
Chapter 15. Ambiguity Revisited
Seal up the mouth of outrage for a while,
Till we can clear these ambiguities
—
As mentioned at several points in earlier chapters, David McGoveran has a proposal for resolving the ambiguities that can arise in connection with view updating (in the absence of information equivalence, that is). In this final chapter, I want to say something about that proposal. Before I do, however, there are some points I must make absolutely clear:
To say only that his proposal resolves the ambiguities doesn’t begin to do justice to David’s scheme overall. Rather, that scheme is (of course) a scheme for addressing the database updating issue in its entirety. It begins by recognizing that, as I explained in Chapter 2, the only true variable—the only thing that can really be updated, logically speaking—is the entire database (or dbvar, rather, though it doesn’t use that term). The database, and the relvars within that database, are characterized by predicates; however, those predicates, unlike the ones I’ve been talking about in this book, are completely formal in nature. In particular, they completely subsume what in Chapter 2 I called the total database constraint. Update requests too are expressed in terms of such predicates (they might refer to relvars by name for user convenience, but such references serve merely as shorthand for the pertinent relvar predicates). Implementing an update request then consists in combining the database predicates and update predicates appropriately and computing the relation or relations that together satisfy such combined predicates; those relations then effectively constitute the updated portion of the database.[149] For further details, I refer you to David’s patents, which were cited in the Concluding Remarks section of Chapter 3.
I should also make it clear that David wouldn’t even agree that what I’ve been calling ambiguities are ambiguities anyway. In effect, that is, he believes a disambiguating mechanism along the lines of the one I’ll be presenting in this chapter ought always to be employed. (Of course, if it were, then there would never be any need to appeal to the various pieces of pragma I’ve described in earlier chapters.) In other words, not to use that disambiguating mechanism is simply to underspecify the update request in question—in which case it’s rather hard to say just what an appropriate response should be on the part of the DBMS (all possible responses become equally “correct,” in a sense).
How does the foregoing relate to the approach to updating I’ve been discussing in the present book? Well, I do believe that approach is generally in the spirit of David’s proposal, at least to the extent that I understand that proposal. However, I’ve tried to present the approach in more familiar and more concrete terms—terms that I think make sense in the context of relational systems as generally understood (in other words, relational systems as I’ve tried to describe them in numerous previous books and other writings). I’ve also tried to present the approach in such a way as to make a path to possible implementation in such systems comparatively clear.
Without further ado, let me now explain the “disambiguating mechanism” (or one possible disambiguating mechanism, at any rate)—that is, a concrete scheme for resolving ambiguities that’s based on the more abstract proposals described in David’s patents.
Predicates and Constraints Revisited
I’d like to begin with a quick review of predicates and constraints as I’ve been using those terms in this book. Recall from Chapter 2 that every relvar has an associated relvar predicate, which is, loosely, what the relvar in question means to the user. For example, the predicate for the suppliers relvar S is:
Supplier SNO is under contract, is named SNAME, has status STATUS, and is located in city CITY.
For brevity, let’s refer to this predicate as pred(S); more generally, in fact, let’s refer to the predicate for any given relvar R as pred(R).[150] Then each tuple in R at any given time T is supposed to be such that the attribute values from that tuple, when substituted for the parameters in pred(R), yield a proposition—more specifically, a proposition that’s an instantiation of pred(R)—that we believe to be true at that time T. For example, the fact that the tuple (S1,Smith,20,London) appears in relvar S right now means we believe the following proposition to be true at this time:
Supplier S1 is under contract, is named Smith, has status 20, and is located in city London.
Now, in order to be able to use relvar R in any meaningful way at all, the user must be aware of (and of course understand!) that predicate pred(R). It follows that the “owner” or “creator” of relvar R—or possibly the DBA—must somehow tell anyone who uses that relvar exactly what the corresponding predicate is. What’s more, these remarks are true of virtual relvars (i.e., views) just as much as they are of base ones. For example, the predicate pred(NLS) for view NLS (“non London suppliers”) from earlier chapters is:
Supplier SNO is under contract, is named SNAME, has status STATUS, and is located in city CITY (and CITY is not London).
Every user of view NLS, for whatever purpose, must be aware of and understand this predicate.
