
Chapter 9. Applications
In our previous chapters, we’ve looked at worker behaviors and how they can be grouped together to form a supervision tree. In this chapter, we explore the application behavior, which allows us to package together supervision trees, modules, and other resources into one semi-independent unit, providing the basic building blocks of large Erlang systems. An OTP application is a convenient way to package code and configuration files and distribute the result around the world for others to use.
An Erlang node typically consists of a number of loosely coupled OTP applications that interact with each other. OTP applications come from a variety of sources:
Some are available as part of the standard Ericsson distribution, including mnesia, sasl, and os_mon.
Other generic applications that are not part of the Ericsson distribution but are necessary for the functionality of many Erlang systems can be obtained commercially or as open source. Examples of generic applications include elarm for alarming, folsom or exometer for metrics, and lager for logging.
Each node also has one or more nongeneric applications that contain the system’s business logic. These are often developed specifically for the system, containing the core of the functionality.
A final category of OTP applications are those that are full user applications themselves that, together with their dependencies, could run on a standalone basis in an Erlang node. The bundle of applications is referred to as a release. Examples include the Yaws web server, the Riak database, the RabbitMQ message broker, and the MongooseIM chat server. While not a common practice, inter-application throughput and overall performance can sometimes be improved by running business logic applications together on the same node with these types of full applications.
Regardless of their sources, though, OTP applications are generally structured the same way. We explore the details of this structure in the remainder of this chapter. In the rest of the book, we use the term “application” to refer specifically to an OTP application, and not an application in the broader sense of the word.
How Applications Run
One way to view an application is as a means of packaging resources into reusable components. Resources can consist of modules, processes, registered names, and configuration files. They could also include other non-Erlang source or executable code, such as bash scripts, graphics, or drivers. Though different OTP applications contain different resources and perform different functions or services, to the Erlang run-time system they all look the same; it doesn’t distinguish between them in terms of how it loads and runs them, allows them to be accessed and invoked from other applications, or terminates them. Figure 9-1 shows how various components run together on the Erlang runtime.
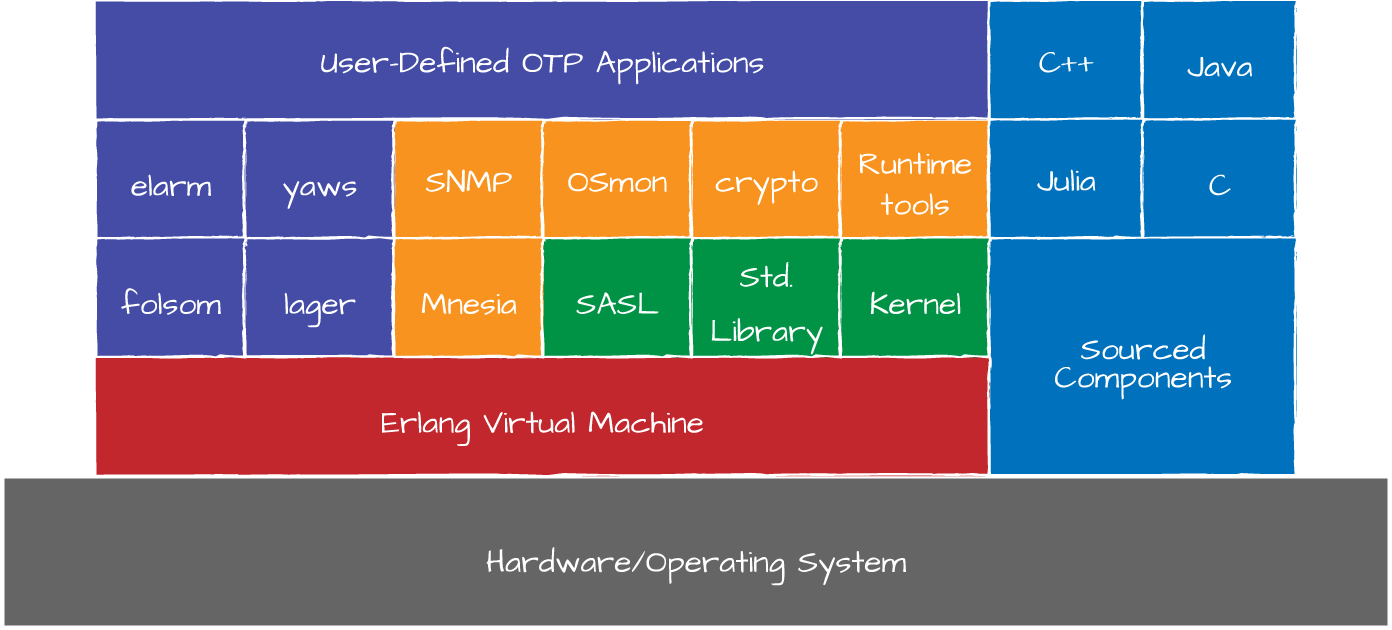
Figure 9-1. An Erlang release
Applications can be configured, started, and stopped as a whole. This allows a system to easily manage many supervision trees, running them independently of each other. One application can also depend on another one; for example, a server-side web application might depend on a web server application such as Yaws. Supporting application dependencies means the runtime has to handle starting and stopping applications in the proper order. This provides a basis for cleanly encapsulating functionality and encourages reusability in a way that goes far beyond that of modules.
There are two types of applications: normal
applications and library
applications. Normal applications start a top-level supervisor,
which in turn starts its children, forming the supervision tree. Library
applications contain library modules but do not start a supervisor or
processes themselves; the function calls they export are invoked by
workers or supervisors running in a different application. A typical
example of a library application is stdlib, which contains all of the OTP standard libraries such as
supervisor, gen_event, gen_server,
and gen_fsm.
Behind the scenes in the Erlang VM a process called the application controller starts on every node. For every OTP application, the controller starts a pair of processes called the application master. It is the master that starts and monitors the top-level supervisor and takes action if it terminates (Figure 9-2).
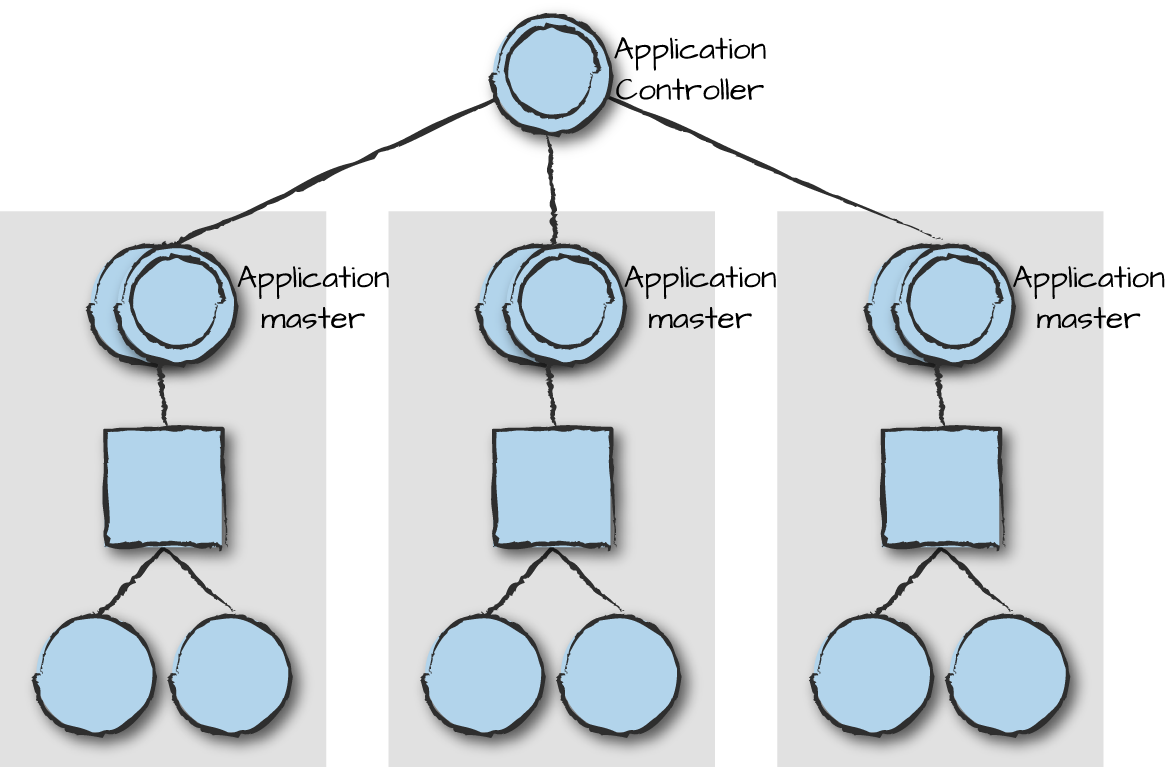
Figure 9-2. Application controller
When using releases (covered in Chapter 11), the Erlang runtime treats each application as a single unit; it can be loaded, started, stopped, and unloaded as a whole. When loading an application, the runtime system loads all modules and checks all its resources. If a module is missing or corrupt, startup fails and the node is shut down. When starting an application, the master spawns the top-level supervisor, which in turn starts the remainder of the supervision tree. If any of the behaviors in the supervision tree fail at startup, the node is also shut down. When stopped, the application master terminates the top-level supervisor, propagating the shutdown exit signal to all behavior processes in the supervision tree. Finally, when unloading an application, the runtime purges all modules for that application from the system.
Now that we have a high-level overview of how everything is glued together, let’s start looking at the details.
The Application Structure
Applications are packaged in a directory that follows a special structure and naming convention. Tools depend on this structure, as do the release-handling mechanisms. A typical application directory has the structure shown in Figure 9-3, containing the ebin, src, priv, and include directories.
