
Chapter 6. Join Views I: One to One Joins
This phrase I have coined
For views to be joined—
Updating through V
Updates A, also B
—
I’d like to begin this chapter by repeating something I said at the end of Chapter 3:
The topic of view updating can unfortunately be quite confusing, even when it’s not particularly controversial. Part of the difficulty lies in the fact that there’s unavoidably a lot of detail to wade through, and it’s easy to lose one’s way in debates and discussions. In particular, it’s all too easy to forget, especially in examples, which relvars are base ones and which ones are views. It’s important to keep a clear head!
I repeat these remarks here because I think it’s only fair to warn you that they seem to be especially applicable in the case of join views in particular.
Given the foregoing, I thought it might be helpful to give some idea right at the outset of where we’re going to wind up in our investigations into this topic. Our target, of course, is a set of rules for updating through join. And what I claim we’re going to finish up with is a set of rules—a single, uniform set of rules—that work for all joins.[81] In particular, it’s not going to make any difference whether the join we’re dealing with is one to one, one to many, or many to many. In fact, let me immediately show in outline what the rules in question look like. Assume we’re trying to update a view V defined as A JOIN B. Then the rules can be stated as follows:
ON INSERT INTOV: INSERTA(sub)tuples if they don't already exist, INSERTB(sub)tuples if they don't already exist ON DELETE FROMV: DELETEA(sub)tuples if they don't exist elsewhere, DELETEB(sub)tuples if they don't exist elsewhere
Of course, the rules as just stated are loose in the extreme; nevertheless, I think this rough and ready formulation should help you hang on to the big picture as we struggle through all of the detailed discussions to follow in this chapter and the next two.
Example 1: Information Equivalence
Because join is so important, and because there are so many issues we need to discuss in connection with it, I’ve decided to split my treatment of the topic into three separate chapters. In this first one, I want to limit my attention to what might be regarded as the simplest possible case: viz., the case in which the join in question is a one to one join specifically. As usual, I’ll base my discussions on some simple examples.
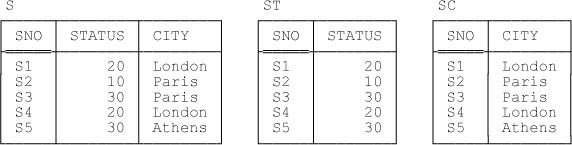
My first example is effectively the inverse of the first of the projection examples from the previous chapter. (As noted in that chapter, there’s a tight connection between join views and projection views in general.) To be specific, suppose we’re given base relvars ST and SC, looking like this (in outline):
ST { SNO , STATUS } KEY { SNO }
SC { SNO , CITY } KEY { SNO }(As in Chapter 5, I ignore attribute SNAME for simplicity.) Now suppose we define the join of these two relvars, ST JOIN SC, as a view S:
S { SNO , STATUS , CITY } KEY { SNO }Further, let’s assume this join is strictly one to one, in the sense that every tuple in ST joins to exactly one tuple in SC and vice versa. In other words, we have information equivalence—the design consisting of ST and SC taken together and the design consisting of just view S are clearly information equivalent. Sample values are shown in Figure 6-1 (of course, that figure is identical to Figure 5-1 in Chapter 5, but now ST and SC are base relvars and S is a view).
Here’s the predicate for the join (of course, it’s basically the usual predicate for relvar S, but simplified to take account of the fact that we’ve dropped attribute SNAME):
| S: Supplier SNO is under contract, has status STATUS, and is located in city CITY. |
As usual, the first thing to do is consider what happens if all three relvars are base ones. But we’ve already done that, in the discussion of Example 1 in Chapter 5! So let me just repeat here the salient points from that discussion. First, as already indicated, each of the three relvars has {SNO} as its sole key. The following constraints also hold (as noted in Chapter 5, they’re all equality dependencies (EQDs), and together they ensure that the two designs are, as I’ve already said, information equivalent):
CONSTRAINT ... S = JOIN { ST , SC } ;
CONSTRAINT ... ST = S { SNO , STATUS } ;
CONSTRAINT ... SC = S { SNO , CITY } ;
CONSTRAINT ... IDENTICAL { S { SNO } , ST { SNO } , SC { SNO } } ;Actually, if you check, you’ll see I gave these constraints in a different order in the previous chapter. I’ve reordered them here to show that, first, S is indeed equal to the join of the other two relvars; next—in order to guarantee the desired information equivalence—ST and SC are indeed equal to the corresponding projections of S; and finally, every supplier number appearing in S also appears in both ST and SC and vice versa. Note: In fact, of course, this final constraint is a logical consequence of certain of the other three constraints taken together (which ones, exactly?).
