
Data sources are very similar to regular resources. The main difference is that they are read-only. You can't always (actually, far from it) you can have the complete infrastructure in your Terraform templates. It is often the case that some resources do already exist and you don't have much control over them. You still need to use them inside your Terraform templates, though. That's when data sources become handy.
In the Terraform documentation for each provider, there is a list of data sources (if any are available). They are configured almost the same as regular resources, with some differences.
Let's try them out in our template. There is a feature named VPC Peering in AWS. It allows connecting two different VPC in a way that instances inside both can talk to each other. We could have a VPC provided by other team, responsible for management layer for our infrastructure (artifacts storage, DNS, and so on). In order to access it from VPC we created with Terraform, we need to set up peering.
First, create a new VPC manually via AWS management console as shown in the following screenshot:
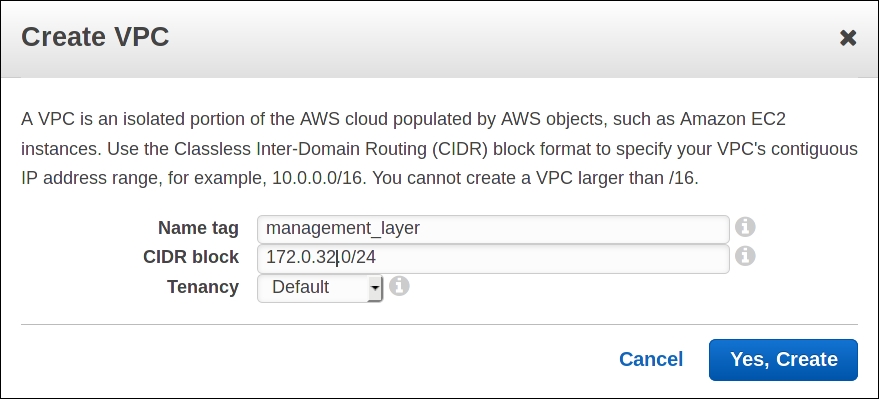
Then copy the ID of following VPC:
Now we are ready to use VPC data source. Add it to your template, before creating our old VPC:
data "aws_vpc" "management_layer" {
id = "vpc-c36cbdab"
}
Of course, you need to replace VPC ID with the one you've created manually. Now we can create a peering connection between manually created VPC and Terraform-created VPC:
data "aws_vpc" "management_layer" {
id = "vpc-c36cbdab"
}
resource "aws_vpc" "my_vpc" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_vpc_peering_connection" "my_vpc-management" {
peer_vpc_id = "${data.aws_vpc.management_layer.id}"
vpc_id = "${aws_vpc.my_vpc.id}"
auto_accept = true
}
Data sources are referenced with the data keyword in front of resource name.
That's not the most sophisticated example of data sources, as you might have noted: we could simply use management layer VPC ID directly, without data sources at all. There is, perhaps, a better example: fetching AMI ID's via data source.
AMI (Amazon Machine Image) is an image format used on AWS. It's a starting point for each EC2 instance. There are many publicly available AMIs for different operating systems, sometimes with software already preinstalled and preconfigured (such as Wordpress).
AWS users can create their own AMIs with the process widely named as image baking. The simplest way to bake an image is first to create a new instance from existing AMI, then configure it (manually or with some configuration management tool) and make a new AMI out of this instance.
Some companies take this process to extreme levels by baking tons of AMIs every day and recreating existing instances with new AMIs, instead of performing in-place upgrades. This approach enables to achieve so-called immutable infrastructure, where you never touch a running server at all and each update is performed by recreating an instance. We will learn how to do immutable infrastructure with Terraform in Chapter 6, Scaling and Updating Infrastructure.
HashiCorp tools, including Terraform, are often built with immutable infrastructure approach in mind. Packer, another product of this company, is focused exactly on creating images for multiple platforms. We are going to discuss how to orchestrate this kind of upgrades with Terraform in a later chapter. But in this chapter, let's use AMI data source inside application module to fetch an AMI for our EC2 instance:
data "aws_ami" "app-ami" {
most_recent = true
owners = ["self"]
}
resource "aws_instance" "app-server" {
ami = "${data.aws_ami.app-ami.id}"
instance_type = "${lookup(var.instance_type, var.environment)}"
subnet_id = "${var.subnet_id}"
vpc_security_group_ids = ["${concat(var.extra_sgs, aws_security_group.allow_http.*.id)}"]
tags {
Name = "${var.name}"
}
}
This code would pull most recently created AMI from the AWS account used for Terraform runs. We don't even need to know the ID; it will be retrieved automatically. For sure we shouldn't fetch most recent AMI all the time, but it can break the environment if most recent AMI is wrong. But then, of course, Terraform allows you to be more specific about which AMI to fetch using filters and regular expressions inside this data source. We will omit the usage of them and leave it as an exercise.
