
CHAPTER 5
Practical Beagle Board Programming
This chapter describes several different programming options for the Beagle boards, including scripted and compiled languages. An LED flashing example is provided in all the languages so that you can investigate each language's structure and syntax. The advantages and disadvantages of each language are discussed along with example uses. The chapter then focuses on the C/C++ programming languages, describing their principles and why object-oriented programming (OOP) is appropriate and necessary for the development of scalable embedded systems applications. Finally, the chapter details how you can interface directly to the Linux kernel using the GNU C library. A single chapter can only scratch the surface on this topic, so this one focuses on physical programming tasks, which are required throughout the remainder of this book.
EQUIPMENT REQUIRED FOR THIS CHAPTER:
Introduction
As discussed in Chapter 3, embedded Linux is essentially “Linux on an embedded system.” If your favorite programming language is available under Linux, then it is also likely to be available for the Beagle boards. So, is your favorite language suitable for programming your board? That depends on what you intend to do with the board. Are you interfacing to electronics devices/modules? Do you plan to write rich user interfaces? Are you planning to write a device driver for Linux? Is performance important, or are you developing an early pre-prototype? Each of the answers to these questions will impact your decision regarding which language you should use. In this chapter, you are introduced to several different languages, and the advantages and disadvantages of each category of language are outlined. As you read through the chapter, try to avoid focusing on a favorite language, but instead use the correct language for the job at hand.
How does programming on embedded systems compare to programming on desktop computers? Here are some points to consider:
- You should always write the clearest and cleanest code that is as maintainable as possible, just as you would on a desktop PC.
- Don't optimize your code until you are certain that it is complete.
- You typically need to be more aware of how you are consuming resources than when programming on the desktop computer. The size of data types matter, and passing data correctly really matters. You need to be concerned with memory availability, file system size, and data communication availability/bandwidth.
- You often need to learn about the underlying hardware platform. How does it handle the connected hardware? What data buses are available? How do you interface with the operating system and low-level libraries? Are there any real-time constraints?
For the upcoming discussion, it is assumed you are planning to do some type of physical computing—that is, interfacing to the different input or outputs on your board. Therefore, the example that is used to describe the structure and syntax of the different languages is a simple interfacing example. Before looking at the languages themselves, we will begin with a brief performance evaluation of different languages running on the Beagle platform in order to put the following discussions in context.
Performance of Different Languages
Which language is the best on the Beagle platform? Well, that is an incredibly emotive and difficult question to answer. Different languages perform better on different benchmarks and different tasks. In addition, a program written in a particular language can be optimized for that language to the point that it is barely recognizable as the original code. Nor is speed of execution always an important factor; you may be more concerned with memory usage, the portability of the code, or the ability to quickly apply changes.
However, if you are planning to develop high-speed or real-time number-crunching applications, then performance may be a key factor in your choice of programming language. In addition, if you are setting out to learn a new language and you may possibly be developing algorithmically rich programs in the future, then it may be useful to keep performance in mind.
A simple test has been put in place to determine the CPU performance of the languages discussed in this chapter. The test uses the n-body benchmark (gravitational interaction of planets in the solar system) code from benchmarksgame.alioth.debian.org. The code uses the same algorithm for all languages, and the board is running in the same state in all cases. The test uses 5 million iterations of the algorithm to ensure that the script used for timing does not need to be highly accurate. All of the programs gave the same correct result, indicating that these all ran correctly and to completion. The test is available in the book's Git repository in the directory chp05/performance/. Note that you must have installed Java and other languages on your board to run all of the tests. Use the following call to execute the test:
/chp05/performance$ ./runRunning the Tests:The C/C++ Code Example-0.169075164 -0.169083134It took 34 seconds to run the C/C++ test …Finished Running the Benchmarks
The results of the tests are displayed in Table 5-1. In the first column, you can see the results for the PocketBeagle, running at its top processor frequency of 1 GHz. For this number-crunching application, the general-purpose language, C++, performs the task in 34 seconds. This time has been weighted as one unit. Therefore, Java takes 1.15 times longer to complete the same task, the highly optimized Rust completes the task more quickly than C++, Node.js (for BoneScript) is 1.24 times longer, Perl takes 26.8 times longer, and Python takes 57 times longer. The processing durations in seconds are provided in parentheses. As you move across the columns, you can see that this performance is relatively consistent, even as the processor frequency is adjusted (discussed in the next section) or a desktop i7 64-bit processor is used.
Table 5-1: Numerical Computation Time for 5,000,000 Iterations of the n-Body Algorithm on a BeagleBoard.org Debian Stretch Hard-float Image
| VALUE | TYPE | POCKETBEAGLE1 AT 1 GHZ | POCKETBEAGLE AT 600 MHZ | INTEL 64-BIT I7 DEBIAN PC2 |
| C++3 | Compiled | 1.00× (34 s) | 1.00× (57 s) | 1.00× (0.641 s) |
| C (gcc) | Compiled | 0.95× (32 s) | 0.96× (55 s) | 0.97× (0.623s) |
| Rust4 | Compiled | 0.85× (29 s) | 0.86× (49 s) | 0.66× (0.425 s) |
| C++14 | Compiled | 1.06× (36 s) | 1.07× (61 s) | 0.95× (0.608 s) |
| Haskell5 | Compiled | 1.06× (36 s) | 1.05× (60 s) | 1.78× (1.141 s) |
| Java6 | JIT | 1.15× (39 s) | 1.16× (66 s) | 1.28× (0.818 s) |
| Node.js7 | JIT | 1.24× (42 s) | 1.30× (74 s) | 1.67× (1.071 s) |
| Mono C# | JIT | 1.50× (51 s) | 1.53× (87.4 s) | 2.13× (1.363 s) |
| Cython8 | Compiled | 1.97× (67 s) | 1.96× (112 s) | 1.19× (0.765 s) |
| Lua9 | Interpreted | 6.41× (218 s) | 6.31× (360 s) | 28.6× (18.304 s) |
| Cython | Compiled | 22.0× (751 s) | 22.1× (1262 s) | 55.8× (35.742 s) |
| Perl | Interpreted | 26.8× (910 s) | 20.3× (1156 s) | 59.6× (38.214 s) |
| Ruby10 | Interpreted | 34.2× (1162 s) | 31.0× (1770 s) | 46.0× (29.454 s) |
| Python | Interpreted | 57.0× (1937 s) | 58.2× (3318 s) | 98.3× (63.032 s) |
The second column in Table 5-1 indicates the language type, where compiled refers to natively compiled languages, JIT refers to just-in-time compiled languages, and interpreted refers to code that is executed by interpreters. The distinction in these language types is described in detail throughout this chapter and is not quite as clear-cut as presented in the table.
All of the programs use between 98 percent and 99 percent of the CPU while executing. The relative performance of Java, Node.js, and Mono C# is impressive given that code is compiled dynamically (“just-in-time”), which is discussed later in this chapter. Any dynamic compilation latency is included in the timings, as the test script includes the following Bash script code to calculate the execution duration of each program:
Duration="5000000"echo -e " The C++ Code Example"T="$(date +%s%N)"./n-body $DurationT="$(($(date +%s%N)-T))"T=$((T/1000000))echo "It took ${T} milliseconds to run the C++ test"
The C++14 code is the version of the C++ programming language that was published in 2014 (needs gcc 5+ for full support). This is discussed again later in this chapter. The program contains optimizations that are specific to this release of C++, and interestingly, while this version performs better on the desktop computer, it slightly underperforms on the PocketBeagle. The Java program uses the +AggressiveOpts flag to enable performance optimization, and it was used because it did not involve modifying the source code.
The results for Python are particularly poor because of the algorithmic nature of the problem. However, the benchmarks (benchmarksgame.alioth.debian.org) indicate that the range will be 9 to 100 times slower than the optimized C++ code for general processing to algorithm-rich code, respectively. If you are comfortable with Python and you would like to improve upon its performance, then you can investigate Cython, which is a Python compiler that automatically removes the dynamic typing capability and enables you to generate C code directly from your Python code. Cython and the extension of Python with C/C++ are discussed at the end of this chapter.
The final column provides the results for the same code running on a desktop computer virtual machine. You can see that the relative performance of the applications is broadly in line, but also note that the C++ program runs 40 times faster on the single i7 thread than it does on the PocketBeagle at 1 GHz. I hope that will help you frame your expectations with respect to the type of numerical processing that is possible on a standard Beagle board, particularly when investigating computationally expensive applications such as signal processing and computer vision.
As previously discussed, this is only one numerically oriented benchmark test, but it is somewhat indicative of the type of performance you should expect from each language. There have been many studies on the performance of languages; however, a well-specified analysis by Hundt (2011) has found that in terms of performance, “C++ wins out by a large margin. However, it also required the most extensive tuning efforts, many of which were done at a level of sophistication that would not be available to the average programmer.”
Setting the CPU Frequency
In the previous section, the clock frequency of the Beagle board was adjusted dynamically at run time. The BeagleBoard.org Debian image has various governors that can be used to profile the performance/power usage ratio. For example, if you were building a battery-powered PocketBeagle application that has low processing requirements, you could reduce the clock frequency to conserve power. You can find out information about the current state of the board by typing the following:
debian@ebb:~$ sudo apt install cpufrequtilsdebian@ebb:~$ cpufreq-info…available cpufreq governors: conservative, ondemand, userspace,powersave, performance, schedutilcurrent policy: frequency should be within 300 MHz and 1000 MHz.The governor "performance" may decide which speed to usewithin this range.current CPU frequency is 1000 MHz.cpufreq stats: 300 MHz:0.00%, 600 MHz:0.00%, 720 MHz:0.00%,800 MHz:0.00%, 1000 MHz:100.00%
You can see that different governors are available, with the profile names conservative, ondemand, userspace, powersave, performance, and schedutil. To enable one of these governors, type the following:
debian@ebb:~$ sudo cpufreq-set -g ondemanddebian@ebb:~$ cpufreq-info… The governor "ondemand" may decide which speed to use within this range.debian@ebb:~$ sudo cpufreq-set -f 600MHzdebian@ebb:~$ cpufreq-info… current CPU frequency is 600 MHz.
The ondemand is useful as it dynamically switches the CPU frequency. For example, if the CPU frequency is currently 600 MHz and the average CPU usage between governor samplings is above the threshold (called the up_threshold), then the CPU frequency will be automatically increased. You can tweak these and other settings using their sysfs entries. For example, to set the threshold at which the CPU frequency rises to the point at which the CPU load reaches 90 percent of available capacity, use the following:
debian@ebb:~$ sudo cpufreq-set -g ondemanddebian@ebb:~$ cd /sys/devices/system/cpu/cpufreq/ondemand/debian@ebb:/sys/devices/system/cpu/cpufreq/ondemand$ lsignore_nice_load min_sampling_rate sampling_down_factor up_thresholdio_is_busy powersave_bias sampling_ratedebian@ebb: … /ondemand$ cat up_threshold95debian@ebb: … /ondemand$ sudo sh -c "echo 90 > up_threshold"debian@ebb: … /ondemand$ cat up_threshold90
If these tools are not installed on your board, you must install the cpufrequtils package. On Debian Stretch, the default governor is performance, but you can switch to ondemand by editing the cpufrequtils file in /etc/init.d/ as follows:
debian@ebb:~$ cd /etc/init.ddebian@ebb:/etc/init.d$ more cpufrequtils | grep GOVERNOR=GOVERNOR="performance"debian@ebb:/etc/init.d$ sudo nano cpufrequtilsdebian@ebb:/etc/init.d$ more cpufrequtils | grep GOVERNOR=GOVERNOR="ondemand"debian@ebb:/etc/init.d$ sudo reboot
Scripting Languages
A scripting language is a computer programming language that is used to specify script files, which are interpreted directly by a run-time environment to perform tasks. Many scripting languages are available, such as Bash, Perl, Lua, and Python, and these can be used to automate the execution of tasks on a Beagle board, such as system administration, interaction, and even interfacing to electronic components.
Scripting Language Options
Which scripting language should you choose for a Beagle board? There are many strong opinions, and it is a difficult topic, as Linux users tend to have a favorite scripting language; however, you should choose the scripting language with features that suit the task at hand. Here are some examples:
- Bash scripting: A great choice for short scripts that do not require advanced programming structures. Bash scripts are used extensively in this book for small, well-defined tasks, such as the timing code in the previous section. You can use the Linux commands discussed in Chapter 3 in your Bash scripts.
- Perl: A great choice for scripts that parse text documents or process streams of data. It enables you to write straightforward scripts and even supports the object-oriented programming (OOP) paradigm, which is discussed later in this chapter.
