
10 Modeling Multiprocessor Real-Time Systems at Transaction Level
Giovanni Beltrame, Gabriela Nicolescu and Luca Fossati
CONTENTS
10.3.2 Pthreads as a Real-Time Concurrency Model
This chapter presents a transaction-level technique for the modeling, simulation, and analysis of real-time applications on multiprocessor systems-on-chip (MPSoCs). This technique is based on an application-transparent emulation of operating system (OS) primitives, including support for or real-time OS (RTOS) elements. The proposed methodology enables a quick evaluation of the real-time performance of an application with different design choices, including the study of system behavior as task deadlines become stricter or looser. The approach has been verified on a large set of multithreaded, mixed-workload (real-time and non-real-time) applications and benchmarks. Results show that the presented methodology (1) enables accurate real-time and responsiveness analysis of parallel applications running on MPSoCs, (2) allows the designer to devise an optimal interrupt distribution mechanism for the given application, and (3) helps sizing the system to meet performance for both real-time and non-real-time parts.
10.1 Introduction
Increasingly, large portions of electronic systems are being implemented in software, with the consequence that the software development effort is becoming a dominant factor in the development flow. The problem is aggravated by the strong trend from the “classical” embedded systems toward real-time (RT) systems with explicitly concurrent hardware that is more difficult to analyze and to model. In such systems, beyond the correctness of algorithms, early verification of the real-time behavior and timing constraints is essential. Guaranteeing the required properties with explicitly concurrent software and hardware adds a degree of complexity, which combines with the fact that software deployment and testing on target hardware is difficult and time consuming. To gather timing details and to validate the functionality of the overall system as soon as possible in the development process, high level models of the interactions among application, operating system, and hardware platform are necessary. Unfortunately, generally used methodologies suffer from the code equivalence problem (as presented in Yoo et al. [1]): the code executed by the virtual system is different from the code executed by the final deployed hardware, especially for code that concerns OS primitives. This may change the overall system behavior, leading to less-than-optimal or incorrect design choices. RT systems further complicate the situation as the correctness of the computation is highly dependent on its timing behavior, which implies a necessity for accurate modeling of scheduling choices, task interactions, and interrupt response times. Moreover, the implementation of critical RTOS parts can be carried out either in software or using hardware accelerators, with major consequences on system cost, behavior, and timing features.
In this work, we provide a codesign environment suitable for the development of multiprocessor systems with real-time requirements. The core idea consists in the transparent emulation of RTOS primitives on top of a virtual platform described at the transaction level; the implementation guarantees full compatibility with any POSIX-compliant application. Overall, our approach provides fast and accurate simulation results, allowing effective high-level design space exploration (DSE) for multicore RT systems. Our methodology can be applied to various tasks, such as analysis of system responsiveness in the face of different load and of varying frequency of external events, and as exploration of different scheduling policies.
This article is organized as follows: Section 10.2 describes previous research on the subject and Section 10.3 presents how the proposed methodology addresses the identified issues. Finally, Section 10.4 shows the experimental results and Section 10.5 draws some concluding remarks.
10.2 Previous Work
A hardware/software (HW/SW) codesign flow [2] usually starts at system level, when the boundaries between the hardware and software parts of the final system have not yet been established. After functional verification, the HW/SW partitioning takes place and co-simulation is used to validate and refine the system. The tight time-to-market constraints, the high complexity of current designs, and the low simulation speed of instruction set simulators (ISSs) push for the addition of (RT)OS models in system-level hardware description languages (HDL) (such as SystemC or SpecC). This allows native execution of both the hardware and software models of the system, consistently accelerating simulation. In addition, as both hardware and software partitions are described using the same HDL, it is easy to move functionalities between them. Such ideas have been presented in work that models the application, the hardware, and the services of the RTOS using the same HDL [3, 4, 5 and 6]. Because of limitations in the typical HDL processing model, true concurrency is not achieved, and a trade-off has to be determined between simulation speed and accuracy of the intertask interaction models. When the design is refined, the RTOS model can be translated automatically into software services. Unfortunately, however, in practice, the use of a widely adopted RTOS is preferred, meaning that results taken during the modeling phase are no longer accurate.
