
Chapter 9. Reducing memory use
This chapter covers
- Short structures
- Sharded structures
- Packing bits and bytes
In this chapter, we’ll cover three important methods to help reduce your memory use in Redis. By reducing the amount of memory you use in Redis, you can reduce the time it takes to create or load a snapshot, rewrite or load an append-only file, reduce slave synchronization time,[1] and store more data in Redis without additional hardware.
1 Snapshots, append-only file rewriting, and slave synchronization are all discussed in chapter 4.
We’ll begin this chapter by discussing how the use of short data structures in Redis can result in a more efficient representation of the data. We’ll then discuss how to apply a concept called sharding to help make some larger structures small.[2] Finally, we’ll talk about packing fixed-length data into STRINGs for even greater memory savings.
2 Our use of sharding here is primarily driven to reduce memory use on a single server. In chapter 10, we’ll apply similar techniques to allow for increased read throughput, write throughput, and memory partitioning across multiple Redis servers.
When used together, these methods helped me to reduce memory use from more than 70 gigabytes, split across three machines, down to under 3 gigabytes on a single machine. As we work through these methods, remember that some of our earlier problems would lend themselves well to these optimizations, which I’ll point out when applicable. Let’s get started with one of the first and easiest methods to reduce memory use: short structures.
9.1. Short structures
The first method of reducing memory use in Redis is simple: use short structures. For LISTs, SETs, HASHes, and ZSETs, Redis offers a group of configuration options that allows for Redis to store short structures in a more space-efficient manner. In this section, we’ll discuss those configuration options, show how to verify that we’re getting those optimizations, and discuss some drawbacks to using short structures.
When using short LISTs, HASHes, and ZSETs, Redis can optionally store them using a more compact storage method known as a ziplist. A ziplist is an unstructured representation of one of the three types of objects. Rather than storing the doubly linked list, the hash table, or the hash table plus the skiplist as would normally be the case for each of these structures, Redis stores a serialized version of the data, which must be decoded for every read, partially re-encoded for every write, and may require moving data around in memory.
9.1.1. The ziplist representation
To understand why ziplists may be more efficient, we only need to look at the simplest of our structures, the LIST. In a typical doubly linked list, we have structures called nodes, which represent each value in the list. Each of these nodes has pointers to the previous and next nodes in the list, as well as a pointer to the string in the node. Each string value is actually stored as three parts: an integer representing the length, an integer representing the number of remaining free bytes, and the string itself followed by a null character. An example of this in figure 9.1 shows the three string values "one", "two", and "ten" as part of a larger linked list.
Figure 9.1. How long LISTs are stored in Redis

Ignoring a few details (which only make linked lists look worse), each of these three strings that are each three characters long will actually take up space for three pointers, two integers (the length and remaining bytes in the value), plus the string and an extra byte. On a 32-bit platform, that’s 21 bytes of overhead to store 3 actual bytes of data (remember, this is an underestimate of what’s actually stored).
On the other hand, the ziplist representation will store a sequence of length, length, string elements. The first length is the size of the previous entry (for easy scanning in both directions), the second length is the size of the current entry, and the string is the stored data itself. There are some other details about what these lengths really mean in practice, but for these three example strings, the lengths will be 1 byte long, for 2 bytes of overhead per entry in this example. By not storing additional pointers and metadata, the ziplist can cut down overhead from 21 bytes each to roughly 2 bytes (in this example).
Let’s see how we can ensure that we’re using the compact ziplist encoding.
Using the ziplist encoding
In order to ensure that these structures are only used when necessary to reduce memory, Redis includes six configuration options, shown in the following listing, for determining when the ziplist representation will be used for LISTs, HASHes, and ZSETs.
Listing 9.1. Configuration options for the ziplist representation of different structures

The basic configuration options for LISTs, HASHes, and ZSETs are all similar, composed of -max-ziplist-entries settings and -max-ziplist-value settings. Their semantics are essentially identical in all three cases. The entries settings tell us the maximum number of items that are allowed in the LIST, HASH, or ZSET for them to be encoded as a ziplist. The value settings tell us how large in bytes each individual entry can be. If either of these limits are exceeded, Redis will convert the LIST, HASH, or ZSET into the nonziplist structure (thus increasing memory).
If we’re using an installation of Redis 2.6 with the default configuration, Redis should have default settings that are the same as what was provided in listing 9.1. Let’s play around with ziplist representations of a simple LIST object by adding some items and checking its representation, as shown in the next listing.
Listing 9.2. How to determine whether a structure is stored as a ziplist