Data sources are relatively new concept in Terraform, and there are still not that many of them, especially for third-party providers, developed by community. Some of data sources might look almost useless, whereas others provide a handy way to retrieve remote data to use inside the template.
There are two particularly useful data sources that needs a longer discussion:
template_fileexternal_file
It's not an unusual situation when you need to provide long-form non-Terraform-specific text configuration to your Terraform templates. On many occasions, you need to pass to Terraform a bootstrap script for your virtual machines, or upload large file to S3, or, another example, configure IAM policies.
Sometimes, these files are static, that is, you don't need to change anything inside them, you just need to read their contents inside Terraform template. For this use case, there is a file() function. You pass a relative path to your file as an argument to this function, and it will read its contents to whatever place you need.
Let's use this function to upload a public SSH key to EC2. Add the following snippet to template.tf, right before an application module:
resource "aws_key_pair" "terraform" {
key_name = "terraform"
public_key = "${file("./id_rsa.pub")}"
}
You need to either copy existing public key to your working directory or generate new one with the ssh-keygen command. As an exercise, use this keypair when creating an application EC2 instance in order to get SSH access to it with your private key.
If you are a heavy IAM user, then you might want to create extra directory policies in your Terraform directory, where you could store all your json definitions of policies. Then, creating a policy could look as simple as:
resource "aws_iam_role_policy" "s3-assets-all" {
name = "s3=assets@all"
role = "${aws_iam_role.app-production.id}"
policy = "${file("policies/[email protected]")}"
}
AWS doesn't provide a convenient way to reuse and version policies. With Terraform, you can easily have both.
Note
As mentioned in Chapter 1, Infrastructure Automation, it is critical to have a solid naming scheme for everything you do in the cloud. In the earlier S3 policy snippet, one possible naming scheme is used: policy name is built as ${service_name}=${resource_name}@${action_name}. This makes the whole policies usage much cleaner.
Static files as a preceding public key example are common, but sometimes, you need more control over the contents of your files. Terraform provides the template_file data source, responsible for rendering text templates. It's really useful for bootstrap scripts, such as the ones you provide to cloud-init.
So far, we didn't do much of configuration of the EC2 instance we've created. Let's install some packages on it and then configure additional DNS server. We will set a DNS server as a variable for a root module and pass it down to the application module. We will also add an extra variable for packages to be installed for this module.
First, let's define new variables in variables.tf:
variable "external_nameserver" { default = "8.8.8.8" }
variable "extra_packages" {
description = "Additional packages to install for particular module"
default = {
MightyTrousers = "wget bind-utils"
}
}
Note how map is used here: one key per specific application. There is no way in Terraform to pass variables directly to modules. If you want to configure something in module, you need to define similar variable for the root module and then pass it to the module. Unfortunately, it means that you need to duplicate every variable: once in the root module, and then in the module you want to configure.
The problem comes when you reuse the same module multiple times, for example, to set up multiple different applications. In this case, multiple approaches can be used. You could prefix a variable name with a module instance name:
variable "mighty_trousers_extra_packages" { }
Or you could use maps and then lookup value you need. Using maps provides better grouping of variables, and it's easier to set default value:
variable "extra_packages" {
description = "Additional packages to install for particular module"
default = {
base = "wget"
MightyTrousers = "wget bind-utils"
}
}
Then, when you pass this variable to module, you can always fall back to default:
"${lookup(var.extra_packages, "my_app", "base")}
Let's pass the add variables to the module at the bottom of the modules/application/variables.tf file:
variable "extra_packages" {}
variable "external_nameserver" {}
At this point, it might be unclear when and where to specify default values for variables. We did specify them in a root module, but did not do it in application module. If we always pass variables from the top level to the module level, then there is no real need for defaults on the module level; defaults from the top will set values for the module. But if in some case we do not pass variables to module from the root module, then defaults for module variables are required. It depends on how you use and configure your modules.