An extension to these works has been implemented by Schirner and Domer [7] addressing the problem of modeling preemption, interrupts, and intertask interactions in abstract RTOS models. Their work mainly concentrates on simulating the system timing behavior, and the code equivalence problem is not taken into account.
He et al. [8] present a configurable RTOS model implemented on top of SystemC: as opposed to other approaches, only the software part of the system is modeled, while the hardware portion is taken into account only by means of timing annotations inside the RTOS model.
A different technique is used in Yoo et al. [1] for automatic generation of timed OS simulation models. These models partially reuse unmodified OS primitives, thus mitigating the code equivalence problem. High emulation speed is obtained, thanks to native execution on the host machine, but the timing of the target architecture is not accurately replicated and it does not allow precise modeling of multiprocessor systems. In contrast, we use ISSs in our approach, which implies lower simulation speed but also, as the assembly code of the final application is used, minimization of the code equivalence problem. Our approach is also OS-independent, enabling broader DSE.
An untimed abstract model of an RTOS is presented in Honda et al. [9]. The model supports all the services of the µITRON standard; therefore, it can be used with a wide range of applications, but this work is applied only to uniprocessor systems.
Similar goals are pursued in Posadas et al. [6] by mapping OS thread management primitives to SystemC. However, because of limitations in the SystemC process model, true concurrency cannot be achieved. Girodias et al. [10] also address the lack of support for embedded software development by working in the .NET environment and by mapping hardware tasks to eSys.net processes and software tasks to an abstract OS interface mapped onto .NET threads. A further refinement step allows the mapping of software tasks on a Win32 port of the chosen target OS.
All these approaches help the designer to perform and refine the HW/SW partition, but they do not help in the validation of the high-level design (for the code equivalence problem) and they are limited in the assessment of the system’s timing properties. However, the execution on an ISS of the exact same software that will be deployed on the embedded system is seldom possible because the RTOS has to be already chosen and ported to the target hardware, meaning that it may be difficult or even impossible to refine the HW/SW partitioning (since the OS should be updated accordingly) and to explore alternative system configurations.
This chapter proposes a way to emulate RTOS primitives to minimize code equivalence issues while still maintaining both independence from a specific OS and high timing accuracy.
10.3 Proposed Methodology
For the implementation and evaluation of the design methodology presented in this study, we use the open source simulation platform ReSP [11]. ReSP is based on the SystemC library and it targets the modeling of multiprocessor systems. Its most peculiar feature consists in the integration of C++ and Python programming languages; this augments the platform with the concept of reflection [12], allowing full observability and control of every C++ or SystemC element (variable, method, etc.) specified in any component model. In this work, we exploit and extend ReSP’s system call emulation subsystem to support the analysis of real-time systems and applications. The presented functionalities are used for preliminary exploration of the applications’ behavior for guiding the designer in the choice of the target RTOS and as a support for early HW/SW codesign.
10.3.1 System Call Emulation
System call emulation is a technique enabling the execution of application programs on an ISS without the necessity to simulate a complete OS. The low-level calls made by the application to the OS routines (system calls, SC) are identified and intercepted by the ISS and then redirected to the host environment, which takes care of their actual execution. Suppose, for example, that the simulated application program contains a call to the open routine to open file “filename.” Such a call is identified by the ISS and routed to the host OS, which actually opens “filename” on the filesystem of the host. The file handle is then passed back to the simulated environment. A simulation framework with system call emulation capabilities allows the application developers to start working as early as possible, even before a definitive choice about the target OS is performed. This can also help in the selection, customization, configuration, and validation of the OS itself. Figure 10.1 shows an overview of ReSP’s system call emulation mechanism. Here, each ISS communicates with one centralized trap emulator (TE), the component responsible for forwarding SCs from the simulated environment to the host. To ensure independence between the ISS and the TE, interfaces (IF-1,IF-2, etc.) are created and communication between the TE and the ISS exclusively takes place through them.
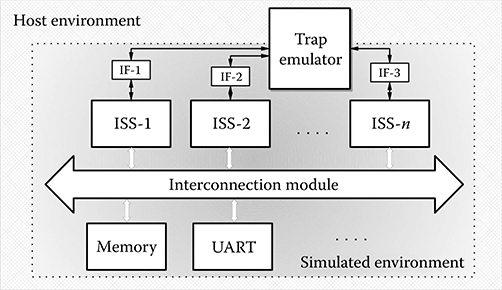
FIGURE 10.1 Organization of the simulated environment including system call emulation.
