
Chapter 7. Event Handlers
The mobile frequency server your company produces hits the market and appears to be extremely popular. Having no visibility into its performance and uptime, you have been asked to implement monitoring software that not only collects statistics and logs important things that happen, but also warns you when things go wrong. And that is where the problem begins. When you are in the office, you want a widget to start flashing on your screen. When you leave your desk, you might want to keep the widget, but also have the system send you an email. And if you leave the office, you want an SMS or pager message but no emails. Your other colleagues on call might prefer a phone call, as an SMS or pager message would not wake them up in the middle of the night. So, the same event types must trigger different actions at different times, all dependent on external factors. This is where the event handler behavior comes to the rescue.
Events
An event represents a state change in the system. It could be a high CPU load, a hardware failure, or a trace event resulting from the activity in a port. An event manager is an Erlang process that receives a specific type of event, which could be alarms, warnings, equipment state changes, debug traces, or issues related to network connectivity. When generated, events are sent to the manager in the form of a message, as shown in Figure 7-1. For every event generated, the system might want to take a specific set of actions, as discussed earlier: generate SNMP traps; send emails, SMSs, or pager messages; collect statistics; print messages to a console; or log the event to a file. We call these processes that generate events producers and processes receiving and handling these events consumers.
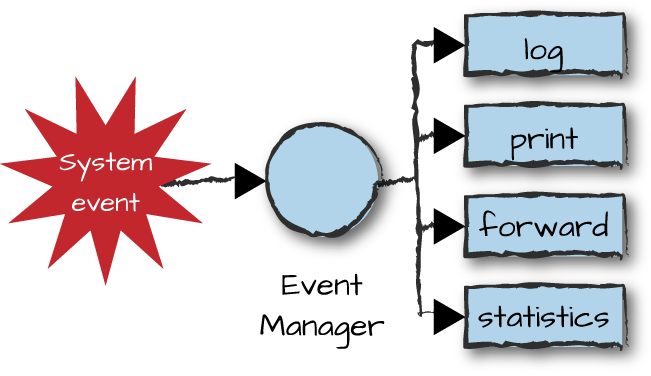
Figure 7-1. Event managers and handlers
Event handlers are behavior callback modules that handle these types of actions. They subscribe to events sent to a manager, allowing different handlers to subscribe to the same events. Different managers handling different event types can use the same event handler. If a handler allows you to log events to a file, another allows you to print them to a console, and a third collects statistics, they could be all be used both by the event manager dealing with debug traces and the event manager handling equipment state changes. Functionality to add, remove, query, and upgrade handlers during runtime is provided in the code implementing the event manager. If you were to implement the code managing events and handlers, what would be generic to all Erlang systems and what would be specific to your application? Table 7-1 shows the breakdown.
| Generic | Specific |
|---|---|
|
|
Starting and stopping the event manager processes is generic, as is registering them with an alias. The process name and events sent to the manager are specific, but the producer sending them, the manager receiving them, and the act of calling a handler are generic. The event handlers themselves are specific, as well as what we do to initialize them, along with cleaning up when they are removed (or when the event manager is stopped). How the handlers deal with the events is specific, as is their loop data. And finally, upgrading the handlers is generic, but what the individual handlers have to do to hand over their state is specific.
Let’s have a look at the event behavior module. While the generic server still acts as its foundation, it is very different from the behaviors we’ve looked at so far.
Generic Event Managers and Handlers
Generic event handlers and managers are part of the standard library
application, and like all other behaviors, are split up into generic and
specific code. The gen_event module contains all of the generic code. The process running this
code is often referred to as the event manager. The callback modules subscribing to the events and handling them
through a set of callback functions are called the event handlers. Each handler solves a specific event-driven
task and is part of the specific code. Unlike other behaviors, which allow
only one callback module per instance, an event manager can take care of zero or more event handlers, as shown in Figure 7-2.
But despite the possibility of there being multiple handlers, they will
all be executed in a single event manager process.
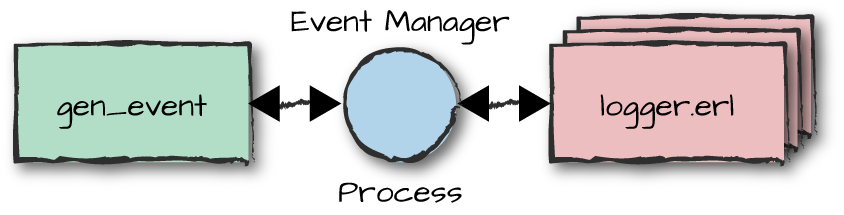
Figure 7-2. Handler callback module
Starting and Stopping Event Managers
The gen_event:start_link(NameScope) function starts a new event manager.
NameScope specifies the local or
global process name or the via
module, first explained in “Going Global”. Should you
not want to register the process, use start_link/0 and communicate
with it using its pid. Unlike with other behaviors, start_link/0
accepts no callback modules, arguments, or options. Nor does it invoke
any callback functions. All the manager does is set its handler list to
the empty list:
gen_event:start()gen_event:start(NameScope)gen_event:start_link()gen_event:start_link(NameScope)->{ok,Pid}{error,{already_started,Pid}}gen_event:stop(NameScope)->ok
Because you are not calling an init/1 callback
function that can return stop or
ignore, or even generate a runtime
error, not much can go wrong here unless an event manager or process
with the same name is already registered.
