a at the start is the same as /descendant::a), and then uses a predicate to choose only those <a> elements that have a preceding sibling — that is, another <a> element earlier in the document, but only going back as far as the start of the parent element — where that other <a> element has the same value for its href attribute as this one (the dot meaning the node you’re testing with the predicate). You might use this expression to match the second and subsequent links in a paragraph to the same footnote, for example.
XPath Expressions
Like most computer languages, XPath has expressions. In XPath 1 the outermost expression had to match nodes in the XPath 1 data model; more recent versions of XPath remove this restriction. This means that the following are all valid XPath expressions:
- count(//p): The number of <p> elements in the document.
- 2 + 2: Five. Wait, three. No, four, that’s it, four!
- 1 + count(//p) + string-length(@id): One more than the number of <p> elements in the whole document, plus the number of characters in the id attribute of the current element (the context node).
- 10 idiv 4: Two (idiv is integer division). XPath can’t use “/” for division because that’s already used for paths.
- (1, 2, 3): In XPath 2 and later, this makes a sequence, in this case a sequence of integers (whole numbers).
- (1 to 100)[. mod 5 eq 0] (XPath 2 and later): Those numbers between 1 and 100 (inclusive) that are divisible by five.
Table 7-3 lists the operators you can use in an XPath expression.
TABLE 7-3: XPath Operators
| XPATH OPERATOR | MEANING |
| + - * idiv div mod | Addition, subtraction, multiplication, integer division (3 idiv 2 gives 1), division (3 div 2 gives 1.5), modulus, or remainder (12 mod 7 gives 5). |
| eq, ne, gt, lt, ge, le | Equals, not equals, greater than, less than, greater than or equal, less than or equal. See the section “Equality in XPath,” later in the chapter. |
| <<, >> | A << B is true if A and B are nodes in a document (for example, elements) and A occurs before B; A >> B is true if A comes after B. Note that these operators generally need to be escaped in XML documents. |
| union, intersect, |, except | A union B gives all nodes matched by either A or B, and is the same as A|B; A intersect B gives nodes in both A and B. See the section “XPath Set Operations.” |
| to | 3 to 20 gives a sequence of integers 3, 4, 5,...18, 19, 20. |
| , | The comma separates items in sequences, as well as arguments to functions. |
| +, - | The so-called unary operators, for negative and positive numbers, like -2 and +42. |
| e(list) | Calls e as a function with the given arguments; e can be the literal name of a function, like concat(“hello”, “ “, “world”), or can be an expression returning a “function item.” See the section “Defining Your Own Functions” later in this chapter. |
| (e1, e2, e3...) | A sequence of values. |
Equality in XPath
Two values are said to be equal if they are the same, and checking to see if things are equal is called testing for equality. The reason a precise term is needed for this action is because equality is a very important and precise concept in computing, and in XPath in particular. The following sections describe the main ways XPath has to compare items and their values to see if they are equal. There are also some sneaky unofficial ways you’ll see mentioned as well.
The = Operator Works on Lists
The = operator in XPath actually operates on sequences (or, in XPath 1, on node lists). If A and B are two sequences, you could read A = B as “there’s at least one value that appears in both A and B.” Here are some examples:
- (1, 2, 3) = (2, 4, 6, 8): True, because 2 appears on both sides.
- (“a”, “hello”, “b”) = (“c”, “Hello”, “A”): False (XPath, like XML, is case-sensitive).
- 3 = (1, 2, 3): True, the single value on the left is just treated like a short sequence.
This behavior may seem odd at first, but it’s very useful with XML documents. Consider the following example:
/book/entry[p/place = “Oxford”]
This finds all the <entry> elements that contain a <p> element, which, in turn, contains a <place> element whose string value is equal to Oxford. There might be lots of <place> elements, and that’s perfectly normal: if any of them has the value Oxford, the predicate will be true, and the containing <entry> will be returned.
The = operator works on simple (atomic) values; see the deep-equal() function for comparing structure.