The compensatory actions are the same as before, too, though again I’ve changed the sequence:
ON DELETEdtFROM ST , DELETEdcFROM SC , INSERTitINTO ST , INSERTicINTO SC : WITH (t1:=itJOIN SC ,t2:=icJOIN ST ,t3:= S MATCHINGdt,t4:= S MATCHINGdc) : INSERTt1INTO S , INSERTt2INTO S , DELETEt3FROM S , DELETEt4FROM S ; ON DELETEdFROM S , INSERTiINTO S : DELETEd{ SNO , STATUS } FROM ST , DELETEd{ SNO , CITY } FROM SC , INSERTi{ SNO , STATUS } INTO ST , INSERTi{ SNO , CITY } INTO SC ;
Let me remind you also that INSERT and “key UPDATE” operations on ST and SC must be “double updates,” for otherwise they’ll fail on a Golden Rule violation.
Now suppose as we originally did that S is in fact a view, the join of ST and SC. Then:
The fact that S is a view of ST and SC is not sufficient to ensure that the constraints specified by the various CONSTRAINT statements shown above (with the exception of the first one) will be enforced automatically. The compensatory actions aren’t sufficient, either. For example, neither the fact that S is the join of ST and SC, nor the compensatory actions, are sufficient to prevent the insertion of a tuple for supplier S9 into ST without the simultaneous insertion of a tuple for S9 into SC. Thus, the pertinent constraints need to be explicitly stated (and explicitly enforced by the DBMS, of course).
However, the compensatory actions from ST and SC to S will happen automatically, precisely because S is a view; that is, updates on ST and/or SC will automatically be reflected appropriately in S.
The compensatory actions from S to ST and SC—these are the view updating rules as such—will also happen automatically, again precisely because S is a view. That is, updates on S are “really” updates on the underlying relvars ST and/or SC, and so are automatically visible in S, as well as in ST or SC or both.
Also, a user who sees only the join view S can behave in all respects exactly as if that view were a base relvar. Such a user will be aware of the fact that {SNO} is a key (but not of any other constraints, nor of any compensatory actions), and will be aware also of the corresponding predicate:
| S: Supplier SNO is under contract, has status STATUS, and is located in city CITY. |
And, to spell the point out, INSERTs, DELETEs, and explicit UPDATEs on that view S all work exactly as they would if S were a base relvar instead.
Example 2: Information Hiding
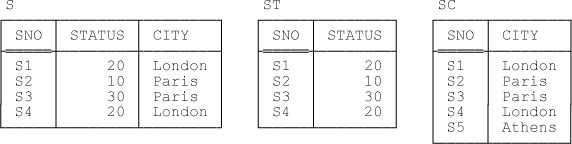
So updating a one to one join view, in the case where we have information equivalence, is essentially straightforward. But what if we’re dealing with an information hiding situation? By way of a concrete example, suppose a supplier can be represented in base relvar ST and not base relvar SC or the other way around; in other words, instead of requiring every supplier to have both a status and a city, as we did in Example 1, suppose now only that every supplier is required to have at least one of those two properties.[82] Then the join S of ST and SC loses information, inasmuch as it’s no longer guaranteed that ST and SC are equal to the projections of that join on the appropriate attributes. In fact, of the constraints mentioned in the previous section, the only ones that continue to hold are the usual key constraints ({SNO} is a key for each of S, ST, and SC), together with this one:[83]
CONSTRAINT ... S = JOIN { ST , SC } ;Sample values satisfying the foregoing conditions can be obtained by modifying Figure 6-1 to remove the tuple for supplier S5 from each of relvars S and ST but not from relvar SC (see Figure 6-2). Of course, the predicate for S is still as it was for Example 1.
