
Chapter 9
XQuery
WHAT YOU WILL LEARN IN THIS CHAPTER:
- Why you should learn XQuery
- How XQuery uses and extends XPath
- Introduction to the XQuery language
- How to make and search an XML database
- When to use XQuery and when to use XSLT
- The future of XQuery, and how to learn more
XQuery is a language for searching and manipulating anything that can be represented as a tree using the XQuery and XPath Data Model (the “XDM” that you heard about in Chapter 7, “Extracting Data from XML”). XQuery programs (or expressions as they are called) can access multiple documents, or even multiple databases, and extract results very efficiently.
XQuery builds on and extends XPath. This means that XQuery’s syntax is like XPath and not XML element–based like XSLT.
In this chapter you will learn all about this XQuery language: what it is and how to use it. You will also learn some rough guidelines for when to use XQuery, when to use XSLT, and when to use both, in Chapter 19, “Case Study: XML in Publishing.” The short story is that XSLT is often best if you expect to process entire XML documents from start to finish and XQuery is often best if you are processing only part of a document, if you work with the same document repeatedly, or if you are processing a large number of documents.
XQUERY, XPATH, AND XSLT
XQuery, XPath, and XSLT share a lot of components. The best way to break down the various relationships though is this: where XSLT uses XPath — for example, in match expressions and in <xslt:value-of> — XQuery extends XPath. Any XPath 2 expression that you can write is also an XQuery expression. Let’s look at each relationship separately.
XQuery and XSLT
Like XSLT (see Chapter 8), XQuery implementations often support a collection() function to work on databases or on the filesystem (for example, with collection(“∗.xml”)); however, whereas XSLT’s greatest strength lies in apply-templates and processing entire documents, XQuery is often best for extracting and processing small parts of documents, perhaps doing “joins” across multiple documents. The two languages are largely equivalent, but implementations tend to be optimized for these two different usages.
XQuery and XPath
Both XPath (starting with version 2) and XQuery are built on the same abstract data model, the XDM. Because of this, XQuery is not defined to operate over XML documents. Instead, like XPath 2, it is defined to work on abstract trees called data model instances; these could be constructed from XML documents, but they could also come from relational databases, RDF triple stores, geographical information systems, remote databases, and more.
Some differences do exist between XQuery and XPath, of course. The biggest one you’ll see in practice is that there is no default context item in XQuery. For example, if you try a query like the following you’ll get an error about no default context item.
/dictionary/entry[6]
This is because XQuery is commonly used to get information out of databases, or out of whole collections of documents. So, instead you write
doc(“dictionary.xml”)/dictionary/entry[6]
and all is well.
The biggest difference between XQuery and XPath, though, and by far the most important, is that there’s more of XQuery: it’s a full language in its own right. You look at some more examples in a moment, but first you should learn a little about where and how XQuery is used.
XQUERY IN PRACTICE
XQuery is widely used today, and lots of different implementations exist. The examples in this chapter focus on two implementations, Saxon and BaseX. In addition, this section covers some of the other areas in which XQuery has been quietly transforming whole industries.
Standalone XQuery Applications
In the previous chapter you used Saxon, a Java-based XSLT engine that you ran from the command line. Saxon also implements XQuery, so you could use Saxon to run the examples later in this chapter. Saxon reads your XML document, reads your query, runs the query against the document, and then prints the result.
Another open source standalone application for running XQuery is BaseX, which can be used either standalone or as a server, and which also has a graphical user interface. Dozens of other similar XQuery programs are available.
Part of SQL
Recent editions of the SQL standard from the International Organization for Standards (ISO, not an acronym) include a way to embed XQuery expressions in the middle of SQL statements. The major relational databases such as Oracle, IBM DB2, and Microsoft SQL Server all implement XQuery.
Callable from Java or Other Languages
Saxon, BaseX, Qizx, and a host of other programs come with Java libraries so that Java programmers can use XQuery instead of, or alongside, the document object model (DOM). Java programmers have reported that their programs became 100 times smaller when they moved to using XQuery instead of the DOM, and therefore much easier to understand and maintain.
XQuery libraries are also available for other languages, such as PHP, C++, and Perl: BaseX, Zorba, Berkeley DB XML, and others.
A Native-XML Server
BaseX, MarkLogic (commercial), eXist, Qizx, and several other programs exist that make an index of any number of XML documents, and can run queries against those documents using a server, so that there’s no large startup time.
Some of these programs can also be called from a web server, using the servlet API or even as an Apache HTTP Web Server module; some of them include web servers so that you can write entire web-based applications in XQuery.
These programs tend to be mature, solid, robust, and very fast.
XQuery Anywhere
You can use XQuery on the cloud, in web browsers, on mobile devices, embedded inside devices — there are too many variations to list them all! Sometimes XQuery is hidden, or forms an inconspicuous part of a system. Apple’s Sherlock program was extensible using XQuery; a number of commercial decision management and business support systems use XQuery, but don’t generally make a big deal out of it.
In this chapter you’ll use two different XQuery programs. One, Saxon, is a command-line program that reads an XQuery expression and one or more XML documents and produces a result. The second, BaseX, is a database server that’s fast and easy to install and configure. BaseX runs XQuery expressions too, but instead of loading XML documents from your hard drive it can also use a database for better performance. You have already used Saxon in its XSLT mode. In the following exercise you’ll install BaseX and see how easy it is to use.