Figure 10.2 shows the system call emulation mechanism where each ISS communicates with the centralized TE, the component responsible for forwarding the system calls from the simulated to the host environment.
Instead of identifying the SCs through particular assembly instructions or special addresses (as in most simulator environments), we use the name (i.e., the symbol) of the corresponding routine. When the application program is loaded, the names of the low-level SCs (e.g., sbrk, _open, etc.) are associated with their addresses in the binary file and registered with the TE. At runtime, the ISS then checks for those addresses, and when one is found, the corresponding SC is emulated on the host environment.
The TE provides the emulation of concurrency management routines with an additional unit, called a concurrency manager (CM), where the TE intercepts calls for thread creation, destruction, synchronization etc. For this purpose, we created a placeholder library containing all the symbols (i.e., the function identifiers) of the POSIX-Thread standard, but without a corresponding implementation. This ensures that programs using the pthread library can correctly compile. During execution, all calls to pthread routines are trapped and forwarded to the CM. If the application software is compiled with a recent GNU GCC compiler (at least version 4.2), it is also possible to successfully emulate OpenMP directives. The CM is able to manage shared memory platforms with an arbitrary number of symmetric processors.
In addition to system call emulation, these functionalities can be used, through the CM, for the emulation of concurrency management (thread creation, destruction, mutex lock, unlock, etc.) routines. With respect to previous work, these mechanisms demonstrate the following advantages:
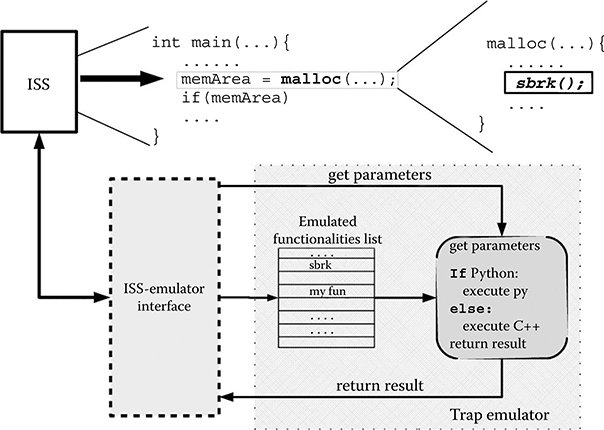
FIGURE 10.2 Internal structure and working mechanisms of the function trap emulator.
Independence from the cross-compiler toolchain: since the names of the system call routines are used, it is not necessary to adhere to the conventions with which the software is built or to create fictitious jumps in the code.
High interoperability with different ISS types: the IF is the only component that requires customization to allow a new ISS to be integrated with the TE.
Extensibility: the presented mechanism can also be used for preliminary HW/SW partitioning. Moreover, by emulating the POSIX-Threads routines, multithreaded applications can be easily simulated.
Since only the low-level SCs (e.g., sbrk) are emulated and the rest of the OS code (e.g., malloc) is executed unmodified in the ISS, our method maintains high code equivalence with the final software, even at the assembly level.
Communication between the emulator and the ISS is a critical point in the overall design. On the one hand, it must be designed to be flexible and portable so that ISSs can be easily plugged into the system. On the other hand, it must be as fast as possible to guarantee high simulation speed. These are conflicting requirements and a proper trade-off must be determined. Two solutions were identified: the first is purely based on compiled C++, while the second, more flexible, one uses Python to unintrusively access the ISS internal variables.
To guarantee the timing accuracy of each input/output (I/O)-related SC (such as the write operation), which would generate traffic on the communication medium, we assume the SC is executed inside the processor, modeling only the data transfer from processor to memory and vice-versa. While this is only an approximation of an actual system, accuracy is not severely affected as shown by our experiments.
10.3.2 Pthreads as a Real-Time Concurrency Model
Pthreads are a well known concurrent application programming interface (API) and, as part of the POSIX standard, are available for most operating systems (either natively or as a compatibility layer). The Pthread API provides extensions for managing real-time threads, in the form of two scheduling classes:
FIFO: threads of equal priority are scheduled following a first-come first-served policy; if a thread of high priority is created while one of lower priority is running, the running thread is preempted.