Now, as I’ve written elsewhere (in SQL and Relational Theory, for example), in a perfect world the predicate pred(R) would serve as the “criterion for acceptability of updates” on relvar R. But this goal is obviously unachievable as stated. In the case of relvar S, for example:
First of all, the DBMS can’t know what it means for a “supplier” to be “under contract” or to be “located” somewhere; these are matters of interpretation. For example, if the supplier number S1 and the city name London happen to appear together in the same tuple, then the user can interpret that fact to mean supplier S1 is located in London, but there’s no way the DBMS can do anything analogous.
What’s more (and perhaps more important), even if the DBMS could know what it means for a supplier to be under contract or to be located somewhere, it still couldn’t know a priori whether what the user tells it is true. If the user asserts (by means of some update operation) that there’s a supplier S6 named Lopez with status 30 and city Madrid, then there’s no way the DBMS can possibly know whether that assertion is true; all the DBMS can do is check that the assertion in question doesn’t violate any integrity constraints. Assuming it doesn’t, the DBMS will then insert the tuple (S6,Lopez,30,Madrid) into relvar S, and will effectively treat that tuple as representing a true proposition from this point forward.
In other words, the pragmatic criterion for acceptability of updates on a given relvar, in today’s DBMSs, is, as also explained in Chapter 2, not the relvar predicate but rather the pertinent (total) relvar constraint. Thus, the relvar constraint for a given relvar might be regarded—with a rather large dose of wishful thinking—as the DBMS’s approximation to the corresponding relvar predicate.[151] Of course, this state of affairs explains the emphasis on constraints throughout earlier chapters of this book.
An Intersection Example
Now suppose there were a way to tell the DBMS the name of the predicate for any given relvar, so that the DBMS would at least know that, e.g., the predicate for the suppliers relvar S is pred(S). Note: Presumably the DBMS would keep those predicate names along with the relvar definitions in the catalog. Presumably too there would be a way of keeping text versions of those predicates in the catalog as well (for use in error messages and other ergonomic purposes), although this aspect of what I’m discussing here isn’t relevant to the question of view updating as such. Of course, there’s still no suggestion that the DBMS should be able to “understand” those predicates in any sense—that’s not the point at issue.
Suppose further that we could refer to those predicates by name, somehow, in requests to the DBMS. By way of example, consider the following scenario. Imagine we have two relvars, A and B, with predicates pred(A) and pred(B), respectively. To make the example a little more concrete, let A and B be, respectively, relvar PL and relvar PK from Chapters Chapter 9, 10, and 11 (and 14). Just to remind you once again, these relvars both have just a single attribute PNO (part number); relvar PL gives part numbers for parts on sale, and relvar PK gives part numbers for parts in stock. So the predicates pred(PL) and pred(PK)are as follows:
| PL: Part PNO is on sale. |
| PK: Part PNO is in stock. |
Note that these relvars are of the same relation type. Sample values are shown in Figure 15-1, along with sample values for the corresponding intersection, union, and difference relvars XLK, ULK, and DLK, respectively (see further discussion below).
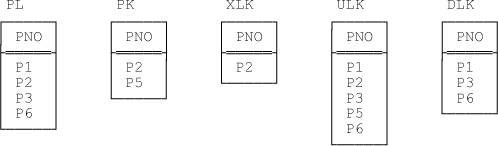
In order to make the discussions that follow a little more user friendly, let me introduce the names ON_SALE and IN_STOCK to be used in place of the slightly more formal names pred(PL) and pred(PK), respectively. (The fact that these names are the same as the attribute names I used in Chapters Chapter 9, Chapter 10 and Chapter 11 in connection with what in those chapters I called “a better design” is of course not a coincidence.) Now let relvars XLK, ULK, and DLK in fact be views, defined as PL INTERSECT PK, PL UNION PK, and PL MINUS PK, respectively (sample values for these views are also shown in Figure 15-1, as I’ve said). Clearly, then, the predicates for all of these relvars are as follows (“formal” or symbolic versions shown in parentheses):
| PL: Part PNO is on sale. (ON_SALE) |
| PK: Part PNO is in stock. (IN_STOCK) |
| XLK: Part PNO is both on sale and in stock. (ON_SALE AND IN_STOCK) |
| ULK: Part PNO is on sale or in stock. (ON_SALE OR IN_STOCK) |
| DLK: Part PNO is on sale and not in stock. (ON_SALE AND NOT IN_STOCK) |
What’s more, given that the DBMS knows ON_SALE and IN_STOCK are the “formal” or symbolic predicates for relvars PL and PK, respectively, it can obviously figure out for itself the corresponding “formal” or symbolic predicates for relvars XLK, ULK, and DLK.
