
Comparing DATA Step Match-Merges and PROC SQL Joins
Overview
You have seen that it is possible to create identical
results with a DATA step match-merge and a PROC SQL inner join. Although
the results might be identical, these two processes are very different,
and trade-offs are associated with choosing one method over the other.
The following tables summarize some of the advantages and disadvantages
of each of these two methods.
|
Advantages
|
Disadvantages
|
|---|---|
|
|
|
Advantages
|
Disadvantages
|
|---|---|
|
|
Although it is possible
to produce identical results with a DATA step match-merge and a PROC
SQL join, these two processes will not always produce results that
are identical by default.
Consider the following
simplified examples to see how each method works in various circumstances.
The following two steps
show two different ways to produce the same combination of two data
sets, Data1 and Data2, that have a common variable, X. If Data1 contains
two variables, X and Y, and Data2 contains two variables, X and Z,
then both of the following steps produce an output data set named
Data3 that contains three variables, X, Y, and Z.
Note: The code shown in the following
two steps illustrates a simple comparison of a DATA step match-merge
and a PROC SQL join. This comparison will be explored in the next
several sections.
data data3;
merge data1 data2;
by x;
run;
proc sql;
create table data3 as
select data1.x, data1.y, data2.z
from data1, data2
where data1.x=data2.x;
quit;The contents of Data3
will vary depending on the values that are in each input data set
and on the method used for merging. Consider the following examples.
Examples
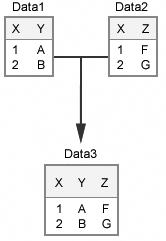
One-to-one
matches produce identical results whether the data sets are merged
in a DATA step or joined in a PROC SQL step. Suppose that Data1 and
Data2 contain the same number of observations. Also, suppose that
in each data set, the values of X are unique, and that each value
appears in both data sets.
When these data sets
are either merged in a DATA step or joined in a PROC SQL step, Data3
will contain one observation for each unique value of X, and it will
have the same number of observations as Data1 and Data2.
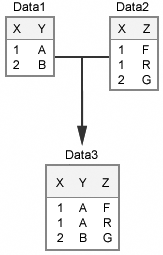
One-to-many
matches produce identical results whether the data sets are merged
in a DATA step or joined in a PROC SQL step. Suppose that Data1contains
unique values for X, but that Data2 does not contain unique values
for X. That is, Data2 contains multiple observations that have the
same value of X and therefore contains more observations than Data1.
When these two data
sets are either merged in a DATA step or joined in a PROC SQL step,
Data3 will contain the same number of observations as Data2. In Data3,
one observation from Data1 that has a particular value for X might
be matched with multiple observations from Data2 that have the same
value for X.
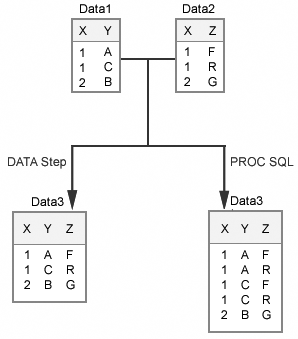
Many-to-many
matches produce different results depending on whether the data sets
are merged in a DATA step or joined in a PROC SQL step. Suppose the
values of X are not unique in both Data1 and Data2.
When the data sets are
merged in a DATA step, the observations are matched and combined sequentially.
In the example below,
Data3 will contain the same number of observations as the larger of
the two input sets. In cases where there is a many-to-many match on
the values of the BY variable, a DATA step match-merge probably does
not produce the desired output because the output data set will not
contain all of the possible combinations of matching observations.
When the data sets are
joined in a PROC SQL step, each match appears as a separate observation
in the output data set. In the example below, the first observation
that has a value of
1 for X in Data1
is matched and combined with each observation from Data2 that has
a value of 1 for X. Then, the second
observation that has a value of 1 for
X in Data1is matched and combined with each observation from Data2
that has a value of 1 for X, and so
on.