Round-robin: same scheduling policy of FIFO, with the difference that the processor is shared, in a round robin fashion, among threads of equal priority.
To manage these functionalities, Pthreads provide routines for setting/ reading/ changing thread priorities and scheduling policies. However, even when using the POSIX-Threads RT extension, the standard does not fully allow the management of RT systems. Important features, such as task scheduling based on deadlines, are not present and this prevents an effective modeling and analysis of a wide range of RT systems. For this reason, our emulation layers extend the POSIX-Thread standard with the introduction of the earliest deadline first (EDF) [13] scheduling policy and with the possibility of declaring a task as unpreemptible. Theoretical results [14] expose that EDF scheduling brings better performance with respect to standard priority-based scheduling. In our implementation, the emulated RT features are compatible with the popular OS RTEMS task management policies.
This work enables the exploration, tuning, and analysis of RT systems. To effectively and efficiently perform such activities, we must be able to explore the task scheduling policies, their priorities, and in general, task attributes. As modifying the source code is not suitable for fast coexploration, thread attributes and scheduling policies can be specified also outside the simulation space, using ReSP capabilities. Figure 10.3 shows how ReSP can be used to tune a given system using an optimization loop: attributes are set, the system is simulated, the simulation results can be used to change the system parameters, and so on. The designer has two possible alternatives: (1) specifying the desired RT behavior directly in the application source code or (2) via Python scripting. The first mechanism is simply obtained by emulation of all threading-related primitives. In particular, the calls made by the application software to the functions for managing thread attributes are redirected to the CM, which takes care of managing and scheduling the tasks according to such attributes. The second method consists of using Python to directly export the internal structure of the CM to ReSP. As such, it is possible, either before or during the simulation, to modify the CM status and change the thread management policies without modifications to the application source code. In both cases, the system load and RT behavior can be modified during simulation, enabling an effective exploration of the system’s real-time behavior.
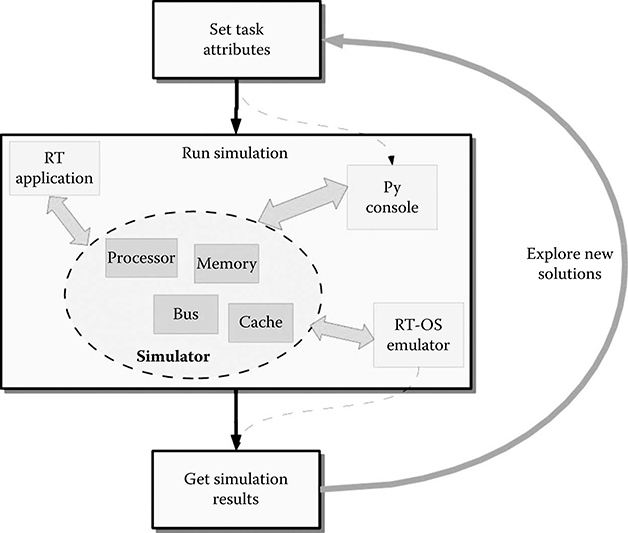
FIGURE 10.3 Exploration flow of real-time policies. Note how task attributes are modified at runtime through the Python console.
10.3.3 Real-Time Concurrency Manager
As mentioned in Section 10.3.1, the TE provides the emulation of concurrency management routines with an additional unit, the CM. The overall mechanism is analogous to the one depicted in Figure 10.2, but instead of trapping I/O or memory management, the TE traps routines for thread creation, destruction, synchronization, etc. During execution, all calls to pthread routines are trapped and forwarded to the CM in the simulator environment. If the application software is compiled with a recent GNU GCC compiler (at least version 4.2), it is also possible to successfully emulate OpenMP directives.
This CM was augmented to deal with real-time extensions and to correctly keep statistics about issues such as missed deadlines, serviced interrupts, etc. In particular, the following features were added:
Context Switch Capabilities. To execute different threads on the same processor, context switch capabilities are necessary because a processor can switch between two threads either when the current thread is blocked (e.g., for synchronization) or when the time quantum associated with the current thread expires. Switching context consists of saving all the ISS registers and restoring the registers for the next thread, much like what would happen when using a nonemulated OS, with the only difference that registers are not saved on the stack in memory, but in the simulator’s space.