Now as we know from earlier chapters, views like those above can give rise to ambiguity. For example, consider the following update on the intersection view XLK:[152]
DELETE ( XLK WHERE PNO = 'P2' ) FROM XLK ;
According to the rules described in Chapter 9, the effect of this delete will be to cause the tuple for part P2 to be deleted from both PL and PK. But critics can and do object that the desired effect (removing the tuple from XLK) can be achieved by deleting that tuple just from PL or just from PK or from both, and there’s no good reason for choosing any particular one of these options over the others, and so the delete should be rejected.
Now, I suggested in Chapter 9 that such deletes should be accepted anyway, despite the ambiguity—but of course I didn’t mean to suggest by my arguments in that chapter or elsewhere that we shouldn’t look for a way of resolving such ambiguities if we could. So let’s take a closer look.
Consider the user, U say, who issues the foregoing delete on relvar XLK. Suppose for simplicity that XLK is the only relvar user U is aware of—i.e., user U doesn’t even know relvars PL and PK exist. Despite this lack of awareness, user U must nevertheless be aware that the predicate for XLK is of the form ON_SALE AND IN_STOCK, where ON_SALE stands for Part PNO is on sale and IN_STOCK stands for Part PNO is in stock. So if user U wants to delete the tuple for part P2 from XLK, it must necessarily be the case that he or she wants to do so because he or she knows[153] that exactly one of the following three possibilities holds:
Part P2 is now not on sale (but is still in stock).
Part P2 is now not in stock (but is still on sale).
Part P2 is now neither on sale nor in stock.
What’s more, of course, user U must also necessarily know exactly which one of these possibilities is in fact the case—for if not, then he or she has no business updating the database in the first place! Suppose for the sake of the example it’s Possibility 2. Then (to invent some syntax on the fly) the user can and should issue the following delete (note the text in boldface):
DELETE ( XLK WHERE PNO = 'P2' ) PRED ( IN_STOCK ) FROM XLK ;The purpose of the specification PRED (IN_STOCK) is to inform the DBMS that the tuple(s) to be deleted are all supposed to satisfy the predicate IN_STOCK (only), and should therefore be deleted from relvar PK (only). Of course, those tuples will still appear in relvar PL after the delete, but they certainly won’t appear in the intersection view XLK.
Suppose now that Possibility 3 is in fact the case; then the appropriate PRED specification would be PRED (IN_STOCK AND ON_SALE).[154] And it seems reasonable to make this specification the default, so that if no explicit PRED specification appears at all, the delete behaves exactly as described in Chapter 9.
Union and Difference Examples
Just to review, the situations where ambiguity at least potentially arises are as follows:[155]
Deleting through an intersection (see Chapter 9)
Inserting through a union (see Chapter 10)
Deleting through a difference (see Chapter 11)
Of these, I’ve already discussed the first case in the previous section—except now let me point out that, of course, intersection is a special case of join, and so the ideas illustrated in that previous section can surely be generalized to deal with join views too. But let’s consider examples of the other two cases.
Union
First union. Consider the following update on the union view ULK:
INSERT RELATION { TUPLE { PNO 'P4' } } INTO ULK ;
(The expression RELATION {TUPLE {PNO ‘P4’}} is a relation selector invocation, denoting the relation containing just the specified tuple.) According to the rules described in Chapter 10, then, the effect of this insert is to cause the specified tuple to be inserted into both PL and PK, although the desired effect—inserting the tuple into ULK—could be achieved by inserting that tuple into either PL or PK, and there’s no apparent need to insert it into both.
But consider the user once again (U, say) who issues the foregoing insert. Suppose for simplicity that ULK is the only relvar user U is aware of—i.e., user U doesn’t even know relvars PL and PK exist. Despite this lack of awareness, user U must nevertheless be aware that the predicate for ULK is of the form ON_SALE OR IN_STOCK (where again ON_SALE stands for Part PNO is on sale and IN_STOCK stands for Part PNO is in stock). So if user U wants to insert the tuple for part P4 into ULK, it must necessarily be the case that he or she wants to do so because he or she knows that exactly one of the following possibilities holds:
Part P4 is now on sale (but not in stock).
Part P4 is now in stock (but not on sale).
Part P4 is now both on sale and in stock.