Adding Event Handlers
Now that we can start and stop our manager, let’s implement a handler and add it. Event handlers are added to and removed from the event manager process dynamically, at runtime. They are considered more generic than other behaviors because you can implement an event handler that can not only handle different event types, but do so in different event managers.
In our logger example, we implement an event handler that logs events and unexpected messages to standard I/O or a file, depending on which parameters are provided when it is added to the manager. As with our other generic behaviors, we start with the behavior directive and export our callback functions:
-module(logger).-behavior(gen_event).-export([init/1,terminate/2,handle_event/2,handle_info/2]).init(standard_io)->{ok,{standard_io,1}};init({file,File})->{ok,Fd}=file:open(File,write),{ok,{Fd,1}};init(Args)->{error,{args,Args}}.
If we call the gen_event:add_handler(Name, Mod, Args)
function, the handler implemented in the Mod module is
added to the event manager. The event manager calls the
Mod:init(Args) callback function, returning {ok,
LoopData}, where the LoopData refers to that
particular handler. In our example, our loop data contains a tuple with
either the file descriptor or the atom standard_io and the integer 1, a counter
incremented every time we receive an event. If we pass the standard_io atom as an argument, all events
will be printed to the shell. Passing {file,
File}, where file is an
atom and File is a string containing
the filename, will log all events to that file.
To manage multiple events, the event manager stores its handlers and their loop data in a list. Figure 7-3 shows our handler instance and its loop data getting added to the list of other handlers stored by the event manager.
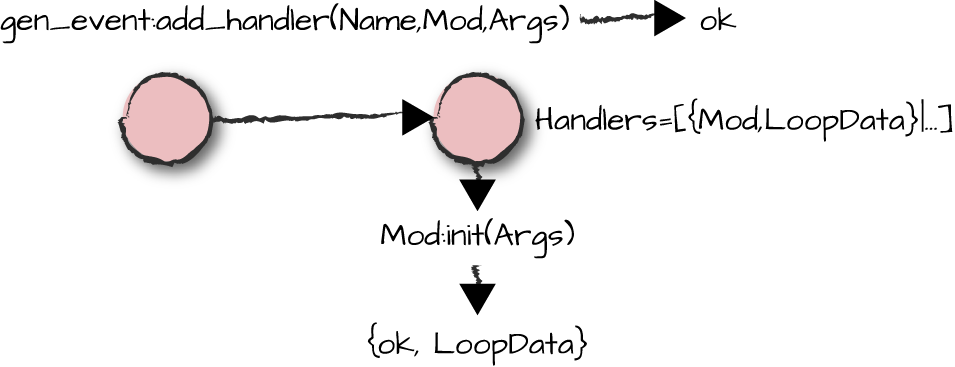
Figure 7-3. Adding handlers
You can not only add many handlers to a manager, but also add the
same handler many times, storing different instances of the loop data.
In our case, we could add two logger handlers, one saving everything to a
file and the other printing the events in the shell. Alternatively, the
Mod parameter can be specified as {Module,
Id}, where Id can be any Erlang term. If Id is
unique, it allows client functions to differentiate between multiple
handlers using the same callback module in a particular manager.
gen_event:add_handler(NameScope,Mod,Args)->{'EXIT',Reason}okTermMod:init/1->{ok,LoopData}{ok,LoopData,hibernate}Term
Adding a nonexistent event handler will result in the event
manager failing to call Mod:init/1 and returning
{'EXIT', Reason}, where Reason is the undef runtime error
(the undefined function). Should the evaluation of any expression in the
init/1 callback function fail, {'EXIT',
Reason} will be returned. Keep in mind that {'EXIT',
Reason} is the tuple caught within the scope of a try-catch
expression, and not an exception.
If the init/1 callback returns a Term
other than {ok, LoopData}, the Term itself is
returned. This includes the case where the Term is the atom
ok without the LoopData,
a common beginner error. Whenever init/1 does not return
{ok, LoopData}, the event handler is not added to the
manager. This means just returning ok without
LoopData will not work as you might at first think, as the
handler is not added.
In our example, if the handler is started with arguments that fail
pattern matching in the first two clauses, init/1 returns
{error, {args, Args}} and the manager does not add it to
its list of handlers. So, while init/1 can return any term,
be careful and stick to return values of the format {ok,
LoopData} and {error, Reason} to avoid
confusion.
Just like other behaviors, you can make your event manager
hibernate in between events. It is enough for one handler to return
hibernate for this to happen. Use
hibernation with care, and only if events will be intermittent.
Hibernating your process will trigger a full-sweep garbage collection
before you hibernate and right after waking up. This is not a behavior you
want when receiving a large number of events at short intervals.
Deleting an Event Handler
Now that we have added a handler, let’s see what we need to do in order to
delete it. The logger callback
module exports the terminate(Args, LoopData) callback
function. This function is invoked whenever
gen_event:delete_handler(Name, Mod, Args) is called. Name identifies the specific event
manager process where our handler is registered; it is either its pid,
or its local Name if registered locally. But when using
name servers, {global, Name} has to be passed, or if you
are using your own name server, pass {via, Name, Module}.
Mod specifies the handler you want to delete and
Args is any valid Erlang term passed as the first argument
to terminate/2. Args could be the reason for
termination or just a parameter with instructions needed in the cleanup
(Figure 7-4).