With the new DEBUG OBJECT command at our disposal, discovering whether an object is stored as a ziplist can be helpful to reduce memory use.
You’ll notice that one structure is obviously missing from the special ziplist encoding, the SET. SETs also have a compact representation, but different semantics and limits, which we’ll cover next.
9.1.2. The intset encoding for SETs
Like the ziplist for LISTs, HASHes, and ZSETs, there’s also a compact representation for short SETs. If our SET members can all be interpreted as base-10 integers within the range of our platform’s signed long integer, and our SET is short enough (we’ll get to that in a moment), Redis will store our SET as a sorted array of integers, or intset.
By storing a SET as a sorted array, not only do we have low overhead, but all of the standard SET operations can be performed quickly. But how big is too big? The next listing shows the configuration option for defining an intset’s maximum size.
Listing 9.3. Configuring the maximum size of the intset encoding for SETs
![]()
As long as we keep our SETs of integers smaller than our configured size, Redis will use the intset representation to reduce data size. The following listing shows what happens when an intset grows to the point of being too large.
Listing 9.4. When an intset grows to be too large, it’s represented as a hash table.

Earlier, in the introduction to section 9.1, I mentioned that to read or update part of an object that uses the compact ziplist representation, we may need to decode the entire ziplist, and may need to move in-memory data around. For these reasons, reading and writing large ziplist-encoded structures can reduce performance. Intset-encoded SETs also have similar issues, not so much due to encoding and decoding the data, but again because we need to move data around when performing insertions and deletions. Next, we’ll examine some performance issues when operating with long ziplists.
9.1.3. Performance issues for long ziplists and intsets
As our structures grow beyond the ziplist and intset limits, they’re automatically converted into their more typical underlying structure types. This is done primarily because manipulating the compact versions of these structures can become slow as they grow longer.
For a firsthand look at how this happens, let’s start by updating our setting for list-max-ziplist-entries to 110,000. This setting is a lot larger than we’d ever use in practice, but it does help to highlight the issue. After that setting is updated and Redis is restarted, we’ll benchmark Redis to discover performance issues that can happen when long ziplist-encoded LISTs are used.
To benchmark the behavior of long ziplist-encoded LISTs, we’ll write a function that creates a LIST with a specified number of elements. After the LIST is created, we’ll repeatedly call the RPOPLPUSH command to move an item from the right end of the LIST to the left end. This will give us a lower bound on how expensive commands can be on very long ziplist-encoded LISTs. This benchmarking function is shown in the next listing.
Listing 9.5. Our code to benchmark varying sizes of ziplist-encoded LISTs

As mentioned before, this code creates a LIST of a given size and then executes a number of RPOPLPUSH commands in pipelines. By computing the number of calls to RPOPLPUSH divided by the amount of time it took, we can calculate a number of operations per second that can be executed on ziplist-encoded LISTs of a given size. Let’s run this with steadily increasing list sizes to see how long ziplists can reduce performance.
Listing 9.6. As ziplist-encoded LISTs grow, we can see performance drop