java -cp BaseX.jar org.basex.BaseXGUI
 <?xml version=”1.0”?><?xml version=”1.0” encoding=”utf-8”?>
<entry id=”armstrong-john”>
<title>Armstrong, John</title>
<body><p>, an English physician and poet,
was born in <born>1715</born> in the parish of Castleton in Roxburghshire,
where his father and brother were clergymen; and having
completed his education at the university of Edinburgh,
took his degree in physic, Feb. 4, 1732, with much reputation.</p>
</body>
</entry>
<?xml version=”1.0”?><?xml version=”1.0” encoding=”utf-8”?>
<entry id=”armstrong-john”>
<title>Armstrong, John</title>
<body><p>, an English physician and poet,
was born in <born>1715</born> in the parish of Castleton in Roxburghshire,
where his father and brother were clergymen; and having
completed his education at the university of Edinburgh,
took his degree in physic, Feb. 4, 1732, with much reputation.</p>
</body>
</entry>armstrong.xml
xmllint --noout armstrong.xml
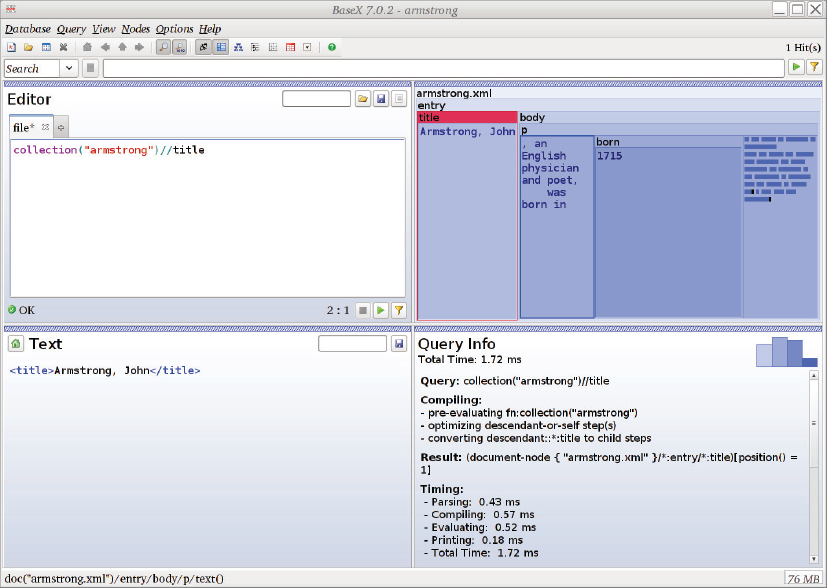
collection(“armstrong”)//title
java -cp saxon9he.jar net.sf.saxon.Query thetitle.xq
BUILDING BLOCKS OF XQUERY
In the previous section you saw a very simple XQuery expression, just to get something working. Your sample query was just one line long, and a lot of useful XQuery expressions are like that in practice. But just as often you’ll see longer and more complicated constructions, some scaling up to entire applications.
Before you learn about XQuery in detail, there are some things you should know that will help you. This section takes a more in-depth look at some building blocks of XQuery.
FLWOR Expressions, Modules, and Functions
You learn about each of these things in detail later, but for now, you should know that whereas templates are the heart of XSLT, the heart of XQuery is in “FLWOR” expressions, in functions, and in modules.
FLWOR (pronounced “flower”) stands for For, Let, Where, Order by, Return; you can think of it as XQuery’s equivalent to the SQL SELECT statement. Here is a simple example:
students.xml
The keywords are bold just so you can see how they fit in with the FLWOR idea; you don’t have to type them in bold, of course. If you downloaded BaseX or Saxon, you can fetch students.xml from the website for this book and run the example just as it is.
Although this short example doesn’t use all the components — it has no let or order by clauses — it is still a FLWOR expression.
Following is a slightly bigger example, using a much larger XML document The sample XML document is 4,000 lines long, and too large to print in this book; it is from the two-hundred-year-old dictionary of biography edited by Chalmers. The full 32-volume dictionary is online at http://words.fromoldbooks.org/, but this is just a tiny fraction of it, with simplified markup:
for $dude in doc(“chalmers-biography-extract.xml”)//entry
where xs:integer($dude/@died) lt 1600
order by $dude/@died
return $dude/title
dudes-simple.xq
On the first line you can see there’s a for expression starting. If you’re familiar with procedural languages like PHP or C, note that this for is very different! In XQuery, for generates a sequence of values. It does this by making a sequence of tuples, evaluating the body of the for expression for each tuple, and constructing a sequence out of the result.
Here is a simple example to help you understand tuples:
for $a in 1 to 5, $b in (“a”, “b”, “c”)
return <e id=”{$b}{$a}”/>
If you type this into the BaseX query window and run it, or put it in a text file and run Saxon on it in XQuery mode (not XSLT mode), you will see this result:
<e id=”a1”/> <e id=”b1”/> <e id=”c1”/> <e id=”a2”/> <e id=”b2”/> <e id=”c2”/> <e id=”a3”/> <e id=”b3”/> <e id=”c3”/> <e id=”a4”/> <e id=”b4”/> <e id=”c4”/> <e id=”a5”/> <e id=”b5”/> <e id=”c5”/>
This shows fifteen lines of output, one for each possible combination of the numbers 1 through 5 and the letters a, b, and c. The XQuery processor has generated all fifteen combinations and, for each combination, has evaluated the query body on the second line. The results are then put into the sequence you see as the result. Each combination, such as (3, a), represents a single tuple.
A multi-threaded XQuery processor might evaluate the query body in parallel; on a large database it might be faster to generate the tuples in some particular order, making best use of an in-memory cache. All that matters is that the results end up in the right order. This is generally true in XQuery: optimizers can rearrange your query, sometimes in quite surprising ways, as long as the result is the same. Most times you won’t have to think about this, but if you call external functions that interact with the outside world, you might be able to see this happening.
Now that you know a bit about tuples and for, let’s return to the code example:
for $dude in doc(“chalmers-biography-extract.xml”)//entry
where xs:integer($dude/@died) lt 1600
order by $dude/@died
return $dude/title
dudes-simple.xq
The first line starts the FLWOR expression: the tuples consist of a single item each, bound to $dude, and the items are each <entry> elements.
The next line weeds out the results, keeping only tuples in which the dude (or dudette) died after the year 1600. The xs:integer() function converts the attribute to a number so that you can do the comparison.
The third line tells the XQuery processor to sort the resulting sequence by the (string) value of the $dude/@died attribute. Hmm, that’s going to go wrong if someone died before the year 1000, so you should change it like so:
order by xs:integer($dude/@died) ascending
ascending is the default, but now you can guess how to sort with most recent first, using descending instead. The default, if there is no order by clause, is to use document order if that applies, but otherwise it’s in the order in which the tuples are generated.