- Lua: Is a fast and lightweight scripting language that can be used for embedded applications because of its small footprint. Lua supports the object-oriented programming (OOP) paradigm (using tables and functions) and dynamic typing, which is discussed shortly. Lua has an important role in Chapter 12 for the programming of NodeMCU Wi-Fi modules.
- Python: Is great for scripts that need more complex structure and are likely to be built upon or modified in the future. Python supports the OOP paradigm and dynamic typing, which is discussed shortly.
These four scripting languages are available for the Beagle standard Debian image. It would be useful to have some knowledge of all of these scripting languages, as you may find third-party tools or libraries that make your current project straightforward. This section provides a brief overview of each of these languages, including a concise segment of code that performs a similar function in each language. It finishes with a discussion about the advantages and disadvantages of scripting languages in general.
In Chapter 2 an approach is described for changing the state of the on-board LEDs using Linux shell commands. It is possible to turn an LED on or off, and even make it flash. For example, you can use the following:
root@ebb:/sys/class/leds/beaglebone:green:usr3# echo none > triggerroot@ebb:/sys/class/leds/beaglebone:green:usr3# echo 1 > brightnessroot@ebb:/sys/class/leds/beaglebone:green:usr3# echo 0 > brightness
to turn a user LED on and off. This section examines how it is possible to do the same tasks but in a structured programmatic form.
Bash
Bash scripts are a great choice for short scripts that do not require advanced programming structures, and that is exactly the application to be developed here. The first program leverages the Linux console commands such as echo and cat to create the concise script in Listing 5-1 that enables you to choose, using command-line arguments, whether you want to turn the USR3 LED on or off or place it in a flashing mode. For example, using this script by calling ./bashLED on would turn the USR3 LED on. It also provides you with the trigger status information.
Listing 5-1: chp05/bashLED/bashLED
#!/bin/bashLED3_PATH=/sys/class/leds/beaglebone:green:usr3function removeTrigger{echo "none" >> "$LED3_PATH/trigger"}echo "Starting the LED Bash Script"if [ $# != 1 ]; thenecho "There is an incorrect number of arguments. Usage is:"echo -e " bashLED Command where command is one of "echo -e " on, off, flash or status e.g. bashLED on "exit 2fiecho "The LED Command that was passed is: $1"if [ "$1" == "on" ]; thenecho "Turning the LED on"removeTriggerecho "1" >> "$LED3_PATH/brightness"elif [ "$1" == "off" ]; thenecho "Turning the LED off"removeTriggerecho "0" >> "$LED3_PATH/brightness"elif [ "$1" == "flash" ]; thenecho "Flashing the LED"removeTriggerecho "timer" >> "$LED3_PATH/trigger"echo "50" >> "$LED3_PATH/delay_on"echo "50" >> "$LED3_PATH/delay_off"elif [ "$1" == "status" ]; thencat "$LED3_PATH/trigger";fiecho "End of the LED Bash Script"
The script is available in the directory /chp05/bashLED/. If you entered the script manually using the nano editor, then the file needs to have the executable flag set before it can be executed (the git repository retains executable flags). Therefore, to allow all users to execute this script, use the following:
/chp05/bashLED$ chmod ugo+x bashLED What is happening within this script? First, all of these command scripts begin with a sha-bang #! followed by the name and location of the interpreter to be used, so #!/bin/bash in this case. The file is just a regular text file, but the sha-bang is a magic-number code to inform the OS that the file is an executable. Next, the script defines the path to the LED for which you want to change state using the variable LED3_PATH. This allows the default value to be easily altered if you want to use a different user LED or path.
The script contains a function called removeTrigger, mainly to demonstrate how functions are structured within Bash scripting. This function is called later in the script. Each if is terminated by a fi. The ; after the if statement terminates that statement and allows the statement then to be placed on the same line. The elif keyword means else if, which allows you to have multiple comparisons within the one if block. The newline character
terminates statements.
The first if statement confirms that the number of arguments passed to the script ($#) is not equal to 1. Remember that the correct way to call this script is of the form ./bashLED on. Therefore, on will be the first user argument that is passed ($1), and there will be one argument in total. If there are no arguments, then the correct usage will be displayed, and the script will exit with the return code 2. This value is consistent with Linux system commands, where an exit value of 2 indicates incorrect usage. Success is indicated by a return value of 0, so any other nonzero return value generally indicates the failure of a script.
If the argument that was passed is on, then the code displays a message; calls the removeTrigger function; and writes the string "1" to the brightness file in the LED3 /sys/ directory. The remaining functions modify the USR3 LED values in the same way as described in Chapter 2. You can execute the script as follows:
debian@ebb:~/exploringbb/chp05/bashLED$ ./bashLEDThere are no arguments. Usage is:bashLED Command where command is one ofon, off, flash or status e.g. bashLED ondebian@ebb:~/exploringbb/chp05/bashLED$ ./bashLED statusThe LED Command that was passed is: statusnone … mmc0 [timer] oneshot disk-activity …debian@ebb:~/exploringbb/chp05/bashLED$ ./bashLED onThe LED Command that was passed is: onTurning the LED ondebian@ebb:~/exploringbb/chp05/bashLED$ sudo ./bashLED flashdebian@ebb:~/exploringbb/chp05/bashLED$ ./bashLED off
Notice that the script was prefixed by sudo when it was called for the flash function only. This is because the flash function enables the timer state on the LED, which creates two new file entries in the directory called delay_on and delay_off. Unlike the other entries in this directory, these two new entries are not in the gpio group, and therefore the user debian does not have permission to write to them.
debian@ebb:/sys/class/leds/beaglebone:green:usr3$ ls -l-rw-rw-r-- 1 root gpio 4096 May 13 09:16 brightness-rw-r--r-- 1 root root 4096 May 13 17:42 delay_off-rw-r--r-- 1 root root 4096 May 13 17:42 delay_on …
For security reasons, you cannot use the setuid bit on a script to set it to execute as root. If users had write access to this script and its setuid bit was set as root, then they could inject any command that they wanted into the script and would have de facto superuser access to the system. For a comprehensive online guide to Bash scripting, please see Mendel Cooper's “Advanced Bash-Scripting Guide” at www.tldp.org/LDP/abs/html/.
Lua
Lua is the best performing interpreted language in Table 5-1 by a significant margin. In addition to good performance, Lua has a clean and straightforward syntax that is accessible for beginners. The interpreter for Lua has a small footprint—approximately 131 KB in size (ls -lh /usr/bin/lua5.3), which makes it suitable for low-footprint embedded applications. For example, Lua can be used successfully on the ultra-low-cost ($2–$5) ESP Wi-Fi modules that are described in Chapter 12, despite their modest memory allocations. In fact, once a platform has an ANSI C compiler, then the Lua interpreter can be built for it. However, one downside is that the standard library of functions is somewhat limited in comparison to other more general scripting languages, such as Python. You can install the Lua interpreter using sudo apt install lua5.3.
Listing 5-2 provides a Lua script that has the same structure as the Bash script, so it is not necessary to discuss it in detail.
Listing 5-2: chp05/luaLED/luaLED.lua
#!/usr/bin/lua5.3local LED3_PATH = "/sys/class/leds/beaglebone:green:usr3/"-- Example function to write a value to the GPIOfunction writeLED(directory, filename, value)file = io.open(directory..filename, "w") -- append dir and file namesfile:write(value) -- write the value to the filefile:close()endprint("Starting the Lua LED Program")if arg[1]==nil then -- no argument provided?print("This program requires a command")print(" usage is: ./luaLED.lua command")print("where command is one of on, off, or status")do return endendif arg[1]=="on" thenprint("Turning the LED on")writeLED(LED3_PATH, "trigger", "none")os.execute("sleep 0.1")writeLED(LED3_PATH, "brightness", "1")elseif arg[1]=="off" thenprint("Turning the LED off")writeLED(LED3_PATH, "trigger", "none")os.execute("sleep 0.1")writeLED(LED3_PATH, "brightness", "0")elseif arg[1]=="status" thenprint("Getting the LED status")file = io.open(LED3_PATH.."brightness", "r")print(string.format("The LED state is %s.", file:read()))file:close()elseprint("Invalid command!")endprint("End of the Lua LED Program")
You can execute this script in the same manner as the bashLED script (e.g., ./luaLED.lua on or by typing lua luaLED.lua on from the /chp05/luaLED/ directory), and it will result in a comparable output. There are two things to be careful of with Lua in particular: strings are indexed from 1, not 0; and functions can return multiple values, unlike most languages. Lua has a straightforward interface to C/C++, which means that you can execute compiled C/C++ code from within Lua or use Lua as an interpreter module within your C/C++ programs. There is an excellent reference manual at www.lua.org/manual/ and a six-page summary of Lua at tiny.cc/beagle501.
Perl
Perl is a feature-rich scripting language that provides you with access to a huge library of reusable modules and portability to other OSs (including Windows). Perl is best known for its text processing and regular expressions modules. In the late 1990s it was a popular language for server-side scripting for the dynamic generation of web pages. Later it was superseded by technologies such as Java servlets, Java Server Pages (JSP), and PHP. The language has evolved since its birth in the 1980s and now includes support for the OOP paradigm. Perl 5 (v5.24+) is installed by default on the Debian Linux image. Listing 5-3 provides a segment of a Perl example that has the same structure as the Bash script, so it is not necessary to discuss it in detail. Apart from the syntax, little has actually changed in the translation to Perl.
Listing 5-3: chp05/perlLED/perlLED.pl (Segment)
#!/usr/bin/perl$LED3_PATH = "/sys/class/leds/beaglebone:green:usr3";$command = $ARGV[0];# Perl Write to LED3 function, the filename $_[0] is the first argument# and the value to write is the second argument $_[1]sub writeLED3{open(FILE, ">" . $LED3_PATH . $_[0] )or die "Could not open the file, $!";print FILE $_[1] ;close(FILE);}sub removeTrigger{writeLED3 ( "/trigger", "none");}print "Starting the LED Perl Script ";# 0 means that there is exactly one argumentif ( $#ARGV != 0 ){print "There are an incorrect number of arguments. Usage is: ";print " bashLED Command, where command is one of ";print " on, off, flash or status e.g. bashLED on ";exit 2;}print "The LED Command that was passed is: " . $command . " ";if ( $command eq "on" ){print "Turning the LED on ";removeTrigger();writeLED3 ("/brightness", "1");}… //full listing available in chp05/perlLED/perlLED.pl
A few small points are worth noting in the code. The < or > sign on the filename indicates whether the file is being opened for read or write access, respectively; the arguments are passed as $ARGV[0…n], and the number of arguments is available as the value $#ARGV. A file open, followed by a read or write, and a file close are necessary to write the values to /sys/; and the arguments are passed to the subroutine writeLED3 and these are received as the values $_[0] and $_[1], which is not the most beautiful programming syntax, but it works perfectly well. To execute this code, simply type sudo ./perlLED.pl on, as the sha-bang identifies the Perl interpreter. You could also execute it by typing perl perlLED.pl status.
For a good resource about getting started with installing and using Perl 5, see the guide “Learning Perl” at learn.perl.org.
Python
Python is a dynamic and strongly typed OOP language that was designed to be easy to learn and understand. Dynamic typing means you do not need to associate a type (e.g., integer, character, string) with a variable; rather, the value of the variable “remembers” its own type. Therefore, if you were to create a variable x=5, the variable x would behave as an integer; but if you subsequently assign it using x="test", it would then behave like a string. Statically typed languages such as C/C++ or Java would not allow the redefinition of a variable in this way (within the same scope). Strongly typed means that the conversion of a variable from one type to another requires an explicit conversion. The advantages of object-oriented programming structures are discussed later in this chapter. Python is installed by default on the BeagleBoard Debian image. The Python example to flash the LED is provided in Listing 5-4.