A remark on terminology: The title of this chapter implies, or at least strongly suggests, that ST JOIN SC is still a one to one join, but of course it isn’t—not really. The truth is, the term “one to one” is often used somewhat loosely to include both (a) what might be called the strict case, as in Example 1 in the previous section, and (b) cases like the one currently under discussion, in which it’s possible for one participant (in whatever relationship it is that we happen to be talking about) to have an element with no counterpart in the other. Here’s a lightly edited quote from The Relational Database Dictionary, Extended Edition (Apress, 2008):
A one to one correspondence is, strictly, a rule pairing two sets s1 and s2 (not necessarily distinct) such that each element of s1 corresponds to exactly one element of s2 and each element of s2 corresponds to exactly one element of s1. However, the term is often used somewhat loosely to mean a pairing such that (a) each element of s1 corresponds to at most one element of s2 and each element of s2 corresponds to exactly one element of s1, or (b) each element of s1 corresponds to exactly one element of s2 and each element of s2 corresponds to at most one element of s1, or (c) each element of s1 corresponds to at most one element of s2 and each element of s2 corresponds to at most one element of s1. The term is probably best avoided unless the intended meaning is clear.
The final sentence here notwithstanding, I will in fact be using the term quite a lot in what follows, because I think my intended meaning will always be clear from the context. End of remark.
Back to Example 2. Let me now stress the fact that, precisely because the join view S loses information, a database containing just that view isn’t information equivalent to one containing base relvars ST and SC. (An example of a query on the latter that has no counterpart on the former is “Get supplier numbers for suppliers who have a city but no status.”) More precisely, any information that can be represented by S alone can certainly be represented by the combination of ST and SC, but the converse is false. As a consequence, it’s obvious that there’ll be updates on ST and/or SC that have no counterpart on S. An example is “Insert a tuple into SC for a supplier with supplier number S9 and city London,” without simultaneously inserting a tuple for that same supplier S9 into ST.
So what compensatory actions apply? Well, since there’s no longer a strict one to one relationship between relvars ST and SC, it’s now possible as just indicated to insert into, or delete from, just one of the two without simultaneously inserting into or deleting from the other. Thus, since S is required to be at all times equal to the join of ST and SC, we clearly have:
ON INSERTitINTO ST , INSERTicINTO SC : INSERT (itJOIN SC ) INTO S , INSERT (icJOIN ST ) INTO S ; ON DELETEdtFROM ST , DELETEdcFROM SC : DELETE ( S MATCHINGdt) FROM S , DELETE ( S MATCHINGdc) FROM S ;
Now, I’ve shown these rules separately for reasons of clarity, but of course they can be combined into one:
ON DELETEdtFROM ST , DELETEdcFROM SC , INSERTitINTO ST , INSERTicINTO SC : DELETE ( S MATCHINGdt) FROM S , DELETE ( S MATCHINGdc) FROM S , INSERT (itJOIN SC ) INTO S , INSERT (icJOIN ST ) INTO S ;
And if you compare this rule with the corresponding rule for Example 1 from the previous section—the strict one to one case—you’ll see it’s essentially identical (except that I used some introduced names in that previous section, for clarity). Here in order to make it easier to do the comparison is that previous rule:
ON DELETEdtFROM ST , DELETEdcFROM SC , INSERTitINTO ST , INSERTicINTO SC : WITH (t1:=itJOIN SC ,t2:=icJOIN ST ,t3:= S MATCHINGdt,t4:= S MATCHINGdc) : INSERTt1INTO S , INSERTt2INTO S , DELETEt3FROM S , DELETEt4FROM S ;
So much for updates on ST and/or SC. But what about the join view?—i.e., what happens if we do INSERTs or DELETEs on S, instead of on ST and/or SC? In fact INSERTs are reasonably straightforward:
ON INSERTiINTO S : INSERTi{ SNO , STATUS } INTO ST , INSERTi{ SNO , CITY } INTO SC ;
Note that inserting a tuple t into S must cascade to both ST and SC. (It’s true that one of those cascaded INSERTs might in fact be a “no op,” but they can’t both be.)[84] For (a) if S is a view—that’s the case we’re considering—and we were to cascade to (say) just ST, and no matching tuple previously existed in SC, then tuple t would never appear in S and we’d have an Assignment Principle violation on our hands; conversely, (b) if all three relvars were base ones and (again) we cascaded to just ST and no matching tuple previously existed in SC, then S would no longer be equal to ST JOIN SC and we’d have a Golden Rule violation on our hands instead. Indeed, the very fact that these two different scenarios give rise to two different exceptions suggests rather strongly (in accordance with The Principle of Interchangeability) that we need to have appropriate compensatory actions in place in order to hide the difference.