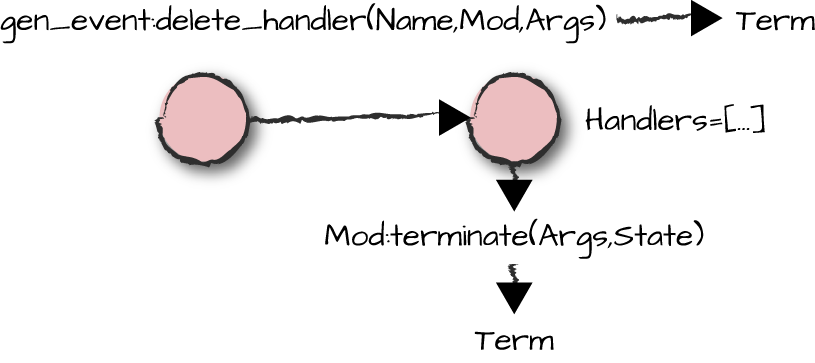
Figure 7-4. Deleting handlers
In our example, if we were to remove the logger handler, we would have to cater for the cases where we are printing the logs to standard I/O or to a file:
terminate(_Reason,{standard_io,Count})->{count,Count};terminate(_Reason,{Fd,Count})->file:close(Fd),{count,Count}.
When the terminate/2 function returns, the handler is
deleted from the list of handlers in the specific event manager process
identified by the Name argument to
delete_handler/3. Other managers using the same handler are
not affected. If multiple handlers are registered using the same
Mod, such as one for logging to standard_io
and another for logging to a file, they are deleted in the reverse order
of their addition. If you stop the manager using gen_event:stop/1, all handlers are
deleted with reason stop.
Note how terminate/2 returns Term. This
becomes the return value of the delete_handler/3 call. In
our example, we return the log counter, {count, Count},
which lets the caller of delete_handler/3 know how many
events came through the handlers before they were terminated. But if we
were upgrading the handler, Term might be all of the loop
data. We cover upgrades later in this chapter.
Attempting to delete a handler that isn’t registered results in a return value of
{error, module_not_found}. Both adding and deleting a
handler in a nonexistent event manager, irrespective of whether the
manager is referenced using a pid or a registered alias, will result in
the calling process terminating with reason noproc.
gen_event:delete_handler(NameScope,Mod,Args)->{error,module_not_found}{'EXIT',Reason}TermMod:terminate/2->Term
Sending Synchronous and Asynchronous Events
Events can be sent to the manager and forwarded to the handlers synchronously or asynchronously depending on the need to control the rate at which producers generate events. Events are handled by the manager process, which invokes all added handlers sequentially, one at a time. If you send multiple events to the event manager and they need to be handled by several—potentially slow—event handlers, your message queue might grow and result in a reduction of throughput as described in “Synchronous versus asynchronous calls”, so make sure your handler does not become a bottleneck. We discuss techniques to handle large volumes of messages in “Balancing Your System”.
The gen_event:notify/2 function sends an asynchronous event to all handlers and
immediately returns ok. The callback
function Mod:handle_event/2 is called for every handler
that has been added to the manager, one at a time. gen_event:sync_notify/2 also
invokes the Mod:handle_event/2 callback function for
all handlers. The difference from its asynchronous variant is that
ok is returned only when all callbacks have been
executed.
Let’s consider how we might implement the
handle_event/2 callback function for our logger:
handle_event(Event,{Fd,Count})->(Fd,Count,Event,"Event"),{ok,{Fd,Count+1}}.(Fd,Count,Event,Tag)->io:format(Fd,"Id:~wTime:~wDate:~w~n"++Tag++":~w~n",[Count,time(),date(),Event]).
The handle_event/2 callback, illustrated in Figure 7-5, receives an event
together with either the atom standard_io or the file descriptor of the file
opened in the init/1 callback. The print/4
function invokes io:format/3 to output the counter value,
the current date and time, and the Event tag value followed by the event
itself.
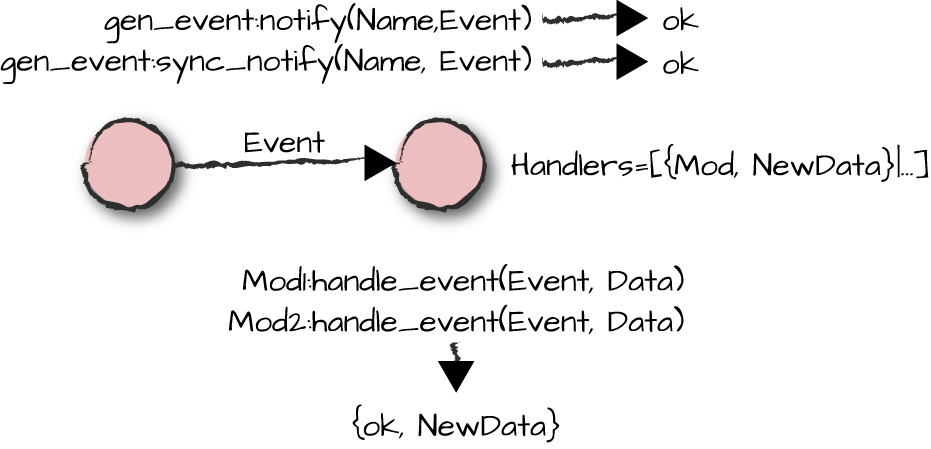
Figure 7-5. Notifications
If our event handler receives any non-OTP-compliant events
originating from links, trapping exits, process monitors, monitoring
distributed Erlang nodes, or messages resulting from
Pid!Msg, they are handled in the handle_info/2 callback function of the
event handlers:
handle_info(Event,{Fd,Count})->(Fd,Count,Event,"Unknown"),{ok,{Fd,Count+1}}.