The eq Operator Works on Single Values
If you know you intend to compare exactly one pair of values, you can use the singleton operator eq instead: @chapterNumber eq 7, for example. Two reasons to use this are: first, that if your assumption is incorrect and there’s more than one value, you’ll get an error; second, that eq is often slightly faster than =. But it is much better for code to be correct and slow than wrong and fast, so use eq only when you are sure there will only be one value on the left and one on the right.
The is Operator Works on Identity
In larger programs you’ll often have variables that refer to nodes, and you may want to know if two variables refer to the same node. If you used the eq operator you’d be asking if you have two nodes whose contents have the same value, but with is you can ask if the two nodes are actually the same node, in the same place on the tree. In XQuery, you might write the following to treat a particular node differently:
if ($input is $target) then $target else process ($input)
count($input) = count($input|.)
The deep-equal() Function Works on Subtrees
Finally, you can compare two entire subtrees to see if they are the same:
deep-equal(e1, e2)
This will be true if the structures and content are equal. Consider Listing 7-2:
![]() LISTING 7-2: try.xml
LISTING 7-2: try.xml
<?xml version=”1.0”?>
<store>
<item id=”shoes”><quantity>12</quantity></item>
<street-address>12</street-address>
<name>Shoe Store</name>
</store>
The XPath expression /store/item = /store/street-address is true. But deep-equal(/store/item, /store/street-address) is false.
XPath Literal Values, Types, and Constructors
You’ve already seen quite a few examples of literal values in XPath. Table 7-4 puts them all together in one place, and you can also look back to Chapter 5, “XML Schemas” for more examples of XSD simple types. The table also shows the constructors, which are functions that take a string and return a value of the given type. In most cases you don’t need to use the constructors, however in a few cases they can make your code clearer, and they are needed when you want to distinguish between values of different types, such as a number that’s a shoe size and another that’s a price. For example, the following two snippets of XSLT have the same effect, but it’s easy to miss the single quotes in the first line:
TABLE 7-4: XPath Literal Values and Types
| VALUE TYPE | DESCRIPTION |
| Integer | 0, 1, 2, and so on. Note that -1 is (strictly speaking) a unary minus operator applied to a number. Constructor: xs:integer(“12”) |
| Float, double | Same as for XSD, for example, 2.5, NaN. Constructors: xs:double(“2.5e-17”), xs:float(“42”) |
| String | Use either double or single quotes, like XML attribute values. See also the following section “XPath String Quoting.” Constructors: string(“hello world”) and xs:string(“hello world”) |
| Boolean | Use true() or false() to make them, and combine them with and, or, and the pseudo-function not(expr). |
| xs:dateTime, xs:anyURI, other Schema types | You can make any XSD simple type using the name of the type and a string, just as with float. See Chapter 5 “XML Schemas” for examples of values. |
| Function Items and Inline Functions | See the section “Defining Your Own Functions” later in this chapter. |
| Sequences | The comma constructs a sequence in XPath 2 and later: (1, 2, 42, 3) |
<xsl:value-of select=”'/'”/>
<xsl:value-of select=”string('/')”/>
XPath alone can never construct or remove document nodes. An XPath expression that returns a node will therefore also return all of the descendants of that node. If you want to do more extensive changes to the input, use XSLT or XQuery. Once you’ve learned XPath, XSLT and XQuery are plain sailing.
XPath String Quoting
Sometimes you need to include an apostrophe in a string, and this can get tricky. In XPath 2 or later you can double the apostrophe, 'can''t', but in XPath 1 you may have to resort to tricks using the concat() function to join its arguments together and make a single string. In XSLT 1 you could also sometimes use numeric character references — " for the double quote and ' for the single quote (apostrophe). In all versions of XPath, a string with single quotes around it can contain double quotes, and a string with double quotes around it can contain single quotes without a problem.
Variables in XPath Expressions
XPath is a declarative language. This means that you describe the results you want, and it’s up to the computer to figure out how to get there. There’s no looping, and no way to change the value of variables. In fact, you can’t even set variables in the first place in XPath 1, so all XPath variables come from the host language outside of XPath.
