
Comparing SQL Joins and DATA Step Match-Merges
Overview
You should be
familiar with the use of the DATA step to merge data sets. DATA step
match-merges and PROC SQL joins can produce the same results. However,
there are important differences between these two techniques. For
example, a join does not require that you sort the data first; a DATA
step match-merge requires that the data be sorted.
Compare the use of SQL
joins and DATA step match-merges in the following situations:
-
when all of the values of the selected variable (column) match
-
when only some of the values of the selected variable (column) match.
When All of the Values Match
When all of the
values of the BY variable match, you can use a PROC SQL inner join
to produce the same results as a DATA step match-merge.
Suppose you want to
combine the tables One and Two, as shown below.
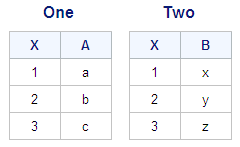
These two tables have
the column X in common, and all values of X in each row match across
the two tables. Both tables are already sorted by X.
The following DATA step
match-merge (followed by a PROC PRINT step) and the PROC SQL inner
join produce identical reports.
|
DATA Step Match-Merge
|
PROC SQL Inner Join
|
|---|---|
data merged;
merge one two;
by x; run;
proc print data=merged noobs;
title 'Table Merged';
run; |
proc sql;
title 'Table Merged';
select one.x, a, b
from one, two
where one.x = two.x
order by x; |
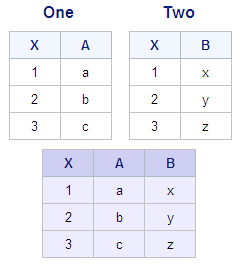
Note: The DATA step match-merge
creates a data set whereas the PROC SQL inner join, as shown here,
creates only a report as output. To make these two programs completely
identical, the PROC SQL inner join could be rewritten to create a
table. For detailed information about creating tables with PROC SQL,
see
Creating and Managing Tables Using PROC SQL.
Note: If the order of rows in the
output does not matter, the ORDER BY clause can be removed from the
PROC SQL join. Without the ORDER BY clause, this join is more efficient,
because PROC SQL does not need to make a second pass through the data.
When Only Some of the Values Match
When only some of the values of the BY variable match,
you can use a PROC SQL full outer join to produce the same result
as a DATA step match-merge. Unlike the DATA step match-merge, however,
a PROC SQL outer join does not overlay the two common columns by
default. To overlay common columns, you must use the COALESCE function
in the PROC SQL full outer join.
Note: The COALESCE function can
also be used with inner join operators.
Consider what happens when you use a
PROC SQL full outer join without the COALESCE function. Suppose you
want to combine the tables Three and Four. These two tables have the
column X in common, but most of the values of X do not match across
tables. Both tables are already sorted by X. The following DATA step
match-merge (followed by a PROC PRINT step) and the PROC SQL outer
join combine these tables, but do not generate the same output. The
COALESCE function can also be used with inner join operators.
|
DATA Step Match-Merge
|
PROC SQL Full Outer
Join
|
|---|---|
data merged;
merge three four;
by x;
run;
proc print data=merged noobs;
title 'Table Merged';
run; |
proc sql;
title 'Table Merged';
select three.x, a, b
from three
full join
four
on three.x = four.x
order by x; |
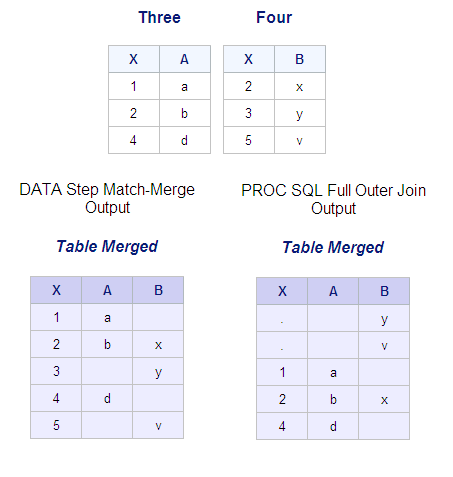
The DATA step match-merge
automatically overlays the common column, X. The PROC SQL outer join
selects the value of X from just one of the tables, table Three, so
that no X values from table Four are included in the PROC SQL output.
However, the PROC SQL outer join cannot overlay the columns by default.
The values that vary across the two merged tables are in bold above.
Consider how the COALESCE
function is used in the PROC SQL outer join to overlay the common
columns.
When Only Some of the Values Match: Using the COALESCE Function
When you add the COALESCE function
to the SELECT clause of the PROC SQL outer join, the PROC SQL outer
join can produce the same result as a DATA step match-merge.
|
General form, COALESCE
function in a basic SELECT clause:
SELECT COALESCE (column-1<,...column-n>)
column-1 through column-n
are the names of two
or more columns to be overlaid. The COALESCE function requires that
all arguments have the same data type.
|
The COALESCE function
overlays the specified columns by
-
checking the value of each column in the order in which the columns are listed
-
returning the first value that is a SAS nonmissing value.
Note: If all returned values are
missing, COALESCE returns a missing value.
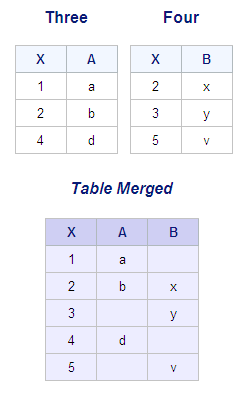
When the COALESCE function
is added to the preceding PROC SQL full outer join, the DATA step
match-merge (with PROC PRINT step) and the PROC SQL full outer join
will combine rows in the same way. The two programs, the tables, and
the output are shown below.
Understanding the Advantages of PROC SQL Joins
DATA step match-merges and PROC SQL joins both have
advantages and disadvantages. Here are some of the main advantages
of PROC SQL joins.
|
Advantage
|
Example
|
|---|---|
|
PROC SQL joins do not
require sorted or indexed tables.
|
proc sql;
select table1.x, a, b
from table1
full join
table2
on table1.x = table2.x; where table-1 is
sorted by column X and table-2 is not |
|
PROC SQL joins do not
require that the columns in join expressions have the same name.
|
proc sql;
select table1.x, lastname,
status
from table1, table2
where table1.id =
table2.custnum; |
|
PROC SQL joins can use
comparison operators other than the equal sign (=).
|
proc sql;
select a.itemnumber, cost,
price
from table1 as a,
table2 as b
where a.itemnumber = b.itemnumber
and a.cost>b.price; |
Note: Join performance can be substantially
improved when the tables are indexed on the column(s) on which the
tables are being joined. You can learn more about indexing in
Creating and Managing Indexes Using PROC SQL.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.