Aside: There’s still an issue here, though. E.g., given the sample values shown in Figure 6-2, an attempt to insert a tuple into S for supplier S5 will violate the key constraint on SC if the city in that new tuple is anything other than Athens. But a user who sees only the join view S doesn’t know about relvar SC. At the same time, we surely don’t want to prohibit INSERTs on S entirely. Maybe this is a case where an operation has to be rejected simply “because the system says so,” without further explanation (?). Similar remarks apply to (say) an attempt to change the supplier number in S for supplier S1 to S5. End of aside.
Observe now that the foregoing rule for INSERTs on S is identical to the corresponding rule for Example 1 from the previous section (the strict one to one case). Observe further that—as suggested in the introduction to this chapter—that rule can be loosely characterized as follows: “On inserting tuple t into A JOIN B, insert the A portion of t into A unless it already exists there, and insert the B portion of t into B unless it already exists there.” Note: Of course, by the A portion of t, what I really mean is that subtuple of t that’s the (tuple) projection of t on the attributes of A (and similarly for the B portion of t). And by it already exists there (where “it” refers to either the A portion or the B portion of t), I mean there’s already a tuple in the pertinent relvar (A or B) that’s equal to the pertinent subtuple.
So much for INSERTs on S. What about DELETEs? Well, first let me reiterate that we’re talking here about the case in which a constraint to the effect that ST{SNO} = SC{SNO} has not been stated. Of course, the fact that such a constraint hasn’t been stated doesn’t mean it isn’t supposed to hold!—it might or it might not (be supposed to hold, that is). To put the point another way, the fact that the DBMS doesn’t know the constraint is supposed to hold doesn’t mean it knows it isn’t (if you follow me).[85] So the question becomes: What should the DBMS do—(a) assume the constraint holds anyway, or (b) assume it doesn’t? (Of course, it goes without saying that it does have to operate on the basis of one or other of these two assumptions.) Now, if the DBMS operates under assumption (a), it will do its best to ensure that suppliers are represented in both ST and SC (if they’re represented at all, that is), even though a supplier not so represented won’t cause a violation of The Golden Rule. (It won’t cause a violation of The Golden Rule precisely because the constraint hasn’t been stated.) In fact, if the DBMS does operate under assumption (a), the updating rules—the delete rules in particular—become exactly the same as those for the strict one to one case, and that’s the end of the discussion. So what happens if it operates under assumption (b)?
Before I try to answer that question, let me just state for the record that assumption (b) doesn’t correspond to a constraint—it corresponds to the absence of a constraint. I mean, I hope it’s obvious that there’s no formal CONSTRAINT statement we can write that says it’s legal for some supplier number to appear in ST and not SC or the other way around. (I mention this point because in fact I’ve encountered people who apparently believe the opposite. If you’re such a person yourself, then I suggest you try writing such a CONSTRAINT statement. If you try this exercise, I think it’ll quickly convince you that what I’m saying here is correct—if you weren’t convinced already, that is.)