Variables are marked by a dollar sign ($); they can contain node lists or sequences as well as the “atomic” types like numbers and strings. Here is an example in which $year is given the value 1732 and $e is the top-level <book> element in a large biographical dictionary:
$e/entry[@born le $year and @died ge $year]
This expression gets all the entry elements for people alive during the given year.
In XPath 2 and 3 you can define variables using for and let, although you still can’t change their values.
New Expressions in XPath 2
XPath 2 introduces for, let, if, some, and every expressions, as well as casts. All of these expressions are really useful, but only work in XPath 2 and later. You won’t be able to try them in the popular open-source xmllint program, nor in other programs based on libxml2, because that supports only XPath 1. However, if you have a version of the oXygen XML editor that uses the Saxon XPath engine, you can type them into the XPath 2.0 box in the upper right of the XML editor program. They also work in XQuery, so you could try the BaseX open source XQuery program used for some of the examples in Chapter 9, “XQuery.”
XPath “for” Expressions
The format of a for expression is simple. Take a look at the following one that is a complete XPath expression that returns the numbers 5, 10, 15, 20, and so on up to 100:
for $i in (1 to 20) return $i * 5
Figure 7-2 shows a screenshot of oXygen after entering this expression.
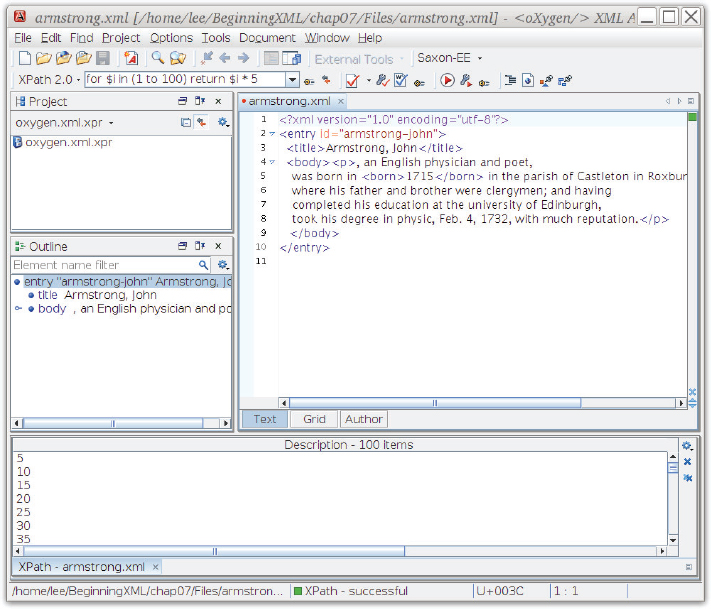
The return clause is evaluated once for each distinct value of $i and the result is a sequence.
You can also include multiple variables with a comma between them, like this:
for $lastname in (//person/name/last),
$i in (1 to string-length($lastname))
return substring($lastname, 1, $i)
If you have a single <last> element containing Smith, this XPath expression generates SSmSmiSmitSmith.
Now you’ve seen some examples it’s time to try something yourself. In the activity that follows, you’ll learn how XPath expressions can return any sequence of values, and you’ll experience XPath in action.
for $i in (1 to 20) return $i * 5
string-join(for $i in (1 to 20) return $i * 5, “, “)
string-join(for $i in (1 to 20) return string($i * 5), “, “)
string-join((“apple”, “orange”, “banana”), “===”)
apple===orange===banana
XPath “let” Expressions
The syntax of a let expression is very simple; see the following:
let $v := 6 return $v + 1
As with the for expression, you can have more than one variable like so:
let $entry := //entry[@id = “galileo”],
$born := $entry/@born, $died := $entry/@died
return $died - $born
XPath “if” Expressions
Like many programming and query languages, XPath 2 introduced if/then/else. Unlike many other languages, though, the else is always required. See the following:
if (name() eq “entry”) then “yes” else “no”
Note that you can’t use if-then-else to guard against errors:
if (true()) then population/$i else population/0
This will likely raise a divide-by-zero error even though the “else” part is never used. The XPath 2 and XQuery languages were designed this way to give implementations as much power as possible to rewrite your expressions to make them go faster.