Listing 5-4: chp05/pythonLED/pythonLED.py
#!/usr/bin/pythonimport sysLED3_PATH = "/sys/class/leds/beaglebone:green:usr3"def writeLED ( filename, value, path=LED3_PATH ):"This function writes the passed value to the file in the path"fo = open( path + filename,"w")fo.write(value)fo.close()returndef removeTrigger():writeLED (filename="/trigger", value="none")returnprint "Starting the LED Python Script"if len(sys.argv)!=2:print "There are an incorrect number of arguments"print " usage is: pythonLED.py command"print " where command is one of on, off, flash or status."sys.exit(2)if sys.argv[1]=="on":print "Turning the LED on"removeTrigger()writeLED (filename="/brightness", value="1")elif sys.argv[1]=="off":print "Turning the LED off"removeTrigger()writeLED (filename="/brightness", value="0")elif sys.argv[1]=="flash":print "Flashing the LED"writeLED (filename="/trigger", value="timer")writeLED (filename="/delay_on", value="50")writeLED (filename="/delay_off", value="50")elif sys.argv[1]=="status":print "Getting the LED trigger status"fo = open( LED3_PATH + "/trigger", "r")print fo.read()fo.close()else:print "Invalid Command!"print "End of Python Script"
The formatting of this code is important—in fact, Python enforces the layout of your code by making indentation a structural element. For example, after the line if len(sys.argv)!=2:, the next few lines are “tabbed” in. If you did not tab in one of the lines—for example, the sys.exit(2) line—then it would not be part of the conditional if statement, and the code would always exit at this point in the program. To execute this example, in the pythonLED directory, enter the following:
debian@ebb:~/exploringbb/chp05/pythonLED$ sudo ./pythonLED.py flashFlashing the LEDdebian@ebb:~/exploringbb/chp05/pythonLED$ ./pythonLED.py status… [timer] oneshot disk-activity ide-disk mtd nand-disk heartbeat …
Python is popular on the Beagle platform for good pedagogical reasons, but as users turn their attention to more advanced applications, it is difficult to justify the performance deficit. This chapter concludes with a discussion on how you can use either Cython or combine Python with C/C++ to dramatically improve the performance of Python. However, the complexity of Cython itself should motivate you to consider using C/C++ directly.
To conclude this discussion of scripting, there are several strong choices for applications on the Beagle platform. Table 5-2 lists some of the key advantages and disadvantages of command scripting, when considered in the context of the compiled languages discussed shortly.
Table 5-2: Advantages and Disadvantages of Command Scripting
| ADVANTAGES | DISADVANTAGES |
| Perfect for automating Linux system administration tasks that require calls to Linux commands. | Performance is poor for complex numerical or algorithmic tasks. |
Easy to modify and adapt to changes. Source code is always present and complex toolchains (see Chapter 7) are not required to make modifications. Generally, nano is the only tool that you need. |
Generally, relatively poor/slow programming support for data structures, graphical user interfaces, sockets, threads, etc. |
| Generally, straightforward programming syntax and structure that are reasonably easy to learn when compared to languages like C++ and Java. | Generally, poor support for complex applications involving multiple, user-developed modules or components (Python and Perl do support OOP). |
| Generally, quick turnaround in coding solutions by occasional programmers. | Code is in the open. Direct access to view your code can be an intellectual property or a security concern. |
| Lack of development tools (e.g., refactoring). |
Dynamically Compiled Languages
With the interpreted languages just discussed, the source code text file is “executed” by the user passing it to a run-time interpreter, which then translates or executes each line of code. JavaScript and Java have different life cycles and are quite distinct languages.
JavaScript and Node.js on the Beagle boards
As discussed in Chapter 2, in the section “Node.js, Cloud9, and BoneScript,” Node.js is JavaScript that is run on the server side. JavaScript is an interpreted language by design; however, thanks to the V8 engine that was developed by Google for its Chrome web browser, Node.js actually compiles JavaScript into native machine instructions as it is loaded by the engine. This is called just-in-time (JIT) compilation or dynamic translation. As demonstrated at the beginning of this chapter, Node.js's performance for the numerical computation tasks is impressive for an interpreted language because of optimizations for the ARMv7 platform.
Listing 5-5 is the same LED code example written using JavaScript and executed by calling the nodejs executable.
Listing 5-5: chp05/nodejsLED/nodejsLED.js
// Ignore the first two arguments (nodejs and the program name)var myArgs = process.argv.slice(2);var LED3_PATH = "/sys/class/leds/beaglebone:green:usr3"function writeLED( filename, value, path ){var fs = require('fs');try {// The next call must be syncronous, otherwise the timer will not workfs.writeFileSync(path+filename, value);}catch (err) {console.log("The Write Failed to the File: " + path+filename);}}function removeTrigger(){writeLED("/trigger", "none", LED3_PATH);}console.log("Starting the LED Node.js Program");if (myArgs[0]==null){console.log("There is an incorrect number of arguments.");console.log(" Usage is: nodejs nodejsLED.js command");console.log(" where command is one of: on, off, flash or status.");process.exit(2); //exits with the error code 2 (incorrect usage)}switch (myArgs[0]) {case 'on':console.log("Turning the LED On");removeTrigger();writeLED("/brightness", "1", LED3_PATH);break;case 'off':console.log("Turning the LED Off");removeTrigger();writeLED("/brightness", "0", LED3_PATH);break;case 'flash':console.log("Making the LED Flash");writeLED("/trigger", "timer", LED3_PATH);writeLED("/delay_on", "50", LED3_PATH);writeLED("/delay_off", "50", LED3_PATH);break;case 'status':console.log("Getting the LED Status");fs = require('fs');fs.readFile(LED3_PATH+"/trigger", 'utf8', function (err, data) {if (err) { return console.log(err); }console.log(data);});break;default:console.log("Invalid Command");}console.log("End of Node.js script");
The code is available in the /chp05/nodejsLED/ directory, and it can be executed by typing nodejs nodejsLED.js [option]. The code has been structured in the same way as the previous examples, and there are not too many syntactical differences; however, there is one major difference between Node.js and other languages: functions are called asynchronously. Up to this point, all the languages discussed followed a sequential-execution mode. Therefore, when a function is called, the program counter (also known as the instruction pointer) enters that function and does not reemerge until the function is complete. Consider, for example, code like this:
functionA();functionB();
The functionA() is called, and functionB() will not be called until functionA() is fully complete. This is not the case in Node.js! In Node.js, functionA() is called first, and then Node.js continues executing the subsequent code, including entering functionB(), while the code in functionA() is still being executed. This presents a serious difficulty for the current application, with this segment of code in particular:
case 'flash':console.log("Making the LED Flash");writeLED("/trigger", "timer", LED3_PATH);writeLED("/delay_on", "50", LED3_PATH);writeLED("/delay_off", "50", LED3_PATH);break;
The first call to writeLED() sets up the sysfs file system (as described in Chapter 2) to now contain new delay_on and delay_off file entries. However, because of the asynchronous nature of the calls, the first writeLED() call has not finished setting up the file system before the next two writeLED() calls are performed. This means that the delay_on and delay_off file system entries are not found, and the code to write to them fails. You should test this by changing the call near the top of the program from fs.writeFileSync(…) to fs.writeFile(…).
To combat this issue you can synchronize (prevent threads from being interrupted) the block of code where the three writeLED() functions are called, ensuring that the functions are called sequentially. Alternatively, as shown in this code example, you can use a special version of the Node.js writeFile() function called writeFileSync() to ensure that the first function call to modify the file system blocks the other writeFileSync() calls from taking place.
Node.js allows asynchronous calls because they help ensure that your code is “lively.” For example, if you performed a database query, your code may be able to do something else useful while awaiting the result. When the result is available, a callback function is executed in order to process the received data. This asynchronous structure is perfect for Internet-attached applications, where posts and requests are being made of websites and web services and it is not clear when a response will be received (if at all). Node.js has an event loop that manages all the asynchronous calls, creating threads for each call as required and ensuring that the callback functions are executed when an asynchronous call completes its assigned tasks. Node.js is revisited in Chapter 11 when the Internet of Things is discussed.
Java on the Beagle Boards
Up to this point in the chapter, interpreted languages are examined, meaning the source code file (a text file) is executed using an interpreter or dynamic translator at run time. Importantly, the code exists in source code form, right up to the point when it is executed using the interpreter.
With traditional compiled languages, the source code (a text file) is translated directly into machine code for a particular platform using a set of tools, which we will call a compiler for the moment. The translation happens when the code is being developed; once compiled, the code can be executed without needing any additional run-time tools.
Java is a hybrid language: you write your Java code in a source file, e.g., example.java, which is a regular text file. The Java compiler (javac) compiles and translates this source code into machine code instructions (called bytecodes) for a Java virtual machine (VM). Regular compiled code is not portable between hardware architectures, but bytecode files (.class files) can be executed on any platform that has an implementation of the Java VM. Originally, the Java VM interpreted the bytecode files at run time; however, more recently, dynamic translation is employed by the VM to convert the bytecodes into native machine instructions at run time.
The key advantage of this life cycle is that the compiled bytecode is portable between platforms, and because it is compiled to a generic machine instruction code, the dynamic translation to “real” machine code is efficient. The downside of this structure when compared to compiled languages is that the VM adds overhead to the execution of the final executable.
The Java Runtime Environment (JRE), which provides the Java virtual machine (JVM), is not installed on the Beagle Debian image by default because it occupies approximately 177 MB when installed.
Listing 5-6 provides a source code example that is also available in the GitHub repository in bytecode form.
Listing 5-6: chp05/javaLED/LEDExample.java (Segment)
package exploringBB;import java.io.*;public class LEDExample {private static String LED3 = "/sys/class/leds/beaglebone:green:usr3";private static void writeLED(String fname, String value, String path){try{BufferedWriter bw = new BufferedWriter(new FileWriter(path+fname));bw.write(value);bw.close();}catch(IOException e){System.err.println("Failed to access Sysfs: " + fname);}}private static void removeTrigger(){writeLED("/trigger", "none", LED3);}public static void main(String[] args) {System.out.println("Starting the LED Java Application");if(args.length!=1) {System.out.println("Incorrect number of arguments."); …System.exit(2);}if(args[0].equalsIgnoreCase("On")||args[0].equalsIgnoreCase("Off")){System.out.println("Turning the LED " + args[0]);removeTrigger();writeLED("/brightness",args[0].equalsIgnoreCase("On")?"1":"0",LED3);}… // full code available in the repository directory}}
The program can be executed using the run script that is in the /chp05/javaLED/ directory. You can see that the class is placed in the package directory exploringBB.
Early versions of Java suffered from poor computational performance; however, more recent versions take advantage of dynamic translation at run time (just-in-time, or JIT, compilation) and, as demonstrated at the start of this chapter, the performance was less than 15 percent slower (including dynamic translation) than that of the natively compiled C++ code, with only a minor additional memory overhead. Table 5-3 lists some of the advantages and disadvantages of using Java for development on the Beagle platform.
Table 5-3: Advantages and Disadvantages of Java on the Beagle Platform
| ADVANTAGES | DISADVANTAGES |
| Code is portable. Code compiled on the PC can be executed on any Beagle board or another embedded Linux platform. | Sandboxed applications do not have access to system memory, registers, or system calls (except through /proc/) or Java Native Interface (JNI). |
| There is a vast and extensive library of code available that can be fully integrated in your project. | Executing as root is slightly difficult because of required environment variables. |
| Full OOP support. | It is not suitable for scripting. |
| Can be used for user-interface application development on a Beagle board that is attached to a display. | Computational performance is respectable but slower than optimized C/C++ programs. Slightly heavier on memory. |
| Strong support for multithreading. | Strictly typed and no unsigned integer types. |
| Has automatic memory allocation and de-allocation using a garbage collector, removing memory leak concerns. | Royalty payment is required if deployed to a platform that “involves or controls hardware.”11 |
To execute a Java application under Debian, where it needs access to the /sys/ directory, you need the application to run with root access. Unfortunately, because you need to pass the bytecode (.class) file to the Java VM, you must call sudo and create a temporary shell of the form sudo sh -c 'java myClass'. The application can be executed using the following:
…/chp05/javaLED$ sudo sh -c 'java exploringBB.LEDExample Off'Starting the LED Java ApplicationTurning the LED Off…/chp05/javaLED$ sudo sh -c 'java exploringBB.LEDExample On'Starting the LED Java ApplicationTurning the LED On
C and C++ on the Beagle Boards
C++ was developed by Bjarne Stroustrup at Bell Labs (now AT&T Labs) during 1983–1985. It is based on the C language (named in 1972) that was developed at AT&T for UNIX systems in the early 1970s (1969–1973) by Dennis Ritchie. As well as adding an object-oriented (OO) framework (originally called “C with Classes”), C++ also improves the C language by adding features such as better type checking. It quickly gained widespread usage, which was largely due to its similarity to the C programming language syntax and the fact that it allowed existing C code to be used when possible. C++ is not a pure OO language but rather a hybrid, having the organizational structure of OO languages but retaining the efficiencies of C, such as typed variables and pointers.