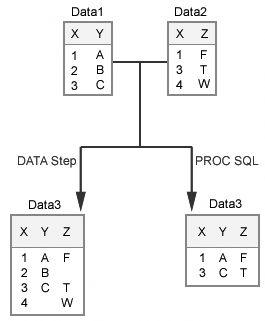
Nonmatching
data between the data sets produces different results depending on
whether the data sets are merged in a DATA step or combined by using
a PROC SQL inner join.
When data sets that
contain nonmatching values for the BY variable are merged in a DATA
step, the observations in each are processed sequentially. Data3 will
contain one observation for each unique value of X that appears in
either Data1 or Data2. For nonmatching values of X, the observation
in Data3 will have a missing value for the variable that is taken
from the other input data set.
In this PROC SQL step,
the output data set will contain only those observations that have
matching values for the BY variable. In the example below, Data3 does
not have any observations with missing values, because any observation
from Data1 or from Data2 that contains a nonmatching value for X is
not included in Data3.
You have seen the results
of DATA step match-merges and PROC SQL joins in several simple scenarios.
To help you understand the differences more fully, consider how the
DATA step processes a match-merge and how PROC SQL processes a join.
Execution of a DATA Step Match-Merge
-
If the BY values do not match, SAS reads from the input data set with the lowest BY value. If the BY value matches the BY value from the previous observation, SAS does not reinitialize the PDV but overwrites the values in the PDV. If the BY value does not match the previous BY value, SAS reinitializes the PDV. The PDV and the output data set then contain missing values for variables that are unique to the other data set.
PROC SQL Join
A
PROC SQL join uses a different process than a DATA step merge to combine
tables
Conceptually,
PROC SQL first creates a Cartesian product of all input tables. That
is, PROC SQL first matches each row with every other row in the other
input tables. Then, PROC SQL eliminates any observations from the
result set that do not satisfy the WHERE clause. The PROC SQL query
optimizer uses methods to minimize the Cartesian product that must
be built.
Execution of a PROC SQL Join
-
This example shows the execution of the PROC SQL step below. This PROC SQL step creates a new table to hold the results of an inner join on two input tables. This discussion provides a conceptual view of how PROC SQL works rather than a literal depiction of the join process. In reality, PROC SQL uses optimization routines that make the process more efficient.
proc sql; create table work.data3 as select * from data1, data 2 where data1.x=data2.x; quit;
Earlier in this chapter,
you learned that a DATA step match-merge will probably not produce
the desired results when the data sources that you want to combine
have a many-to-many match. You also learned that PROC SQL and the
DATA step match-merge do not, by default, produce the same results
when you combine data sources that contain nonmatching data. Now that
you have seen how DATA step match-merges and PROC SQL joins work,
consider an example of using each of these techniques to combine data
from a many-to-many match that also contains nonmatching data.
Example: Combining Data from a Many-to-Many Match
Suppose you want to
combine the data from Sasuser.Flightschedule and Sasuser.Flightattendants.
The Sasuser.Flightschedule data set contains data about flights that
have been scheduled for a fictional airline. The data set Sasuser.Flightattendants
contains information about the flight attendants of a fictional airline.
A partial listing of each of these data sets is shown below.
|
Date
|
Destination
|
FlightNumber
|
EmpID
|
|---|---|---|---|
|
01MAR2000
|
YYZ
|
132
|
1739
|
|
01MAR2000
|
YYZ
|
132
|
1478
|
|
01MAR2000
|
YYZ
|
132
|
1130
|
|
01MAR2000
|
YYZ
|
132
|
1390
|
|
01MAR2000
|
YYZ
|
132
|
1983
|
|
01MAR2000
|
YYZ
|
132
|
1111
|
|
01MAR2000
|
YYZ
|
182
|
1076
|
|
01MAR2000
|
YYZ
|
182
|
1118
|
|
EmpID
|
JobCode
|
LastName
|
FirstName
|
|---|---|---|---|
|
1350
|
FA3
|
Arthur
|
Barbara
|
|
1574
|
FA2
|
Cahill
|
Marshall
|
|
1437
|
FA3
|
Carter
|
Dorothy
|
|
1988
|
FA3
|
Dean
|
Sharon
|
|
1983
|
FA2
|
Dunlap
|
Donna
|
|
1125
|
FA2
|
Eaton
|
Alicia
|
|
1475
|
FA1
|
Fields
|
Diana
|
|
1422
|
FA1
|
Fletcher
|
Marie
|
Suppose you want to
combine all variables from the Sasuser.Flightschedule data set with
the first and last names of each flight attendant who is scheduled
to work on each flight. Sasuser.Flightschedule contains data for 45
flights. Three flight attendants are scheduled to work on each flight.