Be that as it may, let’s take a closer look at assumption (b). Let’s consider a concrete example. Suppose we try to delete the tuple (S1,20,London) from S. Clearly, the DBMS could achieve the desired effect by doing any of the following: 1. deleting the tuple (S1,20) from ST; 2. deleting the tuple (S1,London) from SC; or 3. doing both. In other words, we might consider any of the following as a possible delete rule for S:
Cascade the delete to just ST.
Cascade the delete to just SC.
Cascade the delete to both ST and SC.
Note: There’s a fourth possibility too, of course: Reject the delete entirely, on the grounds that we don’t know which of the other three options to choose. On the grounds that it’s surely desirable in general for user requests to succeed if they sensibly can, however, it seems preferable to accept the delete and let it cascade appropriately—especially since cascading (more specifically, cascading to both ST and SC, option 3) is the logically correct thing to do if assumption (a) is in fact the right one (i.e., if ST{SNO} and SC{SNO} are supposed to be equal after all, even though no constraint to that effect has been explicitly stated).
Now, as I’m sure you’ve realized, we’re dealing with a big issue here. Indeed, what we’re talking about is the classic ambiguity issue (or what some people describe as an ambiguity issue, at any rate). To spell the point out, the fact that there doesn’t seem to be a good way to choose among the various options is exactly what critics complain about; I mean, it’s exactly why some writers believe view updating is, in the general case, impossible. So I want to present arguments in favor of my own position, which is that I think we should go with option 3 (i.e., cascade to both). Before I do that, however, let me just point out that no analogous problem arises in connection with the projection counterpart to the join example under discussion, even though (as I’ve said previously) join views and projection views are two sides of the same coin. The reason is this: If we start with relvar S and replace it by its projections ST and SC, then certainly any information that can be represented by the original design can also be represented by the revised design. But if we start with relvars ST and SC and replace them by their join S, then it’s possible that some information can be represented by the original design and not by the revised design—in which case information equivalence is lost. And it’s only if information equivalence is lost that the ambiguity issue arises.
Pragma
As I’ve said, I’m going to present arguments in favor of the position that we should go with option 3—the position, in other words, that we should treat Example 2 as far as possible just like Example 1. But first let me remind you of something I said in Chapter 3:
Even when we don’t have information equivalence, sometimes it’ll be possible to apply the view updating rules anyway (albeit only partially, perhaps), and I’ll discuss such cases in detail too. But I must stress that updating in such cases can lead to results that, while of course always formally predictable and well defined, might sometimes be undesirable—possibly even unacceptable for some reason). Because of this state of affairs, I leave to others (perhaps the individual user, perhaps the DBA, perhaps even the DBMS) the choice as to whether updates should in fact be allowed in such situations.
The case at hand is a perfect example of the foregoing; to go with option 3 means, precisely, applying the rules that work in the information equivalence case to the case where information is hidden, or lost. In other words, there’s a clear element of pragma involved in my position here.[86] Now, I’m going to do my best to convince you that the pragma in question makes sense—in particular, as the extract from Chapter 3 says, it does at least produce results that are formally predictable and well defined—but, as that extract also makes clear, it’s entirely possible that others will disagree with my position here and so might want to opt out (as it were) of my proposals on this particular issue. I’ll come back and revisit this possibility at the very end of the subsection immediately following. First, however, let me try to explain my own position.
Symmetry
I believe symmetry is a good design principle in general. To quote Polya:
“If a problem is symmetric in some ways we may derive some profit from noticing its interchangeable parts and it often pays to treat those parts which play the same role in the same fashion … Try to treat symmetrically what is symmetrical, and do not destroy wantonly any natural symmetry” (George Polya: How To Solve It, 2nd ed., Princeton University Press, 1971).
