
Using Inner Joins
Introducing Inner Join Syntax
An inner join combines
and displays only the rows from the first table that match rows from
the second table, based on the matching criteria (also known as join
conditions) that are specified in the WHERE clause. A join condition
is an expression that specifies the column(s) on which the tables
are to be joined.
The following diagram
illustrates an inner join of two tables. The shaded area of overlap
represents the matching rows (the subset of rows) that the inner join
returns as output.
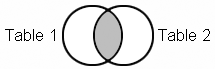
Note: An inner
join is sometimes called a conventional join.
Inner join syntax builds
on the syntax of the simplest type of join that was shown earlier.
In an inner join, a WHERE clause is added to restrict the rows of
the Cartesian product that is displayed in output.
|
General form, SELECT
statement for inner join:
SELECT column-1<,...column-n>
FROM table-1
| view-1, table-2 | view-2<,...table-n
| view-n>
WHERE join-condition(s)
<AND other
subsetting condition(s)>
<other
clauses>;
join-condition(s)
refers to one or more
expressions that specify the column or columns on which the tables
are to be joined.
other subsetting condition(s)
refers to optional
expressions that are used to subset rows in the query results.
<other clauses>
refers to optional
PROC SQL clauses.
|
Note: The maximum number of tables
that you can combine in a single inner join depends on your version
of SAS. For more information see the SAS documentation. If the join
involves views (either in-line views or PROC SQL views), it is the
number of tables that underlie the views, not the number of views
themselves, that counts toward the limit. In-line views are covered
later in this chapter and PROC SQL views are discussed in
Creating and Managing Views Using PROC SQL.
Example
When a WHERE clause
is added to the PROC SQL query shown earlier, only a subset of rows
is included in output. The modified query, tables, and output are
shown below:
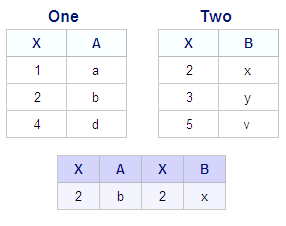
Because of the WHERE
clause, this inner join does not display all rows from the Cartesian
product (all possible combinations of rows from both tables) but only
a subset of rows. The WHERE clause expression (join condition) specifies
that the result set should include only rows whose values of column
X in the table One are equal to values in column X of the table Two.
Only one row from One and one row from Two have matching values of
X. Those two rows are combined into one row of output.
Note: PROC SQL does not perform
a join unless the columns that are compared in the join condition
(in this example, One.X, and Two.X) have the same data type. However,
the two columns are not required to have the same name. For example,
the join condition shown in the following WHERE statement is valid
if ID and EmpID have the same data type:
where table1.id = table2.empid
Note: The join condition that is
specified in the WHERE clause often contains the equal (=)
operator, but the expression might contain one or more other operators
instead. An inner join that matches rows based on the equal (=)
operator, in which the value of a column or expression in one table
must be equivalent to the value of a column or expression in another
table, is called an equijoin.
Consider how PROC SQL
processes this inner join.
Understanding How Joins Are Processed
Understanding how PROC SQL processes
inner and outer joins helps you understand which output is generated
by each type of join. Conceptually, PROC SQL follows these steps to
process a join:
-
builds a Cartesian product of rows from the indicated tables
-
evaluates each row in the Cartesian product, based on the join conditions specified in the WHERE clause (along with any other subsetting conditions), and removes any rows that do not meet the specified conditions
-
if summary functions are specified, summarizes the applicable rows
-
returns the rows that are to be displayed in output.
Note: The PROC SQL query optimizer
follows a more complex process than the conceptual approach described
here, by breaking the Cartesian product into smaller pieces. For each
query, the optimizer selects the most efficient processing method
for the specific situation.
By default, PROC SQL
joins do not overlay columns with the same name. Instead, the output
displays all columns that have the same name. To avoid having columns
with the same name in the output from an inner or outer join, you
can eliminate or rename the duplicate columns.
Tip
You can also use the COALESCE
function with an inner or outer join to overlay columns with the same
name. The COALESCE function is discussed, along with outer joins,
later in this chapter.
Eliminating Duplicate Columns
Consider the sample PROC
SQL query that uses an inner join to combine the tables One and Two:
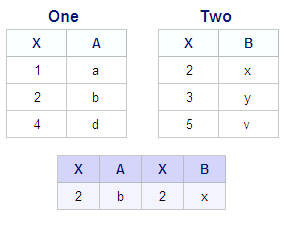
The two tables have
a column with an identical name (X). Because the SELECT clause in
the query shown above contains an asterisk, the output displays all
columns from both tables.