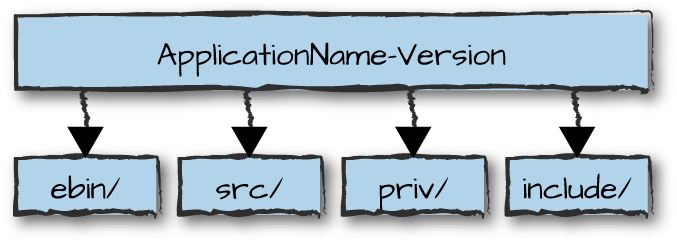
Figure 9-3. Application structure
The name of the application directory is the name of the application followed by its version number. This allows you to store different versions of the application in the same library directory, using the code search path to point to the one being used. Subdirectories of an application include:
- ebin
Contains the beam files and the application configuration file, also known as the app file
- src
Contains the Erlang source code files and include files that you do not want other applications to use
- priv
Contains non-Erlang files needed by the application, such as images, drivers, scripts, or proprietary configuration files
- include
Contains exported include files that can be used by other applications
Other nonstandard directories, such as doc for documentation, test for test cases, and examples, can also be part of your application. What sets nonstandard directories apart from the ones in the previous list is that the runtime system and tools allow you to access the standard directories by application name, without having to reference the version. For instance, when you load an application, the code search path for that application will point straight to the ebin directory of the version you are using. Or, if you want to include the .hrl file of another application, the include path in the makefiles will point to the correct version. This doesn’t happen with nonstandard directories, and as such, you or your tools have to figure out the path.
Let’s have a look at this structure in more detail by following an example in the OTP distribution. Remember that the directory structure of any OTP application in the Erlang distribution will be the same as those of the applications you are implementing in your system.
Go to the Erlang root directory, and from there, cd
into the lib directory. If you are
unsure where Erlang is installed, start a shell and determine the location
of the lib directory by typing code:lib_dir().. The lib directory contains all of the applications included when installing
Erlang. If you have upgraded your release or installed patches, you might
find more than one version of some applications. The versions of the
applications will differ from release to release, so what you see might
differ from the examples in this chapter.
Let’s have a look at the contents of the lib directory and the latest version of the runtime tools application runtime_tools, which should be included in every release:
1>code:lib_dir()."/usr/local/lib/erlang/lib" 2>halt().$cd /usr/local/lib/erlang/lib$ls...<snip>... appmon-2.1.14.2 erts-5.7.5 public_key-0.18 asn1-1.6.13 erts-5.8.1 public_key-0.5 asn1-1.6.14.1 et-1.4 public_key-0.8 asn1-2.0.1 et-1.4.1 reltool-0.5.3 common_test-1.4.7 et-1.4.4.3 reltool-0.5.4 common_test-1.5.1 eunit-2.1.5 reltool-0.6.3 common_test-1.7.1 eunit-2.2.4 runtime_tools-1.8.10 compiler-4.6.5 gs-1.5.11 runtime_tools-1.8.3 compiler-4.7.1 gs-1.5.13 runtime_tools-1.8.4.1 ...<snip>... $cd runtime_tools-1.8.10/$lsdoc examples info src ebin include priv
The doc directory and info file are nonstandard, and as such have nothing to do with OTP (the Ericsson OTP team uses them for documentation purposes). Erlang developers often add other application-specific directories and files, such as test and examples. No guarantees exist that these nonstandard directories and files will be retained between releases. If you look at different versions of the runtime-tools application, for example, you will see that earlier versions have an info file that is no longer present in later versions.
Let’s focus on the OTP standard directories. If you cd
into the ebin directory of the
runtime_tools application and examine its contents,
you will find .beam files, an
.app file, and possibly an .appup file. The .beam files, as you likely already know, contain Erlang byte code. The .app file is a
mandatory application resource file we explore in more detail in “Application Resource Files”. The .appup file might
be there if you have at some point upgraded your application. We cover
this file in more detail in Chapter 12 when
looking at software upgrades.
The src directory contains the Erlang source code. If the modules in this directory use one or more .hrl files that are not exported to be used by other applications, put them here. The current working directory is by default always included in the include file search path, so when compiling, files you put here will be picked up. It is the responsibility of your build system to ensure that beam files resulting from compilation are moved from the src to the ebin directory. Makefiles and tools like rebar3 (covered in “Rebar3”) normally do this for you.
Macros and records defined in include files are often part of interface descriptions, requiring modules in other applications to have access to these definitions. The include directory is used in the build process to provide access to the .hrl files stored in it. Without having to know the location of the include file directory or the application version, you can use the following directive:
-include_lib("Application/include/File.hrl").
where Application is the application name
without the version and
File.hrl is the name of
the include file. The compiler will know which version of the application
you are working with, find the directory, and automatically include the
file without you having to change the version numbers between releases.
Even if include files do not require the .hrl
extension, it is good practice to always use it. Version dependencies are
handled in release files, covered in Chapter 12.
If you run grep ^-include_lib ssl*/src/*.erl from your
Erlang lib directory to examine the
src directories of all the versions
of the ssl application installed on your system, you
will notice that some of the modules include .hrl
files from other applications, such as public_key and
kernel. There will also be a few include files stored
directly in the src directory, which
are used only by the ssl application itself.
The priv directory contains non-Erlang-specific resources. They could be
linked-in drivers, shared libraries for native implemented functions
(NIFs), executables, graphics, HTML pages, JavaScript, or
application-specific configuration files—basically, any source the
application needs at runtime that is not directly Erlang-related resides
here. In the case of the runtime_tools application,
the priv directory includes source
and object code of its trace drivers. Because the path of the priv directory will differ based on the version
of the application you are running, use
code:priv_dir(Application) in your code to generically find
it.
The ebin and priv directories are usually the only ones shipped and deployed on target machines. This will probably answer your question as to why the mandatory application resource file is included in the ebin directory and not src. If you look at other applications shipped as part of the standard distribution, you will also notice that the priv directory is not mandatory if it is not used. The sasl application, for example, has no priv directory, and there are other such applications as well.
Although it is up to you whether you ship source code and documentation with your products, it is not a good idea to bundle them up with your release deployed on target machines, because once you’ve upgraded your beam files, no checks are made to ensure the source code is up to date. Once, when called in to resolve an outage, we were reading the code on the production machines until we realized it was the first release of the code, now woefully out of date as the sources had since been patched, rewritten, cleaned up, and redeployed. After all, those who deployed the new beam files knew the source code on the target machines was not up to date. They also knew that they were not always the ones supporting the system, but assumed we would be using the source code repository, or that we would just ask. Should you find yourself in a similar predicament, follow our words of wisdom and always start with the assumption that those supporting the systems you have written and deployed are antisocial axe murderers who know where you live. They will not speak to you in the middle of the night when called to deal with an outage caused by a bug in your code, but might come knocking on your door at dawn once the system is operational again.
And while we have your attention, please, never ever deploy the compiler application and your system source code with production systems. If you do, you are really asking for trouble, because you will end up changing and compiling the code on target machines in an attempt to resolve the issue. Assuming it is the correct version of the code (which it probably isn’t), and assuming it actually solves the problem (which it probably won’t), there is still the risk you will forget to commit the changes back to your actual source code repository. Don’t forget all of this is happening at 3 AM, and all you want is to return to sleep. Code should be taken from the repository and tested in a test environment before deploying it to a live system. No matter how urgent the fix, don’t cut corners, because you will risk paying the price later, irrespective of the time of day (or night).
The Callback Module
The application behavior is no different from other OTP behaviors. The
module containing the generic code, application, is part of the
kernel library, and a callback module contains all of the
specific code (Figure 9-4).
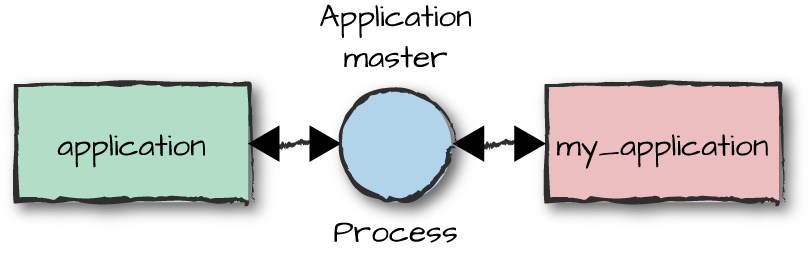
Figure 9-4. Application behavior
The behavior directive must be included in the callback module, along with the mandatory and optional callbacks. Of all behaviors, the application callback module is the simplest. Unless you are dealing with takeovers and failovers in distributed environments or complex startup strategies, expect your application callback module to require no more than a few simple lines of code.
Starting and Stopping Applications
The callback module is invoked when starting your application. You
start it by calling application:start(Application), where
Application is the application name. This call loads all of
the modules that are bundled with the application and starts the master
processes, one of which calls the Mod:start(StartType,
StartArgs) callback function in the application callback module.
The start/2 function has to return {ok, Pid},
where Pid is the process identifier of the top-level
supervisor. If the application is not already loaded, application:load(Application) is
called prior to starting the master processes. Our application callback
module looks something like this:
-module(bsc).-behavior(application).%% Application callbacks-export([start/2,stop/1]).start(_StartType,_StartArgs)->bsc_sup:start_link().stop(_Data)->ok.
The first argument, _StartType, is ignored by most
applications; it is usually the atom normal, but if we’re running distributed
applications with automated failover and takeover, it could have the
value {takeover, Node} or {failover, Node}. We
look at these values later in the chapter. The second argument,
_StartArgs, comes from the mod key of the
application resource file, described in “Application Resource Files”.