Finally, the fourth line of the listing says what to generate in the result for each tuple that was accepted: return the title element. If you run this, you’ll get output that starts like this:
<title> <csc>Abu</csc>-<csc>Nowas</csc> </title> <title> <csc>Ado</csc> </title> <title> <csc>Alfes</csc>,<csc>Isaac</csc> </title> <title> <csc>Algazeli</csc>,<csc>Abou</csc>-<csc>Hamed</csc>-<csc>Mohammed</csc> </title>
There are two difficulties with the output generated by this example. The first is that it’s hard to read, and the second is that there’s no outermost element to make it legal XML output. It turns out to be rather easy to generate XQuery output that is not well-formed XML, a problem that may be partly addressed in XQuery 3.0 with an option to validate the output automatically. In the following exercise you’ll make a version of the query that generates nicer output.
dudes.xq
java -jar saxon9he.jar -query dudes.xq > results.xml
<?xml version=”1.0” encoding=”UTF-8”?> <results> <dude>Abu-Nowas (810)</dude> <dude>Ado (875)</dude> <dude>Alfes, Isaac (1103)</dude> <dude>Algazeli, Abou-Hamed-Mohammed (1111)</dude> <dude>Aben-Ezra (1165)</dude> <dude>Ailred (1166)</dude> <dude>Accorso, Francis (1229)</dude> . . . </results>
$dude/title//text()
<title> <csc>Abel</csc>, <csc>Gaspar</csc> </title>
normalize-space(string-join($dude/title/descendant-or-self::text(), “”))
XQuery Expressions Do Not Have a Default Context
In XSLT or XPath, there’s usually a current node and a context item. You can write things like //boy[eye-color = “yellow”] or <xsl:apply-templates/>, and because there’s a default context, the right thing happens.
In XQuery you have to be explicit, and write things like:
doc(“students.xml”)//boy[eye-color = “yellow”]/name
or, more commonly:
for $boy in doc(“students.xml”)/students/boy where $boy/eye-color = “yellow” return $boy/name
THE ANATOMY OF A QUERY EXPRESSION
Now that you’ve learned a bit more about XQuery, this section gets more formal and goes over the basic parts of a query.
Every complete query has two parts: the prolog and the query body. There is also an optional third part, the version declaration. Often the optional version declaration is left out and the prolog is empty, making the entire query just a query body. This is how the examples in the chapter thus far have been constructed, but not for long. Look at the following example for a complete query.
In section 4 of http://www.w3.org/TR/xquery-30/ you will see the following:
[1]Module ::= VersionDecl? (LibraryModule | MainModule) [3]MainModule ::= Prolog QueryBody
Rule [1] says that, in XQuery, a module starts with a version declaration, which (because of that question mark after it) is optional; then there is either a LibraryModule or a MainModule. If you look at the definition of MainModule on the next line, it consists of a prolog followed by a query body.
You’ll come back to modules later in this chapter. For now, the important part to know is that every complete XQuery consists of a version declaration, a prolog, and a body. (Remember that in the examples so far the optional version declaration was left out and the prolog was empty.)
The following sections introduce the version declaration and the various things you can put into the query prolog; you’ll see some examples along the way, and after the prolog you’ll come back to the query body, which is where your FLWOR expressions go.
The Version Declaration
Every XQuery query body can begin with a version declaration like so:
xquery version “1.0” encoding “utf-8”;
The values 1.0 (for the version of XQuery in use) and utf-8 (for the encoding of the file containing the query) are defaults. If you use features from versions of XQuery newer than 1.0, you should indicate the minimum required version in the version declaration. If you don’t use a version declaration, the default is 1.0. You can leave out the encoding or the version if you like, as shown here:
xquery version “1.0”; xquery encoding “utf-8”;
The Query Prolog
The XQuery prolog is a place for definitions and settings to go, before the actual query body itself. The prolog is everything after the (optional) version declaration but before the start of the query.
You can define functions, bind prefixes to namespaces, import schemas, define variables, and more. The items can appear in any order, although, for example, a namespace declaration has to appear before you try to use the namespace it declares.
Namespace Declarations
Use a namespace declaration to connect a short name, called a prefix, to a namespace URI like so:
declare namespace fobo = “http://www.fromoldbooks.org/ns/”;
The prefix fobo here is said to be bound to the namespace URI http://www.fromoldbooks.org/ns/.
XQuery comes with a number of namespace bindings already built in:
xml = http://www.w3.org/XML/1998/namespace xs = http://www.w3.org/2001/XMLSchema xsi = http://www.w3.org/2001/XMLSchema-instance fn = http://www.w3.org/2005/xpath-functions local = http://www.w3.org/2005/xquery-local-functions
You can bind them yourself too if you prefer, using declare namespace in the same way. The local namespace is for use in your own functions, as you’ll learn shortly.
Importing Schemas
You can “import” a W3C XML Schema into your query so that you can then refer to the types it defines, and so that an XQuery engine can use it for validation. The schema must be an XSD-format XML document, or at least, that’s the only format that the XQuery specification demands. The following example shows you how to import an XML Schema:
import schema fobo=”http://www.fromoldbooks.org/Search/”;
import schema “http://www.exmple.org/” at “http://www.example.org/xsdfiles/”;
import schema fobo=”http://www.fromoldbooks.org/Search/”
at “http://www.fromoldbooks.org/Search/xml/search.xsd”,
“http://www.fromoldbooks.org/Search/xml/additional.xsd”;
The first example instructs the XQuery processor to import a schema associated with the namespace URI http://www.fromoldbooks.org/Search and also to bind that URI to prefix fobo, but does not tell the XQuery processor where to find the schema.
The second example imports a schema for a given namespace URI, and gives the URI for its location. You can use a relative URI for the location hint if you like, but it’s up to the implementation as to how to fetch the schema, unfortunately.
The third example gives all three elements: a prefix, a namespace URI, and then not one, but two, location hints. Again, it’s up to the individual implementation as to whether both locations are used or only the first one found.
If you want to import an XML Schema document that does not use namespaces, use the empty string (“”) as the target namespace.
When you import a schema into a query, two things happen: first, the things defined in the schema (types, elements, attributes) become available in the “in-scope schema definitions” in the query. You can use the types defined in the schema just as if they were built-in types, and you can validate XML fragments against the schema definitions. Second, validated XML document nodes have schema type information associated with them (this attribute’s value is an integer, that element contains a BirthplaceCity, and so on).
You can use the imported schema types in XPath element tests — for example, element(∗, my:typename) to match any element whose type is declared in an imported schema to be typename in the namespace associated in the query with the prefix my. You can use element(my:entry, my:entrytype) to match only an element called entry and of schema type entrytype, again in an appropriately declared namespace. You can leave out the type name and use element(student:boy) to match any element whose name is boy; you can also write element() or element(∗) to match any element.