At first glance, you may be thinking that this isn’t so bad even when you let a ziplist grow to a few thousand elements. But this shows only a single example operation, where all we’re doing is taking items off of the right end and pushing them to the left end. The ziplist encoding can find the right or left end of a sequence quickly (though shifting all of the items over for the insert is what slows us down), and for this small example we can exploit our CPU caches. But when scanning through a list for a particular value, like our autocomplete example from section 6.1, or fetching/updating individual fields of a HASH, Redis will have to decode many individual entries, and CPU caches won’t be as effective. As a point of data, replacing our RPOPLPUSH command with a call to LINDEX that gets an element in the middle of the LIST shows performance at roughly half the number of operations per second as our RPOPLPUSH call when LISTs are at least 5,000 items long. Feel free to try it for yourself.
If you keep your max ziplist sizes in the 500–2,000 item range, and you keep the max item size under 128 bytes or so, you should get reasonable performance. I personally try to keep max ziplist sizes to 1,024 elements with item sizes at 64 bytes or smaller. For many uses of HASHes that we’ve used so far, these limits should let you keep memory use down, and performance high.
As you develop solutions to problems outside of our examples, remember that if you can keep your LIST, SET, HASH, and ZSET sizes small, you can help keep your memory use low, which can let you use Redis for a wider variety of problems.
Keeping key names short
One thing that I haven’t mentioned before is the use of minimizing the length of keys, both in the key portion of all values, as well as keys in HASHes, members of SETs and ZSETs, and entries in LISTs. The longer all of your strings are, the more data needs to be stored. Generally speaking, whenever it’s possible to store a relatively abbreviated piece of information like user:joe as a key or member, that’s preferable to storing username:joe, or even joe if user or username is implied. Though in some cases it may not make a huge difference, if you’re storing millions or billions of entries, those extra few megabytes or gigabytes may be useful later.
Now that you’ve seen that short structures in Redis can be used to reduce memory use, in the next section we’ll talk about sharding large structures to let us gain the benefits of the ziplist and intset optimizations for more problems.
9.2. Sharded structures
Sharding is a well-known technique that has been used to help many different databases scale to larger data storage and processing loads. Basically, sharding takes your data, partitions it into smaller pieces based on some simple rules, and then sends the data to different locations depending on which partition the data had been assigned to.
In this section, we’ll talk about applying the concept of sharding to HASHes, SETs, and ZSETs to support a subset of their standard functionality, while still letting us use the small structures from section 9.1 to reduce memory use. Generally, instead of storing value X in key Y, we’ll store X in key Y:<shardid>.
Sharding LISTs
Sharding LISTs without the use of Lua scripting is difficult, which is why we omit it here. When we introduce scripting with Lua in chapter 11, we’ll build a sharded LIST implementation that supports blocking and nonblocking pushes and pops from both ends.
Sharding ZSETs
Unlike sharded HASHes and SETs, where essentially all operations can be supported with a moderate amount of work (or even LISTs with Lua scripting), commands like ZRANGE, ZRANGEBYSCORE, ZRANK, ZCOUNT, ZREMRANGE, ZREMRANGEBYSCORE, and more require operating on all of the shards of a ZSET to calculate their final result. Because these operations on sharded ZSETs violate almost all of the expectations about how quickly a ZSET should perform with those operations, sharding a ZSET isn’t necessarily that useful, which is why we essentially omit it here.
If you need to keep full information for a large ZSET, but you only really perform queries against the top- or bottom-scoring X, you can shard your ZSET in the same way we shard HASHes in section 9.2.1: keeping auxiliary top/bottom scoring ZSETs, which you can update with ZADD/ZREMRANGEBYRANK to keep limited (as we’ve done previously in chapters 2 and 4–8).
You could also use sharded ZSETs as a way of reducing single-command latencies if you have large search indexes, though discovering the final highestand lowest-scoring items would take a potentially long series of ZUNIONSTORE/ZREMRANGEBYRANK pairs.
When sharding structures, we can make a decision to either support all of the functionality of a single structure or only a subset of the standard functionality. For the sake of simplicity, when we shard structures in this book, we’ll only implement a subset of the functionality offered by the standard structures, because to implement the full functionality can be overwhelming (from both computational and code-volume perspectives). Even though we only implement a subset of the functionality, we’ll use these sharded structures to offer memory reductions to existing problems, or to solve new problems more efficiently than would otherwise be possible.
The first structure we’ll talk about sharding is the HASH.
9.2.1. HASHes
One of the primary uses for HASHes is storing simple key/value pairs in a grouped fashion. Back in section 5.3, we developed a method of mapping IP addresses to locations around the world. In addition to a ZSET that mapped from IP addresses to city IDs, we used a single HASH that mapped from city IDs to information about the city itself. That HASH had more than 370,000 entries using the August 2012 version of the database, which we’ll now shard.
To shard a HASH table, we need to choose a method of partitioning our data. Because HASHes themselves have keys, we can use those keys as a source of information to partition the keys. For partitioning our keys, we’ll generally calculate a hash function on the key itself that will produce a number. Depending on how many keys we want to fit in a single shard and how many total keys we need to store, we’ll calculate the number of shards we need, and use that along with our hash value to determine the shard ID that the data will be stored in.
For numeric keys, we’ll assume that the keys will be more or less sequential and tightly packed, and will assign them to a shard ID based on their numeric key value (keeping numerically similar keys in the same shard). The next listing shows our function for calculating a new key for a sharded HASH, given the base key and the HASH key HASH.
Listing 9.7. A function to calculate a shard key from a base key and a secondary entry key