Figure 9-5 shows how the application callback
module starts the top-level supervisor. The application callback
module’s start/2 function typically just calls the start_link function provided by the
top-level supervisor. For example, the bsc:start/2 function
shown earlier simply calls bsc_sup:start_link/0.
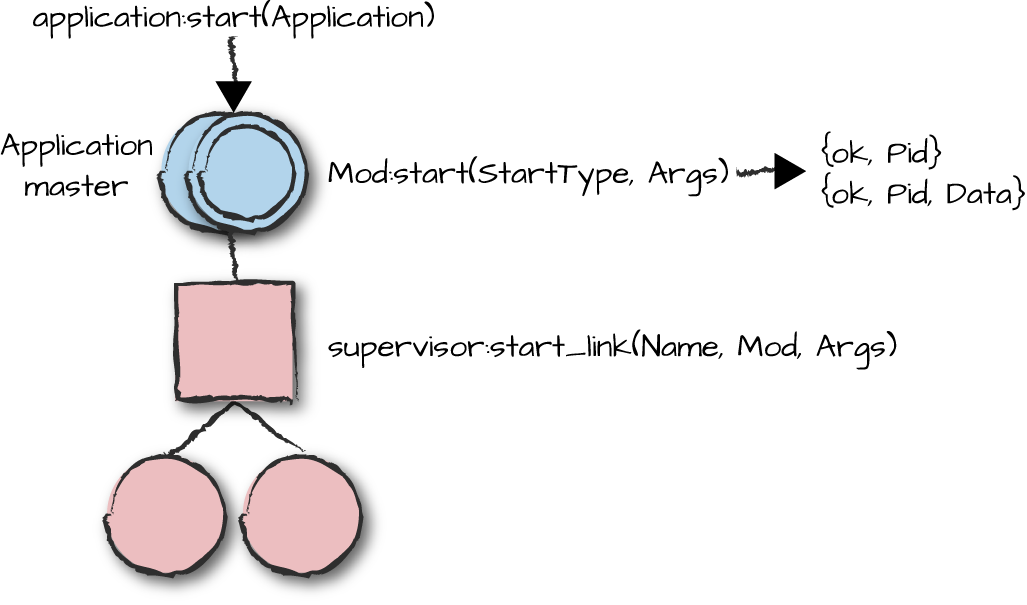
Figure 9-5. Starting applications
In our case, bsc_sup:start_link/0 returns {ok,
Pid}, which is also what bsc:start/2 returns.
Another valid return value is {ok, Pid, Data}, where the
contents of Data are stored and later passed to the
stop/1 callback function (Figure 9-6).
If you do not return any Data, just ignore the argument
passed to stop/1 (in case you’re curious, it will be bound
to [] in that case).
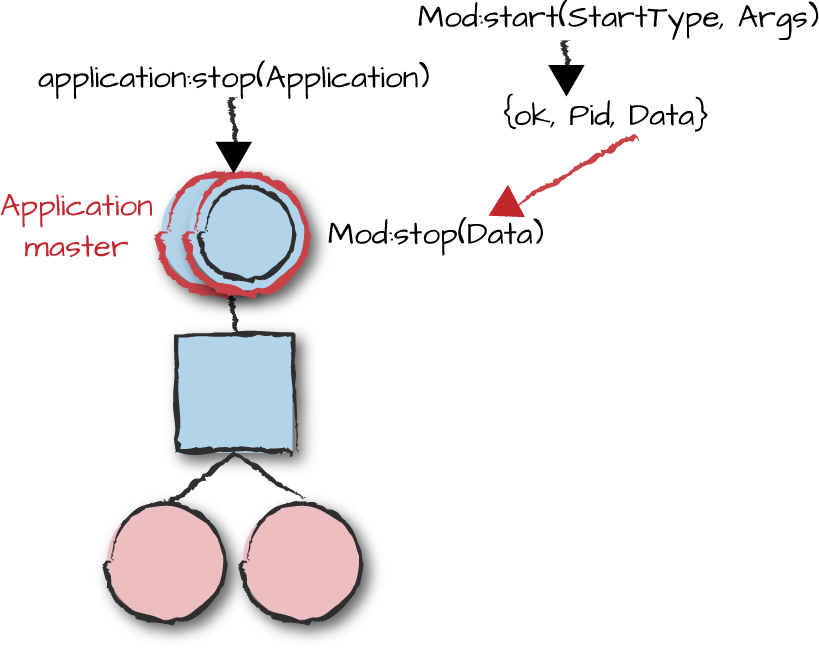
Figure 9-6. Stopping applications
To stop an application, use application:stop(Application). This
results in the callback function Mod:stop/1 being called
after the supervision tree has been
terminated, including all workers and supervisors.
Mod:prep_stop/1 is an equally important but optional
callback invoked before the processes are terminated. If you need to
clean anything up before terminating your supervision tree,
prep_stop/1 is where you trigger it.
Let’s try loading, starting, and stopping the
sasl application from the standard OTP
distribution. Depending on how you installed Erlang,
sasl might or might not be started automatically
when you start the shell. You can find out by typing application:which_applications().. In
the following example, we do this in shell command 1, getting back a
list of tuples. The first element is the application name, the second is
a descriptive string,1 and the third is a string denoting the application
version. When you start Erlang, its boot script determines which
applications it starts. If the sasl application is
in there, first stop it before attempting to run the example. In our
installation of Erlang, it is not started:
Example 9-1. Loading an application
1>application:which_applications().[{stdlib,"ERTS CXC 138 10","2.0"}, {kernel,"ERTS CXC 138 10","3.0"}] 2>application:load(sasl).ok 3>application:start(sasl).ok 4> =PROGRESS REPORT==== 17-Feb-2014::19:51:08 === supervisor: {local,sasl_safe_sup} started: [{pid,<0.42.0>}, {name,alarm_handler}, {mfargs,{alarm_handler,start_link,[]}}, {restart_type,permanent}, {shutdown,2000}, {child_type,worker}] ...<snip>... 4>application:stop(sasl).=INFO REPORT==== 17-Feb-2014::19:51:23 === application: sasl exited: stopped type: temporary ok
The system architecture support libraries (sasl) application is a collection of tools for building, deploying, and upgrading Erlang releases. It is part of the minimal OTP release; together with the kernel and stdlib applications, it has to be included in all OTP-compliant releases. We cover all of this in more detail later.
In our example, we load sasl in shell command
2 and start it in shell command 3. You will notice that when we start
the application, a long list of progress reports is printed in the shell
(we deleted all but the first one from our output).
sasl starts its top-level supervisor, which in turn
starts other supervisors and workers. These progress reports come from
the supervisors and workers started as part of the main supervision
tree. We stop the application in shell command 4. Before reading on,
have a look at the source code of the sasl callback module,
defined in the file sasl.erl. If
you’re unsure where to find it, use the shell command m(sasl). It will tell you where the
beam file is located. The source code is up a level, and then down again
in a directory called src. The
functions to look at in the source code are start/2 and
stop/1.
Application Resource Files
Every application must be packaged with a resource file, often
referred to as the app file. It
contains a specification consisting of configuration data, resources, and
information needed to start the application. The specification is a tagged
tuple of the format {application, Application, Properties},
where Application is an atom denoting the application name
and Properties is a list of tagged tuples.
Let’s step through the sasl
application resource file before putting one together ourselves for the
mobile phone example. This is version 2.3.3 of the application; be aware
the contents of your app file might differ based on the release you
downloaded. Looking at it, you should immediately spot mod,
which points out the application callback module and arguments passed to
the start/2 callback function:
{application,sasl,[{description,"SASL CXC 138 11"},{vsn,"2.3.3"},{modules,[sasl,alarm_handler,format_lib_supp,misc_supp,overload,rb,rb_format_supp,release_handler,release_handler_1,erlsrv,sasl_report,sasl_report_tty_h,sasl_report_file_h,si,si_sasl_supp,systools,systools_make,systools_rc,systools_relup,systools_lib]},{registered,[sasl_sup,alarm_handler,overload,release_handler]},{applications,[kernel,stdlib]},{env,[{sasl_error_logger,tty},{errlog_type,all}]},{mod,{sasl,[]}}]}.
Let’s step through the properties in order. The property list contains a set of standard items. All items are optional—if an item is not included in the list, a default value is set—but there are a few that almost all applications set. The list of standard items includes:
{description, Description}where
Descriptionis a string of your choice. You will see the description string surface when you callapplication:which_applications()in the shell. The default value is an empty string.{vsn, Vsn}where
Vsnis a string denoting the version of the application. It should mirror the name of the directory and in automated build systems is set by scripts, not by hand. If omitted, the default value is an empty string.{modules, Modules}where
Modulesis a list of modules defaulting to the empty list. The module list is used when creating your release and loading the application, with a one-to-one mapping between the modules listed here and the beam files included in the ebin directory. If your module beam file is in the ebin directory but is not listed here, it will not be loaded automatically.2 This list is also used to check the module namespace for clashes between applications, ensuring names are unique.Each module is specified as an atom denoting the module name, as in the
saslexample. Up to R15, it was also possible to specify the module version{Module, Vsn}, as it appeared in the-vsn(Vsn)directive in the module itself. This is no longer the case.{registered, Names}where
Namescontains a list of registered process names running in this application. Including this property ensures that there will be no name clashes with registered names in other applications. Missing a name will not stop the process from running, but could result in a runtime error later when another application tries to register the same name. If omitted, the default value is the empty list.{applications, AppList}where
AppListis a list of application dependencies that must be started in order for this application to start. All applications are dependent on the kernel and stdlib applications, and many also depend on sasl. Dependencies are used when generating a release to determine the order in which applications are started. Sometimes, only an application such as sasl is provided, which in turn depends on kernel and stdlib. This will work, but it makes the system harder to maintain and understand. The default for this property is the empty list, but it is extremely unusual to omit it since doing so implies there are no dependencies on other applications.{env, EnvList}where
EnvListis a list of{Key, Value}tuples that set environment variables for the application. Values can be retrieved using functions from theapplicationmodule:get_env(Key)orget_all_env()by processes in the application, orget_env(Application, Key)andget_all_env(Application)for processes that are not part of the application. Environment variables can also be set through other means covered later in this chapter. This property defaults to the empty list.{mod, Start}where
Startis a tuple of the format{Module, Args}containing the application callback module and arguments passed to its start function. Each tuple results in a call toModule:start(normal, Args)when the application starts. Omitting this property will result in the application being treated as a library application, started by a supervisor or worker in another application, and no supervision tree will be created at startup.