The implementation of handle_info/2 for the logger is
almost identical to handle_event/2, except that it passes
the tag value "Unknown" to the print function
to indicate that it doesn’t know the source of the event.
gen_event:notify(NameScope,Event)gen_event:sync_notify(Name,Event)->okMod:handle_event(Event,Data)Mod:handle_info(Event,Data)->{ok,NewData}{ok,NewData,hibernate}remove_handler{swap_handler,Args1,NewData,Handler2,Args2}
If a handler returns remove_handler from its
handle_event/2 or handle_info/2 function,
Mod:terminate(remove_handler, Data) is called and the handler is deleted. We look at swapping
handlers later in this chapter. Until then, let’s make sure that the
code in the event handler we have written so far works.
In shell command 1, we start the event manager without registering or linking it to its parent. Should the shell process crash, the event manager process will not be affected. We proceed by adding a handler and sending two notifications, one synchronous and one asynchronous:
1>{ok, P} = gen_event:start().{ok,<0.35.0>} 2>gen_event:add_handler(P, logger, {file, "alarmlog"}).ok 3>gen_event:notify(P, {set_alarm, {no_frequency, self()}}).ok 4>gen_event:sync_notify(P, {clear_alarm, no_frequency}).ok
Note how both calls return the atom ok. The semantic
difference is that shell command 4 does not return ok until
all the handlers have executed their handle calls.
In shell command 5, we add a second instance of the handler, this
time directing events to standard I/O. In shell command 6, we send a
non-OTP-compliant message that is logged and printed to the shell by the
handle_info/2 callback function of our two event handler
instances:
5>gen_event:add_handler(P, logger, standard_io).ok 6>P ! sending_junk.Id:1 Time:{18,59,25} Date:{2013,4,26} Unknown:sending_junk sending_junk
In shell commands 7 and 8, we read the binary contents of the
alarmlog file and print them out in
the shell. We see the first two events we sent asynchronously and
synchronously, as well as the unknown message received by the
handle_info/2 call:
7>{ok, Binary} = file:read_file("alarmlog").{ok,<<"Id:1 Time:{18,59,10} Date:{2013,4,26} Event:{set_alarm,{no_frequency,... 8>io:format(Binary).Id:1 Time:{18,59,10} Date:{2013,4,26} Event:{set_alarm,{no_frequency,<0.32.0>}} Id:2 Time:{18,59,14} Date:{2013,4,26} Event:{clear_alarm,no_frequency} Id:3 Time:{18,59,25} Date:{2013,4,26} Unknown:sending_junk ok 9>gen_event:delete_handler(P, freq_overload, stop).{error,module_not_found} 10>gen_event:stop(P).ok
We wrap up this example by trying to delete
freq_overload, an event handler that has not been added to
this event manager. As expected, this returns the error module_not_found. Finally, we stop the
event manager, by default terminating all of the event handlers.
Download the logger handler from the book’s code repository and
take it for a spin. Test sending it synchronous and asynchronous
messages when the event manager has been stopped (or has crashed), and
start it using start_link and make the shell crash. Finally, try to figure out what happens if
you provide an invalid filename when adding the handler.
Retrieving Data
Let’s implement another event handler, one that stores metrics. Every time
we log an event, we also bump up a counter in an ETS table that tells us how many times this event has been
logged. If it is the first occurrence of the event, we create a new
entry in the table. Have a look at the code, and if necessary, refer to the
manual pages of the ets module:
-module(counters).-behavior(gen_event).-export([init/1,terminate/2,handle_event/2,handle_info/2]).-export([get_counters/1,handle_call/2]).get_counters(Pid)->gen_event:call(Pid,counters,get_counters).init(_)->TableId=ets:new(counters,[]),{ok,TableId}.terminate(_Reason,TableId)->Counters=ets:tab2list(TableId),ets:delete(TableId),{counters,Counters}.handle_event(Event,TableId)->tryets:update_counter(TableId,Event,1)of_ok->{ok,TableId}catcherror:_->ets:insert(TableId,{Event,1}),{ok,TableId}end.handle_call(get_counters,TableId)->{ok,{counters,ets:tab2list(TableId)},TableId}.handle_info(_,TableId)->{ok,TableId}.
Of interest in this example is how we retrieve the counters.
Using gen_event:sync_event/2 would not have
worked, as despite it being synchronous, it forwards the event to all
handlers and returns ok. We need to
specify the handler to which we want to send our synchronous message, and we do so using the
gen_event:call(NameScope, Mod, Message) function.
As Figure 7-6 shows, the event handler synchronously receives the request in the Mod:handle_call/2 callback and returns a
tuple of the format {ok, Reply, NewData}, where
Reply is the return value of the request.