In general, when it comes to configuring modules, current Terraform APIs to do it can seem a bit fragile and inflexible. You can easily end up with lots of duplication and a bit of a mess when it comes to finding the source of truth for variable values. It might become more robust in future Terraform releases, of course. But as of version 0.8, one needs to take these limitations in consideration.
We are finally ready to use template file data source. Add it to modules/application/application.tf:
data "template_file" "user_data" {
template = "${file("${path.module}/user_data.sh.tpl")}"
vars {
packages = "${var.extra_packages}"
nameserver = "${var.external_nameserver}"
}
}
The template_file allows to pass variables to the file, thus giving you a chance to configure this file with some specific values. The file itself is specified as a template parameter. Note the use of ${path.module}: by default path will be relative to the root template files. ${path.module} allows you to use the path to the module folder without guessing it.
Create a file modules/application/user_data.sh.tpl with the following content:
#!/usr/bin/bash yum install ${packages} -y echo "${nameserver}" >> /etc/resolv.conf
Variables inside template files are used pretty much the same way they are used in Terraform templates. You need to be careful, though: dollar sign is used in both Terraform and regular bash scripts. Sometimes, you will have to escape the dollar sign, so Terraform doesn't try to interpolate it and therefore doesn't fail. Escaping is done simply by duplicating dollar sign: $$.
Finally, let's render this template file as a user data for the instance:
resource "aws_instance" "app-server" {
ami = "${data.aws_ami.app-ami.id}"
instance_type = "${lookup(var.instance_type, var.environment)}"
subnet_id = "${var.subnet_id}"
vpc_security_group_ids = ["${concat(var.extra_sgs, aws_security_group.allow_http.*.id)}"]
user_data = "${data.template_file.user_data.rendered}"
tags {
Name = "${var.name}"
}
}
Now, if we got the script right, after EC2 instance will be created, cloud-init will run this script and extra packages as well as new external nameserver will be configured.
Changing user_data normally leads to resource recreation. We don't really want our server to be destroyed when this file changes. Let's revise what we learned in previous chapter about lifecycle block and tell the instance to ignore changes of user_data:
lifecycle {
ignore_changes = ["user_data"]
}
Template files provide an easy way to generate bigger configuration files that can later be reused in order to set up the machines, external services, and so on. For cloud-init, use-case Terraform also provides the template_cloud_init_config resource that renders multipart cloud-init config from source files.
A template file is not the only provider that is useful for configuration purposes. Let's take a quick look at few other resources Terraform provides.
Since Terraform 0.8, there is also an external_data resource. It allows us to call any other program and use the data returned by it, as long as it implements a specific protocol. The main requirement for this program is that it returns a valid JSON as a result of execution. Create the following tiny Ruby script in the root template directory:
require 'json'
data = {
owner: "Packt"
}
puts data.to_json
Now configure external data resource as follows:
data "external" "example" {
program = ["ruby", "${path.module}/custom_data_source.rb"]
}
Finally, use it inside the module to extend its name attribute:
module "mighty_trousers" {
source = "./modules/application"
vpc_id = "${aws_vpc.my_vpc.id}"
subnet_id = "${aws_subnet.public.id}"
name = "MightyTrousers-${data.external.example.result.owner}"
# ...
}
As you see, you can access any JSON object key via the result attribute of external data source. As of Terraform version 0.8.2, it is not possible to use nested keys from the result, it is limited to the flat objects.
An external data source is an extremely powerful resource. Essentially, it allows you to connect absolutely any data source to your Terraform templates - third party APIs, SQL databases, NoSQL databases, you name it. You just need to implement a tiny wrapper between Terraform and this data source to comply with what Terraform expects. You could even connect Terraform to the data storage of your configuration management tool, be it Puppet Hiera, Puppet DB, or Chef APIs.
Note, though, that using this resource you need to ensure that every machine that uses this template has all the software used inside external data source program - Terraform won't do that for you. In the previously mentioned example, you need to make sure that Terraform users have Ruby installed. That's also the reason why Terraform Enterprise can't guarantee that your template will work well when it has this data source; you cannot expect Terraform Enterprise to have any extra software installed.
Remove the external data source from our root template. There are some more resources that give you a bit more flexibility in terms of configuring your templates. Let's explore them.