Here are some other properties that are not included in the sasl.app file example but that are useful and are often included in other app files:
{id, Id}where
Idis a string denoting the product identifier. This property is used by overzealous configuration management trolls but, as you can see, not by the OTP team. The default value is the empty string.{included_applications, Apps}where
Appsis a list of applications included as subapplications to the main one. The difference with included applications is that their top-level supervisors have to be started by one of the other supervisors. We cover included applications in more depth later in this chapter. Omitting this property will default it to the empty list.{start_phases, Phases}where
Phasesis a list of tuples of the format{Phase, Args}:Phaseis an atom andArgsis a term. This allows the application to be started in phases, allowing it to synchronize with other parts of the system and start workers in the background. BeforeModule:start/2returns,Module:start_phase(StartPhase, StartType, Args)will be called for every phase.StartTypeis the atomnormal, or the tuples{takeover, Node}or{failover, Node}. We cover start phases in more detail later in this chapter.
The Base Station Controller Application File
Having looked at how app files are constructed, let’s create one we can use
in the base station controller. Alongside the description
and application vsn, we list all of the
modules that form the application. We follow that with a
list of the registered worker and supervisor process names,
and state in the applications list that the bsc application is dependent on sasl, kernel, and stdlib. We do not set any env
variables, but explicitly keep the list empty for readability reasons.
And finally, the application callback module mod is set to
bsc, passing [] as a dummy argument:
{application,bsc,[{description,"Base Station Controller"},{vsn,"1.0"},{modules,[bsc,bsc_sup,frequency,freq_overload,logger,simple_phone_sup,phone_fsm]},{registered,[bsc_sup,frequency,frequency_sup,overload,simple_phone_sup]},{applications,[kernel,stdlib,sasl]},{env,[]},{mod,{bsc,[]}}]}.
With the app file completed, all that remains is to place it in the ebin directory, compile the source code, and make sure the resulting beam files are placed in the ebin directory.
Starting an Application
When starting the Erlang emulator, include the path to your application ebin directory. This is a good habit when testing; bsc might be one of the many applications we have written and for which we need a load path, so starting Erlang directly from the ebin directory might not always be an option. Adding a path will no longer be a problem when implementing a release, but do it for now, as it is not set automatically. In our example, we add the path when starting Erlang using:
erl -pa bsc-1.0/ebin
but you could also use code:add_patha/1 to add the path within the
Erlang shell.
Let’s try starting the bsc
application. In shell prompt 1, we fail because sasl, one of the applications bsc depends on, has not been started. We could
have avoided that by using application:ensure_all_started/1,
which starts up an application’s dependencies and then starts the
application itself, but here we simply resolve it by starting
sasl in shell command 2 and then starting
bsc again in shell command 3. For every child started
by our top-level supervisor bsc_sup, we
get a progress report from sasl. This is all
happening behind the scenes as a result of using OTP behaviors:
1>application:start(bsc).{error,{not_started,sasl}} 2>application:start(sasl)....<snip>... =PROGRESS REPORT==== 9-Jan-2016::18:47:09 === application: sasl started_at: nonode@nohost ok 3>application:start(bsc).=PROGRESS REPORT==== 9-Jan-2016::18:47:40 === supervisor: {local,bsc} started: [{pid,<0.51.0>}, {id,freq_overload}, {mfargs,{freq_overload,start_link,[]}}, {restart_type,permanent}, {shutdown,2000}, {child_type,worker}] =PROGRESS REPORT==== 9-Jan-2016::18:47:40 === supervisor: {local,bsc} started: [{pid,<0.53.0>}, {id,frequency}, {mfargs,{frequency,start_link,[]}}, {restart_type,permanent}, {shutdown,2000}, {child_type,worker}] =PROGRESS REPORT==== 9-Jan-2016::18:47:40 === supervisor: {local,bsc} started: [{pid,<0.54.0>}, {id,simple_phone_sup}, {mfargs,{simple_phone_sup,start_link,[]}}, {restart_type,permanent}, {shutdown,2000}, {child_type,worker}] =PROGRESS REPORT==== 9-Jan-2016::18:47:40 === application: bsc started_at: nonode@nohost ok 4>l(phone), phone:start_test(150, 500).*DBG* <0.123.0> got {'$gen_sync_all_state_event', {<0.34.0>,#Ref<0.0.5.140>}, {outbound,109}} in state idle <0.123.0> dialing 109 ...<snip>...
After starting the base station, we took it for a test run by
starting a few hundred phones that randomly call each other. Because the
phone module is not part of the application, we load it
before calling phone:start_test/2. In our case, not doing
this would not make a difference, but it might if we were running in
embedded mode in production, where modules are not loaded automatically.
We cover different start modes when looking at release handling in Chapter 11.
If you have run this example, keep the Erlang shell open, type observer:start()., and
read on.
Environment Variables
Erlang uses environment variables mainly to obtain configuration
parameters when initializing the application behaviors. You can set,
inspect, and change these variables. Start an Erlang shell, make sure the
sasl application is running, and type
application:get_all_env(sasl).. Don’t worry about the meaning
of the environment variables for now—we explain them later,
when we cover sasl reports—but be aware
that they are not the same as the environment variables supported by your
operating system shells. For now, we focus just on how they are set and
retrieved.
If you ran the get_all_env(sasl) call as we suggested,
you saw that it returns the environment variables belonging to the
sasl application. If you want a
specific variable, say errlog_type, use
application:get_env(sasl, errlog_type). If the process
retrieving the environment variables is part of an application’s
supervision tree, you can omit the application name and just call
application:get_all_env() or
application:get_env(Key).
Using functionality similar to that in the application:get_application() call, OTP
uses the Erlang process group leader to determine the application to which
the process belongs. In our examples we are using the shell, which is not
part of the sasl application supervision tree, so we
have to specify the application.
Where are these environment variables set? If you look at the
sasl.app file, you will find them in
the env attribute of the application resource file. The app
file usually contains default values you might want to override on a
case-by-case basis, depending on the system and use of the application.
This is best done using the system configuration file. It is a plain-text
file with the .config suffix
containing an Erlang term of the format:
[{Application1,[{Key1,Value1},{Key2,Value2},...]},{Application2,[{Key2,Value2}|...}].
Tell the application controller which configuration file to read when starting the Erlang VM by using:
erl -config filenamewhere filename is the name of the system
configuration file, with or without the .config suffix.
If prototyping, testing, or troubleshooting, you can override values set in the app and config files at startup in the command-line prompt using:
erl -applicationkeyvalue
Although convenient, this approach should not be used to set values in production systems. For the sake of clarity, stick to app and config files, as they will be the first point of call for anyone debugging or maintaining the system.
With this knowledge at hand, let’s write our own bsc.config file containing the frequencies for our frequency allocator example and override some of the sasl environment variables:
[{sasl,[{errlog_type,error},{sasl_error_logger,tty}]},{bsc,[{frequencies,[1,2,3,4,5,6]}]}].
This file overrides the errlog_type and sasl_error_logger environment variables set in
the app file. To test the configuration parameters from the shell, start the
Erlang node and provide it with the name of the configuration file, placed
in the same directory where you start Erlang. In production systems,
config files are placed in specific release directories. We look at them
in more detail in Chapter 11.
In the following command starting the erl shell, we take configuration a step further
and override sasl_error_logger, setting
its value to false. We do this in the
remainder of our examples to suppress the progress reports:
$erl -config bsc.config -sasl sasl_error_logger false -pa bsc-1.0/ebinErlang/OTP 18 [erts-7.2] [smp:8:8] [async-threads:10] [kernel-poll:false] Eshell V7.2 (abort with ^G) 1>application:start(sasl).ok 2>application:get_all_env(sasl).[{included_applications,[]}, {errlog_type,error}, {sasl_error_logger,false}] 3>application:start(bsc).ok 4>application:get_env(bsc, frequencies).{ok,[1,2,3,4,5,6]} 5>application:set_env(bsc, frequencies, [1,2,3,4,5,6,7,8,9]).ok 6>application:get_env(bsc, frequencies).{ok,[1,2,3,4,5,6,7,8,9]}
In shell command 1, we start sasl, retrieving all of its environment variables in shell command 2. Note the final values of the environment variables:
errlog_typeis set in the bsc.config file, overriding the value set in the app file.included_applicationscomes from the app file. Not originally an environment variable, it is converted into one by the application controller.sasl_error_loggeris set in the app file, overridden in the config file, and overridden again on the Unix prompt level when starting Erlang.
The frequencies environment variable can be
used in the get_frequencies() call of the frequency server to
retrieve the frequencies. Note how we do not have to specify the
application name in the code, because the runtime can determine the
application from the group leader of the process making the call. In
earlier versions of the frequency module, the
get_frequencies/0 function had a hardcoded list of
frequencies. In this example, the code will work with or without the
bsc.config file:
get_frequencies()->caseapplication:get_env(frequencies)of{ok,FreqList}->FreqList;undefined->[10,11,12,13,14,15]end.