Unlike Java, C++ is not “owned” by a single company. In 1998 the International Organization for Standardization (ISO) committee adopted a worldwide uniform language specification that aimed to remove inconsistencies between the various C++ compilers (Stroustrup, 1998). This standardization continues today with C++11 approved by the ISO in 2011 (gcc 4.7+ supports the flag -std=c++11), C++14 fully supported by gcc version 5, and many features of C++17 supported in gcc version 6 (with more to come in gcc version 7). At the time of writing, the current version of gcc and exact set of features available can be determined using this:
debian@ebb:~/exploringbb/chp05/overview$ g++ -v…gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1)debian@ebb:~/exploringbb/chp05/overview$ more version.cpp#include <iostream>int main(int argc, char** argv) {std::cout << __cplusplus << std::endl;return 0;}…/chp05/overview$ g++ version.cpp -o version…/chp05/overview$ ./version201402…/chp05/overview$ g++ -std=c++17 version.cpp -o version…/chp05/overview$ ./version201500
While it is important to understand the functionality available to you through your version of gcc, many of the newer features of C++ are not vital to developing code on embedded devices.
Why am I covering C and C++ in more detail than other languages in this book?
- First, I believe that if you can understand the workings of C and C++, then you can understand the workings of any language. In fact, most compilers (Java native methods, Java virtual machine, JavaScript) and interpreters (Bash, Lua, Perl, and Python) are written in C.
- At the beginning of this chapter, a significant performance advantage of C/C++ over other many languages was described (yes, it was demonstrated using only one random test!). It is also important to remember that the same code running on the PocketBeagle at 1 GHz was approximately 53 times slower than the same code running on only one thread (12 total) of an Intel i7-5820K at 3.3 GHz.
- Chapter 16 explains how to develop Linux loadable kernel modules (LKM), which requires a reasonable grasp of the C programming language. Later in this chapter, code is provided that demonstrates how you can communicate directly with Linux kernel space using the GNU C Library (glibc).
- Many of the application examples in this book such as streaming network data and image processing use C++ and a comprehensive library of C++ code called Qt.
Table 5-4 lists some advantages and disadvantages of using C/C++ on the Beagle boards. The next section reviews some of the fundamentals of C and C++ programming to ensure that you have the skills necessary for the remaining chapters in this book. It is not possible to cover every aspect of C and C++ programming in just one chapter of one book. The “Further Reading” section at the end of this chapter directs you to recommended texts.
Table 5-4: Advantages and Disadvantages of C/C++ on the Beagle Boards
| ADVANTAGES | DISADVANTAGES |
| You can build code directly on the board or you can cross-compile code. The C/C++ languages are ISO standards, not owned by a single vendor. | Compiled code is not portable. Code compiled for your x86 desktop will not run on the Beagle board's ARM processor. |
| C++ has full support for procedural programming, OOP, and support for generics through the use of STL (Standard Template Library). | Many consider the languages to be complex to master. There is a tendency to need to know everything before you can do anything. |
| It gives excellent computational performance, especially if optimized; however, optimization can be difficult and can reduce the portability of your code. | The use of pointers and the low-level control available makes code prone to memory leaks. With careful coding these can be avoided and can lead to efficiencies over dynamic memory management schemes. |
| Can be used for user-interface application development on the Beagle boards using third-party libraries. Libraries such as Qt and Boost provide extensive additional resources for components, networking, etc. | By default, C and C++ do not support graphical user interfaces, network sockets, etc. Third-party libraries are required. |
Offers low-level access to glibc for integrating with the Linux system. Programs can be setuid to root. |
Not suitable for scripting (there is a C shell, csh, that does have syntax like C). Not ideal for web development either. |
| The Linux kernel is written in C and having knowledge of C/C++ can help if you ever need to write device drivers or contribute to Linux kernel development. | C++ attempts to span from low-level to high-level programming tasks, but it can be difficult to write very scalable enterprise or web applications. |
The next section provides a revision of the core principles that have been applied to examples on the Beagle boards. It is intended to serve as an overview and a set of reference examples that you can come back to again and again. It also focuses on topics that cause my students difficulties, pointing out common mistakes. Also, please remember that course notes for my Object-Oriented Programming module are publicly available at ee402.eeng.dcu.ie along with further support materials.
C and C++ Language Overview
The following examples can be edited using the nano editor and compiled on the Beagle boards directly using the gcc and g++ compilers, which are installed by default. The code is in the directory chp05/overview/.
The first example you should always write in any new language is “Hello World.” Listings 5-7 and 5-8 provide C and C++ code, respectively, for the purpose of a direct comparison of the two languages.
Listing 5-7: chp05/overview/helloworld.c
#include <stdio.h>int main(int argc, char *argv[]){printf("Hello World! ");return 0;}
Listing 5-8: chp05/overview/helloworld.cpp
#include<iostream>int main(int argc, char *argv[]){std::cout << "Hello World!" << std::endl;return 0;}
The #include call is a preprocessor directive that effectively loads the contents of the stdio.h file (/usr/include/stdio.h) in the C case, and the iostream header (/usr/include/c++/6/iostream) file in the C++ case, and copies and pastes the code in at this exact point in your source code file. These header files contain the function prototypes, enabling the compiler to link to and understand the format of functions such as printf() in stdio.h and streams like cout in iostream. The actual implementation of these functions is in shared library dependencies. The angular brackets (< >) around the include filename means that it is a standard, rather than a user-defined include (which would use double quotes).
The main() function is the starting point of your application code. There can be only one function called main() in your application. The int in front of main() indicates that the program will return a number to the shell prompt. As stated, it is good to use 0 for successful completion, 2 for invalid usage, and any other set of numbers to indicate failure conditions. This value is returned to the shell prompt using the line return 0 in this case. The main() function will return 0 by default. Remember that you can use echo $? at the shell prompt to see the last value that was returned.
The parameters of the main() function are int argc and char *argv[]. As you saw in the scripting examples, the shell can pass arguments to your application, providing the number of arguments (argc) and an array of strings (*argv[]). In C/C++ the first argument passed is argv[0], and it contains the name and full path used to execute the application.
The C code line printf("Hello World!
"); allows you to write to the Linux shell, with the
representing a new line. The printf() function provides you with additional formatting instructions for outputting numbers, strings, etc. Note that every statement is terminated by a semicolon.
The C++ code line std::cout << "Hello World!" << std::endl; outputs a string just like the printf() function. In this case, cout represents the output stream, and the function used is actually the <<, which is called the output stream operator. The syntax is discussed later, but std::cout means the output stream in the namespace std. The endl (end line) representation is the same as
. This may seem more verbose, but you will see why it is useful later in the discussion on C++ classes. These programs can be compiled and executed directly on the Beagle board by typing the following:
…/chp05/overview$ gcc helloworld.c -o helloworldc…/chp05/overview$ ./helloworldcHello World!…/chp05/overview$ g++ helloworld.cpp -o helloworldcpp…/chp05/overview$ ./helloworldcppHello World!
The sizes of the C and C++ executables are different to account for the different header files, output functions, and exact compilers that are used.
debian@ebb:~/exploringbb/chp05/overview$ ls -l helloworldc*-rwxr-xr-x 1 debian debian 8348 May 14 02:48 helloworldc-rwxr-xr-x 1 debian debian 9152 May 14 02:48 helloworldcpp
Compiling and Linking
You just saw how to build a C or C++ application, but there are a few intermediate steps that are not obvious in the preceding example, as the intermediate stage outputs are not retained by default. Figure 5-1 illustrates the full build process from preprocessing right through to linking.

Figure 5-1: Building C/C++ applications on the Beagle boards
You can perform the steps in Figure 5-1 yourself. Here is an example of the actual steps that were performed using the Helloworld.cpp code example. The steps can be performed explicitly as follows, so that you can view the output at each stage:
debian@ebb:/tmp$ ls -l helloworld.cpp-rw-r--r-- 1 debian debian 114 May 14 02:51 helloworld.cppdebian@ebb:/tmp$ g++ -E helloworld.cpp > processed.cppdebian@ebb:/tmp$ ls -l processed.cpp-rw-r--r-- 1 debian debian 641377 May 14 02:51 processed.cppdebian@ebb:/tmp$ g++ -S processed.cpp -o helloworld.sdebian@ebb:/tmp$ ls -l helloworld.s-rw-r--r-- 1 debian debian 3161 May 14 02:52 helloworld.sdebian@ebb:/tmp$ g++ -c helloworld.sdebian@ebb:/tmp$ lshelloworld.cpp helloworld.o helloworld.s processed.cppdebian@ebb:/tmp$ g++ helloworld.o -o helloworlddebian@ebb:/tmp$ ls -l helloworld-rwxr-xr-x 1 debian debian 9148 May 14 02:53 helloworlddebian@ebb:/tmp$ ./helloworldHello World!
You can see the text format output after preprocessing by typing less processed.cpp, where you will see the necessary header files pasted in at the top of your code. At the bottom of the file you will find your code. This file is passed to the C/C++ compiler, which validates the code and generates platform-independent assembler code (.s). You can view this code by typing less helloworld.s, as illustrated in Figure 5-1.
This .s text file is then passed to the assembler, which converts the platform-independent instructions into binary instructions for the Beagle board (the .o file). You can see the assembly language code that was generated if you use the objdump (object file dump) tool on your board by typing objdump -D helloworld.o, as illustrated in Figure 5-1.
Object files contain generalized binary assembly code that does not yet provide enough information to be executed on the board. However, after linking the final executable code, helloworld contains the target-specific assembly language code that has been combined with the libraries, statically and dynamically as required—you can use the objdump tool again on the executable, which results in the following output:
…/chp05/overview$ objdump -d helloworldcpp | lesshelloworldcpp: file format elf32-littlearmDisassembly of section .init:00000668 <_init>:668: e92d4008 push {r3, lr}66c: eb00002f bl 730 <call_weak_fn>670: e8bd8008 pop {r3, pc}…
The first column is the memory address, which steps by 4 bytes (32-bits) between each instruction (i.e., 66c − 668 = 4). The second column is the full 4-byte instruction at that address. The third and fourth columns are the human-readable version of the second column that describes the opcode and operand of the 4-byte instruction. For example, the first instruction at address 668 is a push, which pushes r3, which is one of the ARM processor's sixteen 32-bit registers (labeled r0-r15), followed by lr (the link register, r14) onto the stack.
Understanding ARM instructions is another book in and of itself (see infocenter.arm.com). However, it is useful to appreciate that any natively compiled code, whether it uses the OOP paradigm or not, results in low-level machine code, which does not support dynamic typing, OOP, or any such high-level structures. In fact, whether you use an interpreted or compiled language, the code must eventually be converted to machine code so that it can execute on the board's ARM processor.
Writing the Shortest C/C++ Program
Is the HelloWorld example the shortest program that can be written in C or C++? No, Listing 5-9 is the shortest valid C and C++ program.
Listing 5-9: chp05/overview/short.c
main(){} This is a fully functional C and C++ program that compiles with no errors and works perfectly, albeit with no output. Therefore, in building a C/C++ program, there is no need for libraries; there is no need to specify a return type for main(), as it defaults to int; the main() function returns 0 by default in C++ and an undefined number in C (see the following echo $? call); and an empty function is a valid function. This program will compile as a C or C++ program as follows:
…/chp05/overview$ gcc short.c -o shortcshort.c:1:1: warning: return type defaults to 'int' ……/chp05/overview$ g++ short.c -o shortcpp…/chp05/overview$ ls -l shortc*-rwxr-xr-x 1 debian debian 8276 May 14 03:10 shortc-rwxr-xr-x 1 debian debian 8292 May 14 03:10 shortcpp…/chp05/overview$ ./shortc…/chp05/overview$ echo $?0…/chp05/overview$ ./shortcpp…/chp05/overview$ echo $?0
This is one of the greatest weaknesses of C and C++. There is an assumption that you know everything about the way the language works before you write anything. In fact, aspects of the preceding example might be used by programmers to demonstrate how clever they are, but they are actually demonstrating poor practice in making their code unreadable by less “expert” programmers. For example, if you rewrite the C++ code in short.cpp to include comments and explicit statements, to create short2.cpp, and then compile both using the -O3 optimization flag, the output will be as follows:
…/chp05/overview$ more short.cppmain(){}…/chp05/overview$ more short2.cpp// A really useless program, but a program neverthelessint main(int argc, char *argv[]){return 0;}…/chp05/overview$ g++ -O3 short.cpp -o short01…/chp05/overview$ g++ -O3 short2.cpp -o short02…/chp05/overview$ ls -l short0*-rwxr-xr-x 1 debian debian 8292 May 14 03:15 short01-rwxr-xr-x 1 debian debian 8292 May 14 03:15 short02
Note that the executable size is exactly the same! Adding the comment, the explicit return statement, the explicit return type, and explicit arguments has had no impact on the size of the final binary application. However, the benefit is that the actual functionality of the code is much more readily understood by a novice programmer.