Real-Time Scheduler. We implemented the real-time scheduler in three different versions: FIFO, Round-Robin, and EDF. Each task can be assigned a scheduling policy and tasks with different policies can coexist in the system. Figure 10.4 shows how the scheduler is implemented inside the CM and communicates with the rest of the system through the TE. Each task, according to the selected policy, is inserted in a specific queue. Policies of tasks can be varied at runtime either from the application code or by directly interacting with ReSP through the Python console. The latter mechanism has been implemented to enable flexible task management, thus allowing an effective and efficient exploration of the different scheduling policies and priorities and the different RTOS configurations. Tasks with the EDF policy are assigned the highest priority. The scheduler is able to manage shared memory platforms with an arbitrary number of symmetric processors. Since scheduling and, in general, task management operations are performed in the host environment, it is possible to add features such as deadlock and race-condition detection without altering the system behavior. Because of this, our system can also be successfully employed for verification of system correctness. In contrast, if such features as deadlock and race-condition detection were implemented in the simulated software, system behavior would be affected and disallow the verification.
Interrupt Management. The interrupt management is composed of an emulated interrupt generator and an interrupt service routine (ISR) manager. While the former is present only to emulate external events and to force execution of ISRs (to enable the analysis of the system behavior under different practical environmental conditions), the latter feature is used to deal with ISRs, no matter how they are triggered. No major modifications were necessary to the system to control ISRs since, after creation, they are treated as standard real-time tasks.
Python Integration. This feature enables task control from outside of the simulated application. This means that from ReSP’s interactive shell it is possible to manage task priorities, deadlines, etc. As such, it is not necessary to modify the simulated software to perform an effective exploration and to analyze the effects of different scheduling policies and/or priorities.
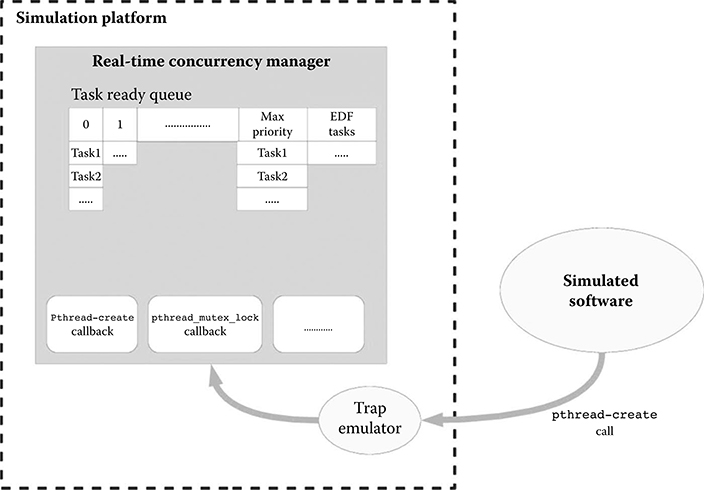
FIGURE 10.4 Detailed structure of the real-time concurrency manager (CM). The CM communicates with the simulated application through the trap emulator. In the CM, RT tasks are organized in queues of different priorities.
10.3.4 Interrupt Management
Reactivity to external events is a fundamental feature in embedded systems, expecially for what concerns real-time applications; most of the time such systems have to react in a timely and predictable manner to inputs coming from the outside world. The interrupt management system implemented in ReSP’s CM has two operating modes: interrrupts can either be triggered by simulated peripheral components described in SystemC (thus mimicking the actual system behavior) or they can be artificially raised by the CM, to ease the analysis of the systems’ real-time behavior under particular stress conditions. The latter mechanism is particularly useful to quickly emulate, explore, and analyze the behavior in different environmental conditions.
In both ways ISRs are managed by the CM and they are treated like normal tasks, meaning that any function can be defined as an ISR. As such, custom priorities, scheduling policies, etc. can be associated to these routines as explained above for standard tasks. Parameters such as generation frequency, temporal distribution, interrupt type, etc. can be easily set and changed even at runtime using ReSP reflective capabilities, thus allowing an effective exploration of the configuration alternatives and a simple emulation of the possible environmental conditions.
10.4 Experimental Results
The methodology has been tested on a large set of OpenMP-based benchmarks (namely the OMPScr suite) and a large parallel application, namely ffmpeg (video encoding/decoding).