In shell command 5 in our example interaction, we set environment variables directly in the Erlang shell, retrieving them in shell command 6. The application name is optional; if not provided, the environment variables set and retrieved will be those of the application belonging to the process executing the call. In our example, we provided the application because the shell process is not part of the bsc application.
Warning
Although there is nothing stopping you from setting environment
variables in the shell using the application:set_env functions, it is
advisable to do so only for applications you have written yourself or
know well. For third-party applications, including those that are part
of the Erlang distribution, changing environment variables once the
application has been started is dangerous. As you do not know when and
where the application reads these environment variables, changing them
may cause it to enter an inconsistent state and behave unexpectedly. You
are also not guaranteed your changes will survive a restart. Do this at
your own risk, and only if you know how the values are read and
refreshed by the applications using them.
Application Types and Termination Strategies
When we stopped the sasl application in Example 9-1, we got the following info report:
=INFO REPORT==== 17-Feb-2014::19:51:23 ===
application: sasl
exited: stopped
type: temporaryDid you notice that the application type was set to
temporary? The type determines what happens to the virtual
machine and to other applications within it when your application
terminates. The temporary type is the default assigned when
you start an application using application:start(Name). Three
application types exist:
temporaryWhen an application of this type terminates, no matter what the reason, it does not affect other running applications or the virtual machine.
transientIf an application of this type terminates with reason
normal, other applications are not affected. For abnormal terminations, other applications are terminated, together with the virtual machine. This option is relevant only when writing your own supervisor behavior (see Chapter 10), because supervisors use reasonshutdownto terminate.permanentIf a permanent application terminates for whatever reason, normal or abnormal, all other running applications are also terminated together with the virtual machine.
These options become relevant when creating our own releases, as
they can be set in the start scripts. In proper OTP releases, all
applications tend to be permanent. Top-level supervisors in an application
should never terminate. When they do, they assume that your restart
strategy failed, so the whole node is taken down. Stopping an application with application:stop/1, however,
has no effect on other applications, irrespective of type.
Distributed Applications
OTP comes with a convenient distribution mechanism for migrating applications across nodes. It can handle the majority of cases where you need an instance of an application running in your cluster, and can act as a stopgap measure until a more complex solution can be put in place. The majority of cases assume reliable networks, so use with care and make sure you have covered your edge cases should a network partition occur.
Distributed applications are managed by a process called the distributed application
controller, implemented in the dist_ac module and
registered with the same name. You will find an instance of this process
in the kernel supervision tree running on every distributed node.
To run your distributed application, all you need to do is configure a few environment variables in the kernel application, ensure that requests are transparently forwarded to the node where the applications are running, and then test, test, and test again. You have to specify the precedence order for the nodes where you want the application to run. If the node on which an application is running fails, the application will fail over to the next node in the precedence list. If a newly started or connected node with higher precedence appears in the cluster, the application will be migrated to that node in what OTP calls a takeover.
Let’s assume our system consists of a cluster of four nodes, n1@localhost, n2@localhost, n3@localhost, and n4@localhost. Let’s create a configuration file, dist.config, setting the kernel environment variables distributing our bsc application across them:
[{kernel,[{distributed,[{bsc,1000,[n1@localhost,{n2@localhost,n3@localhost},n4@localhost]}]},{sync_nodes_mandatory,[n1@localhost]},{sync_nodes_optional,[n2@localhost,n3@localhost,n4@localhost]},{sync_nodes_timeout,15000}]},{bsc,[{frequencies,[1,2,3,4,5,6]}]}].
Note that if you intend to run the distributed bsc example, you may need to replace all occurrences of the string “localhost” in the dist.config file with your own computer’s host name.
Of the environment variables in the kernel
application, the first we need to set is distributed. It consists of a list of tuples
containing the application we want to distribute, a timeout value, and the
distributed list of nodes and node tuples, which defines the order of
precedence of nodes on which we want the application to run. So, this
list:
[{bsc,1000,[n1@localhost,{n2@localhost,n3@localhost},n4@localhost]}]
specifies
bsc as the application, 1000 (measured in
milliseconds) as the time to wait for the node to come back up, and the
following node precedence:
[n1@localhost,{n2@localhost,n3@localhost},n4@localhost]
The
precedence specifies that the application will start on n1.
Should that node fail or be shut down, the distributed application
controller will wait 1 second and then fail the application over to either
n2 or n3. They have been given the same
precedence by being grouped into the same tuple. If both n2
and n3 fail, the controller will check to see whether
n1 has come back up and, if it is still down, will fail the
application over to n4. If one of the other nodes comes back
up, the application is later moved via a takeover to the node with the
highest precedence.
The sync_nodes_mandatory and
sync_nodes_optional environment variables specify the nodes
to be connected into the distributed system. When starting the system, the
distributed application controller tries to connect the specified nodes,
waiting for the number of milliseconds specified in the
{sync_nodes_timeout, Timeout} environment variable. If you
omit the timeout when defining the nodes in your kernel environment
variables, the timeout defaults to 0.
The {sync_nodes_mandatory, NodeList} environment
variable defines the nodes with which the distributed application
controller must synchronize; the system
will start only if all of these nodes are started and connected to each
other within Timeout milliseconds.
The environment variable {sync_nodes_optional,
NodeList} specifies nodes that can also be connected at system
startup, but unlike mandatory nodes, the failure of any of these nodes to
join the cluster within the specified Timeout does not
prevent the system from starting up.
The best way to understand the environment variable settings is to play with the dist.config configuration file. Let’s first start node n2 on its own:
$ erl -sname n2@localhost -config dist -pa bsc-1.0/ebinThis node will wait the 15 seconds set in the
sync_nodes_timeout value for n1 to come up. If
the node fails to connect to n1 within that time frame, it
will terminate, regurgitating a long and to the untrained eye
incomprehensible error message. Nodes n3 and n4
are optional, so assuming n1 comes up within the timeout
period, n2 will also wait for these two nodes within the same
period, after which it starts normally whether or not n3 and
n4 have connected.
Let’s try again, but this time, before starting n2,
start n1 and n3:
$erl -sname n1@localhost -config dist -pa bsc-1.0/ebin$erl -sname n3@localhost -config dist -pa bsc-1.0/ebin
The nodes will wait 15 seconds for the optional nodes to come up. If
they don’t, the nodes will start regardless. You can try deleting
n4 from the config file (or decide to start it), avoiding the
timeout if the other nodes are up.
When all nodes are up, let’s start the sasl and
bsc applications on all nodes, starting with
n3, followed by n2 and n1. Type the
following in all three Erlang shells and pay attention to when the shell
command returns:
application:start(sasl),application:start(bsc).
You will notice that the shell will hang in n2 and
n3, returning only when the bsc
application is started in n1, as it is the node running with
the highest priority. If you start the observer and inspect the
Applications tab on the different nodes, you will notice that the
supervision tree is started only on n1. Looking at the
progress reports for n2 and n3, you will notice
that the bsc application is also
started, but without its supervision tree.
Keeping an eye on nodes n2 and n3, shut
down node n1 using the halt() shell command.
The application controller will wait 1,000 milliseconds for
n1 to restart. If it doesn’t, you will see the progress
reports for the bsc app being started
on either n2 and n3. In our config file, because
both n2 and n3 have the same precedence, either
one will be chosen nondeterministically. In Figure 9-8, we assume that the chosen node is
n2.
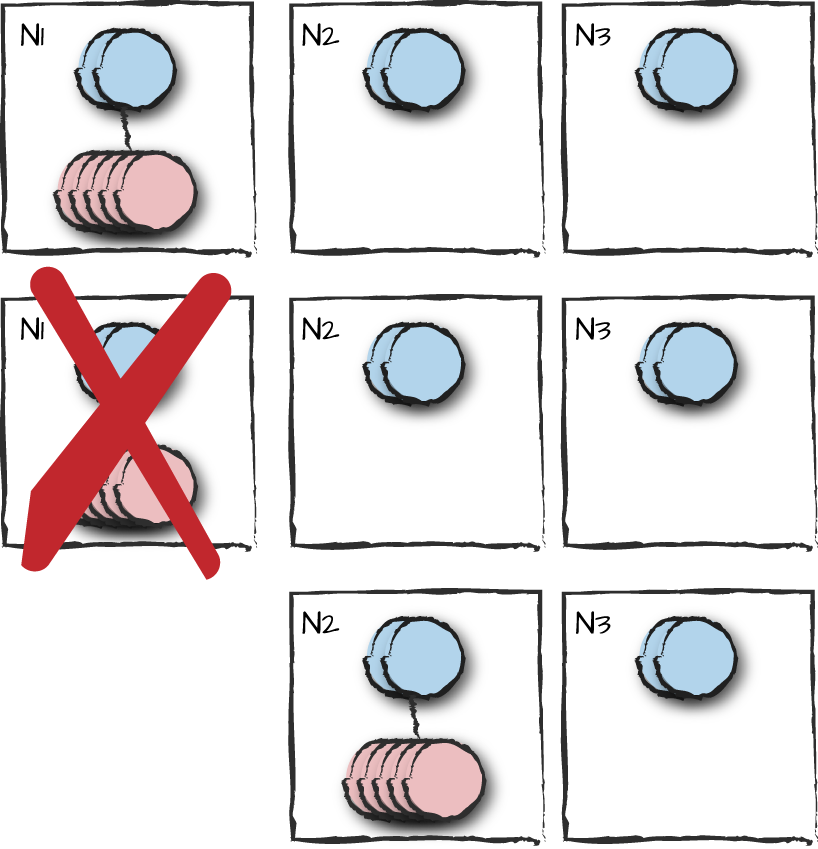
Figure 9-8. Failing over with different precedence
Now that n1 is down, let’s shut down n2 (or n3 if the bsc application was started on it instead). You will see that application fail over to the remaining node (Figure 9-9). Use the observer to check that the supervision tree has started correctly (Figure 9-7). Restart the node you just shut down and observe what happens. You will notice that it hangs for 15 seconds, waiting for n1 to restart. Because n1 is mandatory and has not restarted, the node fails to restart.