In our function, you’ll notice that for non-numeric keys we calculate a CRC32 checksum. We’re using CRC32 in this case because it returns a simple integer without additional work, is fast to calculate (much faster than MD5 or SHA1 hashes), and because it’ll work well enough for most situations.
Being consistent about total_elements and shard_size
When using non-numeric keys to shard on, you’ll notice that we use the total_elements value to calculate the total number of shards necessary, in addition to the shard_size that’s used for both numeric and non-numeric keys. These two pieces of information are necessary to keep the total number of shards down. If you were to change either of these numbers, then the number of shards (and thus the shard that any piece of data goes to) will change. Whenever possible, you shouldn’t change either of these values, or when you do change them, you should have a process for moving your data from the old data shards to the new data shards (this is generally known as resharding).
We’ll now use our shard_key() to pick shards as part of two functions that will work like HSET and HGET on sharded hashes in the following listing.
Listing 9.8. Sharded HSET and HGET functions

Nothing too complicated there; we’re finding the proper location for the data to be stored or fetched from the HASH and either setting or getting the values. To update our earlier IP-address-to-city lookup calls, we only need to replace one call in each of two functions. The next listing shows just those parts of our earlier functions that need to be updated.
Listing 9.9. Sharded IP lookup functions
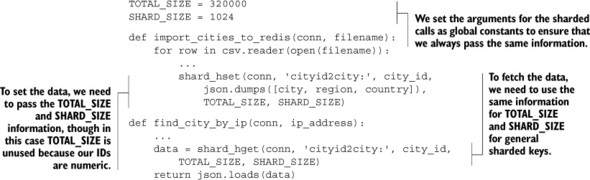
On a 64-bit machine, storing the single HASH of all of our cities takes up roughly 44 megabytes. But with these few small changes to shard our data, setting hash-max-ziplist-entries to 1024 and hash-max-ziplist-value to 256 (the longest city/country name in the list is a bit over 150 characters), the sharded HASHes together take up roughly 12 megabytes. That’s a 70% reduction in data size, which would allow us to store 3.5 times as much data as before. For shorter keys and values, you can potentially see even greater percentage savings (overhead is larger relative to actual data stored).
Storing STRINGs in HASHes
If you find yourself storing a lot of relatively short strings or numbers as plain STRING values with consistently named keys like namespace:id, you can store those values in sharded HASHes for significant memory reduction in some cases.
As you saw, getting and setting values in a sharded HASH is easy. Can you add support for sharded HDEL, HINCRBY, and HINCRBYFLOAT operations?
We’ve just finished sharding large hashes to reduce their memory use. Next, you’ll learn how to shard SETs.
9.2.2. SETs
One common use of an operation known as map-reduce (which I mentioned in chapters 1 and 6) is calculating unique visitors to a website. Rather than waiting until the end of the day to perform that calculation, we could instead keep a live updated count of unique visitors as the day goes on. One method to calculate unique visitors in Redis would use a SET, but a single SET storing many unique visitors would be very large. In this section, we’ll shard SETs as a way of building a method to count unique visitors to a website.
To start, we’ll assume that every visitor already has a unique identifier similar to the UUIDs that we generated in chapter 2 for our login session cookies. Though we could use these UUIDs directly in our SET as members and as keys to shard using our sharding function from section 9.2.1, we’d lose the benefit of the intset encoding. Assuming that we generated our UUIDs randomly (as we’ve done in previous chapters), we could instead use the first 15 hexadecimal digits from the UUID as a full key. This should bring up two questions: First, why would we want to do this? And second, why is this enough?
For the first question (why we’d want to do this), UUIDs are basically 128-bit numbers that have been formatted in an easy-to-read way. If we were to store them, we’d be storing roughly 16 bytes (or 36 if we stored them as-is) per unique visitor. But by only storing the first 15 hexadecimal digits[3] turned into a number, we’d only be storing 8 bytes per unique visitor. So we save space up front, which we may be able to use later for other problems. This also lets us use the intset optimization for keeping memory use down.
3 Another good question is why 56 and not 64 bits? That’s because Redis will only use intsets for up to 64-bit signed integers, and the extra work of turning our 64-bit unsigned integer into a signed integer isn’t worth it in most situations. If you need the extra precision, check out the Python struct module and look at the Q and q format codes.
For the second question (why this is enough), it boils down to what are called birthday collisions. Put simply: What are the chances of two 128-bit random identifiers matching in the first 56 bits? Mathematically, we can calculate the chances exactly, and as long as we have fewer than 250 million unique visitors in a given time period (a day in our case), we’ll have at most a 1% chance of a single match (so if every day we have 250 million visitors, about once every 100 days we’ll have about 1 person not counted). If we have fewer than 25 million unique visitors, then the chance of not counting a user falls to the point where we’d need to run the site for roughly 2,739 years before we’d miss counting a single user.
Now that we’ve decided to use the first 56 bits from the UUID, we’ll build a sharded SADD function, which we’ll use as part of a larger bit of code to actually count unique visitors. This sharded SADD function in listing 9.10 will use the same shard key calculation that we used in section 9.2.1, modified to prefix our numeric ID with a non-numeric character for shard ID calculation, since our 56-bit IDs aren’t densely packed (as is the assumption for numeric IDs).
Listing 9.10. A sharded SADD function we’ll use as part of a unique visitor counter