“We expect that any symmetry found in the data and condition of the problem will be mirrored by the solution … Symmetry should result from symmetry” (George Polya: Mathematical Discovery: On Understanding, Learning, and Teaching Problem Solving, 2nd ed., John Wiley & Sons, 1981).
Aside: Polya also articulates in this latter book what he calls The Principle of Nonsufficient Reason: “No [solution] should be favored of eligible possibilities among which there is no sufficient reason to choose.” Some might appeal to this principle as a basis for rejecting deletes on join views entirely: at least, join views like the one currently under discussion. To me, however, that position is too extreme; it throws the baby out with the bathwater, as it were. Let me continue to present what I regard as good reasons—well, fairly good reasons, anyway—for not taking such a drastic step but, rather, going with option 3. End of aside.
In my experience, asymmetry often means we’ve got something wrong. At the very least, it can lead to counterintuitive behavior, behavior that can seem capricious and, precisely for that reason, hard to understand, teach, learn, and remember. In the case at hand, an asymmetric solution would mean cascading deletes on S to ST but not SC (option 1) or the other way around (option 2). This arbitrariness has at least two unpleasant consequences. First, it means the DBA, or some other human agency, might to have to get involved in order to choose between the two options (without, I might add, any good guidelines to help in making that choice, in general). Second, it raises the possibility that a view defined as ST JOIN SC and one defined as SC JOIN ST might have different update behavior, a state of affairs that’s surely undesirable. So I think considerations of symmetry alone are sufficient to make options 1 and 2 nonstarters.
I observe further that options 1 and 2 are actually the wrong choice if assumption (a) is in fact the right one. That is, options 1 and 2—and assumption (b)—are a safe way to go only if it’s definitely the case that a supplier can have a status but no city or vice versa. But the DBMS doesn’t and can’t know that such is definitely the case if all it knows is that S = ST JOIN SC. And if assumption (b) is in fact the right one after all, at least option 3 still works, and it produces a predictable result.
So let’s consider option 3. Obviously, that option has the advantage that it avoids the foregoing problems. But there’s another reason why that option is attractive—another appeal to symmetry, in fact—and that is that, under option 3, the delete rule is symmetric with respect to its insert rule counterpart. (We’ve already seen that inserts on S cascade to both ST and SC, so why shouldn’t deletes on S be treated similarly?) In fact, option 3 implies, loosely speaking, that (a) deleting an existing tuple t from S and then inserting it again, and (b) inserting a new tuple t into S and then deleting it again, both preserve the status quo,[87] a state of affairs that seems intuitively both reasonable and desirable.
Aside: I need to elaborate somewhat on the foregoing, however. When I say “preserve the status quo,” I’m referring to the status quo with respect to relvar S (the join view) specifically, and my claim is 100 percent correct. The picture with respect to relvars ST and SC is unfortunately a little more complicated. To spell the matter out: The status quo with respect to those relvars is preserved if (a) an existing tuple is deleted from S and then inserted again, but not necessarily if (b) a new tuple is inserted into S and then deleted again. The reason is that inserting a new tuple into S might actually cause a tuple to be inserted into just one of ST and SC, whereas under option 3 deleting an existing tuple from S will always cause a tuple to be deleted from both.
There’s another (related) issue as well. Suppose we start off with just relvars ST and SC (i.e., without the join view). Let supplier S1 be represented in both ST and SC. Clearly, then, we can delete supplier S1 from relvar ST, say, without that delete cascading to relvar SC. But now suppose we introduce the join view S. Under option 3, then, that delete will now cascade to relvar SC—and it’ll do so, moreover, even if the join view S isn’t visible to the user issuing the delete on ST! I’ll revisit this particular issue, and several similar ones, in Chapters Chapter 9–11, also in Chapter 15. End of aside.
Another argument in favor of option 3 is the following: If we can agree on that option, then we’ll have a single, uniform rule that applies universally to the question of deleting through join, regardless of whether the join in question is one to one, one to many, or many to many. Of course, I haven’t demonstrated this point yet, but I will, over the course of the next two chapters.