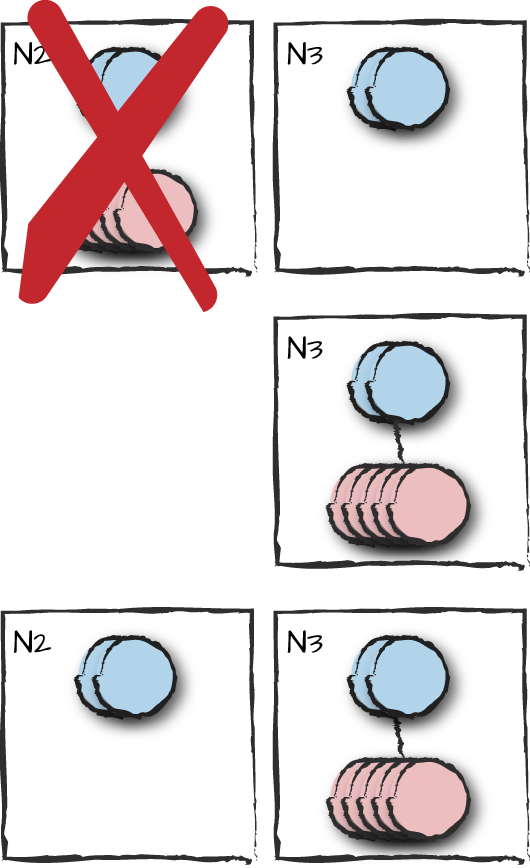
Figure 9-9. Failing over with the same precedence
Restart both n1 and n2 (or n3 if
it was the node that shut down) within 15 seconds of each other. Both will
wait 15 seconds for the nonmandatory node n4 to start. After the timeout, start both
sasl and bsc on n2
using application:start/1. Just as the first time you started the cluster, the application
hangs waiting for bsc to start on
n1 so that the nodes can coordinate
among each other. When you start bsc on
n1, there will be a takeover from
n3, where the behaviors are terminated
and the supervision tree is taken down (Figure 9-10).
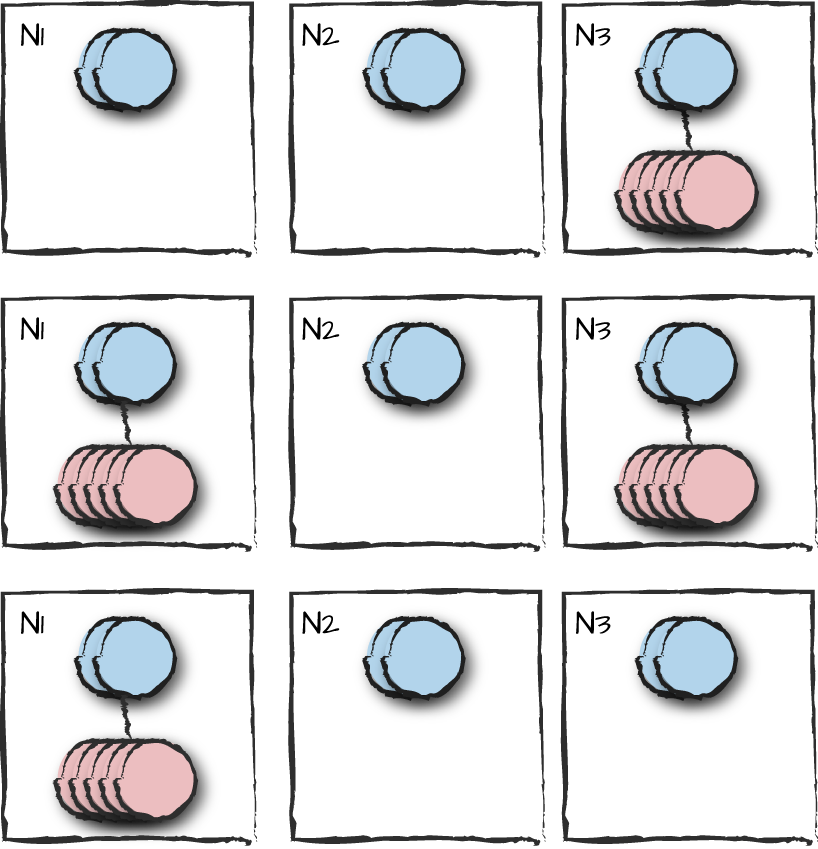
Figure 9-10. Application takeover
This is a limited approach that might cover some use cases and not others. The moral of the story if you go down this route is to pick your mandatory nodes with care. When designing your system with no single point of failure, you should not assume or require any of the nodes to be up at any one time. If there are services you require for a failover or a takeover to be successful, do the checks in start phases when starting the applications or in the worker processes themselves. While this layer can be thin and consist of only a couple hundred lines of code, it is application dependent. Make sure you’ve thought through your design. We look at other approaches to distributed architectures when discussing clusters in Chapter 13.
Start Phases
Some systems are so complex that it is not enough to start each application one at a time. In such systems, applications need to be started in phases and synchronized with each other. Imagine a node that is part of a cluster handling instant messaging:
In a first phase, as a background task, you might want to start loading all of the Mnesia tables containing routing and configuration data. This could take time, as some of the tables might have to be restored because of an abrupt shutdown or node crash.
Once the tables load, the next phase gets your system to a state where you are ready to start accepting configuration requests. We refer to this as enabling the administration state. This might include checking links toward other clusters in the federation that users might want to connect to, configuring hardware, and waiting for all of the other parts of the system, such as the authentication server or logging facility, to start correctly.
When this phase completes, you will be able to inspect and configure the system, but not allow any users to initiate sessions. Your final start phase might be to provide the go-ahead and start allowing users to log on and traffic to run through this node. We refer to this phase as enabling the operational state.
If we add the following parameter in our bsc.app file, we allow three start phases:
{start_phases,[{init,[]},{admin,[]},{oper,[]}]}
In our application callback module source file, bsc.erl, we need to export and define the
callback function start_phase(StartPhase, StartType, Args).
This function will be called for every phase defined in the app file,
after the supervision tree has been started but before
application:start(Application) returns. The
StartPhase argument reflects which phase is currently being
processed. So, in our example, if we added:
start_phase(StartPhase,StartType,Args)->io:format("bsc:start_phase(~p,~p,~p).~n",[StartPhase,StartType,Args]).
to our application callback module bsc.erl and ran it with the updated bsc.app file, we would get the following sequence of events when starting the application. Both these files are in the start_phases directory of the code repository:
$erl -pz bsc-1.0/ebin/ -pa start_phases/ -sasl sasl_error_logger falseErlang/OTP 18 [erts-7.2] [smp:8:8] [async-threads:10] [kernel-poll:false] Eshell V7.2 (abort with ^G) 1>application:start(sasl), application:start(bsc).bsc:start_phase(init,normal,[]). bsc:start_phase(admin,normal,[]). bsc:start_phase(oper,normal,[]). ok
Here, the StartType argument is always the atom
normal, indicating this is a normal
startup. Each phase invokes a synchronous or asynchronous call that
triggers certain operations, as well as setting the internal state that
allows or disallows requests to be handled by the node.
When shutting down the system, we can disable the operational state, stopping new requests from executing but allowing all existing requests to execute to completion. This could make the system reject user login attempts while allowing existing sessions to expire. When there are no more requests going through the node, the operational state can be disabled and the node shut down. This could happen when all the users have logged out, or after a timeout, where the system times out the remaining sessions and disables the operational state. To shut down the node, disable the operational state. A simple example using start phases appears in the next section.
Included Applications
In your app resource file, you have the option of specifying the parameter included_applications. The directory structure
of included applications should be placed in the lib directory, alongside all other applications
in that release. When the main application is started, all included
applications are loaded but not started. It is up to the top-level
supervisor of the main application to start the included applications’
supervision trees. You could start them as dynamic children or as static
ones by returning the child specification in the supervisor
init/1 callback function.
When starting your application, you can either call the
start/2 function in the application callback module, assuming
it returns {ok, Pid} (and not {ok, Pid, Data},
since it is not possible for us to pass that data to the callback
module’s prep_stop/1 callback function as it
expects when it is stopped), or directly call the start_link
function of the top-level supervisor. There is no more to it; it’s as
simple as that!
In every node, included applications may be included only once by other applications. This restriction avoids clashes in the application namespace, ensuring that each module and registered process (local or global) is unique. If you need to start several identical supervision trees in the same node, place the code in a standalone library application. Do not include this application anywhere else other than by dependency and ensure that there are no name clashes with the locally and globally registered processes.
You might be asking yourself, why go through the hassle of included applications when we can instead have a flat application structure, starting the applications individually? The answer lies in start phases.
Start Phases in Included Applications
You can use start phases to synchronize
your included applications at startup. As the included
application supervision trees are started by the main application, you
need to follow a few steps to invoke the start_phase/3
callback function in the application callback module.
First, in your included application app files, make sure you have
included the mod and start_phases parameters.
The callback module is used to determine where the
start_phase/3 call is made. The arguments are ignored,
because the ones in the start_phases item are used.