You see more examples of how you can use the schema types when you write your own functions in just a moment; see Chapter 5 for examples of defining your own types, although not all XQuery implementations support user-defined types. Because not all XQuery implementations support user-defined schema types, a detailed description is out of the scope of this book, but most implementations do at least support types for variables and function arguments, and queries can run much faster if you use them.
Importing Modules and Writing Your Own Modules
You can also import modules. A module is a collection of XQuery definitions. Following is how you’d tell your XQuery processor that you wanted to use a module:
import module namespace fobo=”http://www.example.org/ns/” at “fobo-search.xqm”; import module “global-defs.xqm”;
As with schemas, you can assign a prefix; unlike importing schemas, however, modules always associate their names with a namespace URI, so you can’t just use an empty string. The location URI is a hint, and different implementations may do different things with it.
Once you import a module you can use the public functions and variables that it defines.
Modules are most often written in XQuery, and are just the same as the main XQuery file, except that they start with a module declaration instead of a module import statement, like so:
import module namespace fobo = “http://www.example.org/ns/”;
Modules are very useful. They let you:
- Organize larger applications into more manageable parts
- Manage having multiple people working on the same application
- Have multiple implementations of an API, to separate out the non-portable (implementation-dependent) parts clearly
- Share libraries of code with other people
You can find some community-contributed library modules at www.exquery.org that you can try.
Variable Declarations
XQuery is a declarative language, like XSLT, so the “variables” are really more like the symbols used in algebra than variables in a regular programming language: you can’t change their values! There’s no assignment.
Here are some example variable declarations:
declare variable $socks := “black”; declare variable $sockprice as xs:decimal := 3.6; declare variable $argyle as element(∗) := <sock>argyle</sock>;
The full syntax is:
declare variable $name [ as type] := [external] value;
The brackets ([]) mean you can leave off the things inside of them (don’t include the brackets either, of course!). Notice how XQuery is a language in which values can include XML elements: anything that can go in an XDM instance can be used as a value.
You can refer to variables outside the query — for example, variables exported in a host language such as PHP or Java — by calling them external.
One common use for a variable is to put configuration at the top of a program or module like so:
declare variable $places as xs:string := doc(“places.xml”);
Putting the call to doc() in a variable in the query prolog is no different from putting it everywhere you want to use it: the document will still be loaded only once. But this way you only have to change it in once place.
The value used to initialize a variable can be any expression. You can also give an explicit type to a variable like so:
declare variable $items-per-page as xs:integer := 16;
declare variable $config as element(config, mytype:config) :=
<config>36</config>;
Functions and Function Items
Just as XQuery variables are a useful way to give a name to some meaningful value, a function is a way to give a name to a meaningful expression.
Although XQuery expressions can use all of the functions defined by XPath (see Appendix B for a full list), it’s often useful to define your own. If you find yourself repeating some fragment of XQuery over and over again, or if naming a calculation will make the query clearer, you should use a function. Here is a complete example of a query with a variable, a function, and a one-line query body:
declare variable $james := <person><name>James</name><socks>argyle</socks></person>;
declare function local:get-sock-color(
$person as element(person)) as xs:string
{
xs:string($person/socks)
};
local:get-sock-color($james)
function.xq
The first line declares a variable called $james as a fragment of XML.
The next line declares a function called local:get-sock-color(). The local namespace is reserved in XQuery for user-defined functions like this.
The function takes as input a <person> element and uses a simple XPath expression to return the value of the <socks> subelement, converted to a string.
Finally, you have a query body, the actual part that does the work, and all it does here is pass the variable as an argument, or parameter, to the function and return the result, which shows that James wears argyle socks.
User-defined functions are the second-most important aspect of XQuery, after the FLWOR expression.
Recursive Functions
Although this topic is often considered advanced in programming language courses, recursion, once grasped, is a fundamental part of XML processing. The idea is very simple: you write a function that handles the first part of its input, and then, to handle the rest, the function calls another copy of itself! Here is a very simple example you can try:
declare variable $numbers as xs:integer∗ := (1, 2, 3, 4, 5, 6);
declare function local:sum-of-squares($input as xs:integer∗) as xs:integer
{
if (empty($input)) then 0
else
let $first := $input[1]
return $first ∗ $first + local:sum-of-squares($input[position() gt 1])
};
local:sum-of-squares($numbers)
recursive-function.xq
In this example the function is declared to be in the predefined local namespace. The function sum-of-squares takes a list of numbers as input and returns a single number as a result.
On the fourth line the function checks to see if the input is empty, and, if it is, returns zero (nothing to do). Every recursive function must do something like this or it will never stop, and your query will never finish!
If the input is not empty, there must be at least one number, so you take the first such number and multiply it by itself. If the input list had only one number inside it, that would be all the function ever had to do. But the input might have more than one number, so you need to produce the square of the first number in the list added to the sum of the squares of the rest of the numbers. You already have (most of) a function to calculate the sum of squares, so you call it to do the work. Notice that you give it not $input but $input with the first element removed, $input[position() gt 1], so that the list is shorter. That way you know that eventually the entire list will be processed and the function will finish.
Recursion turns out to be a very natural fit for working with XML, because XML trees are themselves recursive: elements can contain elements, which in turn can contain more elements, all the way down! If you work with XQuery (or XSLT) a lot, you should take the time to become comfortable with recursion.
External Functions
When XQuery is called from another “host” programming language, such as Java, C++, or Perl, you might want to call functions in that host language from within your XQuery expressions. Not all implementation support this, and restrictions usually exist on the sorts of functions you can call, so you’ll have to read the documentation that came with the XQuery engine or host environment.
External functions usually consist of two steps: the first is to expose the function from the host language, and the second is to declare it inside your query. It is really only feasible to give you an example for the second part. Here’s the part you’d put in your query:
declare function java:imagesize($imgfile as xs:anyURI) as xs:integer∗ external;
Now you can use that function in XQuery just like any other. The host language or the XQuery implementation’s documentation will tell you which namespace to use and how to declare it (or it should, at least!).
Module Imports
XQuery lets you write collections of functions and variables and save them; later, you can reuse such a named collection as a library module. This can be an excellent way to structure larger applications, and even with smaller queries, it can help if more than one person or department is involved. You could provide a set of functions that hide the representation of information behind a set of functions, so that you can later change the representation; you could also provide a set of functions that work the same way across multiple XQuery implementations just by importing the appropriate version of a module.