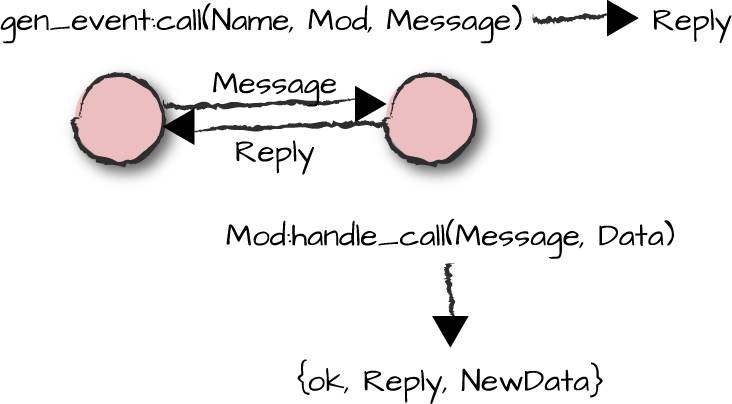
Figure 7-6. Calls
gen_event:call(NameScope,Mod,Request)gen_event:call(NameScope,Mod,Request,Timeout)->Reply{error,bad_module}{error,{'EXIT',Reason}}{error,Term}Mod:handle_call(Event,Data)->{ok,Reply,NewData}Term
The default timeout in gen_event:call/3 is
5,000 milliseconds. It can be overridden by passing either a
Timeout value as an integer in milliseconds or the atom
infinity. If Mod is not
an event handler that has been added to NameScope,
{error, bad_module} is returned. If the callback function
handle_call/2 terminates abnormally when handling the
request, expect {error, {'EXIT', Reason}}. And finally, if
handle_call/2 returns any term other than {ok, Reply,
NewData}, the return value of gen_event:call will be
{error, Term}. In both of these error cases, the handler is
removed from the list managed by the event manager without affecting the other handlers.
1>{ok, P} = gen_event:start().{ok,<0.35.0>} 2>gen_event:add_handler(P, counters, {}).ok 3>gen_event:notify(P, {set_alarm, {no_frequency, self()}}).ok 4>gen_event:notify(P, {event, {frequency_denied, self()}}).ok 5>gen_event:notify(P, {event, {frequency_denied, self()}}).ok 6>counters:get_counters(P).{counters,[{{event,{frequency_denied,<0.33.0>}},2}, {{set_alarm,{no_frequency,<0.33.0>}},1}]}
Handling Errors and Invalid Return Values
It is not just when its handle_call/2 terminates
abnormally or returns an invalid reply that a handler gets
deleted. An abnormal termination in any of its callbacks will also
result in deletion. The event manager and other handlers are not
affected. This differs from other behaviors in that the event handler is
silently removed, without any notifications being sent to the event
manager’s supervisor. What also differs from other behaviors is that
the event manager will by default trap exits. The assumption is that
event managers are added and removed dynamically and independently of
each other, and as a result, a crash should not affect anything in its
surrounding environment (see Figure 7-7). While fault isolation is a good property,
failing silently isn’t.
Figure 7-7. Handler crash
To better understand how abnormal termination in event handlers works, let’s use the following code snippet as an example:
-module(crash_example).-behavior(gen_event).-export([init/1,terminate/2,handle_event/2]).init(normal)->{ok,[]};init(return)->error;init(ok)->ok;init(crash)->exit(crash).terminate(_Reason,_LoopData)->ok.handle_event(crash,_LoopData)->1/0;handle_event(return,_LoopData)->error.
Depending on what parameters we send to the event handler when adding it to the event manager and notifying it of an event, we can generate runtime errors and return invalid values. Step through the shell commands in the following example, mapping all requests to the error conditions that occur:
1>{ok,P}=gen_event:start().{ok,<0.35.0>} 2>gen_event:which_handlers(P).[] 3>gen_event:add_handler(P, crash_example, return).error 4>gen_event:which_handlers(P).[] 5>gen_event:add_handler(P, crash_example, normal).ok 6>gen_event:which_handlers(P).[crash_example] 7>gen_event:notify(P, crash).ok =ERROR REPORT==== 27-Apr-2013::09:27:49 === ** gen_event handler crash_example crashed. ** Was installed in <0.35.0> ** Last event was: crash ** When handler state == [] ** Reason == {badarith, [{crash_example,handle_event,2, [{file,"crash_example.erl"},{line,13}]}, ...]} 8> gen_event:which_handlers(P). [] 9>gen_event:add_handler(P, crash_example, normal).ok 10>gen_event:notify(P, return).ok =ERROR REPORT==== 27-Apr-2013::09:28:41 === ** gen_event handler crash_example crashed. ** Was installed in <0.35.0> ** Last event was: return ** When handler state == [] ** Reason == error 11>gen_event:which_handlers(P).[]
While error reports are generated (these are covered in more detail in “The SASL Application”), no runtime errors occur, and as a
result, no EXIT signals are generated. Sending
notifications can fail silently, resulting in the handler being deleted
without any processes or humans noticing.
You get around this problem by connecting a handler to the calling process using
gen_event:add_sup_handler/3. It works in the same way as
add_handler/3, with the side effect that the calling
process is now monitoring the handler, and the calling process is being
monitored by the newly added instance of the handler in the manager. If
an exception occurs or an incorrect return value is returned in
callbacks handling events, a message of the format
{gen_event_EXIT, Mod, Reason} is sent to the process that
added the handler. Reason can be one of the
following:
normalif a callback function returnedremove_handleror the handler was removed usingdelete_handler/3shutdownif the event manager is being stopped, either by its supervisor or by thestop/1call{'EXIT', Term}if a runtime error occurredTermif the callback returned anything other than{ok, LoopData}or{ok, Reply, LoopData}{swapped, NewMod, Pid}, wherePidhas swapped the handler
We look into swapping handlers in the next section.
Monitoring goes two ways. If the process that added the handler
terminates, the handler is removed with {stop, Reason} as
an argument. This ensures that multiple instances of the handler are not
included in the manager should the handler be added by a behavior stuck in a cyclic restart.
Fail Loudly!