With a sharded SADD function, we can now keep unique visitor counts. When we want to count a visitor, we’ll first calculate their shorter ID based on the first 56 bits of their session UUID. We’ll then determine today’s date and add the ID to the sharded unique visitor SET for today. If the ID wasn’t already in the SET, we’ll increment today’s unique visitor count. Our code for keeping track of the unique visitor count can be seen in the following listing.
Listing 9.11. A function to keep track of the unique visitor count on a daily basis
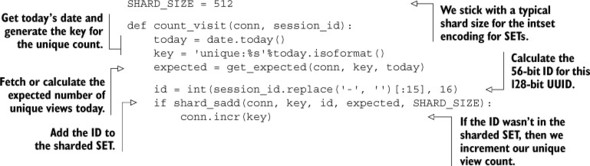
That function works exactly as described, though you’ll notice that we make a call to get_expected() to determine the number of expected daily visitors. We do this because web page visits will tend to change over time, and keeping the same number of shards every day wouldn’t grow as we grow (or shrink if we have significantly fewer than a million unique visitors daily).
To address the daily change in expected viewers, we’ll write a function that calculates a new expected number of unique visitors for each day, based on yesterday’s count. We’ll calculate this once for any given day, estimating that today will see at least 50% more visitors than yesterday, rounded up to the next power of 2. Our code for calculating this can be seen next.
Listing 9.12. Calculate today’s expected unique visitor count based on yesterday’s count