The following example shows how to import a module called wikidates that might provide functions for finding birth and death dates for people based on the XML version of Wikipedia:
import module namespace
wiki = “http://www.example.org/wikidates” at “wikidates.xqm”;
This is a fictional example, and uses example.org, a domain intended only for use in books and examples.
You can leave out the namespace wiki = part if you like, but that would be a fairly advanced usage.
The only difference between the main query itself (also called the main module in the specification) and a module file is this: a module file must have, immediately after the optional version and encoding declaration, a module declaration, like so:
module namespace w = “http://www.example.org/wikidates”;
As usual with XML namespaces, when you import the module you must use the exact same namespace URI, although the prefix (w in this example) doesn’t have to be the same. Within the module a function might be named w:getDateOfBirth, and if you imported the module using the prefix wiki, you’d call the function as wiki:getDateOfBirth(). The XQuery engine knows you mean the same function because the prefixes are bound to the same namespace URI, once in the library module and once in the main module.
In addition, where the main module has a prolog followed by a query body, the library module has only a prolog, and no query body.
Some XQuery modules are available at www.exquery.org and are worth exploring, and some XQuery engines also come with module libraries of their own.
Optional Prolog Features
You can specify various options in the prolog; these are defined by specific XQuery engines, so you should look at the documentation for the product you’re using.
The most common options have to do with serialization: the way that the results are written out. If you are using an in-memory query that just returns a tree or stores results directly back to a database, serialization is probably not an issue. If you are creating HTML (or, more likely, XHTML), you need to use the right options: XHTML is not the same as writing HTML elements in XML syntax. For example, the <br> HTML element must be written <br /> in HTML, with a space between the r and / — it cannot be written as <br></br>. In XQuery 3.0, serialization is likely to be a standard part of the language, but for now just be aware that you’ll probably need to read the documentation for the XQuery engines you use.
The Query Body
You have now seen all of the main parts of the query prolog, and you have also seen some sample queries. The query body is a single XQuery expression after the prolog; it’s the actual query, and although it’s only a single expression, it can be very long! You can also give a sequence of expressions, separated by commas. Because the items in the prolog are all optional, an entire query could be a single simple expression. When XQuery is used from within Java or SQL, this is not uncommon; when XQuery is used to handle complex business transactions, much longer queries are more likely.
Because XQuery extends XPath, you can use pretty much any XPath expression in XQuery. The biggest extensions after FLWOR are described in the following sections.
Typeswitch Expressions
The idea of a typeswitch expression is that you can write code to behave differently based on the type of an expression, such as the argument to a function.
Suppose in the dictionary of biography you have what are called blind entries; these are entries that just have a headword or title, such as “Isaac Newton,” and then just say, “See Newton, Isaac.”
You might define two separate types in your schema for the dictionary, entry and blindentry perhaps, even though both use the same element name. Then you could process them differently like so:
typeswitch ($entry)
case $e as element(entry, blindEntry) return ()
case $e as element(entry, entry) return process-entry($e)
default return fn:error(xs:QName(“my:err042”), “bad entry type”)
Element Constructors
XPath expressions can only ever return pointers into the document tree (or, more correctly, references into XDM instances). People frequently want to do things like “return all of the school elements without any of their children” or to make entirely new elements not in the input. For this you need to use XQuery.
Anywhere you can have an expression or literal value, you can have an element constructor. Two types of element constructors exist: direct and computed.
Direct Element Constructors
You have already seen some examples of direct element constructors:
let $isaac := <entry id=”newton-isaac” born=”1642” died=”1737”> <title>Sir Isaac Newton</title> </entry> return $isaac/title
A direct element constructor can also have namespace declarations, and can contain expressions; you’ll come back to this next example in Chapter 18, “Scalable Vector Graphics (SVG),” but for now all that matters is you could generate a <rect> element with some expressions in the attribute values or content, like so:
let $box:= <rect xmlns=”http://www.w3.org/2000/svg”
width=”{$width}” height=”{$width ∗ 2}”
x=”{$isaac/@born}” y=”{math:sin(xs:integer($isaac/@died))}” />,
$text := <text>His name was {$isaac/title/text()}.</text>
Your XQuery implementation may provide an option to say whether space at the start and end of elements is included or ignored; this space is called boundary space.
You can also make comments and processing instructions like so:
let $c := <--∗ this is an example of a direct XML comment constructor ∗-->,
$p := <?php echo date() ?>
Computed Element Constructors
If you don’t know the name of an element in advance, sometimes you have to use a computed element constructor. You can mix the two styles, and you can always use the computed element constructors, so some people choose to use these all the time, but they can be harder to read. The following example shows computed element constructors:
declare namespace svg = “http://www.w3.org/2000/svg”;
let $width := 30,
$height := 20,
$isaac := <entry id=”newton-isaac” born=”1622” died=”1736”>
<title>Sir Isaac Newton</title>
</entry>,
$box := element svg:box {
attribute width { $width },
attribute height { $height },
attribute x { $isaac/@born },
attribute y { math:sin(xs:integer($isaac/@died)) }
},
$p := element text {
fn:concat(
“His name was “,
data($isaac/title),
“.”)
} return ($box, $p)
This example generates the following output:
<svg:box xmlns:svg=”http://www.w3.org/2000/svg” width=”30” height=”20” x=”1622” y=”0.96375518644307”/> <text>His name was Sir Isaac Newton.</text>
The computed syntax is harder to work with when you are mixing text and values (mixed content). In that case, it’s usually best to use the direct constructors, or to mix the two syntaxes like so:
$p := elememt wrapper {
<text>His name was {data($isaac/title)) }</text>
};
You can also construct text nodes and documents, using text and document instead of element or attribute.
FLWOR Expressions Revisited
It’s time to give the full syntax for FLWOR expressions. You have already seen most of the parts in the “Building Blocks of XQuery” section. Note that XQuery 1, the stable version of XQuery, has a very basic FLWOR expression, and XQuery 3 extends it (there was no XQuery 2). In what follows, the parts that were introduced in 3.0 are marked like this: 3.0.