If you are writing a system with requirements on high
availability and fault tolerance, the last thing you want is a handler
being silently deleted or failing in init/1 and not being
added at all. Always check the return value of the
add_handler/3 and add_sup_handler/3 calls.
If you have to use add_handler, ensure that you execute
any code that might fail as a result of a bug, external dependencies
(such as a disk full error), or corrupt data within the scope of a
try-catch expression. Where possible, use
add_sup_handler/3, pattern matching on its return value
to ensure that the handler has been properly added, and pay attention
to all exception messages you receive as a result. You don’t
want your alarm system to fail without raising any alarms!
Swapping Event Handlers
The event manager provides functionality to swap handlers during runtime. It
allows a handler to pass its state to a new handler, ensuring that no
events are lost in the process. The second parameter of the gen_event:swap_handler/3 call is a tuple
containing the name of the handler callback module we want to replace,
together with the arguments passed to its terminate
function. The third parameter is a tuple containing the callback module of the
new handler and the arguments passed to its init
function. Figure 7-8 shows these parameters along with the steps that take place when swapping handlers.
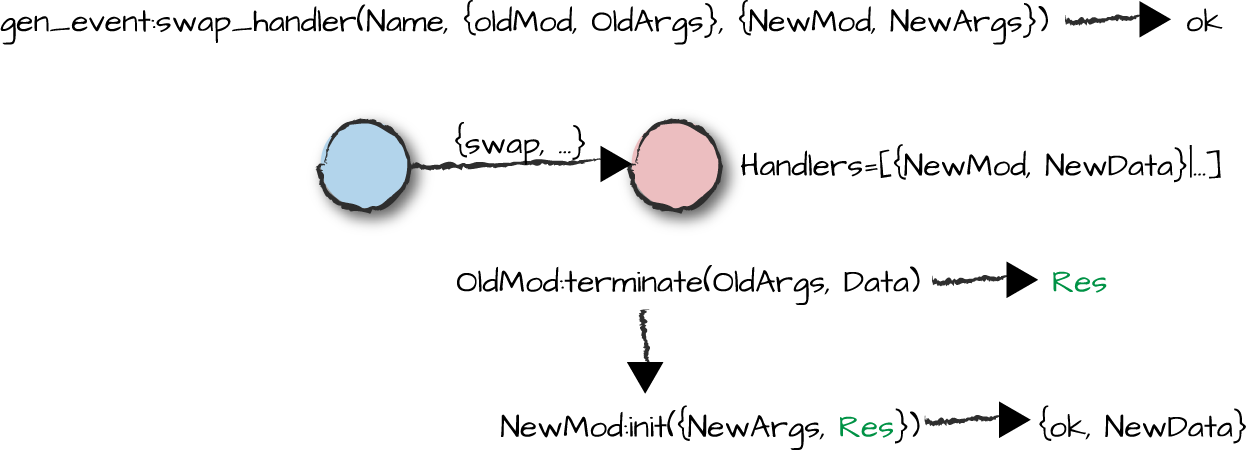
Figure 7-8. Swapping handlers
The terminate callback function in the old handler is
first called. Its return value, Res, is passed in a tuple
together with the arguments intended for the init function
of the new handler. It couldn’t be simpler! If you want to swap the
handler and start supervising the connection between the handler and the
calling process, use gen_event:swap_sup_handler/3. The handler
you are swapping does not have to be supervised.
An example is probably the best way to demonstrate swapping. Let’s
extend our logger handler to be able to flip between logging to a file and
printing to standard I/O. We extend our terminate function
to handle the reason swap, returning
Res, a tuple of the format {Type, Count}.
Type is either the file descriptor or the atom standard_io, and Count is the
unique ID for the next item to be logged. As we do not know what the
logger we are swapping to wants to do with the events, we do not close
the file and instead let the handler deal with it in its
init/1 call.
In the init/1 call, we add two cases where we accept
the same Args as when we are adding the handler, but also
the results sent back from terminate. So, if we are logging to a file and
want to swap to standard I/O, we close the file and return {ok,
{standard_io, Count}}. If we are printing to standard I/O, we
open the file and start writing events in it. In both cases, we retain
whatever value Count is set to:
init({standard_io,{Fd,Count}})whenis_pid(Fd)->file:close(Fd),{ok,{standard_io,Count}};init({File,{standard_io,Count}})whenis_list(File)->{ok,Fd}=file:open(File,write),{ok,{Fd,Count}};...terminate(swap,{Type,Count})->{Type,Count};...
If we test our code, starting the manager, adding the logger handler, raising an alarm, swapping the handlers, and raising a second alarm, we get the following results:
1>{ok, P} = gen_event:start().{ok,<0.35.0>} 2>gen_event:add_handler(P, logger, {file, "alarmlog"}).ok 3>gen_event:notify(P, {set_alarm, {no_frequency, self()}}).ok 4>gen_event:swap_handler(P, {logger, swap}, {logger, standard_io}).ok 5>gen_event:notify(P, {set_alarm, {no_frequency, self()}}).Id:2 Time:{10,1,16} Date:{2013,4,27} Event:{set_alarm,{no_frequency,<0.33.0>}} ok 6>{ok, Binary}=file:read_file("alarmlog"), io:format(Binary).Id:1 Time:{10,1,16} Date:{2013,4,27} Event:{set_alarm,{no_frequency,<0.33.0>}} ok
Wrapping It All Up
Now that we have a handler, let’s wrap it in a module, hiding the
event manager API in a more intuitive and application-specific set of
functions. We do this in the freq_overload module, which is responsible
for starting the manager along with providing an API for setting and
clearing the no_frequency alarm and generating events when
a client is denied a frequency. It also provides a wrapper around the
functions used to add and delete handlers. We leave the handler-specific
function calls, such as retrieving the counters or swapping from file to
standard I/O, local to the handlers themselves:
-module(freq_overload).-export([start_link/0,add/2,delete/2]).-export([no_frequency/0,frequency_available/0,frequency_denied/0]).start_link()->casegen_event:start_link({local,?MODULE})of{ok,Pid}->add(counters,{}),add(logger,{file,"log"}),{ok,Pid};Error->Errorend.no_frequency()->gen_event:notify(?MODULE,{set_alarm,{no_frequency,self()}}).frequency_available()->gen_event:notify(?MODULE,{clear_alarm,no_frequency}).frequency_denied()->gen_event:notify(?MODULE,{event,{frequency_denied,self()}}).add(M,A)->gen_event:add_sup_handler(?MODULE,M,A).delete(M,A)->gen_event:delete_handler(?MODULE,M,A).