What’s more, of course, user U must also know which one of these possibilities is in fact the case. Suppose for the sake of the example that it’s Possibility 2. Then the user can and should issue the following insert:
INSERT RELATION { TUPLE { PNO 'P4' } } PRED ( IN_STOCK ) INTO ULK ;Now the new tuple will be inserted into relvar PK (only).
Suppose now that Possibility 3 is in fact the case; then the appropriate PRED specification would be PRED (IN_STOCK AND ON_SALE).[156] And it seems reasonable to make this specification the default, so that if no explicit PRED specification appears at all, the delete behaves exactly as described in Chapter 10.
Difference
Turning now to difference, consider the following update on the difference view DLK:
DELETE ( DLK WHERE PNO = 'P1' ) FROM DLK ;
According to the rules described in Chapter 11, the effect of this delete is to cause the specified tuple to be deleted from PL and inserted into PK, although the desired effect—deleting the tuple from DLK—could be achieved by either one of these operations and there’s no apparent need to do both.
Once again, however, consider the user U who issues the foregoing delete. Suppose DLK is the only relvar user U is aware of—i.e., user U doesn’t even know relvars PL and PK exist. Despite this lack of awareness, user U must nevertheless be aware that the predicate for DLK is of the form ON_SALE AND NOT IN_STOCK (where once again ON_SALE stands for Part PNO is on sale and IN_STOCK stands for Part PNO is in stock). So if user U wants to delete the tuple for part P1 from DLK, it must necessarily be the case that he or she wants to do so because he or she knows exactly which one of the following possibilities holds:
Part P1 is now not on sale (and still not in stock).
Part P1 is now in stock (and still on sale).
Part P1 is now not on sale but is in stock.
Suppose for the sake of the example that Possibility 2 is the pertinent one. Then the user can and should issue the following delete:
DELETE ( DLK WHERE PNO = 'P1' ) PRED ( IN_STOCK ) FROM DLK ;
The PRED specification here is to be understood as follows: The tuple for part P1 now satisfies the predicate for relvar PK (it didn’t do so before, of course, or it wouldn’t have appeared in relvar DLK in the first place), and so it needs to be inserted into relvar PK, without being deleted from relvar PL. Note: For the record, the specification for Possibility 1 would be PRED (NOT ON_SALE), which would cause the tuple to be deleted from relvar PL, without being inserted into any relvar PK; the specification for Possibility 3 would be PRED (NOT ON_SALE AND IN_STOCK), which would cause the tuple to be deleted from relvar PL and inserted into relvar PK. And it seems reasonable to make this last specification the default, so that if no explicit PRED specification appears at all, the delete behaves exactly as described in Chapter 11.
More on Predicates
One reviewer of an early version of this chapter expressed some doubt as to whether the arguments in the last two sections were really valid. To be specific, he—the reviewer was male—suggested it might not always be true that (for example) in the case of a view defined as A UNION B, the user would know that the predicate was of the form pred(A) OR pred(B). And he went on to give an example of two relvars MOTHER and FATHER, each with a single attribute called NAME, and predicates NAME is somebody’s mother and NAME is somebody’s father, respectively, and then suggested that the predicate for MOTHER UNION FATHER might be, not NAME is somebody’s mother OR NAME is somebody’s father, but simply NAME is somebody’s parent.
In response to this example, let me observe first that relvars MOTHER and FATHER are clearly disjoint, and the union is thus a disjoint union. So the true predicate for that union isn’t quite as I gave it in the previous paragraph, but rather:
| (NAME is somebody’s mother OR NAME is somebody’s father) |
| AND |
| NOT (NAME is somebody’s mother AND NAME is somebody’s father) |
Thus, if a user of the union view really does know only the predicate NAME is somebody’s parent, there won’t be any way for that user to specify that INSERT operations on the view must effectively be targeted at just one of the two relvars MOTHER and FATHER. Instead, such operations will simply fail, on a Golden Rule violation.
That being said, I think I’d also have to question the wisdom of the DBA—or whoever it is who’s responsible for informing the user of the predicate for the view—if that person decided, in the case at hand, not to tell the user what the proper predicate was. But you can’t legislate wisdom, I suppose.