XPath “some” and “every” Expressions
XPath calls some and every quantified expressions; they are like the “implicit existential quantifier” that you learned about: the “=” operator. For example the following code could be read as “some node $n2 whose value appears in $list1 is equal to some other node $n2 whose value appears in $list2.”
$list1 = $list2
You could also write this as:
some $v in $list1 satisfies length(index-of($list2, $v)) ge 1
The “some . . . satisfies” expression returns true if the expression after “satisfies” is true, using the variable (or variables) you bind after the keyword, for at least one value in $list1.
Similarly, if you replace some by every, the expression returns true if the expression is true for every separate value in the list. Here is a longer example:
let $list := (1, 2, 3, 4, 5),
$squares := (1, 4, 9, 25)
return
every $i in $list satisfies ($i * $i) intersect $squares
The example makes use of effective boolean value — the expression intersecting a list with one item, the square of $i, with the list of squares will be true if it’s not an empty set. The result of the whole XPath expression is false though because the value sixteen is missing from the list of squares.
These four expressions — if-then-else, let-return, some-satisfies, and every-satisfies — are all very useful in their place, and you should be aware of them in case you have to work with someone else’s XPath expressions! The last two in particular, some and every, are often used simply because they were used as examples in the W3C XQuery 1.0 Use Cases document that you can find on http://www.w3.org/TR/.
XPath Cast and Type Expressions
XPath 2 added expressions that work on the XML Schema type of expressions and values: instance of, cast, castable, and treat as. In practice these may be useful when XPath is embedded in SQL expressions or when XPath is used inside XSLT and XQuery, but tend not to be useful when XPath is used alone because it’s rare to have Schema-type information available outside of type-aware environments.
instance of
You can use instance of to determine if a value is in fact of a particular type. The following example will copy a <sock> element to its output, but will ignore anything else:
if ($input instance of element(sock)) then $input else ()
cast
Sometimes you need to convert a value from one type to another. The way you do this is usually with a cast, although in some more complex cases, especially for complex user-defined types, you may end up writing a function to do it instead. You can only cast to atomic types, not elements, and, unlike in languages like C++, casting can affect the value. For example, you could cast an attribute to an integer in order to pass its value to a function expecting numbers. In the following snippet, if you tried to compare @born to 1700 directly, you’d get a type error unless the XPath engine knew that @born attribute held an integer, perhaps because of some XML Schema validation episode that had already happened:
//entry[(@born cast as xs:integer) gt 1700]
castable
In XPath 2 there’s no way to catch errors, so if a cast fails you end up with no results. The castable expression lets you do the cast only if it is going to work:
if ($entry/@born castable as xs:integer) then $entry/@born cast as xs:integer else 42
treat as
The treat as expression is used as a sort of assertion: A treat as T says that the XPath compiler is to behave as if A really does have type T, and allows you to write anything that you could write in that case. If, at runtime, A does not have type T, the XPath processor will raise an error. Normally XPath is actually interpreted rather than compiled, and the compiler part is called static analysis; this is done before evaluating expressions to make sure there are no type errors. The difference between cast and treat as is that cast affects the dynamic type of the value that is actually supplied, and maybe even changes it, whereas treat as does not change the value and will raise a runtime error if the value does not have the right type, but will allow you to write expressions like math:sqrt($x treat as xs:double).
XPath Functions
A function in mathematics is way of giving a name to a calculation; in XPath, functions work in much the same way. A function is said to take arguments, also called parameters, meaning that they have input; the output is called the result of the function.
For example, string-length(“Jerusalem”) is a call to the function string-length with argument “Jerusalem”, and the result is, of course, 9. Like most computer languages XPath includes quite a few predefined functions. XPath 2 added considerably to their number, and XPath 3 will add even more. Most of the new functions since XPath 1 come from one of two sources: first, from handling XML Schema types, since that ability was added for XPath 2; second, because users wanted them and showed a compelling reason to add them, often on the W3C public “bugzilla” tracking system, and sometimes by asking their vendor or implementer to add a feature.
There’s a complete list of the XPath functions in Appendix B at the back of this book, along with a list of the W3C XML Schema types. This section looks at a few of the functions to give you a feel for some of the things you can do.