Finally, in your top-level application, alongside your start
phases, you need to change your mod parameter to:
{mod,{application_starter,[Mod,Args]}}
passing
the application callback module Mod and Args
as arguments. The OTP application_starter module provides the logic
to start your top-level application and coordinate the start phases of
the included applications.
The process is straightforward. The top-level application’s
supervision tree starts the included applications. The first
start_phase/3 function is called in the callback module of
the top-level application, after which all included applications are
traversed in the order they are defined. If one or more of the included
applications have the same phase defined as the one in the top-level
application, start_phase/3 is called for each of these
included applications.
The next start phase in the top-level application is recursively triggered. Start phases defined in the included applications but not in the top-level application are never triggered.
All of what we’ve described is best shown in an example. We create
a top-level application, top_app,
that includes the bsc application.
The top_app callback module is responsible for starting the
supervision tree of the included bsc
application:
-module(top_app).-behavior(application).-export([start/2,start_phase/3,stop/1]).start(_Type,_Args)->{ok,_Pid}=bsc_sup:start_link().start_phase(StartPhase,StartType,Args)->io:format("top_app:start_phase(~p,~p,~p).~n",[StartPhase,StartType,Args]).stop(_Data)->ok.
In our top application’s top_app.app file, we define the
start, admin, and stop phases.
They are different from the start phases in bsc,
which in “Start Phases”, our previous example, were set
to init, admin, and oper. Note
also the included_applications and the value we give the
mod attribute:
{application,top_app,[{description,"Included Application Example"},{vsn,"1.0"},{modules,[top_app]},{applications,[kernel,stdlib,sasl]},{included_applications,[bsc]},{start_phases,[{start,[]},{admin,[]},{stop,[]}]},{mod,{application_starter,[top_app,[]]}}]}.
The start phases work as follows. The top application is started,
which in turn starts the bsc
supervision tree. Once that is successful, the first start phase in
top_app, start, is
triggered. If any of the included applications, in the order they appear
in the included_applications list, also has this phase, it
is also called. If you are trying this on your computer, do not forget
to compile the contents of the top_app directory, and use the bsc.app file in the start_phases directory of this chapter’s code
repository:
$erl -pz bsc-1.0/ebin/ -pa start_phases/ -pa top_app/ -sasl sasl_error_logger falseErlang/OTP 18 [erts-7.2] [smp:8:8] [async-threads:10] [kernel-poll:false] Eshell V7.2 (abort with ^G) 1>application:start(sasl), application:start(top_app).top_app:start_phase(start,normal,[]). top_app:start_phase(admin,normal,[]). bsc:start_phase(admin,normal,[]). top_app:start_phase(stop,normal,[]). ok
We have kept the example simple so as to demonstrate the
principles without getting lost in the business logic. In our example,
we call all of the start phases in the top application, but only
admin in the included one, as it is the only phase they
both have in common.
Combining Supervisors and Applications
Some supervisor callback modules contain only a few lines of code. And if your application does not have to deal with complex initialization procedures, start phases, and distribution, but needs only to start the top-level supervisor, it will be just as compact. A common practice is to combine the two callback modules, as their callback function names do not overlap. While some people will strongly disagree with this practice, you are bound to come across it when reading other people’s code—even code that is part of the standard Ericsson distribution.
For example, cd into the sasl directory of your OTP installation and
have a look at the sasl.erl file. At
the time of writing, version 2.6.1 of the sasl application combined the supervisor
init/1 callback function in its application
module together with the application start/2 and
stop/1 callback functions. In this example, the developers
included only the -behavior(application). directive, but
there is nothing stopping you from including the
-behavior(supervisor). directive as well. The only side
effect is a compiler warning telling you about two behavior directives in
the same callback module. We recommend including both directives, because
it facilitates the understanding of the purpose of the callback module.
Here is a simple example of what combining the supervisor and
application callback modules would look like in our bsc example:
-module(bsc).-behavior(application).-behavior(supervisor).-export([start/2,start_phase/3,stop/1,init/1]).start(_Type,_Args)->{ok,Pid}=supervisor:start_link({local,?MODULE},?MODULE,[]).start_phase(Phase,Type,Args)->io:format("bsc:start_phase(~p,~p,~p).",[Phase,Type,Args]).stop(_Data)->ok.%% Supervisor callbacksinit(_)->ChildSpecList=[child(freq_overload),child(frequency),child(simple_phone_sup)],{ok,{{rest_for_one,2,3600},ChildSpecList}}.child(Module)->{Module,{Module,start_link,[]},permanent,2000,worker,[Module]}.
The SASL Application
Throughout this chapter, we’ve been telling you to look at the SASL callback module, app file, directory structure, and supervision tree, but we have yet to tell you what SASL actually does.
SASL stands for system architecture support libraries. The SASL application (sasl) is a container for useful items needed in large-scale software design. It is one of the mandatory applications (along with kernel and stdlib) required in a minimal OTP release. It is mandatory because it contains all of the common library modules used for release handling and software upgrades.
We cover releases in Chapter 11 and
software upgrades in Chapter 12. SASL doesn’t
stop, however, at handling releases and software upgrades. In “The SASL Alarm Handler”, we looked at the alarm handler, a simple alarm
manager and handler that is started by default when you start any
OTP-based system. SASL also has a very basic way, through its
overload library module, to regulate CPU load in the system.
We cover load regulation in more detail in Chapter 13, when we discuss the architecture of a
typical Erlang node. Have patience.
What we concentrate on in this chapter are the SASL reports used to
monitor the activity in supervision trees when processes are started,
terminated, and restarted. You will have come across SASL reports in the
previous chapters of this book. They are the printouts you see in the
shell when starting applications, supervisors, and worker processes. You
might have noticed that they appeared only when the SASL application was
started and the sasl_error_logger
environment variable was not set to false.
SASL starts an event handler that receives the following reports:
- Supervisor reports
Issued by a supervisor when one of its children terminates abnormally.
- Progress reports
Issued by a supervisor when starting or restarting a child or by the application master when starting the application.
- Error reports
Issued by behaviors upon abnormal termination.
- Crash reports
Issued by processes started with the
proc_liblibrary, which by default include behaviors. We coverproc_libin the next chapter.
Default settings print reports to standard I/O. You can override this by setting environment variables, which allow you to send the reports to wraparound binary logs as well as to limit which reports are forwarded. The formats of the reports vary depending on the version of the OTP release you are running. Let’s have a look at the SASL environment variables that allow you to control the reports:
sasl_error_loggerDefaults to
ttyand installs thesasl_report_tty_hhandler module, which prints the reports to standard output. If you instead specify{file,FileName}, whereFileNameis a string containing the relative or absolute path of a file, thesasl_report_file_hhandler is installed, storing all reports inFileName. If this environment variable is set tofalse, no handlers are installed, and as a result, no SASL reports are generated.errlog_typeCan take the values
error,progress, orall, the default if you omit the variable. Use this variable to restrict the types of error or progress reports printed or logged to file by the installed handler.utc_logAn optional environment variable that, if set to
true, will convert all timestamps in the reports to Universal Coordinated Time (UTC).
The following configuration file stores all the SASL reports in a
text file called SASLlogs. We do this
by setting the sasl_error_logger environment variable to
{file, "SASLlogs"}. We also enable UTC time with the
utc_log environment variable:
[{sasl,[{sasl_error_logger,{file,"SASLlogs"}},{utc_log,true}]},{bsc,[{frequencies,[1,2,3,4,5,6]}]}].
If you start the sasl and bsc applications in a local, nondistributed node, you will find all of the logs stored as plain text in the running directory. In our example, we show just the first and last reports. Note how the UTC tag is appended to the timestamp:
$erl -pa bsc-1.0/ebin/ -config logtofile.configErlang/OTP 18 [erts-7.2] [smp:8:8] [async-threads:10] [kernel-poll:false] Eshell V7.2 (abort with ^G)1> application:start(sasl), application:start(bsc).ok2> halt().$cat SASLlogs=PROGRESS REPORT==== 9-Jan-2016::10:09:25 UTC === supervisor: {local,sasl_safe_sup} started: [{pid,<0.40.0>}, {name,alarm_handler}, {mfargs,{alarm_handler,start_link,[]}}, {restart_type,permanent}, {shutdown,2000}, {child_type,worker}] ...<snip>... =PROGRESS REPORT==== 9-Jan-2016::10:09:33 UTC === application: bsc started_at: nonode@nohost
Text files might be good during your development phase, but when
moving to production, it is best to move to wraparound logs that store
events in a searchable binary format. Because text and binary formats are
implemented by different handlers, they can be added and run alongside
each other. To install the binary log handler,
error_logger_mf_h, you have to set three environment
variables. If any of these are disabled, the handler will not be added.
The environment variables needed are:
error_logger_mf_dirA string specifying the directory that stores the binary logs. The default is a period (
"."), which specifies the current working directory. If this environment variable is set tofalse, the handler is not installed.error_logger_mf_maxbytesAn integer defining the maximum size in bytes of each log file.
error_logger_mf_maxfilesAn integer between 1 and 256 specifying the maximum number of wraparound log files that are generated.
Sticking to our bsc example, let’s try storing
the SASL logs in a binary file using the rb.config configuration file found in the
book’s code repository. Note how we are explicitly turning off the events
sent to the shell by setting the sasl_error_logger
environment variable to false and the
frequencies to the atom crash, rather
than a list of integers, ensuring that the process fails when we try to
allocate a frequency:
[{sasl,[{sasl_error_logger,false},{error_logger_mf_dir,"."},{error_logger_mf_maxbytes,20000},{error_logger_mf_maxfiles,5}]},{bsc,[{frequencies,crash}]}].