Static and Dynamic Compilation
You can build with the flag -static to statically link the libraries, rather than the default form of linking dynamically with shared libraries. This means that the compiler and linker effectively place all the library routines required by your code directly within the program executable.
…/chp05/overview$ g++ -O3 short.cpp -static -o short_static…/chp05/overview$ ls -l short_static-rwxr-xr-x 1 debian debian 448792 May 14 03:19 short_static
It is clear that the program executable size has grown significantly from 8 KB to 449 KB. One advantage of this form is that the program can be executed by ARM systems on which the C++ standard libraries are not installed.
With dynamic linking, it is useful to note that you can discover which shared library dependencies your compiled code is using, by calling ldd.
…/chp05/overview$ ldd shortcpplinux-vdso.so.1 (0xbefcd000)libstdc++.so.6 => /usr/lib/arm-linux-gnueabihf/libstdc++.so.6 (0xb6dcf000)libm.so.6 => /lib/arm-linux-gnueabihf/libm.so.6 (0xb6d57000)libgcc_s.so.1 => /lib/arm-linux-gnueabihf/libgcc_s.so.1 (0xb6d2e000)libc.so.6 => /lib/arm-linux-gnueabihf/libc.so.6 (0xb6c40000)/lib/ld-linux-armhf.so.3 (0xb6eed000)
You can see from this output that the g++ compiler (and glibc) on the Debian image for the Beagle boards has been patched to support the generation of hard floating-point (gnueabihf) instructions by default. This allows for faster code execution with floating-point numbers than if it used the soft floating-point ABI (application binary interface) to emulate floating-point support in software (gnueabi).
Variables and Operators in C/C++
A variable is a data item stored in a block of memory that has been reserved for it. The type of the variable defines the amount of memory reserved and how it should behave (see Figure 5-2). This figure describes the output of the code example sizeofvariables.c in Listing 5-10.
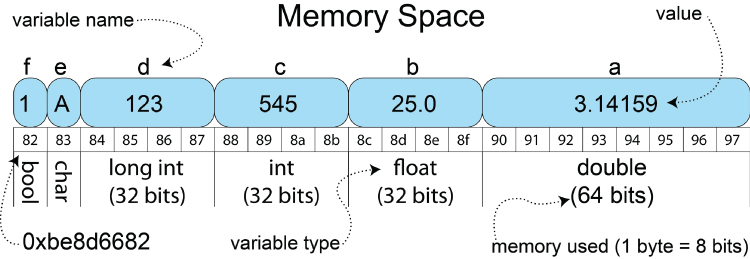
Figure 5-2: Memory allocation for variables running on a 32-bit Beagle board
Listing 5-10 details various variables available in C/C++. When you create a local variable c, it is allocated a box/block of memory on the stack (predetermined reserved fast memory) depending on its type. In this case, c is an int value; therefore, four bytes (32 bits) of memory are allocated to store the value. Assume that variables in C/C++ are initialized with arbitrary values; therefore, in this case c = 545; replaces that initial random value by placing the number 545 in the box. It does not matter if you store the number 0 or 2,147,483,647 in this box: it will still occupy 32 bits of memory! Please note that there is no guarantee regarding the ordering of local variable memory—it was fortuitously linear in this particular example.
Listing 5-10: chp05/overview/sizeofvariables.c
#include<stdio.h>#include<stdbool.h> //required for the C bool typedefint main(){double a = 3.14159;float b = 25.0;int c = 545; // note: variables are not = 0 by default!long int d = 123;char e = 'A';bool f = true; // no need for definition in C++printf("a val %.4f & size %d bytes (@addr %p). ", a, sizeof(a),&a);printf("b val %4.2f & size %d bytes (@addr %p). ", b, sizeof(b),&b);printf("c val %d (oct %o, hex %x) & ""size %d bytes (@addr %p). ", c, c, c, sizeof(c), &c);printf("d val %d & size %d bytes (@addr %p). ", d, sizeof(d), &d);printf("e val %c & size %d bytes (@addr %p). ", e, sizeof(e), &e);printf("f val %5d & size %d bytes (@addr %p). ", f, sizeof(f), &f);}
The sizeof(c) operator returns the size of the type of the variable in bytes. In this example, it will return 4 for the size of the int type. The &c call can be read as the “address of” c. This provides the address of the first byte that stores the variable c, in this case returning 0xbe8d6688. The %.4f on the first line means display the floating-point number to four decimal places. Executing this program on a PocketBeagle gives the following:
/chp05/overview$ ./sizeofvariablesa val 3.1416 & size 8 bytes (@addr 0xbe8d6690).b val 25.00 & size 4 bytes (@addr 0xbe8d668c).c val 545 (oct 1041, hex 221) & size 4 bytes (@addr 0xbe8d6688).d val 123 & size 4 bytes (@addr 0xbe8d6684).e val A & size 1 bytes (@addr 0xbe8d6683).f val 1 and size 1 bytes (@addr 0xbe8d6682).
The Beagle boards have 32-bit microprocessors, so you are using four bytes to represent the int type. The smallest unit of memory that you can allocate is one byte, so, yes, you are representing a Boolean value with one byte, which could actually store eight unique Boolean values. You can operate directly on variables using operators. The program operators.c in Listing 5-11 contains some points that often cause difficulty in C/C++:
Listing 5-11: chp05/overview/operators.c
#include<stdio.h>int main(){int a=1, b=2, c, d, e, g;float f=9.9999;c = ++a;printf("The value of c=%d and a=%d. ", c, a);d = b++;printf("The value of d=%d and b=%d. ", d, b);e = (int) f;printf("The value of f=%.2f and e=%d. ", f, e);g = 'A';printf("The value of g=%d and g=%c. ", g, g);return 0;}
This will give the following output:
/chp05/overview$ ./operatorsThe value of c=2 and a=2.The value of d=2 and b=3.The value of f=10.00 and e=9.The value of g=65 and g=A.
On the line c=++a; the value of a is pre-incremented before the equals assignment to c on the left side. Therefore, a was increased to 2 before assigning the value to c, so this line is equivalent to two lines: a=a+1; c=a;. However, on the line d=b++; the value of b is post-incremented and is equivalent to two lines:
d=b; b=b+1;. The value of d is assigned the value of b, which is 2, before the value of b is incremented to 3.
On the line e=(int)f; a C-style cast is being used to convert a floating-point number into an integer value. Effectively, when programmers use a cast, they are notifying the compiler that they are aware that there will be a loss of precision in the conversion of a floating-point number to an int (and that the compiler will introduce conversion code). The fractional part will be truncated, so 9.9999 is converted to e=9, as the.9999 is removed by the truncation. One other point to note is that the printf("%.2f",f) displays the floating-point variable to two decimal places, in contrast, rounding the value.
On the line g='A', g is assigned the ASCII equivalent value of capital A, which is 65. The printf("%d %c",g, g); will display either the int value of g if %d is used or the ASCII character value of g if %c is used.
A const keyword can be used to prevent a variable from being changed. There is also a volatile keyword that is useful for notifying the compiler that a particular variable might be changed outside its control and that the compiler should not apply any type of optimization to that value. This notification is useful on the Beagle board if the variable in question is shared with another process or physical input/output.
It is possible to define your own type in C/C++ using the typedef keyword. For example, if you did not want to include the header file stdbool.h in the sizeofvariables.c previous example, it would be possible to define it in this way instead:
typedef char bool;#define true 1#define false 0
Probably the most common and most misunderstood mistake in C/C++ programming is present in the following:
if (x=y){// perform a body statement Z}
When will the body statement Z be performed? The answer is whenever y is not equal to 0 (the current value of x is irrelevant!). The mistake is placing a single = (assignment) instead of == (comparison) in the if statement. The assignment operator returns the value on the RHS, which will be automatically converted to true if y is not equal to 0. If y is equal to zero, then a false value will be returned. Java does not allow this error, as there is no implicit conversion between 0 and false and 1 and true.
Pointers in C/C++
A pointer is a special type of variable that stores the address of another variable in memory—we say that the pointer is “pointing at” that variable. Listing 5-12 is a code example that demonstrates how you can create a pointer p and make it point at the variable y.
Listing 5-12: chp05/overview/pointers.c
#include<stdio.h>int main(){int y = 1000;int *p;p = &y;printf("The variable has value %d and the address %p. ", y, &y);printf("The pointer stores %p and points at value %d. ", p, *p);printf("The pointer has address %p and size %d. ", &p, sizeof(p));return 0;}
When this code is compiled and executed, it will give the following output:
/chp05/overview$ ./pointersThe variable has value 1000 and the address 0xbede26bc.The pointer stores 0xbede26bc and points at value 1000.The pointer has address 0xbede26b8 and size 4.
So, what is happening in this example? Figure 5-3 illustrates the memory locations and the steps involved. In step 1, the variable y is created and assigned the initial value of 1000. A pointer p is then created with the dereference type of int. In essence, this means that the pointer p is being established to point at int values. In step 2, the statement p = &y; means “let p equal the address of y,” which sets the value of p to be the 32-bit address 0xbede26bc. We now say that p is pointing at y. These two steps could have been combined using the call int *p = &y; (i.e., create a pointer p of dereference type int and assign it to the address of y).

Figure 5-3: Example of pointers in C/C++ on a Beagle board (with 32-bit addressing)
Why does a pointer need a dereference type? For one example, if a pointer needs to move to the next element in an array, then it needs to know whether it should move by four bytes, eight bytes, etc. Also, in C++ you need to be able to know how to deal with the data at the pointer based on its type. Listing 5-13 is another example of working with pointers that explains how a simple error of intention can cause serious problems.
Listing 5-13: chp05/overview/pointers2.c
#include<stdio.h>int main(){int y = 1000, z;int *p = &y;printf("The pointer p has the value %d and address: %p ", *p, p);// Let z = 1000 + 5 and the increment p and y to 1001 -- wrong!!!z = *p++ + 5;printf("The pointer p has the value %d and address: %p ", *p, p);printf("The variable z has the value %d ", z);return 0;}
This will give the output as follows:
debian@ebb:~/exploringbb/chp05/overview$ ./pointers2The pointer p has the value 1000 and address: 0xbeef357cThe pointer p has the value 1005 and address: 0xbeef3580The variable z has the value 1005
In this example, the pointer p is of dereference type int, and it is set to point at the address of y. At this point in the code the output is as expected, as p has the “value of” 1000 and the “address of” 0xbeef357c. On the next line the intention may have been to increase (post-increment) the value of y by 1 to 1001 and assign z a value of 1005 (i.e., before the post-increment takes place). However, perhaps contrary to your intention, p now has the “value of” 1005 and the “address of” 0xbeef3580.
Why has this occurred? Part of the difficulty of using pointers in C/C++ is understanding the order of operations in C/C++, called the precedence of the operations. For example, if you write the statement
int x = 1 + 2 * 3; what will the value of x be? In this case, it will be 7, because in C/C++ the multiplication operator has a higher level of precedence than the addition operator. Similarly, the problem in Listing 5-13 is your possible intention of using *p++ to increment the “value of” p by 1.
In C/C++ the post-increment operator (p++) has precedence over the dereference operator (*p). This means that *p++ actually post-increments the “address of” the pointer p by one int (i.e., 4 bytes), but before that, it is dereferenced (as 1000 in this example) so that it is added to 5 and assigned to z (as visible on the third output line). Most worrying is the second output line, as it is clear that p is now “pointing at” z, which just happens to be at the next address—it could actually refer to an address outside the program's memory allocation. Such errors of intention are difficult to debug without using the debugging tools that are described in Chapter 7. To fix the code to suit your intention, simply use (*p)++, which makes it clear that it is the “value of” p that should be post-incremented by 1, resulting in p having the “value of” 1001 and z having the value 1005. Should this change be applied, the pointer p would not increment its address.
There are approximately 58 operators in C++, with 18 different major precedence levels. Even if you know the precedence table, you should still make it clear for other users what you intend in a statement by using round brackets (()), which have the highest precedence level after the scope resolution (::), increment (++), and decrement (--) operators. Therefore, you should always write the following:
int x = 1 + (2 * 3); Finally, on the topic of C pointers, there is also a void* pointer that can be declared as void *p;, which effectively states that the pointer p does not have a dereference type and it will need to be assigned at a later stage (see /chp05/overview/void.c) using the following syntax:
int a = 5;void *p = &a;printf("p points at address %p and value %d ", p, *((int *)p));
When executed, this code will give an output like the following:
The pointer p points at address 0xbea546c8 and value 5 Therefore, it is possible to cast a pointer from one dereference type to another, and the void pointer can potentially be used to store a pointer of any dereference type. In Chapter 6 void pointers are used to develop an enhanced GPIO interface.