The basic assumption of this work is that the system is subject to a mixed application workload: a computationally intensive element with soft real-time constraints and a set of elements with very strict hard real-time characteristics, here called computational and real-time parts, respectively. The number and parameters of both the computational and real-time parts varies and strictly depends on the system being considered. This model well represents applications such as observation spacecraft payload, where massive data processing is required with high availability, while response to external stimuli within a given time is paramount (e.g., for the spacecraft’s navigation system).
The purpose of our methodology is to answer a set of key questions during the development of real-time applications running on an MPSoC:
What is the performance of the real-time applications? Is the system missing any deadlines with the current hardware and scheduling setup?
What is the performance of the computational part? Is it performing within requirements?
How much performance can the current hardware and software setup deliver? Is it possible to add additional computational or real-time tasks without affecting global performance? Can we reduce the number of hardware resources? What is the benefit of moving parts of the application or OS to hardware?
All tests have been executed using ReSP on a multi-ARM architecture consisting of a variable number of cores with caches, and a shared memory, all interconnected by a shared bus. Simulations where timing was recorded were run on a Core 2 Duo 2.66GHz Linux machine.
To evaluate the performance and accuracy of OS emulation with respect to a real OS, twelve OmpSCR benchmarks were run with the real-time operating system eCos [15], using a 4-core platform. A large set of eCos system calls were measured running six of these benchmarks as a training or calibration set, and the average latency of each class of system calls was determined. The Lilliefors/Van Soest test of normality [16] applied to the residuals of each class shows evidence of nonnormality (L = 0.30 and Lcritical = 0.28 with α = .01), but given that the population variability remains limited (with a within-group mean square MSS(A) = 7602 clock cycles), it can be assumed that each average latency is representative of its class.
The derived latencies were introduced for each system call in our OS emulation system, and the remaining six benchmarks (used as a validation set) were executed. Since profiling did not include all functions used by the OS and for which the latency was considered zero, the overall results were uniformly biased for underestimation. This bias can be easily corrected considering the average error, leading to an average error of 6.6 ± 5.5%, as shown in Figure 10.5. Even with this simple scheme, the methodology can very well emulate the behavior of a specific OS with minimal error, especially considering that full code equivalence is present for the application and library functions, but threading, multiprocessor management, and low-level OS functions are emulated.
In addition, the use of the OS emulation layer introduces a noticeable speedup (13.12 ± 6.7 times) when compared to running the OS on each ISS. This is because of several factors, including the absence of some hardware components such as debugging UARTs and timers (the TE implements a terminal in the host OS and the configuration manager uses SystemC and its events to keep track of time), and the fact that, in our mechanism, idle processors do not execute busy loops but they are, instead, suspended. The latter is implemented by trapping the busy loop wait function in the TE and redirecting it to a SystemC wait() call.
Using the proposed methodology, a designer can verify the real-time performance of a multiprocessor system under load and explore the use of different interrupt distribution and handling schemes. As proof-of-concept, we ran the benchmarks as computationally intensive applications, while the real-time tasks are implemented by synthetic functions, with varying deadlines. These functions can be categorized as (1) housekeeping (scheduled regularly, perform sanity checks, repetitive tasks, etc.) and (2) response to external events (when an alarm is fired, its response is usually required within a given deadline).
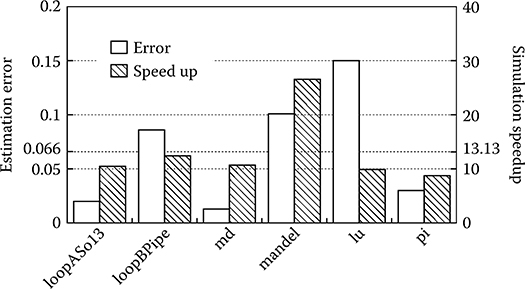
FIGURE 10.5 Simulation speedup and estimation error using the emulation layer instead of eCos.