Most of that function is reading and massaging data in one way or another, but the overall result is that we calculate an expected number of unique views for today by taking yesterday’s view count, increasing it by 50%, and rounding up to the next power of 2. If the expected number of views for today has already been calculated, we’ll use that.
Taking this exact code and adding 1 million unique visitors, Redis will use approximately 9.5 megabytes to store the unique visitor count. Without sharding, Redis would use 56 megabytes to store the same data (56-bit integer IDs in a single SET). That’s an 83% reduction in storage with sharding, which would let us store 5.75 times as much data with the same hardware.
For this example, we only needed a single SET command to determine the unique visitor count for a given day. Can you add sharded SREM and SISMEMBER calls? Bonus points: Assuming that you have two sharded SETs with the same expected total number of items, as well as the same shard size, you’ll have the same number of shards, and identical IDs will be in the same shard IDs. Can you add sharded versions of SINTERSTORE, SUNIONSTORE, and SDIFFSTORE?
Other methods to calculate unique visitor counts
If you have numeric visitor IDs (instead of UUIDs), and the visitor IDs have relatively low maximum value, rather than storing your visitor information as sharded SETs, you can store them as bitmaps using techniques similar to what we describe in the next section. A Python library for calculating unique visitor counts and other interesting analytics based on bitmaps can be found at https://github.com/Doist/bitmapist.
After sharding large SETs of integers to reduce storage, it’s now time to learn how to pack bits and bytes into STRINGs.
9.3. Packing bits and bytes
When we discussed sharding HASHes, I briefly mentioned that if we’re storing short strings or counters as STRING values with keys like namespace:id, we could use sharded HASHes as a way of reducing memory use. But let’s say that we wanted to store a short fixed amount of information for sequential IDs. Can we use even less memory than sharded HASHes?
In this section, we’ll use sharded Redis STRINGs to store location information for large numbers of users with sequential IDs, and discuss how to perform aggregate counts over this stored data. This example shows how we can use sharded Redis STRINGs to store, for example, location information for users on Twitter.
Before we start storing our data, we need to revisit four commands that’ll let us efficiently pack and update STRINGs in Redis: GETRANGE, SETRANGE, GETBIT, and SETBIT. The GETRANGE command lets us read a substring from a stored STRING. SETRANGE will let us set the data stored at a substring of the larger STRING. Similarly, GETBIT will fetch the value of a single bit in a STRING, and SETBIT will set an individual bit. With these four commands, we can use Redis STRINGs to store counters, fixed-length strings, Booleans, and more in as compact a format as is possible without compression. With our brief review out of the way, let’s talk about what information we’ll store.
9.3.1. What location information should we store?
When I mentioned locations, you were probably wondering what I meant. Well, we could store a variety of different types of locations. With 1 byte, we could store country-level information for the world. With 2 bytes, we could store region/state-level information. With 3 bytes, we could store regional postal codes for almost every country. And with 4 bytes, we could store latitude/longitude information down to within about 2 meters or 6 feet.
Which level of precision to use will depend on our given use case. For the sake of simplicity, we’ll start with just 2 bytes for region/state-level information for countries around the world. As a starter, listing 9.13 shows some base data for ISO3 country codes around the world, as well as state/province information for the United States and Canada.
Listing 9.13. Base location tables we can expand as necessary

I introduce these tables of data initially so that if/when we’d like to add additional state, region, territory, or province information for countries we’re interested in, the format and method for doing so should be obvious. Looking at the data tables, we initially define them as strings. But these strings are converted into lists by being split on whitespace by our call to the split() method on strings without any arguments. Now that we have some initial data, how are we going to store this information on a per-user basis?
Let’s say that we’ve determined that user 139960061 lives in California, U.S., and we want to store this information for that user. To store the information, we first need to pack the data into 2 bytes by first discovering the code for the United States, which we can calculate by finding the index of the United States’ ISO3 country code in our COUNTRIES list. Similarly, if we have state information for a user, and we also have state information in our tables, we can calculate the code for the state by finding its index in the table. The next listing shows the function for turning country/state information into a 2-byte code.
Listing 9.14. ISO3 country codes