Document Handling
The doc() and document() functions read an external XML document and return the document node, through which you can access the rest of the document. The document must, of course, parse as well-formed XML.
Take Listing 7-3, which contains extra information about people in the biography, such as this:
![]() LISTING 7-3: extra.xml
LISTING 7-3: extra.xml
<?xml version=”1.0” encoding=”utf-8”?> <people> <person id=”armstrong-john”> <p>W. J. Maloney's 1954 book “George and John Armstrong of Castleton, 2 Eighteenth-Century Medical Pioneers” was reviewed by Dr. Jerome M Schneck.</p> </person> <person id=”newton-sir-isaac”> <p>Invented the apple pie.</p> </person> </people>
Now you could use XPath to extract the names of people who are in both the biography and the extra file like so:
/entry[@id = doc(“extra.xml”)//person/@id]/title
If you try this in oXygen with the armstrong.xml (Listing 7-1) file open, and with extra.xml (Listing 7-3) in the same folder as armstrong.xml, you will find the result shown is Armstrong, John.
You won’t be able to try this example with xmllint or other XPath 1 programs, because XPath 1 didn’t have a function to load a file; it came from XSLT.
String-Handling Functions
People do a lot of string-handling in XPath, especially from XSLT or XQuery. String functions include substring(), substring-before(), substring-after(), translate(), matches(), replace(), concat(), string-length(), and more. See Appendix B, “Xpath Functions” for a full list.
It’s worth learning about substring-before() and substring-after() because they’re a little unusual. The call substring-before(“abcdefcdef”, “cd”) returns ab, and substring-after(“abcdefcdef”, “cd”) returns efcdef. In other words, the functions search the string you give, and look for the first occurrence of the second argument (“cd” in this example). Then they return either everything before that first occurrence or everything after it.
The matches() and replace() functions use regular expressions. They were introduced in XPath 2, although you can find implementations for XSLT 1 at www.exslt.org. Regular expressions, also called patterns, are extremely useful for anyone working extensively with text, and if that’s your situation, it’s worth using an XSLT 2 or XPath 2 processor such as Saxon just for that single feature.
Numeric Functions
XPath 1 includes only a very few numeric functions: sum(), floor(), ceiling(), round(), and, to construct a number from a string, number(). There were also some named operators such as div, idiv, and mod.
XPath 2 adds abs(), round-half-to-even(), and trigonometric and logarithmic functions such as sin(), sqrt(), and so forth.
The XPath 3 draft adds format-number().
One reason to add the trigonometric functions to XPath was that people are now using XSLT and XQuery to generate graphics using SVG. You will learn more about SVG in Chapter 18, “Scalable Vector Graphics (SVG)”.
Defining Your Own Functions
You can define your own functions for use in XPath expression in two ways. The first, starting in XPath 3, is by using inline functions like so:
let $addTax := function($a as xs:double) {
$a * 1.13
} return $addTax(/invoice/amounts/total)
Inline functions are mainly useful with XQuery and XSLT; if you’re using XPath from a traditional programming language, you’re more likely to want to do that processing in the parent language. However, inline functions in XPath 3 can help to simplify large and complex XPath expressions.
The second way to define your own function is to write (or call) an external function. For example, if you are using the Saxon XSLT engine, which is written in Java, you can call out to functions that are implemented in XSLT (the host language) as well as to external functions written in Java. They’re called external because they’re outside not only XPath, but also the language (in this case XSLT) that is using XPath. Chapter 8 returns to this topic and gives you examples of defining functions.
In XPath 3 you can also refer to functions using function items. A function item is the name of a function (complete with namespace prefix if needed) followed by a hash (#) and the number of arguments. For example you could use fn:round#1 because round() has only one argument. If you define a variable to contain a function item you can use the variable like the function. For example, the following expression returns the value 4:
let $r := round#1 return $r(3.5)
XPath Set Operations
XPath node lists are not really sets: every time you do a step, they are sorted into document order and duplicate nodes are eliminated. But it’s still useful to do set-like operations on them.