A first analysis that is performed with the current methodology is to run the real-time part separately from the computational part, reducing all OS-related latencies (such as the latency of the mutex lock operation) to zero. The obtained concurrency profile shows the number of active PEs in time, that is, the effective utilization of the system resources. A similar graph is derived for the computational part, allowing the designer to determine if sufficient resources are available to run the application within its performance constraints. Finally, the computational and real-time parts are combined together and the concurrency profile is drawn as shown in Figure 10.6. This graph helps the designer tweak the hardware and software to match the desired requirements. As an example, the combination diagram (Figure 10.6b) can show a lower-than-expected utilization in case access to a shared bus represents a bottleneck in the system. If, instead, utilization is already at a maximum, the designer can conclude that more processing elements are necessary to reach the performance requirements. Simulating the system with realistic OS-related latencies (that can be targeted to any possible OS choice) leads to determining the best OS choice for the current application.
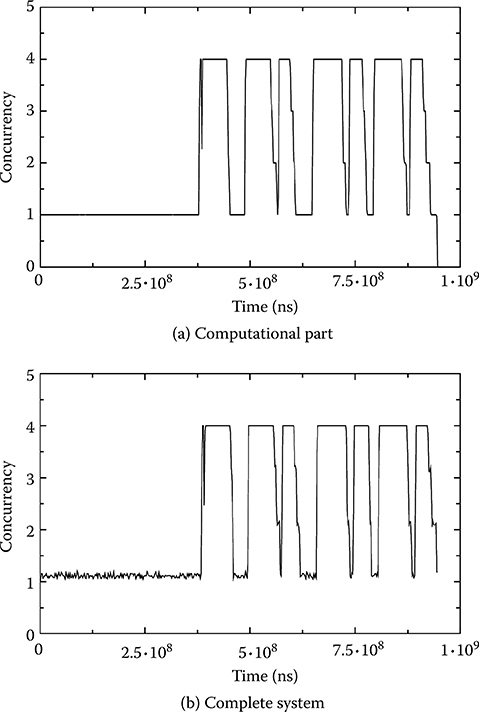
FIGURE 10.6 The concurrency profiles of the ffmpeg benchmark, showing the computational parts (a) and the combination of the computational and real-time parts (b).
Figure 10.7 shows how the methodology is used to determine the best scheduler for the system where the performance is graphed for two schedulers (Priority and EDF).
Running the application with and without RT tasks shows the different computational performance of the system, as depicted in Figure 10.8. As in our methodology, the RT or non-RT status of a task can be changed without modifications to the code, and this evaluation is simply made with two runs of the simulator. The designer can see how changes in the OS scheduling affect the performance of the system.
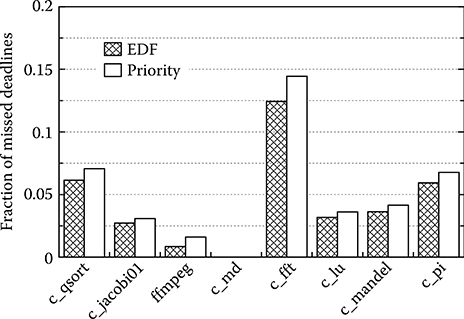
FIGURE 10.7 Fraction of missed deadlines with different schedulers and high real-time workload (1 kHz).
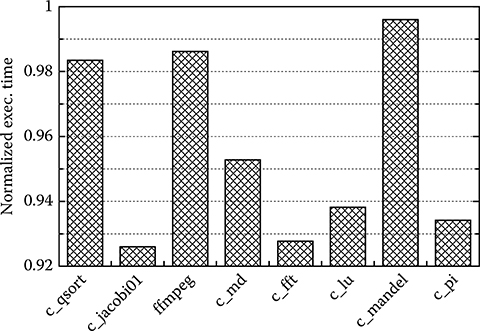
FIGURE 10.8 The performance impact of the real-time (RT) part on the computational part, that is, their relative execution time when compared to execution without the RT part.
10.5 Concluding Remarks
In this chapter we presented an innovative mechanism for RTOS emulation inside ISS. In addition to being nonintrusive in the ISS source code, the described techniques are extended for the emulation of real-time tasks. High code equivalence is maintained, enabling fast and accurate simulation of real-time applications. This powerful RTOS emulation mechanism allows the early DSE of the RTOS and its configuration. In particular, it helps the designer determine the best OS parameters (such as scheduling mechanism, tick frequency, etc.) and allows the early evaluation of important performace metrics (e.g., missed deadline count and interrupt response time). Our methodology has been applied to many mixed-workload (real-time and non-real-time) applications and benchmarks, showing how it can be used to analyze their real-time behavior and how the system can be parametrized to obtain the desired performance for both the real-time and non-real-time parts.