C-Style Strings
The C language has no built-in string type but rather uses an array of the character type, terminated by the null character (�), to represent a string. There is a standard C library for strings that can be used, as shown in Listing 5-14.
Listing 5-14: chp05/overview/cstrings.c
#include<stdio.h>#include<string.h>#include<stdlib.h>int main(){char a[20] = "hello ";char b[] = {'w','o','r','l','d','!','�'}; // the � is importanta[0]='H'; // set the first character to be Hchar *c = strcat(a,b); // join/concatenate a and bprintf("The string c is: %s ", c);printf("The length of c is: %d ", strlen(c)); // call string length// find and replace the w with a Wchar *p = strchr(c,'w'); // returns pointer to first 'w' char*p = 'W';printf("The string c is now: %s ", c);if (strcmp("cat", "dog")<=0){ // ==0 would be equalprintf("cat comes before dog (lexiographically) ");}//insert "to the" into middle of "Hello World!" string - very messy!char *d = " to the";char *cd = malloc(strlen(c) + strlen(d));memcpy(cd, c, 5);memcpy(cd+5, d, strlen(d));memcpy(cd+5+strlen(d), c+5, 6);printf("The cd string is: %s ", cd);//tokenize cd string using spacesp = strtok(cd," ");while(p!=NULL){printf("Token:%s ", p);p = strtok(NULL, " ");}return 0;}
The code is explained by the comments within the example. When executed, this code will give the following output:
/chp05/overview$ ./cstringsThe string c is: Hello world!The length of c is: 12The string c is now: Hello World!cat comes before dog (lexiographically)The cd string is: Hello to the WorldToken:HelloToken:toToken:theToken:World
LED Flashing Application in C
Now that you have covered enough C programming to get by, you can look at how to write the LED flashing application in C. In Listing 5-15 the same structure as the other examples has been retained.
Listing 5-15: chp05/makeLED/makeLED.c
#include<stdio.h>#include<stdlib.h>#include<string.h>#define LED3_PATH "/sys/class/leds/beaglebone:green:usr3"void writeLED(char filename[], char value[]); //function prototypesvoid removeTrigger();int main(int argc, char* argv[]){if(argc!=2){printf("Usage is makeLEDC and one of: ");printf(" on, off, flash or status ");printf(" e.g. makeLED flash ");return 2;}printf("Starting the makeLED program ");printf("The current LED Path is: " LED3_PATH " ");// select whether command is on, off, flash or statusif(strcmp(argv[1],"on")==0){printf("Turning the LED on ");removeTrigger();writeLED("/brightness", "1");}else if (strcmp(argv[1],"off")==0){printf("Turning the LED off ");removeTrigger();writeLED("/brightness", "0");}else if (strcmp(argv[1],"flash")==0){printf("Flashing the LED ");writeLED("/trigger", "timer");writeLED("/delay_on", "50");writeLED("/delay_off", "50");}else if (strcmp(argv[1],"status")==0){FILE* fp; // see writeLED function below for descriptionchar fullFileName[100];char line[80];sprintf(fullFileName, LED3_PATH "/trigger");fp = fopen(fullFileName, "rt"); //reading text this timewhile (fgets(line, 80, fp) != NULL){printf("%s", line);}fclose(fp);}else{printf("Invalid command! ");}printf("Finished the makeLED Program ");return 0;}void writeLED(char filename[], char value[]){FILE* fp; // create a file pointer fpchar fullFileName[100]; // to store the path and filenamesprintf(fullFileName, LED3_PATH "%s", filename); // write path/namefp = fopen(fullFileName, "w+"); // open file for writingfprintf(fp, "%s", value); // send the value to the filefclose(fp); // close the file using the file pointer}void removeTrigger(){writeLED("/trigger", "none");}
Build this program by calling the ./build script in the /chp05/makeLED/ directory, and execute it using ./makeLEDC on, ./makeLEDC off, etc.
The only topic that you have not seen before is the use of files in C, but the worked example should provide you with the information you need in the writeLED() function. The FILE pointer fp points to a description of the file that identifies the stream, the read/write position, and its state. The file is opened using the fopen() function that is defined in stdio.h, which returns a FILE pointer. In this case, it is being opened for write/update (w+). The alternatives would be as follows: read (r), write (w), append (a), read/update (r+), and append/update (a+). If you are working with binary files you would append a b to the state—e.g., w+b would open a new binary file for update (write and read). Also, t can be used to explicitly state that the file is in text format.
For a full reference of C functions available in the standard libraries, see www.cplusplus.com/reference/.
The C of C++
As discussed previously, the C++ language was built on the C language, adding support for OOP classes; however, a few other differences are immediately apparent when you start working with general C++ programming. Initially, the biggest change that you will notice is the use of input/output streams and the general use of strings.
First Example and Strings in C++
Listing 5-16 shows the string example, rewritten to use the C++ string library.
Listing 5-16: chp05/overview/cppstrings.cpp
#include<iostream>#include<sstream> // to tokenize the string//#include<cstring> // C++ equivalent of C header if neededusing namespace std;int main(){string a = "hello ";char temp[] = {'w','o','r','l','d','!','�'}; //the � is important!string b(temp);a[0]='H';string c = a + b;cout << "The string c is: " << c << endl;cout << "The length of c is: " << c.length() << endl;int loc = c.find_first_of('w');c.replace(loc,1,1,'W');cout << "The string c is now: " << c << endl;if (string("cat")< string("dog")){cout << "cat comes before dog (lexiographically) ";}c.insert(5," to the");cout << "The c string is now: " << c << endl;// tokenize string using spaces - could use Boost.Tokenizer// or C++11 to improve syntax. Using stringstream this time.stringstream ss;ss << c; // put the c string on the stringstreamstring token;while(getline(ss, token, ' ')){cout << "Token: " << token << endl;}return 0;}
Build this code by typing g++ cppstrings.cpp -o cppstrings. When executed, this code gives the same output as the cstrings.c example. Some aspects are more straightforward in C++, but there are some points worth mentioning.
The code uses the iostream and sstream header files, which are C++ headers. If you want to use a C header file, you need to prepend the name with a c; therefore, to use the C string.h header file you would use #include<cstring>. There is a concept called namespaces in C++ that enables a programmer to limit a function or class to a particular scope. In C++ all the standard library functions and classes are limited to the standard namespace. You can explicitly identify that you want to use a class from the std namespace by using std::string. However, that is quite verbose. The alternative is to use the statement using namespace std;, which brings the entire namespace into your code. Do not do this in one of your C++ header files, as it will pollute the namespace for anyone who uses your header file.
The code uses cout, which is the standard output stream, and the output stream operator (<<) to display strings. There is an equivalent standard input stream (cin) and the input stream operator (>>). The output stream operator “looks to” its right and identifies the type of the data. It will display the data depending on its type, so there is no need for %s, %d, %p, and so on, as you would use in the printf() function. The endl stream manipulation function inserts a newline character and flushes the stream.
The string objects are manipulated in this example using + to append two strings and using < or == to compare two strings. These operators are essentially functions like append() and strcmp(). In C++ you can define what these operators do for your own data types (operator overloading).
Passing by Value, Pointer, and Reference
As you have seen with the code samples, functions enable us to write a section of code that can be called several times, from different locations in our code. There are three key ways of passing a value to a function.
- Pass by value: This will create a new variable (
valin the following code example) and will store a copy of the value of the source variable (a) in this new variable. Any changes to the variablevalwill not have any impact on the source variablea. Pass by value can be used if you want to prevent the original data from being modified; however, a copy of the data has to be made, and if you are passing a large array of data, such as an image, then copying will have a memory and computational cost. An alternative to pass by value is to pass by constant reference. In the following example,ais also passed as the second argument to the function by constant reference and is received as the valuecr. The valuecrcan be read in the function, but it cannot be modified. - Pass by pointer: You can pass a pointer to the source data. Any modifications to the value at the pointer (
ptr) will affect the source data. The call to the function must pass an address (&b—address ofb). - Pass by reference: In C++ you can pass a value by reference. The function determines whether an argument is to be passed by value or passed by reference, through the use of the ampersand symbol. In the following example,
&refindicates that the valuecis to be passed by reference. Any modifications torefin the function will affect the value ofc.
Here is a function with all four examples (passing.cpp):
int afunction(int val, const int &cr, int *ptr, int &ref){val+=cr;// cr+=val; // not allowed because it is constant*ptr+=10;ref+=10;return val;}int main(){int a=100, b=200, c=300;int ret;ret = afunction(a, a, &b, c);cout << "The value of a = " << a << endl;cout << "The value of b = " << b << endl;cout << "The value of c = " << c << endl;cout << "The return value is = " << ret << endl;return 0;}
When executed, this code will result in the following output:
/chp05/overview$ ./passingThe value of a = 100The value of b = 210The value of c = 310The return value is = 200
If you want to pass a value to a function that is to be modified by that function in C++, then you can pass it by pointer or by reference; however, unless you are passing a value that could be NULL or you need to re-assign the pointer in the function (e.g., iterate over an array), then always use pass by reference. Now you are ready to write the LED code in C++!
Flashing the LEDs Using C++ (non-OO)
The C++ LED flashing code is available in makeLED.cpp in the /chp05/makeLED/ directory. As most of the code is similar to the C example, it is not repeated here. However, it is worth displaying the following segment, which is used to open the file using the fstream file stream class. The output stream operator (<<) in this case sends the string to fstream, where the c_str() method returns a C++ string as a C string.
void writeLED(string filename, string value){fstream fs;string path(LED3_PATH);fs.open((path + filename).c_str(), fstream::out);fs << value;fs.close();}
Writing a Multicall Binary
Multicall binaries can be used in Linux to build a single application that does the job of many (e.g., BusyBox in Linux that provides several system tools in a single executable file). There is an example in the chp05/makeLEDmulti/ directory called makeLEDmulti.cpp that uses the first command-line argument to switch the functionality of the application based on the command name that was called. This code has been modified to add a small function:
bool endsWith(string const &in, string const &comp){return (0==in.compare(in.length()-comp.length(),comp.length(),comp));}
This function checks to see whether the in string ends with the contents of the comp string. This is important because the application could be called using ./flashled or ./chp05/makeLEDmulti/flashled, depending on its location. The switching comparison then looks like the following:
if(endsWith(cmd,"onled")){cout << "Turning the LED on" << endl;removeTrigger();writeLED("/brightness", "1");}
If you list the files in the directory after calling ./build, you will see the following files and symbolic links:
debian@ebb:~/exploringbb/chp05/makeLEDmulti$ ls -l-rwxr-xr-x 1 debian debian 542 May 13 00:14 buildlrwxrwxrwx 1 debian debian 12 May 14 04:42 flashled -> makeLEDmultilrwxrwxrwx 1 debian debian 12 May 14 04:42 ledstatus -> makeLEDmulti-rwxr-xr-x 1 debian debian 15344 May 14 04:42 makeLEDmulti-rw-r--r-- 1 debian debian 2474 May 13 00:14 makeLEDmulti.cpplrwxrwxrwx 1 debian debian 12 May 14 04:42 offled -> makeLEDmultilrwxrwxrwx 1 debian debian 12 May 14 04:42 onled -> makeLEDmulti
Each one of these symbolic links looks like an individual command, even though they link back to the same executable makeLEDmulti. The makeLEDmulti parses argv[0] to determine which symbolic link was used. You can see the impact of that here, where the symbolic links are called:
debian@ebb:~/exploringbb/chp05/makeLEDmulti$ ./onledThe current LED Path is: /sys/class/leds/beaglebone:green:usr3… Turning the LED on …debian@ebb:~/exploringbb/chp05/makeLEDmulti$ ./ledstatus… Current trigger details:… [none] rc-feedback kbd-scrolllock …
Overview of Object-Oriented Programming
Object-oriented programming is a programming approach that enables organizing software as a collection of objects, which consist of both data and behavior. In contrast to the functional programming examples you have seen to this point, you don't ask the question “What does it do?” first but rather “What is it?” In theory, this means your code is written to allow for future changes to the functionality, without having to redesign the structure of your code. In addition, it should also mean you can decompose your code into modules that can be reused by you and others in future projects.
The following discussion highlights a few core concepts that you need to understand before you can write object-oriented code. The discussion uses pseudocode as the concepts are relevant to all languages that support the OOP paradigm, including C++, Python, Rust, Lua tables, C#, Java, JavaScript, Perl, Ruby, the OOHaskell library, etc.