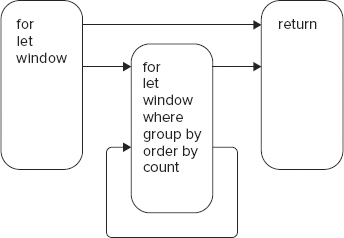
A FLWOR expression starts with one of the keywords for, let, or window3.0, and its associated clause like so:
for | let | window3.0
After the initial for, let, or window3.0, there can be any number of optional clauses as shown here:
(for | let | window3.0 | where | group by3.0 | order by | count3.0)∗
The end of the FLWOR expression is signaled by a return clause:
return ExprSingle
Here, ExprSingle in the XQuery grammar means any single XQuery expression. Figure 9-2 shows a railroad diagram in which you start on the left and follow arrows until you get to the right. You can go round the middle loop as many times as you like, or not at all.
The individual parts of the FLWOR expression expand as shown in the following sections. In the explanations square brackets are used to mean something can be left out: [at $pos] means either put at $pos there, or don’t. The square brackets are just to show you it’s optional, and are not part of the query. The following explanations also use italics to show where you where you can put a value of your own, so as type means you’d type the literal word as followed by a space, and then the name of any type you wanted, such as xs:integer∗ to mean a sequence of whole numbers.
A type can be empty-sequence() to mean (of course) the empty sequence, or it can be a type name, such as xs:integer, optionally followed by an occurrence indicator: ∗ to mean zero or more, ? to mean zero or one, + to mean one or more, or with no indicator to mean exactly one. Thus, xs:integer? will accept either the empty sequence (no integers) or exactly one number. You can’t put an occurrence indicator after empty-sequence() because XQuery does not support sequences of sequences.
The for Clause
Every FLWOR expression starts with a for clause, a let clause, or a window clause. The for clause has the following syntax:
for $var [as xs:integer] [allowing empty] [at $pos] in expr
Here are some examples; you can try them in the BaseX query window:
- Using the at position feature:
for $entry as element(entry) at $n in //entry return <li>{$n}. {$entry/@id}</li>
- Using two variables:
for $a in (1, 2, 3), $b in (4, 5) return $a + $b
- Generating a tuple even for the empty sequence:
for $a allowing empty in () return 42
The let Clause
Use let to bind a variable to a value; you can have more than one let clause by separating them with commas. The syntax is:
let $var [as type] := expression
Here are two examples:
- Specifying a type:
let $x as xs:decimal := math:sin(0.5) return $x
- With both for and let, and a direct element constructor:
for $a in (1, 2, 3) let $b := $a ∗ $a return <r>{$b}</r>
The window Clause
The window clause lets you process several adjacent tuples at a time; it’s described in the section “Coming In XQuery 3.0” later in this chapter.
The where Clause
The where part of a FLWOR is used to weed out tuples, leaving just the ones you want. If you have only a single bound variable in your for part, it’s the same as using a predicate. For example:
for $person in /dictionary/entry[@born lt 1750]
has the same effect as
for $person in /dictionary/entry where #born lt 1750
However, because the where clause operates on tuples rather than nodes, if you have more than one item in each tuple, you have to use a where clause like so:
for $a in (1 to 50), $b in (2, 3, 5, 7) where $a mod $b eq 0 return $a ∗ $b
Some implementations also do different optimizations on predicates and where, so one may be faster than the other, but in most cases you should concentrate on making your query as easy to read as possible.
The group by Clause
Grouping is introduced in XQuery 3.0, and is described later in this chapter.
The order by Clause
Use the order by clause to sort the tuples based on the value of an expression. The following complete example sorts all the people in the dictionary by their date of birth, lowest (earliest) first:
for $person in //entry[@born] order by xs:integer(@born) ascending return $person/title
The syntax is:
[stable] order by expression [direction] [collation “URI”]
You can have any number of the clauses after order by, separated by commas. The direction looks like this:
ascending|descending [ empty (greatest|least) ]
empty greatest and empty least say how the empty sequence is to be compared: whether it goes after all other values or before them.
The stable keyword tells the query processor to keep items in the same order if they have equal keys; sometimes it’s much faster if the implementation can return items with equal sort keys in any order, but that’s not always what you want.
ascending and descending say whether to put the results least first or greatest first.
The collation names a set of sorting rules, usually for comparing strings. For example, your implementation might provide a collation that’s case insensitive, or one in which letters with accents or diacriticals (é, Ô, Æ, ñ, ü) sort the same as if they did not have the marks (e, o, AE, n, u, or ue). The actual URIs you can use are implementation defined, meaning you have to look them up in the manual for the XQuery engine you’re using.
Here are some more examples, showing just the order by clause:
order by $b ascending empty least order by $b descending empty greatest order by $b stable ascending order by $e
The count Clause
Earlier, you saw how the for clause has an optional at $n to associate a variable with the position in the sequence selected by the for clause.
The count clause is similar, but numbers the overall tuples. The following example shows the difference:
for $boy at $boypos in (“Simon”, “Nigel”, “David”),
$game at $gamepos in (“pushups”, “situps”)
count $count
return
<tuple n=”{$count”}>
boy {$boypos} is {$boy}, item {$gamepos}: {$game}
</tuple>
Count-boys-games.xq
The output is as follows:
<tuple n=”1”>boy 1 is Simon, item 1: pushups</tuple> <tuple n=”2”>boy 1 is Simon, item 2: situps</tuple> <tuple n=”3”>boy 2 is Nigel, item 1: pushups</tuple> <tuple n=”4”>boy 2 is Nigel, item 2: situps</tuple> <tuple n=”5”>boy 3 is David, item 1: pushups</tuple> <tuple n=”6”>boy 3 is David, item 2: situps</tuple>
The count clause was introduced for XQuery 3.0, and at the time of writing was not yet widely implemented. You can simulate it, if needed:
for $activity at $n in (
for $boy at $boypos in (“Simon”, “Nigel”, “David”),
$game at $gamepos in (“pushups”, “situps”)
return
concat(“boy “, $boypos, “ is “, $boy,
“ item “, $gamepos, “: “, $game)
)
return <tuple n=”{$n}”>{$activity}</tuple>
The trick here is to use a nested FLWOR expression. The inner expression generates a sequence of strings, each one corresponding to the content of one of those <tuple> elements from the previous example. Then the outer FLWOR maps each of those strings to a <tuple> element, and because there’s only one input sequence, the list of strings, the at $pos clause numbers the strings.
This is a fairly advanced example, and shows how you can use a FLWOR expression wherever you can use as a sequence.