Be that as it may, what happens if the union view doesn’t represent a disjoint union? Let’s take a concrete example (a variation on an example discussed briefly in Chapter 10). Suppose some parts are manufactured abroad, others are manufactured domestically, and some are both. Suppose further that we represent this situation by means of two relvars, both with a single attribute PNO, one (PA) giving part numbers for parts manufactured abroad, the other (PD) giving part numbers for parts manufactured domestically. Then the union of these two relvars—call it UAD—is an overlapping union, and it gives part numbers for all parts. The predicates are as follows:
| PA: Part PNO is used in the enterprise and is manufactured abroad. |
| PD: Part PNO is used in the enterprise and is manufactured domestically. |
| UAD: Part PNO is used in the enterprise and is manufactured either abroad or domestically (and possibly both). |
Well, if the user is told that the predicate for UAD is just Part PNO is used in the enterprise, then inserts will simply have to work as described in Chapter 10, and there’s an end on’t. Again, however, I think I’d have to question the wisdom of whoever it was who told the user that’s what the predicate is. (By the way, note the relevance here of the discussions in the section Information Equivalence Revisited in the previous chapter.)
Concluding Remarks
I’d like to close this chapter, and the main part of this book, by repeating and stressing a point I touched on at the very beginning of the chapter (when I referred to ambiguities arising only “in the absence of information equivalence”). Indeed, the various ambiguities that can occur with the view updating approach as described in earlier chapters, and the various objections to that approach that have been voiced by certain critics, all have the same root cause: To be specific, they all have their origin in the fact that, sometimes, the DBMS simply hasn’t been given enough information. For instance, suppose the database contains two distinct relvars with the same heading, as in the various examples involving relvars PL and PK discussed earlier in the present chapter and in several earlier chapters. Clearly those relvars represent different information (because if they didn’t, there’d be no point in having both); in other words, they correspond to different predicates. But if those predicates aren’t made known to the DBMS somehow—if they exist only external to the system, as it were (perhaps only in the mind of some user)—then there are bound to be occasions where it’ll be impossible for the DBMS to do the right thing.
Now, my own preferred solution to such problems is as discussed in Chapters Chapter 9–Chapter 11, under the general heading “A Better Design.” Just to remind you, in the case of relvars PL and PK specifically, that solution involved the introduction of two attributes ON_SALE and IN_STOCK (each of type BOOLEAN, and having the obvious interpretations). In effect, what I did was redesign the database in such a manner as to give the DBMS the otherwise hidden information—in particular, to redesign it in such a manner that the DBMS could tell for itself which relvar(s) a given tuple logically belonged in. (To put the point another way, the introduction of those attributes allowed the pertinent predicates to be directly represented by means of constraints, thereby effectively making them—the predicates, that is—“known to the DBMS” as required.) However, if the designer, for whatever reason, sees fit not to design the database in such a sensible manner, then I think a scheme along the lines of the one sketched in the present chapter is our only hope of getting the DBMS always to do the right thing.
[149] One consequence of this approach is that Golden Rule violations never occur! If U is an update request that would normally violate some constraint, the combined predicate for U, since it effectively includes all pertinent constraints, simply denotes an empty set, and so no updating is actually done. By way of example, consider an explicit UPDATE request that attempts to change the CITY value to London for some tuple in relvar NLS (“non London suppliers”). In effect, that UPDATE request is modified to say UPDATE NLS WHERE CITY = ‘London’—and, of course, no tuple in NLS ever satisfies this WHERE clause.
[150] I adopt this notation, or naming convention, purely for expository purposes. In practice I hope users would be able to choose their own more “user friendly” predicate names if they want to (and I’ll do exactly that myself in later examples).
[151] Wishful thinking is right! This remark is, unfortunately, more than a little charitable to today’s DBMSs. The sad truth is, most DBMSs today (which are SQL systems, of course) don’t even provide much by way of support for constraints in the first place, let alone support for the corresponding predicates.
[152] In this chapter I find it convenient to use a syntactic style for coding examples that more closely resembles genuine Tutorial D syntax, instead of the pseudocode style I’ve been using in previous chapters.
[153] Actually “believes” might be better than “knows” here, but I’ll stay with “knows” for simplicity.
[154] This specification is, of course, effectively just the predicate for XLK, but in a way that’s a fluke, as we’ll see in the next section.
[155] When I say “at least potentially” here, what I’m referring to is situations in which information equivalence is lost. Observe in particular that the situations in question include all of the various anomalous examples described in Chapter 14.
[156] Observe that AND is correct here, not OR, even though the predicate for ULK is IN_STOCK OR ON_SALE.