References
1. Yoo, S., G. Nicolescu, L. Gauthier, and A. A. Jerraya. 2002. “Automatic Generation of Fast Timed Simulation Models for Operating Systems in SoC design.” In Proceedings of the Conference on Design, Automation and Test in Europe (DATE ’02), pp. 620–627. IEEE Computer Society, Washington, DC.
2. Wolf. W., 2003. “A Decade of Hardware/Software Codesign.” Computer 36(4): 38–43.
3. Moigne, R. L., O. Pasquier, and J. Calvez. 2004. “A Generic RTOS Model for Real-Time Systems Simulation with SystemC.” In Proceedings of the Conference on Design, Automation and Test in Europe, Volume 3 (DATE ’04), Vol. 3, pp. 82–87. IEEE Computer Society, Washington, DC.
4. Huck, E., B. Miramond, and F. Verdier. 2007. “A Modular SystemC RTOS Model for Embedded Services Exploration.” In First European Workshop on Design and Architectures for Signal and Image Processing (DASIP), ECSI, Grenoble, France.
5. Gerstlauer, A., H. Yu, and D. Gajski. 2003. “RTOS Modeling for System Level Design.” In Proceedings of the Conference on Design, Automation and Test in Europe (DATE ’04), pp. 130–135. IEEE Computer Society, Washington, DC.
6. Posadas, H., J. Adamez, P. Sanchez, E. Villar, and F. Blasco. 2006. “POSIX Modeling in SystemC.” In ASP-DAC ’06: Proceedings of the 2006 Asia and South Pacific Design Automation Conference, pp. 485–90. Yokohama, Japan: IEEE Press.
7. Schirner, G., and R. Domer. 2008. “Introducing Preemptive Scheduling in Abstract RTOS Models Using Result Oriented Modeling.” In Proceedings of the Conference on Design, Automation and Test in Europe (DATE ’08). ACM, New York.
8. He, Z., A. Mok, and C. Peng. 2005. “Timed RTOS Modeling for Embedded System Design.” In Proceedings of the Real Time and Embedded Technology and Applications Symposium 448–457. IEEE Computer Society, Washington, DC.
9. Honda, S., T. Wakabayashi, H. Tomiyama, and H. Takada. 2004. “RTOS-Centric Hardware/Software Cosimulator for Embedded System Design.” In CODES+ISSS ’04: Proceedings of the 2nd IEEE/ACM/IFIP International Conference on Hardware/ Software Codesign and System Synthesis, pp 158–163. IEEE Computer Society, Washington, DC.
10. Girodias, B., E. M. Aboulhamid, and G. Nicolescu. 2006. “A Platform for Refinement of OS Services for Embedded Systems.” In DELTA ’06: Proceedings of the Third IEEE International Workshop on Electronic Design, Test and Applications, pp. 227–236. IEEE Computer Society, Washington, DC.
11. Beltrame, G., L. Fossati, and D. Sciuto. 2009. “ReSP: A Nonintrusive Transaction-Level Reflective MPSoC Simulation Platform for Design Space Exploration.” Computer-Aided Design of Integrated Circuits and Systems, IEEE Transactions on 28(12): 1857–69.
12. Foote, B. and R. E. Johnson. 1989. “Reflective Facilities in Smalltalk-80.” Proceedings OOPSLA ’89, ACM SIGPLAN Notices 24: 327–35.
13. Kargahi, M. and A. Movaghar. 2005. “Non-Preemptive Earliest-Deadline-First Scheduling Policy: A Performance Study.” In MASCOTS ’05: Proceedings of the 13th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, pp. 201–10. IEEE Computer Society, Washington, DC.
14. Buttazzo, G. C. 2005. “Rate Monotonic vs. EDF: Judgment Day.” Real-Time Systems 29(1): 5–26.
15. eCos operating system. http://ecos.sourceware.org/.
16. Lilliefors, H. 1967. “On the Kolmogorov-Smirnov Test for Normality with Mean and Variance Unknown.” Journal of the American Statistical Association. Vol. 62, No. 318 (Jun., 1967), pp. 399–402.