We start the bsc application in shell command
1, and cause a crash of the frequency server in shell command 2 when we
try to pattern match the atom crash
into a head and a tail in the allocate/2 function of the
frequency module:
$erl -pa bsc-1.0/ebin -config rb.configErlang/OTP 18 [erts-7.2] [smp:8:8] [async-threads:10] [kernel-poll:false] Eshell V7.2 (abort with ^G) 1>application:start(sasl), application:start(bsc).ok 2>frequency:allocate().=ERROR REPORT==== 9-Jan-2016::19:24:30 === ** Generic server frequency terminating ** Last message in was {allocate,<0.34.0>} ** When Server state == {data,[{"State",{{available,crash},{allocated,[]}}}]} ** Reason for termination == ** {function_clause,[{frequency,allocate, [{crash,[]},<0.34.0>], [{file,"bsc-1.0/src/frequency.erl"}, {line,99}]}, ...<snip>... 3>rb:start().rb: reading report...done. {ok,<0.56.0>} 4>rb:list().No Type Process Date Time == ==== ======= ==== ==== 14 progress <0.37.0> 2016-01-09 19:24:26 13 progress <0.37.0> 2016-01-09 19:24:26 12 progress <0.37.0> 2016-01-09 19:24:26 11 progress <0.37.0> 2016-01-09 19:24:26 10 progress <0.24.0> 2016-01-09 19:24:26 9 progress <0.46.0> 2016-01-09 19:24:26 8 progress <0.46.0> 2016-01-09 19:24:26 7 progress <0.46.0> 2016-01-09 19:24:26 6 progress <0.24.0> 2016-01-09 19:24:26 5 error <0.46.0> 2016-01-09 19:24:30 4 crash_report frequency 2016-01-09 19:24:30 3 supervisor_report <0.46.0> 2016-01-09 19:24:30 2 progress <0.46.0> 2016-01-09 19:24:30 1 progress <0.46.0> 2016-01-09 19:24:30 ok
Try it out yourself in the shell, as it will help you understand how
applications and supervision trees work. The first thing you will notice
is that, even though we set sasl_error_logger to false, we still get an error report. This is
because all the environment variable controls are supervisor, crash, and progress reports. Error reports are printed out irrespective of
configuration file settings. We’ve reduced the size of this particular
error report in the trial run, because our focus is on the report
browser.
Having caused a crash, we start the report browser using
rb:start() in shell command 3. After it reads in all of the
reports, we list them in shell command 4 with rb:list(). If
at any time you do not recall the report browser commands,
rb:help() will list them. The progress reports 14–6 (they are
listed in reverse order, with the oldest having the highest number) are
the ones starting the application and its supervision tree. Let’s start by
inspecting reports 1–5:
The frequency server generates reports 4 and 5 as a result of its abnormal termination. The reports contain complementary information needed for postmortem debugging and troubleshooting.
The supervisor generates report 3 as a result of the termination. It contains the information stored by the supervisor of that particular child.
Reports 1 and 2 are issued by the children being restarted. In our case, it is the frequency server that crashed and the
simple_phone_supsupervisor that was terminated and restarted as a result of therest_for_allstrategy of the top-levelbsc_supsupervisor.
Progress Reports
Progress reports are issued by a supervisor when starting a child, worker or supervisor alike. These reports include the name of the supervisor and the child specification of the child being started. They are also issued by the application master when starting or restarting an application. In this case, the report shows the application name and the node on which it is started. Here’s an example:
5> rb:show(6).
PROGRESS REPORT <0.7.0> 2016-01-09 19:24:26
===============================================================================
application bsc
started_at nonode@nohost
okThe progress report in our example is the one telling us that the
bsc application was started
correctly. Note how we are using rb:show/1 to view
individual reports.
Error Reports
Error reports are raised by behaviors upon abnormal termination. In our
case, the frequency server generates the report when terminating
abnormally. You can generate your own error reports using the
error_logger:error_msg(String, Args) call, but we advise
against this. Use this command sparingly and only for unexpected errors,
as too many user-generated reports will hide serious issues and clutter
the logs, making it harder to find important details when you are
looking for crash reports and other real errors. Here’s the error report
from our example:
6>rb:show(5).ERROR REPORT <0.51.0> 2016-01-09 19:24:30 =============================================================================== ** Generic server frequency terminating ** Last message in was {allocate,<0.34.0>} ** When Server state == {data,[{"State",{{available,crash},{allocated,[]}}}]} ** Reason for termination == ** {function_clause,[{frequency,allocate, [{crash,[]},<0.34.0>], [{file,"bsc-1.0/src/frequency.erl"}, {line,99}]}, {frequency,handle_call,3, [{file,"bsc-1.0/src/frequency.erl"}, {line,66}]}, {gen_server,try_handle_call,4, [{file,"gen_server.erl"},{line,629}]}, {gen_server,handle_msg,5, [{file,"gen_server.erl"},{line,661}]}, {proc_lib,init_p_do_apply,3, [{file,"proc_lib.erl"},{line,240}]}]} ok 7>error_logger:error_msg("Error in ~w. Division by zero!~n", [self()]).ok =ERROR REPORT==== 9-Jan-2016::19:28:19 === Error in <0.57.0>. Division by zero!
Crash Reports
Crash reports are issued by processes started with the proc_lib
library. If you look at the exit reason in our example, you will realize
that this applies to all behaviors, which are started from that library.
A try-catch in the main behavior loop will trap abnormal
terminations and generate a crash report. No reports are generated if
the behavior or process terminates with reason normal or when the supervisor terminates the
behavior with reason shutdown. A
crash report contains information on the crashed process, including exit
reason, initial function, and message queue, as well as other process
information typically found using the process_info BIFs.
The crash report from our example looks like this:
8> rb:show(4).
CRASH REPORT <0.51.0> 2016-01-09 19:24:30
===============================================================================
Crashing process
initial_call {frequency,init,['Argument__1']}
pid <0.51.0>
registered_name frequency
error_info
{exit,
{function_clause,
[{frequency,allocate,
[{crash,[]},<0.34.0>],
[{file,"bsc-1.0/src/frequency.erl"},{line,99}]},
{frequency,handle_call,3,
[{file,"bsc-1.0/src/frequency.erl"},{line,66}]},
{gen_server,try_handle_call,4,
[{file,"gen_server.erl"},{line,629}]},
{gen_server,handle_msg,5,
[{file,"gen_server.erl"},{line,661}]},
{proc_lib,init_p_do_apply,3,
[{file,"proc_lib.erl"},{line,240}]}]},
[{gen_server,terminate,7,[{file,"gen_server.erl"},{line,826}]},
{proc_lib,init_p_do_apply,3,
[{file,"proc_lib.erl"},{line,240}]}]}
ancestors [bsc,<0.47.0>]
messages []
links [<0.48.0>]
dictionary []
trap_exit false
status running
heap_size 987
stack_size 27
reductions 412
okSupervisor Reports
Supervisor reports are issued by supervisors upon abnormal child termination. They usually follow the error reports issued by the children themselves. The supervisor report contains the name of the reporting supervisor and the phase of the child in which the error occurred:
9> rb:show(3).
SUPERVISOR REPORT <0.48.0> 2016-01-09 19:24:30
===============================================================================
Reporting supervisor {local,bsc}
Child process
errorContext child_terminated
reason
{function_clause,
[{frequency,allocate,
[{crash,[]},<0.34.0>],
[{file,"bsc-1.0/src/frequency.erl"},{line,99}]},
{frequency,handle_call,3,
[{file,"bsc-1.0/src/frequency.erl"},{line,66}]},
{gen_server,try_handle_call,4,
[{file,"gen_server.erl"},{line,629}]},
{gen_server,handle_msg,5,[{file,"gen_server.erl"},{line,661}]},
{proc_lib,init_p_do_apply,3,
[{file,"proc_lib.erl"},{line,240}]}]}
pid <0.51.0>
id frequency
mfargs {frequency,start_link,[]}
restart_type permanent
shutdown 2000
child_type worker
okIf you look close to the top of the example output, you will find
the report phase of the child when the error occurred: one of start_error, child_terminated, or shutdown_error. In our case, the
termination happened because of a runtime error, resulting in the report
phase being child_terminated. It is
followed with the reason for termination and the child
specification.
You can look at the last two progress reports on your own. They
are the progress reports generated when the frequency server and phone
supervisor are restarted. Use rb:help(), and spend some
time experimenting with the commands in the report browser, especially
the filters and regular expressions.
Summing Up
In this chapter, we covered the behavior that allows us to package code, resources, configuration files, and supervision trees into what we call an application. Applications are the reusable building blocks of your systems; they are loaded, started, and stopped as a single unit. They provide functionality such as start phases, synchronization, and failover in distributed clusters, as well as basic monitoring and logging services.
Table 9-1 lists the major functions used to control applications.
| Application function or action | Application callback function |
|---|---|
application:start/1,
application:start/2 | Module:start/2,
Module:start_phase/3 |
application:stop/1 | Module:prep_stop/1,
Module:stop/2 |
You can read more about applications in the application manual pages,
and about resource files in the app manual
page. The OTP Design Principles User’s Guide, which comes with the
standard Erlang documentation, has sections covering general, included,
and distributed applications. To learn more about the tools we’ve covered,
consult the manual pages for the report browser, rb, as well as the observer. Read through the
code of the examples provided in this chapter and see how applications in
the Erlang distribution are packaged and configured.
What’s Next?
Now that we know how to create our applications, the basic building blocks for Erlang systems, next we look at how to group them together in a release and start our systems using boot files. But first, we look at some of the libraries used to implement special processes, and using that knowledge to define our own behaviors. What are special processes, I hear you say? They are processes that, despite not being OTP behaviors that come as part of the stdlib application, can be added to OTP supervision trees. Read on to find out more.