Classes and Objects
Think about the concept of a television: you do not need to remove the case to use it, as there are controls on the front and on the remote; you can still understand the television, even if it is connected to a games console; it is complete when you purchase it, with well-defined external requirements, such as power supply and signal inputs; and your television should not crash! In many ways that description captures the properties that should be present in a class.
A class is a description. It should describe a well-defined interface to your code; represent a clear concept; be complete and well documented; and be robust, with built-in error checking. Class descriptions are built using two building blocks.
- States (or data): The state values of the class.
- Methods (or behavior): How the class interacts with its data. Method names usually include an action verb (e.g.,
setX()).
For example, here is pseudocode (i.e., not real C++ code) for an illustrative Television class:
class Television{int channelNumber;bool on;powerOn() { on = true; }powerOff(){ on = false;}changeChannel(int x) { channelNumber = x; }};
Therefore, the example Television class has two states and three methods. The benefit of this structure is that you have tightly bound the states and methods together within a class structure. The powerOn() method means nothing outside this class. In fact, you can write a powerOn() method in many different classes without worrying about naming collisions.
An object is the realization of the class description—an instance of a class. To continue the analogy, the Television class is the blueprint that describes how you would build a television, and a Television object is the physical realization of those plans into a physical television. In pseudocode this realization might look like this:
void main(){Television dereksTV();Television johnsTV();dereksTV.powerOn();dereksTV.changeChannel(52);johnsTV.powerOn();johnsTV.changeChannel(1);}
Therefore, dereksTV and johnsTV are objects of the Television class. Each has its own independent state, so changing the channel on dereksTV has no impact on johnsTV. To call a method, it must be prefixed by the object name on which it is to be called (e.g., johnsTV.powerOn()); calling the changeChannel() method on johnsTV objects does not have any impact on the dereksTV object.
In this book, a class name generally begins with a capital letter, e.g., Television, and an object generally begins with a lowercase letter, e.g., dereksTV. This is consistent with the notation used in many languages, such as Java. Unfortunately, the C++ standard library classes (e.g., string, sstream) do not follow this naming convention.
Encapsulation
Encapsulation is used to hide the mechanics of an object. In the physical television analogy, encapsulation is provided by the box that protects the inner electronic systems. However, you still have the remote control that will have a direct impact on the way the inner workings function.
In OOP, you can decide what workings are to be hidden (e.g., TV electronics) using an access specifier keyword called private and what is to be part of the interface (TV remote control) using the access specifier keyword public. It is good practice to always set the states of your class to be private so that you can control how they are modified by public interface methods of your own design. For example, the pseudocode might become the following:
class Television{private:int channelNumber;bool on;remodulate_tuner();public:powerOn() { on = true; }powerOff(){ on = false;}changeChannel(int x) {channelNumber = x;remodulate_tuner();}};
Now the Television class has private state data (on, channelNumber) that is affected only by the public interface methods (powerOn(), powerOff(), changeChannel()) and a private implementation method remodulate_tuner() that cannot be called from outside the class.
There are a number of advantages of this approach. First, users of this class (another programmer) need not understand the inner workings of the Television class; they just need to understand the public interface. Second, the author of the Television class can modify and/or perfect the inner workings of the class without affecting other programmers' code.
Inheritance
Inheritance is a feature of OOP that enables building class descriptions from other class descriptions. Humans do this all the time; for example, if you were asked, “What is a duck?” you might respond with, “It's a bird that swims, and it has a bill instead of a beak.” This description is reasonably accurate, but it assumes that the concept of a bird is also understood. Importantly, the description states that the duck has the additional behavior of swimming but also that it has the replacement behavior of having a bill instead of a beak. You could loosely code this with pseudocode as follows:
class Bird{public:void fly();void describe() { cout << "Has a beak and can fly"; }};class Duck: public Bird{ // Duck IS-A BirdBill bill;public:void swim();void describe() { cout << "Has a bill and can fly and swim"; }};In this case, you can create an object of the Duck class:int main(){Duck d; //creates the Duck instance object dd.swim(); //specific to the Duck classd.fly(); //inherited from the parent Bird classd.describe(); //describe() is inheritated and overridden in Duck//so, "Has a bill and can fly and swim" would appear}
The example here illustrates why inheritance is so important. You can build code by inheriting from, and adding to, a class description (e.g., swim()) or inheriting from a parent class and replacing a behavior (e.g., describe()) to provide a more specific implementation—this is called overriding a method, which is a type of polymorphism (multiple forms). Another form of polymorphism is called overloading, which means multiple methods can have the same name, in the same class, disambiguated by the compiler by having different parameter types.
You can check that you have an inheritance relationship by the IS-A test; for example, a “duck is a bird” is valid, but a “bird is a duck” would be invalid because not all birds are ducks. This contrasts to the IS-A-PART-OF relationship; for example, a “bill is a part of a duck.” An IS-A-PART-OF relationship indicates that the bill is a member/state of the class. Using this simple check can be useful when the class relationships become complex.
You can also use pointers with objects of a class; for example, to dynamically allocate memory for two Duck objects, you can use the following:
int main(){Duck *a = new Duck();Bird *b = new Duck(); //parent pointer can point to a child objectb->describe(); //will actually describe a duck (if virtual)//b->swim(); //not allowed! Bird does not 'know' swim()}
Interestingly, the Bird pointer b is permitted to point at a Duck object. As the Duck class is a child of a Bird class, all of the methods that the Bird pointer can call are “known” by the Duck object. Therefore, the describe() method can be called. The arrow notation (b->describe()) is simply a neater way of writing (*b).describe(). In this case, the Bird pointer b has the static type Bird and the dynamic type Duck.
One last point is that an additional access specifier called protected can be used through inheritance. If you want to create a method or state in the parent class that you want to be available to the child class but you do not want to make public, then use the protected access specifier.
Object-Oriented LED Flashing Code
These OOP concepts can now be applied to a real C++ application on the Beagle boards by restructuring the functionally oriented C++ code into a class called LED, which contains states and methods. One difference with the code that is presented in Listing 5-17 is that it allows you to control the four user LEDs using the same OO code. Therefore, using the LED class, four different LED instance objects are created, each controlling one of the board's four physical user LEDs.
Listing 5-17: chp05/makeLEDOOP/makeLEDs.cpp
#include<iostream>#include<fstream>#include<string>#include<sstream>using namespace std;#define LED_PATH "/sys/class/leds/beaglebone:green:usr"class LED{private:string path;int number;virtual void writeLED(string filename, string value);virtual void removeTrigger();public:LED(int number);virtual void turnOn();virtual void turnOff();virtual void flash(string delayms);virtual void outputState();virtual ~LED();};LED::LED(int number){this->number = number; // set number state to be the number passed// next part is easier with C++11 (see Chp.7) using to_string(number)ostringstream s; // using a stream to contruct the paths << LED_PATH << number; // append LED number to LED_PATHpath = string(s.str()); // convert back from stream to string}void LED::writeLED(string filename, string value){ofstream fs;fs.open((path + filename).c_str());fs << value;fs.close();}void LED::removeTrigger(){writeLED("/trigger", "none");}void LED::turnOn(){cout << "Turning LED" << number << " on." << endl;removeTrigger();writeLED("/brightness", "1");}void LED::turnOff(){cout << "Turning LED" << number << " off." << endl;removeTrigger();writeLED("/brightness", "0");}void LED::flash(string delayms = "50"){cout << "Making LED" << number << " flash." << endl;writeLED("/trigger", "timer");writeLED("/delay_on", delayms);writeLED("/delay_off", delayms);}void LED::outputState(){ifstream fs;fs.open( (path + "/trigger").c_str());string line;while(getline(fs,line)) cout << line << endl;fs.close();}LED::~LED(){ // A destructor - called when the object is destroyedcout << "destroying the LED with path: " << path << endl;}int main(int argc, char* argv[]){if(argc!=2){cout << "Usage is makeLEDs <command>" << endl;cout << " command is one of: on, off, flash or status" << endl;cout << " e.g. makeLEDs flash" << endl;}cout << "Starting the makeLEDs program" << endl;string cmd(argv[1]);// Create four LED objects and put them in an arrayLED leds[4] = { LED(0), LED(1), LED(2), LED(3) };// Do the same operation on all four LEDs - easily changed!for(int i=0; i<=3; i++){if(cmd=="on")leds[i].turnOn();else if(cmd=="off")leds[i].turnOff();else if(cmd=="flash")leds[i].flash("100"); //default is "50"else if(cmd=="status")leds[i].outputState();else{ cout << "Invalid command!" << endl; }}cout << "Finished the makeLEDs program" << endl;return 0;}
This code can be built and executed by typing the following:
/chp05/makeLEDOOP$ ./build/chp05/makeLEDOOP$ ./makeLEDs status/chp05/makeLEDOOP$ sudo ./makeLEDs flash/chp05/makeLEDOOP$ sudo ./makeLEDs off
There are scripts in the directory /chp05/ to return the LEDs to their standard state, called restoreLEDsBeagleBone and restoreLEDsPocketBeagle:
/chp05$ sudo ./restoreLEDsBeagleBone/chp05$ sudo ./restoreLEDsPocketBeagle
This code is structured as a single class LED with private states for the path and the number, and private implementation methods writeLED() and removeTrigger(). These states and helper methods are not accessible outside the class. The public interface methods are turnOn(), turnOff(), flash(), and outputState(). There are two more public methods.
- The first is a constructor, which enables you to initialize the state of the object. It is called by
LED led(0)to create the objectledof theLEDclass with number0. This is similar to the way you assign initial values to anint, e.g.,int x = 5;. A constructor must have the same name as the class name (LEDin this case), and it cannot return anything, not evenvoid. - The last is a destructor (
~LED()). Like a constructor, it must have the same name as the class name and is prefixed by the tilde (~) character. This method is called automatically when the object is being destroyed. You can see this happening when you run the code sample.
The keyword virtual is also new. You can think of this keyword as “allowing overriding to take place when an object is dynamically bound.” It should always be there (except for the constructor), unless you know that there will definitely be no child class. Removing the virtual keyword will result in a slight improvement in the performance of your code.
The syntax voidLED::turnOn(){…} is simply used to state that the turnOn() method is the one associated with the LED class. It is possible to have many classes in the one .cpp file, and it would be possible for two classes to have a turnOn() method; therefore, the explicit association allows you to inform the compiler of the correct relationship. I have written this code in a single file, as it is the first example. However, you will see in later examples that it is better practice to break your code into header files (.h) and implementation files (.cpp).
Ideally the layout of the C++ version of the LED flashing code is clear at this point. The advantage of this OOP version is that you now have a structure that can be built upon when you want to provide additional functionality to interact with the system LEDs. In a later chapter, you will see how you can build similar structures to wrap electronic modules such as accelerometers and temperature sensors and how to use the encapsulation property of OOP to hide some of the more complex calculations from programmers who interface to the code.
Interfacing to the Linux OS
In Chapter 3, the Linux directory structure is discussed, and one of the directories discussed is the /proc/ directory—the process information virtual file system. It provides you with information about the run-time state of the kernel, and it enables you to send control information to the kernel. In effect, it provides you with a file-based interface from user space to kernel space. There is a Linux kernel guide to the /proc/ file system at tiny.cc/beagle502. For example, if you type the following:
debian@ebb:/proc$ cat cpuinfoprocessor : 0model name : ARMv7 Processor rev 2 (v7l)BogoMIPS : 995.32Features : half thumb fastmult vfp edsp thumbee neon vfpv3 tls vfpd32CPU implementer : 0x41CPU architecture: 7CPU variant : 0x3CPU part : 0xc08CPU revision : 2 …
it provides you with information on the CPU. Try some of the following: cat uptime, cat interrupts, cat version in the same directory. The example,
chp05/proc/readUptime.cpp, provides an example program to read the system uptime and calculate the percentage of system idle time.
Many /proc/ entries can be read by programs that execute with regular user accounts; however, many entries can be written to only by a program with superuser privileges. For example, entries in /proc/sys/kernel/ enable you to configure the parameters of a Linux kernel as it is executing.
You need to be careful with the consistency of the files in /proc/. The Linux kernel provides for atomic operations—instructions that execute without interruption. Certain “files” within /proc/ (such as /proc/uptime) are totally atomic and cannot be interrupted while these are being read; however, other files such as /proc/net/tcp are atomic only within each row of the file, meaning that the file will change as it is being read, and therefore simply reading the file may not provide a consistent snapshot.
Glibc and Syscall
The Linux GNU C library, glibc, provides an extensive set of wrapper functions for system calls. It includes functionality for handling files, signals, mathematics, processes, users, and much more. See tiny.cc/beagle503 for a full description of the GNU C library.