Note how we are adding the counters in our
freq_overload:start_link/0 call. This ensures that if the
event manager is restarted, the counters and logger handlers will also
be added. The downside is that we are unable to supervise the handlers
from the event manager process in case it crashes. If you want another
process to monitor the handlers, use freq_overload:add/2, which uses
gen_event:add_sup_handler/3.
When setting alarms and raising events, we are also including the
pid of the frequency allocator. This allows us to differentiate among
different allocators (called the alarm or event
originators), allowing operational staff to determine which servers are
overutilized and need to be allocated a larger frequency pool. We want
to raise an alarm every time the allocator runs out of frequencies and
clear it when a frequency becomes available. If a client allocates the
last frequency, we call freq_overload:no_frequency/0,
setting the no_frequency alarm. If a
frequency is deallocated in a state where there were no frequencies
available, we clear the alarm by calling
freq_overload:frequency_available/0. We also raise an event
every time a user is denied a frequency by calling the function
freq_overload:frequency_denied/0. We handle this as a
separate event, as we might be out of frequencies but do not reject
requests. The code additions to frequency.erl are
straightforward:
allocate({[],Allocated},_Pid)->freq_overload:frequency_denied(),{{[],Allocated},{error,no_frequency}};allocate({[Res|Resources],Allocated},Pid)->caseResourcesof[]->freq_overload:no_frequency();_->okend,{{Resources,[{Res,Pid}|Allocated]},{ok,Res}}.deallocate({Free,Allocated},Res)->caseFreeof[]->freq_overload:frequency_available();_->okend,NewAllocated=lists:keydelete(Res,1,Allocated),{[Res|Free],NewAllocated}.
Now that we have fixed other code in the frequency allocator and
implemented our freq_overload event manager, let’s add the
logger and counters handlers to the event manager and run
them alongside each other, as seen in Figure 7-9. Along with raising alarms, we also log
them.
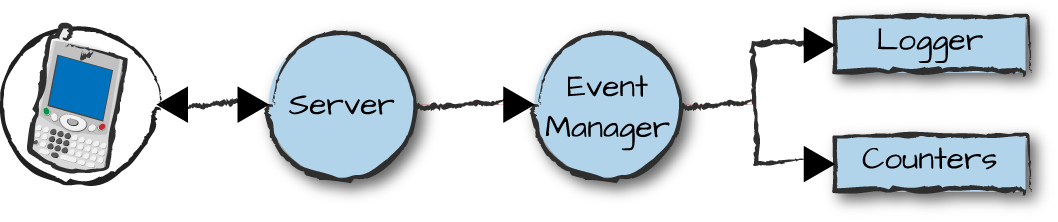
Figure 7-9. Handler example
We start the frequency server and the event manager and add a second
logger event handler, this one
printing to the shell. In our example, the frequency allocator had six
frequencies. In shell command 4, we allocate all of them, raising a
no_frequency alarm. This happens
despite the last request being successful and returning {ok,
15}:
1>frequency:start_link().{ok,<0.35.0>} 2>freq_overload:start_link().{ok,<0.37.0>} 3>freq_overload:add(logger, standard_io).ok 4>frequency:allocate(), frequency:allocate(), frequency:allocate(), frequency:allocate(), frequency:allocate(), frequency:allocate().Id:1 Time:{10,41,25} Date:{2015,2,28} Event:{set_alarm,{no_frequency,<0.35.0>}} {ok,15} 5>frequency:allocate().Id:2 Time:{10,41,46} Date:{2015,2,28} Event:{event,{frequency_denied,<0.35.0>}} {error,no_frequency} 6>frequency:allocate().Id:3 Time:{10,42,0} Date:{2015,2,28} Event:{event,{frequency_denied,<0.35.0>}} {error,no_frequency} 7>frequency:deallocate(15).Id:4 Time:{10,42,16} Date:{2015,2,28} Event:{clear_alarm,no_frequency} ok 8>counters:get_counters(freq_overload).{counters,[{{set_alarm,{no_frequency,<0.35.0>}},1}, {{clear_alarm,no_frequency},1}, {{event,{frequency_denied,<0.35.0>}},2}]}
Having set the alarm, we then try to allocate two frequencies and fail
both times. We clear the alarm when deallocating a frequency in shell
command 7. When we retrieve the counters, we see that a frequency was
denied twice and that the no_frequency alarm was set and cleared
once.