Therefore, your output data set should contain 135 observations (three
for each flight).
You could use the following
PROC SQL step to combine Sasuser.Flightschedule with Sasuser.Flightattendants.
proc sql;
create table flightemps as
select flightschedule.*, firstname, lastname
from sasuser.flightschedule, sasuser.flightattendants
where flightschedule.empid=flightattendants.empid;
quit;The resulting Flightemps
data set contains 135 observations.
Now, suppose you use
the following DATA step match-merge to combine these two data sets.
proc sort data=sasuser.flightattendants out=fa; by empid; run; proc sort data=sasuser.flightschedule out=fs; by empid; run; data flightemps2; merge fa fs; by empid; run;
The resulting Flightemps2
data set contains 272 observations. The DATA step match-merge does
not produce the correct results because it combines the data sequentially.
In the correct results, there are three observations for each unique
flight from Sasuser.Flightschedule, and there are no missing values
in any of the observations. By contrast, the results from the DATA
step match-merge contain six observations for each unique flight and
many observations that have missing values.
In the last example,
data was combined from two data sets that have a many-to-many match.
The PROC SQL join produced the correct results, but the DATA step
match-merge did not. However, you can produce the correct results
in a DATA step. First, consider using multiple SET statements to combine
data.
Using Multiple SET Statements
You can use multiple SET statements to combine observations
from several SAS data sets.
For example, the following
DATA step creates a new data set named Combine. Each observation in
Combine contains data from one observation in Dataset1 and data from
one observation in Dataset2.
data combine; set dataset1; set dataset2; run;
When you use multiple
SET statements, the following results occur:
-
Processing stops when SAS encounters the end-of-file (EOF) marker on either data set (even if there is more data in the other data set). Therefore, the output data set contains the same number of observations as the smallest input data set.
-
The variables in the program data vector (PDV) are not reinitialized when a second SET statement is executed.
-
For any variables that are common to both input data sets, the value or values from the data set in the second SET statement will overwrite the value or values from the data set in the first SET statement in the PDV.
Keep in mind that using
multiple SET statements to combine data from multiple input sources
that do not have a one-to-one match can be complicated. If you are
working with data sources that do not have a one-to-one match, or
that contain nonmatching data, you will need to add additional DATA
step syntax in order to produce the results that you want.
Example: Using Multiple SET Statements with a Many-to-Many Match
Remember that in the previous example you wanted to
combine Sasuser.Flightschedule with Sasuser.Flightattendants. Your
resulting data set should contain all variables from the Sasuser.Flightschedule
data set with the first and last names of each flight attendant who
is scheduled to work on each flight. Sasuser.Flightschedule contains
data for 45 flights, and three flight attendants are scheduled to
be on each flight. Therefore, your output data set should contain
135 observations (three for each flight).
You can use the following
DATA step to perform this table lookup operation. In this program,
the first SET statement reads an observation from the Sasuser.Flightschedule
data set. Then the DO loop executes, and the second SET statement
reads each observation in Sasuser.Flightattendants. The EmpID variable
in Sasuser.Flightattendants is renamed so that it does not overwrite
the value for EmpID that has been read from Sasuser.Flightschedule.
Instead, these two values are used for comparison to control which
observations from Sasuser.Flightattendants should be included in the
output data set for each observation from Sasuser.Flightschedule.
data flightemps3(drop=empnum jobcode);
set sasuser.flightschedule;
do i=1 to num;
set sasuser.flightattendants
(rename=(empid=empnum))
nobs=num point=i;
if empid=empnum then output;
end;
run;The resulting Flightemps3
data set contains 135 observations and no missing values. Keep in
mind that although it is possible to use a DATA step to produce the
same results that a PROC SQL join creates by default, the PROC SQL
step might be much more efficient.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.