It is much more straightforward to call a glibc function than it is to parse the equivalent /proc/ entries. Listing 5-18 provides a C++ example that uses the glibc passwd structure to find out information about the current user. It also uses the syscall() function directly to determine the user's ID and to change the access permissions of a file—see the comments in the listing.
Listing 5-18: /exploringbb/chp05/syscall/glibcTest.cpp
#include<gnu/libc-version.h>#include<sys/syscall.h>#include<sys/types.h>#include<pwd.h>#include<cstdlib>#include<sys/stat.h>#include<iostream>#include<signal.h>#include<unistd.h>using namespace std;int main(){// Use helper functions to get system information:cout << "GNU libc version is: " << gnu_get_libc_version() << endl;// Use glibc passwd struct to get user information - no error check!:struct passwd *pass = getpwuid(getuid());cout << "The current user's login is: " << pass->pw_name << endl;cout << "-> their full name is: " << pass->pw_gecos << endl;cout << "-> their user ID is: " << pass->pw_uid << endl;// You can use the getenv() function to get environment variablescout << "The user's shell is: " << getenv("SHELL") << endl;cout << "The user's path is: " << getenv("PATH") << endl;// An example syscall to call a get the user ID -- see sys/syscall.hint uid = syscall(0xc7);cout << "Syscall gives their user ID as: " << uid << endl;// Call chmod directly -- type "man 2 chmod" for more informationint ret = chmod("test.txt", 0666);// Can use syscall to do the same thingret = syscall(SYS_chmod, "test.txt", 0666);return 0;}
This code can be tested as follows, where you can see that the file permissions are altered by the program, and the current user's information is displayed:
…/chp05/syscall$ touch test.txt…/chp05/syscall$ chmod 644 test.txt…/chp05/syscall$ ls -l test.txt-rw-r--r-- 1 debian debian 0 May 15 03:40 test.txt…/chp05/syscall$ sudo usermod -c "Exploring BeagleBone" debian…/chp05/syscall$ g++ glibcTest.cpp -o glibcTest…/chp05/syscall$ ./glibcTestGNU libc version is: 2.24The current user's login is: debian-> their full name is: Exploring BeagleBone-> their user ID is: 1000The user's shell is: /bin/bashThe user's path is: /home/debian/bin:/usr/local/sbin:/usr/…Syscall gives their user ID as: 1000…/chp05/syscall$ ls -l test.txt-rw-rw-rw- 1 debian debian 0 May 15 03:40 test.txt
There are many glibc functions, but the syscall() function requires special attention. It performs a generalized system call using the arguments that you pass to the function. The first argument is a system call number, as defined in /sys/syscall.h—you will need to follow through the header includes files to find the definitions. Alternatively, you can use syscalls.kernelgrok.com to search for definitions (e.g., search for SYS_getuid and you will see that the register eax = 0xc7, as used in Listing 5-18). Clearly, it is better if you use SYS_getuid instead.
Improving the Performance of Python
Despite the popularity of Python, it is clear from Table 5-1 that if you are to use it for certain embedded applications that you may need enhanced performance. This section describes two alternative approaches for addressing the performance issue by investigating Cython, as well as an alternative approach of extending Python with C/C++ code using Boost.Python.
Regardless of the approach taken, the first step is to set up your board so that you build a C/C++ module. You do this by installing the Python development package for the exact version of Python that you are using. Adapt the instructions in this section to use the library versions that you identify using the following steps:
debian@ebb:~$ python --versionPython 2.7.13debian@ebb:~$ python3 --versionPython 3.5.3debian@ebb:~$ sudo apt install python3-devdebian@ebb:~$ sudo apt install python-devdebian@ebb:~$ ls /usr/lib/arm-linux-gnueabihf/libpython*.so/usr/lib/arm-linux-gnueabihf/libpython2.7.so/usr/lib/arm-linux-gnueabihf/libpython3.5m.so
Cython
Cython is an optimizing compiler for Python and a language that extends Python with C-style functionality. Typically, the Cython compiler uses your Python code to generate efficient C shared libraries, which you can then import into other Python programs. However, to get the maximum benefit from Cython you must adapt your Python code to use Cython-specific syntax. The top-performing Cython entry in Table 5-1 (i.e., at 1.97×) is available at /performance/cython_opt/nbody.pyx. If you inspect the code, you will see the use of cdef C variable declarations and various variable types (e.g., double, int), which indicates the removal of dynamic typing from the base Python version (/performance/n-body.py).
A concise example is developed here to describe the first steps involved in adapting Python code to create Cython code. The example code proves the relationship ![]() by applying a simple numerical integration approach, as provided in Listing 5-19.
by applying a simple numerical integration approach, as provided in Listing 5-19.
Listing 5-19: /chp05/cython/test.py
from math import sindef integrate_sin(a,b,N):dx = (b-a)/Nsum = 0for i in range(0,N):sum += sin(a+i*dx)return sum*dx
The code in Listing 5-19 can be executed directly within the Python interpreter as follows (use exec(open("test.py").read()) under Python3):
debian@ebb:~/exploringbb/chp05/cython$ pythonPython 2.7.13 (default, Nov 24 2017, 17:33:09)>>> from math import pi>>> execfile('test.py')>>> integrate_sin(0,pi,1000)1.9999983550656624>>> integrate_sin(0,pi,1000000)1.9999999999984077
And, a timer can be introduced to evaluate its performance.
>>> import timeit>>> print(timeit.timeit("integrate_sin(0,3.14159,1000000)",setup →="from __main__ import integrate_sin", number=10))66.1992490292>>> quit()
The timeit module allows you to determine the execution duration of a function call. In this example, the PocketBeagle takes 66 seconds to evaluate the function 10 times, with N equal to 1,000,000.
It is possible to get a report on computationally costly dynamic Python behavior within your source code using the following:
debian@ebb:~/exploringbb/chp05/cython$ sudo apt install cythondebian@ebb:~/exploringbb/chp05/cython$ cython -a test.pydebian@ebb:~/exploringbb/chp05/cython$ ls -l *.html-rw-r--r-- 1 debian debian 30610 May 17 01:27 test.html
The darker the shade of yellow on a line in the HTML report, the greater the level of dynamic behavior that is taking place on that line.
Cython supports static type definitions, which greatly improves the performance of the code. The code can be adapted to test.pyx in Listing 5-20 where the types of the variables and return types are explicitly defined.
Listing 5-20: /chp05/cython/test.pyx
cdef extern from "math.h":double sin(double x)cpdef double integrate_sin(double a, double b, int N):cdef double dx, scdef int idx = (b-a)/Nsum = 0for i in range(0,N):sum += sin(a+i*dx)return sum*dx
An additional configuration file setup.py is required, as provided in Listing 5-21, so that Cython can compile the module correctly.
Listing 5-21: /chp05/cython/setup.py
from distutils.core import setupfrom distutils.extension import Extensionfrom Cython.Distutils import build_extext_modules = [Extension("test", ["test.pyx"])]setup(name = 'random number sum application',cmdclass = {'build_ext' : build_ext },ext_modules = ext_modules)
Python can use the setup.py configuration file to directly build the test.pyx file into C code (test.c), which is then compiled and linked to create a shared library (test.so). The library code can be executed directly within Python as follows, where the execution duration is 49 seconds—an improvement in performance.
…/chp05/cython$ python setup.py build_ext --inplacerunning build_ext……/chp05/cython$ lsbuild setup.py test.c test.html test.py test.pyx test.so…/chp05/cython$ pythonPython 2.7.13 (default, Nov 24 2017, 17:33:09)>>> import timeit>>> print(timeit.timeit("test.integrate_sin(0,3.14159,1000000)", →setup="import test",number=10))49.4493851662
Cython goes some way to addressing performance concerns that you may have in using Python; however, there is a significant learning curve in adapting Python code for efficiency, which has only been touched upon here. An alternative approach is to write custom C/C++ code modules that add to the capability of Python, rather than using Cython at all.
Boost.Python
An alternative approach is to extend Python with a wrapper that binds C/C++ and Python called Boost.Python, which essentially wraps the Python/C API. In addition, it simplifies the syntax and provides support for calls to C++ objects. You can search for the latest release and install Boost.Python on your board using the following steps (~119 MB):
debian@ebb:~$ apt-cache search libboost-pythonlibboost-python-dev - Boost.Python Library development files (default version)libboost-python1.62-dev - Boost.Python Library development fileslibboost-python1.62.0 - Boost.Python Librarydebian@ebb:~$ sudo apt install libboost-python1.62-dev
A C++ program can be developed as in Listing 5-22 that uses the Boost.Python library and its special BOOST_PYTHON_MODULE(name) macro that declares the Python module initialization functions—essentially replacing the verbose syntax that is present in Listing 5-21.
Listing 5-22: /chp05/boost/ebb.cpp
#include<string>#include<boost/python.hpp> // .hpp convention for c++ headersusing namespace std; // just like cpp for source filesnamespace exploringbb{ // keep the global namespace cleanstring hello(string name) { // e.g., returns "Hello Derek!"return ("Hello " + name + "!");}double integrate(double a, double b, int n) { // same as beforedouble sum=0, dx = (b-a)/n;for(int i=0; i<n; i++){ sum += sin((a+i)*dx); }return sum*dx;}}BOOST_PYTHON_MODULE(ebb){ // the module is called ebbusing namespace boost::python; // require the boost.python namespaceusing namespace exploringbb; // bring in custom namespacedef("hello", hello); // make hello() visible to Pythondef("integrate", integrate); // make integrate() also visible}
The code can be built into a shared library as before. Make sure to include the boost_python library in the build options.
…/chp05/boost$ g++ -O3 ebb.cpp -fPIC -shared -I/usr/include/ →python2.7/-lpython2.7 -lboost_python -o ebb.so…/chp05/boost$ ls -l *.so-rwxr-xr-x 1 debian debian 30092 May 17 01:56 ebb.so
The library can then be used by a Python script, such as that in Listing 5-23.
Listing 5-23: /chp05/boost/test.py
#!/usr/bin/python# A Python program that calls C program codeimport ebbprint "Start of the Python program"print ebb.hello("Derek")val = ebb.integrate(0, 3.14159, 1000000)print "The integral result is: ", valprint "End of the Python program"
The script in Listing 5-23 can be executed, resulting in the following output:
debian@ebb:~/exploringbb/chp05/boost$ ./test.pyStart of the Python programHello Derek!The integral result is: 1.99999999999End of the Python program
The code can be executed directly within Python as follows, where the execution duration is 6.7 seconds—a significant improvement in performance.
debian@ebb:~/exploringbb/chp05/boost$ python>>> import timeit>>> print(timeit.timeit("ebb.integrate(0, 3.14159, →1000000)",setup="import ebb",number=10))6.69945406914
Despite its large footprint, Boost.Python is the recommended approach for integrating C/C++ and Python code because of its performance, simplified syntax, and support for C++ classes. See tiny.cc/beagle504 for further details.
Summary
After completing this chapter, you should be able to
- Describe the multitude of issues that would impact on your choice of programming languages to use in building applications for the Beagle platform
- Write basic scripting language program code on your board that interfaces to the on-board LEDs
- Compare and contrast scripting, hybrid, and compiled programming languages, and their application to the embedded Linux applications
- Write C code examples that interface to the Beagle board's on-board LEDs
- Wrap C code in C++ classes to provide greater program structure
- Write advanced C/C++ code that is capable of interfacing to Linux operating system commands
- Write C/C++ modules that can be called directly from Python
Further Reading
Most of the sections in this chapter contain links to the relevant websites for further reading and reference materials. Here is a list of some books on programming that are relevant to the materials in this chapter:
- Bad to the Bone: Crafting Electronics Systems with BeagleBone Black, Steven Barrett and Jason Kridner (Morgan & Claypool, 2015)
- BeagleBone Cookbook: Software and Hardware Problems and Solutions, Mark A. Yoder and Jason Kridner (O'Reilly Media, 2015)
- BeagleBone for Dummies, Rui Santos and Luís Miguel Costa Perestrelo (Wiley, 2015)
Bibliography
- debian.org. (2013, 12 1). The Computer Language Benchmarks Game. Retrieved 5 17, 2018, from Debian.org:
benchmarksgame.alioth.debian.org - Hundt, R. (2011). Loop Recognition in C++/Java/Go/Scala. Proceedings of Scala Days 2011. Mountain View, CA.:
www.scala-lang.org. - Stroustrup, B. (1998, 10 14). International standard for the C++ programming language published. Retrieved 5 17, 2018, from www.stroustrup.com:
www.stroustrup.com/iso_pressrelease2.html