SOME OPTIONAL XQUERY FEATURES
At the same time that the XQuery language itself was being developed, three fairly large add-on facilities were being developed. They are Full Text Search, XQuery Update, and XQuery Scripting. The first two are widely supported; scripting is less widely used, but still useful to know about.
Describing these facilities in much depth is beyond the scope of a “Beginning” book; they could easily each have a chapter on their own. But you will learn in this section what these three facilities are for, see some examples, and learn how to find out more.
XQuery and XPath Full Text
This optional facility adds the idea of an external index to words or tokens occurring in the database, so that you can find all elements containing a given phrase very quickly. The Full Text language extends XPath, but in practice only really makes sense in XQuery, even though it could also be used with XSLT. Because the Full Text facility was finalized after XQuery 1.0, implementations vary a lot in how they support it. However, where it’s available it can be very powerful.
One advantage of using full text searching is that it’s usually pretty fast, even when you have terabytes or petabytes of data in your database. The speed is also predictable, which makes it useful for implementing interactions with human users.
Here is an example, using the biographical dictionary:
for $e in //entry where $e//p contains text “Oxford” return (normalize-space($e/title), “
”)
This returns results like this:
Adams, Fitzherbert Airay, Henry Aldrich, Robert
The entries returned are those for which the where clause is true: the entries that have a <p> element (a paragraph) that contains the word “Oxford.” The query actually returns a sequence of two items for each matching entry. The first item is the title, converted to a string and with leading and trailing spaces removed, and the second item in the sequence is a newline, represented in hexadecimal as an XML character reference, “
” — the newline is just to make each title be on a separate line.
The Full Text specification has a lot of features: you can enable stemming, so that hop might also match hopped, hopping, and hops; you also can enable a thesaurus, so that walk might also match amble, shuffle, stroll, path, and so on.
The XQuery Update Facility
So far all of the XQuery expressions you have seen return some fraction of the original document, and leave the document unchanged. If you’re using a database, the chances are high that you’ll need to change documents from time to time. A content management system might let users edit articles, or might represent users and their profiles as XML documents.
You might insert a new entry at the end of the biography like so:
insert nodes
<entry id=”bush-george”><title>George Bush</title></entry>
as last into doc(“dictionary.xml”)/dictionary
The XQuery Update Facility Use Cases, which you can find at http://www.w3.org/TR/(choose the “all items sorted by date” option), has many more examples. However, you will need to check the documentation for your system to see if it supports the Update Facility and, if so, exactly how.
XQuery Scripting Extension
This specification is still a draft at the time of writing. The XQuery Working Group at W3C does not have agreement on the language. However, some aspects are very useful and are widely implemented. In particular, whereas the Update Facility does not let what it calls an updating expression return a value, the scripting extension makes it possible to mix updates and value returns. You could, for example, report on whether a database insert was successful, something not possible with just the Update Facility.
The scripting extension also adds procedural-programming constructs such as loops, variable assignment, and blocks.
COMING IN XQUERY 3.0
When this book was written, XQuery 1.0 was well-established, and the W3C XML Query Working Group (in conjunction with the W3C XSLT Working Group) had skipped over 2.0 and was working on XQuery 3.0. The details were not final (XQuery was a “working draft” and not a “Recommendation”) and you should consult http://www.w3.org/TR/ for the latest published version of XQuery; the specification is readable and has examples. If you’ve followed along this far you should have little difficulty in reading the specification, especially after reviewing this section with its introductory descriptions of some of the new features. You can also find Use Cases documents parallel to the specifications, containing further examples, and these do generally get updated as the language specification evolves.
The following sections will give you an idea of what’s coming in XQuery 3.0.
Grouping and Windowing
Suppose you want to make a table showing all the entries in your XML extract from the dictionary of biography, but you want to sort the entries by where the people were born. The following query generates such a list, putting a <group> element around all the people born in the same place:
for $e in /dictionary/entry[@birthplace]
let $d := $e/@birthplace
group by $d
order by $d
return
if (count($e) eq 1) then () else
<group birthplace=”{$e[1]/@birthplace}”>
{
for $person in $e
return
<person id=”{$person/id}”
born=”{$person/@born}”
died=”{$person/@died}”
>{
data($person/title)
}
</person>
}
</group>
Here is a snippet of the output, showing the first two groups:
<group birthplace=”Amsterdam”>
<person id=”” born=”1519” died=”1585”>
Aersens, Peter
</person>
<person id=”” born=”1622” died=”1669”>
Anslo, Reiner
</person>
</group>
<group birthplace=”Bologna”>
<person id=”” born=”1466” died=”1558”>
Achillini, John
Philotheus
</person>
<person id=”” born=”1574” died=”1640”>
Achillini, Claude
</person>
<person id=”” born=”1570” died=”1632”>
Agucchio, John
Baptista
</person>
<person id=”” born=”1479” died=”1552”>
Alberti, Leander
</person>
<person id=”” born=”1578” died=”1638”>
Alloisi, Balthazar
</person>
</group>
More formally, the syntax of a windowing expression (in the XQuery 3.0 draft document, at least) is that you can have either:
for tumbling window $var [as type] in expression windowStart [windowEnd]
or
for sliding window $var [as type] in expression windowStart windowEnd
The first form, the tumbling window, is for processing the tuples one clump at a time. Each time the windowStart expression is true, a new clump is started. If you give an end condition, the clumps will contain all the tuples from the start to when the end is true, inclusive; if you don’t give an end condition, a new clump of tuples starts each time the start condition is true.
In the second form, the sliding window, a tuple can appear in more than one window. For example, you could use a tumbling window to add a running average of the most recent five items to a table of numbers. Each row of the table would be processed five times, and you might add a table column showing the average of the number on that row and the numbers on the four rows before it.
The count Clause
The count clause in the FLWOR expression has already been described in this chapter, but since this is a list of XQuery 3.0 additions you should know that count was added for XQuery 3.
Try and Catch
Try and catch are familiar to programmers using Java or C++; it’s a way to evaluate some code and then, if the code raised an error, instead of ending the query right then and there, you use the emergency fallback code you supply in the catch clause.
The syntax of a try/catch expression is very simple:
try { expression } catch errorlist { expression }
You can also have multiple catch clauses, one after the other with no comma between them.