So my conclusion is this: I think it’s better for the DBMS to operate under assumption (a), even if the corresponding constraint hasn’t been stated explicitly. In other words, I think the view updating rules given in the previous section for the strict one to one case should be followed even if the join is only known to be one to one in the looser sense of that term. And I point out now that—as suggested in the introduction to this chapter—the option 3 delete rule can be loosely characterized as follows: “On deleting tuple t from A JOIN B, delete the A portion of t from A and the B portion of t from B” (and we could harmlessly add “unless it exists elsewhere in the relvar” to each part of this rule, since we’re talking about a one to one join and the A portion of t simply won’t exist elsewhere in A, nor will the B portion of t exist elsewhere in B).
If we can agree on the foregoing position, then we’ll have agreed on a universal set of rules for updating one to one join views that do at least always work and do guarantee that joins are strictly one to one when they’re supposed to be. What’s more, if those rules do sometimes give rise to consequences that are considered unpalatable for some reason, then there are always certain ad hoc fixes (such as using the DBMS’s authorization subsystem to prohibit certain updates) that can be adopted to avoid those consequences.
Note: Please don’t misunderstand me here. I’m not saying we must employ such fixes in order for the system to work properly. A system that relies for its correct operation on the user, or the DBA, always “doing the right thing”—e.g., using the authorization subsystem appropriately—is obviously not acceptable.[88] So we must always at least permit join view updates, even when the joins aren’t strictly one to one, and we must have a set of rules that work even in that case. That’s why I advocate the position I do.[89]
Concluding Remarks
There are a couple of final points I’d like to make in connection with updating one to one joins. The first is this. In terms of our running example, I’ve considered two possibilities: Every supplier has both a status and a city, or every supplier has at least one of those two properties. But there are at least two further possibilities:
The properties are mutually exclusive (i.e., every supplier has exactly one of them).
One property is mandatory but the other is optional (e.g., every supplier has a city, and some suppliers have a status as well).
A moment’s reflection is sufficient to show that the first of these possibilities isn’t very interesting. The reason is that such a supplier would always be represented in either ST or SC but not both; the join S would therefore always be empty, and deletes on that join would always be a “no op” and inserts on that join would always fail (unless they’re “no ops” as well). As for the second possibility, I suppose it could be argued that this is a case where an option 1 or option 2 delete rule might make sense. Well, maybe; I don’t find the argument very convincing myself; but I suppose I could be persuaded otherwise if it could be shown there was a really strong requirement here. For the time being, however, I propose to stay with my “one size fits all” rule as described earlier in the chapter (which does of course still work, even in the rather special case under discussion here).
My other point has to do with the fact that—as is of course well known—intersection is a special case of one to one join.[90] It follows that the rules for updating through a one to one join apply to intersection as well (more precisely, they reduce to the rules for updating through an intersection, in the special case where the join itself reduces to an intersection). To spell those rules out (albeit in simplified form),[91] let V be defined as A INTERSECT B. Then we have:
ON INSERTiINTOA: INSERT (iINTERSECTB) INTOV; ON INSERTiINTOB: INSERT (iINTERSECTA) INTOV; ON DELETEdFROMA: DELETEdFROMV; ON DELETEdFROMB: DELETEdFROMV; ON INSERTiINTOV: INSERTiINTOA, INSERTiINTOB; ON DELETEdFROMV: DELETEdFROMA, DELETEdFROMB;
Now, I’ll have a lot more to say about intersection as such in Chapter 9, but I wanted to mention it here because it allows me to spell out what earlier in this chapter I referred to as “the classic ambiguity issue” in logical terms. As I’ve said, the rule for deleting through a one to one join, in the case where the term “one to one” is being used only loosely (as in Example 2), does involve a certain degree of pragma. Well, now I can pin down exactly what that pragma consists of. Recall from Chapter 2 that every relvar, and more generally every relational expression, has an associated predicate (in the latter case, the predicate is derived from the predicates for the relvars involved in the expression, in accordance with the semantics of the relational operations involved in that expression). So let the predicates for A and B be PA and PB, respectively; then the predicate for V = A INTERSECT B is PA AND PB. That is, if tuple t appears in V, then PA(t) AND PB(t) is true (implying, of course, that PA(t) and PB(t) are both individually true).[92]
Now suppose we delete t from V. What we mean by that update is that the proposition PA(t) AND PB(t) is now no longer true; in other words, either PA(t) is false OR PB(t) is false (and possibly both). By contrast, deleting t from both A and B means PA(t) is false AND PB(t) is false; in other words, both are false. And so here we have the ambiguity issue in logical terms—namely, the proposed option 3 rule for deleting through a one to one join, in the case where the term “one to one” is being used only loosely, is tantamount to treating logical OR as logical AND.