The SASL Alarm Handler
We’ve been talking about alarm handlers in this chapter without giving a proper definition, but the time has come to set the record straight. An alarm handler is the part of the system that records ongoing issues and takes appropriate actions. If your system reaches a high memory mark or is running out of disk space (or frequencies), you will want to set (or raise) an alarm. When memory usage decreases or old log files are deleted, the respective alarms are cleared. At any point in time, it should be possible to inspect the list of active alarms and get a snapshot of ongoing issues.
The SASL alarm handler process is an event manager and handler that comes as part of the Erlang runtime system and provides this functionality. It is a very basic alarm handler you are encouraged to replace or complement in your own project when more functionality is required. The philosophy of developing Erlang systems is to start simple and add complexity as your system grows. That is exactly what has been done with the SASL alarm handler.
Depending on how you have installed Erlang on your computer, the
SASL alarm handler might already have been started. Run whereis(alarm_handler). in your shell to
find out. If you get back the atom undefined, start the alarm handler by typing
application:start(sasl). in the shell. You might get some progress reports printed out in
the shell, once again depending on how you installed Erlang. We cover the
reports, alarming in general, and other useful tools and libraries in SASL
in Chapter 9, Chapter 11, and Chapter 16.
For now, don’t worry about the reports.
If whereis/1 returns a pid, the alarm handler is
already running and you do not need to do anything other than try it
out:
1>whereis(alarm_handler).<0.41.0> 2>alarm_handler:set_alarm({103, fan_failure}).=INFO REPORT==== 26-Apr-2013::08:23:27 === alarm_handler: {set,{103,fan_failure}} ok 3>alarm_handler:set_alarm({104, cabinet_door_open}).=INFO REPORT==== 26-Apr-2013::08:23:43 === alarm_handler: {set,{104,cabinet_door_open}} ok 4>alarm_handler:clear_alarm(104).=INFO REPORT==== 26-Apr-2013::08:24:04 === alarm_handler: {clear,104} ok 5>alarm_handler:get_alarms().[{103,fan_failure}]
In our example, picture a rack in which the cooling fan fails. A system administrator goes to the rack, opens the cabinet door to inspect what is going on, closes it, and heads off to order a replacement fan. What we’ve done is raise two alarms with IDs 103 and 104. These IDs are used to clear the alarm, something that happens in shell command 4 when the cabinet door is closed. The wrapper around the SASL event manager and event handler exports the following functions:
alarm_handler:set_alarm({AlarmId,Description})->okalarm_handler:clear_alarm(AlarmId)->okalarm_handler:get_alarms()->[{AlarmId,Description}]
In a complex system, you might have hundreds of alarms of varying severities, where clearing one will by default clear half a dozen other ones dependent on it. You will want to keep accurate statistics, log everything, and in advanced systems run agents that take immediate action. In the case of the fan failure, for example, you would want to start shutting down all equipment in that cabinet to avoid overheating. The existing handler does none of this and will not scale. But to start off, it works and fits in with the iterative design, develop, and test cycles that are the norm when developing Erlang systems.
Replacing or complementing the existing handler is easy. You need to
handle the events {set_alarm, {AlarmId, AlarmDescr}} and
{clear_alarm, AlarmId}. If you want to swap the existing
handler using swap_handler/3:
gen_event:swap_handler(alarm_handler,{alarm_handler,swap},{NewHandler,Args})
the init function in your new handler should pattern
match the argument {Args, {alarm_handler, Alarms}}, where
Args is passed in the swap_handler/3 call and
{alarm_handler, Alarms} is the term returned from the terminate/2 call of the old handler. Alarms is a list of {AlarmId, Description}
tuples.
Summing Up
In this chapter, we introduced how events are handled by the event
manager behavior. You should by now have a good understanding of the
advantages of using the gen_event behavior instead of rolling
your own or increasing the complexity of one of your subsystems by
integrating this functionality in it. The biggest difference between the
event manager and other OTP behaviors is the one-to-many relationship,
where you can associate many event handlers with one event manager. The
most important functions and callbacks we have covered are listed in Table 7-2.
| gen_event function or action | gen_event callback function |
|---|---|
gen_event:start/0, gen_event:start/1,
gen_event:start_link/0, gen_event:start_link/1 | |
gen_event:add_handler/3,
gen_event:add_sup_handler/3 | Module:init/1 |
gen_event:swap_handler/3,
gen_event:swap_sup_handler/3 | Module1:terminate/2, Module2:init/1 |
gen_event:notify/2, gen_event:sync_notify/2 | Module:handle_event/2 |
gen_event:call/3, gen_event:call/4 | Module:handle_call/2 |
gen_event:delete_handler/3 | Module:terminate/2 |
gen_event:stop/1 | Module:terminate/2 |
Pid ! Msg, monitors, exit messages, messages from ports and
socket, node monitors, and other non-OTP messages | Module:handle_info/2 |
Before reading on, make sure you review the manual pages for the
gen_event module. An example that complements the
ones in this chapter is the alarm_handler
module. Read through the code and you will notice how the developers have integrated
the client functions to start and stop the event manager as well as the
handler functions themselves.
What’s Next?
The event manager is the last worker behavior we cover. Event managers, along with generic servers, FSMs, and behaviors you have written yourself, are started and monitored in supervision trees. The next chapter covers the supervisor behavior, responsible for starting, stopping, and monitoring other supervisors and workers. We show you how to write your own behaviors in Chapter 10. We go into more detail on the importance of alarms in ensuring the high availability and reliability of your systems when we cover monitoring and preemptive support in Chapter 16.