Here is a complete try/catch example:
for $i in (2, 0.2, 0.0, 4)
return
try {
12 div $i
} catch ∗ {
42
}
If you try this with BaseX, you will see the following result:
6 60 42 3
When the XQuery engine (BaseX) came to find the resulting value for the input tuple (0.0), it had to evaluate 12 divided by zero, and that’s an error. Because the error happened inside a try clause, BaseX checked to see if there was a catch clause that matched the error. There was indeed: the ∗ means to catch any error. So BaseX used the expression in the catch block for the value, and returned 42.
If you try without the try/catch,
for $i in (0.5, 0.2, 0.0, 4) return 12 div $i
you’ll see the following error in the BaseX Query Info window:
Error: [FOAR0001] '12' was divided by zero.
You can catch specific errors, and even more than one error at a time like so:
for $i in (2, 0.2, 0.0, 4)
return
try {
12 div $i
} catch FOAR0001|FOAR0002 { 42 }
The error codes in XQuery are designed so that the first two letters tell you which specification defines them: for example, Functions and Operators for FO. You can look in the corresponding specification to see what the code means.
try { 12 div $i }
catch FOAR0001 { 42 } catch ∗ { 43 }
switch Expressions
The switch expression was introduced because long chains of if-then-else conditions can be hard to read, and, more importantly, because sometimes switch expresses the writer’s intent more clearly. Take the following example:
for $word in (“the”, “an”, “a”, “apple”, “boy”, “girl”)
return (“ “,
switch (substring($word, 1, 1))
case “a” return upper-case($word)
case “t” return $word
case “b” case “B” return <b>{$word}</b>
default return $word)
This example produces the following output:
the AN A APPLE <b>boy</b> girl
The switch statement looks at the first letter of the item it was given, and behaves differently depending on the value, converting words starting with an “a” to uppercase, and surrounding words starting with a “b” with a <b> element, and so on. Notice the two case expression clauses for “b” and “B”, which share an action.
The rather sparse syntax of switch, with no punctuation between cases and no marking at the end, means that if you get syntax errors you may want to put the entire construct in parentheses, to help you find the mistake. In this example there’s a FLWOR for clause with its return, constructing a sequence of a single space followed by whatever the switch expression returns, for each item (actually each tuple) in the for.
Function Items and Higher Order Functions
With XQuery 3.0, the language designers finally admitted that XQuery is a functional language, and added a number of functional programming tools. Some of these are very advanced, and some are very straightforward. This section sticks to the straightforward parts.
Function Items
A “function item” is really just the name of a function together with the number of arguments it takes. For example, you can make a function item to refer to the math:sqrt() function, which takes a single numeric argument and returns its square root, just by writing sqrt#1 in your query.
Why on earth would you want to do this? Read on!
Higher Order Functions
A higher order function is just a fancy name for a function that works with other functions. Consider the following simple function:
declare function local:double-root($x as xs:double)
as xs:double
{
2 ∗ math:sqrt($x)
};
local:double-root(9.0)
If you try this, you’ll discover that, because the square root of nine is three, you get two times three, which is six, as a result.
But what if you wanted to write local:double-sin($x) as well? Or local:double-cos($x)? After a while you start to wonder if you could pass in the name of the function to call instead of sqrt(). And you can, as shown in the following code.
declare function local:double-f(
$x as xs:double,
$f as function($x as xs:double) as xs:double
) as xs:double {
2 ∗ $f($x)
};
local:double-it(9.0, math:sqrt#1)
higher-order.xq
Now you could call double-it() with any function, not only math:sqrt().
This ability to use functions as arguments also lets you write XQuery modules that can accept functions for defining their configuration options, or to change the way they behave.
You can also declare functions inside expressions (actually an XPath 3 feature), and LISP programmers will be pleased to see map and apply as well as fold.
JSON Features
At the time of writing, support for JSON was under discussion in the W3C XQuery Working Group, but no definite resolution had been reached. One proposal is called JSONIQ. In any case, it seems likely that interoperability between JSON and XML will be a part of XQuery in the future. See Chapter 16, “AJAX” for more about JSON.
XQuery, Linked Data, and the Semantic Web
If you are working with RDF, whether as RSS feeds or as Semantic Web Linked Data, XQuery has something to offer you.
You can fairly easily generate RSS and RDF/XML with XQuery, of course. The query language for RDF is called SPARQL, and there’s even a SPARQL query processor written in XQuery that turns out to be faster than many native SPARQL engines. SPARQL engines can produce results in XML, and that too can be processed with XQuery.
XML and RDF both have their separate uses, as do SPARQL and XQuery, and you can use them together when it makes sense.
SUMMARY
- XQuery is a W3C-standardized language for querying documents and data.
- XQuery operates on instances of the XPath and XQuery Data Model, so you can use XQuery to work with anything that can build a suitable model. This often includes relational databases and RDF triple stores.
- Objects in the data model and objects and values created by XQuery expressions have types as defined by W3C XML Schema.
- XQuery and XSLT both build on XPath; XSLT is an XML-syntax language which includes XPath expressions inside attributes and XQuery uses XPath syntax extended with more keywords.
- There are XQuery processors (sometimes called XQuery engines) that work inside relational databases, accessing the underlying store directly rather than going through SQL. There are also XML-native databases, and some XQuery engines just read files from the hard drive, from memory, or over the network.
- XQuery Update is a separate specification for making changes to data model instances.
- XPath and XQuery Full Text is a separate specification for full-text searching of XML documents or other data model instances.
- XQuery Scripting is a separate specification that adds procedural programming to XQuery, but it is currently not a final specification.
- The two most important building-blocks of XQuery are the FLWOR expression and functions.
- XQuery FLWOR stands for for-let-where-order by-return.
- User-defined functions can be recursive, and can be collected together along with user-defined read-only “variables” into separate library files called modules.
EXERCISES
You can find suggested solutions to these exercises in Appendix A.
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY POINTS |
| What is XQuery? | XQuery is a database query language, and also a general-purpose language in which XML elements are a native data type. XQuery is widely implemented, fairly popular, and easy to learn. There are standalone XQuery implementations, embedded implementations, and implementations that work with XML databases. |
| XQuery and XPath | XQuery extends the XPath syntax, unlike XSLT, which embeds XPath inside XML attributes in the XSLT language. |
| FLWOR expressions | The most important part of XQuery; use them to do joins, to construct and manipulate sequences, to sort, and to filter. |
| Functions and modules | You can define function libraries, called modules, with XQuery. |