To eliminate a duplicate
column, you can specify just one of the duplicate columns in the SELECT
statement. The SELECT statement in the preceding PROC SQL query can
be modified as follows:
proc sql;
select one.x, a, b
from one, two
where one.x = two.xHere, the SELECT clause
specifies that only the column X from table One is included in output.
The output, which now displays only one column X, is shown below.
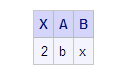
Note: In an inner equijoin, like
the one shown here, it does not matter which of the same-named columns
is listed in the SELECT statement. The SELECT statement in this example
could have specified Two.X instead of One.X.
Another way to eliminate
the duplicate X column in the preceding example is shown below:
proc sql;
select one.*, b
from one, two
where one.x = two.x;By using the asterisk
(*) to select all columns from table One, and only B from table Two,
this query generates the same output as the preceding version.
Renaming a Column By Using a Column Alias
If you are working with
several tables that have a column with a common name but slightly
different data, you might want both columns to appear in output. To
avoid the confusion of displaying two different columns with the same
name, you can rename one of the duplicate columns by specifying a
column alias in the SELECT statement. For example, you could modify
the SELECT statement of the sample query as follows:
proc sql;
select one.x as ID, two.x, a, b
from one, two
where one.x = two.x;The output of the modified
query is shown here.
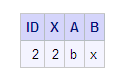
Now that the column
One.X has been renamed to ID, the output clearly indicates that ID
and X are two different columns.
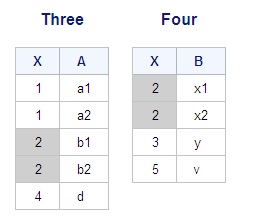
Joining Tables That Have Rows with Matching Values
Consider what happens
when you join two tables in which multiple rows have duplicate values
of the column on which the tables are being joined. Each of the tables
Three and Four has multiple rows that contain the value 2 for column
X. The following PROC SQL inner join matches rows from the two tables
based on the common column X:
The output shows how
this inner join handles the duplicate values of X.
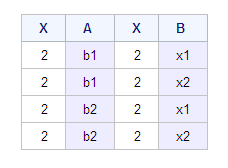
All possible combinations
of the duplicate rows are displayed. There are no matches on any other
values of X, so no other rows are displayed in output.
Note: A DATA step match-merge would
output only two rows, because it processes data sequentially from
top to bottom. Later in this chapter, there is a comparison of PROC
SQL joins and DATA step match-merges.
Specifying a Table Alias
To enable PROC SQL to distinguish
between same-named columns from different tables, you use qualified
column names. To create a qualified column name, you prefix the column
name with its table name. For example, the following PROC SQL inner
join contains several qualified column names (shown highlighted):
proc sql; title 'Employee Names and Job Codes'; select staffmaster.empid, lastname, firstname, jobcode from sasuser.staffmaster, sasuser.payrollmaster where staffmaster.empid=payrollmaster.empid;
It can be difficult
to read PROC SQL code that contains lengthy qualified column names.
In addition, entering long table names can be time-consuming. Fortunately,
you can use a temporary, alternate name for any or all tables in any
PROC SQL query. This temporary name, which is called a table alias,
is specified after the table name in the FROM clause. The keyword
AS is often used, although its use is optional.
The following modified
PROC SQL query specifies table aliases in the FROM clause, and then
uses the table aliases to qualify column names in the SELECT and WHERE
clauses:
proc sql; title 'Employee Names and Job Codes'; select s.empid, lastname, firstname, jobcode from sasuser.staffmaster as s, sasuser.payrollmaster as p where s.empid=p.empid;
In this query, the optional
keyword AS is used to define the table aliases in the FROM clause.
The FROM clause would be equally valid with AS omitted, as shown below:
from sasuser.staffmaster s, sasuser.payrollmaster p
Note: While using table aliases
help you work more efficiently, the use of table aliases does not
cause SAS to execute the query more quickly.