Location code calculation isn’t that interesting or difficult; it’s primarily a matter of finding offsets in lookup tables, and then dealing with “not found” data. Next, let’s talk about actually storing our packed location data.
9.3.2. Storing packed data
After we have our packed location codes, we only need to store them in STRINGs with SETRANGE. But before we do so, we have to think for a moment about how many users we’re going to be storing information about. For example, suppose that Twitter has 750 million users today (based on the observation that recently created users have IDs greater than 750 million); we’d need over 1.5 gigabytes of space to store location information for all Twitter users. Though most operating systems are able to reasonably allocate large regions of memory, Redis limits us to 512 megabyte STRINGs, and due to Redis’s clearing out of data when setting a value beyond the end of an existing STRING, setting the first value at the end of a long STRING will take more time than would be expected for a simple SETBIT call. Instead, we can use a technique similar to what we used in section 9.2.1, and shard our data across a collection of STRINGs.
Unlike when we were sharding HASHes and SETs, we don’t have to worry about being efficient by keeping our shards smaller than a few thousand elements, since we can access an element directly without decoding any others. Similarly, we can write to a given offset efficiently. Instead, our concern is more along the lines of being efficient at a larger scale—specifically what will balance potential memory fragmentation, as well as minimize the number of keys that are necessary. For this example, we’ll store location information for 220 users (just over 1 million entries) per STRING, which will use about 2 megabytes per STRING. In the next listing, we see the code for updating location information for a user.
Listing 9.15. A function for storing location data in sharded STRINGs
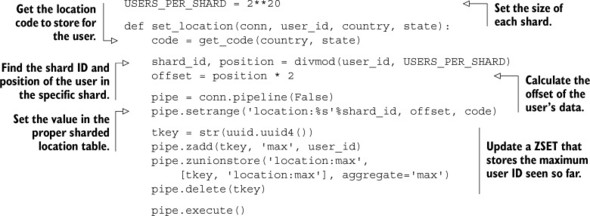
For the most part, there shouldn’t be anything surprising there. We calculate the location code to store for a user, calculate the shard and the individual shard offset for the user, and then store the location code in the proper location for the user. The only thing that’s strange and may not seem necessary is that we also update a ZSET that stores the highest-numbered user ID that has been seen. This is primarily important when calculating aggregates over everyone we have information about (so we know when to stop).
9.3.3. Calculating aggregates over sharded STRINGs
To calculate aggregates, we have two use cases. Either we’ll calculate aggregates over all of the information we know about, or we’ll calculate over a subset. We’ll start by calculating aggregates over the entire population, and then we’ll write code that calculates aggregates over a smaller group.
To calculate aggregates over everyone we have information for, we’ll recycle some code that we wrote back in section 6.6.4, specifically the readblocks() function, which reads blocks of data from a given key. Using this function, we can perform a single command and round trip with Redis to fetch information about thousands of users at one time. Our function to calculate aggregates with this block-reading function is shown next.
Listing 9.16. A function to aggregate location information for everyone

This function to calculate aggregates over country- and state-level information for everyone uses a structure called a defaultdict, which we also first used in chapter 6 to calculate aggregates about location information before writing back to Redis. Inside this function, we refer to a helper function that actually updates the aggregates and decodes location codes back into their original ISO3 country codes and local state abbreviations, which can be seen in this next listing.
Listing 9.17. Convert location codes back to country/state information
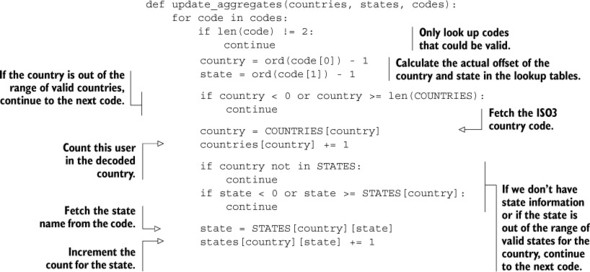
With a function to convert location codes back into useful location information and update aggregate information, we have the building blocks to perform aggregates over a subset of users. As an example, say that we have location information for many Twitter users. And also say that we have follower information for each user. To discover information about where the followers of a given user are located, we’d only need to fetch location information for those users and compute aggregates similar to our global aggregates. The next listing shows a function that will aggregate location information over a provided list of user IDs.
Listing 9.18. A function to aggregate location information over provided user IDs

This technique of storing fixed-length data in sharded STRINGs can be useful. Though we stored multiple bytes of data per user, we can use GETBIT and SETBIT identically to store individual bits, or even groups of bits.
9.4. Summary
In this chapter, we’ve explored a number of ways to reduce memory use in Redis using short data structures, sharding large structures to make them small again, and by packing data directly into STRINGs.
If there’s one thing that you should take away from this chapter, it’s that by being careful about how you store your data, you can significantly reduce the amount of memory that Redis needs to support your applications.
In the next chapter, we’ll revisit a variety of topics to help Redis scale to larger groups of machines, including read slaves, sharding data across multiple masters, and techniques for scaling a variety of different types of queries.