Suppose $a and $b are two unimaginatively named node lists. Table 7-5 shows some set-like operations you can do using XPath 1, XPath 2, or later.
TABLE 7-5: XPath Set-like Operations
| OPERATION | XPATH EXPRESSION |
| . occurs within $a | count($a|.) = count($a) |
| All nodes in $a or $b | $a|$b or, in Xpath 2 or later, $a union $b |
| Only nodes in both $a and $b | $a[count(.|$b) = count($b)] or, in XPath 2 or later, $a intersect $b |
| Nodes in $a but not in $b | $a[not(count(.|$b) = count($b)] or, in XPath 2 or later, $a except $b |
XPath and Namespaces
One of the most common questions people ask when they start to use XPath is “why doesn’t my XPath expression match anything?”
By far the most common reason is that the elements in the document have an associated XML namespace, and the XPath expression don’t account for this.
XPath does not give a complete way to handle namespaces itself: you need the cooperation of the host language. You have to bind (connect) a prefix string that you choose to the exact same URI, byte for byte, that’s in the document.
Take a look at Listing 7-4 for an example:
![]() LISTING 7-4: tiny.html
LISTING 7-4: tiny.html
<?xml version=”1.0” encoding=”UTF-8”?>
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN”
“http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<title>This is not a title</title>
</head>
<body>
<h1>No h1 here</h1>
<p>No p here</p>
</body>
</html>
You might think (as most people do at first) that you could extract the title of this document like this:
/html/head/title
But if you try this you’ll discover it doesn’t work. Recall that a namespace URI is actually a part of the element’s name in XML. So there’s no element called “title” in this document. Instead, there’s one whose namespace URI is that of XHTML and whose local name is “title”.
The following will work but is cumbersome:
/*[local-name() = “html”]/*[local-name() = “head”]/*[local-name() = “title”]
Strictly speaking, you should also test namespace-uri() in each of those predicates too, in case there are elements from some other namespace in the document with the same local names, but it’s already too complicated to work with. Use this approach only as a last resort.
The preferred way to use XPath in documents with namespaces is to bind a prefix to the document’s namespace and use that. For example, in PHP you might do something like this:
$sxe = new SimpleXMLElement($html);
$sxe->registerXPathNamespace('h', 'http://www.w3.org/1999/xhtml'),
$result = $sxe->xpath('/h:html/h:body/h:title'),
foreach ($result as $title) {
echo $title . “
”;
}
The loop at the end is because XPath returns a node list, although in this case of course you’ll only get one item back.
The same sort of technique works in most other languages, including Java, JavaScript, Perl, Python, Ruby, C, C++, Scala, and so forth. XSLT and XQuery also provide ways to work with XML namespaces, as you’ll learn in Chapters 8 and 9.
SUMMARY
- XML is often stored in memory in a tree structure like DOM.
- XPath is a terse, powerful way to refer to parts of an XML document.
- XPath works on trees, including both DOM and XDM; not on tags.
- XPath uses node tests, predicates, and steps.
- XPath works with W3C XML Schema types as well as with plain untyped XML.
- XPath provides the foundation for XSLT and XQuery, and is also available in most programming languages.
- XPath cannot change the document, and cannot return elements that are not part of the document; to do those things you need a language such as XSLT, the subject of the next chapter.
EXERCISES
You can find answers to these exercises in Appendix A.
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY POINTS |
| How XML is stored in memory | XML is usually stored in trees, using DOM, XDM, or some other data model. |
| What is XPath? | XPath is an expression language used primarily for finding items in XML trees. |
| Is XPath a programming language? | Although XPath is a complete language, it is designed to be “hosted” in another environment, such as XSLT, a Web browser, Query, or Java. |
| XPath and Namespaces | You generally have to bind a prefix to a namespace URI outside of XPath and use expressions like /h:html/h:body/h:div to match elements with an associated namespace. |
| Can XPath change the document, or return elements without their children, or make new elements? | No. Use XQuery or XSLT for that. |
| When should I program with the DOM? | The DOM API is low-level; use XPath, XQuery, or XSLT in preference to direct access of the DOM. |