Note: We might alternatively say that deleting t from V means NOT(PA(t) AND PB(t)) is true while deleting t from both A and B means NOT(PA(t)) AND NOT (PB(t)) is true. But NOT(PA(t)) AND NOT(PB(t)) is equivalent to NOT(PA(t) OR PB(t)), and hence the option 3 delete rule means we’re effectively treating logical AND as logical OR (the other way around, in other words). Of course, it makes no real difference to the objection either way.
I don’t want to explore this issue any further at this juncture; suffice it to say that David McGoveran has a proposal for resolving it, which I’ll describe in Chapter 15.
[81] Some might say “work” should be in quotation marks here. What I mean by my claim is: The rules do at least produce well defined, predictable results in all circumstances. Whether those results are always acceptable is another question! See later for further discussion.
[82] “At least one,” because allowing a supplier to have neither would make no sense—such a supplier wouldn’t appear in either ST or SC and therefore wouldn’t appear in S (= ST JOIN SC) either.
[83] Certain inclusion dependencies (INDs) hold too, but I won’t bother to spell them out in detail.
[84] They would both be if t already existed in S, but recall from Chapter 4 that we don’t need to discuss that case.
[85] In symbols, NOT(knows(p)) doesn’t imply knows(NOT(p)). Or as somebody or other once said: “Absence of evidence isn’t evidence of absence.” Mind you, if a certain constraint is supposed to hold but the DBMS hasn’t been informed of that fact, then the design is certainly incomplete, and errors of various kinds are certain to ensue. But such violations of good design principles aren’t exactly unknown in practice.
[86] Here and elsewhere in this book I choose to overlook the fact that none of the dictionaries I consulted seem to recognize pragma as a legitimate English word.
[87] The same would be true of options 1 and 2, though.
[88] And here is as good a place as any to make the more general point that whatever view updating rules we do adopt, they certainly can’t rely on the database being well designed (e.g., they can’t assume relvars are always properly normalized). In other words, we must allow the database designer the freedom to make a mess of things. Note: That said, I feel bound to say too that much of the complexity (such as it is) that arises with view updating in general arises precisely when the design we’re dealing with is a bad one—in particular, when it’s incomplete, in the sense that it’s incapable of capturing all of the facts about the real world that it ought to be capable of capturing.
[89] The idea that if you don’t like what happens when you do X, then you shouldn’t do X—“If it hurts when you hit yourself over the head with a hammer, then don’t hit yourself over the head with a hammer”—is sometimes referred to as The Groucho Principle. My suggestion here (viz., if you don’t like what happens when you do certain updates, then don’t do those updates) can be seen as an appeal to that principle. Now, I would certainly agree in general that if the only argument you can find in support of some position is an appeal to The Groucho Principle, then that position must be pretty weak. But, of course, I don’t believe in the case at hand that an appeal to The Groucho Principle is the only argument I have to support my position.
[90] Strict or otherwise—though in fact “strict” makes little sense here (why?).
[92] I use the expression PA(t) to denote the proposition obtained by instantiating predicate PA by using attribute values from tuple t as arguments to replace PA’s parameters, and similarly for PB(t).