Table aliases are usually
optional. However, there are two situations that require their use,
as shown below.
|
Table aliases are required
when...
|
Example
|
|---|---|
|
a table is joined to
itself (called a self-join or reflexive join)
|
from airline.staffmaster as s1, airline.staffmaster as s2 |
|
you need to reference
columns from same-named tables in different libraries
|
from airline.flightdelays as af, work.flightdelays as wf where af.delay > wf.delay |
So far, you have seen
relatively simple examples of inner joins. However, as in any other
PROC SQL query, inner joins can include more advanced components,
such as
-
titles and footers
-
functions and expressions in the SELECT clause
-
multiple conditions in the WHERE clause
-
an ORDER BY clause for sorting
-
summary functions with grouping.
Here are a few examples
of more complex inner joins.
Example: Complex PROC SQL Inner Join
Suppose you want to
display the names (first initial and last name), job codes, and ages
of all company employees who live in New York. You also want the results
to be sorted by job code and age.
The data that you need
is stored in the two tables listed below.
|
Table
|
Relevant Columns
|
|---|---|
|
Sasuser.Staffmaster
|
EmpID, LastName, FirstName,
State
|
|
Sasuser.Payrollmaster
|
EmpID, JobCode, DateOfBirth
|
Of the three columns
that you want to display, JobCode is the only column that already
exists in the tables. The other two columns need to be created from
existing columns.
The PROC SQL query shown
here uses an inner join to generate the output that you want:
proc sql outobs=15;
title 'New York Employees';
select substr(firstname,1,1) || '. ' || lastname
as Name,
jobcode,
int((today() - dateofbirth)/365.25)
as Age
from sasuser.payrollmaster as p,
sasuser.staffmaster as s
where p.empid =
s.empid
and state='NY'
order by 2, 3;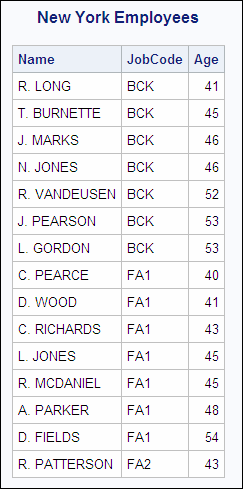
The SELECT clause, shown
below, specifies the new column Name, the existing column JobCode,
and the new column Age:
select substr(firstname,1,1) || '. ' || lastname
as Name,
jobcode,
int((today() - dateofbirth)/365.25)
as AgeTo create the two new
columns, the SELECT clause uses functions and expressions as follows:
-
To create Name, the SUBSTR function extracts the first initial from FirstName. Then the concatenation operator combines the first initial with a period, a space, and then the contents of the LastName column. Finally, the keyword AS names the new column.
-
To calculate Age, the INT function returns the integer portion of the result of the calculation. In the expression that is used as an argument of the INT function, the employee's birthdate (DateOfBirth) is subtracted from today's date (returned by the TODAY function), and the difference is divided by the number of days in a year (365.25).
The WHERE clause contains
two expressions linked by the logical operator AND:
where p.empid =
s.empid
and state='NY'This query only outputs
rows that have matching values of EmpID and rows in which the value
of State is
NY. You do not need to
prefix the column name State with a table name, because State occurs
in only one of the tables.
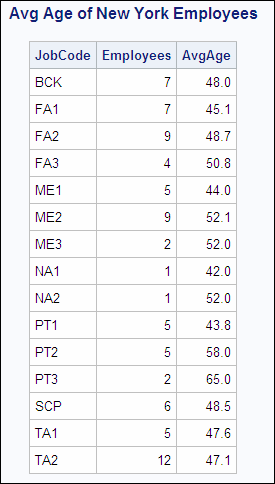
Example: PROC SQL Inner Join with Summary Functions
You can also summarize
and group data in a PROC SQL join. To illustrate, modify the previous
PROC SQL inner join so that the output displays the following summarized
columns for New York employees in each job code: number of employees
and average age. The modified query is shown below:
proc sql outobs=15;
title 'Avg Age of New York Employees';
select jobcode,
count(p.empid) as Employees,
avg(int((today() - dateofbirth)/365.25))
format=4.1 as AvgAge
from sasuser.payrollmaster as p,
sasuser.staffmaster as s
where p.empid =
s.empid
and state='NY'
group by jobcode
order by jobcode;To create two new columns,
the SELECT clause uses summary functions as follows:
-
To create Employees, the COUNT function is used with p.EmpID (Payrollmaster.EmpID) as its argument.
-
To create AvgAge, the AVG function is used with an expression as its argument. As described in the previous example, the expression uses the INT function to calculate each employee's age.
The output of this modified
query is shown below.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.